Flink 高可用集群部署指南
一、部署架构设计
1. 集群架构
graph TDClient([客户端]) --> JM1[JobManager 1]Client --> JM2[JobManager 2]Client --> JM3[JobManager 3]subgraph ZooKeeper集群ZK1[ZooKeeper 1]ZK2[ZooKeeper 2]ZK3[ZooKeeper 3]endsubgraph TaskManager集群TM1[TaskManager 1]TM2[TaskManager 2]TM3[TaskManager 3]endJM1 --> ZK1JM2 --> ZK2JM3 --> ZK3JM1 --> TM1JM1 --> TM2JM1 --> TM32. 节点规划
| 节点 | 主机名 | IP 地址 | 角色分配 | 硬件配置 |
|---|---|---|---|---|
| 节点1 | flink-jm1 | 10.0.0.101 | JobManager + ZooKeeper | 8核16GB |
| 节点2 | flink-jm2 | 10.0.0.102 | JobManager + ZooKeeper | 8核16GB |
| 节点3 | flink-jm3 | 10.0.0.103 | JobManager + ZooKeeper | 8核16GB |
| 节点4 | flink-tm1 | 10.0.0.104 | TaskManager | 16核32GB |
| 节点5 | flink-tm2 | 10.0.0.105 | TaskManager | 16核32GB |
| 节点6 | flink-tm3 | 10.0.0.106 | TaskManager | 16核32GB |
二、环境准备
1. 系统要求
- 操作系统: CentOS 7.9 或 Ubuntu 20.04 LTS
- Java版本: OpenJDK 11 (建议使用 Azul Zulu 11)
- 防火墙: 开放以下端口
- JobManager: 6123, 6124, 8081, 8082
- TaskManager: 6121, 6122, 6125
- ZooKeeper: 2181, 2888, 3888
2. 基础配置(所有节点)
# 创建专用用户
sudo useradd -m -s /bin/bash flink
sudo passwd flink# 配置主机名解析(所有节点)
sudo tee -a /etc/hosts <<EOF
10.0.0.101 flink-jm1
10.0.0.102 flink-jm2
10.0.0.103 flink-jm3
10.0.0.104 flink-tm1
10.0.0.105 flink-tm2
10.0.0.106 flink-tm3
EOF# 配置SSH免密登录(JobManager节点间)
sudo -u flink ssh-keygen -t rsa -P ''
sudo -u flink ssh-copy-id flink@flink-jm1
sudo -u flink ssh-copy-id flink@flink-jm2
sudo -u flink ssh-copy-id flink@flink-jm3# 安装Java
sudo apt install -y openjdk-11-jdk
echo 'export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64' | sudo tee /etc/profile.d/java.sh
source /etc/profile三、ZooKeeper集群部署
1. 安装配置(所有ZK节点执行)
# 下载解压
cd /opt
sudo wget https://downloads.apache.org/zookeeper/zookeeper-3.8.1/apache-zookeeper-3.8.1-bin.tar.gz
sudo tar -xzf apache-zookeeper-3.8.1-bin.tar.gz
sudo mv apache-zookeeper-3.8.1-bin zookeeper
sudo chown -R flink:flink /opt/zookeeper# 创建数据目录
sudo mkdir /data/zookeeper
sudo chown flink:flink /data/zookeeper# 配置zoo.cfg
sudo -u flink tee /opt/zookeeper/conf/zoo.cfg <<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
maxClientCnxns=100
admin.enableServer=false
server.1=flink-jm1:2888:3888
server.2=flink-jm2:2888:3888
server.3=flink-jm3:2888:3888
EOF# 创建myid文件(每个节点不同)
# flink-jm1:
echo "1" | sudo -u flink tee /data/zookeeper/myid
# flink-jm2:
echo "2" | sudo -u flink tee /data/zookeeper/myid
# flink-jm3:
echo "3" | sudo -u flink tee /data/zookeeper/myid2. 启动与验证
# 所有ZK节点启动服务
sudo -u flink /opt/zookeeper/bin/zkServer.sh start# 检查集群状态
sudo -u flink /opt/zookeeper/bin/zkCli.sh -server flink-jm1:2181
[zk: flink-jm1:2181(CONNECTED) 0] srvr四、Flink集群部署
1. 安装Flink(所有节点)
cd /opt
sudo wget https://dlcdn.apache.org/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
sudo tar -xzf flink-1.17.1-bin-scala_2.12.tgz
sudo mv flink-1.17.1 flink
sudo chown -R flink:flink /opt/flink# 设置环境变量
echo 'export FLINK_HOME=/opt/flink' | sudo tee /etc/profile.d/flink.sh
echo 'export PATH=$PATH:$FLINK_HOME/bin' | sudo tee /etc/profile.d/flink.sh
source /etc/profile2. 高可用配置(JobManager节点)
flink-conf.yaml 关键配置:
# flink-jm1、flink-jm2、flink-jm3节点配置
# /opt/flink/conf/flink-conf.yaml# 高可用配置
high-availability: zookeeper
high-availability.storageDir: hdfs:///flink/ha
high-availability.zookeeper.quorum: flink-jm1:2181,flink-jm2:2181,flink-jm3:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /flink-cluster# 状态后端配置(需HDFS支持)
state.backend: rocksdb
state.checkpoints.dir: hdfs:///flink/checkpoints
state.savepoints.dir: hdfs:///flink/savepoints
state.backend.rocksdb.checkpoint.transfer.thread.num: 4
state.backend.rocksdb.localdir: /data/rocksdb# JobManager配置
jobmanager.rpc.address: flink-jm1
jobmanager.rpc.port: 6123
jobmanager.memory.process.size: 4096m
jobmanager.scheduler: adaptive# TaskManager配置
taskmanager.memory.process.size: 24576m # 24GB
taskmanager.memory.managed.size: 8192m # 8GB 堆外内存
taskmanager.numberOfTaskSlots: 8
taskmanager.memory.network.min: 512m
taskmanager.memory.network.max: 1024m# 网络与通信
taskmanager.network.bind-policy: ip
akka.ask.timeout: 60s# Web UI
rest.address: 0.0.0.0
rest.port: 8081# 检查点配置
execution.checkpointing.interval: 5min
execution.checkpointing.timeout: 10min
execution.checkpointing.mode: EXACTLY_ONCEmasters配置:
# /opt/flink/conf/masters(所有JobManager节点相同)
flink-jm1:8081
flink-jm2:8081
flink-jm3:8081workers配置:
# /opt/flink/conf/workers(所有节点相同)
flink-tm1
flink-tm2
flink-tm33. TaskManager节点配置
# /opt/flink/conf/flink-conf.yaml(所有TaskManager节点)# 覆盖JobManager地址配置
jobmanager.rpc.address: flink-jm1# TaskManager专用配置
taskmanager.memory.process.size: 24576m
taskmanager.memory.managed.size: 8192m
taskmanager.numberOfTaskSlots: 84. 配置HDFS支持(可选)
# 所有节点
sudo tee -a /opt/flink/conf/flink-conf.yaml <<EOF
fs.hdfs.hadoopconf: /etc/hadoop/conf
fs.hdfs.hdfsdefault: hdfs-default.xml
fs.hdfs.hdfssite: hdfs-site.xml
EOF# 复制Hadoop配置文件到Flink目录
sudo cp /etc/hadoop/conf/*-site.xml /opt/flink/conf/五、启动集群
1. 启动JobManager集群
# 在每个JobManager节点执行
sudo -u flink $FLINK_HOME/bin/jobmanager.sh start# 检查启动状态
sudo -u flink $FLINK_HOME/bin/jobmanager.sh status2. 启动TaskManager集群
# 在每个TaskManager节点执行
sudo -u flink $FLINK_HOME/bin/taskmanager.sh start# 检查启动状态
sudo -u flink $FLINK_HOME/bin/taskmanager.sh status3. 查看集群状态
# 查看JobManager列表
sudo -u flink $FLINK_HOME/bin/jobmanager.sh list# 查看Web UI
http://flink-jm1:8081
http://flink-jm2:8081
http://flink-jm3:8081六、高可用验证测试
1. 提交示例作业
$FLINK_HOME/bin/flink run -m flink-jm1:8081 \$FLINK_HOME/examples/streaming/StateMachineExample.jar2. 故障转移测试
# 查找主JobManager PID
ps aux | grep '[j]obmanager'# 模拟故障,杀死主JobManager
kill -9 <JM_PID># 观察日志(约10-30秒后自动恢复)
tail -f /opt/flink/log/flink-flink-jobmanager-*.log3. 检查点验证
# 查看检查点状态
hdfs dfs -ls /flink/checkpoints# 列出正在运行的作业
$FLINK_HOME/bin/flink list -m flink-jm2:8081七、运维管理脚本
1. 集群启动/停止脚本
#!/bin/bash
# flink-cluster.shcase $1 in
start)for jm in flink-jm1 flink-jm2 flink-jm3; dossh flink@$jm "$FLINK_HOME/bin/jobmanager.sh start"donefor tm in flink-tm1 flink-tm2 flink-tm3; dossh flink@$tm "$FLINK_HOME/bin/taskmanager.sh start"done;;
stop)for tm in flink-tm1 flink-tm2 flink-tm3; dossh flink@$tm "$FLINK_HOME/bin/taskmanager.sh stop"donefor jm in flink-jm1 flink-jm2 flink-jm3; dossh flink@$jm "$FLINK_HOME/bin/jobmanager.sh stop"done;;
restart)$0 stopsleep 5$0 start;;
status)for jm in flink-jm1 flink-jm2 flink-jm3; doecho "=== $jm ==="ssh flink@$jm "$FLINK_HOME/bin/jobmanager.sh status"donefor tm in flink-tm1 flink-tm2 flink-tm3; doecho "=== $tm ==="ssh flink@$tm "$FLINK_HOME/bin/taskmanager.sh status"done;;
*)echo "Usage: $0 {start|stop|restart|status}"exit 1;;
esac2. 日志监控脚本
#!/bin/bash
# monitor-flink-logs.shtail -f /opt/flink/log/flink-flink-*.log \| awk '/ERROR/ {print "\033[31m" $0 "\033[39m"; next}/WARN/ {print "\033[33m" $0 "\033[39m"; next}/Transition.+MASTER/ {print "\033[32m" $0 "\033[39m"; next}{print}'八、常见问题解决
1. JobManager无法选举
症状:日志中出现No leader available错误
解决方案:
# 检查ZooKeeper连接
$FLINK_HOME/bin/flink list -m zookeeper# 清空临时状态(谨慎操作)
hdfs dfs -rm -r /flink/ha/*2. TaskManager无法注册
症状:Web UI中不显示TaskManager
解决方案:
# 检查网络连通性
telnet flink-jm1 6123# 检查防火墙
sudo ufw status# 增加网络超时(flink-conf.yaml)
taskmanager.registration.timeout: 5min3. 检查点失败
症状:作业因检查点超时失败
解决方案:
# 优化配置(flink-conf.yaml)
execution.checkpointing.interval: 2min
execution.checkpointing.timeout: 5min
state.backend.rocksdb.localdir: /data/rocksdb九、备份与恢复
1. Savepoint操作
# 手动创建Savepoint
flink savepoint <job-id> hdfs:///flink/savepoints# 从Savepoint恢复
flink run -s hdfs:///flink/savepoints/savepoint-... \-m flink-jm1:8081 /path/to/job.jar2. 配置备份
# 备份关键配置
tar -czvf flink-conf-backup.tar.gz /opt/flink/conf# 备份作业JAR包
hdfs dfs -copyFromLocal /opt/flink/jobs /flink/job-backups十、安全增强建议
1. 启用Kerberos认证
# flink-conf.yaml
security.kerberos.login.keytab: /etc/security/keytabs/flink.service.keytab
security.kerberos.login.principal: flink/_HOST@REALM
security.kerberos.login.contexts: Client2. SSL加密通信
# flink-conf.yaml
security.ssl.enabled: true
security.ssl.keystore: /etc/ssl/flink.keystore
security.ssl.truststore: /etc/ssl/flink.truststore
security.ssl.keystore-password: changeme
security.ssl.truststore-password: changeme3. 访问控制
# Web UI访问限制
rest.address: 127.0.0.1
# 或使用代理+Nginx基础认证完成上述部署后,您将获得一个高可用的 Flink 集群,能够承受节点故障并保证作业持续运行。建议首次部署完成后进行完整的故障转移测试,确保高可用功能按预期工作。
十一、关联知识
【分布式技术】中间件-分布式协调服务zookeeper
相关文章:

Flink 高可用集群部署指南
一、部署架构设计 1. 集群架构 graph TDClient([客户端]) --> JM1[JobManager 1]Client --> JM2[JobManager 2]Client --> JM3[JobManager 3]subgraph ZooKeeper集群ZK1[ZooKeeper 1]ZK2[ZooKeeper 2]ZK3[ZooKeeper 3]endsubgraph TaskManager集群TM1[TaskManager 1…...
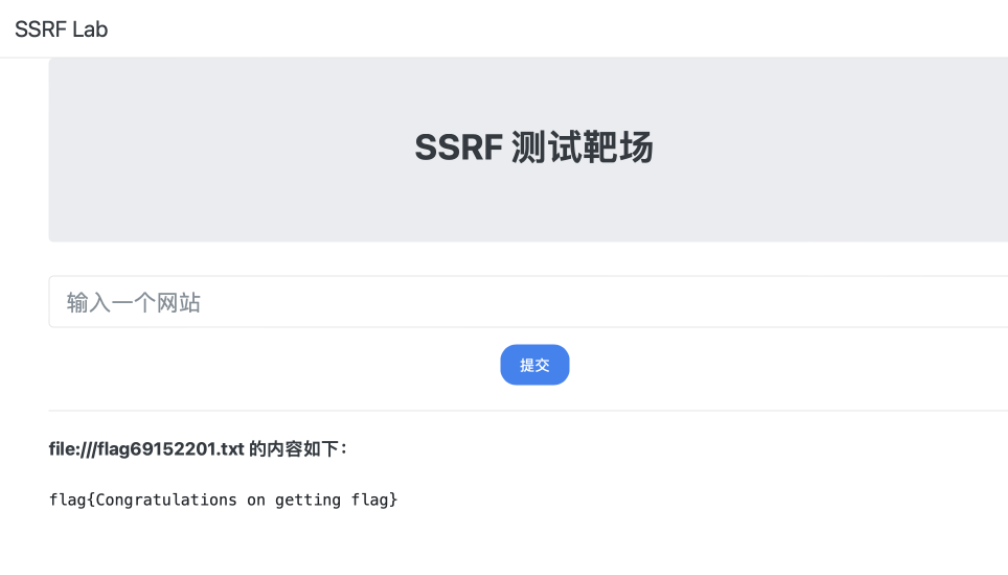
【云安全】以Aliyun为例聊云厂商服务常见利用手段
目录 OSS-bucket_policy_readable OSS-object_public_access OSS-bucket_object_traversal OSS-Special Bucket Policy OSS-unrestricted_file_upload OSS-object_acl_writable ECS-SSRF 云攻防场景下对云厂商服务的利用大同小异,下面以阿里云为例 其他如腾…...

读文献先读图:GO弦图怎么看?
GO弦图(Gene Ontology Chord Diagram)是一种用于展示基因功能富集结果的可视化工具,通过弦状连接可以更直观的展示基因与GO term(如生物过程、分子功能等)之间的关联。 GO弦图解读 ①内圈连线表示基因和生物过程之间的…...

青少年编程与数学 02-020 C#程序设计基础 16课题、文件操作
青少年编程与数学 02-020 C#程序设计基础 16课题、文件操作 一、文件操作1. 什么是文件操作?2. 文件操作在程序设计中的重要性小结 二、C#文件操作1. 引入命名空间2. 常见文件操作(1)创建文件(2)写入文件(3…...

怎么让大语言模型(LLMs)自动生成和优化提示词:APE
怎么让大语言模型(LLMs)自动生成和优化提示词:APE https://arxiv.org/pdf/2211.01910 1. 研究目标:让机器自己学会设计提示词 问题:大语言模型(如GPT-3)很强大,但需要精心设计的“提示词”才能发挥最佳效果。过去靠人工设计提示词,费时费力,还可能因表述差异导致模…...
)
网关路由配置(Gateway Filters)
- id: system-admin-api # 路由的编号uri: grayLb://system-serverpredicates: # 断言,作为路由的匹配条件,对应 RouteDefinition 数组- Path/admin-api/system/**filters:- RewritePath/admin-api/system/v3/api-docs, /v3/api-docs # 配置,…...
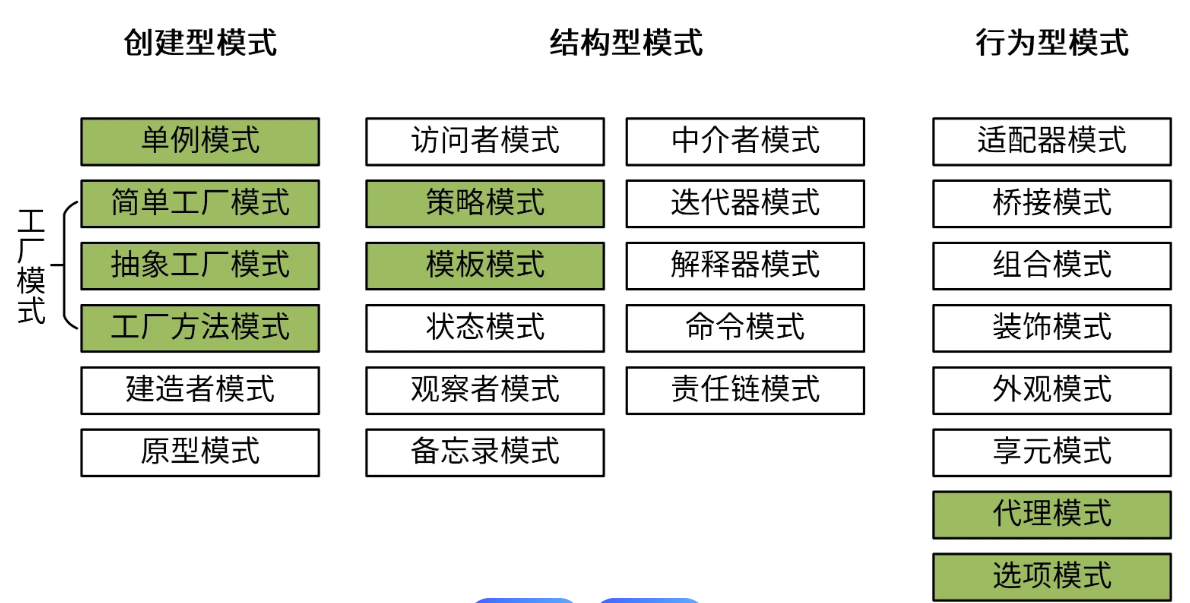
实现单例模式的常见方式
前言 java有多种设计模式,如下图所示: 单例模式它确保一个类只有一个实例,并提供一个全局访问点。 1、单例模式介绍 1.1、使用原因 为什么要使用单例模式? 1. 控制资源访问 核心价值:确保对共享资源(如…...

Go 为何天生适合云原生?
当前我们正处在 AI 时代,但是在基础架构领域,仍然处在云原生时代。云原生仍然是当前时代的风口之一。作为一个 Go 开发者,职业进阶的下一站就是学习云原生技术。作为 Go 开发者学习云原生技术有得天独厚的优势,这是因为 Go 天生适…...
受限的情况下,如何优先处理需求并保证核心交付?)
数仓面试提问:在资源(计算、存储、人力)受限的情况下,如何优先处理需求并保证核心交付?
在资源受限的情况下高效处理需求并保证核心交付,是每个团队管理者都会面临的挑战。这种既要“少花钱多办事”又要确保关键任务不延误的压力,面对这种情况,我们需要一套系统化的方法来实现需求评估、优先级排序和有效沟通。以下是经过实践验证的策略和方法: 🛠️ 一、 保证…...

第七十四篇 高并发场景下的Java并发容器:用生活案例讲透技术原理
避开快递/电路/医疗案例,聚焦餐厅、超市、影院等生活场景,轻松掌握高并发设计精髓 引言:为什么需要并发容器? 想象一个繁忙的火锅店:30个服务员同时用平板电脑下单。若用普通HashMap记录订单,当两人同时操…...
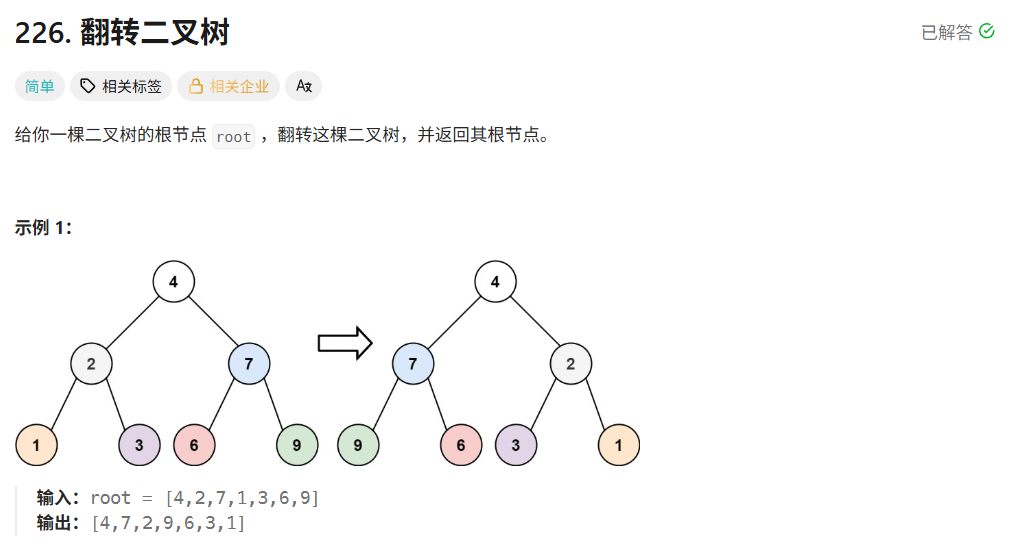
day20 leetcode-hot100-38(二叉树3)
226. 翻转二叉树 - 力扣(LeetCode) 1.广度遍历 思路 这题目很简单,就是交换每个节点的左右子树,也就是相当于遍历到某个节点,然后交换子节点即可。 具体步骤 (1)创建队列,使用广…...

Python打卡训练营学习记录Day46
作业: 今日代码较多,理解逻辑即可对比不同卷积层特征图可视化的结果(可选) 一、CNN特征图可视化实现 import torch import matplotlib.pyplot as pltdef visualize_feature_maps(model, input_tensor):# 注册钩子获取中间层输出…...

使用 C/C++ 和 OpenCV 实现滑动条控制图像旋转
使用 C 和 OpenCV 实现滑动条控制图像旋转 本文将介绍如何使用 C 和 OpenCV 库创建一个简单的应用程序,该程序可以显示一张图片,并允许用户通过一个滑动条(Trackbar)来实时控制图片的旋转角度。这是一个非常实用的交互式功能&…...

【 java 集合知识 第一篇 】
目录 1.概念 1.1.集合与数组的区别 1.2.集合分类 1.3.Collection和Collections的区别 1.4.集合遍历的方法 2.List 2.1.List的实现 2.2.可以一边遍历一边修改List的方法 2.3.List快速删除元素的原理 2.4.ArrayList与LinkedList的区别 2.5.线程安全 2.6.ArrayList的扩…...
)
护网行动面试试题(2)
文章目录 51、常见的安全工具有哪些?52、说说Nmap工具的使用?53、近几年HW常见漏洞有哪些?54、HW 三(四)大洞56、获得文件读取漏洞,通常会读哪些文件57、了解过反序列化漏洞吗?58、常见的框架漏…...
实战)
使用WebSocket实时获取印度股票数据源(无调用次数限制)实战
使用WebSocket实时获取印度股票数据源(无调用次数限制)实战 一、前置准备 1. 获取API密钥 登录 StockTV开发者平台 → 联系客服获取测试Key(格式MY4b781f618e3f43c4b055f25fa61941ad),该密钥无调用次数限制且支持实时…...

阿里140 补环境日志
所有属性值是 __cheng________ 都是我做的防止套代理 非140环境检测代码 这个日志绝大多数 是做和浏览器tostring结果 处理一致 方法: toString 函数: ...... 结果: ..... 当前代码补了事件和dom 实际手补 比这少些 下方为环境日志: VM526 vm.js:…...

uniapp map组件的基础与实践
UniApp 中的 map 组件用于在应用中展示地图,并且支持在地图上添加标记、绘制线条和多边形等功能。以下是一些基本用法: 1. 基本结构 首先,确保你在页面的 .vue 文件中引入了 map 组件。以下是创建一个简单地图的基本代码结构: <template><view class="con…...

在 Kali 上打造渗透测试专用的 VSCode 环境
Kali Linux 是渗透测试领域的首选操作系统,搭配一款高效的代码编辑器可以显著提升工作效率。Visual Studio Code(VSCode)以其轻量、强大的扩展性和跨平台支持,成为许多安全研究者的选择。本文将详细介绍如何在 Kali Linux 上安装 …...

《前端面试题:CSS3新特性》
CSS3新特性指南:从基础到实战详解 CSS3作为现代Web开发的核心样式标准,彻底改变了前端开发者的工作方式。它不仅解决了传统CSS的诸多痛点,还引入了强大的布局模型、动画系统和响应式设计能力。本文将全面解析CSS3的十大核心新特性࿰…...
Hub-600 六通道CANFD集线器)
极速互联·智控未来——SG-Can(FD)Hub-600 六通道CANFD集线器
工业通信的全维进化,CANFD高速网络的终极枢纽! 核心革新 CANFD协议深度支持:名义波特率5K-1Mbps,数据域速率飙升至5Mbps(较传统CAN提升5倍),开启位速率转换最低100Kbps,完美兼容新旧…...
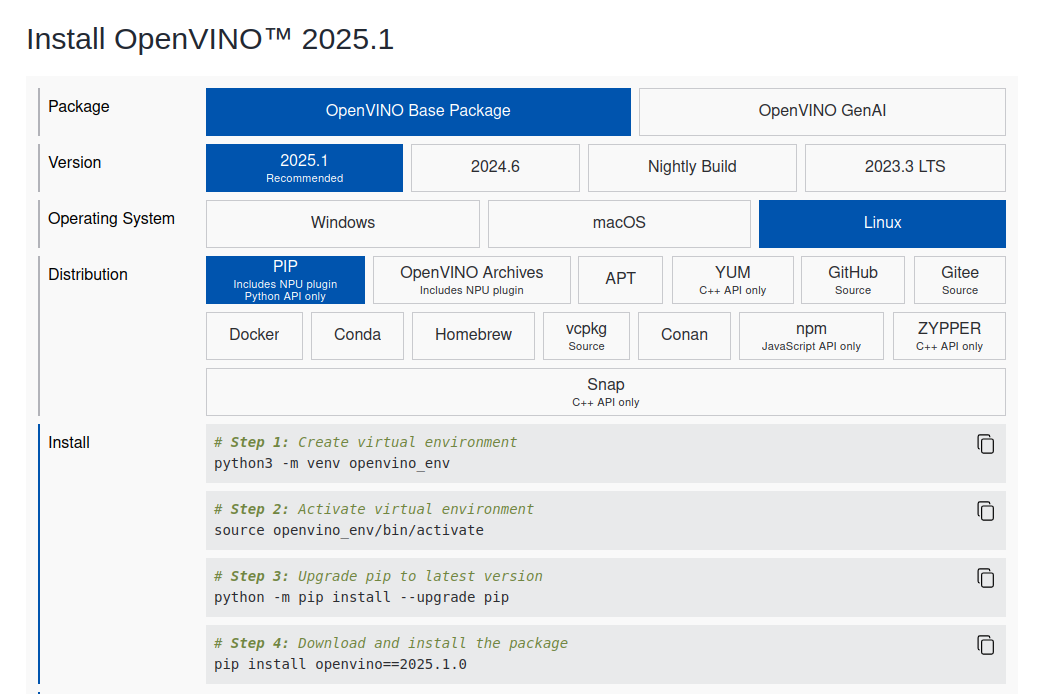
OpenVINO环境配置--OpenVINO安装
TOC环境配置–OpenVINO安装 本节内容 OpenVINO 支持的安装方式有很多种,每一种操作系统以及语言都有对应的安装方法,在官网上有很详细的教程: 我们可以根据自己的需要,来点选环境配置和安装方法,然后网页会给出正…...

Linux top 命令 的使用总结
以下是 Linux top 命令 的使用总结,按功能分类整理,方便快速查询: 一、命令行参数 参数描述示例-d <秒数>设置刷新间隔时间top -d 2(每2秒刷新)-p <PID>监控指定进程IDtop -p 1234(仅显示PID为1234的进程)-u <用户名>显示指定用户的进程top -u root(…...

ajax学习手册
Ajax 通俗易懂学习手册 目录 Ajax 基础概念XMLHttpRequest 详解Fetch API (现代方式)处理不同数据格式错误处理和状态码Ajax 高级技巧实战项目案例最佳实践 Ajax 基础概念 什么是 Ajax? Ajax Asynchronous JavaScript And XML 通俗解释: Ajax 就像…...

Python爬虫实战:研究urlunparse函数相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上的数据量呈现出指数级增长。如何从海量的网页数据中高效地获取有价值的信息,成为了学术界和工业界共同关注的问题。网络爬虫作为一种自动获取网页内容的技术,能够按照预定的规则遍历互联网上的网页,并提取出所需…...

[蓝桥杯]采油
采油 题目描述 LQ 公司是世界著名的石油公司,为世界供应优质石油。 最近,LQ 公司又在森林里发现了一大片区域的油田,可以在这个油田中开采 nn 个油井。 LQ 公司在这 nn 个油井之间修建了 n−1n−1 条道路,每条道路连接两个油井…...

OpenLayers 地图定位
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图定位功能很常见,在移动端和PC端都需要经常用到,像百度、高德、谷歌都提供了方便快捷的定位功能。OpenLayers中也提供了定位的…...
黑龙江云前沿服务器租用:便捷高效的灵活之选
服务器租用,即企业直接从互联网数据中心(IDC)提供商处租赁服务器。企业只需按照所选的服务器配置和租赁期限,定期支付租金,即可使用服务器开展业务。 便捷快速部署:租用服务器能极大地缩短服务器搭建周期…...

PyTorch中matmul函数使用详解和示例代码
torch.matmul 是 PyTorch 中用于执行矩阵乘法的函数,它根据输入张量的维度自动选择适当的矩阵乘法方式,包括: 向量内积(1D 1D)矩阵乘向量(2D 1D)向量乘矩阵(1D 2D)矩…...
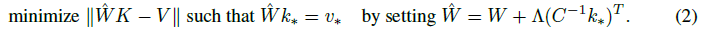
论文解读:Locating and Editing Factual Associations in GPT(ROME)
论文发表于人工智能顶会NeurIPS(原文链接),研究了GPT(Generative Pre-trained Transformer)中事实关联的存储和回忆,发现这些关联与局部化、可直接编辑的计算相对应。因此: 1、开发了一种因果干预方法,用于识别对模型的事实预测起…...