使用 Python + SQLAlchemy 创建知识库数据库(SQLite)—— 构建本地知识库系统的基础《一》
📚 使用 Python + SQLAlchemy 创建知识库数据库(SQLite)—— 构建本地知识库系统的基础
🧠 一、前言
随着大模型技术的发展,越来越多的项目需要构建本地知识库系统来支持 RAG(Retrieval-Augmented Generation)、Agent 记忆管理、文档检索等功能。
本文将介绍如何使用 Python + SQLAlchemy 搭建一个结构清晰、可扩展性强的知识库数据库,适用于 AI 助手、智能问答系统等场景。
🗂️ 二、项目目标
我们希望创建一个 SQLite 数据库,包含以下四张核心表:
| 表名 | 描述 |
|---|---|
knowledge_base | 存储知识库基本信息(名称、简介、向量库类型、嵌入模型等) |
knowledge_file | 存储每个知识库中的文件信息(文件名、大小、修改时间、切分情况等) |
file_doc | 存储文件切片后的文档片段 ID 及其元数据 |
summary_chunk | 存储文档摘要与对应的文档 ID 列表 |
这些表构成了一个完整的知识库管理系统的基础架构,可用于后续的文档加载、向量化、检索和更新操作。
🔧 三、环境依赖
- Python 3.12+
- SQLAlchemy
- sqlite3(Python 自带)
安装命令如下:
pip install sqlalchemy
🗃️ 四、数据库配置与初始化
我们使用 SQLite 作为本地存储方式,路径如下:
DB_PATH = "/Volumes/PSSD/未命名文件夹/donwload/创建知识库数据库/knowledge_base/info.db"
SQLALCHEMY_DATABASE_URI = f"sqlite:///{DB_PATH}"
通过 SQLAlchemy 的 create_engine 和 sessionmaker 初始化数据库连接池。
engine = create_engine(SQLALCHEMY_DATABASE_URI,json_serializer=lambda obj: json.dumps(obj, ensure_ascii=False),
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base: DeclarativeMeta = declarative_base()
📐 五、ORM 模型定义详解
1. KnowledgeBaseModel —— 知识库基础信息表
| 字段 | 类型 | 默认值 | 描述 |
|---|---|---|---|
id | Integer | - | 主键 |
kb_name | String(50) | - | 知识库名称 |
kb_info | String(200) | - | 知识库简介 |
vs_type | String(50) | - | 向量库类型(如 FAISS、Chroma) |
embed_model | String(50) | - | 嵌入模型名称 |
file_count | Integer | 0 | 文件数量 |
create_time | DateTime | func.now() | 创建时间 |
2. KnowledgeFileModel —— 知识库文件信息表
| 字段 | 类型 | 默认值 | 描述 |
|---|---|---|---|
id | Integer | - | 主键 |
file_name | String(255) | - | 文件名 |
file_ext | String(10) | - | 扩展名 |
kb_name | String(50) | - | 所属知识库 |
document_loader_name | String(50) | - | 文档加载器名称 |
text_splitter_name | String(50) | - | 文本分割器名称 |
file_version | Integer | 1 | 文件版本 |
file_mtime | Float | 0.0 | 最后修改时间 |
file_size | Integer | 0 | 文件大小 |
custom_docs | Boolean | False | 是否自定义 docs |
docs_count | Integer | 0 | 切分文档数 |
create_time | DateTime | func.now() | 创建时间 |
3. FileDocModel —— 文件切片文档表
| 字段 | 类型 | 默认值 | 描述 |
|---|---|---|---|
id | Integer | - | 主键 |
kb_name | String(50) | - | 知识库名称 |
file_name | String(255) | - | 文件名 |
doc_id | String(50) | - | 向量库文档 ID |
meta_data | JSON | {} | 元数据(如来源、页码等) |
该表用于记录每个文件被切分后的每一个 chunk 对应的向量 ID。
4. SummaryChunkModel —— 文档摘要与关联表
| 字段 | 类型 | 默认值 | 描述 |
|---|---|---|---|
id | Integer | - | 主键 |
kb_name | String(50) | - | 知识库名称 |
summary_context | String(255) | - | 总结文本 |
summary_id | String(255) | - | 总结内容在向量库中的 ID |
doc_ids | String(1024) | - | 关联的 doc_id 列表 |
meta_data | JSON | {} | 元数据信息 |
用于存储文档的总结信息,并与原始 chunk 进行关联。
🧱 六、表操作函数
我们提供了两个主要函数用于管理数据库表:
✅ 1. 创建所有表
def create_tables():print("📌 正在创建所有表...")Base.metadata.create_all(bind=engine)print("✅ 表创建完毕")
⚠️ 2. 清空并重建所有表
def reset_tables():Base.metadata.drop_all(bind=engine)Base.metadata.create_all(bind=engine)print("⚠️ 数据库表已清空并重新创建")
这两个函数非常适合在初始化或调试阶段使用。
📝 七、命令行执行方式
你可以通过命令行参数控制数据库行为:
# 创建数据库表
python 创建表.py --create-tables# 清空并重建数据库表
python 创建表.py --clear-tables
输出示例:
📦 执行参数:create_tables: Trueclear_tables: False
📌 正在创建所有表...
✅ 表创建完毕
✅ 执行完毕,耗时: 0:00:00.123456
💡 八、详细的完整代码
#!/usr/bin/env python
# coding=utf-8""""""import os
import json
import sys
import argparse
from datetime import datetime
from sqlalchemy import Column, Integer, String, DateTime, Float, Boolean, JSON, func, create_engine
from sqlalchemy.ext.declarative import declarative_base, DeclarativeMeta
from sqlalchemy.orm import sessionmaker# ======== 数据库路径配置 ========SQLALCHEMY_DATABASE_URI = f"sqlite:///{DB_PATH}"# ======== SQLAlchemy 初始化 ========
engine = create_engine(SQLALCHEMY_DATABASE_URI,json_serializer=lambda obj: json.dumps(obj, ensure_ascii=False),
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base: DeclarativeMeta = declarative_base()# ======== ORM 模型定义 ========class KnowledgeBaseModel(Base):__tablename__ = 'knowledge_base'id = Column(Integer, primary_key=True, autoincrement=True, comment='知识库ID')kb_name = Column(String(50), comment='知识库名称')kb_info = Column(String(200), comment='知识库简介(用于Agent)')vs_type = Column(String(50), comment='向量库类型')embed_model = Column(String(50), comment='嵌入模型名称')file_count = Column(Integer, default=0, comment='文件数量')create_time = Column(DateTime, default=func.now(), comment='创建时间')class KnowledgeFileModel(Base):__tablename__ = 'knowledge_file'id = Column(Integer, primary_key=True, autoincrement=True, comment='知识文件ID')file_name = Column(String(255), comment='文件名')file_ext = Column(String(10), comment='文件扩展名')kb_name = Column(String(50), comment='所属知识库名称')document_loader_name = Column(String(50), comment='文档加载器名称')text_splitter_name = Column(String(50), comment='文本分割器名称')file_version = Column(Integer, default=1, comment='文件版本')file_mtime = Column(Float, default=0.0, comment="文件修改时间")file_size = Column(Integer, default=0, comment="文件大小")custom_docs = Column(Boolean, default=False, comment="是否自定义docs")docs_count = Column(Integer, default=0, comment="切分文档数量")create_time = Column(DateTime, default=func.now(), comment='创建时间')class FileDocModel(Base):__tablename__ = 'file_doc'id = Column(Integer, primary_key=True, autoincrement=True, comment='ID')kb_name = Column(String(50), comment='知识库名称')file_name = Column(String(255), comment='文件名称')doc_id = Column(String(50), comment="向量库文档ID")meta_data = Column(JSON, default={})class SummaryChunkModel(Base):__tablename__ = 'summary_chunk'id = Column(Integer, primary_key=True, autoincrement=True, comment='ID')kb_name = Column(String(50), comment='知识库名称')summary_context = Column(String(255), comment='总结文本')summary_id = Column(String(255), comment='总结矢量id')doc_ids = Column(String(1024), comment="向量库id关联列表")meta_data = Column(JSON, default={})# ======== 表操作函数 ========
def create_tables():print("📌 正在创建所有表...")Base.metadata.create_all(bind=engine)print("✅ 表创建完毕")def reset_tables():Base.metadata.drop_all(bind=engine)Base.metadata.create_all(bind=engine)print("⚠️ 数据库表已清空并重新创建")# ======== 命令行入口 ========
if __name__ == "__main__":parser = argparse.ArgumentParser(description="初始化知识库数据库")parser.add_argument("--create-tables",action="store_true",help="创建数据库表")parser.add_argument("--clear-tables",action="store_true",help="清空并重建数据库表")args = parser.parse_args()start_time = datetime.now()print("📦 执行参数:")for arg, value in vars(args).items():print(f" {arg}: {value}")if args.create_tables:create_tables()if args.clear_tables:reset_tables()print(f"✅ 执行完毕,耗时: {datetime.now() - start_time}")
#python 创建表.py --create-tables
#python 创建表.py --clear-tables
相关文章:
—— 构建本地知识库系统的基础《一》)
使用 Python + SQLAlchemy 创建知识库数据库(SQLite)—— 构建本地知识库系统的基础《一》
📚 使用 Python SQLAlchemy 创建知识库数据库(SQLite)—— 构建本地知识库系统的基础 🧠 一、前言 随着大模型技术的发展,越来越多的项目需要构建本地知识库系统来支持 RAG(Retrieval-Augmented Generat…...

使用柏林噪声生成随机地图
简单介绍柏林噪声 柏林噪声(Perlin Noise)是一种由 Ken Perlin 在1983年提出的梯度噪声(Gradient Noise)算法,用于生成自然、连续的随机值。它被广泛用于计算机图形学中模拟自然现象(如地形、云层、火焰等…...
)
P3 QT记事本(3.4)
3.4 文件选择对话框 QFileDialog 3.4.1 QFileDialog 开发流程 使用 QFileDialog 的基本步骤通常如下: 实例化 :首先,创建一个 QFileDialog 对象的实例。 QFileDialog qFileDialog;设置模式 :根据需要设置对话框的模式&…...
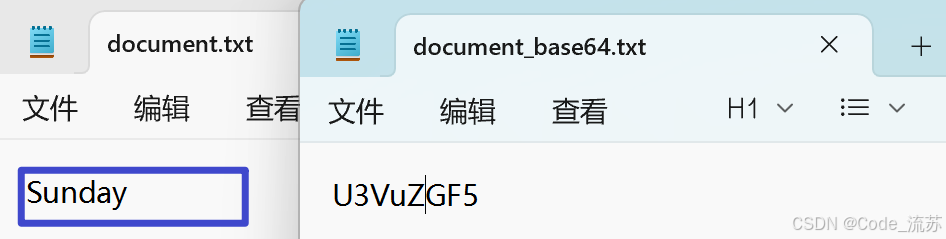
C++课设:实现简易文件加密工具(凯撒密码、异或加密、Base64编码)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、初识文件加密:为什么需要…...
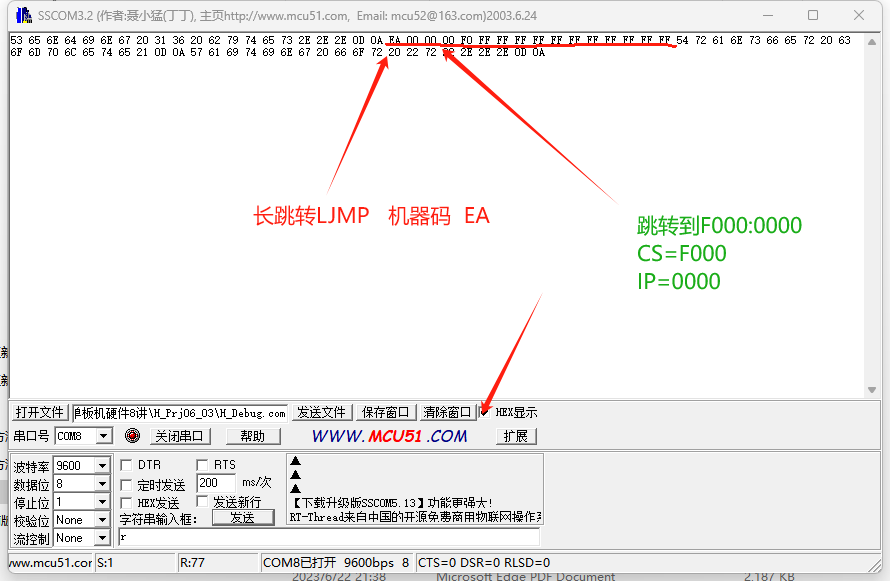
H_Prj06_03 8088单板机串口读取8088ROM复位内存
1.8088CPU复位时,CSFFFFH,IP0000H,因此在ROM的逻辑地址FFFF:0000(FFF0H)处一般要防止一个长跳转指令LJMP(机器码位EAH) 2.写一个完整的8086汇编程序,通过查询方式检测串口接收符串‘r’&#x…...
构建 MCP 服务器:第 3 部分 — 添加提示
这是我们构建 MCP 服务器的四部分教程的第三部分。在第一部分中,我们使用基本资源创建了第一个MCP 服务器;在第二部分中,我们添加了资源模板并改进了代码组织。现在,我们将进一步重构代码并添加提示功能。 什么是 MCP 提示&#…...

xcode 各版本真机调试包下载
下载地址 https://github.com/filsv/iOSDeviceSupport 使用方法: 添加到下面路径中,然后退出重启xcode /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/DeviceSupport...
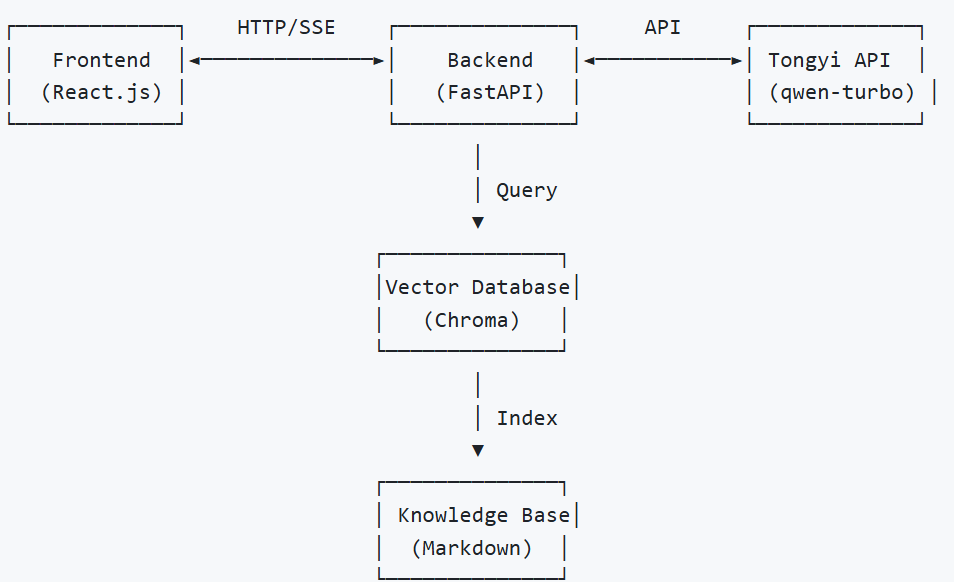
基于React + FastAPI + LangChain + 通义千问的智能医疗问答系统
📌 文章摘要: 本文详细介绍了如何在前端通过 Fetch 实现与 FastAPI 后端的 流式响应通信,并支持图文多模态数据上传。通过构建 multipart/form-data 请求,配合 ReadableStream 实时读取 AI 回复内容,实现类似 ChatGPT…...

C# 中替换多层级数据的 Id 和 ParentId,保持主从或父子关系不变
在C#中替换多层级数据的Id和ParentId,同时保持父子关系不变,可以通过以下步骤实现: 创建旧Id到新Id的映射:遍历所有节点,为每个旧Id生成唯一的新Id,并存储在字典中。 替换节点的Id和ParentId:…...
)
Scade 语言概念 - 方程(equation)
在 Scade 6 程序中自定义算子(Operator)的定义、或数据流定义(data_def)的内容中,包含一种基本的语言结构:方程(equation)(注1)。在本篇中,将叙述 Scade 语言方程的文法形式,以及作用。 注1: 对 Scade 中的 equation, 或 equation…...

PG 分区表的缺陷
简介 好久没发文,是最近我实在不知道写点啥。随着国产化进程,很多 oracle 都在进行迁移,最近遇到了一个分区表迁移之后唯一性的问题。oracle 数据库中创建主键或者唯一索引,不需要引用分区键,但是 PG 就不行ÿ…...

从Copilot到Agent,AI Coding是如何进化的?
编程原本是一项具有一定门槛的技能,但借助 AI Coding 产品,新手也能写出可运行的代码,非专业人员如业务分析师、产品经理,也能在 AI 帮助下直接生成简单应用。 这一演变对软件产业产生了深远影响。当 AI 逐步参与代码生成、调试乃…...

Qt(part 2)1、Qwindow(菜单栏,工具栏,状态栏),铆接部件,核心部件 ,2、添加资源文件 3、对话框
1、Qwindow tips:1,首先为什么创建出的对象基本都是指针形式,个人觉得是对象树的原因(自动释放内存),指针来访问成员函数->的形式。2,菜单栏只能一个的,放窗口基本Set,…...
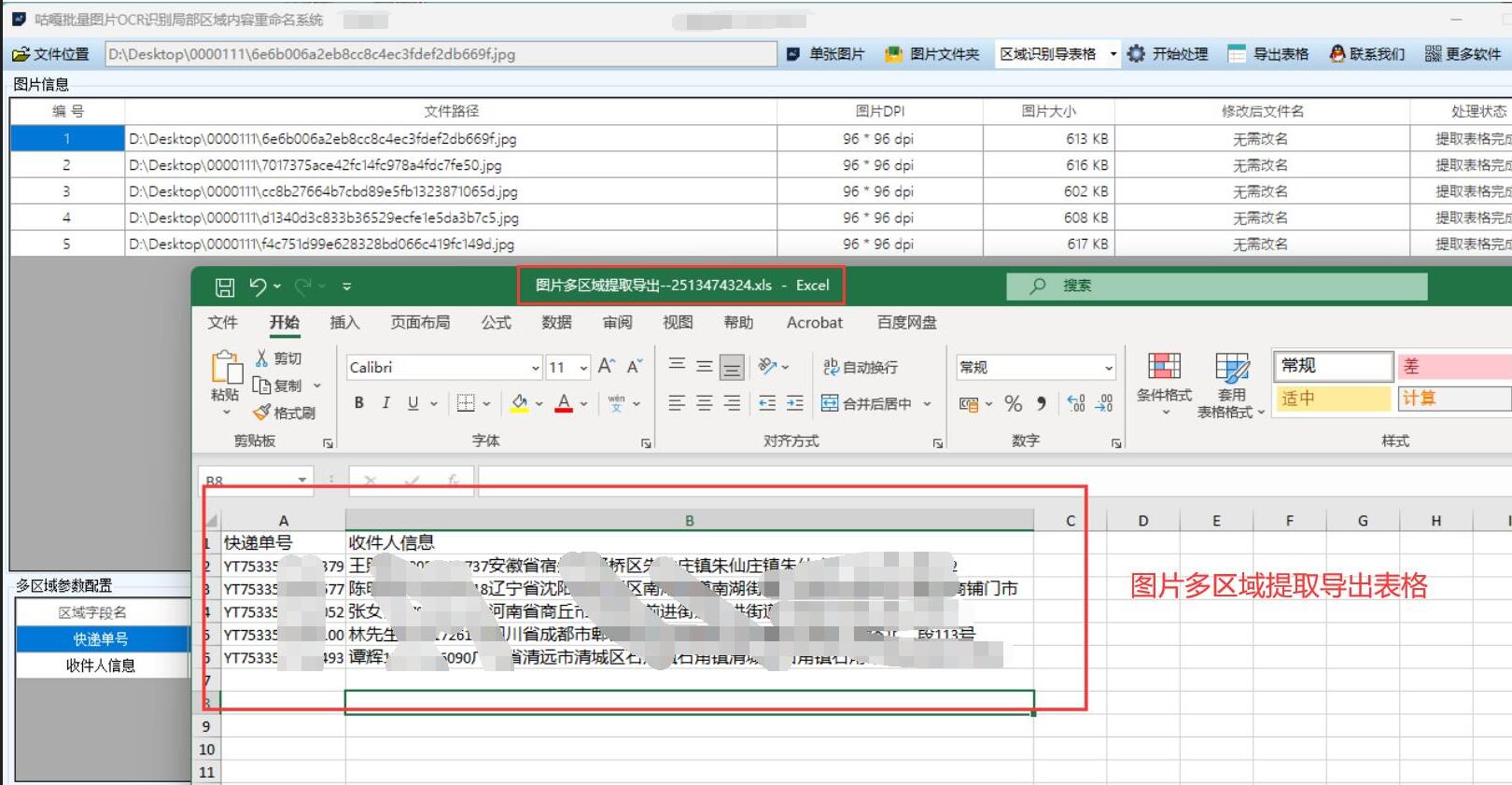
【图片识别Excel】批量提取图片中的文字,图片设置识别区域,识别后将文字提取并保存Excel表格,基于WPF和OCR识别的应用
应用场景 在办公自动化、文档处理、数据录入等场景中,经常需要从大量图片中提取文字信息。例如: 批量处理扫描的表单、合同、发票等文档从图片集中提取特定区域的文字数据将纸质资料快速转换为电子文本并整理归档 通过设置识别区域,可以精…...

深入理解 Java 多线程:原理剖析与实战指南
深入理解 Java 多线程:原理剖析与实战指南 一、引言 在现代软件开发中,多线程编程已经成为提升应用性能与响应能力的重要手段。Java 作为一门成熟的编程语言,自 JDK 1.0 起就提供了对多线程的原生支持。本文将深入剖析 Java 多线程的底层原…...
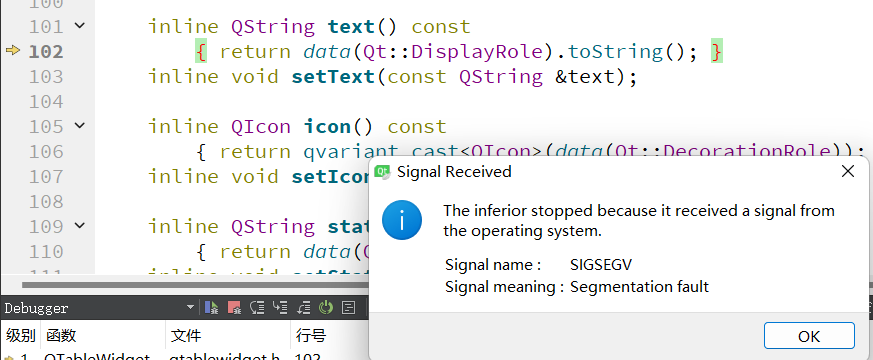
Qt/C++学习系列之Excel使用记录
Qt/C学习系列之Excel使用记录 前言The process was ended forcefully.解决方式断点查语句问题 总结 前言 在项目中解析条目达50多条,并且都需要将对应的结果进行显示。为了将结果显示的更加清晰,考虑采用QTableWidget进行表格设置,而在使用过…...
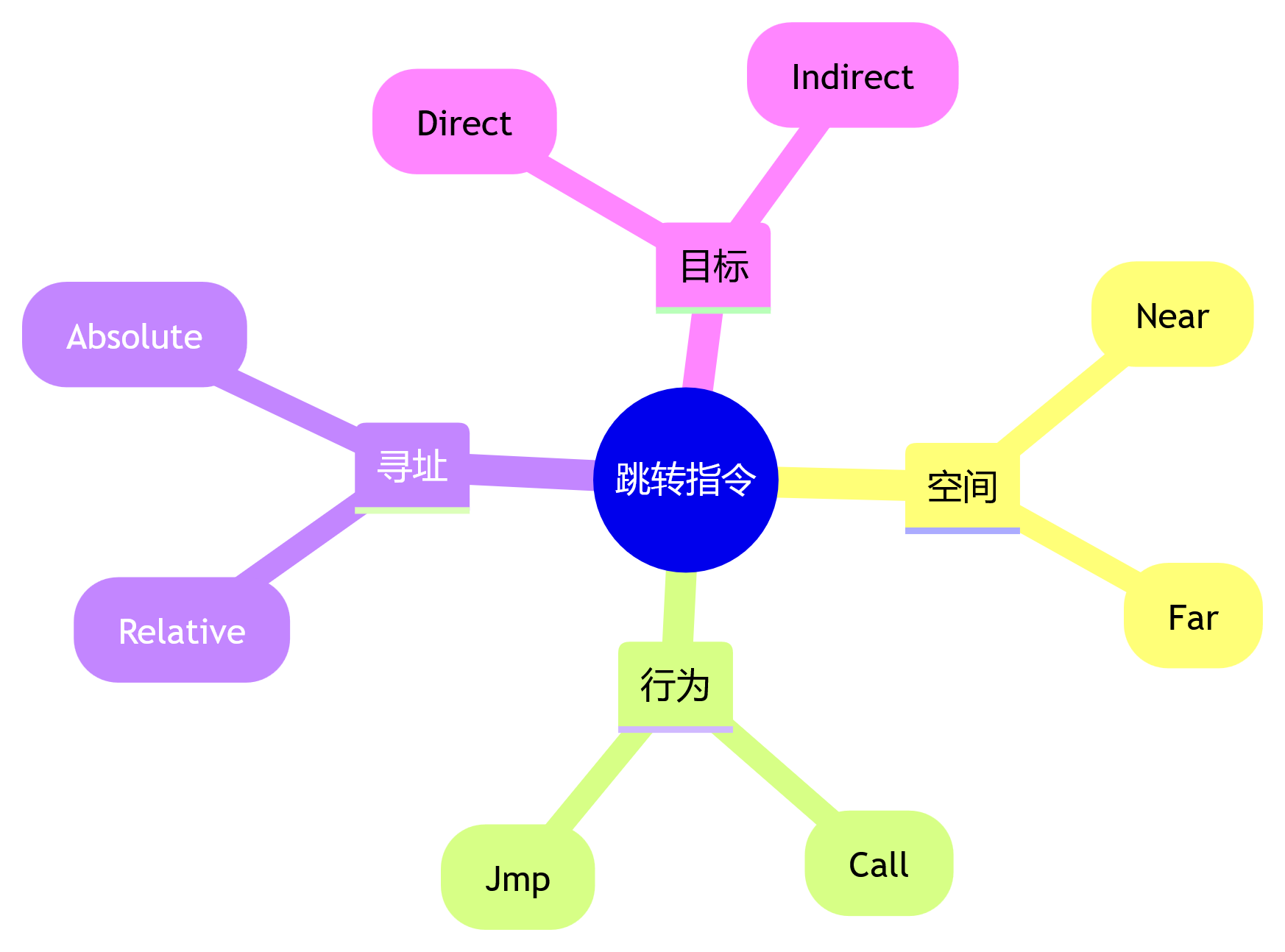
跳转指令四维全解:从【call/jmp 】的时空法则到内存迷宫导航术
一、核心概念:代码世界的空间定位法则 在汇编世界里,我们可以把内存想象成一栋巨大的图书馆: CS(代码段寄存器) 楼层编号 IP(指令指针) 房间编号 当前执行位置 CS:IP(如3楼201…...
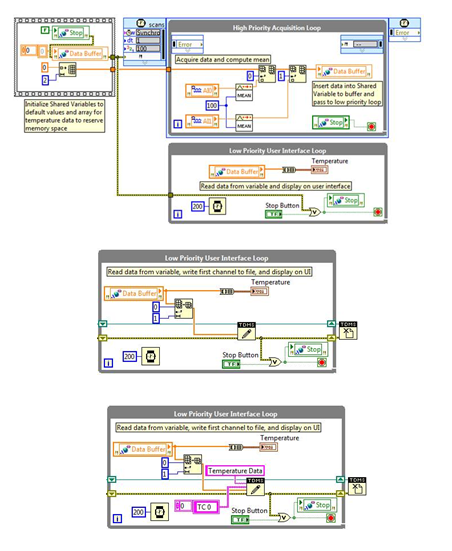
LabVIEW实时系统数据监控与本地存储
基于LabVIEW Real-Time 模块,面向工业自动化、嵌入式测控等场景,提供实时数据采集、监控与本地存储的完整实现路径。通过分层任务调度、TDMS 文件格式应用及跨平台兼容性设计,确保系统在实时性、可靠性与数据管理效率间达到平衡。文中以 Comp…...
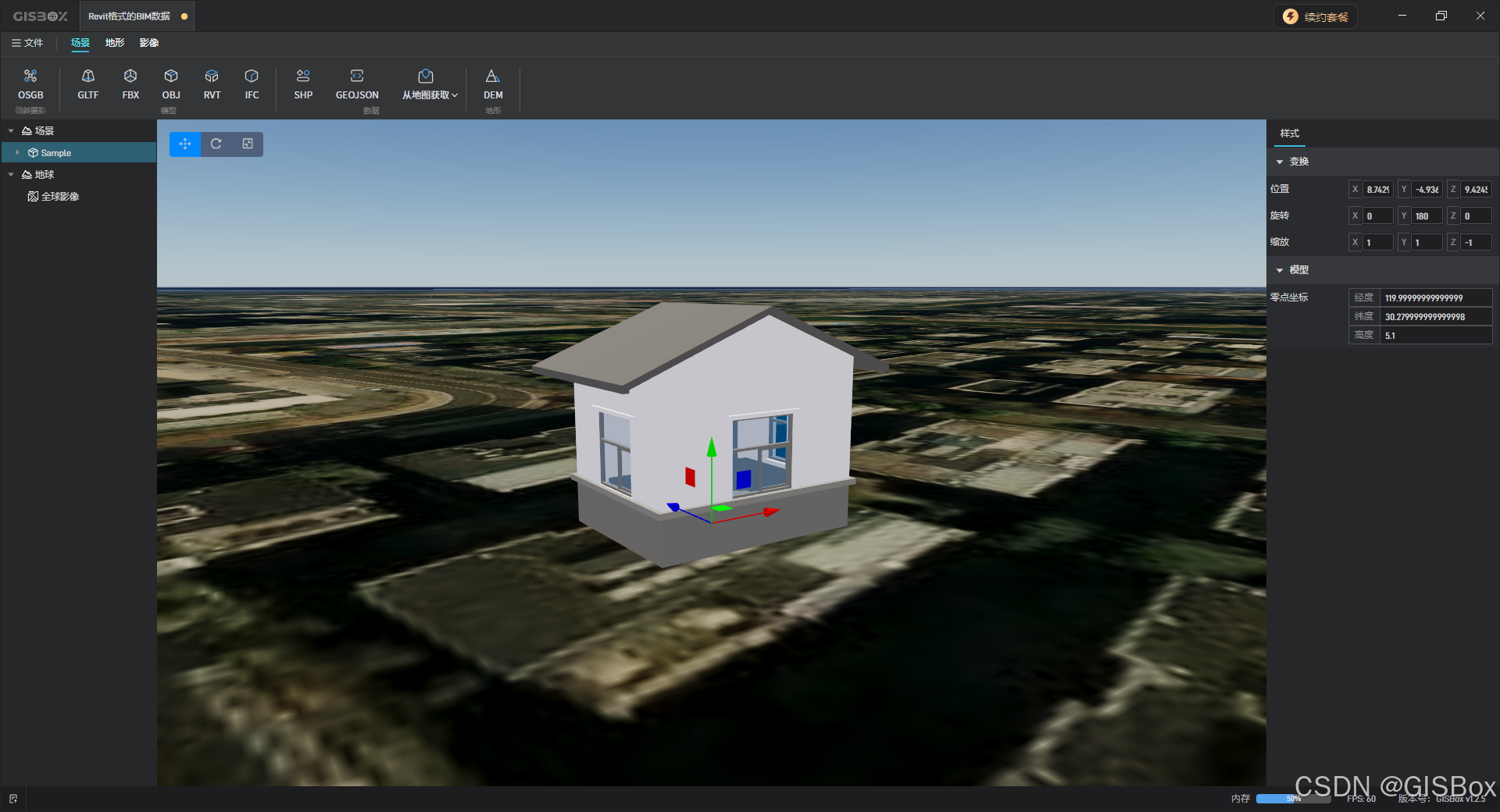
从 Revit 到 3DTiles:GISBox RVT 切片器如何让建筑图元在 Web 端展示
在GIS(地理信息系统)行业蓬勃发展的当下,数据处理与展示的效率和精准度成为关键。GISBox作为一款功能强大的一站式三维GIS数据编辑、转换、发布平台,凭借其独特的“RVT切片器”功能,在RVT图元处理方面也有着不俗的表现…...
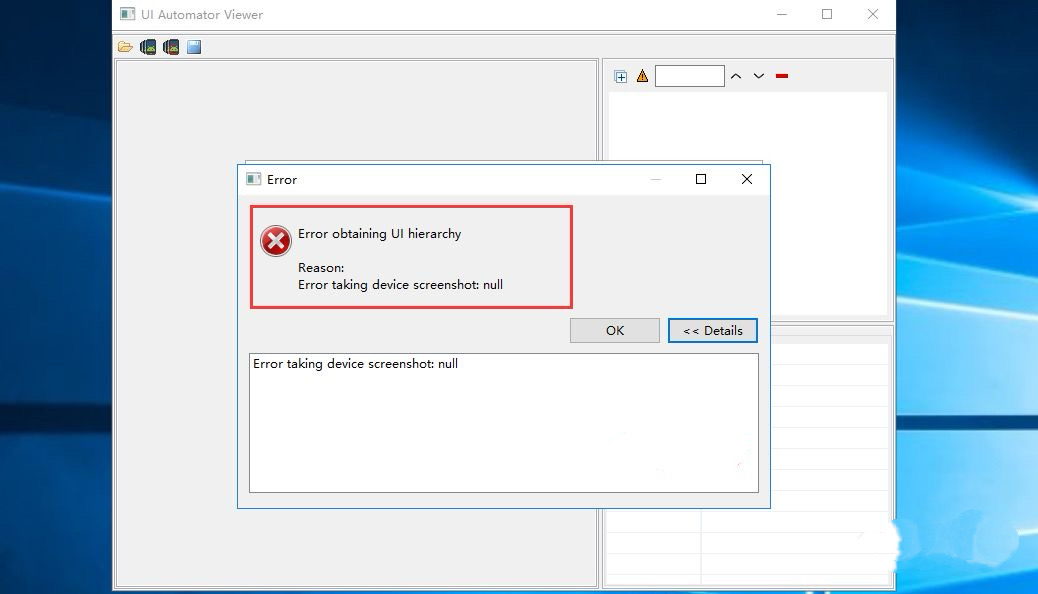
Appium+python自动化(十二)- Android UIAutomator
Android团队在4.1版本(API 16)中推出了一款全新的UI自动化测试工具UiAutomator,用来帮助开发人员更有效率的完成App的Debug工作,同时对于测试人员也是一大福音,为什么这么说呢? UiAutomator提供了以下两种…...

在C语言中使用UUID作为AES加密密钥
在C语言中使用UUID作为AES加密密钥 编译依赖安装示例代码编译和运行关键点说明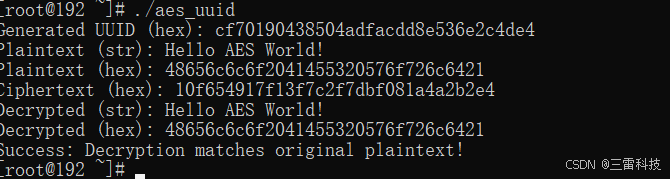注意事项编译依赖安装 运行环境位centos8 Linux 4.18.0-348.7.1.el8_5.x86_64 #1 SMP Wed Dec …...

Nginx+Tomcat负载均衡集群
目录 一、Tomcat 基础与单节点部署 (一)Tomcat 概述 (二)单节点部署案例 1. 案例环境 2. 实施准备 3. 安装 JDK 4. 查看 JDK 安装情况 5. 安装配置 Tomcat 6. 启动 Tomcat 7. 访问测试 8. 关闭 Tomcat (三…...

QQ邮箱发送验证码(Springboot)
一、邮箱发送服务准备 在qq邮箱的设置中选择账号下开启服务。 开启时可能会有短信验证,开启后显示验证码之类的一串英文,复制保存起来,在配置文件中会使用到。 二、后端依赖及配置 依赖 在pom.yml文件中添加相关依赖,redis的…...

Python Copilot【代码辅助工具】 简介
粉丝爱买鳕鱼肠深海鳕鱼肉鱼肉香肠盼盼麦香鸡味块卡乐比(Calbee)薯条三兄弟 独立小包美丽雅 奶茶杯一次性饮料杯好时kisses多口味巧克力糖老金磨方【黑金系列】黑芝麻丸郑新初网红郑新初烤鲜牛肉干超人毛球修剪器去球器剃毛器衣服去毛器优惠券宁之春 红黑…...

如何写高效的Prompt?
概述 提示词(Prompt)的质量将直接影响模型生成结果的质量,所以精心设计一个让大模型能够理解并有效回复的提示词是至关重要的。本文内容自论文中获取:https://arxiv.org/pdf/2312.16171 介绍了5类共计26条提示词书写原则。 书写原则 类别原则备注快速…...

【EF Core】 EF Core并发控制:乐观锁与悲观锁的应用
文章目录 前言一、并发的风险二、EF Core中的并发控制方式2.1 开放式并发(乐观锁)2.1.1 应用程序管理的属性并发令牌2.1.2 数据库生成的并发令牌 2.2 悲观锁 总结 前言 实际的生产环境中,我们经常能遇到数据库由多个应用程序同时使用。每个程…...

WaytoAGI东京大会开启AI全球化新对话:技术无国界,合作促创新
全球AI专家齐聚东京,一场关于技术无国界的对话正在进行。 2025年6月7日,一场备受瞩目的AI盛会——“WaytoAGI全球AI大会东京站”在日本东京樱美林大学新宿校区正式拉开帷幕。这场为期两天的会议(6月7日至8日)由国内最大的AI开源知…...

Harmony核心:动态方法修补与.NET游戏Mod开发
一、Harmony的核心定位与设计哲学 Harmony是一个运行时动态方法修补库,专为修改已编译的.NET/Mono应用程序而设计,尤其适用于游戏Mod开发。其核心创新在于: 非破坏性修改:保留原始方法完整性,避免直接替换或覆盖。多…...

AI系统应用开发工程师
以下是对AI系统应用开发与运维岗位的梳理整合,从企业、岗位、任务、能力等维度进行分类呈现,便于清晰对比两者的工作侧重: 一、代表性企业对比 分类企业名称应用开发方向中移系统集成有限公司、科大讯飞河北科技有限公司、华为技术服务有限…...

Qt Test功能及架构
Qt Test 是 Qt 框架中的单元测试模块,在 Qt 6.0 中提供了全面的测试功能。 一、主要功能 核心功能 1. 单元测试框架 提供完整的单元测试基础设施 支持测试用例、测试套件的组织和执行 包含断言宏和测试结果收集 2. 测试类型支持 单元测试:对单个函…...