Python60日基础学习打卡Day45
之前的神经网络训练中,为了帮助理解借用了很多的组件,比如训练进度条、可视化的loss下降曲线、权重分布图,运行结束后还可以查看单张图的推理效果。
如果现在有一个交互工具可以很简单的通过按钮完成这些辅助功能那就好了,他就是可视化工具tensorboard
tensorboard的基本操作
1.1 发展历史
TensorBoard 是 TensorFlow 生态中的官方可视化工具,用于实时监控训练过程、可视化模型结构、分析数据分布、对比实验结果等。它通过网页端交互界面,将枯燥的训练日志转化为直观的图表和图像,帮助开发者快速定位问题、优化模型,就像给机器学习模型训练过程装了一个「监控屏幕」。你可以用它直观看到训练过程中的数据变化(比如损失值、准确率)、模型结构、数据分布等,不用盯着一堆枯燥的数字看,对新手非常友好。2019 年后与 PyTorch 兼容,变得更通用了。功能进一步丰富,比如支持3D 可视化、模型参数调试等。我们目前只需要要用到最经典的几个功能即可
- 保存模型结构图
- 保存训练集和验证集的loss变化曲线,不需要手动打印了
- 保存每一个层结构权重分布
- 保存预测图片的预测信息
1.2 tensorboard的原理
TensorBoard 的核心原理就是在训练过程中,把训练过程中的数据(比如损失、准确率、图片等)先记录到日志文件里,再通过工具把这些日志文件可视化成图表,这样就不用自己手动打印数据或者用其他工具画图。
所以核心就是2个步骤:
- 数据怎么存?—— 先写日志文件
训练模型时,TensorBoard 会让程序把训练数据(比如损失值、准确率)和模型结构等信息,写入一个特殊的日志文件(.tfevents 文件)
- 数据怎么看?—— 用网页展示日志
写完日志后,TensorBoard 会启动一个本地网页服务,自动读取日志文件里的数据,用图表、图像、文本等形式展示出来。如果只用 print(损失值) 或者自己用 matplotlib 画图,不仅麻烦,还得手动保存数据、写代码。而 TensorBoard 能自动把这些数据 “存下来 + 画出来”,还能生成网页版的可视化界面,随时刷新查看!
下面是tensorboard的核心代码解析,无需运行 看懂大概在做什么即可
1.3 日志目录自动管理
log_dir = 'runs/cifar10_mlp_experiment'
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}" #一个编号有了就赶紧生成下一个
writer = SummaryWriter(log_dir) #关键入口,用于写入数据到日志目录自动避免日志目录重复。若 runs/cifar10_mlp_experiment 已存在,会生成 runs/cifar10_mlp_experiment_1、_2 等新目录,确保每次训练的日志独立存储。
方便对比不同训练任务的结果(如不同超参数实验)
1.4 记录标量数据(Scalar)
# 记录每个 Batch 的损失和准确率
writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)
writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录每个 Epoch 的训练指标
writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)在 tensorboard的SCALARS 选项卡中查看曲线,支持多 run 对比?。
1.5 可视化模型结构(Graph)
dataiter = iter(train_loader)
images, labels = next(dataiter)
images = images.to(device)
writer.add_graph(model, images) # 通过真实输入样本生成模型计算图TensorBoard 界面:在 GRAPHS 选项卡中查看模型层次结构(卷积层、全连接层等)。
1.6 可视化图像(Image)
# 可视化原始训练图像
img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 将多张图像拼接成网格状(方便可视化),将前8张图像拼接成一个网格
writer.add_image('原始训练图像', img_grid)# 可视化错误预测样本(训练结束后)
wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])
writer.add_image('错误预测样本', wrong_img_grid)展示原始图像、数据增强效果、错误预测样本等。
1.7 记录权重和梯度直方图(Histogram)
if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step) # 权重分布if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step) # 梯度分布在 HISTOGRAMS 选项卡中查看不同层的参数分布随训练的变化。监控模型参数(如权重 weights)和梯度(grads)的分布变化,诊断训练问题(如梯度消失 / 爆炸)。
1.8 启动tensorboard
运行代码后,会在指定目录(如 runs/cifar10_mlp_experiment_1)生成 .tfevents 文件,存储所有 TensorBoard 数据。
在终端执行(需进入项目根目录):
tensorboard --logdir=runs # 假设日志目录在 runs/ 下
打开浏览器,输入终端提示的 URL(通常为 http://localhost:6006)。
二、tensorboard实战
2.1 cifar-10 MLP实战
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 创建TensorBoard的SummaryWriter,指定日志保存目录
log_dir = 'runs/cifar10_mlp_experiment'
# 如果目录已存在,添加后缀避免覆盖
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir)# 5. 训练模型(使用TensorBoard记录各种信息)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer):model.train() # 设置为训练模式# 记录训练开始时间,用于计算训练速度global_step = 0# 可视化模型结构dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 添加模型图# 可视化原始图像样本img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始训练图像', img_grid)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 统计准确率和损失running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次记录一次信息到TensorBoardif (batch_idx + 1) % 100 == 0:batch_loss = loss.item()batch_acc = 100. * correct / total# 记录标量数据(损失、准确率)writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录学习率writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)# 每500个批次记录一次直方图(权重和梯度)if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step)print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 记录每个epoch的训练损失和准确率writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0# 用于存储预测错误的样本wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集预测错误的样本wrong_mask = (predicted != target).cpu()if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask].cpu()wrong_batch_labels = target[wrong_mask].cpu()wrong_batch_preds = predicted[wrong_mask].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录每个epoch的测试损失和准确率writer.add_scalar('Test/Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)# 计算并记录训练速度(每秒处理的样本数)# 这里简化处理,假设每个epoch的时间相同samples_per_epoch = len(train_loader.dataset)# 实际应用中应该使用time.time()来计算真实时间print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 可视化预测错误的样本(只在最后一个epoch进行)if epoch == epochs - 1 and len(wrong_images) > 0:# 最多显示8个错误样本display_count = min(8, len(wrong_images))wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])# 创建错误预测的标签文本wrong_text = []for i in range(display_count):true_label = classes[wrong_labels[i]]pred_label = classes[wrong_preds[i]]wrong_text.append(f'True: {true_label}, Pred: {pred_label}')writer.add_image('错误预测样本', wrong_img_grid)writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 关闭TensorBoard写入器writer.close()return epoch_test_acc # 返回最终测试准确率# 6. 执行训练和测试
epochs = 20 # 训练轮次
print("开始训练模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("训练完成后,使用命令 `tensorboard --logdir=runs` 启动TensorBoard查看可视化结果")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")TensorBoard日志保存在: runs/cifar10_mlp_experiment_1 可以在命令行中进入目前的环境,然后通过tensorboard --logdir=xxxx(目录)即可调出本地链接,点进去就是目前的训练信息,可以不断F5刷新来查看变化。
在TensorBoard界面中,你可以看到:
- SCALARS 选项卡:展示损失曲线、准确率变化、学习率等标量数据----Scalar意思是标量,指只有大小、没有方向的量。
- IMAGES 选项卡:展示原始训练图像和错误预测的样本
- GRAPHS 选项卡:展示模型的计算图结构
- HISTOGRAMS 选项卡:展示模型参数和梯度的分布直方图
2.2 cifar-10 CNN实战
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 创建TensorBoard的SummaryWriter,指定日志保存目录
log_dir = 'runs/cifar10_mlp_experiment'
# 如果目录已存在,添加后缀避免覆盖
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir)# 5. 训练模型(使用TensorBoard记录各种信息)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer):model.train() # 设置为训练模式# 记录训练开始时间,用于计算训练速度global_step = 0# 可视化模型结构dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 添加模型图# 可视化原始图像样本img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始训练图像', img_grid)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 统计准确率和损失running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次记录一次信息到TensorBoardif (batch_idx + 1) % 100 == 0:batch_loss = loss.item()batch_acc = 100. * correct / total# 记录标量数据(损失、准确率)writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录学习率writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)# 每500个批次记录一次直方图(权重和梯度)if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step)print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 记录每个epoch的训练损失和准确率writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0# 用于存储预测错误的样本wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集预测错误的样本wrong_mask = (predicted != target).cpu()if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask].cpu()wrong_batch_labels = target[wrong_mask].cpu()wrong_batch_preds = predicted[wrong_mask].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录每个epoch的测试损失和准确率writer.add_scalar('Test/Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)# 计算并记录训练速度(每秒处理的样本数)# 这里简化处理,假设每个epoch的时间相同samples_per_epoch = len(train_loader.dataset)# 实际应用中应该使用time.time()来计算真实时间print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 可视化预测错误的样本(只在最后一个epoch进行)if epoch == epochs - 1 and len(wrong_images) > 0:# 最多显示8个错误样本display_count = min(8, len(wrong_images))wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])# 创建错误预测的标签文本wrong_text = []for i in range(display_count):true_label = classes[wrong_labels[i]]pred_label = classes[wrong_preds[i]]wrong_text.append(f'True: {true_label}, Pred: {pred_label}')writer.add_image('错误预测样本', wrong_img_grid)writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 关闭TensorBoard写入器writer.close()return epoch_test_acc # 返回最终测试准确率# 6. 执行训练和测试
epochs = 20 # 训练轮次
print("开始训练模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("训练完成后,使用命令 `tensorboard --logdir=runs` 启动TensorBoard查看可视化结果")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")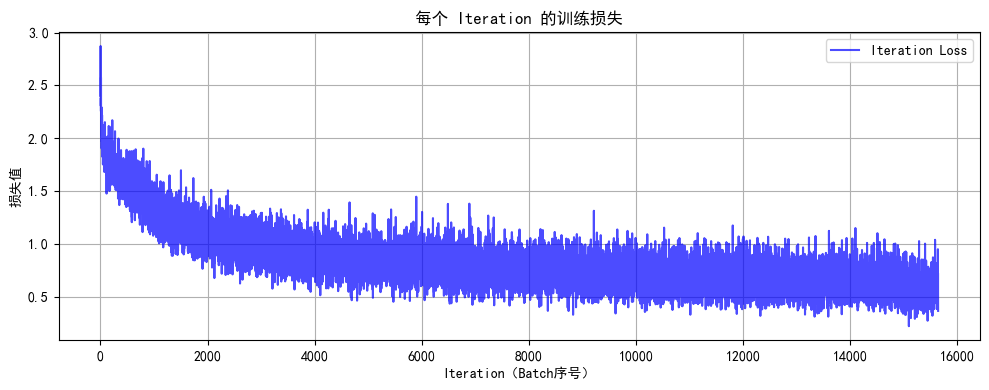
由于已近搭载了tensorboard,上述代码中一些之前可视化的冗余部分可以删除了。
tensorboard的代码还有有一定的记忆量,实际上深度学习的经典代码都是类似于八股文,看多了就习惯了,难度远远小于考研数学等需要思考的内容
实际上对目前的ai而言,你只需要先完成最简单的demo,然后让他给你加上tensorboard需要打印的部分即可。---核心是弄懂tensorboard可以打印什么信息,以及如何看可视化后的结果,把ai当成记忆大师用到的时候通过它来调取对应的代码即可。
相关文章:
Python60日基础学习打卡Day45
之前的神经网络训练中,为了帮助理解借用了很多的组件,比如训练进度条、可视化的loss下降曲线、权重分布图,运行结束后还可以查看单张图的推理效果。 如果现在有一个交互工具可以很简单的通过按钮完成这些辅助功能那就好了,他就是…...

《Java 并发神器:深入理解CompletableFuture.supplyAsync与线程池实战优化》
一、背景介绍 在 Java 后端开发中,我们经常会遇到以下问题: 需要并行执行多个数据库查询或远程调用;单线程执行多个 .list() 方法时耗时过长;希望提升系统响应速度,但又不想引入过多框架。 这时,Java 8 …...
【Visual Studio 2022】卸载安装,ASP.NET
Visual Studio 2022 彻底卸载教程 手动清理残留文件夹 删除C:\Program Files\Microsoft Visual Studio 是旧版本 Visual Studio 的残留安装目录 文件夹名对应的 Visual Studio 版本Microsoft Visual Studio 9.0Visual Studio 2008Microsoft Visual Studio 10.0Visual Studio…...

JVM中的各类引用
JVM中的各类引用 欢迎来到我的博客:TWind的博客 我的CSDN::Thanwind-CSDN博客 我的掘金:Thanwinde 的个人主页 对象 众所不周知,Java中基本所有的对象都是分配在堆内存之中的,除开基本数据类型在栈帧中以外…...
thinkphp-queue队列随笔
安装 # 创建项目 composer create-project topthink/think 5.0.*# 安装队列扩展 composer require topthink/think-queue 配置 // application/extra/queue.php<?php return [connector > Redis, // Redis 驱动expire > 0, // 任务的过期时间…...
STM32标准库-TIM输出比较
文章目录 一、输出比较二、PWM2.1简介2.2输出比较通道(高级)2.3 输出比较通道(通用)2.4输出比较模式2.5 PWM基本结构1、时基单元2、输出比较单元3、输出控制(绿色右侧)4、右上波形图(以绿色脉冲…...

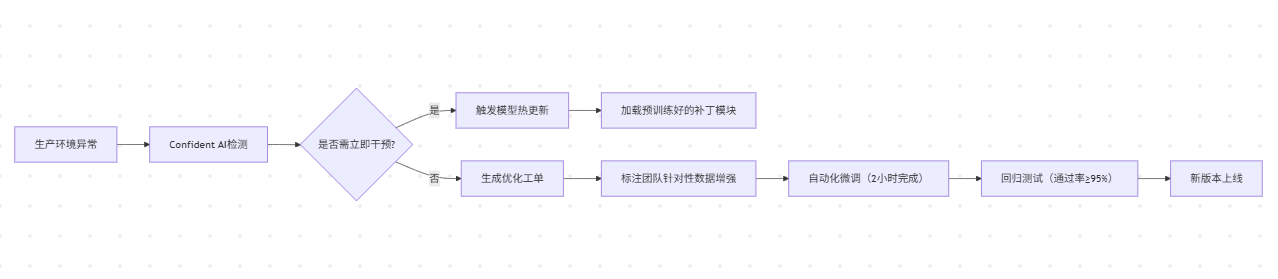
科技创新驱动人工智能,计算中心建设加速产业腾飞
在科技飞速发展的当下,人工智能正以前所未有的速度融入我们的生活。一辆辆无人驾驶的车辆在道路上自如地躲避车辆和行人,行驶平稳且操作熟练;刷脸支付让购物变得安全快捷,一秒即可通行。这些曾经只存在于想象中的场景,…...

figma 和蓝湖 有什么区别
以下是 Figma 和蓝湖的详细对比分析: 核心定位区别 维度Figma蓝湖本质全功能云端设计工具设计协作与交付平台核心功能设计原型协作开发交付设计稿交付标注切图协作设计能力✅ 完整矢量设计工具❌ 无设计功能(需导入其他工具文件)适用阶段全流…...

SQLServer中的存储过程与事务
一、存储过程的概念 1. 定义 存储过程(Stored Procedure)是一组预编译的 SQL 语句的集合,它们被存储在数据库中,可以通过指定存储过程的名称并执行来调用它们。存储过程可以接受输入参数、输出参数,并且可以返回执行…...

STM32H562----------ADC外设详解
1、ADC 简介 STM32H5xx 系列有 2 个 ADC,都可以独立工作,其中 ADC1 和 ADC2 还可以组成双模式(提高采样率)。每个 ADC 最多可以有 20 个复用通道。这些 ADC 外设与 AHB 总线相连。 STM32H5xx 的 ADC 模块主要有如下几个特性: 1、可配置 12 位、10 位、8 位、6 位分辨率,…...
uniapp 安卓 APP 后台持续运行(保活)的尝试办法
在移动应用开发领域,安卓系统的后台管理机制较为复杂,应用在后台容易被系统回收,导致无法持续运行。对于使用 Uniapp 开发的安卓 APP 来说,实现后台持续运行(保活)是很多开发者面临的重要需求,比…...
AI大数据模型如何与thingsboard物联网结合
一、 AI大数据与ThingsBoard物联网的结合可以从以下几个方面实现: 1. 数据采集与集成 设备接入:ThingsBoard支持多种通信协议(如MQTT、CoAP、HTTP、Modbus、OPC-UA等),可以方便地接入各种物联网设备。通过这些协议&am…...
【SSM】SpringBoot笔记2:整合Junit、MyBatis
前言: 文章是系列学习笔记第9篇。基于黑马程序员课程完成,是笔者的学习笔记与心得总结,供自己和他人参考。笔记大部分是对黑马视频的归纳,少部分自己的理解,微量ai解释的内容(ai部分会标出)。 …...

STM32——CAN总线
STM32——CAN总线 1. CAN总线基础概念 1.1 CAN总线简介 控制器局域网(Controller Area Network, CAN)是由Bosch公司开发的串行通信协议,专为汽车电子和工业控制设计,具有以下核心特性: 多主控制架构:所有…...
嵌入式面试高频!!!C语言(四)(嵌入式八股文,嵌入式面经)
更多嵌入式面试文章见下面连接,会不断更新哦!!关注一下谢谢!!!! https://blog.csdn.net/qq_61574541/category_12976911.html?fromshareblogcolumn&sharetypeblogcolumn&…...

数据治理在制造业的实践案例
一、数据治理在制造业的重要性 随着工业4.0的到来,制造业正经历着前所未有的变革。数据治理作为制造业数字化转型的关键组成部分,对提升企业竞争力、优化生产流程、提高产品质量和客户满意度等方面起着至关重要的作用。在制造业中,数据治理不仅涉及到数据的收集、存…...

【强化学习】——03 Model-Free RL之基于价值的强化学习
【强化学习】——03 Model-Free RL之基于价值的强化学习 \quad\quad \quad\quad 动态规划算法是基于模型的算法,要求已知状态转移概率和奖励函数。但很多实际问题中环境 可能是未知的,这就需要不基于模型(Model-Free)的RL方法。 \quad\quad 其又分为: 基于价值(Valu…...
Edge(Bing)自动领积分脚本部署——基于python和Selenium(附源码)
微软的 Microsoft Rewards 计划可以通过 Bing 搜索赚取积分,积分可以兑换礼品卡、游戏等。每天的搜索任务不多,我们可以用脚本自动完成,提高效率,解放双手。 本文将手把手教你如何部署一个自动刷积分脚本,并解释其背…...

html表格转换为markdown
文章目录 工具功能亮点1.核心实现解析1. 剪贴板交互2. HTML检测与提取3. 转换规则设计 2. 完整代码 在日常工作中,我们经常遇到需要将网页表格快速转换为Markdown格式的场景。无论是文档编写、知识整理还是数据迁移,手动转换既耗时又容易出错。本文将介绍…...
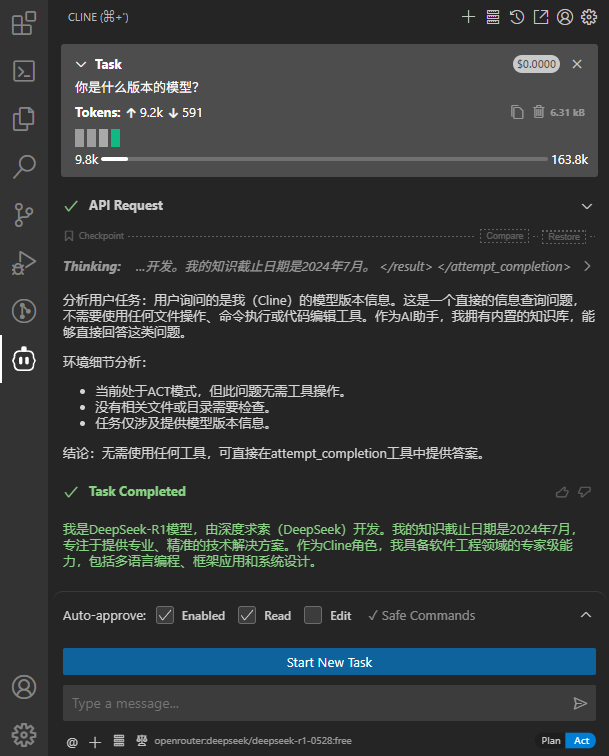
VsCode 安装 Cline 插件并使用免费模型(例如 DeepSeek)
当前时间为 25/6/3,Cline 版本为 3.17.8 点击侧边栏的“扩展”图标 在搜索框中输入“Cline” 找到 Cline 插件,然后点击“安装” 安装完成后,Cline 图标会出现在 VS Code 的侧边栏中 点击 Use your own API key API Provider 选择 OpenRouter…...

短视频矩阵系统源码新发布技术方案有那几种?
短视频矩阵运营在平台政策频繁更迭的浪潮中,已成为内容分发的核心战场。行业领先者如筷子科技、云罗抖去推、超级编导等平台,其稳定高效的代发能力背后,离不开前沿技术方案的强力支撑。本文将深入剖析当前主流的六大短视频矩阵系统代发解决方…...
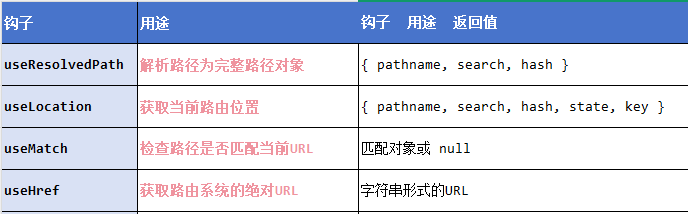
React 第五十二节 Router中 useResolvedPath使用详解和注意事项示例
前言 useResolvedPath 是 React Router v6 提供的一个实用钩子,用于解析给定路径为完整路径对象。 它根据当前路由上下文解析相对路径,生成包含 pathname、search 和 hash 的完整路径对象。 一、useResolvedPath 核心用途 路径解析:将相对…...

【PmHub面试篇】性能监控与分布式追踪利器Skywalking面试专题分析
你好,欢迎来到本次关于PmHub整合性能监控与分布式追踪利器Skywalking的面试系列分享。在这篇文章中,我们将深入探讨这一技术领域的相关面试题预测。若想对相关内容有更透彻的理解,强烈推荐参考之前发布的博文:【PmHub后端篇】Skyw…...

Cursor快速梳理ipynb文件Prompt
1. 整体鸟瞰 请在不运行代码的前提下,总结 <文件名.ipynb> 的主要目的、核心逻辑流程和输出结果。阅读整个项目目录,列出每个 .ipynb / .py 文件的角色,以及它们之间的数据依赖关系(输入→处理→输出)。2. 结构…...
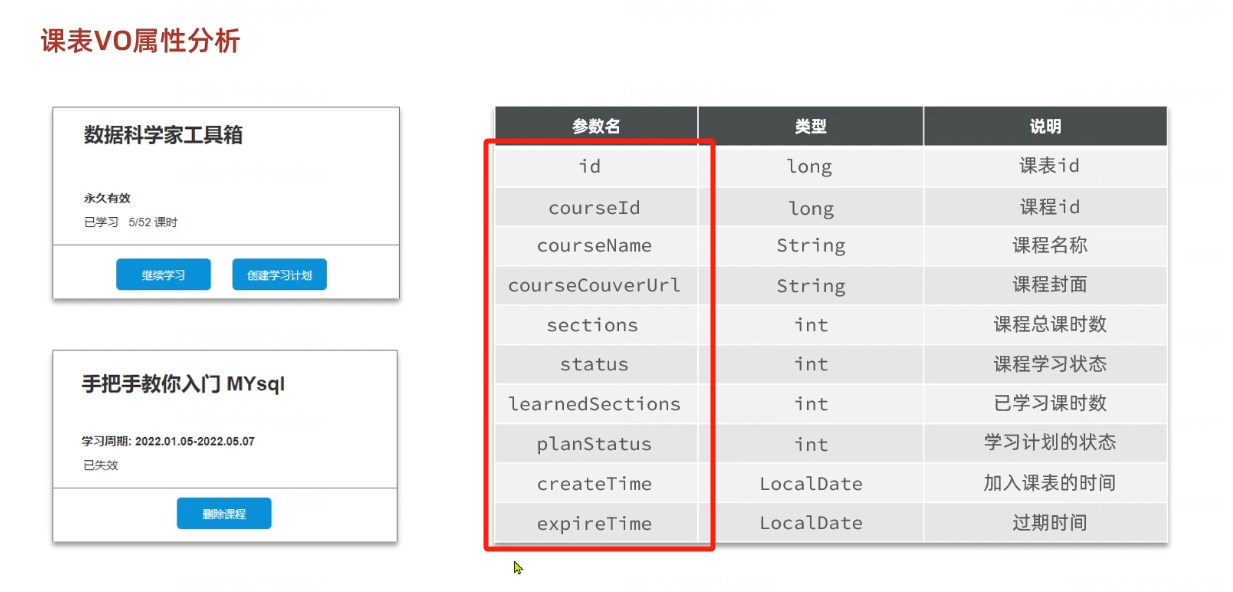
天机学堂-分页查询
需求 分页查询我的课表 返回: 总条数、总页数、当前页的课表信息的集合 返回的VO(已经封装成统一的LearningLessonsVO) 定义Controller RestController RequestMapping("/lessons") RequiredArgsConstructor public class Lear…...

业态即战场:零售平台的生意模型与系统设计解构
目录 一、当我们在电商买菜、点外卖时,其实是零售业态在进化 (一)从“商场选货”到“算法推货”:零售的时代已经不同 (二)“控货”和“卖场”——零售的两种基本商业模式 二、四种经典零售业态解析:控货 vs 卖场,地面 vs 线上 (一)地面控货零售:直营模式的黄金…...
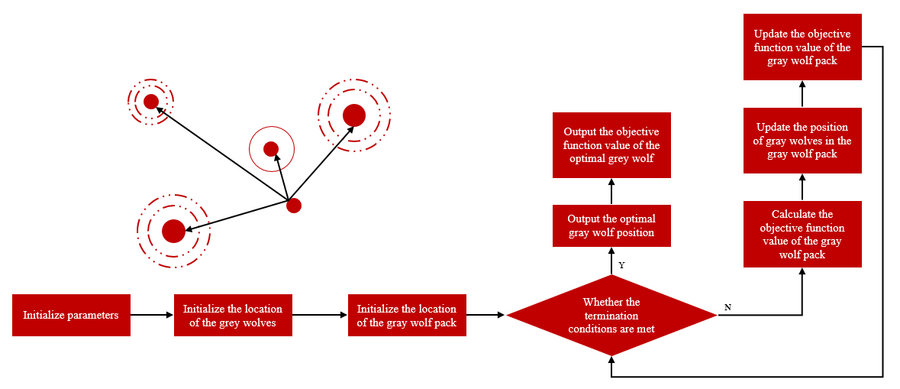
微算法科技(NASDAQ:MLGO)基于信任的集成共识和灰狼优化(GWO)算法,搭建高信任水平的区块链网络
随着数字化转型的加速,区块链技术作为去中心化、透明且不可篡改的数据存储与交换平台,正逐步渗透到金融、供应链管理、物联网等多个领域,探索基于信任的集成共识机制,并结合先进的优化算法来提升区块链网络的信任水平,…...

全新Xsens Animate版本是迄今为止最大的软件升级,提供更清晰的数据、快捷的工作流程以及从录制开始就更直观的体验
我们整合了专业人士喜爱的 Xsens 动捕功能,并使其更加完善。全新Xsens Animate版本是我们迄今为止最大的软件升级,旨在提供更清晰的数据、更快捷的工作流程以及从录制开始就更直观的体验。 从制作游戏动画到流媒体直播头像或构建实时电影内容࿰…...
大语言模型评测体系全解析(下篇):工具链、学术前沿与实战策略
文章目录 一、评测工具链:从手工测试到自动化工程的效率革命(一)OpenCompass:开源评测框架的生态构建1. 技术架构:三层架构实现评测自动化2. 开发者赋能:从入门到进阶的工具矩阵 (二)…...
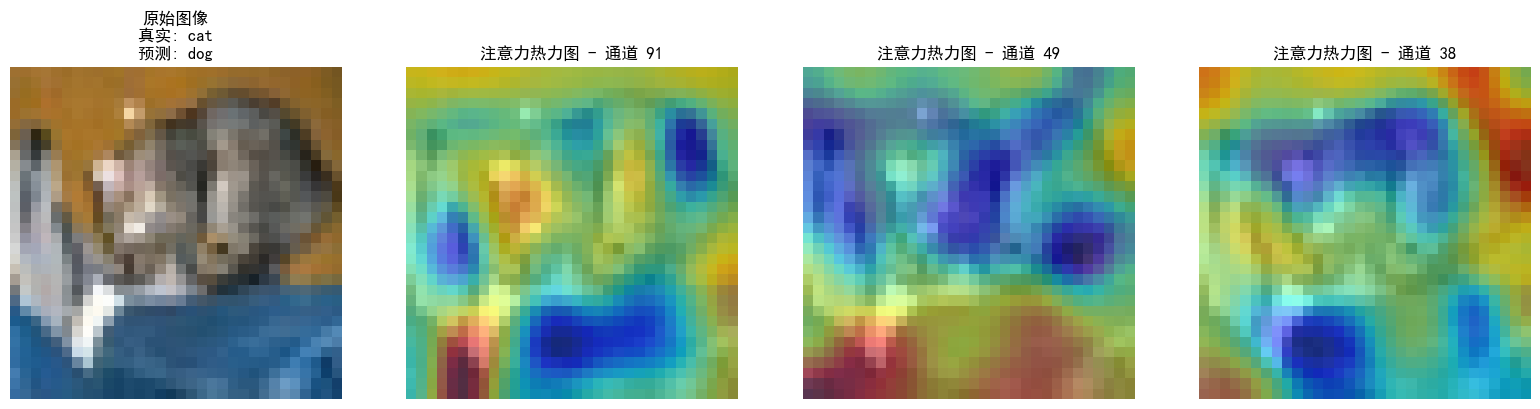
python打卡day46@浙大疏锦行
知识点回顾: 不同CNN层的特征图:不同通道的特征图什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。通道注意力:模型的定义和插入的位置通道注意力后的特征图和热力图 内…...