mysql 页的理解和实际分析
目录
- 页(Page)是 Innodb 存储引擎用于管理数据的最小磁盘单位
- B+树的一般高度
- 记录在页中的存储
- innodb ibd文件
- innodb 页类型
- 分析`ibd`文件
- 查看数据表的行格式
- 查看ibd文件
- 分析 ibd的第4个页:`B-tree Node`类型
- 先分析File Header(38字节-描述页信息)
- 再分析Page Header(56字节-记录页的状态信息)
- 分析Infimum + Supremum Record (26字节-两个虚拟行记录)
- User Record(表中的数据记录)
- COMPACT行记录格式
- File Tailer(最后8字节)
- 附:二进制文件查看小技巧
- 页分裂/页合并
- innodb数据的存储
- 页合并
- 页分裂
- 附加:mysql频繁的插入删除导致的问题
- 1. 性能下降
- 2. 碎片化
- 3. 锁定和阻塞
- 4. 日志文件增长
- 5. 资源竞争
页(Page)是 Innodb 存储引擎用于管理数据的最小磁盘单位
innoDB 中页的默认大小是 16KB
假设一行记录的数据大小为1k,那么单个叶子节点(页)中的记录数=16K/1K=16
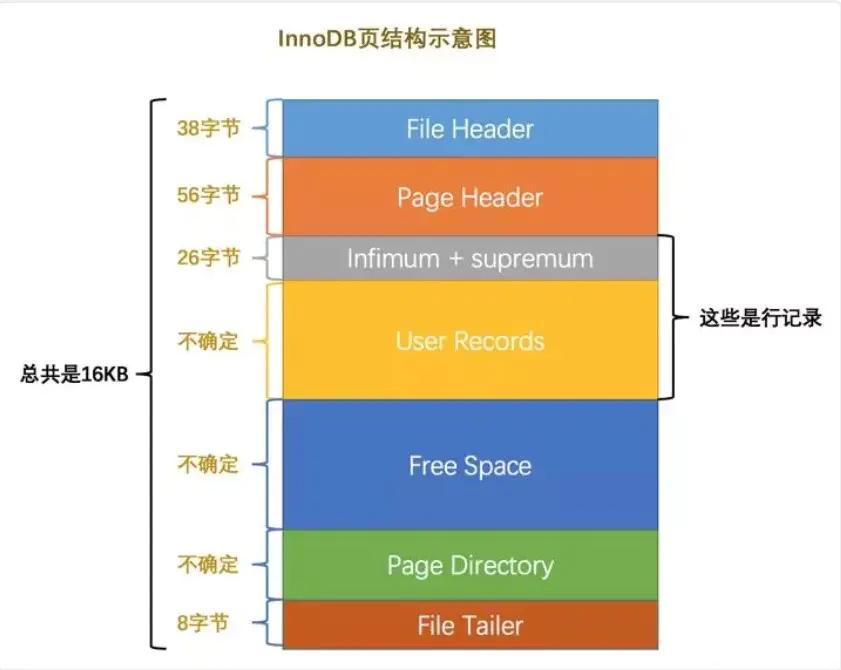
- File Header: 文件头部,页的一些通用信息(38字节)
- page Header: 页面头部,数据页专有的一些信息(56字节)
- infimum+supremum: 行记录最小值和最大值,两个虚拟的行记录(26字节)
- user recorders: 实际存储的行记录内容(不确定)
- free space: 页中尚未使用的空间(不确定)
- Page Directory: 页中的某些记录的相对位置(不确定)
- File Tailer: 校验页是否完整(8字节)
B+树的一般高度
即非叶子节点能存放多少指针?
假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,一个页中能存放多少这样的单元,其实就代表有多少指针,即16kb/14b=1170;那么可以算出一棵高度为2的B+树,大概能存放1170*16=18720条这样的数据记录(即1170个索引,每个索引定位叶子节点的一页数据,一页能存储16行原始数据)。
根据同样的原理我们可以算出一个高度为3的B+树大概可以存放:1170*1170*16=21,902,400行数据。所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次逻辑IO操作即可查找到数据。
记录在页中的存储
- 当一个记录需要插入页的时候,会从
Free space划分空间到User recorders Free Space部分的空间全部被User Records部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了
innodb ibd文件
ibd文件是以页为单位进行管理的,页通常是以16k为单位,所以ibd文件通常是16k的整数倍
innodb 页类型
| 名称 | 十六进制 | 解释 |
|---|---|---|
| FIL_PAGE_INDEX | 0x45BF | B+树叶节点 |
| FIL_PAGE_UNDO_LOGO | 0x0002 | UNDO LOG页 |
| FIL_PAGE_INODE | 0x0003 | 索引节点 |
| FIL_PAGE_IBUF_FREE_LIST | 0x0004 | InsertBuffer空闲列表 |
| FIL_PAGE_TYPE_ALLOCATED | 0x0000 | 该页的最新分配 |
| FIL_PAGE_IBUF_BITMAP | 0x0005 | InsertBuffer位图 |
| FIL_PAGE_TYPE_SYS | 0x0006 | 系统页 |
| FIL_PAGE_TYPE_TRX_SYS | 0x0007 | 事务系统数据 |
| FIL_PAGE_TYPE_FSP_HDR | 0x0008 | FILE SPACE HEADER |
| FIL_PAGE_TYPE_XDES | 0x0009 | 扩展描述页 |
| FIL_PAGE_TYPE_BLOB | 0x000A | BLOB页 |
分析ibd文件
mubi@mubideMacBook-Pro bin $ mysql -uroot -p123456
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 109
Server version: 5.6.40 MySQL Community Server (GPL)Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> use test;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changed
mysql> select * from tb_user;
+------------+--------+----------+-------+-------------+----------+
| id | userID | password | name | phone | address |
+------------+--------+----------+-------+-------------+----------+
| 1 | 00001 | 123456 | zhang | 15133339999 | Shanghai |
| 2 | 00002 | 123456 | wang | 15133339999 | Beijing |
| 4 | 0003 | NULL | abc | NULL | NULL |
| 6 | 0003 | NULL | abc | NULL | NULL |
| 7 | 0004 | 123456 | tom | 110 | beijing |
| 10 | 0004 | 123456 | tom | 110 | beijing |
| 2147483647 | 0004 | 123456 | tom | 110 | beijing |
+------------+--------+----------+-------+-------------+----------+
7 rows in set (0.00 sec)mysql>
查看数据表的行格式
mysql> show table status like 'tb_user'\G;
*************************** 1. row ***************************Name: tb_userEngine: InnoDBVersion: 10Row_format: CompactRows: 6Avg_row_length: 2730Data_length: 16384
Max_data_length: 0Index_length: 16384Data_free: 0Auto_increment: 2147483647Create_time: 2020-03-21 16:10:06Update_time: NULLCheck_time: NULLCollation: utf8_general_ciChecksum: NULLCreate_options:Comment:
1 row in set (0.00 sec)ERROR:
No query specifiedmysql>
查看ibd文件

使用py_innodb_page_info工具(https://github.com/happieme/py_innodb_page_info)

注意到文件大小114688字节(114688 = 16 * 1024 * 7)即有7个页(要分析哪个页直接定位到二进制文件到开始,然后分析即可)
分析 ibd的第4个页:B-tree Node类型
page offset 00000003, page type <B-tree Node>, page level <0000>
>>> hex(3 * 16 * 1024)
'0xc000'
>>> hex(4 * 16 * 1024)
'0x10000'
>>>
先分析File Header(38字节-描述页信息)

- 2D A1 2D 57 -> 数据页的checksum值
- 00 00 00 03 -> 页号(偏移量),当前是第3页
- FF FF FF FF -> 目前只有一个数据页,无上一页
- FF FF FF FF -> 目前只有一个数据页,无下一页
- 00 00 00 04 6F 65 24 CF -> 该页最后被修改的LSN
- 45 BF -> 页的类型,0x45BF代表数据页,刚好这页是数据页
- 00 00 00 00 00 00 00 00 -> 独立表空间,该值为0
- 00 00 00 06 -> 表空间的SPACE ID
再分析Page Header(56字节-记录页的状态信息)
参见:innodb-page-header
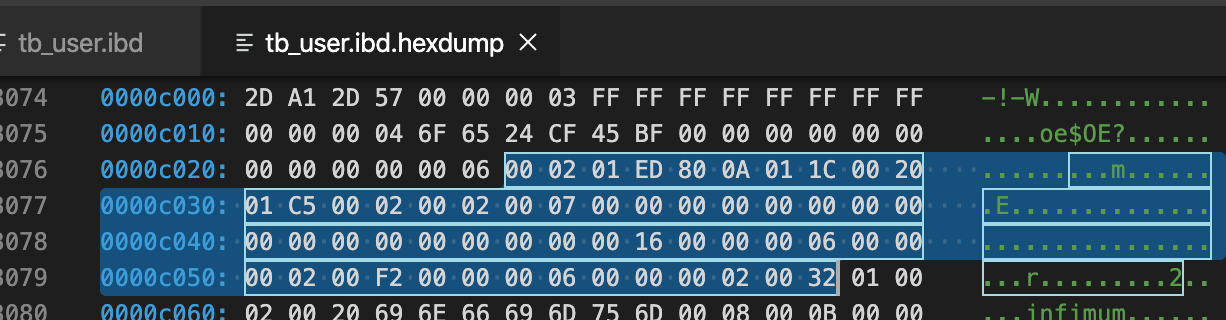
| 标识 | 字节数 | 解释 | 本次值:说明 |
|---|---|---|---|
| PAGE_N_DIR_SLOTS | 2 | number of directory slots in the Page Directory part; initial value = 2 | 00 02,2个槽位 |
| PAGE_HEAP_TOP | 2 | record pointer to first record in heap | 01 ED,堆第一个开始位置的偏移量,也即空闲偏移量 |
| PAGE_N_HEAP | 2 | number of heap records; initial value = 2 | 80 0A |
| PAGE_FREE | 2 | record pointer to first free record | 01 1C |
| PAGE_GARBAGE | 2 | “number of bytes in deleted records” | 00 20,删除的记录字节 |
| PAGE_LAST_INSERT | 2 | record pointer to the last inserted record | 01 C5,最后插入记录的位置偏移 |
| PAGE_DIRECTION | 2 | either PAGE_LEFT, PAGE_RIGHT, or PAGE_NO_DIRECTION | 00 02,自增长的方式进行行记录的插入,方向向右 |
| PAGE_N_DIRECTION | 2 | number of consecutive inserts in the same direction, for example, “last 5 were all to the left” | 00 02 |
| PAGE_N_RECS | 2 | number of up[ser records | 00 07,共7条有效记录数 |
| PAGE_MAX_TRX_ID | 8 | the highest ID of a transaction which might have changed a record on the page (only set for secondary indexes) | 00 00 00 00 00 00 00 00 |
| PAGE_LEVEL | 2 | level within the index (0 for a leaf page) | 00 00 |
| PAGE_INDEX_ID | 8 | identifier of the index the page belongs to | 00 00 00 00 00 00 00 16 |
| PAGE_BTR | 10 | “file segment header for the leaf pages in a B-tree” (this is irrelevant here) | 00 00 00 06 00 00 00 02 00 F2 |
| PAGE_LEVEL | 10 | “file segment header for the non-leaf pages in a B-tree” (this is irrelevant here) | 00 00 00 06 00 00 00 02 00 32 |
0xc000 + 01 ED=0xC1ED地址后面的都是空闲的
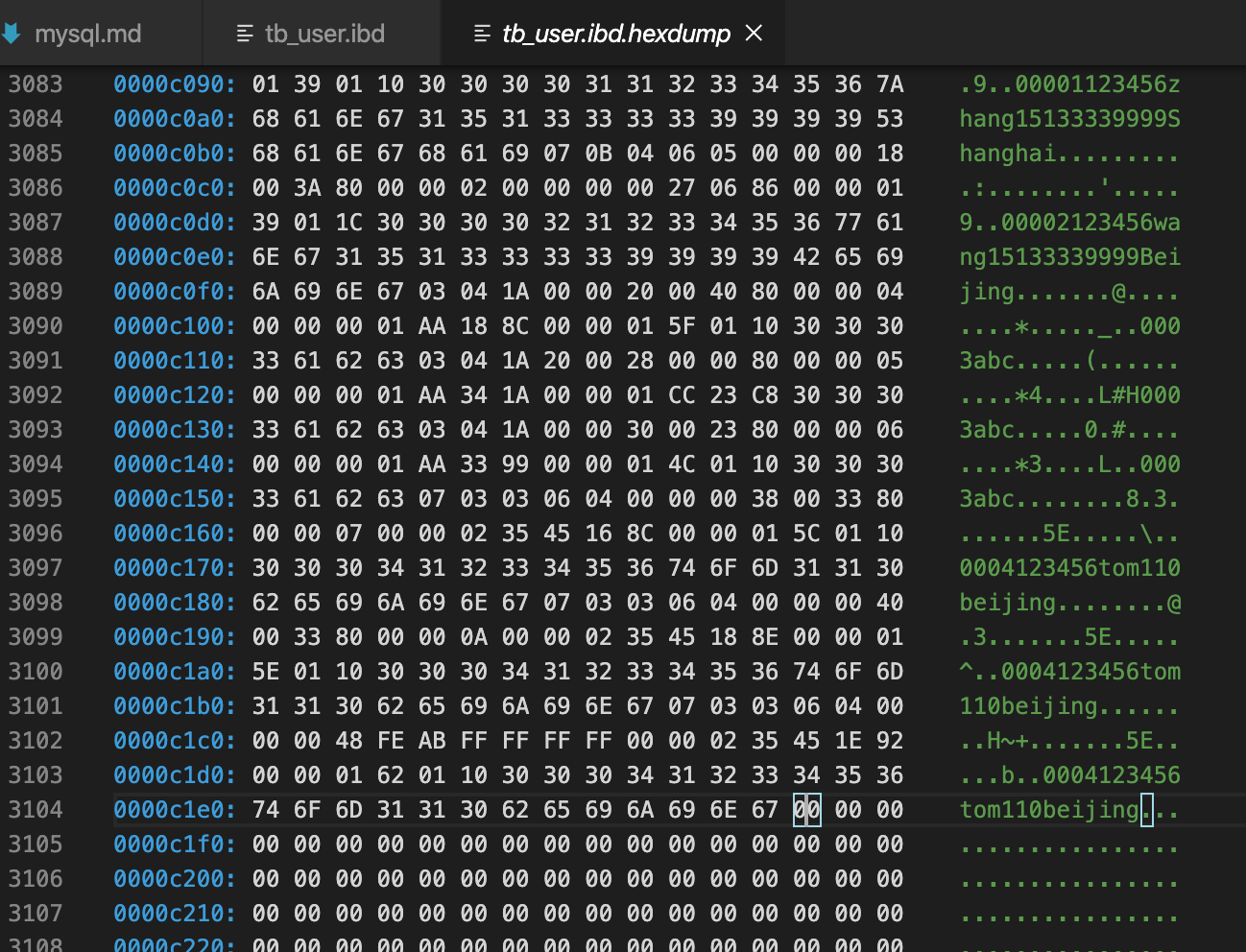
0xc000 + 01 C5=0xC1C5最后一条记录
分析Infimum + Supremum Record (26字节-两个虚拟行记录)
infimum: n. 下确界;
supremum: n. 上确界;
Infimum和Suprenum Record用来限定记录的边界,Infimum是比页中任何主键值都要小的值,Suprenum是指比任何页中可能大值还要大的值,这两个值在页创建时被建立,并且在任何情况下都不会被删除。Infimum和Suprenum与行记录组成单链表结构,查询记录时,从Infimum开始查找,如果找不到结果会直到查到最后的Suprenum为止,然后通过Page Header中的FIL_PAGE_NEXT指针跳转到下一个page继续从Infimum开始逐个查找
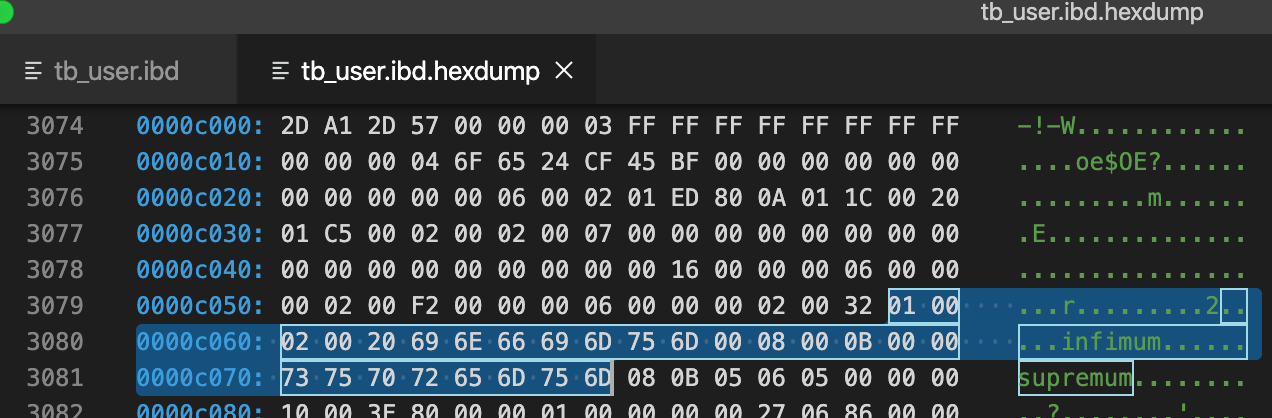
#Infimum伪行记录
01 00 02 00 20/*recorder header*/
69 6E 66 69 6D 75 6D 00/*只有一个列的伪行记录,记录内容就是Infimum(多了一个0x00字节)
*/
#Supremum伪行记录
08 00 0B 00 00/*recorder header*/
73 75 70 72 65 6D 75 6D/*只有一个列的伪行记录,记录内容就是Supremum*/
infimum行记录的recorder header部分,最后2个字节位00 20表示下一个记录的位置的偏移量
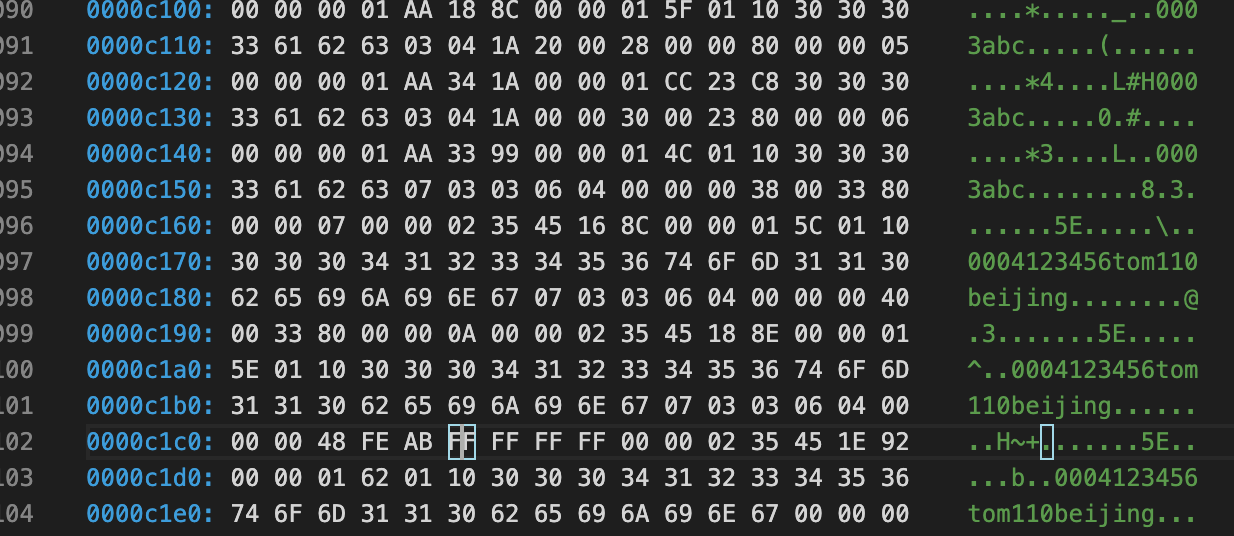
User Record(表中的数据记录)
用户所有插入的记录都存放在这里,默认情况下记录跟记录之间没有间隙,但是如果重用了已删除记录的空间,就会导致空间碎片。每个记录都有指向下一个记录的指针,但是没有指向上一个记录的指针。记录按照主键顺序排序:即用户可以从数据页最小记录开始遍历,直到最大的记录,这包括了所有正常的记录和所有被delete-marked记录,但是不会访问到被删除的记录(PAGE_FREE)
COMPACT行记录格式

-
行格式的首部是一个非NULL变长字段长度列表,而且是按照列的顺序逆序放置的。当列的长度小于255字节,用1字节表示,若大于255个字节,用2个字节表示,变长字段的长度最大不可以超过2个字节(这也很好地解释了为什么MySQL中varchar的最大长度为65535,因为2个字节为16位,即
pow(2,16)-1=65536)。第二个部分是NULL标志位,该位指示了该行数据中是否有NULL值,1个字节表示;该部分所占的字节应该为bytes;接下去的部分是为记录头信息(record header),固定占用5个字节(40位),每位的含义如下 -
预留位1 1(bit位) 没有使用
-
预留位2 1 没有使用
-
delete_mask 1 标记该记录是否被删除
-
min_rec_mask 1 标记该记录是否为B+树的非叶子节点中的最小记录
-
n_owned 4 表示当前槽管理的记录数
-
heap_no 13 表示当前记录在记录堆的位置信息
-
record_type 3 表示当前记录的类型,0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录
-
next_record 16 表示下一条记录的相对位置
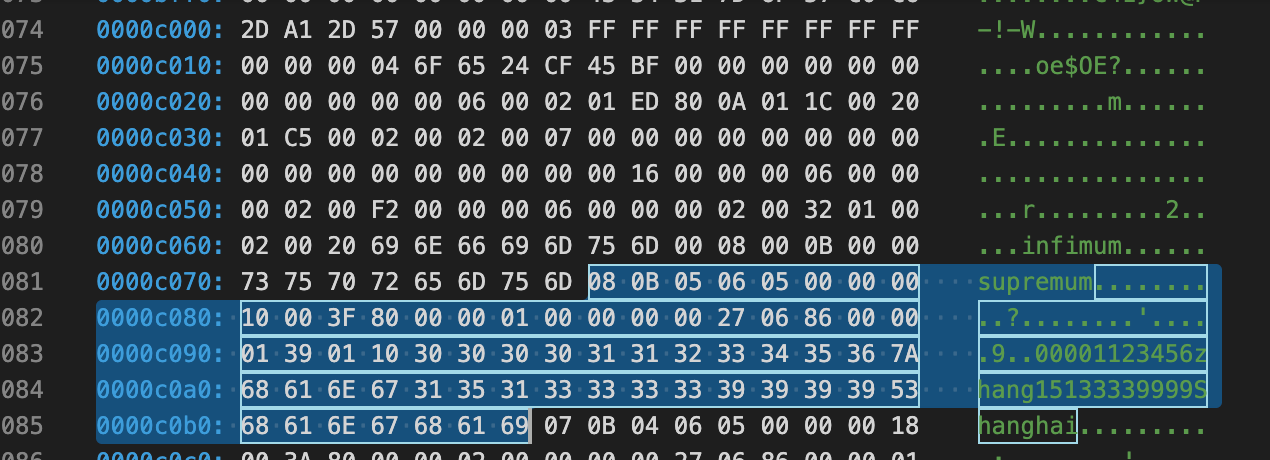
File Tailer(最后8字节)
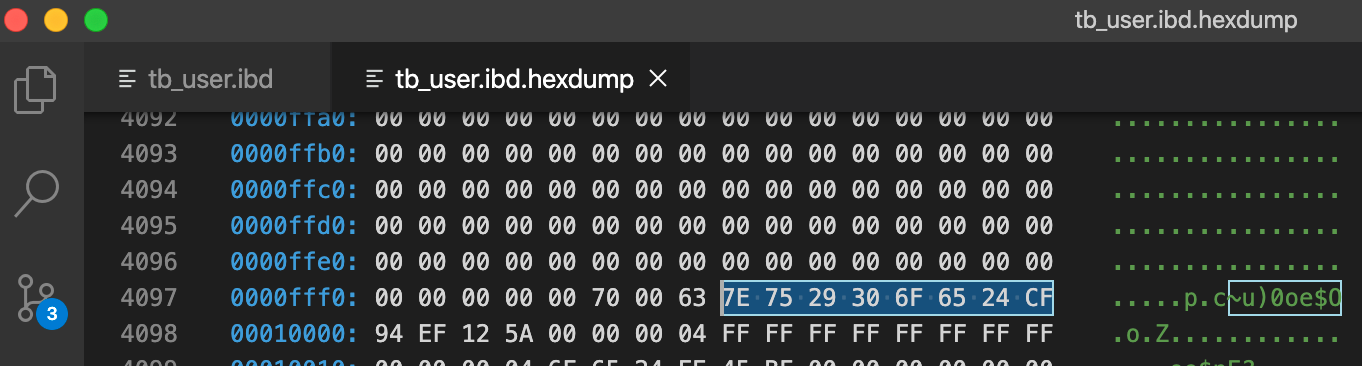
7E 75 29 30 6F 65 24 CF
注意到File Header该页最后被修改的LSN:00 00 00 04 6F 65 24 CF,可以看到后4个字节和File Tailer的后4个字节相同
附:二进制文件查看小技巧
- 使用python可以方便的进行二进制相关的转换
- hex(16) # 10进制转16进制
- oct(8) # 10进制转8进制
- bin(8) # 10进制转2进制
>>> hex(6 * 16 * 1024)
'0x18000'
>>> hex(3 * 16 * 1024)
'0xc000'
>>>
- vscode可以安装
hexdump for VSCode插件
页分裂/页合并
innodb-page-merging-and-page-splitting
InnoDB不是按行的来操作的,它可操作的最小粒度是页,页加载进内存后才会通过扫描页来获取行/记录,curd操作则会产生页合并,页分裂操作。
innodb数据的存储
在 InnoDB 存储引擎中,所有的数据都被逻辑地存放在表空间中,表空间(tablespace)是存储引擎中最高的存储逻辑单位,在表空间的下面又包括段(segment)、区(extent)、页(page), 页中存放实际的数据记录行
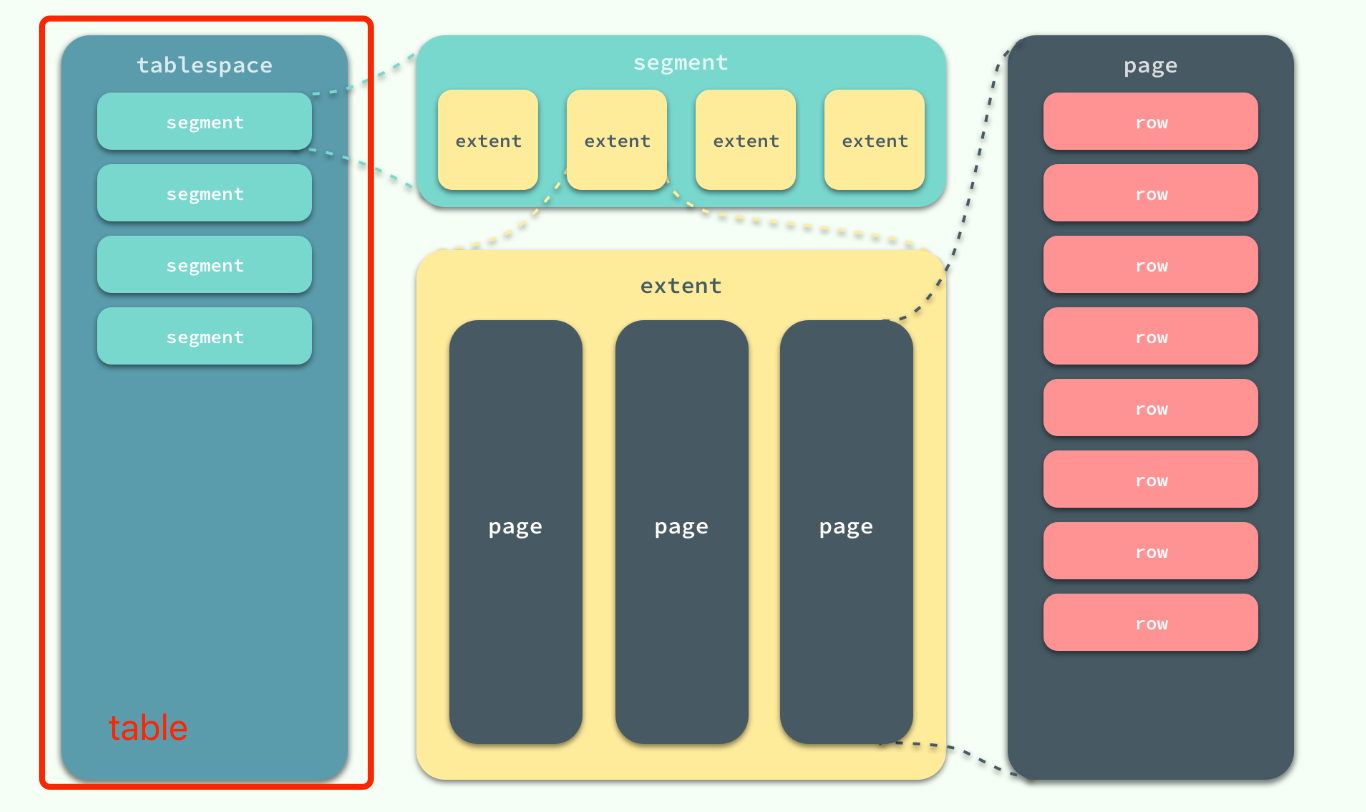
MySQL 使用 InnoDB 存储表时,会将表的定义和数据相关记录、索引等信息分开存储,其中前者存储在.frm文件中,后者存储在.ibd文件中(ibd文件既存储了数据也存储了索引)
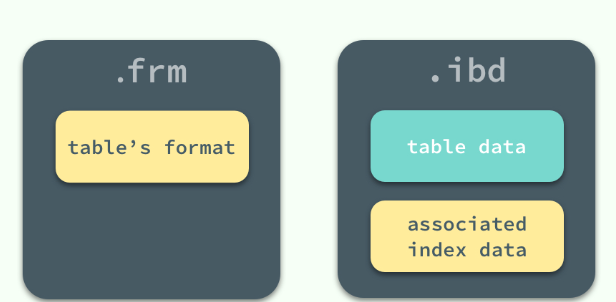
在创建表时,会在磁盘上的 datadir 文件夹中生成一个 .frm 的文件,这个文件中包含了表结构相关的信息
页合并
删除记录时会设置record的flaged标记为删除,当一页中删除记录超过MERGE_THRESHOLD(默认页体积的50%)时,InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。例如:合并操作使得页#5保留它之前的数据,并且容纳来自页#6的数据。页#6变成一个空页,可以接纳新数据。
页分裂
页可能填充至100%,在页填满了之后,下一页会继续接管新的记录。但如果下一页也没有足够空间去容纳新(或更新)的记录,那么就必须创建新的页了,如下
- 创建新页
- 判断当前页(页#10)可以从哪里进行分裂(记录行层面)
- 移动记录行
- 重新定义页之间的关系
#9 #10 #11 #12 #13 ...#8 #10 #14 #11 #12 #13 ...
如上,页#10没有足够空间去容纳新记录,页#11也同样满了, #10要分列为两列, 且页的前后指针关系要发生改变
附加:mysql频繁的插入删除导致的问题
1. 性能下降
频繁的插入和删除操作会增加数据库的工作量,特别是在高并发环境下,可能导致查询响应时间变长。
解决方案:
优化查询:确保你的查询是有效且高效的,使用适当的索引。
批量操作:尽可能使用批量插入(INSERT INTO … VALUES (), (), …)和批量删除(DELETE FROM WHERE id IN (…)) 而不是单条记录操作。
分区表:对于非常大的表,考虑使用分区表,这可以改善查询性能和减少单个表的维护负担。
2. 碎片化
频繁的插入和删除操作会导致数据文件和索引文件碎片化,这会降低查询效率。
解决方案:
定期重建索引:使用OPTIMIZE TABLE命令来重建表的索引,这可以帮助减少碎片。
归档旧数据:定期归档旧数据到另一个表或数据库中,减少主表的负担。
3. 锁定和阻塞
在高并发环境下,频繁的插入和删除操作可能导致行级锁或表级锁,从而引起阻塞和死锁。
解决方案:
减少锁的粒度:考虑使用较低级别的隔离级别(如READ COMMITTED),或者使用乐观锁策略。
锁优化:分析并优化事务的设计,确保事务尽可能短,避免长事务。
使用锁定的最小范围:尽可能在WHERE子句中指定具体的条件来减少锁定的范围。
4. 日志文件增长
频繁的写入操作会增加二进制日志(如binlog)和重做日志(如InnoDB的redo log)的大小,这可能会影响磁盘I/O性能。
解决方案:
配置合适的日志文件大小:调整max_binlog_size或innodb_log_file_size参数以控制日志文件的大小。
定期清理日志文件:使用PURGE BINARY LOGS命令来删除旧的二进制日志文件。
5. 资源竞争
在高负载情况下,频繁的插入和删除可能会增加CPU和内存的使用率,尤其是在多核服务器上。
解决方案:
硬件升级:如果可能,增加服务器的CPU核心数或内存容量。
负载均衡:使用数据库复制或分片策略来分散负载。
监控和调优:定期监控数据库性能,根据需要调整配置。
相关文章:
mysql 页的理解和实际分析
目录 页(Page)是 Innodb 存储引擎用于管理数据的最小磁盘单位B树的一般高度记录在页中的存储 innodb ibd文件innodb 页类型分析ibd文件查看数据表的行格式查看ibd文件 分析 ibd的第4个页:B-tree Node类型先分析File Header(38字节-描述页信息…...

分享一道力扣
刚刚笔试遇到的。好像很简单,但又不容易写的 611 有效三角形 def triangleNumber(self, nums):count 0nums.sort()for i in range(len(nums) - 2):k i 2for j in range(i 1, len(nums) - 1):if nums[i] 0:breakwhile k < len(nums) and nums[i] nums[j] &g…...

青少年编程与数学 01-011 系统软件简介 06 Android操作系统
青少年编程与数学 01-011 系统软件简介 06 Android操作系统 一、历史发展二、核心架构1. Linux 内核层 (Linux Kernel)2. 硬件抽象层 (Hardware Abstraction Layer - HAL)3. Native 层 (Native Libraries & Android Runtime)4. Java API 框架层 (Java Framework Layer)5. 应…...

构建 MCP 服务器:第 2 部分 — 使用资源模板扩展资源
该图像是使用 AI 图像创建程序创建的。 这个故事是在多位人工智能助手的帮助下写成的。 这是构建MCP 服务器教程(共四部分)的第二部分。在第一部分中,我们使用基本资源创建了第一个 MCP 服务器。现在,我们将使用资源模板扩展服务…...
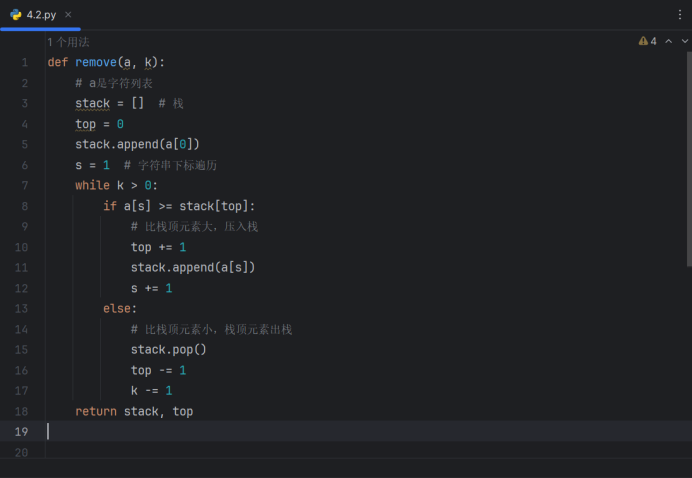
【算法设计与分析】实验——汽车加油问题, 删数问题(算法实现:代码,测试用例,结果分析,算法思路分析,总结)
说明:博主是大学生,有一门课是算法设计与分析,这是博主记录课程实验报告的内容,题目是老师给的,其他内容和代码均为原创,可以参考学习,转载和搬运需评论吱声并注明出处哦。 4-1算法实现题 汽车…...

Ubuntu2404 下搭建 Zephyr 开发环境
1. 系统要求 操作系统:Ubuntu2404(64位)磁盘空间:至少 8GB 可用空间(Zephyr 及其工具链较大) 2. 安装必要工具 Tool Min. Version CMake 3.20.5 Python 3.10 Devicetree compiler 1.4.6 2.1 安装系…...
:基本数据类型扩展)
现代C++特性(一):基本数据类型扩展
文章目录 基础数据类型long long (C 11)numeric_limits()获取当前数据类型的最值warning C4309: “”: 截断常量值新字符类型char16_t和char32_tWindows编程常用字符类型wchar_tchar8_t (C 20) 基础数据类型 C中的基本类型是构建其他数据类型的基础,常见的基础类型…...

【C++进阶篇】C++11新特性(下篇)
C函数式编程黑魔法:Lambda与包装器实战全解析 一. lambda表达式1.1 仿函数使用1.2 lambda表达式的语法1.3 lambda表达式使用1.3.1 传值和传引用捕捉1.3.2 隐式捕捉1.3.3 混合捕捉 1.4 lambda表达式原理1.5 lambda优点及建议 二. 包装器2.1 function2.2 bind绑定 三.…...
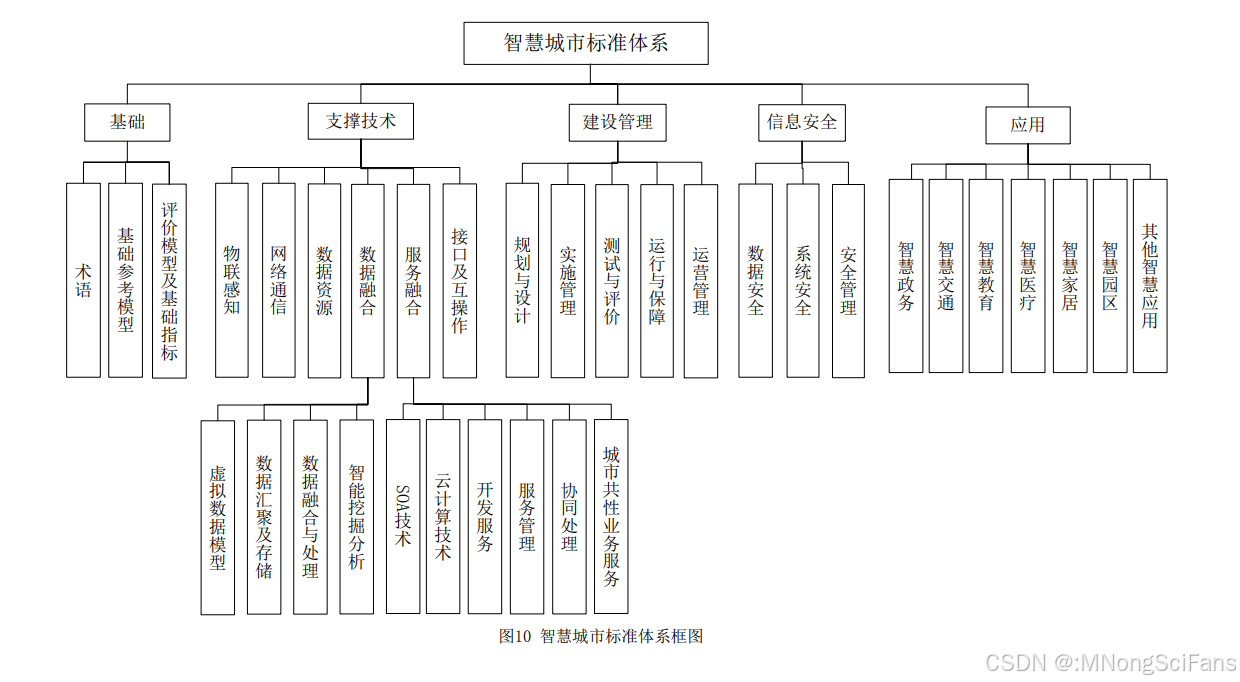
全生命周期的智慧城市管理
前言 全生命周期的智慧城市管理。未来,城市将在 实现从基础设施建设、日常运营到数据管理的 全生命周期统筹。这将避免过去智慧城市建设 中出现的“碎片化”问题,实现资源的高效配 置和项目的协调发展。城市管理者将运用先进 的信息技术,如物…...

echarts柱状图实现动态展示时报错
echarts柱状图实现动态展示时报错 1、问题: 在使用Echarts柱状图时,当数据量过多,x轴展示不下的时候,可以使用dataZoom实现动态展示。如下图所示: 但是当鼠标放在图上面滚动滚轮时或拖动滚动条时会报错,…...

Redis故障转移
概述 本文主要讲述了Redis故障转移的原理及过程,可与「Redis高可用架构」文章一同阅读,可更好理解相关内容,及整个Redis高可用架构的实现原理。 Leader 选举 哨兵首先进入 WATI_START 状态进行准备,等待哨兵成为哨兵集群的 Leade…...
原理与应用(详解篇))
STM32学习笔记:定时器(TIM)原理与应用(详解篇)
前言 定时器是STM32微控制器中最重要且最常用的外设之一,它不仅能提供精确的定时功能,还能实现PWM输出、输入捕获、编码器接口等多种功能。本文将全面介绍STM32的通用定时器,包括其工作原理、配置方法和典型应用。 一、STM32定时器概述 定…...

JAVA获取ES连接并查询所有数据
我们的项目要获取es连接,新版本和旧版本有不小的区别,在8.17.0版本使用的是 ElasticsearchClient <dependency><groupId>co.elastic.clients</groupId><artifactId>elasticsearch-java</artifactId><version>8.17…...

408第一季 - 数据结构 - 线性表
只能用C/C! 顺序表 闲聊 线性表的逻辑顺序和物理顺序相同 都是1234 顺序表的优点: 随机访问,随机访问的意思是访问的时间 和位置没有关系,访问下标1和100一样的,更深层就是直接计算 a100 * 数组大小,随便…...
第23讲、Odoo18 邮件系统整体架构
目录 Odoo 邮件系统整体架构邮件发送方式邮件模板配置SMTP 邮件服务器配置邮件发送过程开发中常见邮件发送需求常见问题排查提示与最佳实践完整示例:审批通过自动发邮件门户表单自动邮件通知案例邮件队列与异步发送邮件添加附件邮件日志与调试多语言邮件模板邮件安…...
)
【QT面试题】(三)
文章目录 Qt信号槽的优点及缺点Qt中的文件流和数据流区别?Qt中show和exec区别QT多线程使用的方法 (4种)QString与基本数据类型如何转换?QT保证多线程安全事件与信号的区别connect函数的连接方式?信号与槽的多种用法Qt的事件过滤器有哪些同步和…...

DeepSeek09-open-webui使用
Open WebUI 完全指南:从安装到知识库搭建与异常处理 最后更新:2025年6月7日 | 适用版本:Open WebUI v0.6.x 一、安装部署 1.1 系统要求 **Python 3.12 **(严格版本要求,更高版本3.13不兼容)Node.js 20.x内…...
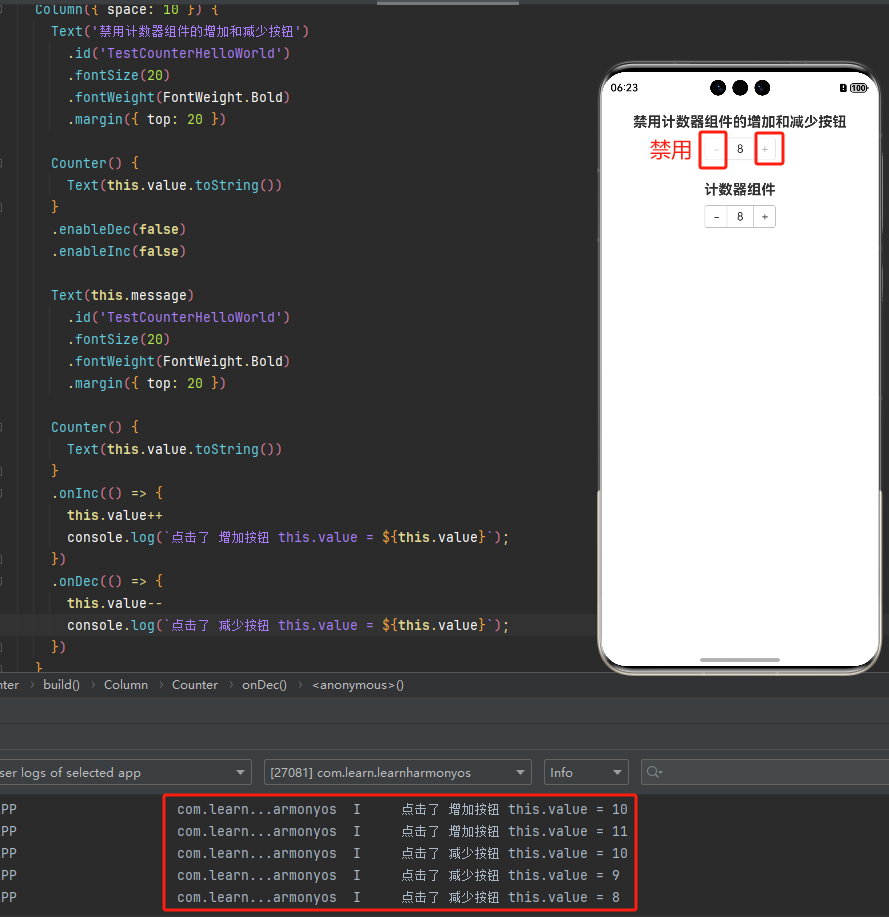
HarmonyOS:Counter计数器组件
一、概述 计数器组件,提供相应的增加或者减少的计数操作。 说明 该组件从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 二、属性 除支持通用属性外,还支持以下属性。 enableInc enableInc(value: b…...

数据类型 -- 字符
在C中,字符型(char)用于存储单个字符,如字母、数字、符号等。字符型是最基本的数据类型之一,常用于处理文本、字符数组(字符串)等场景。 1. 基本类型 • char:标准字符类型&#x…...

WordZero:让Markdown与Word文档自由转换的Golang利器
在日常工作中,我们经常需要在Markdown和Word文档之间进行转换。Markdown方便编写和版本控制,而Word文档更适合正式的商务环境。作为一名Golang开发者,我开发了WordZero这个库,专门解决这个痛点。 项目背景 GitHub仓库࿱…...
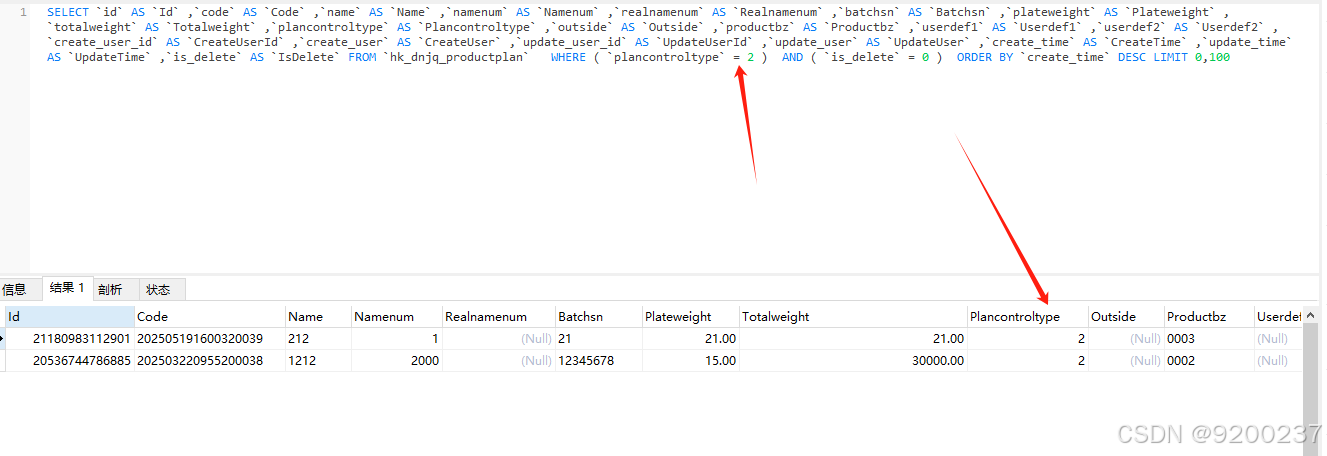
sqlsugar WhereIF条件的大于等于和等于查出来的坑
一、如下图所示,当我用 .WhereIF(input.Plancontroltype > 0, u > u.Plancontroltype (DnjqPlancontroltype)input.Plancontroltype) 这里面用等于的时候,返回结果一条数据都没有。 上图中生成的SQL如下: SELECT id AS Id ,code AS …...

Pandas 技术解析:从数据结构到应用场景的深度探索
序 我最早用Python做大数据项目时,接触最早的就是Pandas了。觉得对于IT技术人员而言,它是可以属于多场景的存在,因为它的本身就是数据驱动的技术生态中,对于软件工程师而言,它是快速构建数据处理管道的基石࿱…...

数据库系统概论(十七)超详细讲解数据库规范化与五大范式(从函数依赖到多值依赖,再到五大范式,附带例题,表格,知识图谱对比带你一步步掌握)
数据库系统概论(十七)超详细讲解数据库规范化与五大范式(从函数依赖到多值依赖,再到五大范式,附带例题,表格,知识图谱对比带你一步步掌握) 前言一、为什么需要规范化1. 我们先想一个…...

[c#]判定当前软件是否用管理员权限打开
有时一些软件的逻辑中需要使用管理员权限对某些文件进行修改时,那么该软件在执行或者打开的场合,就需要用使用管理员身份运行才能达到效果。那么在c#里,如何判定该软件是否是对管理员身份运的呢? 1.取得当前的windows用户。 2.取得…...

并发编程实战(生产者消费者模型)
在并发编程中使用生产者和消费者模式能够解决绝大多数的并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序整体处理数据的速度。 生产者和消费者模式: 在线程的世界中生产者就是产生数据的线程,而消费者则是消费数据的线程。在多线程开…...

分布式微服务系统架构第144集:FastAPI全栈开发教育系统
加群联系作者vx:xiaoda0423 仓库地址:https://webvueblog.github.io/JavaPlusDoc/ https://1024bat.cn/ https://github.com/webVueBlog/fastapi_plus https://webvueblog.github.io/JavaPlusDoc/ 使用docker搭建常用开发环境 docker安装mysql docker ru…...

el-tabs 切换时数据不更新的问题
最近业务需求,需要在页面中使用tabs,使用过程中出现tabs切换,数据不更新的问题,以下是思路和解决办法。 Vue 会追踪你在模板中绑定的数据,并在数据发生变化时重新渲染相应的部分。但在使用 el-tabs 时,有时…...
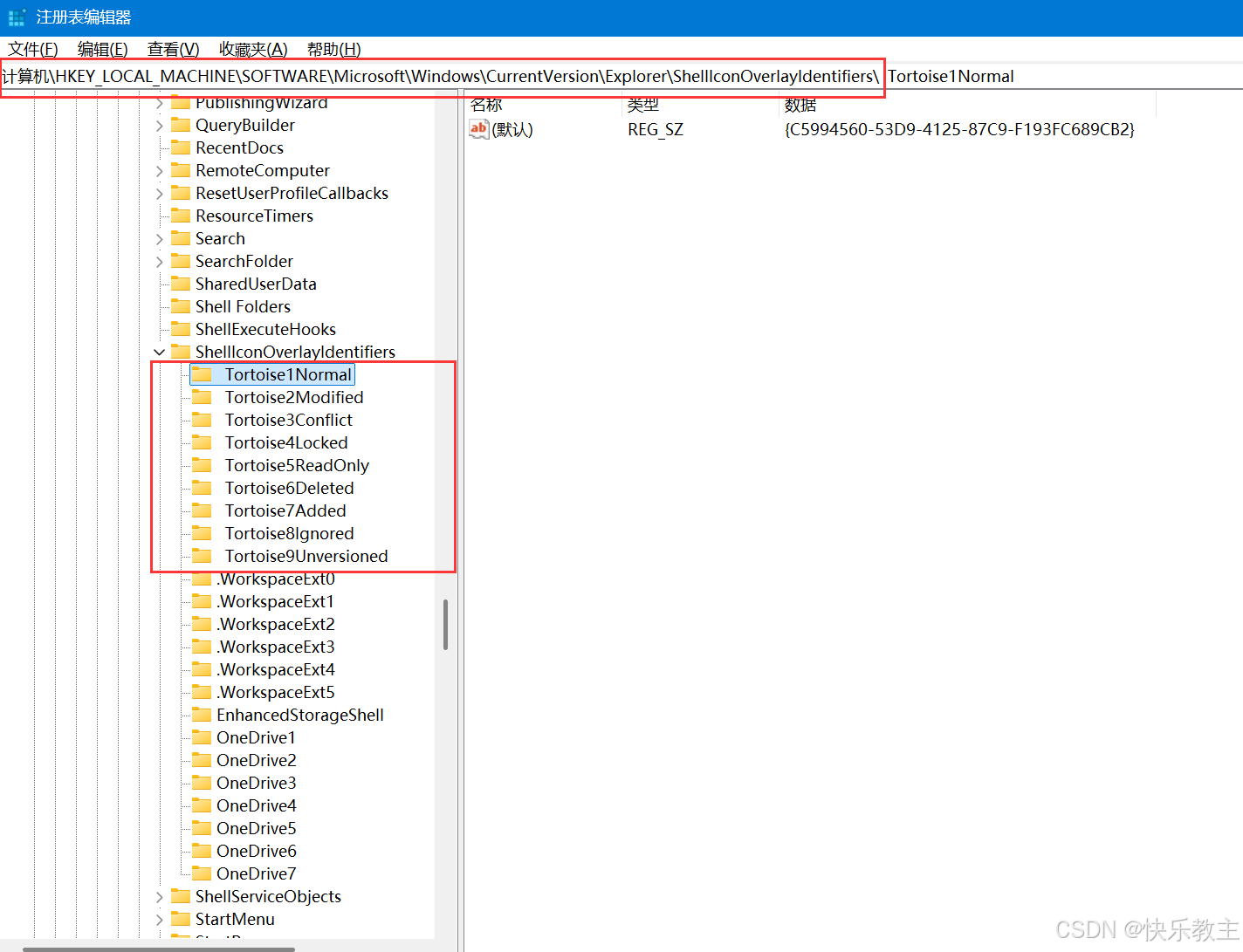
git小乌龟不显示图标状态解决方案
第一步 在开始菜单的搜索处,输入regedit命令,打开注册表。 第二步 在注册表编辑器中,找到HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\ShellIconOverlayIdentifiers 这一项。 第三步 让Tortoise相关的项目排在前…...
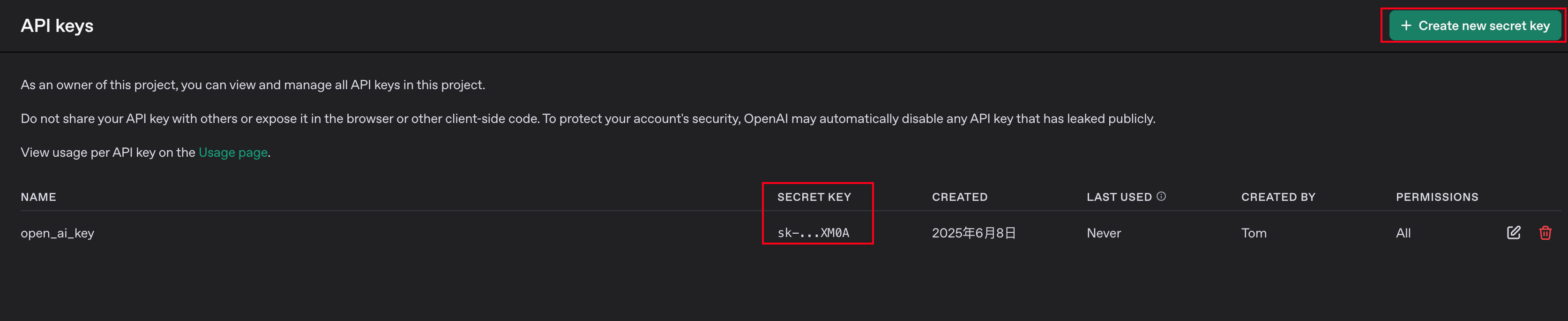
获取 OpenAI API Key
你可以按照以下步骤来获取 openai.api_key,用于调用 OpenAI 的 GPT-4、DALLE、Whisper 等 API 服务: 🧭 获取 OpenAI API Key 的步骤: ✅ 1. 注册或登录 OpenAI 账号 打开 https://platform.openai.com/ 使用你的邮箱或 Google/…...

【Android基础回顾】五:AMS(Activity Manager Service)
Android 的 AMS(Activity Manager Service)是 Android 系统中的核心服务之一,负责管理整个应用生命周期、任务栈、进程和四大组件(Activity、Service、BroadcastReceiver、ContentProvider)的运行。它运行在系统进程 s…...