Kafka 消息模式实战:从简单队列到流处理(二)
四、Kafka 流处理实战
4.1 Kafka Streams 简介
Kafka Streams 是 Kafka 提供的流处理库,它为开发者提供了一套简洁而强大的 API,用于构建实时流处理应用程序。Kafka Streams 基于 Kafka 的高吞吐量、分布式和容错特性,能够处理大规模的实时数据流,并提供低延迟的处理能力。
Kafka Streams 的设计理念是将流处理逻辑简化为一系列的操作,开发者可以使用类似于 SQL 的语法来定义这些操作,从而实现复杂的流处理任务。它支持有状态和无状态的处理,并且能够自动管理分布式环境下的状态存储和故障恢复。
4.2 流处理拓扑(Topology)
流处理拓扑定义了流处理的逻辑和流程,它是一个有向无环图(DAG),由数据源(Source)、处理器(Processor)和接收器(Sink)组成。
- 数据源:数据源是拓扑的起点,它从 Kafka 主题中读取数据,并将数据发送给下游的处理器。数据源可以是一个或多个 Kafka 主题。
- 处理器:处理器是拓扑的核心组件,它对输入的数据进行处理和转换。处理器可以执行各种操作,如过滤、映射、聚合、连接等。一个拓扑中可以包含多个处理器,它们按照顺序依次对数据进行处理。
- 接收器:接收器是拓扑的终点,它将处理后的结果数据发送到 Kafka 主题或其他外部系统中。接收器可以是一个或多个 Kafka 主题,也可以是其他类型的输出目标,如文件系统、数据库等。
4.3 单词计数示例
下面我们通过一个 Java 代码示例,展示如何使用 Kafka Streams 实现单词计数功能。在这个示例中,我们从一个 Kafka 主题读取文本数据,对每个单词进行计数,并将结果输出到另一个 Kafka 主题。
首先,在 Maven 项目的pom.xml文件中添加 Kafka Streams 依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>3.5.1</version>
</dependency>
接下来,编写实现单词计数功能的代码:
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import java.util.Arrays;
import java.util.Properties;
public class WordCountExample {
public static void main(String[] args) {
// 配置Kafka Streams应用
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "word-count-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// 构建流处理拓扑
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("input-topic");
KTable<String, Long> wordCounts = source
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.filter((key, word) ->!word.isEmpty())
.groupBy((key, word) -> word)
.count();
wordCounts.toStream().to("output-topic",
org.apache.kafka.streams.kstream.Produced.with(Serdes.String(), Serdes.Long()));
// 创建并启动Kafka Streams实例
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
// 添加关闭钩子,在程序终止时优雅地关闭Kafka Streams
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
}
在上述代码中:
- 首先配置了 Kafka Streams 应用的基本属性,包括应用 ID、Kafka 集群地址以及默认的键和值序列化器。
- 然后使用StreamsBuilder构建流处理拓扑。从input-topic主题读取数据,将每行文本拆分成单词,过滤掉空单词,按单词分组并计数。
- 最后将计数结果转换为流,并输出到output-topic主题。
- 创建并启动KafkaStreams实例,并添加关闭钩子,确保程序在终止时能够优雅地关闭 Kafka Streams。
4.4 高级功能
Kafka Streams 提供了许多高级功能,使其能够满足复杂的实时流处理需求。
窗口操作:窗口操作允许在特定的时间范围内对流数据进行聚合和计算。Kafka Streams 支持固定窗口(Tumbling Window)、滑动窗口(Hopping Window)和会话窗口(Session Window)。例如,使用固定窗口计算每 5 分钟内的订单数量:
KTable<Windowed<String>, Long> windowedCounts = source
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.count();
连接操作:连接操作可以将多个流或表的数据进行合并。Kafka Streams 支持内连接(Inner Join)、左连接(Left Join)和外连接(Outer Join)。例如,将用户信息表和订单流进行连接,获取每个订单对应的用户信息:
KTable<String, User> userTable = builder.table("user-topic");
KStream<String, Order> orderStream = builder.stream("order-topic");
KStream<String, OrderWithUser> joinedStream = orderStream.join(userTable,
(order, user) -> new OrderWithUser(order, user));
状态存储:Kafka Streams 支持有状态处理,能够在处理过程中保存中间状态。状态存储可以保存在内存中或使用 RocksDB 持久化存储。例如,在单词计数示例中,count操作会将计数结果存储在状态存储中,以便后续查询和更新:
KTable<String, Long> wordCounts = source
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.filter((key, word) ->!word.isEmpty())
.groupBy((key, word) -> word)
.count(Materialized.as("word-count-store"));
容错处理:Kafka Streams 内置了容错机制,能够自动处理数据丢失、节点故障等问题,保证数据处理的一致性和完整性。它会将应用程序的状态保存到 Kafka 中,以便在发生故障时恢复状态。当某个 Kafka Streams 实例发生故障时,其他实例可以接管其工作,继续处理数据,确保流处理任务的连续性。
五、总结与展望
在本次 Kafka 消息模式的探索之旅中,我们从简单队列起步,逐步深入到流处理的复杂领域,全面领略了 Kafka 作为强大分布式消息系统的魅力与实力。
在简单队列场景中,Kafka 展现了其作为消息队列的基础能力。通过搭建 Kafka 和 Zookeeper 环境,我们顺利创建主题,实现了生产者与消费者之间的消息传递。生产者可以灵活地选择同步或异步方式发送消息,消费者则通过自动或手动提交偏移量来确保消息的可靠消费。这种简单而高效的消息队列模式,在许多应用场景中发挥了关键作用,如解耦系统组件、实现异步通信以及流量控制等,为构建稳定、可扩展的应用架构提供了有力支持。
而当我们踏入 Kafka 流处理的世界,更是发现了其无限的潜力。Kafka Streams 提供了一套简洁而强大的 API,使我们能够轻松构建实时流处理应用。通过单词计数示例,我们看到了如何从 Kafka 主题读取数据,对数据进行处理和转换,并将结果输出到其他主题。窗口操作、连接操作、状态存储以及容错处理等高级功能,进一步拓展了 Kafka 流处理的应用范围,使其能够应对各种复杂的实时数据处理需求,如实时监控、实时推荐、欺诈检测等。
展望未来,Kafka 在大数据和实时处理领域的发展前景一片光明。随着技术的不断进步,Kafka 有望在以下几个方面取得更大的突破:
- 流处理能力持续增强:Kafka Streams 和 KSQL 将不断进化,提供更强大的功能和更高的性能。未来,它们可能会支持更多复杂的流处理任务,以及更多 SQL 特性,使开发者能够更加便捷地处理实时数据流。
- 云原生支持不断深化:随着 Kubernetes 等云原生技术的普及,Kafka 将更好地融入云原生环境。未来,Kafka 在 Kubernetes 上的部署和管理将变得更加简单,资源利用将更加高效,弹性扩展能力也将进一步增强,为企业在云端构建实时数据处理平台提供更优质的解决方案。
- 多租户支持更加完善:为了满足多租户环境下的应用需求,Kafka 将进一步增强其安全性和隔离性。通过更细粒度的访问控制和配额管理,Kafka 将确保不同租户之间的数据和资源得到有效隔离,同时提供更好的审计和监控功能,保障多租户环境的稳定运行。
- 运维和监控工具不断优化:Kafka 将持续提升其运维和监控工具的能力,增强 Kafka Manager、Confluent Control Center 等工具的功能,并与 Prometheus、Grafana 等主流监控系统实现更好的集成,为用户提供更全面、更实时的监控和报警机制,降低 Kafka 集群的运维成本。
- 存储引擎持续演进:分层存储(Tiered Storage)等新技术的应用,将使 Kafka 能够将数据分层存储到不同的存储介质上,从而降低存储成本并提高存储效率。未来,Kafka 的存储引擎可能会进一步优化,以适应不断增长的数据量和多样化的存储需求。
- 性能和可靠性进一步提升:Kafka 社区正在考虑引入 Raft 协议来替代目前的 ZooKeeper 协议,这将有望简化 Kafka 的部署和管理,并提供更高的可用性和一致性保障。此外,Kafka 还可能在数据处理速度、容错能力等方面进行优化,以满足对性能和可靠性要求极高的应用场景。
- 智能数据路由和处理成为趋势:借助机器学习和人工智能技术,Kafka 未来可能会实现智能数据路由和处理。通过动态调整数据路由策略,Kafka 能够更高效地处理和分发数据,提高整个系统的性能和效率,为用户提供更加智能化的实时数据处理服务。
Kafka 作为大数据和实时处理领域的重要工具,将继续引领技术发展的潮流。无论是在简单队列场景还是复杂的流处理应用中,Kafka 都将发挥不可替代的作用,为企业的数字化转型和创新发展提供强大的技术支持。
相关文章:
)
Kafka 消息模式实战:从简单队列到流处理(二)
四、Kafka 流处理实战 4.1 Kafka Streams 简介 Kafka Streams 是 Kafka 提供的流处理库,它为开发者提供了一套简洁而强大的 API,用于构建实时流处理应用程序。Kafka Streams 基于 Kafka 的高吞吐量、分布式和容错特性,能够处理大规模的实时…...
 大数据处理架构Hadoop)
大数据(2) 大数据处理架构Hadoop
一、Hadoop简介 1.定义 Hadoop 是一个开源的分布式计算框架,由 Apache 基金会开发,用于处理海量数据,具备高可靠性、高扩展性和高容错性。它主要由两个核心模块组成: HDFS(Hadoop Distributed File System)…...

【Kotlin】注解反射扩展
文章目录 注解用法反射类引用 扩展扩展函数的作用域成员方法优先级总高于扩展函数 被滥用的扩展函数扩展属性静态扩展 标准库中的扩展函数 使用 T.also 函数交换两个变量sNullOrEmpty | isNullOrBlankwith函数repeat函数 调度方式对扩展函数的影响静态与动态调度扩展函数始终静…...
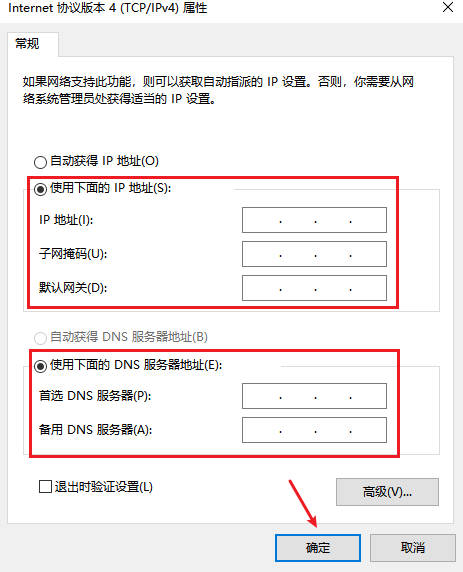
固定ip和非固定ip的区别是什么?如何固定ip地址
在互联网中,我们常会接触到固定IP和非固定IP的概念。它们究竟有何不同?如何固定IP地址?让我们一起来探究这个问题。 一、固定IP和非固定IP的区别是什么 固定IP(静态IP)和非固定IP(动态IP)是两种…...

升级centos 7.9内核到 5.4.x
前面是指南,后面是工作日志。 wget http://mirrors.coreix.net/elrepo-archive-archive/kernel/el7/x86_64/RPMS/kernel-lt-devel-5.4.225-1.el7.elrepo.x86_64.rpm wget http://mirrors.coreix.net/elrepo-archive-archive/kernel/el7/x86_64/RPMS/kernel-lt-5.4.2…...

Nginx 安全设置配置
1、增加header公共文件 文件地址:/etc/nginx/conf.d/security_headers.conf # XSS防护配置add_header X-XSS-Protection "1; modeblock" always; # 其他安全配置add_header X-Content-Type-Options "nosniff";add_header X-Frame-Options &qu…...

协程的常用阻塞函数
以下是一些常见的阻塞函数示例: 1. **Thread.sleep()** 阻塞当前线程一段时间。 kotlin Thread.sleep(1000) // 阻塞线程 1 秒 2. **InputStream.read()** 从输入流中读取数据时会阻塞,直到有数据可用或流结束。 kotlin val inputStream FileInputStre…...

探索NoSQL注入的奥秘:如何消除MongoDB查询中的前置与后置条件
随着互联网技术的飞速发展,数据库作为信息存储与管理的核心,其安全性问题日益凸显。近年来,NoSQL数据库因其灵活性和高性能逐渐成为许多企业的首选,其中MongoDB以其文档存储和JSON-like查询语言在开发社区中广受欢迎。然而&#x…...
使用矩阵乘法+线段树解决区间历史和问题的一种通用解法
文章目录 前言P8868 [NOIP2022] 比赛CF1824DP9990/2020 ICPC EcFinal G 前言 一般解决普通的区间历史和,只需要定义辅助 c h s − t ⋅ a chs-t\cdot a chs−t⋅a, h s hs hs是历史和, a a a是区间和, t t t是时间戳,…...

React Navive初识
文章目录 搭建开发环境安装 Node、homebrew、Watchman安装 Node安装 homebrew安装 watchman 安装 React Native 的命令行工具(react-native-cli)创建新项目编译并运行 React Native 应用在 ios 模拟器上运行 调试访问 App 内的开发菜单 搭建开发环境 在…...
中 的使用说明)
scss(sass)中 的使用说明
在 SCSS(Sass)中,& 符号是一个父选择器引用,它代表当前嵌套规则的外层选择器。主要用途如下: 1. 连接伪类/伪元素 scss 复制 下载 .button {background: blue;&:hover { // 相当于 .button:hoverbackgrou…...
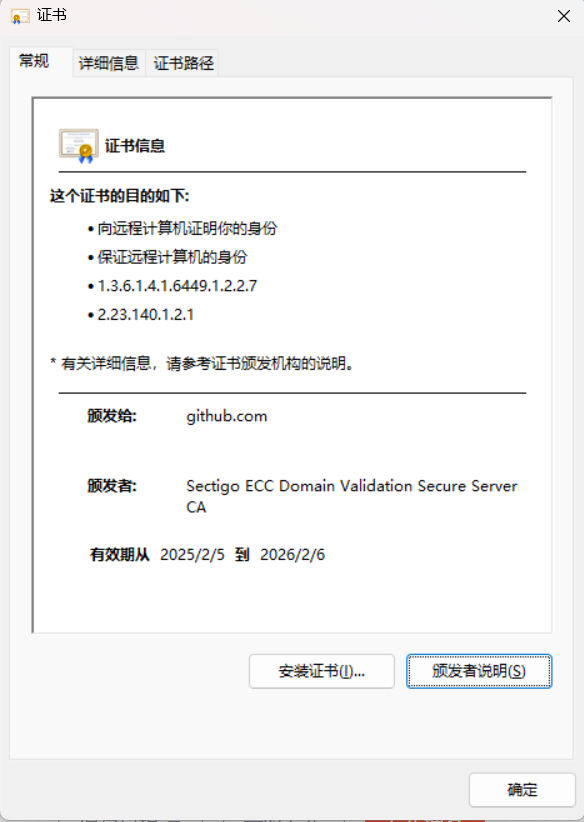
如何从浏览器中导出网站证书
以导出 GitHub 证书为例,点击 小锁 点击 导出 注意:这里需要根据你想要证书格式手动加上后缀名,我的是加 .crt 双击文件打开...

低功耗MQTT物联网架构Java实现揭秘
文章目录 一、引言二、相关技术概述2.1 物联网概述2.2 MQTT协议java三、基于MQTT的Iot物联网架构设计3.1 架构总体设计3.2 MQTT代理服务器选择3.3 物联网设备设计3.4 应用服务器设计四、基于MQTT的Iot物联网架构的Java实现4.1 开发环境搭建4.2 MQTT客户端实现4.3 应用服务器实现…...

总结HTML中的文本标签
总结HTML中的文本标签 文章目录 总结HTML中的文本标签引言一、标题标签(h1 - h6)语法示例使用建议 二、段落标签(p)语法示例使用建议 三、文本节点标签(span)语法示例使用建议 四、粗体标签(b&a…...

python版若依框架开发:前端开发规范
python版若依框架开发 从0起步,扬帆起航。 python版若依部署代码生成指南,迅速落地CURD!项目结构解析前端开发规范文章目录 python版若依框架开发新增 view新增 api新增组件新增样式引⼊依赖新增 view 在 @/views文件下 创建对应的文件夹,一般性一个路由对应⼀个文件, 该…...

AI推理服务的高可用架构设计
AI推理服务的高可用架构设计 在传统业务系统中,高可用架构主要关注服务冗余、数据库容灾、限流熔断等通用能力。而在AI系统中,尤其是大模型推理服务场景下,高可用架构面临更加复杂的挑战,如推理延迟敏感性、GPU资源稀缺性、模型版本切换频繁等问题。本节将专门探讨如何构建…...

GPU集群故障分析:大型AI训练中的硬件问题与影响
GPU集群故障分析:大型AI训练中的硬件问题与影响 核心问题 在大型AI计算集群(如使用上千块GPU卡训练大模型)中: GPU硬件会出哪些毛病?这些问题发生的频率、严重程度如何?最终对AI训练任务有什么影响&#…...
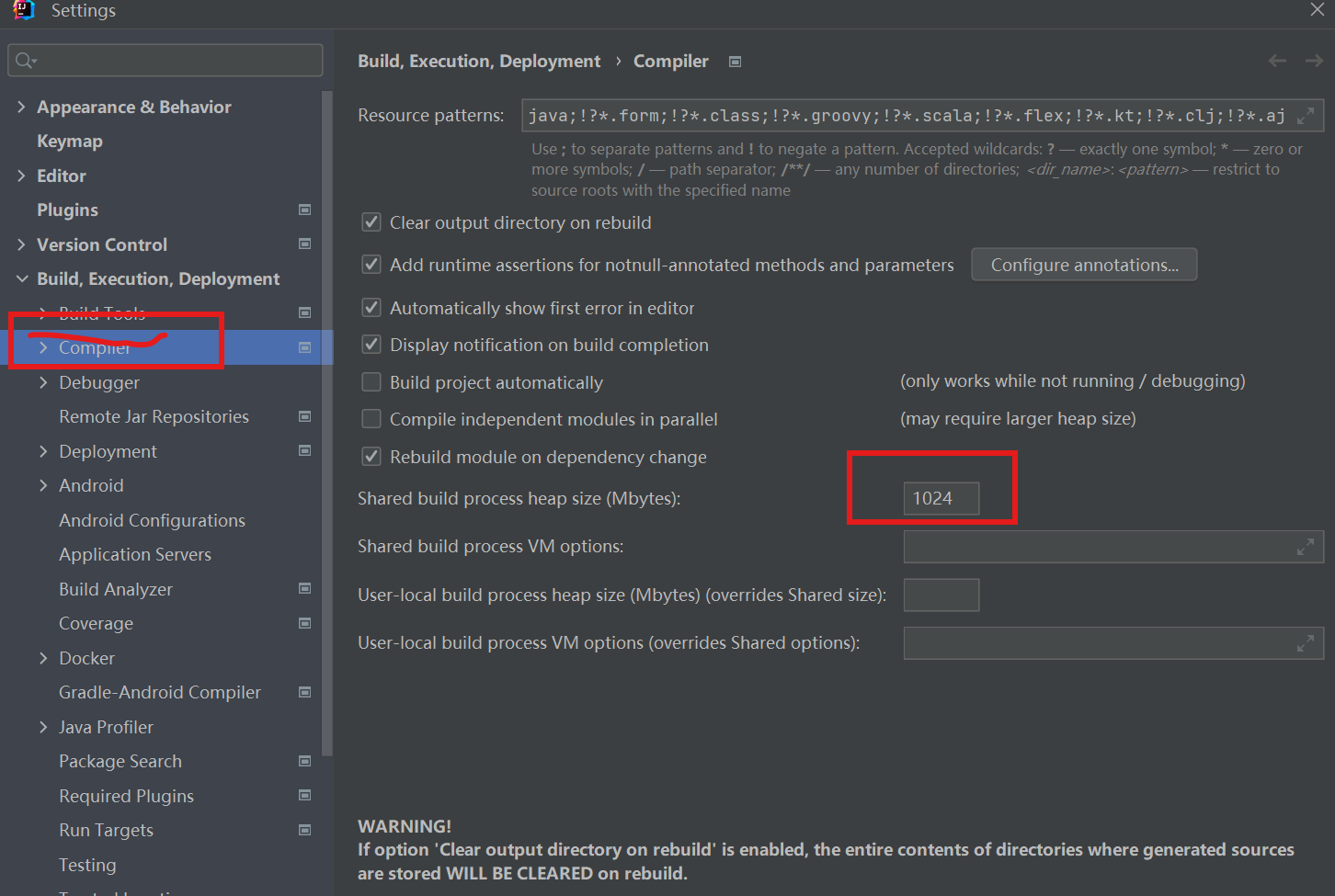
ideal2022.3.1版本编译项目报java: OutOfMemoryError: insufficient memory
最近换了新电脑,用新电脑拉项目配置后,启动时报错,错误描述 idea 启动Springboot项目在编译阶段报错:java: OutOfMemoryError: insufficient memory 2. 处理方案 修改VM参数,分配更多内存 ❌ 刚刚开始以为时JVM内存设置…...
centos7编译安装LNMP架构
一、LNMP概念 LNMP架构是一种常见的网站服务器架构,由Linux操作系统、Nginx Web服务器、MySQL数据库和PHP后端脚本语言组成。 1 用户请求:用户通过浏览器输入网址,请求发送到Nginx Web服务器。 2 Nginx处理:Nginx接收请求后&…...

接口限频算法:漏桶算法、令牌桶算法、滑动窗口算法
文章目录 限频三大算法对比与选型建议一、漏桶算法(Leaky Bucket Algorithm)1.核心原理2.实现3.为什么要限制漏桶容量4.优缺点分析 二、令牌桶算法(Token Bucket Algorithm)1.核心原理2.实现(1)单机实现&am…...

Spring Boot 3.3 + MyBatis 基础教程:从入门到实践
Spring Boot 3.3 MyBatis 基础教程:从入门到实践 在当今的Java开发领域,Spring Boot和MyBatis是构建高效、可维护的后端应用的两个强大工具。Spring Boot简化了Spring应用的初始搭建和开发过程,而MyBatis则提供了一种灵活的ORM(…...

征文投稿:如何写一份实用的技术文档?——以软件配置为例
📝 征文投稿:如何写一份实用的技术文档?——以软件配置为例 目录 [TOC](目录)🧭 技术文档是通往成功的“说明书”💡 一、明确目标读者:他们需要什么?📋 二、结构清晰:让读…...

【后端】RPC
不定期更新。 定义 RPC 是 Remote Procedure Call 的缩写,中文通常翻译为远程过程调用。作用 简化分布式系统开发。实现微服务架构,便于模块化、复用。提高系统性能和可伸缩性。提供高性能通信、负载均衡、容错重试机制。 在现代分布式系统、微服务架构…...

详细讲解Flutter GetX的使用
Flutter GetX 框架详解:状态管理、路由与依赖注入 GetX 是 Flutter 生态中一款强大且轻量级的全功能框架,集成了状态管理、路由管理和依赖注入三大核心功能。其设计理念是简洁高效,通过最小的代码实现最大的功能,特别适合快速开发…...

ReLU 新生:从死亡困境到强势回归
背景 在深度学习领域,激活函数的探索已成为独立研究课题。诸如 GELU、SELU 和 SiLU 等新型激活函数,因具备平滑梯度与出色的收敛特性,正备受关注。经典 ReLU 凭借简洁性、固有稀疏性及其独特优势拓扑特性,依旧受青睐。然而&#…...
tensorflow image_dataset_from_directory 训练数据集构建
以数据集 https://www.kaggle.com/datasets/vipoooool/new-plant-diseases-dataset 为例 目录结构 训练图像数据集要求: 主目录下包含多个子目录,每个子目录代表一个类别。每个子目录中存储属于该类别的图像文件。 例如 main_directory/ ...cat/ ...…...

QuickJS 如何发送一封邮件 ?
参阅:bellard.org : QuickJS 如何使用 qjs 执行 js 脚本 在 QuickJS 中发送邮件需要依赖外部库或调用系统命令,因为 QuickJS 本身不包含 SMTP 功能。以下是两种实现方法: 方法 1:调用系统命令(推荐) 使…...

clickhouse 和 influxdb 选型
以下是 ClickHouse、InfluxDB 和 HBase 在体系架构、存储引擎、数据类型、性能及场景的详细对比分析: 🏗️ 一、体系架构对比 维度ClickHouseInfluxDBHBase设计目标大规模OLAP分析,高吞吐复杂查询 时序数据采集与监控,优化时间线管理高吞吐随机…...
GOOUUU ESP32-S3-CAM 果云科技开发板开发指南(一)(超详细!)Vscode+espidf 通过摄像头拍摄照片并存取到SD卡中,文末附源码
看到最近好玩的开源项目比较多,就想要学习一下esp32的开发,目前使用比较多的ide基本上是arduino、esp-idf和platformio,前者编译比较慢,后两者看到开源大佬的项目做的比较多,所以主要学习后两者。 本次使用的硬件是GO…...

C++学习思路
C++知识体系详细大纲 一、基础语法 (一)数据类型 基本数据类型 整数类型(int, short, long, long long)浮点类型(float, double, long double)字符类型(char, wchar_t, char16_t, char32_t)布尔类型(bool)复合数据类型 数组结构体(struct)联合体(union)枚举类型…...