使用MinIO搭建自己的分布式文件存储
目录
引言:
一.什么是 MinIO ?
二.MinIO 的安装与部署:
三.Spring Cloud 集成 MinIO:
1.前提准备:
(1)安装依赖:
(2)配置MinIO连接:
(3)修改bucket的访问权限:
2.测试上传、删除、下载文件:
3.图片操作:
(1)MinioConfig 配置类:
(2)Controller 接口定义:
(3)Service开发:
【1】根据扩展名获取mimeType:
【2】将文件上传到minio:
【3】获取文件默认存储目录路径 年/ 月/ 日:
【4】获取文件的md5:
4.视频操作:
(1)断点上传:
(2)测试文件分块上传与合并:
【1】分块上传:
【2】合并分块文件:
(3)使用MinIO合并分块:
【1】将分块文件上传至minio:
【2】合并文件,要求分块文件最小5M:
【3】清除分块文件:
(4)三层架构——上传分块:
【1】检查文件是否存在:
【2】文件上传前检查分块文件是否存在:
【3】上传分块文件:
(4) 三层架构——清除分块文件:
(5)三层架构——从MinIO下载文件:
(6)三层架构——合并分块文件:

引言:
一个计算机无法存储海量的文件,通过网络将若干计算机组织起来共同去存储海量的文件,去接收海量用户的请求,这些组织起来的计算机通过网络进行通信,如下图:
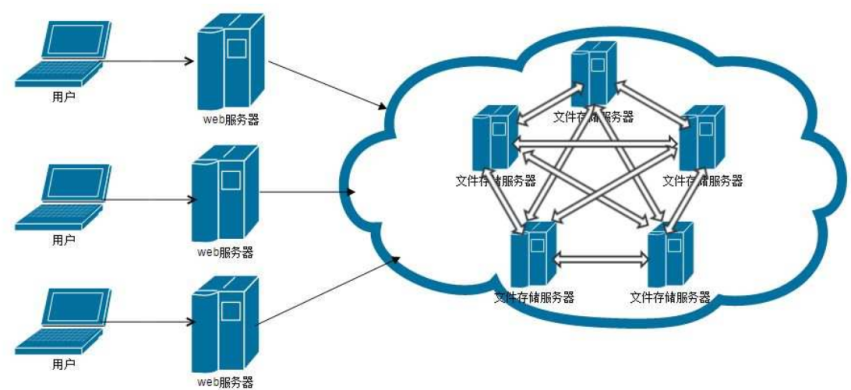
好处:
1、一台计算机的文件系统处理能力扩充到多台计算机同时处理。
2、一台计算机挂了还有另外副本计算机提供数据。
3、每台计算机可以放在不同的地域,这样用户就可以就近访问,提高访问速度。
市面上有哪些分布式文件系统的产品呢?
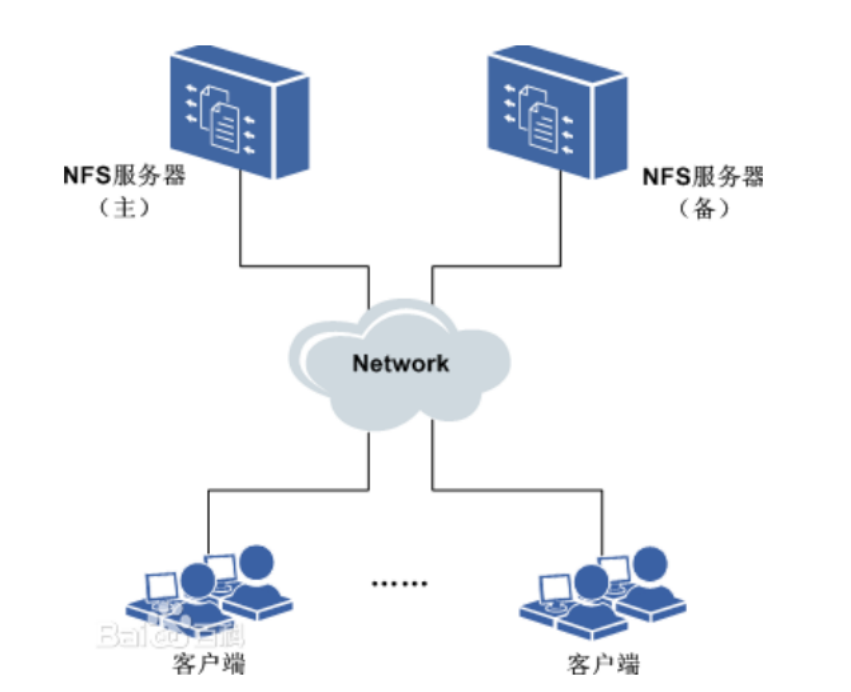
- NFS:在客户端上映射NFS服务器的驱动器,客户端通过网络访问NFS服务器的硬盘完全透明。
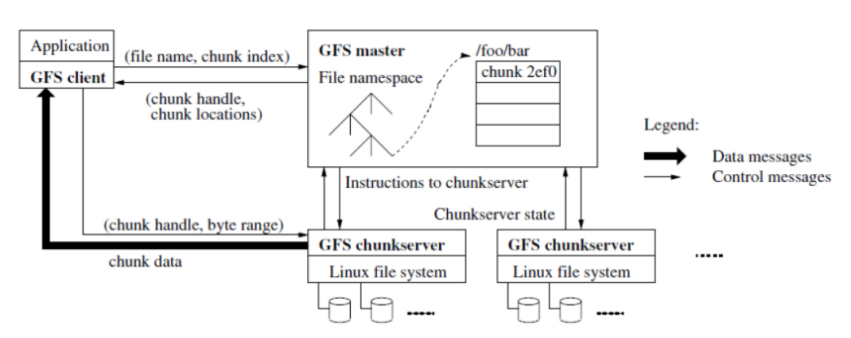
- GFS:采用主从结构,一个GFS集群由一个master和大量的chunkserver组成,master存储了数据文件的元数据,一个文件被分成了若干块存储在多个chunkserver中。用户从master中获取数据元信息,向chunkserver存储数据。
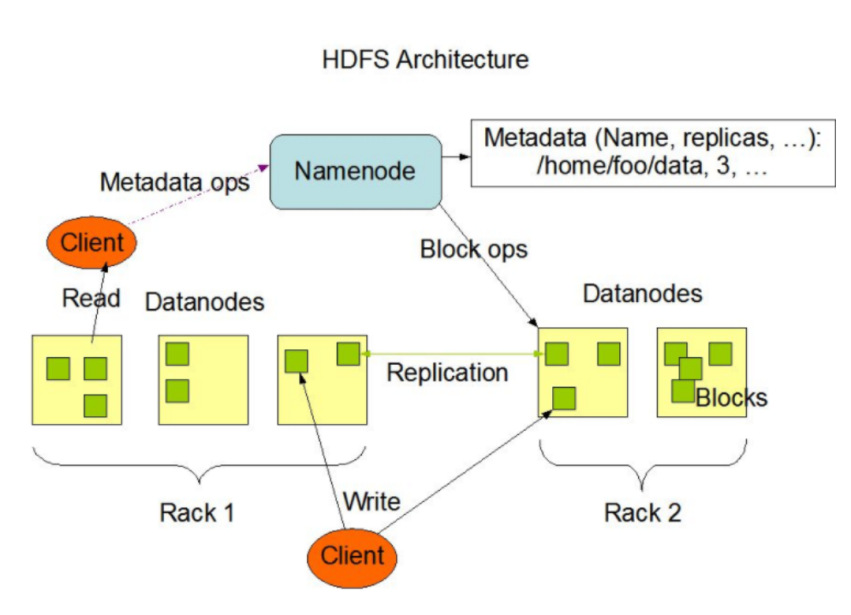
- HDFS:是Hadoop抽象文件系统的一种实现,高度容错性的系统,适合部署在廉价的机器上。能提供高吞吐量的数据访问,非常适合大规模数据集上的应用,HDFS的文件分布在集群机器上,同时提供副本进行容错及可靠性保证。例如客户端写入读取文件的直接操作都是分布在集群各个机器上的,没有单点性能压力。
- 阿里云对象存储服务OSS:对象存储 OSS_云存储服务阿里云对象存储 OSS 是一款海量、安全、低成本、高可靠的云存储服务,提供 99.995 % 的服务可用性和多种存储类型,适用于数据湖存储,数据迁移,企业数据管理,数据处理等多种场景,可对接多种计算分析平台,直接进行数据处理与分析,打破数据孤岛,优化存储成本,提升业务价值。
https://www.aliyun.com/product/oss
- 百度对象存储BOS:对象存储BOS_百度智能云百度智能云对象存储BOS提供稳定、安全、高效、高可扩展的云存储服务。您可以将任意数量和形式的非结构化数据存入对象存储BOS,BOS支持标准、低频、冷和归档存储等多种存储类型,适用于数据迁移、企业数据管理、数据处理、数据湖存储等多种场景。
一.什么是 MinIO ?
MinIO是一个高性能、分布式对象存储系统,专为大规模数据基础设施而设计,它兼容亚马逊 S3 云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等。
它一大特点就是轻量,使用简单,功能强大,支持各种平台,单个文件最大5TB,兼容 Amazon S3接口,提供了 Java、Python、GO等多版本SDK支持。
官网:https://min.io
中文:https://www.minio.org.cn/,http://docs.minio.org.cn/docs/
MinIO的主要特点包括:
- 高性能:作为世界上最快的对象存储之一,MinIO可以支持高达每秒数百GB的吞吐量
- 简单易用:简单的命令行和Web界面,几分钟内即可完成安装和配置
- 云原生:从公有云到私有云再到边缘计算,MinIO都能完美运行
- 开源:采用Apache V2开源协议,可以自由使用和修改
- 轻量级:单个二进制文件即可运行,没有外部依赖
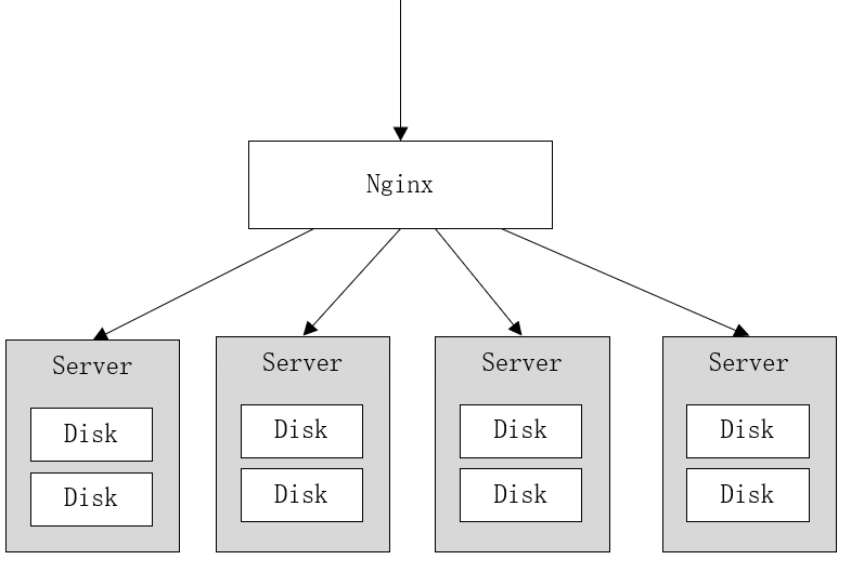
MinIO集群采用去中心化共享架构,每个结点是对等关系,通过Nginx可对MinIO进行负载均衡访问。
去中心化有什么好处?
在大数据领域,通常的设计理念都是无中心和分布式。Minio分布式模式可以帮助你搭建一个高可用的对象存储服务,你可以使用这些存储设备,而不用考虑其真实物理位置。
它将分布在不同服务器上的多块硬盘组成一个对象存储服务。由于硬盘分布在不同的节点上,分布式Minio避免了单点故障。如下图:
Minio使用纠删码技术来保护数据,它是一种恢复丢失和损坏数据的数学算法,它将数据分块冗余的分散存储在各各节点的磁盘上,所有的可用磁盘组成一个集合,上图由8块硬盘组成一个集合,当上传一个文件时会通过纠删码算法计算对文件进行分块存储,除了将文件本身分成4个数据块,还会生成4个校验块,数据块和校验块会分散的存储在这8块硬盘上。
使用纠删码的好处是即便丢失一半数量(N / 2)的硬盘,仍然可以恢复数据。 比如上边集合中有4个以内的硬盘损害仍可保证数据恢复,不影响上传和下载,如果多于一半的硬盘坏了则无法恢复。
二.MinIO 的安装与部署:
下边在本机演示MinIO恢复数据的过程,在本地创建4个目录表示4个硬盘。
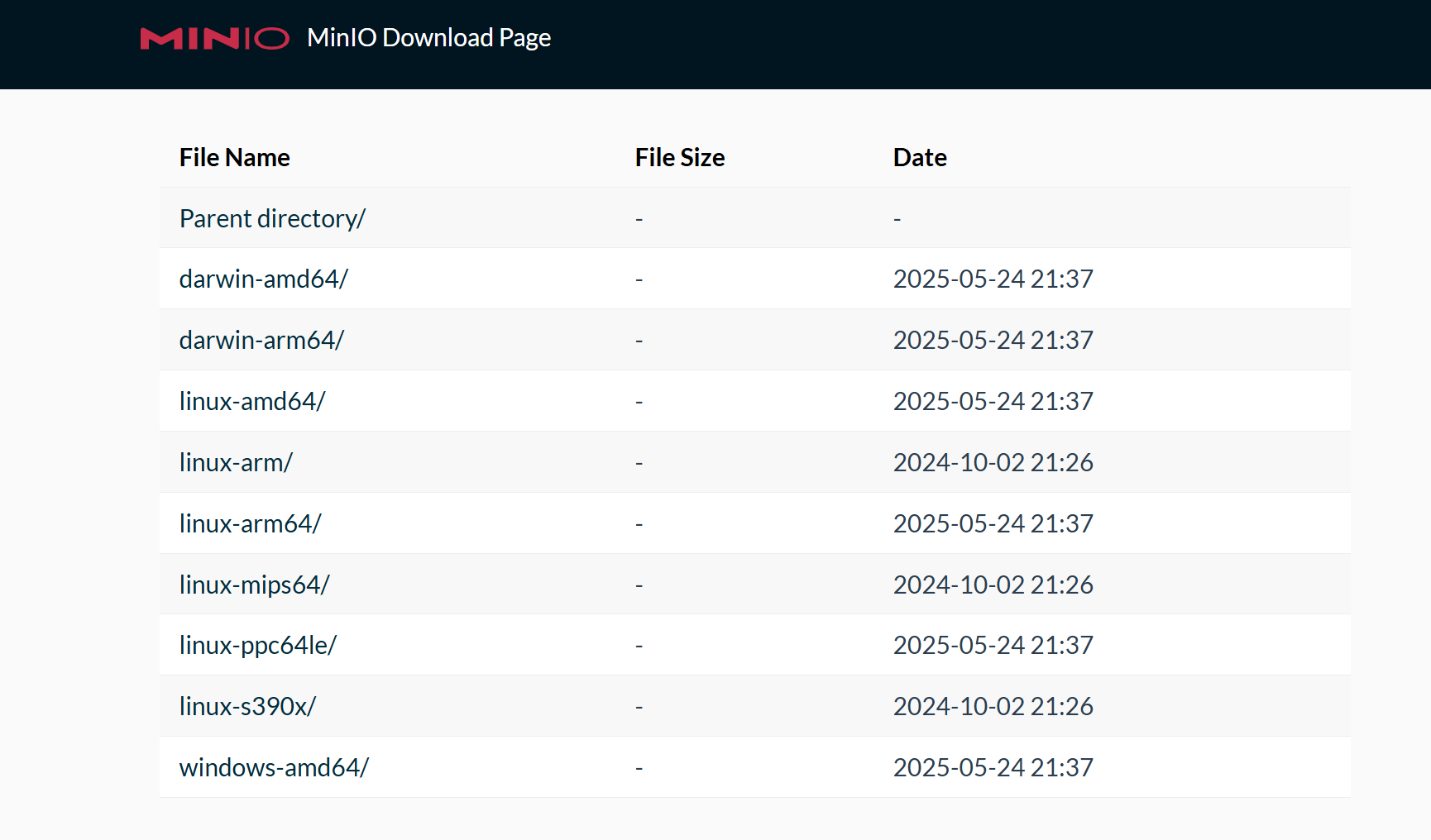
下载minio,下载地址在 Minio下载地址 :
随后CMD进入有minio.exe的目录,运行下边的命令:( 替换自己的安装地址)
minio.exe server E:\minio_data\data1 E:\minio_data\data2 E:\minio_data\data3 E:\minio_data\data4
启动结果如下:
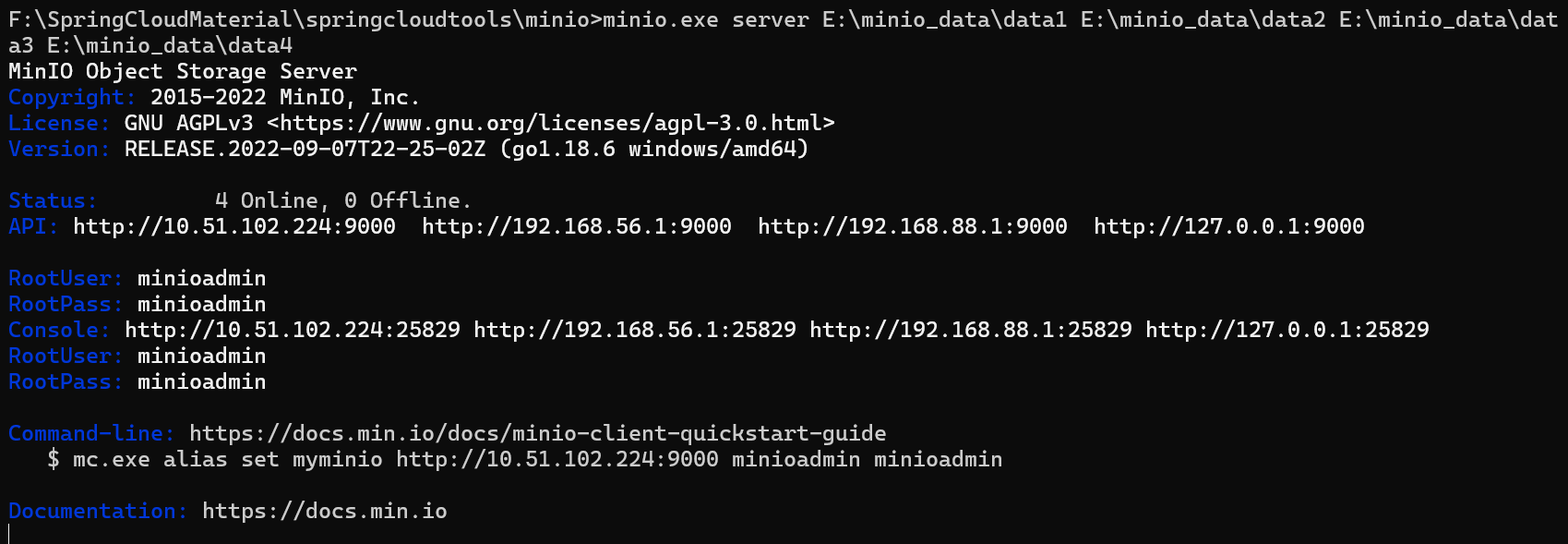
说明如下:
WARNING: MINIO_ACCESS_KEY and MINIO_SECRET_KEY are deprecated.
Please use MINIO_ROOT_USER and MINIO_ROOT_PASSWORD
Formatting 1st pool, 1 set(s), 4 drives per set.
WARNING: Host local has more than 2 drives of set. A host failure will result in data becoming unavailable.
WARNING: Detected default credentials 'minioadmin:minioadmin', we recommend that you change these values with 'MINIO_ROOT_USER' and 'MINIO_ROOT_PASSWORD' environment variables1)老版本使用的MINIO_ACCESS_KEY 和 MINIO_SECRET_KEY不推荐使用,推荐使用MINIO_ROOT_USER 和MINIO_ROOT_PASSWORD设置账号和密码。
2)pool即minio节点组成的池子,当前有一个pool和4个硬盘组成的set集合
3)因为集合是4个硬盘,大于2的硬盘损坏数据将无法恢复。
4)账号和密码默认为minioadmin、minioadmin,可以在环境变量中设置通过'MINIO_ROOT_USER' and 'MINIO_ROOT_PASSWORD' 进行设置。
下边输入 http://192.168.88.1:9000 进行登录(看自己的地址),账号和密码均为为:minioadmin
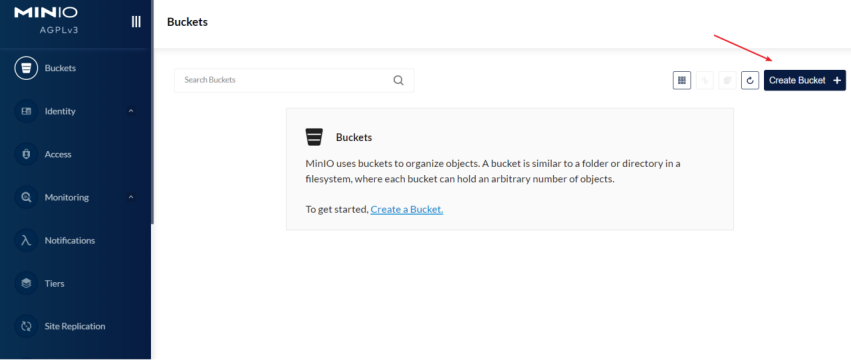
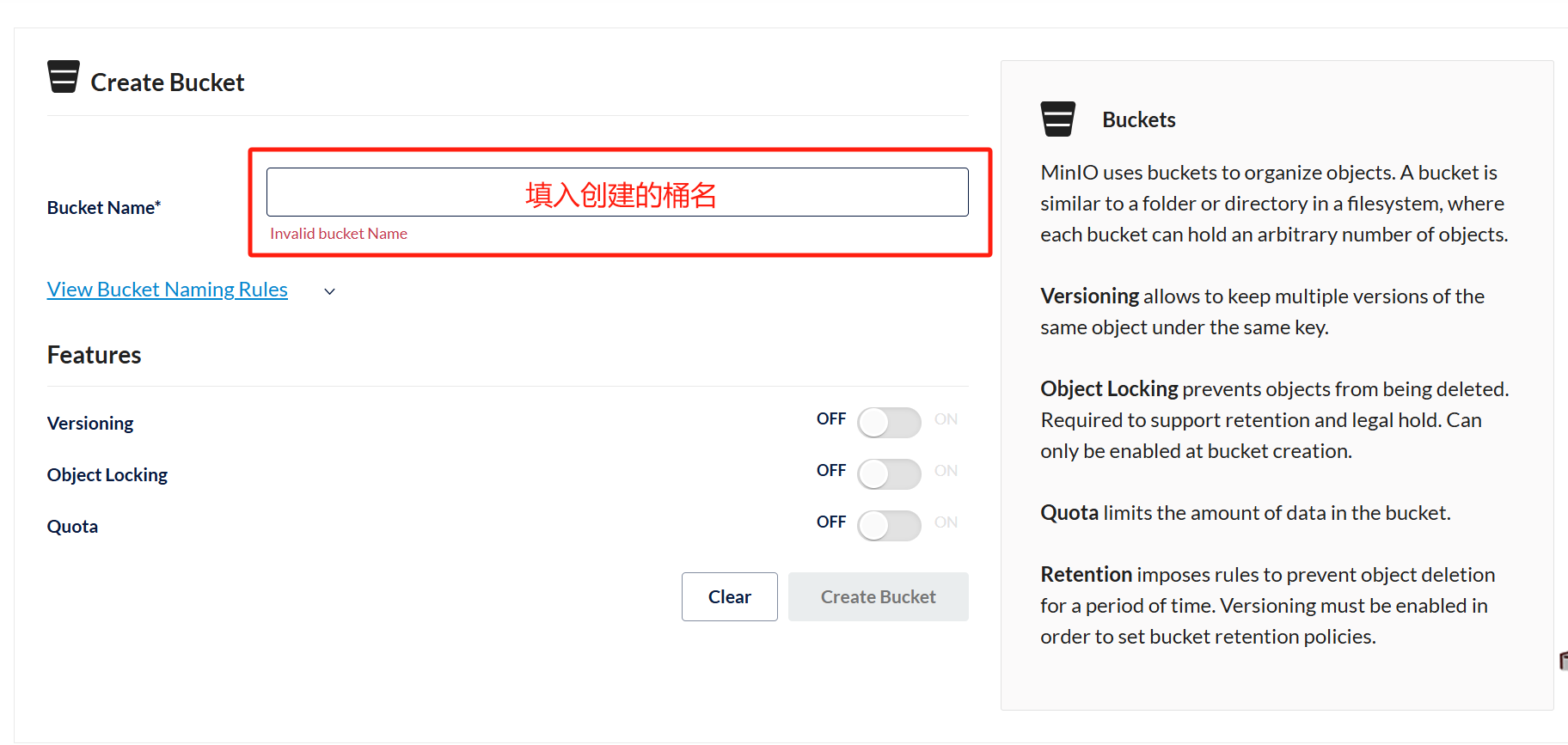
输入bucket的名称,点击“CreateBucket”,创建成功:
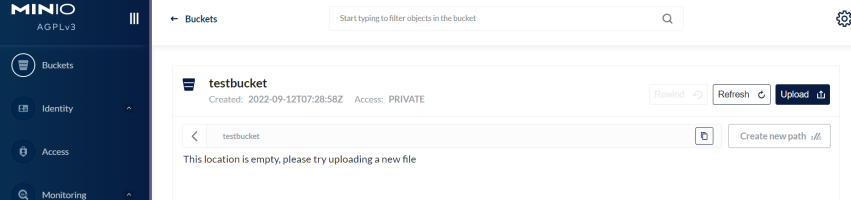
随后就可以进行上传、删除等操作了。
三.Spring Cloud 集成 MinIO:
1.前提准备:
(1)安装依赖:
<dependency><groupId>io.minio</groupId><artifactId>minio</artifactId><version>8.5.2</version>
</dependency>
<dependency><groupId>com.squareup.okhttp3</groupId><artifactId>okhttp</artifactId><version>4.12.0</version>
</dependency>
<!--根据扩展名取mimetype-->
<dependency><groupId>com.j256.simplemagic</groupId><artifactId>simplemagic</artifactId><version>1.17</version>
</dependency>(2)配置MinIO连接:
因为我们要上传普通文件与视频文件,所以创建 mediafiles(普通文件) 与 video(视频文件) 两个 buckets 。
在 bootstrap.yml中添加配置:
minio:endpoint: http://192.168.56.1:9000accessKey: minioadminsecretKey: minioadminbucket:files: mediafilesvideofiles: video需要三个参数才能连接到minio服务。
| 参数 | 说明 |
| Endpoint | 对象存储服务的URL |
| Access Key | Access key就像用户ID,可以唯一标识你的账户。 |
| Secret Key | Secret key是你账户的密码。 |
随后也可以添加对上传文件的限制:
spring:servlet:multipart:max-file-size: 50MBmax-request-size: 50MBmax-file-size:单个文件的大小限制
Max-request-size: 单次请求的大小限制
(3)修改bucket的访问权限:
点击“Manage”修改bucket的访问权限:
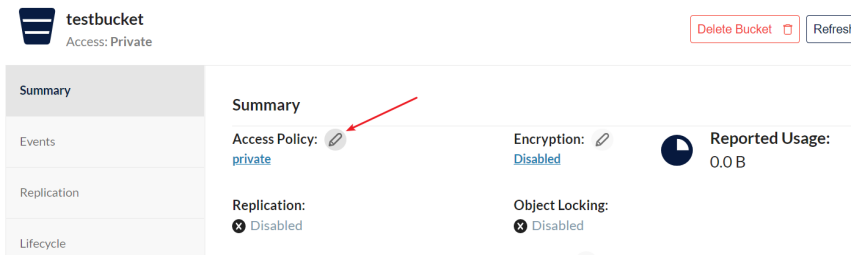
选择public权限:
2.测试上传、删除、下载文件:
首先初始化 minioClient:
MinioClient minioClient =MinioClient.builder().endpoint("http://192.168.56.1:9000").credentials("minioadmin", "minioadmin").build();随后设置contentType可以通过com.j256.simplemagic.ContentType枚举类查看常用的mimeType(媒体类型)。通过扩展名得到mimeType,代码如下:
// 根据扩展名取出mimeType
ContentInfo extensionMatch = ContentInfoUtil.findExtensionMatch(".mp4");
String mimeType = MediaType.APPLICATION_OCTET_STREAM_VALUE;// 通用mimeType,字节流校验文件的完整性,对文件计算出md5值,比较原始文件的md5和目标文件的md5,一致则说明完整:
//校验文件的完整性对文件的内容进行md5
FileInputStream fileInputStream1 = new FileInputStream(new File("D:\\develop\\upload\\1.mp4"));
String source_md5 = DigestUtils.md5Hex(fileInputStream1);
FileInputStream fileInputStream = new FileInputStream(new File("D:\\develop\\upload\\1a.mp4"));
String local_md5 = DigestUtils.md5Hex(fileInputStream);
if(source_md5.equals(local_md5)){System.out.println("下载成功");
}下面是完整的测试代码:
package com.xuecheng.media;import com.j256.simplemagic.ContentInfo;
import com.j256.simplemagic.ContentInfoUtil;
import io.minio.*;
import org.apache.commons.codec.digest.DigestUtils;import org.apache.commons.compress.utils.IOUtils;
import org.junit.jupiter.api.Test;
import org.springframework.http.MediaType;
import java.io.*;public class MinioTest {// 初始化minioClientMinioClient minioClient =MinioClient.builder().endpoint("http://192.168.56.1:9000").credentials("minioadmin", "minioadmin").build();@Testpublic void test_upload() throws Exception {// 通过扩展名得到媒体资源类型 mimeType// 根据扩展名取出mimeTypeContentInfo extensionMatch = ContentInfoUtil.findExtensionMatch(".mp4");String mimeType = MediaType.APPLICATION_OCTET_STREAM_VALUE;// 通用mimeType,字节流if(extensionMatch != null){mimeType = extensionMatch.getMimeType();}// 上传文件的参数信息UploadObjectArgs uploadObjectArgs = UploadObjectArgs.builder().bucket("testbucket")// 桶.filename("C:\\Users\\Eleven\\Videos\\4月16日.mp4") // 指定本地文件路径
// .object("1.mp4")// 对象名在桶下存储该文件.object("test/01/1.mp4")// 对象名 放在子目录下.contentType(mimeType)// 设置媒体文件类型.build();// 上传文件minioClient.uploadObject(uploadObjectArgs);}// 删除文件@Testpublic void test_delete() throws Exception {//RemoveObjectArgsRemoveObjectArgs removeObjectArgs = RemoveObjectArgs.builder().bucket("testbucket").object("test/01/1.mp4").build();// 删除文件minioClient.removeObject(removeObjectArgs);}// 查询文件 从minio中下载@Testpublic void test_getFile() throws Exception {GetObjectArgs getObjectArgs = GetObjectArgs.builder().bucket("testbucket").object("test/01/1.mp4").build();//查询远程服务获取到一个流对象FilterInputStream inputStream = minioClient.getObject(getObjectArgs);//指定输出流FileOutputStream outputStream = new FileOutputStream(new File("D:\\develop\\upload\\1a.mp4"));IOUtils.copy(inputStream,outputStream);//校验文件的完整性对文件的内容进行md5FileInputStream fileInputStream1 = new FileInputStream(new File("D:\\develop\\upload\\1.mp4"));String source_md5 = DigestUtils.md5Hex(fileInputStream1);FileInputStream fileInputStream = new FileInputStream(new File("D:\\develop\\upload\\1a.mp4"));String local_md5 = DigestUtils.md5Hex(fileInputStream);if(source_md5.equals(local_md5)){System.out.println("下载成功");}}
}3.图片操作:
上传课程图片总体上包括两部分:
1、上传课程图片前端请求媒资管理服务将文件上传至分布式文件系统,并且在媒资管理数据库保存文件信息。
2、上传图片成功保存图片地址到课程基本信息表中。
详细流程如下:
1、前端进入上传图片界面
2、上传图片,请求媒资管理服务。
3、媒资管理服务将图片文件存储在MinIO。
4、媒资管理记录文件信息到数据库。
5、前端请求内容管理服务保存课程信息,在内容管理数据库保存图片地址。


首先在minio配置bucket,bucket名称为:mediafiles,并设置bucket的权限为公开。

在nacos配置中minio的相关信息,进入media-service-dev.yaml:
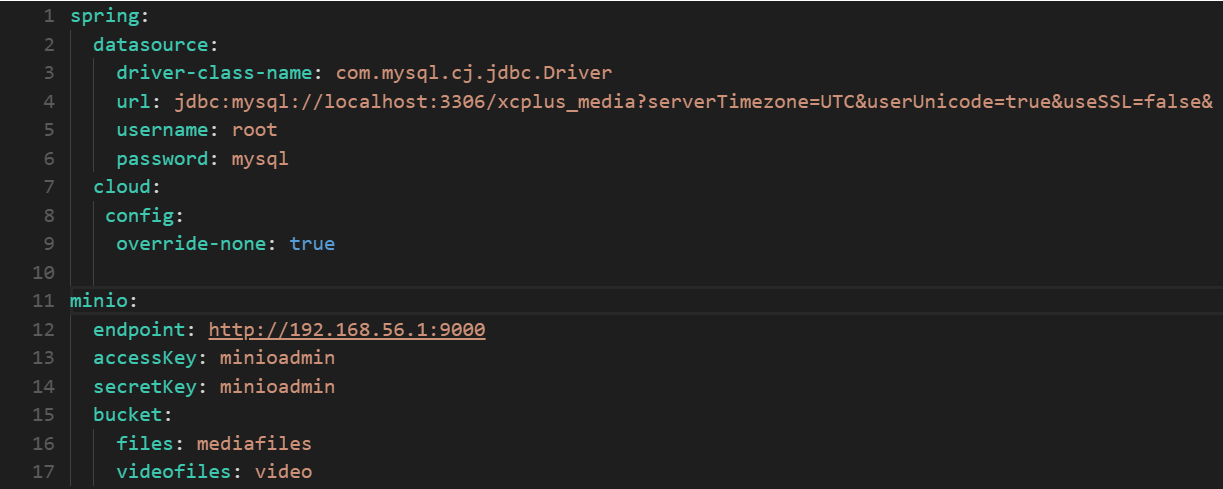
配置信息如下:
minio:endpoint: http://192.168.56.1:9000accessKey: minioadminsecretKey: minioadminbucket:files: mediafilesvideofiles: video(1)MinioConfig 配置类:
package com.xuecheng.media.config;import io.minio.MinioClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** @author eleven* @version 1.0* @description TODO* @date 2025/6/4 15:00*/
@Configuration
public class MinioConfig {@Value("${minio.endpoint}")private String endpoint;@Value("${minio.accessKey}")private String accessKey;@Value("${minio.secretKey}")private String secretKey;@Beanpublic MinioClient minioClient() {MinioClient minioClient = MinioClient.builder().endpoint(endpoint).credentials(accessKey, secretKey).build();return minioClient;}
}
(2)Controller 接口定义:
根据需求分析,下边进行接口定义,此接口定义为一个通用的上传文件接口,可以上传图片或其它文件。
首先分析接口:
请求地址:/media/upload/coursefile
请求内容:Content-Type: multipart/form-data;
因为无法直接获取上传文件的本地路径,所以创建临时文件作为中转,临时文件名以"minio"为前缀,".temp"为后缀。
package com.xuecheng.media.api;import com.xuecheng.base.model.PageParams;
import com.xuecheng.base.model.PageResult;
import com.xuecheng.media.model.dto.QueryMediaParamsDto;
import com.xuecheng.media.model.dto.UploadFileParamsDto;
import com.xuecheng.media.model.dto.UploadFileResultDto;
import com.xuecheng.media.model.po.MediaFiles;
import com.xuecheng.media.service.MediaFileService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;import java.io.File;
import java.io.IOException;/*** @description 媒资文件管理接口* @author eleven* @version 1.0*/@Tag(name = "媒资文件管理接口",description = "媒资文件管理接口")@RestController
public class MediaFilesController {@AutowiredMediaFileService mediaFileService;@Operation(summary = "上传图片")@RequestMapping(value = "/upload/coursefile",consumes = MediaType.MULTIPART_FORM_DATA_VALUE)public UploadFileResultDto upload(@RequestPart("filedata") MultipartFile filedata) throws IOException {// 准备上传文件的信息UploadFileParamsDto uploadFileParamsDto = new UploadFileParamsDto();// 原始文件名称uploadFileParamsDto.setFilename(filedata.getOriginalFilename());// 文件大小uploadFileParamsDto.setFileSize(filedata.getSize());// 文件类型uploadFileParamsDto.setFileType("001001"); // 自定义的字典,001001代表图片// 因为无法直接获得该文件的路径,所以创建一个临时文件File tempFile = File.createTempFile("minio", ".temp");filedata.transferTo(tempFile); // 拷贝文件Long companyId = 1232141425L;// 文件路径String localFilePath = tempFile.getAbsolutePath();//调用service上传图片UploadFileResultDto uploadFileResultDto = mediaFileService.uploadFile(companyId, uploadFileParamsDto, localFilePath);return uploadFileResultDto;}
}
(3)Service开发:
这里分几个方法进行开发:
【1】根据扩展名获取mimeType:
/*** 根据扩展名获取mimeType*/
private String getMimeType(String extension){if(extension == null){extension = "";}// 根据扩展名取出mimeTypeContentInfo extensionMatch = ContentInfoUtil.findExtensionMatch(extension);String mimeType = MediaType.APPLICATION_OCTET_STREAM_VALUE;//通用mimeType,字节流if(extensionMatch != null){mimeType = extensionMatch.getMimeType();}return mimeType;
}【2】将文件上传到minio:
/*** 将文件上传到minio* @param localFilePath 文件本地路径* @param mimeType 媒体类型* @param bucket 桶* @param objectName 对象名* @return*/
public boolean addMediaFilesToMinIO(String localFilePath,String mimeType,String bucket, String objectName){try {UploadObjectArgs uploadObjectArgs = UploadObjectArgs.builder().bucket(bucket)//桶.filename(localFilePath) //指定本地文件路径.object(objectName)//对象名 放在子目录下.contentType(mimeType)//设置媒体文件类型.build();//上传文件minioClient.uploadObject(uploadObjectArgs);log.debug("上传文件到minio成功,bucket:{},objectName:{}",bucket,objectName);return true;} catch (Exception e) {e.printStackTrace();log.error("上传文件出错,bucket:{},objectName:{},错误信息:{}",bucket,objectName,e.getMessage());}return false;
}【3】获取文件默认存储目录路径 年/ 月/ 日:
/*** 获取文件默认存储目录路径 年/月/日*/
private String getDefaultFolderPath() {SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");String folder = sdf.format(new Date()).replace("-", "/")+"/";return folder;
}【4】获取文件的md5:
/*** 获取文件的md5*/
private String getFileMd5(File file) {try (FileInputStream fileInputStream = new FileInputStream(file)) {String fileMd5 = DigestUtils.md5Hex(fileInputStream);return fileMd5;} catch (Exception e) {e.printStackTrace();return null;}
}随后 MediaFileServiceImpl 类创建方法实现上传图片并校验是否成功上传:
如果在uploadFile方法上添加@Transactional,当调用uploadFile方法前会开启数据库事务,如果上传文件过程时间较长那么数据库的事务持续时间就会变长,这样数据库链接释放就慢,最终导致数据库链接不够用。
我们只将addMediaFilesToDb方法添加事务控制即可,将该方法提取出来在 MediaFileTransactionalServiceImpl 中创建方法。
@Autowired
MediaFilesMapper mediaFilesMapper;@Autowired
MinioClient minioClient;@Autowired
private MediaFileTransactionalServiceImpl transactionalService; // 事务,操作数据库//存储普通文件
@Value("${minio.bucket.files}")
private String bucket_mediafiles;//存储视频
@Value("${minio.bucket.videofiles}")
private String bucket_video;@Override
public UploadFileResultDto uploadFile(Long companyId, UploadFileParamsDto uploadFileParamsDto, String localFilePath) {// 文件名String filename = uploadFileParamsDto.getFilename();// 先得到扩展名String extension = filename.substring(filename.lastIndexOf("."));// 根据扩展名得到mimeTypeString mimeType = getMimeType(extension);// 子目录String defaultFolderPath = getDefaultFolderPath();// 文件的md5值String fileMd5 = getFileMd5(new File(localFilePath));String objectName = defaultFolderPath+fileMd5+extension;// 上传文件到minioboolean result = addMediaFilesToMinIO(localFilePath, mimeType, bucket_mediafiles, objectName);if(!result){XueChengPlusException.cast("上传文件失败");}try {// 调用事务方法MediaFiles mediaFiles = transactionalService.addMediaFilesToDbWithTransaction(companyId, fileMd5, uploadFileParamsDto, bucket_mediafiles, objectName);UploadFileResultDto uploadFileResultDto = new UploadFileResultDto();BeanUtils.copyProperties(mediaFiles, uploadFileResultDto);return uploadFileResultDto;} catch (Exception e) {// 如果事务失败,尝试删除已上传的MinIO文件try {minioClient.removeObject(RemoveObjectArgs.builder().bucket(bucket_mediafiles).object(objectName).build());} catch (Exception ex) {log.error("回滚时删除MinIO文件失败", ex);}throw e;}
}而为了回滚数据库,我们在新建的 MediaFileTransactionalServiceImpl 类中创建:

package com.xuecheng.media.service.impl;import com.xuecheng.base.exception.XueChengPlusException;
import com.xuecheng.media.mapper.MediaFilesMapper;
import com.xuecheng.media.model.dto.UploadFileParamsDto;
import com.xuecheng.media.model.po.MediaFiles;
import com.xuecheng.media.service.MediaFileTransactionalService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.time.LocalDateTime;@Slf4j
@Service
public class MediaFileTransactionalServiceImpl implements MediaFileTransactionalService {@Autowiredprivate MediaFilesMapper mediaFilesMapper;/*** @description 将文件信息添加到文件表* @param companyId 机构id* @param fileMd5 文件md5值* @param uploadFileParamsDto 上传文件的信息* @param bucket 桶* @param objectName 对象名称* @return com.xuecheng.media.model.po.MediaFiles* @author Mr.M* @date 2022/10/12 21:22*/@Override@Transactional(rollbackFor = Exception.class)public MediaFiles addMediaFilesToDbWithTransaction(Long companyId, String fileMd5,UploadFileParamsDto uploadFileParamsDto,String bucket, String objectName) {// 原addMediaFilesToDb方法内容MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);if(mediaFiles == null){mediaFiles = new MediaFiles();BeanUtils.copyProperties(uploadFileParamsDto,mediaFiles);mediaFiles.setId(fileMd5);mediaFiles.setCompanyId(companyId);mediaFiles.setBucket(bucket);mediaFiles.setFilePath(objectName);mediaFiles.setFileId(fileMd5);mediaFiles.setUrl("/" + bucket + "/" + objectName);mediaFiles.setCreateDate(LocalDateTime.now());mediaFiles.setStatus("1");mediaFiles.setAuditStatus("002003");int insert = mediaFilesMapper.insert(mediaFiles);if(insert <= 0){log.error("向数据库保存文件失败,bucket:{},objectName:{}",bucket,objectName);throw new XueChengPlusException("保存文件信息失败"); // 触发回滚}}return mediaFiles;}
}4.视频操作:
(1)断点上传:
通常视频文件都比较大,所以对于媒资系统上传文件的需求要满足大文件的上传要求。http协议本身对上传文件大小没有限制,但是客户的网络环境质量、电脑硬件环境等参差不齐,如果一个大文件快上传完了网断了没有上传完成,需要客户重新上传,用户体验非常差,所以对于大文件上传的要求最基本的是断点续传。
什么是断点续传?
引用百度百科:断点续传指的是在下载或上传时,将下载或上传任务(一个文件或一个压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传下载未完成的部分,而没有必要从头开始上传下载,断点续传可以提高节省操作时间,提高用户体验性。
断点续传流程如下图:
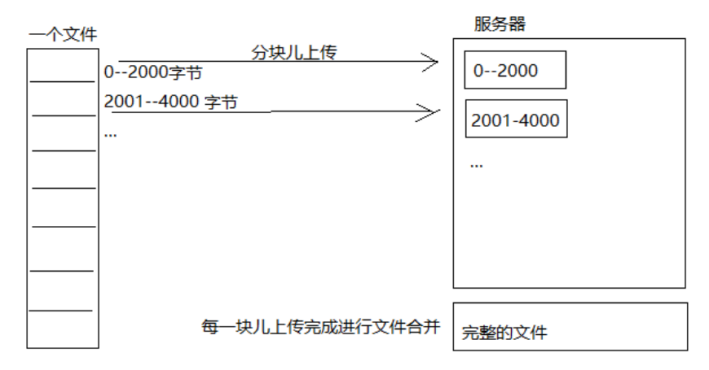
流程如下:
1、前端上传前先把文件分成块
2、一块一块的上传,上传中断后重新上传,已上传的分块则不用再上传
3、各分块上传完成最后在服务端合并文件
(2)测试文件分块上传与合并:
为了更好的理解文件分块上传的原理,下边用java代码测试文件的分块与合并。
文件分块的流程如下:
1、获取源文件长度
2、根据设定的分块文件的大小计算出块数
3、从源文件读数据依次向每一个块文件写数据。
而为了实现文件分块,需要使用 RandomAccessFile。
RandomAccessFile是 Java 提供的 随机访问文件 类,允许对文件进行 任意位置读写,适用于大文件分块、断点续传、数据库索引等场景。构造方法:
// 模式: // "r" : 只读 // "rw": 读写(文件不存在则自动创建) // "rws": 读写 + 同步写入元数据(强制刷盘) // "rwd": 读写 + 同步写入文件内容(强制刷盘) RandomAccessFile raf = new RandomAccessFile(File file, String mode); RandomAccessFile raf = new RandomAccessFile(String path, String mode);操作指针:
方法 作用 long getFilePointer()返回当前指针位置 void seek(long pos)移动指针到指定位置 long length()返回文件长度 void setLength(long newLength)扩展/截断文件 读写数据:
方法 说明 int read()读取1字节(返回 0~255,失败返回-1)int read(byte[] b)读取数据到字节数组 readInt(),readDouble()读取基本类型 write(byte[] b)写入字节数组 writeInt(),writeUTF()写入基本类型或字符串
【1】分块上传:
流程分析:
①初始化阶段
- 设置源文件路径和分块存储目录,自动创建不存在的目录
- 定义每个分块大小为1MB,并根据文件总大小计算所需分块数量
- 初始化1KB的读写缓冲区:byte[] b = new byte[1024];
②文件读取准备
- 使用 RandomAccessFile 以只读模式(r)打开源文件
- 文件指针自动记录读取位置,确保连续性
③分块处理核心流程
- 循环创建每个分块文件,先删除已存在的旧文件
- 为每个分块创建新的 RandomAccessFile 写入流(rw)
- 通过缓冲区循环读取源文件数据,写入分块文件
- 实时检查分块文件大小,达到1MB立即切换下一个分块
④收尾工作
- 每个分块写入完成后立即关闭文件流
- 所有分块处理完毕后关闭源文件流
package com.xuecheng.media;import org.apache.commons.codec.digest.DigestUtils;
import org.apache.commons.io.IOUtils;
import org.junit.jupiter.api.Test;import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.*;/*** @author eleven* @version 1.0* @description 大文件处理测试*/
public class BigFileTest {/*** 测试文件分块方法*/@Testpublic void testChunk() throws IOException {File sourceFile = new File("d:/develop/bigfile_test/nacos.mp4");String chunkPath = "d:/develop/bigfile_test/chunk/";File chunkFolder = new File(chunkPath); // 分块地址文件if (!chunkFolder.exists()) {chunkFolder.mkdirs(); // 不存在则创建}// 分块大小long chunkSize = 1024 * 1024 * 1;// 分块数量 (向上取整)long chunkNum = (long) Math.ceil(sourceFile.length() * 1.0 / chunkSize);System.out.println("分块总数:" + chunkNum);// 缓冲区大小byte[] b = new byte[1024];// 使用流从源文件中读数据,向分块文件中写数据// 使用RandomAccessFile访问文件RandomAccessFile raf_read = new RandomAccessFile(sourceFile, "r"); // r:允许对文件进行读操作// 分块for (int i = 0; i < chunkNum; i++) {// 创建分块文件File file = new File(chunkPath + i);if(file.exists()){file.delete(); // 确保每个文件都是重新生成}boolean newFile = file.createNewFile(); // 在指定路径下创建一个空的物理文件// 如果文件已存在(尽管前面有 file.delete(),但极端情况下可能删除失败)// createNewFile() 会返回 false,防止后续 RandomAccessFile 仍会覆盖写入if (newFile) {// 在 RandomAccessFile 中,文件指针(File Pointer) 会自动记录当前读写位置// 确保每次 read() 或 write() 操作都会从上次结束的位置继续。// 创建分块文件写入流,向分块文件中写数据RandomAccessFile raf_write = new RandomAccessFile(file, "rw"); // rw:允许对文件进行读写操作int len = -1;// 从源文件(raf_read)读取数据到缓冲区 byte[] b,每次最多读取 1024 字节(缓冲区大小)// len 返回实际读取的字节数,如果 len = -1 表示源文件已读完while ((len = raf_read.read(b)) != -1) {// 将缓冲区 b 中的数据读取并写入目标文件(分块文件file),写入范围是 [0, len),确保只写入有效数据raf_write.write(b, 0, len);// 确保每个分块文件不超过指定大小chunkSizeif (file.length() >= chunkSize) {break;}}raf_write.close();System.out.println("完成分块"+i);}}raf_read.close();}
}【2】合并分块文件:
流程分析:
- 初始化阶段:检查并创建合并文件,初始化写入流和缓冲区(1KB),获取所有分块文件并按文件名数字排序,确保按原始顺序合并。
- 文件合并阶段:
- 遍历每个分块文件,使用
RandomAccessFile读取数据到缓冲区- 通过
seek(0)确保每次从分块文件头部读取- 将缓冲区数据写入合并文件,循环直到当前分块读取完毕
- 资源释放:每个分块处理完后立即关闭流,全部合并后关闭写入流。
- 完整性校验:
- 使用
FileInputStream读取原始文件和合并文件的二进制内容- 通过
DigestUtils.md5Hex()计算MD5哈希值比对- 完全一致则判定合并成功
package com.xuecheng.media;import org.apache.commons.codec.digest.DigestUtils;
import org.apache.commons.io.IOUtils;
import org.junit.jupiter.api.Test;import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.*;/*** @author eleven* @version 1.0* @description 大文件处理测试*/
public class BigFileTest {/*** 测试文件合并方法*/@Testpublic void testMerge() throws IOException {// 块文件目录File chunkFolder = new File("d:/develop/bigfile_test/chunk/");// 原始文件File originalFile = new File("d:/develop/bigfile_test/nacos.mp4");// 合并文件File mergeFile = new File("d:/develop/bigfile_test/nacos01.mp4");if (mergeFile.exists()) {mergeFile.delete();}// 创建新的合并文件mergeFile.createNewFile();// 用于写文件RandomAccessFile raf_write = new RandomAccessFile(mergeFile, "rw");// 指针指向文件顶端raf_write.seek(0);// 缓冲区byte[] b = new byte[1024];// 分块列表File[] fileArray = chunkFolder.listFiles();// 转成集合,便于排序List<File> fileList = Arrays.asList(fileArray);// 从小到大排序Collections.sort(fileList, new Comparator<File>() {@Overridepublic int compare(File o1, File o2) {return Integer.parseInt(o1.getName()) - Integer.parseInt(o2.getName());}});// 合并文件for (File chunkFile : fileList) {RandomAccessFile raf_read = new RandomAccessFile(chunkFile, "rw");int len = -1;while ((len = raf_read.read(b)) != -1) {raf_write.write(b, 0, len);}raf_read.close();}raf_write.close();//校验文件try (FileInputStream fileInputStream = new FileInputStream(originalFile);FileInputStream mergeFileStream = new FileInputStream(mergeFile);) {//取出原始文件的md5String originalMd5 = DigestUtils.md5Hex(fileInputStream);//取出合并文件的md5进行比较String mergeFileMd5 = DigestUtils.md5Hex(mergeFileStream);if (originalMd5.equals(mergeFileMd5)) {System.out.println("合并文件成功");} else {System.out.println("合并文件失败");}}}
}(3)使用MinIO合并分块:
【1】将分块文件上传至minio:
// 测试方法:将本地分块文件上传至MinIO对象存储
@Test
public void uploadChunk() {// 1. 初始化分块文件目录String chunkFolderPath = "D:\\develop\\upload\\chunk\\"; // 本地分块文件存储路径File chunkFolder = new File(chunkFolderPath); // 创建文件对象表示该目录// 2. 获取所有分块文件File[] files = chunkFolder.listFiles(); // 列出目录下所有文件(分块文件)// 3. 遍历并上传每个分块文件for (int i = 0; i < files.length; i++) {try {// 3.1 构建上传参数对象UploadObjectArgs uploadObjectArgs = UploadObjectArgs.builder().bucket("testbucket") // 设置目标存储桶名称.object("chunk/" + i) // 设置对象存储路径(格式:chunk/0, chunk/1...).filename(files[i].getAbsolutePath()) // 设置本地文件绝对路径.build(); // 构建上传参数// 3.2 执行上传操作minioClient.uploadObject(uploadObjectArgs); // 调用MinIO客户端上传文件// 3.3 打印上传成功日志System.out.println("上传分块成功" + i); // 标识当前上传的分块序号} catch (Exception e) {// 3.4 捕获并打印上传异常e.printStackTrace(); // 打印异常堆栈(如网络问题、权限不足等)}}
}【2】合并文件,要求分块文件最小5M:
//合并文件,要求分块文件最小5M
@Test
public void test_merge() throws Exception {List<ComposeSource> sources =Stream.iterate(0, i -> ++i) // 从0开始生成无限递增序列.limit(6) // 限制取前6个元素(0-5).map(i -> ComposeSource.builder() // 将每个整数映射为ComposeSource对象.bucket("testbucket") // 设置存储桶名.object("chunk/" + i) // 设置分块对象路径.build()) // 构建ComposeSource.collect(Collectors.toList()); // 收集为List// 合并操作构建对象ComposeObjectArgs composeObjectArgs = ComposeObjectArgs.builder().bucket("testbucket").object("merge01.mp4") // 合并后的文件名.sources(sources).build(); // 要合并的分块文件列表minioClient.composeObject(composeObjectArgs);
}【3】清除分块文件:
// 测试方法:清除MinIO中的分块文件
@Test
public void test_removeObjects() {// 1. 准备待删除的分块文件列表// 使用Stream API生成0-5的序列,构建DeleteObject列表List<DeleteObject> deleteObjects = Stream.iterate(0, i -> ++i) // 生成无限递增序列(0,1,2...).limit(6) // 限制只处理前6个分块(0-5).map(i -> new DeleteObject( // 将每个数字转为DeleteObject"chunk/".concat(Integer.toString(i)) // 构造分块路径格式:chunk/0, chunk/1...)).collect(Collectors.toList()); // 收集为List// 2. 构建删除参数对象RemoveObjectsArgs removeObjectsArgs = RemoveObjectsArgs.builder().bucket("testbucket") // 设置目标存储桶.objects(deleteObjects) // 设置要删除的对象列表.build(); // 构建参数对象// 3. 执行批量删除操作// 返回一个包含删除结果的Iterable对象(可能包含成功/失败信息)Iterable<Result<DeleteError>> results = minioClient.removeObjects(removeObjectsArgs);// 4. 处理删除结果(检查是否有删除失败的记录)results.forEach(r -> {DeleteError deleteError = null;try {// 获取单个删除操作的结果(如果删除失败会抛出异常)deleteError = r.get();// 如果deleteError不为null,表示对应文件删除失败} catch (Exception e) {// 打印删除过程中出现的异常(如网络问题、权限不足等)e.printStackTrace();}});
}(4)三层架构——上传分块:
下图是上传视频的整体流程:
1、前端对文件进行分块。
2、前端上传分块文件前请求媒资服务检查文件是否存在,如果已经存在则不再上传。
3、如果分块文件不存在则前端开始上传
4、前端请求媒资服务上传分块。
5、媒资服务将分块上传至MinIO。
6、前端将分块上传完毕请求媒资服务合并分块。
7、媒资服务判断分块上传完成则请求MinIO合并文件。
8、合并完成校验合并后的文件是否完整,如果不完整则删除文件。
其实整体实现无外乎就是将逻辑由一个文件的操作变为多文件操作。
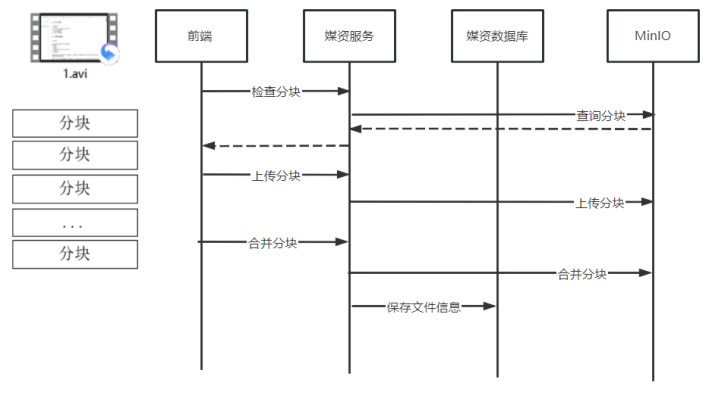
【1】检查文件是否存在:
/*** 文件上传前检查文件是否存在(基于文件MD5值)* @param fileMd5 文件的MD5哈希值(用于唯一标识文件)* @return RestResponse<Boolean> 封装检查结果(true=文件已存在,false=文件不存在)*/
@Override
public RestResponse<Boolean> checkFile(String fileMd5) {// 1. 根据文件MD5查询数据库中的文件记录MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);// 2. 如果数据库中存在该文件记录,则进一步检查MinIO存储中是否真实存在该文件if (mediaFiles != null) {// 从数据库记录中获取MinIO存储的桶名称String bucket = mediaFiles.getBucket();// 从数据库记录中获取MinIO中的文件路径(对象键)String filePath = mediaFiles.getFilePath();// 3. 初始化文件输入流(用于检查文件是否存在)InputStream stream = null;try {// 4. 通过MinIO客户端API获取文件对象// - 使用GetObjectArgs构建获取对象的参数// - .bucket(bucket) 指定存储桶// - .object(filePath) 指定对象路径stream = minioClient.getObject(GetObjectArgs.builder().bucket(bucket).object(filePath).build());// 5. 如果成功获取到输入流(不为null),说明文件确实存在于MinIO中if (stream != null) {// 文件已存在,返回成功响应(true)return RestResponse.success(true);}} catch (Exception e) {// 6. 捕获并处理可能发生的异常(如网络问题、MinIO服务不可用、权限问题等)// - 使用自定义异常处理器抛出业务异常// - 异常信息会包含具体的错误详情XueChengPlusException.cast(e.getMessage());} finally {// 7. 资源清理:确保输入流被正确关闭(防止资源泄漏)if (stream != null) {try {stream.close();} catch (IOException e) {// 关闭流时的异常可以记录日志,但不需要中断业务流程log.error("关闭MinIO文件流失败", e);}}}}// 8. 如果数据库中没有记录 或 MinIO中不存在文件,则返回文件不存在return RestResponse.success(false);
}【2】文件上传前检查分块文件是否存在:
首先我们保存分块文件的路径格式如下:
假设
fileMd5 = "d41d8cd98f00b204e9800998ecf8427e"(一个标准的32位MD5值),生成的路径会是:d/4/d41d8cd98f00b204e9800998ecf8427e/chunk/即:
- 第1级目录:
d(MD5的第1个字符)- 第2级目录:
4(MD5的第2个字符)- 第3级目录:完整的MD5值(
d41d8cd98f00b204e9800998ecf8427e)- 第4级目录:固定字符串
chunk最终路径示例:
d/4/d41d8cd98f00b204e9800998ecf8427e/chunk/
所以获取路径代码为:
// 得到分块文件的目录 private String getChunkFileFolderPath(String fileMd5) {return fileMd5.substring(0, 1) + "/" + fileMd5.substring(1, 2) + "/" + fileMd5 + "/" + "chunk" + "/"; }

下面为检查分块文件是否存在代码:
/*** 文件上传前检查指定分块文件是否存在(用于大文件分片上传的断点续传/秒传功能)* @param fileMd5 文件的MD5值(用于唯一标识整个文件)* @param chunkIndex 当前分块的序号(从0开始或从1开始,需与前端约定一致)* @return RestResponse<Boolean> 封装检查结果(true=分块已存在,false=分块不存在)*/
@Override
public RestResponse<Boolean> checkChunk(String fileMd5, int chunkIndex) {// 1. 根据文件MD5生成分块存储目录路径// 例如:/chunks/{fileMd5}/ 这样的目录结构,用于按文件分组存储分块String chunkFileFolderPath = getChunkFileFolderPath(fileMd5);// 2. 拼接完整的分块文件路径// 例如:/chunks/{fileMd5}/1 表示文件MD5为{fileMd5}的第1个分块String chunkFilePath = chunkFileFolderPath + chunkIndex;// 3. 初始化文件输入流(用于检查分块是否存在)InputStream fileInputStream = null;try {// 4. 通过MinIO客户端API尝试获取分块对象// - 使用GetObjectArgs构建获取对象的参数// - .bucket(bucket_videofiles) 指定存储桶(视频文件专用桶)// - .object(chunkFilePath) 指定分块对象路径fileInputStream = minioClient.getObject(GetObjectArgs.builder().bucket(bucket_videofiles).object(chunkFilePath).build());// 5. 如果成功获取到输入流(不为null),说明分块确实存在于MinIO中if (fileInputStream != null) {// 分块已存在,返回成功响应(true)return RestResponse.success(true);}} catch (Exception e) {// 6. 捕获并处理可能发生的异常// - NoSuchKeyException:分块不存在(MinIO特定异常)// - 其他异常:可能是网络问题、MinIO服务不可用、权限问题等// 当前实现只是打印堆栈跟踪,建议:// 1. 使用日志框架记录异常(如SLF4J)// 2. 区分不同类型的异常返回更精确的响应e.printStackTrace();} finally {// 7. 资源清理:确保输入流被正确关闭(防止资源泄漏)if (fileInputStream != null) {try {fileInputStream.close();} catch (IOException e) {// 关闭流时的异常可以记录日志,但不需要中断业务流程e.printStackTrace();}}}// 8. 如果MinIO中不存在分块(或发生异常),返回文件不存在return RestResponse.success(false);
}【3】上传分块文件:
首先根据扩展名获取mimeType:
如果传入的extension为空,那么就使用通用的mimeType字节流:
String APPLICATION_OCTET_STREAM_VALUE = "application/octet-stream";
/*** 根据扩展名获取mimeType*/
private String getMimeType(String extension){if(extension == null){extension = "";}// 根据扩展名取出mimeTypeContentInfo extensionMatch = ContentInfoUtil.findExtensionMatch(extension);String mimeType = MediaType.APPLICATION_OCTET_STREAM_VALUE;// 通用mimeType,字节流if(extensionMatch != null){mimeType = extensionMatch.getMimeType();}return mimeType;
}随后编写 addMediaFilesToMinIO 上传文件方法:
/*** 将文件上传到minio* @param localFilePath 文件本地路径* @param mimeType 媒体类型* @param bucket 桶* @param objectName 对象名* @return*/
public boolean addMediaFilesToMinIO(String localFilePath,String mimeType,String bucket, String objectName){try {UploadObjectArgs uploadObjectArgs = UploadObjectArgs.builder().bucket(bucket) // 桶.filename(localFilePath) // 指定本地文件路径.object(objectName) // 对象名 放在子目录下.contentType(mimeType) // 设置媒体文件类型.build();// 上传文件minioClient.uploadObject(uploadObjectArgs);log.debug("上传文件到minio成功,bucket:{},objectName:{}",bucket,objectName);return true;} catch (Exception e) {e.printStackTrace();log.error("上传文件出错,bucket:{},objectName:{},错误信息:{}",bucket,objectName,e.getMessage());}return false;
}整体调用:
@Override
public RestResponse uploadChunk(String fileMd5, int chunk, String localChuckFilePath) {// 得到分块文件的目录路径String chunkFileFolderPath = getChunkFileFolderPath(fileMd5);// 得到分块文件的路径String chunkFilePath = chunkFileFolderPath + chunk;String mimeType = getMimeType(null);boolean b = addMediaFilesToMinIO(localChuckFilePath, mimeType, bucket_mediafiles, chunkFilePath);if(!b){return RestResponse.validfail(false,"上传分块文件失败");}return RestResponse.success(true);
}(4) 三层架构——清除分块文件:
/*** 清除分块文件* @param chunkFileFolderPath 分块文件路径* @param chunkTotal 分块文件总数*/
private void clearChunkFiles(String chunkFileFolderPath, int chunkTotal) {try {// 使用Stream生成从0到chunkTotal-1的整数序列// 每个整数代表一个分块文件的序号List<DeleteObject> deleteObjects = Stream.iterate(0, i -> ++i)// 限制流的大小为chunkTotal,即只生成chunkTotal个序号.limit(chunkTotal)// 将每个序号转换为对应的DeleteObject对象// 文件名格式为:chunkFileFolderPath + 序号(转换为字符串).map(i -> new DeleteObject(chunkFileFolderPath.concat(Integer.toString(i))))// 将所有DeleteObject对象收集到一个List中.collect(Collectors.toList());// 构建删除对象的参数// 指定存储桶名称为"video"// 设置要删除的对象列表RemoveObjectsArgs removeObjectsArgs = RemoveObjectsArgs.builder().bucket("video").objects(deleteObjects).build();// 执行批量删除操作,返回一个包含删除结果的IterableIterable<Result<DeleteError>> results = minioClient.removeObjects(removeObjectsArgs);// 遍历删除结果results.forEach(r -> {DeleteError deleteError = null;try {// 获取删除操作的错误信息(如果有)deleteError = r.get();if (deleteError != null) {log.error("清除分块文件失败,objectname:{}", deleteError.objectName(), deleteError);} else {log.error("清除分块文件失败,但未获取到具体的错误信息");}} catch (Exception e) {// 如果获取错误信息时发生异常,打印堆栈并记录错误日志e.printStackTrace();// 记录错误日志,包含出错的对象名和异常信息log.error("清楚分块文件失败,objectname:{}", deleteError.objectName(), e);}});} catch (Exception e) {// 如果整个删除过程中发生异常,打印堆栈并记录错误日志e.printStackTrace();// 记录错误日志,包含分块文件路径和异常信息log.error("清楚分块文件失败,chunkFileFolderPath:{}", chunkFileFolderPath, e);}
}(5)三层架构——从MinIO下载文件:
/*** 从MinIO下载文件* @param bucket 桶名称* @param objectName 对象在桶中的名称* @return 下载后的文件(临时文件),如果下载失败则返回null*/
public File downloadFileFromMinIO(String bucket, String objectName) {// 创建临时文件用于存储下载的内容File minioFile = null;// 使用try-with-resources确保InputStream和FileOutputStream都能正确关闭// 这样可以避免资源泄漏,无需在finally块中手动关闭try (// 从MinIO获取对象(文件)的输入流InputStream stream = minioClient.getObject(GetObjectArgs.builder().bucket(bucket) // 指定桶名称.object(objectName) // 指定对象名称.build());// 创建文件输出流,用于将下载的内容写入临时文件FileOutputStream outputStream = new FileOutputStream(minioFile)) {// 创建临时文件// 文件名前缀为"minio",后缀为".merge"minioFile = File.createTempFile("minio", ".merge");// 使用IOUtils工具类将输入流的内容复制到输出流// 这样可以高效地将文件内容从MinIO传输到本地临时文件IOUtils.copy(stream, outputStream);// 返回下载的临时文件return minioFile;} catch (Exception e) {// 如果下载过程中发生任何异常,打印堆栈跟踪e.printStackTrace();// 可以添加更详细的日志记录log.error("从MinIO下载文件失败,bucket: {}, objectName: {}", bucket, objectName, e);// 下载失败,返回nullreturn null;}// 注意:由于使用了try-with-resources,不再需要finally块来手动关闭资源// 资源会在try块结束时自动关闭
}(6)三层架构——合并分块文件:
首先得到合并后的地址:

/*** 得到合并后的文件的地址* @param fileMd5 文件id即md5值* @param fileExt 文件扩展名* @return*/
private String getFilePathByMd5(String fileMd5,String fileExt){return fileMd5.substring(0,1) + "/" + fileMd5.substring(1,2) + "/" + fileMd5 + "/" +fileMd5 +fileExt;
}
随后调用方法:
/*** 合并文件分块为完整文件(用于大文件分片上传的最终合并阶段)* * @param companyId 公司ID(用于业务关联)* @param fileMd5 文件的MD5值(用于唯一标识整个文件)* @param chunkTotal 分块总数(用于确定需要合并的分块数量)* @param uploadFileParamsDto 文件上传参数DTO(包含文件名等信息)* @return RestResponse<Boolean> 封装合并结果(true=合并成功,false=合并失败)*/
@Override
public RestResponse mergechunks(Long companyId, String fileMd5, int chunkTotal, UploadFileParamsDto uploadFileParamsDto) {// =====获取分块文件路径=====// 根据文件MD5生成分块存储的目录路径(如:/chunks/{fileMd5}/)String chunkFileFolderPath = getChunkFileFolderPath(fileMd5);// 组成将分块文件路径组成 List<ComposeSource>// 使用Stream生成从0到chunkTotal-1的分块索引列表// 为每个分块构建ComposeSource对象(包含bucket和object路径信息)List<ComposeSource> sourceObjectList = Stream.iterate(0, i -> ++i).limit(chunkTotal).map(i -> ComposeSource.builder().bucket(bucket_videofiles) // 指定存储桶(视频文件专用桶).object(chunkFileFolderPath.concat(Integer.toString(i))) // 构建分块路径(如:/chunks/{fileMd5}/0).build()).collect(Collectors.toList());// =====合并=====// 从DTO中获取原始文件名(如:"example.mp4")String fileName = uploadFileParamsDto.getFilename();// 提取文件扩展名(如:".mp4")String extName = fileName.substring(fileName.lastIndexOf("."));// 根据文件MD5和扩展名生成合并后的文件存储路径(如:/videos/{fileMd5}.mp4)String mergeFilePath = getFilePathByMd5(fileMd5, extName);try {// 调用MinIO的composeObject方法合并分块// 参数说明:// - bucket: 存储桶名称// - object: 合并后的文件路径// - sources: 待合并的分块列表ObjectWriteResponse response = minioClient.composeObject(ComposeObjectArgs.builder().bucket(bucket_videofiles).object(mergeFilePath) .sources(sourceObjectList).build());// 记录合并成功的日志log.debug("合并文件成功:{}", mergeFilePath);} catch (Exception e) {// 合并失败的异常处理log.debug("合并文件失败,fileMd5:{},异常:{}", fileMd5, e.getMessage(), e);return RestResponse.validfail(false, "合并文件失败。");}// ====验证md5====// 从MinIO下载合并后的文件到本地临时文件File minioFile = downloadFileFromMinIO(bucket_videofiles, mergeFilePath);if (minioFile == null) {// 下载失败的处理log.debug("下载合并后文件失败,mergeFilePath:{}", mergeFilePath);return RestResponse.validfail(false, "下载合并后文件失败。");}try (InputStream newFileInputStream = new FileInputStream(minioFile)) {// 计算下载文件的MD5值(用于校验文件完整性)String md5Hex = DigestUtils.md5Hex(newFileInputStream);// 比较计算出的MD5与原始MD5是否一致// 不一致说明文件在合并过程中可能损坏或不完整if (!fileMd5.equals(md5Hex)) {return RestResponse.validfail(false, "文件合并校验失败,最终上传失败。");}// 设置文件大小到DTO中(用于后续入库)uploadFileParamsDto.setFileSize(minioFile.length());} catch (Exception e) {// 文件校验过程中的异常处理log.debug("校验文件失败,fileMd5:{},异常:{}", fileMd5, e.getMessage(), e);return RestResponse.validfail(false, "文件合并校验失败,最终上传失败。");} finally {// 确保临时文件被删除(避免磁盘空间泄漏)if (minioFile != null) {minioFile.delete();}}// 文件入库// 将文件元数据(包括公司ID、MD5、文件参数等)事务性保存到数据库mediaFileTransactionalService.addMediaFilesToDbWithTransaction(companyId, fileMd5, uploadFileParamsDto, bucket_videofiles, mergeFilePath);// =====清除分块文件=====// 合并完成后删除所有分块文件(释放存储空间)clearChunkFiles(chunkFileFolderPath, chunkTotal);// 返回成功响应return RestResponse.success(true);
}5.视频转码:
视频上传成功后需要对视频进行转码处理。
什么是视频编码?查阅百度百科如下:

首先我们要分清文件格式和编码格式:
文件格式:是指.mp4、.avi、.rmvb等这些不同扩展名的视频文件的文件格式 ,视频文件的内容主要包括视频和音频,其文件格式是按照一定的编码格式去编码,并且按照该文件所规定的封装格式将视频、音频、字幕等信息封装在一起,播放器会根据它们的封装格式去提取出编码,然后由播放器解码,最终播放音视频。
音视频编码格式:通过音视频的压缩技术,将视频格式转换成另一种视频格式,通过视频编码实现流媒体的传输。比如:一个.avi的视频文件原来的编码是a,通过编码后编码格式变为b,音频原来为c,通过编码后变为d。
音视频编码格式各类繁多,主要有几下几类:
MPEG系列:
(由ISO[国际标准组织机构]下属的MPEG[运动图象专家组]开发 )视频编码方面主要是Mpeg1(vcd用的就是它)、Mpeg2(DVD使用)、Mpeg4(的DVDRIP使用的都是它的变种,如:divx,xvid等)、Mpeg4 AVC(正热门);音频编码方面主要是MPEG Audio Layer 1/2、MPEG Audio Layer 3(大名鼎鼎的mp3)、MPEG-2 AAC 、MPEG-4 AAC等等。注意:DVD音频没有采用Mpeg的。
H.26X系列:
(由ITU[国际电传视讯联盟]主导,侧重网络传输,注意:只是视频编码)
包括H.261、H.262、H.263、H.263+、H.263++、H.264(就是MPEG4 AVC-合作的结晶)
目前最常用的编码标准是视频H.264,音频AAC。
我们将视频录制完成后,使用视频编码软件对视频进行编码,本项目 使用FFmpeg对视频进行编码 。下载:FFmpeg Download FFmpeg
测试是否正常:cmd运行 ffmpeg -v:
安装成功,作下简单测试
将一个.avi文件转成mp4、mp3、gif等。
比如我们将nacos.avi文件转成mp4,运行如下命令:
D:\soft\ffmpeg\ffmpeg.exe -i 1.avi 1.mp4
可以将ffmpeg.exe配置到环境变量path中,进入视频目录直接运行:ffmpeg.exe -i 1.avi 1.mp4
转成mp3:ffmpeg -i nacos.avi nacos.mp3
转成gif:ffmpeg -i nacos.avi nacos.gif
官方文档(英文):ffmpeg Documentation
Mp4VideoUtil类是用于将视频转为mp4格式,是我们项目要使用的工具类。我们要通过ffmpeg对视频转码,Java程序调用ffmpeg,使用java.lang.ProcessBuilder去完成。
package com.xuecheng.base.utils;import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;public class Mp4VideoUtil extends VideoUtil {String ffmpeg_path = "D:\\Program Files\\ffmpeg-20180227-fa0c9d6-win64-static\\bin\\ffmpeg.exe";//ffmpeg的安装位置String video_path = "D:\\BaiduNetdiskDownload\\test1.avi";String mp4_name = "test1.mp4";String mp4folder_path = "D:/BaiduNetdiskDownload/Movies/test1/";public Mp4VideoUtil(String ffmpeg_path, String video_path, String mp4_name, String mp4folder_path){super(ffmpeg_path);this.ffmpeg_path = ffmpeg_path;this.video_path = video_path;this.mp4_name = mp4_name;this.mp4folder_path = mp4folder_path;}//清除已生成的mp4private void clear_mp4(String mp4_path){//删除原来已经生成的m3u8及ts文件File mp4File = new File(mp4_path);if(mp4File.exists() && mp4File.isFile()){mp4File.delete();}}/*** 视频编码,生成mp4文件* @return 成功返回success,失败返回控制台日志*/public String generateMp4(){//清除已生成的mp4
// clear_mp4(mp4folder_path+mp4_name);clear_mp4(mp4folder_path);/*ffmpeg.exe -i lucene.avi -c:v libx264 -s 1280x720 -pix_fmt yuv420p -b:a 63k -b:v 753k -r 18 .\lucene.mp4*/List<String> commend = new ArrayList<String>();//commend.add("D:\\Program Files\\ffmpeg-20180227-fa0c9d6-win64-static\\bin\\ffmpeg.exe");commend.add(ffmpeg_path);commend.add("-i");
// commend.add("D:\\BaiduNetdiskDownload\\test1.avi");commend.add(video_path);commend.add("-c:v");commend.add("libx264");commend.add("-y");//覆盖输出文件commend.add("-s");commend.add("1280x720");commend.add("-pix_fmt");commend.add("yuv420p");commend.add("-b:a");commend.add("63k");commend.add("-b:v");commend.add("753k");commend.add("-r");commend.add("18");
// commend.add(mp4folder_path + mp4_name );commend.add(mp4folder_path );String outstring = null;try {ProcessBuilder builder = new ProcessBuilder();builder.command(commend);//将标准输入流和错误输入流合并,通过标准输入流程读取信息builder.redirectErrorStream(true);Process p = builder.start();outstring = waitFor(p);} catch (Exception ex) {ex.printStackTrace();}
// Boolean check_video_time = this.check_video_time(video_path, mp4folder_path + mp4_name);Boolean check_video_time = this.check_video_time(video_path, mp4folder_path);if(!check_video_time){return outstring;}else{return "success";}}public static void main(String[] args) throws IOException {//ffmpeg的路径String ffmpeg_path = "tools/ffmpeg.exe";//ffmpeg的安装位置//源avi视频的路径String video_path = "D:\\develop\\bigfile_test\\nacos01.avi";//转换后mp4文件的名称String mp4_name = "nacos01.mp4";//转换后mp4文件的路径String mp4_path = "D:\\develop\\bigfile_test\\";//创建工具类对象Mp4VideoUtil videoUtil = new Mp4VideoUtil(ffmpeg_path,video_path,mp4_name,mp4_path);//开始视频转换,成功将返回successString s = videoUtil.generateMp4();System.out.println(s);}
}相关文章:
使用MinIO搭建自己的分布式文件存储
目录 引言: 一.什么是 MinIO ? 二.MinIO 的安装与部署: 三.Spring Cloud 集成 MinIO: 1.前提准备: (1)安装依赖: (2)配置MinIO连接: &…...

单元测试与QTestLib框架使用
一.单元测试的意义 在软件开发中,单元测试是指对软件中最小可测试单元(通常是函数、类的方法)进行隔离的、可重复的验证。进行单元测试具有以下重要意义: 1.提升代码质量与可靠性: 早期错误检测: 在开发…...

java面试场景题:QPS 短链系统怎么设计
以下是对文章的润色版本: 这道场景设计题,初看似乎业务简单,实则覆盖的知识点极为丰富: 高并发与高性能分布式 ID 生成机制;Redis Bloom Filter——高并发、低内存损耗的过滤组件知识;分库、分表海量数据存…...

java面试场景提题:
以下是润色后的文章,结构更清晰,语言更流畅,同时保留了技术细节: 应对百倍QPS增长的系统设计策略 整体架构设计思路 面对突发性百倍QPS增长,系统设计需从硬件、架构、代码、数据四个维度协同优化: 硬件层…...
K7 系列各种PCIE IP核的对比
上面三个IP 有什么区别,什么时候用呢? 7 series Integrated Block for PCIE AXI Memory Mapped to PCI Express DMA subsystem for PCI Express 特点 这是 Kintex-7 内置的 硬核 PCIe 模块。部分事务层也集成在里面,使用标准的PCIE 基本没…...
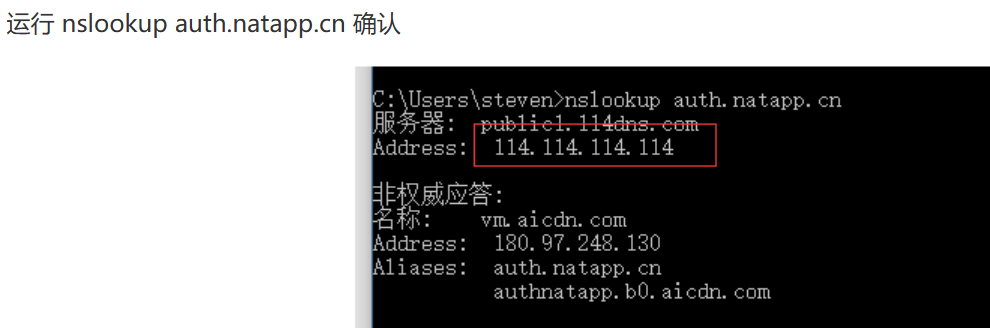
natapp 内网穿透失败
连不上网络错误调试排查详解 - NATAPP-内网穿透 基于ngrok的国内高速内网映射工具 如何将DNS服务器修改为114.114.114.114_百度知道 连不上/错误信息等问题解决汇总 - NATAPP-内网穿透 基于ngrok的国内高速内网映射工具 nslookup auth.natapp.cnping auth.natapp.cn...
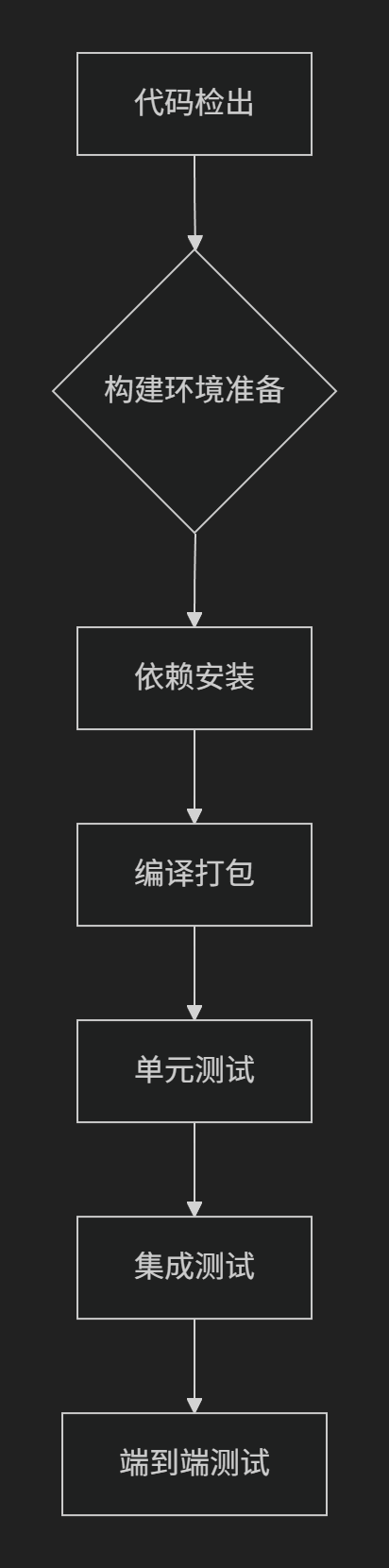
深入解析CI/CD开发流程
引言:主播最近实习的时候发现部门里面使用的是CI/CD这样的集成开发部署,但是自己不是太了解什么意思,所以就自己查了一下ci/cd相关的资料,整理分享了一下 一、CI/CD CI/CD是持续集成和持续交付部署的缩写,旨在简化并…...

Docke启动Ktransformers部署Qwen3MOE模型实战与性能测试
docker运行Ktransformers部署Qwen3MOE模型实战及 性能测试 最开始拉取ktransformers:v0.3.1-AVX512版本,发现无论如何都启动不了大模型,后来发现是cpu不支持avx512指令集。 由于本地cpu不支持amx指令集,因此下载avx2版本镜像: …...

应用分享 | 精准生成和时序控制!AWG在确定性三量子比特纠缠光子源中的应用
在量子技术飞速发展的今天,实现高效稳定的量子态操控是推动量子计算、量子通信等领域迈向实用化的关键。任意波形发生器(AWG)作为精准信号控制的核心设备,在量子实验中发挥着不可或缺的作用。丹麦哥本哈根大学的研究团队基于单个量…...

相机--相机标定实操
教程 camera_calibration移动画面示例 usb_cam使用介绍和下载 标定流程 单目相机标定 我使用的是USB相机,所以直接使用ros的usb_cam功能包驱动相机闭关获取实时图像,然后用ros的camera_calibration标定相机。 1,下载usb_cam和camera_calibration: …...

深入理解汇编语言中的顺序与分支结构
本文将结合Visual Studio环境配置、顺序结构编程和分支结构实现,全面解析汇编语言中的核心编程概念。通过实际案例演示无符号/有符号数处理、分段函数实现和逻辑表达式短路计算等关键技术。 一、汇编环境配置回顾(Win32MASM) 在Visual Studi…...
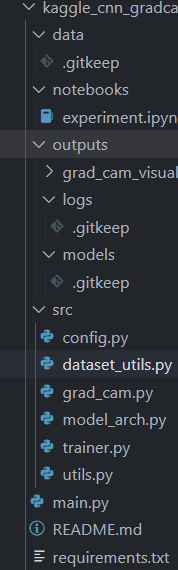
DAY43 复习日
浙大疏锦行-CSDN博客 kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:把项目拆分成多个文件 src/config.py: 用于存放项目配置,例如文件路径、学习率、批次大小等。 # src/config.py# Paths DATA_DIR "data…...

【仿生机器人】仿生机器人智能架构:从感知到个性的完整设计
仿生机器人智能架构:从感知到个性的完整设计 仿生机器人不仅需要模拟人类的外表,更需要具备类人的认知、情感和个性特征。本研究提出了一个综合性的软件架构,实现了从环境感知到情感生成、从实时交互到人格塑造的完整智能系统。该架构突破了…...

【业务框架】3C-相机-Cinemachine
概述 插件,做相机需求,等于相机老师傅多年经验总结的工具 Feature Transform:略Control Camera:控制相机参数Noise:增加随机性Blend:CameraBrain的混合列表指定一个虚拟相机到另一个相机的过渡ÿ…...

【Auto.js例程】华为备忘录导出到其他手机
目录 问题描述方法步骤1.安装下载Visual Studio Code2.安装扩展3.找到Auto.js插件,并安装插件4.启动服务器5.连接手机6.撰写脚本并运行7.本文实现功能的代码8.启动手机上的换机软件 问题描述 问题背景:华为手机换成一加手机,华为备忘录无法批…...

单片机的低功耗模式
什么是低功耗? STM32的低功耗(low power mode)特性是其嵌入式处理器系列的一个重要优势,特别适用于需要长时间运行且功耗敏感的应用场景,如便携式设备、物联网设备、智能家居系统等。 在很多应用场合中都对电子设备的…...
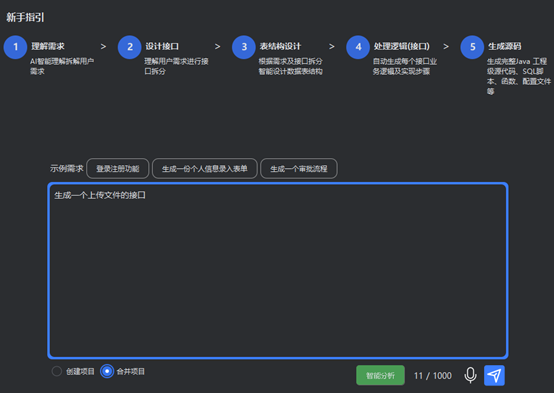
架构师级考验!飞算 JavaAI 炫技赛:AI 辅助编程解决老项目难题
当十年前 Hibernate 框架的 N1 查询隐患在深夜持续困扰排查,当 SpringMVC 控制器中错综复杂的业务逻辑在跨语言迁移时令人抓狂,企业数字化进程中的百万行老系统,已然成为暗藏危机的 “技术债冰山”。而此刻,飞算科技全新发布的 Ja…...

手机端抓包大麦网抢票协议:实现自动抢票与支付
🚀 手机端抓包大麦网抢票协议:实现自动抢票与支付 🚀 🔥 你是否还在为抢不到热门演出票而烦恼?本文将教你如何通过抓包技术获取大麦网抢票协议,并编写脚本实现自动化抢票与支付!🔥 …...

使用阿里云百炼embeddings+langchain+Milvus实现简单RAG
使用阿里云百炼embeddingslangchainMilvus实现简单RAG 注意测试时,替换其中的key、文档等 import os from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.vectorstores import Milvus from langchain_text_splitters impor…...

C#合并CAN ASC文件:实现与优化
C#合并CAN ASC文件:实现与优化 在汽车电子和工业控制领域,CAN(Controller Area Network)总线是一种广泛使用的通信协议。CAN ASC(American Standard Code)文件则是记录CAN总线通信数据的标准格式ÿ…...
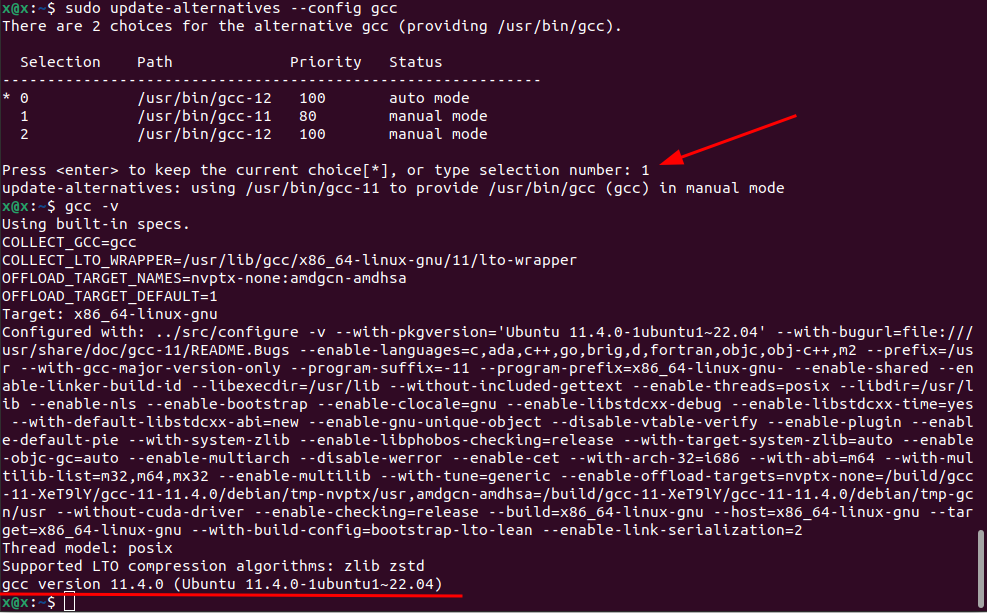
[TIP] Ubuntu 22.04 配置多个版本的 GCC 环境
问题背景 在 Ubuntu 22.04 中安装 VMware 虚拟机时,提示缺少 VMMON 和 VMNET 模块 编译这两个模块需要 GCC 的版本大于 12.3.0,而 Ubuntu 22.04 自带的 GCC 版本为 11.4.0 因此需要安装对应的 GCC 版本,但为了不影响其他程序,需…...
如何思考?分析篇
现代人每天刷 100 条信息,却难静下心读 10 页书。 前言: 我一直把思考当作一件生活中和工作中最为重要的事情。但是我发现当我想写一篇跟思考有关的文章时,却难以下手。因为思考是一件非常复杂的事情,用文字描述十分的困难。 读书…...

Redis:Hash数据类型
🌈 个人主页:Zfox_ 🔥 系列专栏:Redis 🔥 Hash哈希 🐳 ⼏乎所有的主流编程语⾔都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数组、映射。在Redis中&#…...

抗辐照MCU在卫星载荷电机控制器中的实践探索
摘要:在航天领域,卫星系统的可靠运行对电子元件的抗辐照性能提出了严苛要求。微控制单元(MCU)作为卫星载荷电机控制器的核心部件,其稳定性与可靠性直接关系到卫星任务的成败。本文聚焦抗辐照MCU在卫星载荷电机控制器中的应用实践&…...
快捷键的记录
下面对应的ATL数字 ATL4 显示编译输出 CTRL B 编译 CTRLR 运行exe 菜单栏 ALTF ALTE ALTB ALTD ALTH...
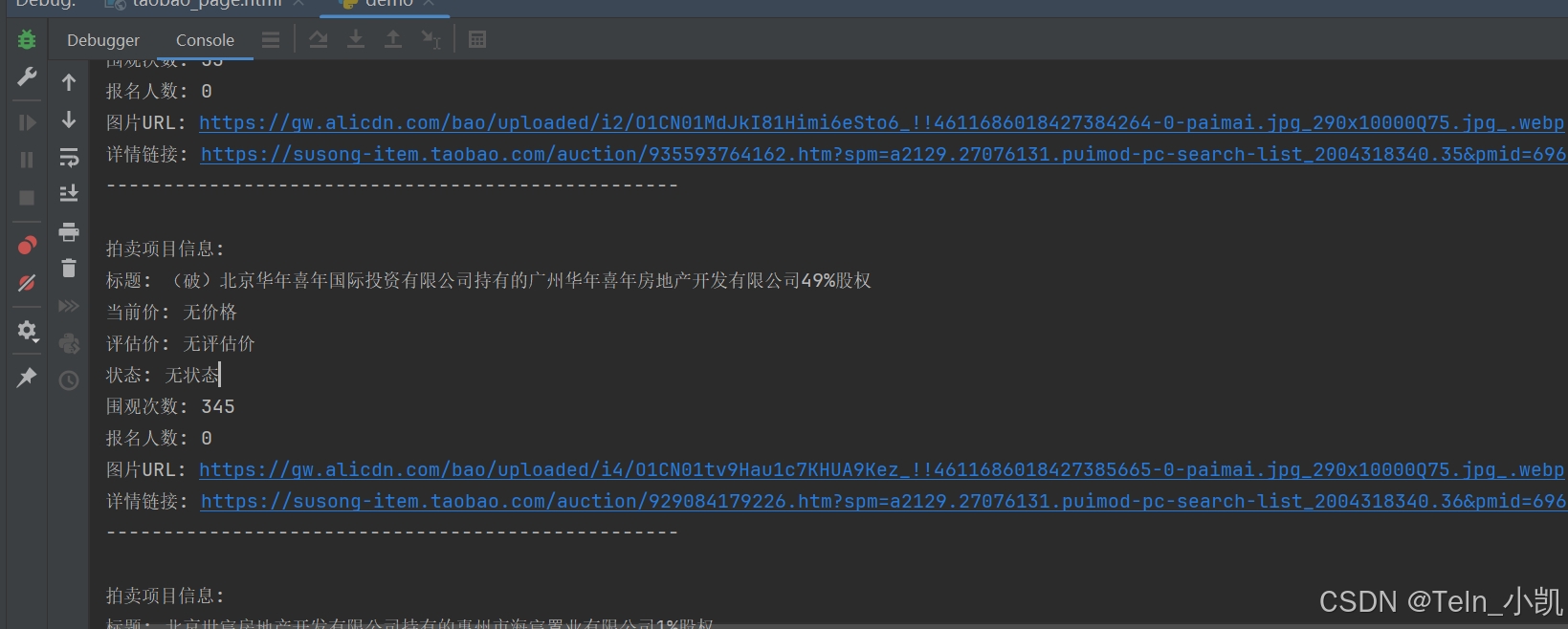
Python读取阿里法拍网的html+解决登录cookie
效果图 import time from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from lxml import etreedef get_taobao_auct…...
electron-vite串口通信
一、构建项目后,安装“串口通信库” npm install serialport二、设置 npm install --save-dev electron-rebuild ./node_modules/.bin/electron-rebuild 注意:如果执行报错以下问题 1、未配置python变量 2、没有Microsoft Visual Studio BuildTools 3…...
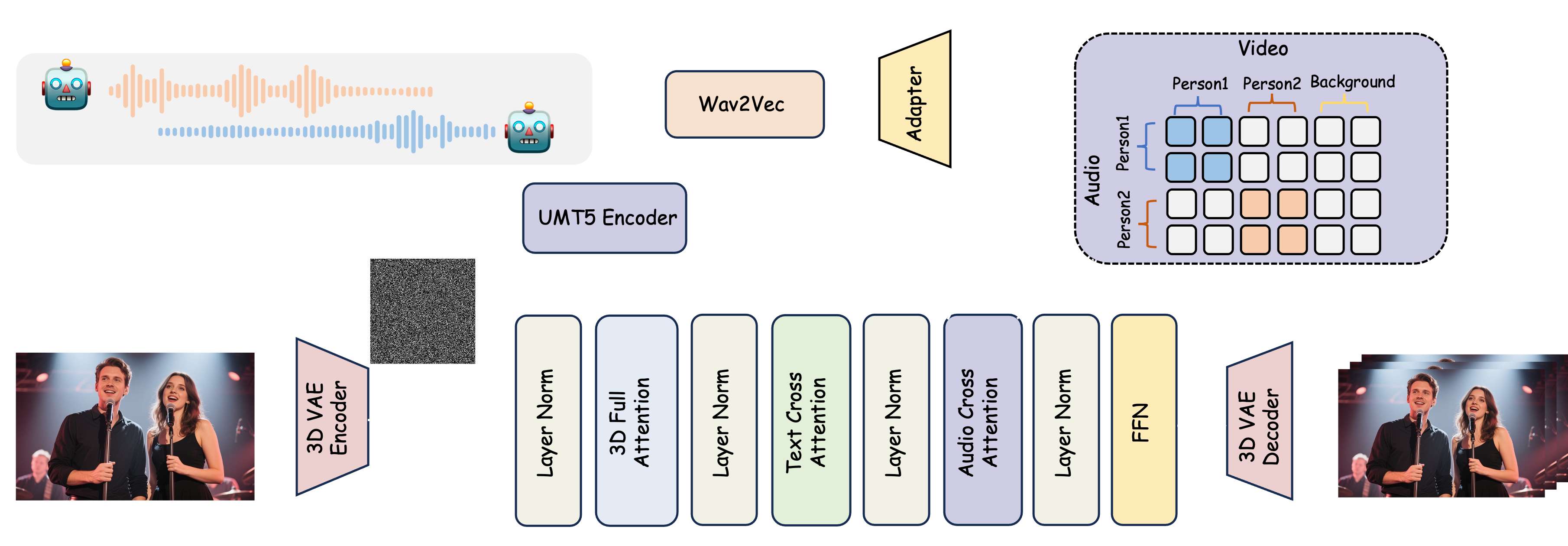
中山大学美团港科大提出首个音频驱动多人对话视频生成MultiTalk,输入一个音频和提示,即可生成对应唇部、音频交互视频。
由中山大学、美团、香港科技大学联合提出的MultiTalk是一个用于音频驱动的多人对话视频生成的新框架。给定一个多流音频输入和一个提示,MultiTalk 会生成一个包含提示所对应的交互的视频,其唇部动作与音频保持一致。 相关链接 论文:https://a…...

Maven的配置与运行
maven配置国内镜像 <!-- # %MAVEN_HOME%\conf\settings.xml # 找到 <mirrors> 标签,添加: --> <mirror><id>aliyunmaven</id><mirrorOf>*</mirrorOf><name>阿里云公共仓库</name><url>htt…...

MySQL 迁移至 Docker ,删除本地 mysql
macOS 的删除有大量的配置文件和相关数据文件要删除,如果 update mysql 那么数据更杂。 停止 MYSQL 使用 brew 安装,则 brew services stop mysql 停止 mysql 。 如果没有使用 brew 安装,则 sudo /usr/local/mysql/support-files/mysq…...