Double/Debiased Machine Learning
独立同步分布的观测数据 { W i = ( Y i , D i , X i ) ∣ i ∈ { 1 , . . . , n } } \{W_i=(Y_i,D_i,X_i)| i\in \{1,...,n\}\} {Wi=(Yi,Di,Xi)∣i∈{1,...,n}},其中 Y i Y_i Yi表示结果变量, D i D_i Di表示因变量, X i X_i Xi表示控制变量。
目标参数 θ 0 \theta_0 θ0的一般定义形式为:
E [ m ( W ; θ 0 , η 0 ) ] = 0 E[m(W;\theta_0,\eta_0)] = 0 E[m(W;θ0,η0)]=0
W W W为观测到的变量, θ 0 ∈ Θ \theta_0\in \Theta θ0∈Θ为目标参数, η 0 ∈ T \eta_0\in \mathcal{T} η0∈T为辅助参数
例如,ATE 的定义为:
θ 0 A T E ≡ E [ E [ Y i ∣ D i = 1 , X i ] − E [ Y i ∣ D i = 0 , X i ] ] \theta_0^{ATE}\equiv E[E[Y_i|D_i=1,X_i] - E[Y_i|D_i=0,X_i]] θ0ATE≡E[E[Yi∣Di=1,Xi]−E[Yi∣Di=0,Xi]]
ATE的IPW估计定义为:
m I P W ( W i ; θ , α ) ≡ α ( D i , X i ) Y i − θ ≡ [ D i E [ D i ∣ X i ] − 1 − D i 1 − E [ D i ∣ X i ] ] Y i − θ m_{IPW}(W_i;\theta,\alpha)\equiv \alpha(D_i,X_i)Y_i - \theta \equiv [\frac{D_i}{E[D_i|X_i]} - \frac{1-D_i}{1-E[D_i|X_i]}]Y_i - \theta mIPW(Wi;θ,α)≡α(Di,Xi)Yi−θ≡[E[Di∣Xi]Di−1−E[Di∣Xi]1−Di]Yi−θ
ATE的Doubly Robust估计的定义为:
m D R ( W i ; θ , η ) ≡ α ( D i , X i ) ( Y i − E [ Y i ∣ D i , X i ] ) Y i + E [ Y i ∣ D i = 1 , X i ] − E [ Y i ∣ D i = 0 , X i ] − θ m_{DR}(W_i;\theta,\eta)\equiv \alpha(D_i,X_i)(Y_i - E[Y_i|D_i,X_i])Y_i + E[Y_i|D_i=1,X_i]- E[Y_i|D_i=0,X_i]-\theta mDR(Wi;θ,η)≡α(Di,Xi)(Yi−E[Yi∣Di,Xi])Yi+E[Yi∣Di=1,Xi]−E[Yi∣Di=0,Xi]−θ
≡ [ D i E [ D i ∣ X i ] − 1 − D i 1 − E [ D i ∣ X i ] ] Y i + E [ Y i ∣ D i = 1 , X i ] − E [ Y i ∣ D i = 0 , X i ] − θ \equiv [\frac{D_i}{E[D_i|X_i]} - \frac{1-D_i}{1-E[D_i|X_i]}] Y_i + E[Y_i|D_i=1,X_i]- E[Y_i|D_i=0,X_i]-\theta ≡[E[Di∣Xi]Di−1−E[Di∣Xi]1−Di]Yi+E[Yi∣Di=1,Xi]−E[Yi∣Di=0,Xi]−θ
一般情况下,目标参数 θ 0 \theta_0 θ0的估计值定义为:
θ ^ : 1 n ∑ i = 1 n m ( W i ; θ ^ , η ^ ) = 0 \hat{\theta}:\frac{1}{n}\sum_{i=1}^nm(W_i;\hat{\theta},\hat{\eta}) = 0 θ^:n1i=1∑nm(Wi;θ^,η^)=0
一阶泰勒展得出:
1 n ∑ i = 1 n m ( W i ; θ ^ , η ^ ) ≈ 1 n ∑ i = 1 n m ( W i ; θ 0 , η 0 ) + 1 n ∑ i = 1 n ∂ ∂ θ m ( W i ; θ 0 , η 0 ) ( θ ^ − θ 0 ) + 1 n ∑ i = 1 n ∂ ∂ η m ( W i ; θ 0 , η 0 ) ( η ^ − η 0 ) ≈ 0 \frac{1}{n}\sum_{i=1}^nm(W_i;\hat{\theta},\hat{\eta}) \approx \frac{1}{n}\sum_{i=1}^nm(W_i;\theta_0,\eta_0) + \frac{1}{n}\sum_{i=1}^n\frac{\partial}{\partial\theta}m(W_i;\theta_0,\eta_0)(\hat{\theta} - \theta_0) + \frac{1}{n}\sum_{i=1}^n\frac{\partial}{\partial\eta}m(W_i;\theta_0,\eta_0)(\hat{\eta} - \eta_0) \approx 0 n1i=1∑nm(Wi;θ^,η^)≈n1i=1∑nm(Wi;θ0,η0)+n1i=1∑n∂θ∂m(Wi;θ0,η0)(θ^−θ0)+n1i=1∑n∂η∂m(Wi;θ0,η0)(η^−η0)≈0
( θ 0 − θ ^ ) ≈ [ 1 n ∑ i = 1 n ∂ ∂ θ m ( W i ; θ 0 , η 0 ) ] − 1 1 n ∑ i = 1 n m ( W i ; θ 0 , η 0 ) + [ 1 n ∑ i = 1 n ∂ ∂ θ m ( W i ; θ 0 , η 0 ) ] − 1 ( η ^ − η 0 ) 1 n ∑ i = 1 n ∂ ∂ η m ( W i ; θ 0 , η 0 ) (\theta_0 - \hat{\theta})\approx [\frac{1}{n}\sum_{i=1}^n\frac{\partial}{\partial\theta}m(W_i;\theta_0,\eta_0)]^{-1}\frac{1}{n}\sum_{i=1}^nm(W_i;\theta_0,\eta_0) + [\frac{1}{n}\sum_{i=1}^n\frac{\partial}{\partial\theta}m(W_i;\theta_0,\eta_0)]^{-1}(\hat{\eta} - \eta_0)\frac{1}{n}\sum_{i=1}^n\frac{\partial}{\partial\eta}m(W_i;\theta_0,\eta_0) (θ0−θ^)≈[n1i=1∑n∂θ∂m(Wi;θ0,η0)]−1n1i=1∑nm(Wi;θ0,η0)+[n1i=1∑n∂θ∂m(Wi;θ0,η0)]−1(η^−η0)n1i=1∑n∂η∂m(Wi;θ0,η0)
目标参数的估计偏差 ( θ 0 − θ ^ ) (\theta_0 - \hat{\theta}) (θ0−θ^)将受到辅助参数估计偏差 ( η ^ − η 0 ) (\hat{\eta} - \eta_0) (η^−η0)的影响,说明目标参数的估计偏差的两种来源分别是:
- 辅助参数的估计偏差 ( η ^ − η 0 ) (\hat{\eta} - \eta_0) (η^−η0)本身,称之为正则化偏差
- 辅助参数的估计偏差 ( η ^ − η 0 ) (\hat{\eta} - \eta_0) (η^−η0)与 W i W_i Wi的强相关性,称之为过拟合偏差
Neyman Orthogonality
∂ ∂ λ { E [ ψ ( W i ; θ 0 , η 0 + λ ( η − η 0 ) ) ] } ∣ λ = 0 = 0 , ∀ η ∈ T \frac{\partial}{\partial\lambda}\{E[\psi(W_i;\theta_0,\eta_0 + \lambda(\eta-\eta_0))]\}|_{\lambda=0}= 0,\forall\eta\in \mathcal{T} ∂λ∂{E[ψ(Wi;θ0,η0+λ(η−η0))]}∣λ=0=0,∀η∈T
m I P W m_{IPW} mIPW is not Neyman orthogonal, m D R m_{DR} mDR is Neyman orthogonal.
Cross Fitting
θ ^ : 1 n ∑ k = 1 K ∑ i ∈ I k m ( W i ; θ ^ , η ^ − k ) = 0 \hat{\theta}:\frac{1}{n}\sum_{k=1}^K\sum_{i\in I_k}m(W_i;\hat{\theta},\hat{\eta}_{-k}) = 0 θ^:n1k=1∑Ki∈Ik∑m(Wi;θ^,η^−k)=0
DML
θ ^ : 1 n ∑ k = 1 K ∑ i ∈ I k ψ ( W i ; θ ^ , η ^ − k ) = 0 \hat{\theta}:\frac{1}{n}\sum_{k=1}^K\sum_{i\in I_k}\psi(W_i;\hat{\theta},\hat{\eta}_{-k}) = 0 θ^:n1k=1∑Ki∈Ik∑ψ(Wi;θ^,η^−k)=0
直接回归不满足 Neyman 正交性
Y = θ T + g ( X ) + ϵ Y = \theta T + g(X) + \epsilon Y=θT+g(X)+ϵ
m ( W ; θ , g ) = Y − θ T − g ( X ) + ϵ m(W;\theta,g) = Y - \theta T - g(X) + \epsilon m(W;θ,g)=Y−θT−g(X)+ϵ
∂ ∂ λ E [ m ( w ; θ , g + λ Δ g ) ] ∣ λ = 0 = E [ − Δ g ( x ) ] ≠ 0 \frac{\partial }{\partial \lambda}E[m(w;\theta,g + \lambda\Delta g)]|_{\lambda=0} = E[-\Delta g(x)] \ne 0 ∂λ∂E[m(w;θ,g+λΔg)]∣λ=0=E[−Δg(x)]=0
DML 满足Neyman正交性
Y − l ( x ) = θ ( T − m ( x ) ) + ϵ ′ , l ( x ) = E [ Y ∣ X = x ] , m ( x ) = E [ T ∣ X = x ] Y-l(x) = \theta (T - m(x)) + \epsilon',l(x) = E[Y|X=x],m(x)=E[T|X=x] Y−l(x)=θ(T−m(x))+ϵ′,l(x)=E[Y∣X=x],m(x)=E[T∣X=x]
m ( W ; θ , η ) = Y − l ( x ) − θ ( T − m ( x ) ) − ϵ ′ , η = ( l , m ) m(W;\theta,\eta) = Y-l(x) - \theta (T - m(x)) - \epsilon',\eta = (l, m) m(W;θ,η)=Y−l(x)−θ(T−m(x))−ϵ′,η=(l,m)
∂ ∂ λ E [ W ; θ , η + λ Δ η ] ∣ λ = 0 = E [ − Δ l ( x ) + θ Δ m ( x ) ] = 0 \frac{\partial}{\partial\lambda}E[W;\theta,\eta + \lambda\Delta\eta]|_{\lambda=0} = E[-\Delta l(x) + \theta\Delta m(x)] = 0 ∂λ∂E[W;θ,η+λΔη]∣λ=0=E[−Δl(x)+θΔm(x)]=0
Example
模拟数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
import dowhy.datasets, dowhy.plotter
rvar = 1 if np.random.uniform() > 0.2 else 0
is_linear = False # A non-linear dataset. Change to True to see results for a linear dataset.
data_dict = dowhy.datasets.xy_dataset(10000, effect=rvar,num_common_causes=2,is_linear=is_linear,sd_error=0.2)
df = data_dict['df']
print(df.head())
dowhy.plotter.plot_treatment_outcome(df[data_dict["treatment_name"]], df[data_dict["outcome_name"]],df[data_dict["time_val"]])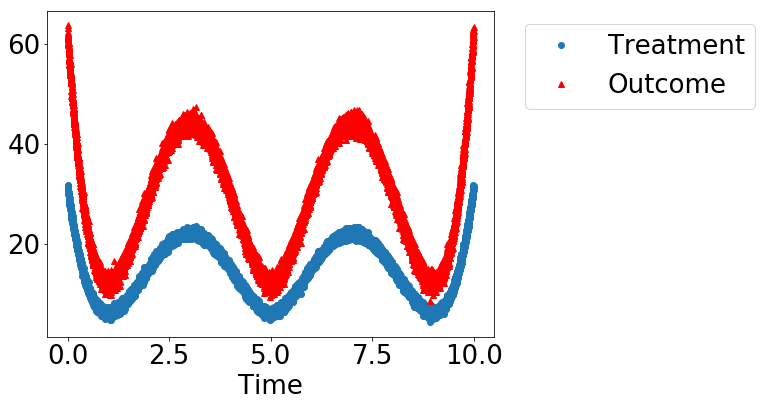
因果关系假设:
- 基于领域知识提出因果关系的假设,定义模型结构
from dowhy import CausalModel
model= CausalModel(data=df,treatment=data_dict["treatment_name"],outcome=data_dict["outcome_name"],common_causes=data_dict["common_causes_names"],instruments=data_dict["instrument_names"])
model.view_model(layout="dot")

因果关系识别:
identified_estimand = model.identify_effect(proceed_when_unidentifiable=True)
print(identified_estimand)
因果关系估计:
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LassoCV
from sklearn.ensemble import GradientBoostingRegressor
dml_estimate = model.estimate_effect(identified_estimand, method_name="backdoor.econml.dml.DML",control_value = 0,treatment_value = 1,confidence_intervals=False,method_params={"init_params":{'model_y':GradientBoostingRegressor(),'model_t': GradientBoostingRegressor(),"model_final":LassoCV(fit_intercept=False),'featurizer':PolynomialFeatures(degree=2, include_bias=True)},"fit_params":{}})
print(dml_estimate)
因果关系反驳测试:
res_placebo=model.refute_estimate(identified_estimand, dml_estimate,method_name="placebo_treatment_refuter", placebo_type="permute",num_simulations=20)
print(res_placebo)
相关文章:
Double/Debiased Machine Learning
独立同步分布的观测数据 { W i ( Y i , D i , X i ) ∣ i ∈ { 1 , . . . , n } } \{W_i(Y_i,D_i,X_i)| i\in \{1,...,n\}\} {Wi(Yi,Di,Xi)∣i∈{1,...,n}},其中 Y i Y_i Yi表示结果变量, D i D_i Di表示因变量, X i X_i Xi表…...

HarmonyOS Next 弹窗系列教程(4)
HarmonyOS Next 弹窗系列教程(4) 介绍 本章主要介绍和用户点击关联更加密切的菜单控制(Menu) 和 气泡提示(Popup) 它们出现显示弹窗出现的位置都是在用户点击屏幕的位置相关 菜单控制(Menu&…...
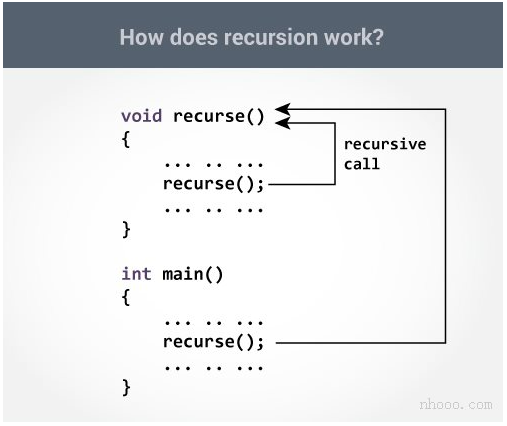
【C】-递归
1、递归概念 递归(Recursion)是编程中一种重要的解决问题的方法,其核心思想是函数通过调用自身来解决规模更小的子问题,直到达到最小的、可以直接解决的基准情形(Base Case)。 核心:自己调用…...
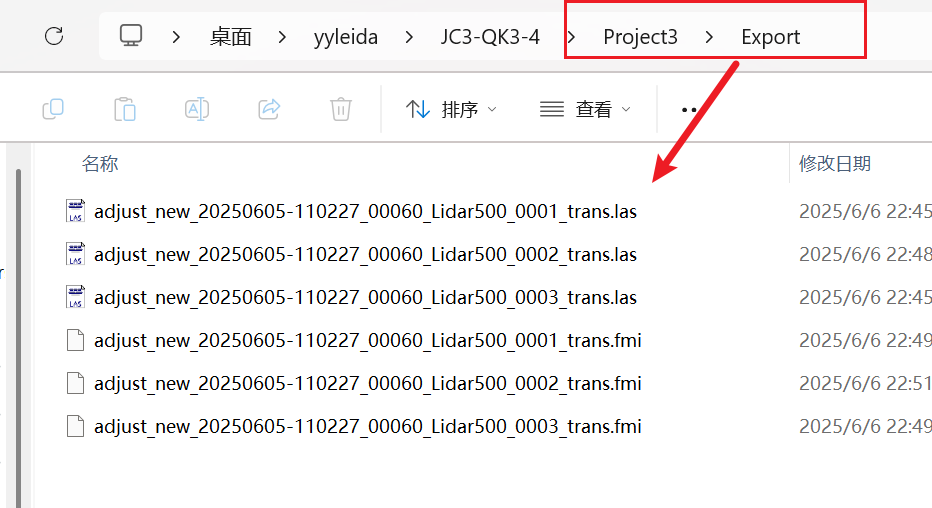
飞马LiDAR500雷达数据预处理
0 引言 在使用飞马D2000无人机搭载LiDAR500进行作业完成后,需要对数据进行预处理,方便给内业人员开展点云分类等工作。在开始操作前,先了解一下使用的软硬件及整体流程。 0.1 外业测量设备 无人机:飞马D2000S激光模块ÿ…...

Kerberos面试内容整理-在 Linux/Windows 中的 Kerberos 实践
Windows 实践: 在Windows环境中,Kerberos 几乎是无形融合的。用户使用域账号登录计算机时,实际上就完成了Kerberos的AS认证并获取TGT;此后的资源访问(如共享文件夹、打印机、数据库等)都会自动使用Kerberos进行验证,而无需用户干预。Windows通过LSASS进程维护和缓存用户…...
已创建的 **Module** 的操作指南)
在 Allegro PCB Editor 中取消(解除或删除)已创建的 **Module** 的操作指南
在 Allegro PCB Editor 中取消(解除或删除)已创建的 Module 有两种主要场景,操作也不同: 📌 场景一:仅想解除元件与 Module 的关联(保留元件位置和布线,但可独立编辑) …...

基于springboot的校园社团信息系统的设计与实现
其他源码获取可以看首页:代码老y 个人简介:专注于毕业设计项目定制开发:springbootvue系统,Java微信小程序,javaSSM系统等技术开发,并提供远程调试部署、代码讲解、文档指导、ppt制作等技术指导。源码获取&…...

nodejs里面的http模块介绍和使用
Node.js的http模块是构建在libuv库之上,以JavaScript接口形式暴露出来的核心模块之一,它允许开发者轻松地创建和管理HTTP服务器及客户端,进而实现网络应用的快速开发。此模块的设计理念围绕着事件驱动和非阻塞I/O模型,这些特性使N…...
mamba架构和transformer区别
Mamba 架构和 Transformer 架构存在多方面的区别,具体如下: 计算复杂度1 Transformer:自注意力机制的计算量会随着上下文长度的增加呈平方级增长,例如上下文增加 32 倍时,计算量可能增长 1000 倍,在处理长序…...

嵌入式鸿蒙开发环境搭建操作方法与实现
Linux环境搭建镜像下载链接: 链接:https://pan.baidu.com/s/1F2f8ED5V1KwLjyYzKVx2yQ 提取码:Leun vscode和Linux系统连接的详细过程1.下载Visual Studio Code...

在 Spring Boot 中使用 WebFilter:实现请求拦截、日志记录、跨域处理等通用逻辑!
💡 前言 在开发 Web 应用时,我们经常需要对所有请求进行统一处理,例如: 记录请求日志实现跨域(CORS)接口权限控制请求参数预处理防止 XSS 攻击 这些功能如果都写在每个 Controller 或 Service 里&#x…...
)
CSS预处理器:Sass与Less的语法和特性(含实际案例)
Sass(SCSS语法示例) 1. 变量:统一管理颜色 // 定义变量 $primary-color: #1a237e; $success-color: #4caf50; $font-size-base: 16px;// 实际应用 body {color: $primary-color;font-size: $font-size-base; }.button {background: $succes…...
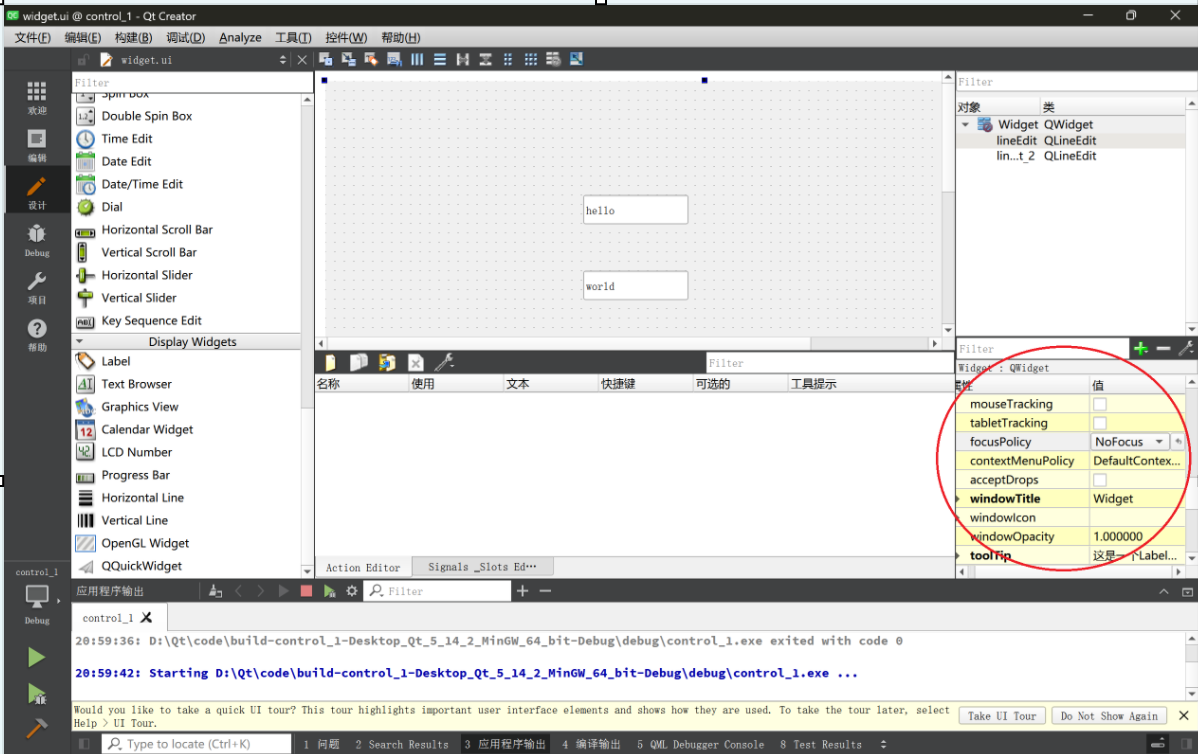
QT常用控件(1)
控件是构成QT的基础元素,例如Qwidget也是一个控件,提供了一个‘空’的矩形,我们可以往里面添加内容和处理用户输入,例如:按钮(QpushButton),基础显示控件(Lableÿ…...

明基编程显示器终于有优惠了,程序员快来,错过等一年!
最近618的活动已经陆续开始了,好多人说这是买数码产品的好时候,作为一名资深程序员,我做了不少功课,决定给自己升级办公设备,入手明基 RD 系列的显示器,这是市面上首家专注于我们程序员痛点和需求的产品&am…...
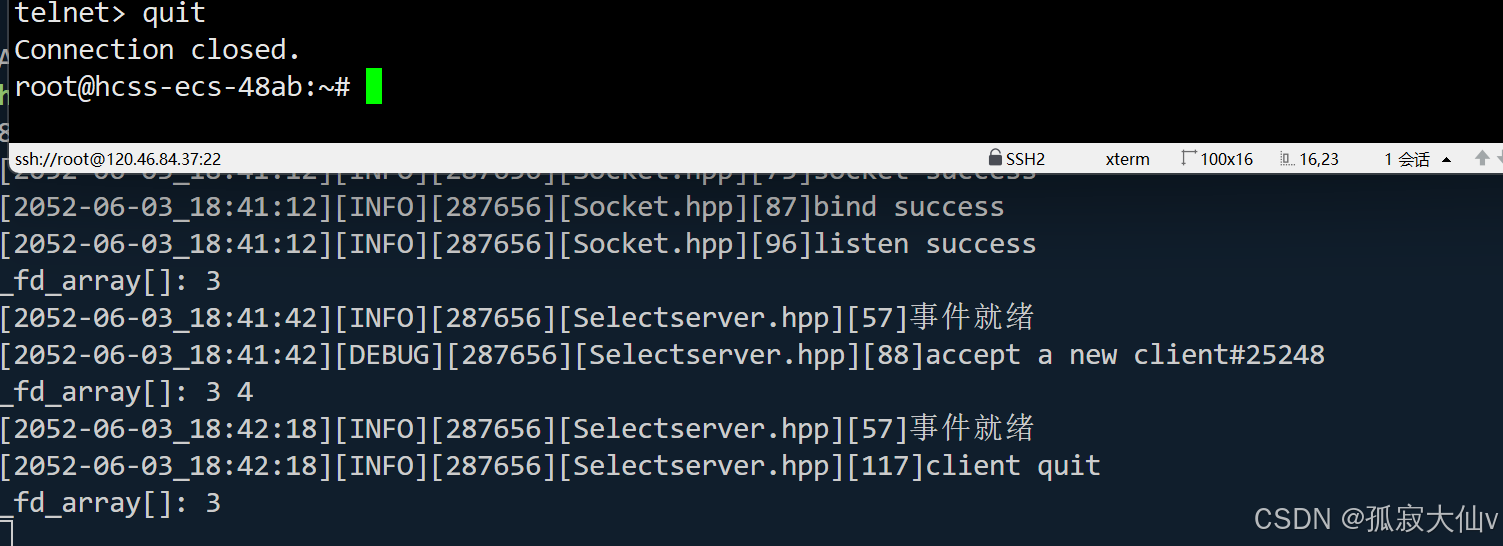
【计算机网络】非阻塞IO——select实现多路转接
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:计算机网络 🌹往期回顾🌹:【计算机网络】NAT、代理服务器、内网穿透、内网打洞、局域网中交换机 🔖流水不争࿰…...
 的完整设计方案)
Figma 中构建 Master Control Panel (MCP) 的完整设计方案
以下是在 Figma 中构建 Master Control Panel (MCP) 的完整设计方案,专为设计系统管理而优化: 一、MCP 核心功能架构 #mermaid-svg-iZAnYxyYU4BtpeaE {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#merma…...

什么是权威解析服务器?权威解析服务器哪些作用?
域名系统(DNS)是互联网的核心基础设施之一,它将易于记忆的域名转换为计算机能够识别的IP地址。DNS服务器在这一过程中扮演着至关重要的角色,它们可以分为以下几种类型: 根DNS服务器 根DNS服务器位于DNS层级结构的最顶端…...

LeetCode--23.合并k个升序链表
解题思路: 1.获取信息: 给出了多个升序链表,要求合并成一个升序链表,返回首元结点 2.分析题目: 外面在21题的时候,讲了怎样合并两个升序链表为一个升序链表,不了解的,建议去看一下21…...

ComfyUI 工作流
目录 🧠 ComfyUI 是什么? ComfyUI 的特点 🔧 ComfyUI 工作流程(节点图) 📌 简单理解 如何安装? 🧠 ComfyUI 是什么? ComfyUI 是一个 Stable Diffusion 的图形化用户界面(GUI),专门用来生成图像。它通过 节点图(Node Graph)形式来让用户定义图像生成的每…...

使用glide 同步获取图片
在 Glide 中,可以使用asBitmap()方法来获取图片的Bitmap对象,进而同步地加载图片。以下是具体示例: String imageUrl "https://example.com/image.jpg"; Bitmap bitmap Glide.with(context).asBitmap().load(imageUrl).apply(ne…...
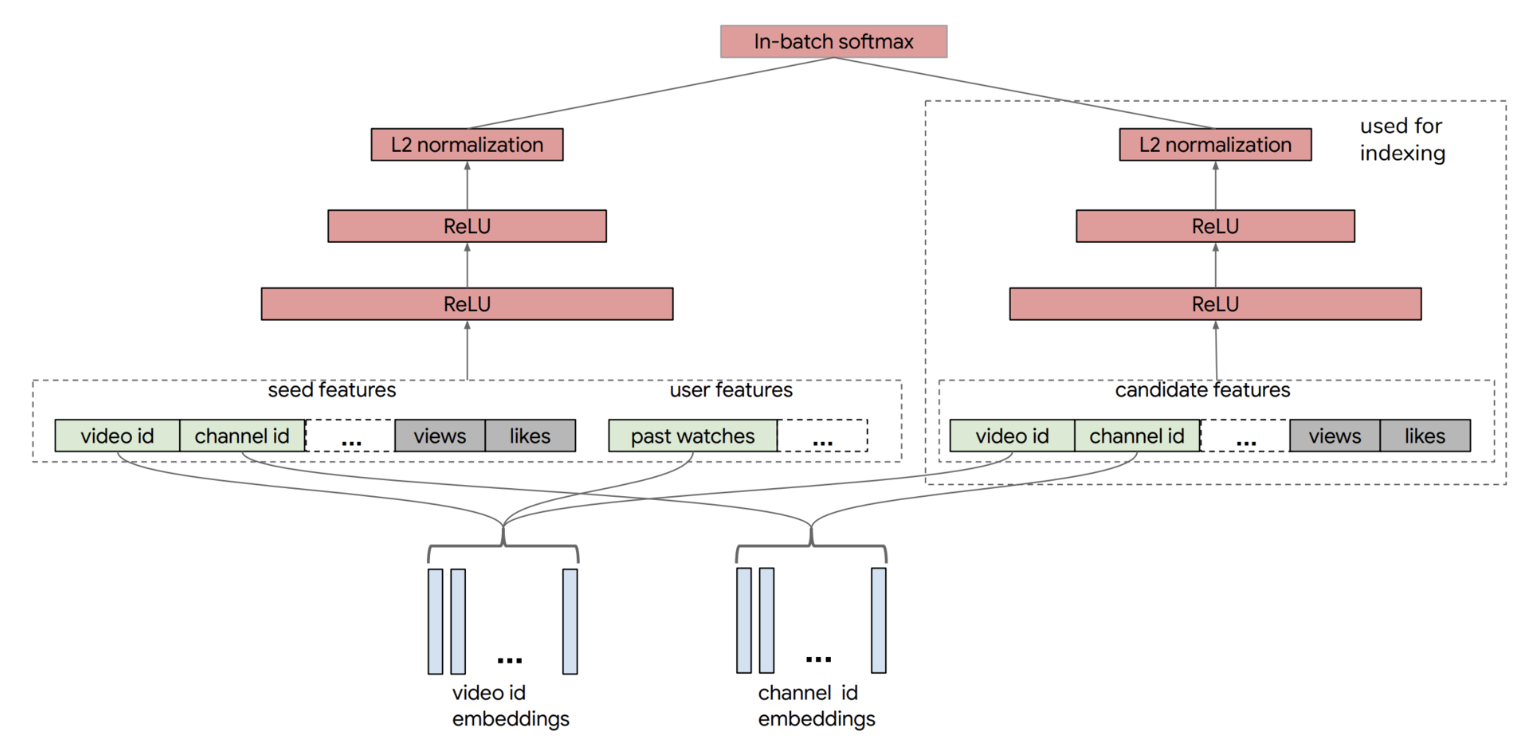
【推荐算法】NeuralCF:深度学习重构协同过滤的革命性突破
NeuralCF:深度学习重构协同过滤的革命性突破 一、算法背景知识:协同过滤的演进与局限1.1 协同过滤的发展历程1.2 传统矩阵分解的缺陷 二、算法理论/结构:NeuralCF架构设计2.1 基础NeuralCF结构2.2 双塔模型进阶结构2.3 模型实现流程对比 三、…...

负载均衡相关基本概念
负载均衡在系统架构设计中至关重要,其核心目标是合理分配负载,提升系统整体性能和可靠性。本文简要介绍了负载均衡的基本概念,包括四层和七层负载均衡、负载均衡的使用场景和实现方式、负载均衡的常用算法以及一些配置相关知识。 1、负载均衡…...

服务器中日志分析的作用都有哪些
服务器日志是用来检测和排查可疑行为的主要工具,运维团队可以通过分析和解读日志文件,发现服务器中潜在的网络安全威胁或异常活动,下面,就让小编和大家一起来了解一下服务器中日志分析的作用都有什么吧! 对于服务器中的…...

【React】useId
在 React 中,useId 是 React 18 引入的一个 Hook,用于生成一个在组件生命周期中保持稳定的唯一 ID。它主要用于: 无障碍(accessibility)场景,比如表单控件需要一个 id 和 label 的 htmlFor 属性配对。服务…...

【51单片机】0. 基础软件安装
最近心血来潮对单片机感兴趣,想着以后工作不景气了就跳槽,兴趣使然为以后做打算吧,开始跟着江科大学习单片机 1. 需要安装的软件说明 使用到的软件包括: Keli:写嵌入式代码的 stc-isp:烧录&下载代码…...
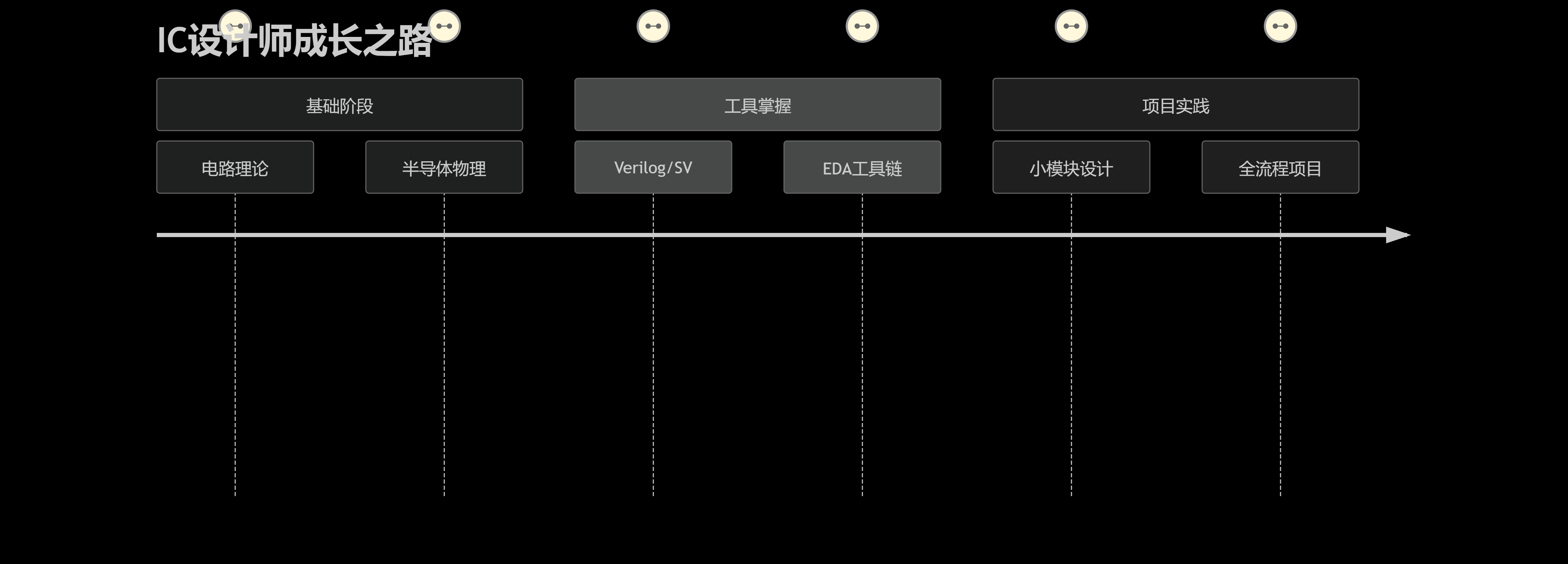
集成电路设计:从概念到实现的完整解析优雅草卓伊凡
集成电路设计:从概念到实现的完整解析优雅草卓伊凡 一、集成电路设计:芯片制造的”灵魂蓝图” 1.1 什么是集成电路设计? 集成电路(IC)设计是指通过电子设计自动化(EDA)工具,将数百…...

动态规划之网格图模型(二)
文章目录 动态规划之网格图模型(二)LeetCode 931. 下降路径最小和思路Golang 代码 LeetCode 2684. 矩阵中移动的最大次数思路Golang 代码 LeetCode 2304. 网格中的最小路径代价思路Golang 代码 LeetCode 1289. 下降路径最小和 II思路Golang 代码 LeetCod…...

uniapp 集成腾讯云 IM 消息搜索功能
UniApp 集成腾讯云 IM 消息搜索功能实战指南 一、功能实现原理 腾讯云 IM 通过 消息漫游 服务端搜索接口 实现消息检索,核心机制如下: 数据存储:消息默认存储7天(可扩展至30天)索引构建:基于消息内容自…...
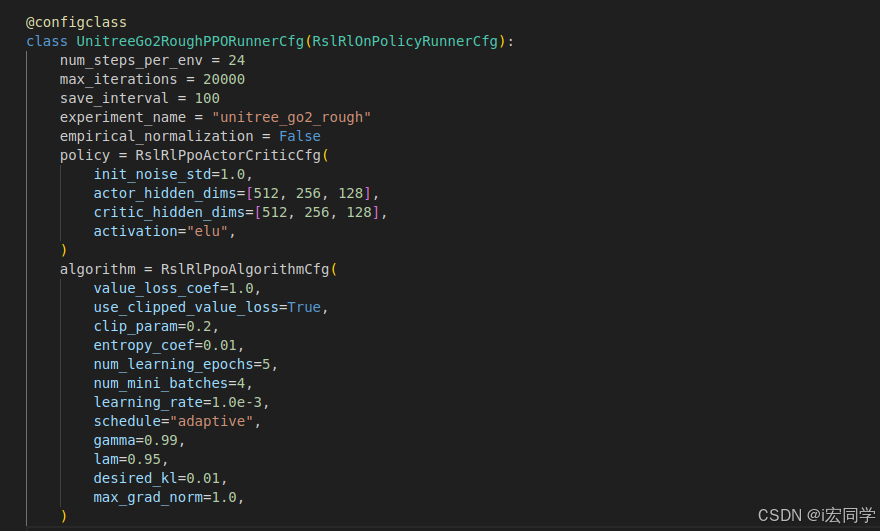
robot_lab——rsl_rl的train.py整体逻辑
文章目录 Go2机器人训练流程详细分析概述1. 训练启动流程1.1 命令行参数解析RSL-RL相关参数组Isaac Sim应用启动参数组 1.2 RL配置1.3 Isaac Sim启动 2. 环境配置加载2.1 Hydra配置系统 3. 环境创建与初始化3.1 Gym环境创建3.2 Manager系统初始化3.2.1 ObservationManager3.2.2…...

AI推荐系统演进史:从协同过滤到图神经网络与强化学习的融合
每一次滑动手机屏幕,电商平台向你推荐心仪商品的背后,是超过百亿量级的浮点运算。从早期的“猜你喜欢”到如今的“比你更懂你”,商品推荐引擎已悄然完成从简单规则到深度智能的技术跃迁。 一、协同过滤:推荐系统的基石与演进 协同…...