Elasticsearch 海量数据写入与高效文本检索实践指南
Elasticsearch 海量数据写入与高效文本检索实践指南
一、引言
在大数据时代,企业和组织面临着海量数据的存储与检索需求。Elasticsearch(以下简称 ES)作为一款基于 Lucene 的分布式搜索和分析引擎,凭借其高可扩展性、实时搜索和分析能力,成为处理海量数据写入与文本检索的热门选择。本文将深入探讨如何在 ES 中实现海量数据的高效写入,并利用其强大的功能进行精准的文本检索,帮助开发者和技术人员更好地应用 ES 解决实际问题。
二、Elasticsearch 基础概念回顾
2.1 核心组件
ES 是一个分布式系统,其核心组件包括节点、集群、索引、类型(在 ES 7.0 后逐渐弃用)、文档。一个或多个节点组成一个集群,索引是文档的集合,类似于关系型数据库中的数据库,而文档则是最小的数据单元,可理解为关系型数据库中的一行记录。
2.2 数据存储与检索原理
ES 基于倒排索引实现高效的文本检索。倒排索引将文档中的每个词与包含该词的文档列表建立关联,当进行文本检索时,通过查找词对应的文档列表,快速定位到相关文档。这种结构使得 ES 在处理大规模文本数据检索时具有极高的性能。
三、海量数据写入 Elasticsearch
3.1 批量写入(Bulk API)
批量写入是实现海量数据高效写入 ES 的关键方法。通过 Bulk API,可以在一个请求中执行多个创建、索引、更新或删除操作。与单个文档写入相比,批量写入减少了网络开销和请求次数,极大地提高了写入效率。以下是一个使用 Python 的 elasticsearch 库进行批量写入的示例:
from elasticsearch import Elasticsearch
import jsones = Elasticsearch()# 准备批量操作数据
bulk_data = []
for i in range(1000):data = {"title": f"Document {i}","content": f"Content of document {i}"}index_action = {"index": {"_index": "my_index","_id": i}}bulk_data.append(json.dumps(index_action))bulk_data.append(json.dumps(data))# 执行批量写入
bulk_request = "\n".join(bulk_data) + "\n"
es.bulk(body=bulk_request)3.2 优化写入性能
- 调整分片和副本数量:在创建索引时,合理设置分片和副本数量。减少副本数量(例如在数据写入阶段先设置为 0,写入完成后再调整)可以提高写入性能,因为副本的同步会消耗资源。分片数量应根据数据量和集群规模进行规划,一般建议每个分片大小控制在 30 - 50GB 左右。
- 优化索引映射(Mapping):根据数据结构定义合适的字段类型,避免使用过于复杂的类型。例如,对于不需要进行全文检索的字段,可设置为 keyword 类型,减少索引构建的开销。
- 调整刷新(Refresh)和 Flush 策略:默认情况下,ES 每 1 秒刷新一次数据,使其可被搜索。在海量数据写入时,可以适当延长刷新间隔,减少频繁刷新带来的性能损耗。同时,合理设置 Flush 操作的触发条件,避免频繁的磁盘 I/O。
3.3 数据预处理与缓存
在将数据写入 ES 之前,进行必要的预处理,如数据清洗、格式转换等,可以减少 ES 的处理压力。此外,引入缓存机制,例如使用 Redis 缓存部分热点数据,避免对 ES 的频繁查询,提高整体系统性能。
四、Elasticsearch 文本检索实践
4.1 基本查询语句
ES 提供了丰富的查询 DSL(Domain-Specific Language),可以实现各种复杂的文本检索需求。以下是一些常见的查询示例:
- Match 查询:用于全文检索,根据字段的分词结果进行匹配。
{"query": {"match": {"content": "example"}}
}- Term 查询:直接匹配精确的词条,不进行分词处理。
{"query": {"term": {"title.keyword": "Document 1"}}
}- Bool 查询:组合多个查询条件,包括 must(必须满足)、must_not(必须不满足)、should(应该满足)等。
{"query": {"bool": {"must": [{"match": {"content": "keyword1"}}],"must_not": [{"match": {"content": "keyword2"}}],"should": [{"match": {"content": "keyword3"}}]}}
}4.2 复杂检索与聚合分析
除了基本查询,ES 还支持复杂的检索和聚合分析功能。例如,使用嵌套查询(Nested Query)处理嵌套文档结构,使用聚合(Aggregation)进行数据统计和分析。以下是一个聚合分析的示例,统计每个标题出现的次数:
{"size": 0,"aggs": {"title_count": {"terms": {"field": "title.keyword"}}}
}4.3 检索性能优化
- 使用合适的分词器:根据文本内容的语言和特点,选择合适的分词器。例如,对于中文文本,IK 分词器是一个常用的选择,它能够提供更精准的分词结果,提高检索准确性。
- 索引优化:定期对索引进行优化操作,如合并分片、删除不再使用的索引,以减少索引文件大小,提高检索性能。
- 缓存与预热:利用 ES 的查询缓存功能,对频繁执行的查询结果进行缓存。同时,在系统启动时对热点数据进行预热,将数据加载到内存中,减少首次查询的响应时间。
五、实际应用案例
5.1 日志分析系统
在日志分析场景中,每天会产生海量的日志数据。通过将日志数据写入 ES,利用其强大的检索和分析功能,可以快速定位错误日志、分析系统性能瓶颈。例如,通过 Match 查询检索包含特定错误信息的日志,使用聚合分析统计不同时间段的日志数量和类型分布。
5.2 文档检索平台
构建一个文档检索平台,将企业内部的各种文档(如合同、报告、技术文档等)存储到 ES 中。用户可以通过关键词搜索快速找到相关文档,借助 Bool 查询和嵌套查询实现复杂的检索条件,如根据文档类型、创建时间、作者等多个条件进行筛选。
六、总结与展望
本文详细介绍了 Elasticsearch 在海量数据写入和文本检索方面的实践方法与优化策略。通过合理运用批量写入、优化索引设置和查询语句,能够有效提高 ES 在处理大数据时的性能和效率。随着数据量的不断增长和应用场景的日益复杂,未来 ES 在分布式存储、检索性能优化和功能扩展等方面仍有很大的发展空间。开发者可以持续关注 ES 的更新动态,不断探索其新特性和应用场景,为企业和用户提供更优质的搜索和分析服务。
以上全面覆盖了 ES 海量数据写入和文本检索的要点。你若对某部分内容想深入了解,或有特定优化需求,欢迎随时告知。
相关文章:

Elasticsearch 海量数据写入与高效文本检索实践指南
Elasticsearch 海量数据写入与高效文本检索实践指南 一、引言 在大数据时代,企业和组织面临着海量数据的存储与检索需求。Elasticsearch(以下简称 ES)作为一款基于 Lucene 的分布式搜索和分析引擎,凭借其高可扩展性、实时搜索和…...
jenkins集成gitlab发布到远程服务器
jenkins集成gitlab发布到远程服务器 前面我们讲了通过创建maven项目部署在jenkins本地服务器,这次实验我们将部署在远程服务器,再以nginx作为前端项目做一个小小的举例 1、部署nginx服务 [rootweb ~]# docker pull nginx [rootweb ~]# docker images …...

AI问答-vue3+ts+vite:http://www.abc.com:3022/m-abc-pc/#/snow 这样的项目 在服务器怎么部署
为什么记录有子路径项目的部署,因为,通过子路径可以区分项目,那么也就可以实现微前端架构,并且具有独特优势,每个项目都是绝对隔离的。 要将 Vue3 项目(如路径为 http://www.abc.com:3022/m-saas-pc/#/sno…...
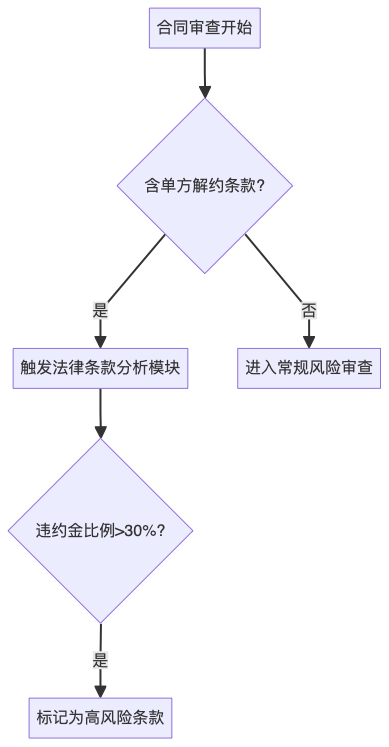
当主观认知遇上机器逻辑:减少大模型工程化中的“主观性”模糊
一、人类与机器的认知差异 当自动驾驶汽车遇到紧急情况需要做出选择时,人类的决策往往充满矛盾:有人会优先保护儿童和老人,有人坚持"不主动变道"的操作原则。这种差异背后,体现着人类特有的情感判断与价值选择。而机器的…...

会计 - 金融负债和权益工具
一、金融负债和权益工具区分的基本原则 (1)是否存在无条件地避免交付现金或其他金融资产的合同义务 如果企业不能无条件地避免以交付现金或其他金融资产来履行一项合同义务,则该合同义务符合金融负债的义务。 常见的该类合同义务情形包括:- 不能无条件避免的赎回; -强制…...

.net Span类型和Memory类型
.NET 中 Span 类型和 Memory 类型的深度剖析 在 .NET 编程的世界里,高效处理内存是提升程序性能的关键。Span<T> 和 Memory<T> 类型的出现,为开发者提供了强大而灵活的工具,用于高效地访问和操作连续内存区域。今天,…...

Dify工具插件开发和智能体开发全流程
想象一下,你正在开发一个 AI 聊天机器人,想让它能实时搜索 Google、生成图像,甚至自动规划任务,但手动集成这些功能耗时又复杂。Dify 来了!这个开源的 AI 应用平台让你轻松开发工具插件和智能体策略插件,快…...

ES6——对象扩展之Set对象
在ES6(ECMAScript 2015)中,Set 对象允许存储任何类型的唯一值,无论是原始值还是对象引用。Set 对象有一些有用的方法,可以操作集合中的数据。以下是一些常用的 Set 对象方法: 方法描述 add 向 Set 对象添加…...
AI书签管理工具开发全记录(十三):TUI基本框架搭建
文章目录 AI书签管理工具开发全记录(十三):TUI基本框架搭建前言 📝1.TUI介绍 🔍2. 框架选择 ⚙️3. 功能梳理 🎯4. 基础框架搭建⚙️4.1 安装4.2 参数设计4.3 绘制ui4.3.1 设计结构体4.3.2 创建头部4.3.3 创…...

<2>-MySQL库的操作
目录 一,创建数据库 二,查看字符集和校验规则 三,修改数据库 四,删除数据库 五,备份和恢复数据库 六,查看连接 一,创建数据库 创建一个名为bin_db的数据库,并设置字符集为utf8…...

Apache DolphinScheduler 和 Apache Airflow 对比
Apache DolphinScheduler 和 Apache Airflow 都是开源的工作流调度平台,用于管理和编排复杂的数据处理任务和管道。以下是对两者在功能、架构、使用场景等方面的对比,用中文清晰说明: 1. 概述 Apache DolphinScheduler: 一个分布…...
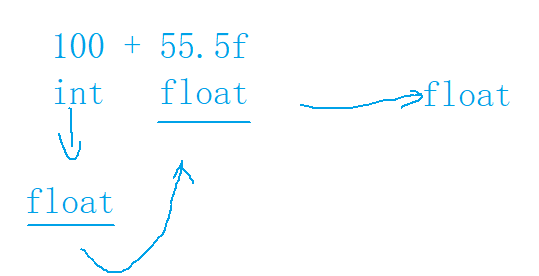
初识结构体,整型提升及操作符的属性
目录 一、结构体成员访问操作符1.1 结构体二、操作符的属性:优先级、结合性2.1 优先级2.2 结合性C 运算符优先级 三、表达式求值3.1 整型提升3.2 算数转化 总结 一、结构体成员访问操作符 1.1 结构体 C语言已经提供了内置类型,如:char,shor…...
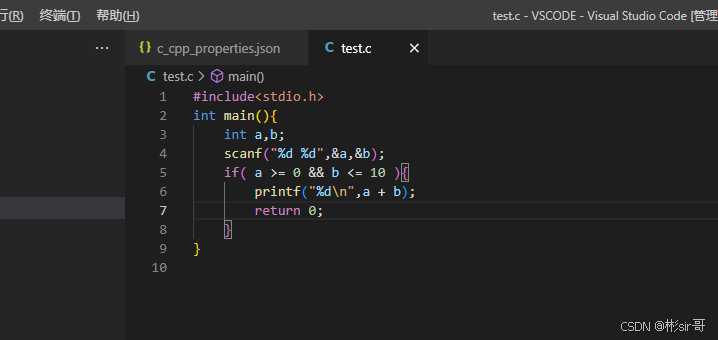
检测到 #include 错误。请更新 includePath。已为此翻译单元(D:\软件\vscode\test.c)禁用波形曲线
原文链接:【VScodeMinGw】安装配置教程 下载mingw64 打开可以看到bin文件夹下是多个.exe文件,gcc.exe地址在环境配置中要用到 原文链接:VSCode中出现“#include错误,请更新includePath“问题,解决方法 重新VScode后…...
)
python --导出数据库表结构(pymysql)
import pymysql from pymysql.cursors import DictCursor from typing import Optional, Dict, List, Anyclass DBSchemaExporter:"""MySQL数据库表结构导出工具,支持提取表和字段注释使用示例:>>> exporter DBSchemaExporter("local…...

如何自动部署GitLab项目
如何自动部署 原理 GitLab有预制的钩子, 在代码提交/合并等事件中,会自动调用WebHoos, 即向该URL发送POST请求在布署服务器上监听该POST, 验证通过后执行相关的布置Shell脚本, 即可完成自动布署 配置环境 安装Python和Pip 2.如果需要, 安装python的requests模块和argparse模…...

在 Windows 系统上运行 Docker 容器中的 Ubuntu 镜像并显示 GUI
在 Windows 上安装一个 X Server(如 VcXsrv 或 X410),Ubuntu 容器通过网络将图形界面转发到 Windows。 步骤: 安装 X Server: 推荐使用VcXsrv,免费开源。 安装后运行 XLaunch,选择࿱…...
 的总结)
基于 COM 的 XML 解析技术(MSXML) 的总结
✅ 一、COM 与 MSXML 简要说明 🔷 什么是 COM? COM(Component Object Model)是一种 Windows 平台下的组件技术,可以实现在不重新编译代码的前提下复用组件。 特点: 用 接口调用方式 解耦依赖;…...

多分辨率 LCD 的 GUI 架构设计与实现
1.1多分辨率显示系统的挑战与解决方案 1.1.1 分辨率适配的核心问题 在嵌入式系统中,同时支持不同分辨率的 LCD(如 240160、320480 等)面临以下挑战: 布局适配:同一界面元素在不同分辨率下需要调整大小和位置 字体显示:小分辨率屏幕需要更小的字体,而大分辨率需要更清…...
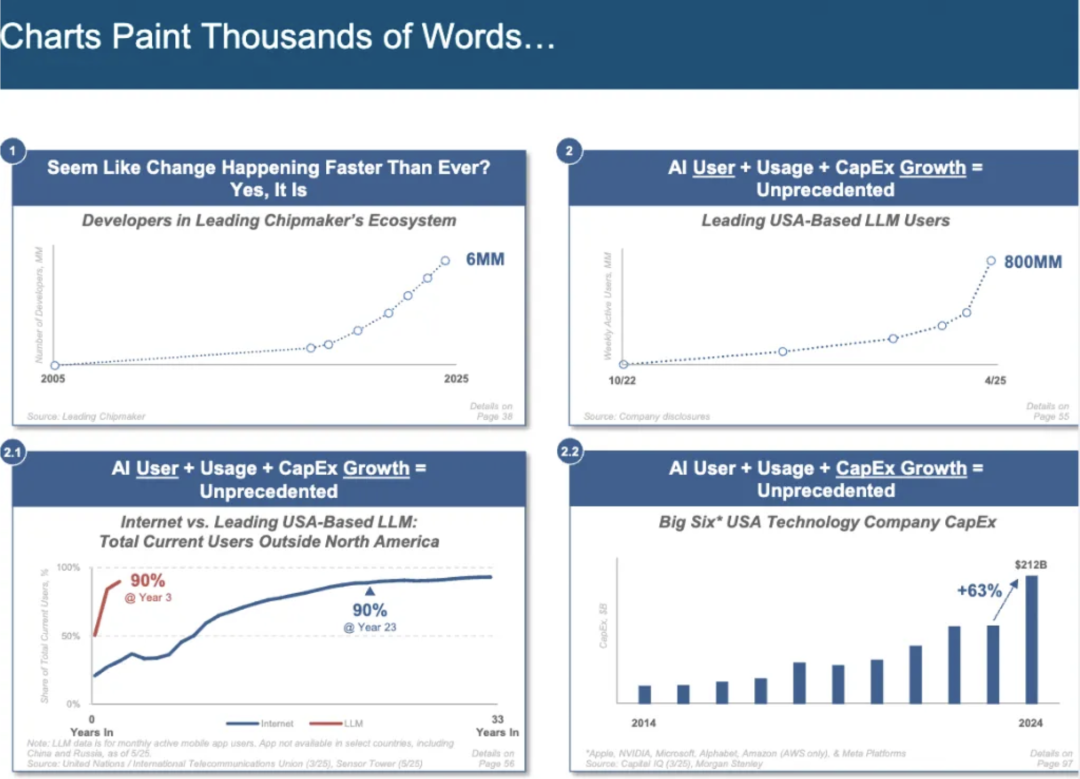
2025年,百度智能云打响AI落地升维战
如果说从AI到Agent是对于产品落地形态的共识,那么如今百度智能云打响的恰是一个基于Agent进行TO B行业表达的AI生产力升维战。 在这个新的工程体系能力里,除了之前百度Create大会上提出的面向Agent的RAG能力等通用能力模块,对更为专业、个性…...

Seed1.5-VL登顶,国产闭源模型弯道超车丨多模态模型5月最新榜单揭晓
随着图像、文本、语音、视频等多模态信息融合能力的持续增强,多模态大模型在感知理解、逻辑推理和内容生成等任务中的综合表现不断提升,正在展现出愈发接近人类的智能水平。多模态能力也正在从底层的感知理解,迈向具备认知、推理、决策能力的…...
和JSON.parse()之间的转换)
SON.stringify()和JSON.parse()之间的转换
1.JSON.stringify() 作用:将对象、数组转换成字符串 const obj {code: "500",message: "出错了", }; const jsonString JSON.stringify(obj); console.log(jsonString);//"{"code":"Mark Lee","message"…...

【学习笔记】构造函数+重载相关
【学习笔记】构造函数重载相关 一、构造函数 构造函数在创建对象的过程就会执行,带参数与不带参数,带参数的构造函数会默认将成员变量赋值传进去的参数。 class Layer { private:int layer_id; // 层IDstd::string layer_json; // 层的JSON配置…...

JVM——打开JVM后门的钥匙:反射机制
引入 在Java的世界里,反射机制(Reflection)就像一把万能钥匙,能够打开JVM的“后门”,让开发者在运行时突破静态类型的限制,动态操控类的内部结构。想象一下,传统的Java程序如同按菜单点菜的食客…...
第3章——SSM整合
一、整合持久层框架MyBatis 1.准备数据库表及数据 创建数据库:springboot 使用IDEA工具自带的mysql插件来完成表的创建和数据的准备: 创建表 表创建成功后,为表准备数据,如下: 2.创建SpringBoot项目 使用脚手架创建…...
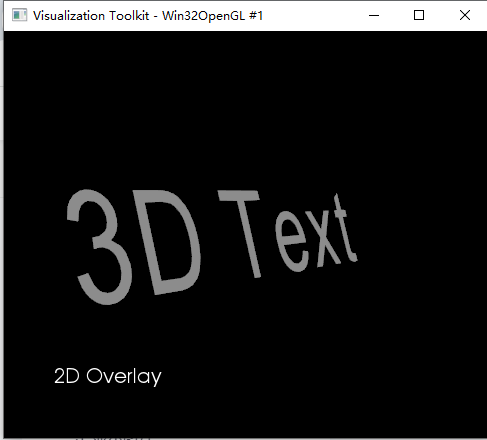
VTK 显示文字、图片及2D/3D图
1. 基本环境设置 首先确保你已经安装了VTK库,并配置好了C开发环境。 #include <vtkSmartPointer.h> #include <vtkRenderWindow.h> #include <vtkRenderWindowInteractor.h> #include <vtkRenderer.h> 2. 显示文字 2D文字 #include &l…...

小白如何在cursor中使用mcp服务——以使用notion的api为例
1. 首先安装node.js,在这一步的时候不要勾选不要勾选 2. 安装完之后,前往notion页面 我的创作者个人资料 | Notion 前往集成页面,添加新集成,自己输入名字,选择内部 新建完之后,进入选择只读 复制密匙 然后前往cursor页面 新建…...

引领AI安全新时代 Accelerate 2025北亚巡展·北京站成功举办
6月5日,网络安全行业年度盛会——"Accelerate 2025北亚巡展北京站"圆满落幕!来自智库、产业界、Fortinet管理层及技术团队的权威专家,与来自各行业的企业客户代表齐聚一堂,围绕"AI智御全球引领安全新时代"主题…...

为什么说数列是特殊的函数
文章目录 前情概要函数特性特殊之处典例剖析前情概要 高三的学生几乎都听老师说过,数列是特殊的函数,那么如何理解这句话呢,无外乎需要关注两点:①函数性,②特殊性,以下举例说明,帮助各位学子理解。 函数特性 既然是按照一定的次序排列而成的一列数字,那么这些数字(…...

解决uniapp开发app map组件最高层级 遮挡自定义解决底部tabbar方法
subNvue,是 vue 页面的原生子窗体,把weex渲染的原生界面当做 vue 页面的子窗体覆盖在页面上。它不是全屏页面,它给App平台vue页面中的层级覆盖和原生界面自定义提供了更强大和灵活的解决方案。它也不是组件,就是一个原生子窗体。 …...

96. 2017年蓝桥杯省赛 - Excel地址(困难)- 进制转换
96. Excel地址(进制转换) 1. 2017年蓝桥杯省赛 - Excel地址(困难) 标签:2017 省赛 1.1 题目描述 Excel 单元格的地址表示很有趣,它使用字母来表示列号。 比如, A 表示第 1 列,…...