实践篇:利用ragas在自己RAG上实现LLM评估②
文章目录
- 使用ragas做评估
- 在自己的数据集上评估
- 完整代码
- 代码讲解
- 1. RAG系统构建
- 核心组件初始化
- 文档处理流程
- 2. 评估数据集构建
- 3. RAGAS评估实现
- 1. 评估数据集创建
- 2. 评估器配置
- 3. 执行评估
本系列阅读:
理论篇:RAG评估指标,检索指标与生成指标①
实践篇:利用ragas在自己RAG上实现LLM评估②
首先我们可以共识LLM的评估最好/最高效的方式就是再利用LLM的强大能力,而不是用传统指标。
假设我们不用LLM评估我们只有两条方式可实现:
- 传统指标,如Bleu。需输入标准答案(通常也是人工审核答案是不是标准的,或者是人工制造标准答案),缺点是效果有限,用了都知道效果惨不忍睹。
- 纯人工打分。缺点是耗时,带有主观性。
使用ragas做评估
推荐一个包ragas。但是它的教程文档确实写得不太好,可能是jupyter格式,直接在py中运行,总是会报少变量之类。我这边都改动了下,确保我们py文件可以运行。
ragas(Retrieval Augmented Generation Assessment)是社区最著名的评估方案,内置了我们常见的评估指标。
利用了LLM评估,因此不需要人工打标。其出名是因为封装了LLM做评估,简单易用(当然其实这些也是我们可以造轮子实现的~)。
代码链接https://github.com/blackinkkkxi/RAG_langchain/blob/main/learn/evaluation/RAGAS-langchian.ipynb
在自己的数据集上评估
完整可运行的代码见本文的完整代码小节,代码可运行。而1~3我们会拆开完整代码讲解,代码主要用于讲解完整代码,可能不能运行。
完整代码
在使用我的代码你只需要把deepseekapi换成你自己的即可。
import os
import re
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.chat_models import init_chat_model
from ragas import evaluate
from ragas.llms import LangchainLLMWrapper
from ragas import EvaluationDataset
from ragas.metrics import LLMContextRecall, Faithfulness, FactualCorrectnessclass RAG:def __init__(self, api_key=None):"""使用DeepSeek模型和BGE嵌入初始化RAG系统"""# 设置环境变量os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 初始化对话模型self.llm = init_chat_model(model="deepseek-chat",api_key=api_key,api_base="https://api.deepseek.com/",temperature=0,model_provider="deepseek",)# 初始化嵌入模型self.embedding_model = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")# 初始化文本分割器self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50)# 初始化向量存储和检索器self.vectorstore = Noneself.retriever = Noneself.qa_chain = None# 设置提示模板self.template = """根据以下已知信息,简洁并专业地回答用户问题。如果无法从中得到答案,请说"我无法从已知信息中找到答案"。已知信息:{context}用户问题:{question}回答:"""self.prompt = PromptTemplate(template=self.template,input_variables=["context", "question"])def load_documents_from_url(self, url, persist_directory="./chroma_db"):"""从网页URL加载文档并创建向量存储"""# 从网页加载文档loader = WebBaseLoader(url)documents = loader.load()# 将文档分割成块chunks = self.text_splitter.split_documents(documents)# 创建向量存储self.vectorstore = Chroma.from_documents(documents=chunks,embedding=self.embedding_model,persist_directory=persist_directory)# 创建检索器self.retriever = self.vectorstore.as_retriever()# 创建问答链self.qa_chain = RetrievalQA.from_chain_type(llm=self.llm,chain_type="stuff",retriever=self.retriever,chain_type_kwargs={"prompt": self.prompt})print(f"成功从 {url} 加载并处理文档")def ask(self, question):"""便捷的提问方法"""result = self.qa_chain.invoke({"query": question})return result["result"]def relevant_docs_with_scores(self, query, k=1):"""计算相关文档及其相似度分数,返回处理后的文档信息"""docs_with_scores = self.vectorstore.similarity_search_with_score(query, k=k)# 处理文档内容processed_docs = []for i, (doc, score) in enumerate(docs_with_scores, 1):# 清理文档内容content = doc.page_content.strip()# 去除回车符、换行符和多余的空白字符content = content.replace('\n', ' ').replace('\r', ' ').replace('\t', ' ')# 合并多个连续空格为单个空格content = re.sub(r'\s+', ' ', content)processed_docs.append({'index': i,'score': score,'content': content})return processed_docs# 使用示例
if __name__ == "__main__":api_key = "X"queries = ["为什么Transformer需要位置编码?","QKV矩阵是怎么得到的?","注意力机制的本质是什么?","对于序列长度为n的输入,注意力机制的计算复杂度是多少?","在注意力分数计算中,为什么要除以√d?","多头注意力机制的主要作用是什么?","解码器中的掩码自注意力是为了什么?","编码器-解码器注意力中,Query来自哪里?","GPT系列模型使用的是哪种架构?","BERT模型适合哪类任务?"]# 初始化RAGrag = RAG(api_key)# 从URL加载文档rag.load_documents_from_url("https://blog.csdn.net/ngadminq/article/details/147687050")expected_responses = ["Transformer的输入是并行处理的,不像RNN有天然的序列关系,因此需要位置编码来为模型提供词元在序列中的位置信息,确保模型能理解词的先后顺序。","QKV矩阵通过将输入向量分别与三个不同的权重矩阵W_q、W_k、W_v进行线性投影得到,这三个权重矩阵是模型的可学习参数,在训练过程中不断优化。","注意力机制的本质是为序列中的每个词找到重要的上下文信息,通过计算词与词之间的相关性分数,实现对重要信息的聚焦和整合。","注意力机制的计算复杂度是O(n²),因为序列中每个词都需要与所有其他词计算注意力分数,形成n×n的注意力矩阵。","除以√d是为了提升训练稳定性,防止注意力分数过大导致softmax函数进入饱和区,确保梯度能够有效传播。","多头注意力机制可以从多个角度捕捉不同类型的词间关联,比如语义关系、句法关系等,增强了模型的表达能力和理解能力。","解码器中的掩码自注意力是为了防止当前位置关注未来位置的信息,确保在自回归生成过程中每个位置只能看到当前及之前的信息。","在编码器-解码器注意力中,Query来自解码器的前一层输出,而Key和Value来自编码器的最终输出,这样解码器就能利用编码器处理的源序列信息。","GPT系列模型使用仅解码器架构,专门针对文本生成任务设计,通过掩码自注意力机制实现从左到右的序列生成。","BERT模型适合分类和理解类任务,如文本分类、命名实体识别、情感分析、问答等,因为它使用双向编码器可以同时关注上下文信息。"]dataset = []for query, reference in zip(queries, expected_responses):# 获取相关文档及分数并打印relevant_docs = rag.relevant_docs_with_scores(query)relevant_docs = relevant_docs[0]['content']response = rag.ask(query)dataset.append({"user_input": query,"retrieved_contexts": [relevant_docs],"response": response,"reference": reference})evaluation_dataset = EvaluationDataset.from_list(dataset)llm = init_chat_model(model="deepseek-chat",api_key=api_key,api_base="https://api.deepseek.com/",temperature=0,model_provider="deepseek",)evaluator_llm = LangchainLLMWrapper(llm)result = evaluate(dataset=evaluation_dataset, metrics=[LLMContextRecall(), Faithfulness(), FactualCorrectness()],llm=evaluator_llm)print(result)以下是运行的结果:
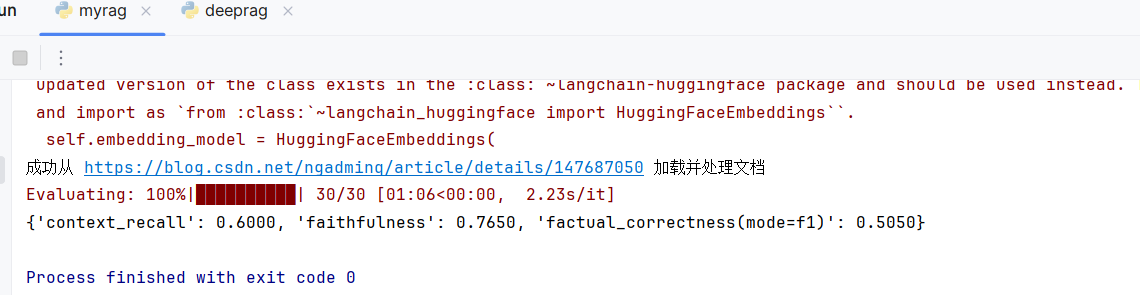
根据我们的结果指标可以针对指标有优化方向
代码讲解
1. RAG系统构建
核心组件初始化
class RAG:def __init__(self, api_key=None):# DeepSeek聊天模型self.llm = init_chat_model(model="deepseek-chat",api_key=api_key,api_base="https://api.deepseek.com/",temperature=0,model_provider="deepseek",)# BGE中文嵌入模型self.embedding_model = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")# 文本分割器self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50)
技术要点:
- 使用DeepSeek作为生成模型,temperature=0确保输出稳定性
- BGE-large-zh-v1.5是目前中文嵌入效果较好的开源模型
- 文本分块策略:500字符块大小,50字符重叠防止信息丢失
文档处理流程
def load_documents_from_url(self, url, persist_directory="./chroma_db"):# 1. 网页内容加载loader = WebBaseLoader(url)documents = loader.load()# 2. 文档分块chunks = self.text_splitter.split_documents(documents)# 3. 向量化存储self.vectorstore = Chroma.from_documents(documents=chunks,embedding=self.embedding_model,persist_directory=persist_directory)# 4. 构建检索链self.qa_chain = RetrievalQA.from_chain_type(llm=self.llm,chain_type="stuff",retriever=self.retriever,chain_type_kwargs={"prompt": self.prompt})
2. 评估数据集构建
数据集需要包含四个核心要求
dataset.append({"user_input": str, # 用户查询,即我们备好的一系列问题"retrieved_contexts": [str,str], # 检索到的上下文,list格式"response": str, # 系统回答"reference": str # 标准答案,人工制造,我这里使用cluade生成的
})
3. RAGAS评估实现
1. 评估数据集创建
from ragas import EvaluationDataset
evaluation_dataset = EvaluationDataset.from_list(dataset)
2. 评估器配置
from ragas.llms import LangchainLLMWrapper
evaluator_llm = LangchainLLMWrapper(llm)
关键点: RAGAS使用LLM作为评估器,需要将LangChain模型包装成RAGAS兼容格式
3. 执行评估
代码使用了三个核心评估指标:
LLMContextRecall(上下文召回率)
- 作用: 评估检索到的上下文是否包含回答问题所需的信息
- 计算方式: 通过LLM判断标准答案中的信息有多少能在检索上下文中找到
- 公式: Context Recall = 可在上下文中找到的标准答案句子数 / 标准答案总句子数
Faithfulness(忠实度)
- 作用: 衡量生成回答与检索上下文的一致性,防止幻觉
- 计算方式: 检查回答中的每个声明是否能在提供的上下文中得到支持
- 公式: Faithfulness = 有上下文支持的声明数 / 总声明数
FactualCorrectness(事实正确性)
- 作用: 评估生成回答的事实准确性
- 计算方式: 将生成回答与标准答案进行事实层面的比较
- 评估维度: 包括事实的正确性、完整性和相关性
from ragas.metrics import LLMContextRecall, Faithfulness, FactualCorrectnessresult = evaluate(dataset=evaluation_dataset, metrics=[LLMContextRecall(), Faithfulness(), FactualCorrectness()],llm=evaluator_llm
)
相关文章:
实践篇:利用ragas在自己RAG上实现LLM评估②
文章目录 使用ragas做评估在自己的数据集上评估完整代码代码讲解1. RAG系统构建核心组件初始化文档处理流程 2. 评估数据集构建3. RAGAS评估实现1. 评估数据集创建2. 评估器配置3. 执行评估 本系列阅读: 理论篇:RAG评估指标,检索指标与生成指…...

【CVE-2025-4123】Grafana完整分析SSRF和从xss到帐户接管
摘要 当Web应用程序使用URL参数并将用户重定向到指定的URL而不对其进行验证时,就会发生开放重定向。 /redirect?url=https://evil.com`–>(302重定向)–>`https://evil.com这本身可能看起来并不危险,但这种类型的错误是发现两个独立漏洞的起点:全读SSRF和帐户接管…...

高精度滚珠导轨在医疗设备中的多元应用场景
在医疗行业不断追求高效、精准与安全的今天,医疗设备的性能优化至关重要。每一个精密部件都像是设备这个庞大“生命体”中的细胞,共同维持着设备的稳定运行。滚珠导轨,这一看似不起眼却功能强大的传动元件,正悄然在医疗设备领域发…...

深入理解Java单例模式:确保类只有一个实例
文章目录 什么是单例模式?为什么我们需要单例模式?单例模式的常见实现方式1. 饿汉式(Eager Initialization)2. 懒汉式(Lazy Initialization)3. 双重检查锁定(Double-Checked Locking - DCL&…...

JavaScript性能优化实战:从核心原理到工程实践的全流程解析
下面我给出一个较为系统和深入的解析,帮助你理解和实践“JavaScript 性能优化实战:从核心原理到工程实践的全流程解析”。下面的内容不仅解释了底层原理,也结合实际工程中的最佳模式和工具,帮助你在项目中贯彻性能优化理念&#x…...

【应用】Ghost Dance:利用惯性动捕构建虚拟舞伴
Ghost Dance是葡萄牙大学的一个研究项目,研究方向是探索人与人之间的联系,以及如何通过虚拟舞伴重现这种联系。项目负责人Cecilia和Rui利用惯性动捕创造出具有流畅动作的虚拟舞伴,让现实中的舞者也能与之共舞。 挑战:Ghost Danc…...
使用 Mechanical 脚本获取联合反作用力和力矩
介绍 在上一篇文章中,我们详细介绍了在 Ansys Mechanical 静态/瞬态结构、随机振动和/或响应谱分析中提取所有螺栓连接的反作用力的过程。他,我们将讨论如何使用 Python 代码结果对象对关节连接执行相同的作,这对于随机振动/响应谱分析非常有…...

Java垃圾回收机制详解:从原理到实践
Java垃圾回收机制详解:从原理到实践 前言 垃圾回收(Garbage Collection,简称GC)是Java虚拟机自动管理内存的核心机制之一。它负责自动识别和回收不再被程序使用的内存空间,从而避免内存泄漏和溢出问题。深入理解垃圾…...

thinkphp8.1 调用巨量广告API接口,刷新token
1、在mysql中建立表sys_token; CREATE TABLE sys_token (id int UNSIGNED NOT NULL,access_token varchar(50) COLLATE utf8mb4_general_ci NOT NULL,expires_in datetime NOT NULL,refresh_token varchar(50) COLLATE utf8mb4_general_ci NOT NULL,refresh_token_expires_in …...

物联网数据归档方案选择分析
最近在做数据统计分析。我在做数据分析时候,需要设计归档表。有两种方式, 方式1:年月日。 其中,日表是每小时数据,每台设备有24条数据 月表是每天数据,每台设备根据实际月天数插入 年表是每月数据,每台设备有12条数据。 方式2:年月日时。 其中,小时表,是每个设备每小…...
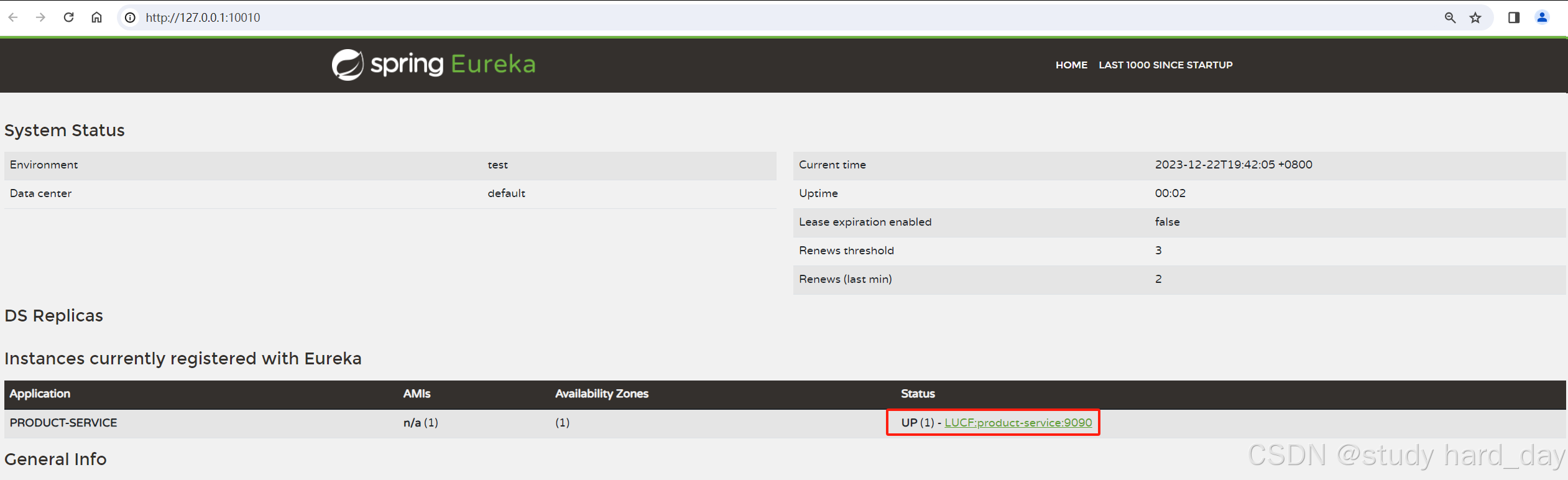
微服务架构下的服务注册与发现:Eureka 深度解析
📦 一、引言 🌐 微服务架构中服务注册与发现的核心价值 在微服务架构中,服务注册与发现是支撑系统可扩展性、高可用性和动态管理的关键基础。 ✅ 核心价值解析 动态扩展与弹性伸缩 服务实例可随时上线/下线,无需手动更新配置&am…...
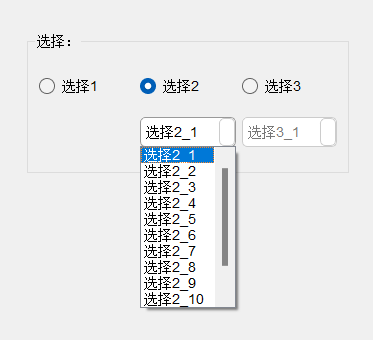
Qt/C++学习系列之QButtonGroup的简单使用
Qt/C学习系列之QButtonGroup的简单使用 前言QButtonGroup刨析源码 具体使用界面设计具体函数使用初始化信号与槽函数(两种方式) 总结 前言 在练手项目中,使用了QButtonGroup。项目需求有互斥的要求,在使用QRadioButton的基础上&a…...

CETOL 6σ v12.1 三维公差分析软件现已可供下载
一、新版本发布 德克萨斯州麦金尼 — 2025年6月5日 —Sigmetrix 宣布其最新版本的 CETOL 6σ 公差分析软件(v12.1)现已可供立即下载。公差分析在诸多方面为企业发展带来益处。它通过平衡质量与制造成本,助力企业提升盈利能力。企业还可借此缩…...

【JavaEE】Spring Boot项目创建
Spring Boot介绍 在学习Spring Boot之前,我们先来认识一下Spring Spring官方是这样介绍的: 可以看到,Spring让Java程序更加快速,简单和安全。Spring对于速度,简单性和生产力的关注使其成为世界上最流行的Java框架 Sp…...

KAG与RAG在医疗人工智能系统中的多维对比分析
1、引言 随着人工智能技术的迅猛发展,大型语言模型(LLM)凭借其卓越的生成能力在医疗健康领域展现出巨大潜力。然而,这些模型在面对专业性、时效性和准确性要求极高的医疗场景时,往往面临知识更新受限、事实准确性不足以及幻觉问题等挑战。为解决这些问题,检索增强生成(…...

车牌识别技术解决方案
在城市化进程不断加速的背景下,小区及商业区域的车辆管理问题日益凸显。为解决这一问题,车牌识别技术应运而生,成为提升车辆管理效率与安全性的关键手段。本方案旨在详细介绍车牌识别系统的基本原理、功能设计、实施流程以及预期效益…...
)
C/C++ 面试复习笔记(4)
1.在多线程的 Linux 程序中,调用系统函数(如pthread_create 创建线程、pthread_mutex_lock 锁定互斥锁等)可能会返回错误码。 与单线程环境相比,多线程环境下的错误处理有哪些需要特别注意的地方?请举例说明如何在多线…...

Unity 大型手游碰撞性能优化指南
Unity 大型手游碰撞性能优化指南 版本: 2.1 作者: Unity性能优化团队 语言: 中文 前言 在Unity大型手游的开发征途中,碰撞检测如同一位隐形的舞者,它在游戏的物理世界中赋予物体交互的灵魂。然而,当这位舞者的舞步变得繁复冗余时,便会悄然消耗宝贵的计算资源,导致帧率下…...

Git仓库的创建
Git服务器准备 假设Git所在服务器为Ubuntu系统,IP地址10.17.1.5。 一. 准备运行git服务的git用户,这里用户名就直接设定为git。 1. 创建一个git用户组,并创建git用户。 sudo groupadd git sudo useradd git -g git 2. 创建git用户目录&…...
从零到一:Maven 快速入门教程
目录 Maven 简介Maven 是什么为什么使用 Maven? 安装 Maven下载 Maven 配置 Maven解压文件配置本地仓库保存路径配置国内仓库地址 Maven 的核心概念了解 pom.xml 文件坐标依赖范围生命周期compileprovidedruntimetestsystemimport 依赖传递依赖排除依赖循环 继承1. …...

DDD架构实战 领域层 事件驱动
目录 核心实现: 这种实现方式的优势: 在实际项目中,你可能需要: 事件驱动往往是在一个微服务内部实现的 领域时间是DDD架构中比较常见的概念 在领域层内部的一个模型更改了状态或者发生了一些行为 向外发送一些通知 这些通…...
 报错:UnsupportedOperationException)
c# List<string>.Add(s) 报错:UnsupportedOperationException
在使用c#读取目录下指定格式文件目录后,使用List<string>.Add 来保存文件名时,出现UnsupportedOperationException错误,找了好久不知道问题出在哪里。 以下是错误代码: using (var fbd new FolderBrowserDialog{Descripti…...
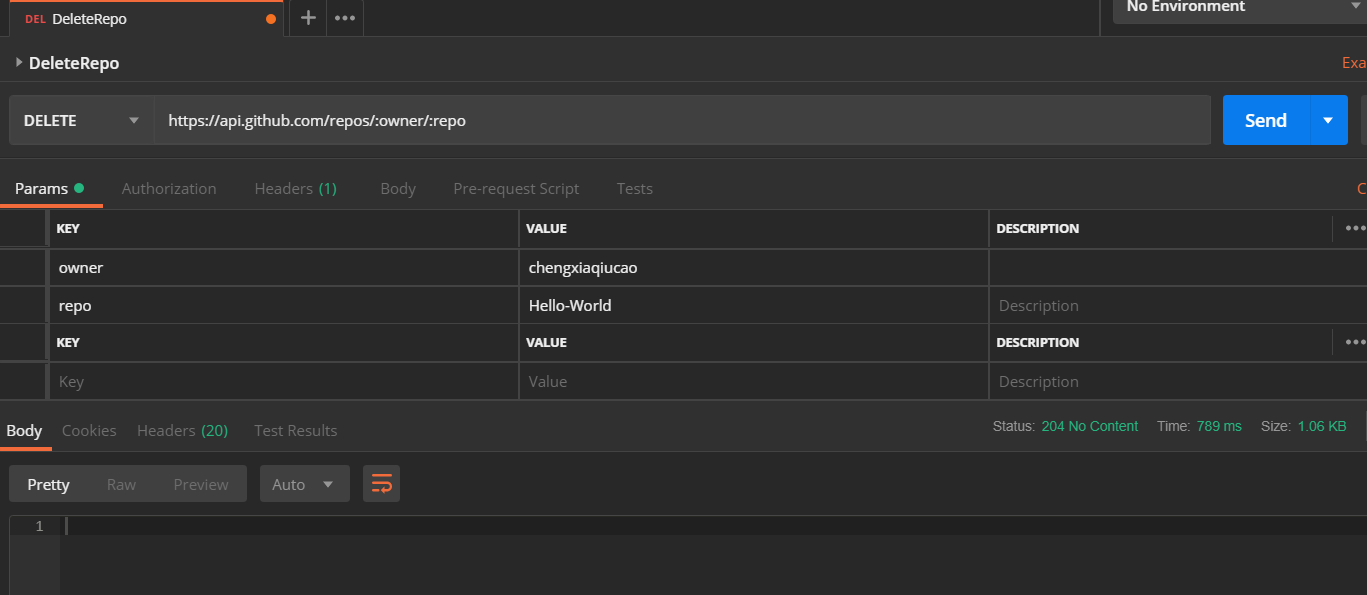
postman基础
前言 本次 Chat 将结合业界广为推崇和使用的 RestAPI 设计典范 Github API,详细介绍 Postman 接口测试工具的使用方法和实战技巧。 在开始这个教程之前,先聊一下为什么接口测试在现软件行业如此重要? 为什么我们要学习 Postman?…...
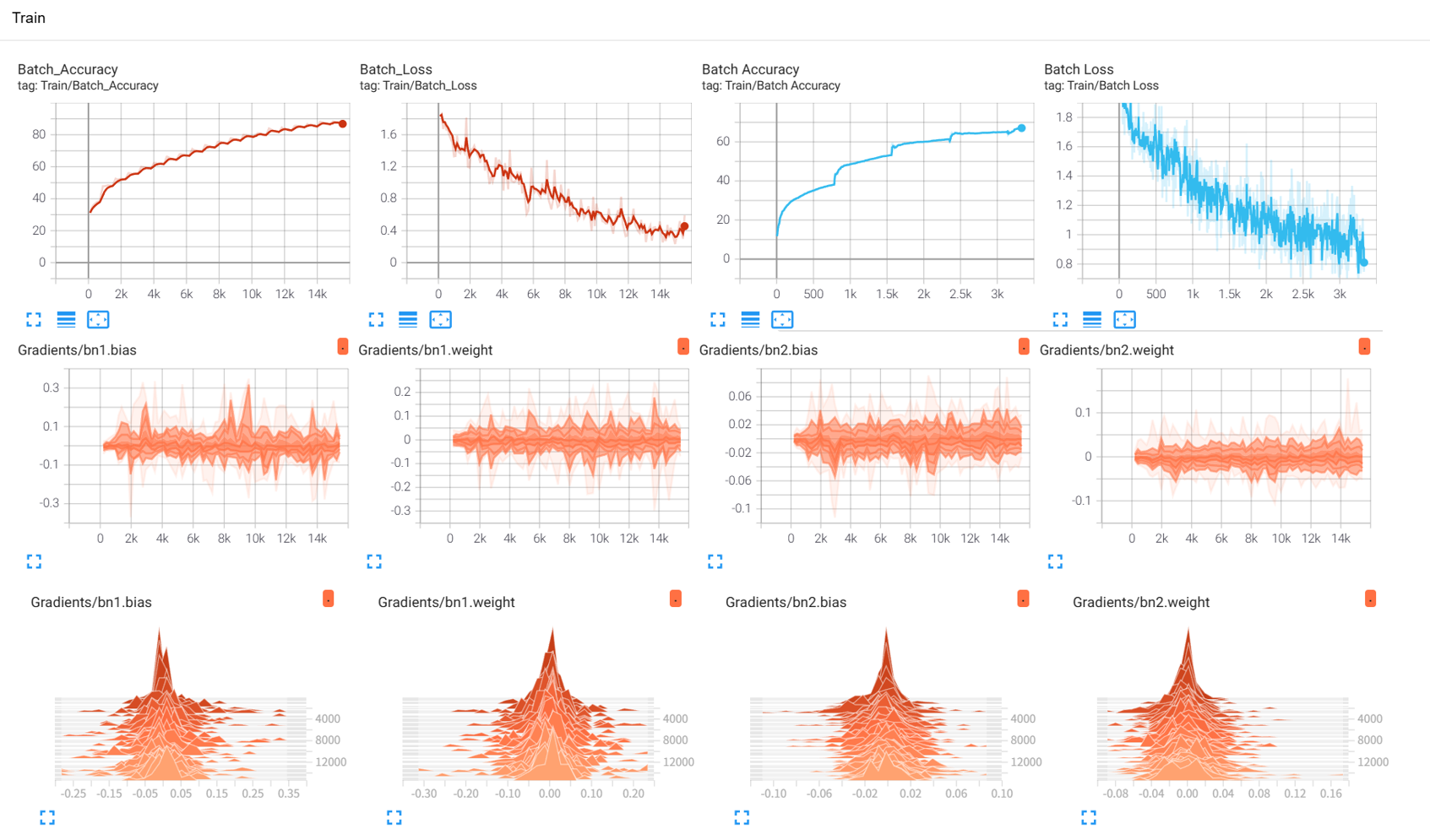
python训练营day45
知识点回顾: tensorboard的发展历史和原理tensorboard的常见操作tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策略下,用tensorbo…...

B+树知识点总结
核心目标:减少磁盘 I/O 数据库系统(如 MySQL)的主要性能瓶颈通常在于磁盘 I/O(读取和写入数据到物理硬盘的速度远慢于内存访问)。B 树的设计核心就是最大限度地减少访问数据时所需的磁盘 I/O 次数。 一、B 树的基本结…...
Halcon透视矩阵
在 Halcon中,透视变换矩阵用于将图像从一个视角转换到另一个视角,常用于图像校正和几何变换。以下是计算透视变换矩阵的步骤及代码示例。 透视形变图像校正的步骤 对图像左简单的处理,分割要校正的区域;提取区域的顶点坐标信息&…...

SpringCloud——OpenFeign
概述: OpenFeign是基于Spring的声明式调用的HTTP客户端,大大简化了编写Web服务客户端的过程,用于快速构建http请求调用其他服务模块。同时也是spring cloud默认选择的服务通信工具。 使用方法: RestTemplate手动构建: // 带查询…...

007-nlohmann/json 项目应用-C++开源库108杰
本课为 fswatch(第一“杰”)的示例项目加上对配置文件读取的支持,同时借助 第三“杰” CLI11 的支持,完美实现命令行参数与配置文件的逻辑统一。 012-nlohmann/json-4-项目应用 项目基于原有的 CMake 项目 HelloFSWatch 修改。 C…...

移动端测试岗位高频面试题及解析
文章目录 一、基础概念二、自动化测试三、性能测试四、专项测试五、安全与稳定性六、高级场景七、实战难题八、其他面题 一、基础概念 移动端测试与Web测试的核心区别? 解析:网络波动(弱网测试)、设备碎片化(机型适配&…...

gvim比较两个文件不同并合并差异
使用 gvim 比较两个文件的不同: 方式一,使用 gvim 同时打开两个待比较的文件。 比较通用方式是采用 gvim -d 选项,具体命令,如下: gvim -d <file1> <file2>方式二,先用 gvim 打开一个文件&am…...