【DAY42】Grad-CAM与Hook函数
内容来自@浙大疏锦行python打卡训练营
@浙大疏锦行
- 回调函数
- lambda函数
- hook函数的模块钩子和张量钩子
- Grad-CAM的示例
作业:理解下今天的代码即可
在深度学习中,我们经常需要查看或修改模型中间层的输出或梯度。然而,标准的前向传播和反向传播过程通常是一个黑盒,我们很难直接访问中间层的信息。PyTorch 提供了一种强大的工具——hook 函数,它允许我们在不修改模型结构的情况下,获取或修改中间层的信息。它的核心价值在于让开发者能够动态监听、捕获甚至修改模型内部任意层的输入 / 输出或梯度,而无需修改模型的原始代码结构。
常用场景如下:
1. 调试与可视化中间层输出
2. 特征提取:如在图像分类模型中提取高层语义特征用于下游任务
3. 梯度分析与修改: 在训练过程中,对某些层进行梯度裁剪或缩放,以改变模型训练的动态
4. 模型压缩:在推理阶段对特定层的输出应用掩码(如剪枝后的模型权重掩码),实现轻量化推理。
我们之前介绍过机器学习可解释性工具,例如 SHAP、PDPBox 等,这些工具在处理结构化数据时,能够有效揭示模型内部的决策逻辑。而在深度学习领域,同样存在一系列方法来解析模型的决策过程:以图像分类任务为例,我们不仅可以通过可视化特征图,直观观察不同层对图像特征的提取程度;还能进一步借助 Grad-CAM 等技术生成特征热力图,清晰展现模型在预测过程中对图像不同区域的关注重点,从而深入理解其决策机制。

一、 前置知识
1.1 回调函数
Hook本质是回调函数,所以我们先介绍一下回调函数
回调函数是作为参数传递给其他函数的函数,其目的是在某个特定事件发生时被调用执行。这种机制允许代码在运行时动态指定需要执行的逻辑,实现了代码的灵活性和可扩展性。
回调函数的核心价值在于:
1. 解耦逻辑:将通用逻辑与特定处理逻辑分离,使代码更模块化。
2. 事件驱动编程:在异步操作、事件监听(如点击按钮、网络请求完成)等场景中广泛应用。
3. 延迟执行:允许在未来某个时间点执行特定代码,而不必立即执行。
其中回调函数作为参数传入,所以在定义的时候一般用callback来命名,在 PyTorch 的 Hook API 中,回调参数通常命名为 hook
# 定义一个回调函数
def handle_result(result):"""处理计算结果的回调函数"""print(f"计算结果是: {result}")# 定义一个接受回调函数的函数
def calculate(a, b, callback): # callback是一个约定俗成的参数名"""这个函数接受两个数值和一个回调函数,用于处理计算结果。执行计算并调用回调函数"""result = a + bcallback(result) # 在计算完成后调用回调函数# 使用回调函数
calculate(3, 5, handle_result) # 输出: 计算结果是: 8是不是看上去很类似于装饰器的写法,我们回顾下装饰器
def handle_result(result):"""处理计算结果的回调函数"""print(f"计算结果是: {result}")def with_callback(callback):"""装饰器工厂:创建一个将计算结果传递给回调函数的装饰器"""def decorator(func):"""实际的装饰器,用于包装目标函数"""def wrapper(a, b):"""被装饰后的函数,执行计算并调用回调"""result = func(a, b) # 执行原始计算callback(result) # 调用回调函数处理结果return result # 返回计算结果(可选)return wrapperreturn decorator# 使用装饰器包装原始计算函数
@with_callback(handle_result)
def calculate(a, b):"""执行加法计算"""return a + b# 直接调用被装饰后的函数
calculate(3, 5) # 输出: 计算结果是: 8回调函数核心是将处理逻辑(回调)作为参数传递给计算函数,控制流:计算函数 → 回调函数,适合一次性或动态的处理需求(控制流指的是程序执行时各代码块的执行顺序)
装饰器实现核心是修改原始函数的行为,在其基础上添加额外功能,控制流:被装饰函数 → 原始计算 → 回调函数,适合统一的、可复用的处理逻辑
两种实现方式都达到了相同的效果,但装饰器提供了更优雅的语法和更好的代码复用性。在需要对多个计算函数应用相同回调逻辑时,装饰器方案会更加高效。
关键区别:回调 vs 装饰器
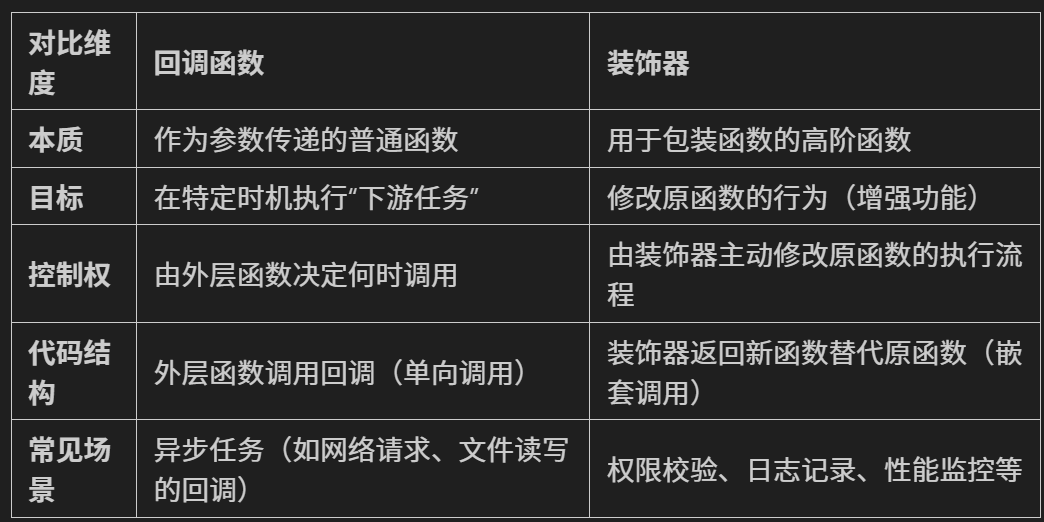 总结:从回调到装饰器的思维升级
总结:从回调到装饰器的思维升级
1. 回调函数是“被动响应”的工具,核心是“传递函数作为参数,等待触发”。
2. 装饰器是“主动改造”的工具,核心是“用新函数包装原函数,修改行为”。
3. Hook 函数是两者的灵活结合,既可以通过回调参数实现(如 PyTorch),也可以通过装饰器机制实现(如某些框架的生命周期钩子)。
Hook 的底层工作原理
PyTorch 的 Hook 机制基于其动态计算图系统:
1. 当你注册一个 Hook 时,PyTorch 会在计算图的特定节点(如模块或张量)上添加一个回调函数。
2. 当计算图执行到该节点时(前向或反向传播),自动触发对应的 Hook 函数。
3. Hook 函数可以访问或修改流经该节点的数据(如输入、输出或梯度)。
这种设计使得 Hook 能够在不干扰模型正常运行的前提下,灵活地插入自定义逻辑。
理解这两个概念后,再学习 Hook 会更轻松——Hook 本质是在程序流程中预留的“可插入点”,而插入的方式可以是回调函数、装饰器或其他形式。
1.2 lamda匿名函数
在hook中常常用到lambda函数,它是一种匿名函数(没有正式名称的函数),最大特点是用完即弃,无需提前命名和定义。它的语法形式非常简约,仅需一行即可完成定义,格式如下:
lambda 参数列表: 表达式
- 参数列表:可以是单个参数、多个参数或无参数。
- 表达式:函数的返回值(无需 return 语句,表达式结果直接返回)。
# 定义匿名函数:计算平方
square = lambda x: x ** 2# 调用
print(square(5)) # 输出: 25这种形式很简约,只需要一行就可以定义一个函数,lambda 的核心价值在于用极简语法快速定义临时函数,避免为一次性使用的简单逻辑单独命名函数,从而减少代码冗余,提升开发效率。
与普通函数的对比

二、 hook函数
Hook 函数是一种回调函数,它可以在不干扰模型正常计算流程的情况下,插入到模型的特定位置,以便获取或修改中间层的输出或梯度。PyTorch 提供了两种主要的 hook:
1. Module Hooks:用于监听整个模块的输入和输出
2. Tensor Hooks:用于监听张量的梯度
下面我们将通过具体的例子来学习这两种 hook 的使用方法。
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt# 设置随机种子,保证结果可复现
torch.manual_seed(42)
np.random.seed(42)2.1 模块钩子 (Module Hooks)
模块钩子允许我们在模块的输入或输出经过时进行监听。PyTorch 提供了两种模块钩子:
- `register_forward_hook`:在前向传播时监听模块的输入和输出
- `register_backward_hook`:在反向传播时监听模块的输入梯度和输出梯度
2.1.1 前向钩子 (Forward Hook)
前向钩子是一个函数,它会在模块的前向传播完成后立即被调用。这个函数可以访问模块的输入和输出,但不能修改它们。让我们通过一个简单的例子来理解前向钩子的工作原理。
import torch
import torch.nn as nn# 定义一个简单的卷积神经网络模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()# 定义卷积层:输入通道1,输出通道2,卷积核3x3,填充1保持尺寸不变self.conv = nn.Conv2d(1, 2, kernel_size=3, padding=1)# 定义ReLU激活函数self.relu = nn.ReLU()# 定义全连接层:输入特征2*4*4,输出10分类self.fc = nn.Linear(2 * 4 * 4, 10)def forward(self, x):# 卷积操作x = self.conv(x)# 激活函数x = self.relu(x)# 展平为一维向量,准备输入全连接层x = x.view(-1, 2 * 4 * 4)# 全连接分类x = self.fc(x)return x# 创建模型实例
model = SimpleModel()# 创建一个列表用于存储中间层的输出
conv_outputs = []# 定义前向钩子函数 - 用于在模型前向传播过程中获取中间层信息
def forward_hook(module, input, output):"""前向钩子函数,会在模块每次执行前向传播后被自动调用参数:module: 当前应用钩子的模块实例input: 传递给该模块的输入张量元组output: 该模块产生的输出张量"""print(f"钩子被调用!模块类型: {type(module)}")print(f"输入形状: {input[0].shape}") # input是一个元组,对应 (image, label)print(f"输出形状: {output.shape}")# 保存卷积层的输出用于后续分析# 使用detach()避免追踪梯度,防止内存泄漏conv_outputs.append(output.detach())# 在卷积层注册前向钩子
# register_forward_hook返回一个句柄,用于后续移除钩子
hook_handle = model.conv.register_forward_hook(forward_hook)# 创建一个随机输入张量 (批次大小=1, 通道=1, 高度=4, 宽度=4)
x = torch.randn(1, 1, 4, 4)# 执行前向传播 - 此时会自动触发钩子函数
output = model(x)# 释放钩子 - 重要!防止在后续模型使用中持续调用钩子造成意外行为或内存泄漏
hook_handle.remove()# # 打印中间层输出结果
# if conv_outputs:
# print(f"\n卷积层输出形状: {conv_outputs[0].shape}")
# print(f"卷积层输出值示例: {conv_outputs[0][0, 0, :, :]}")在上面的例子中,我们定义了一个简单的模型,包含卷积层、ReLU激活函数和全连接层。然后,我们在卷积层上注册了一个前向钩子。当前向传播执行到卷积层时,钩子函数会被自动调用。
钩子函数接收三个参数:
- module:应用钩子的模块实例
- input:传递给模块的输入(可能包含多个张量)
- output:模块的输出
我们可以在钩子函数中查看或记录这些信息,但不能直接修改它们。如果需要修改输出,可以使用 register_forward_pre_hook 或 register_forward_hook_with_kwargs(PyTorch 1.9+)。
最后,我们使用 hook_handle.remove() 释放了钩子,这一点很重要,因为未释放的钩子可能会导致内存泄漏。
# 让我们可视化卷积层的输出
if conv_outputs:plt.figure(figsize=(10, 5))# 原始输入图像plt.subplot(1, 3, 1)plt.title('输入图像')plt.imshow(x[0, 0].detach().numpy(), cmap='gray') # 显示灰度图像# 第一个卷积核的输出plt.subplot(1, 3, 2)plt.title('卷积核1输出')plt.imshow(conv_outputs[0][0, 0].detach().numpy(), cmap='gray')# 第二个卷积核的输出plt.subplot(1, 3, 3)plt.title('卷积核2输出')plt.imshow(conv_outputs[0][0, 1].detach().numpy(), cmap='gray')plt.tight_layout()plt.show()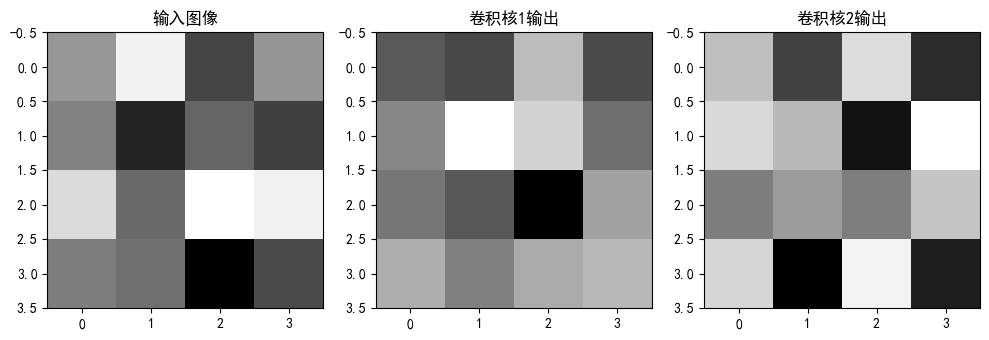
2.1.2 反向钩子 (Backward Hook)
反向钩子与前向钩子类似,但它是在反向传播过程中被调用的。反向钩子可以用来获取或修改梯度信息。
# 定义一个存储梯度的列表
conv_gradients = []# 定义反向钩子函数
def backward_hook(module, grad_input, grad_output):# 模块:当前应用钩子的模块# grad_input:模块输入的梯度# grad_output:模块输出的梯度print(f"反向钩子被调用!模块类型: {type(module)}")print(f"输入梯度数量: {len(grad_input)}")print(f"输出梯度数量: {len(grad_output)}")# 保存梯度供后续分析conv_gradients.append((grad_input, grad_output))# 在卷积层注册反向钩子
hook_handle = model.conv.register_backward_hook(backward_hook)# 创建一个随机输入并进行前向传播
x = torch.randn(1, 1, 4, 4, requires_grad=True)
output = model(x)# 定义一个简单的损失函数并进行反向传播
loss = output.sum()
loss.backward()# 释放钩子
hook_handle.remove()2.2 张量钩子 (Tensor Hooks)
除了模块钩子,PyTorch 还提供了张量钩子,允许我们直接监听和修改张量的梯度。张量钩子有两种:
- register_hook:用于监听张量的梯度
- register_full_backward_hook:用于在完整的反向传播过程中监听张量的梯度(PyTorch 1.4+)
# 创建一个需要计算梯度的张量
x = torch.tensor([2.0], requires_grad=True)
y = x ** 2
z = y ** 3# 定义一个钩子函数,用于修改梯度
def tensor_hook(grad):print(f"原始梯度: {grad}")# 修改梯度,例如将梯度减半return grad / 2# 在y上注册钩子
hook_handle = y.register_hook(tensor_hook)# 计算梯度
z.backward()print(f"x的梯度: {x.grad}")# 释放钩子
hook_handle.remove()在这个例子中,我们创建了一个计算图 z = (x^2)^3。然后在中间变量 y 上注册了一个钩子。当调用 z.backward() 时,梯度会从 z 反向传播到 x。在传播过程中,钩子函数会被调用,我们可以在钩子函数中查看或修改梯度。
在这个例子中,我们将梯度减半,因此最终 x 的梯度是原始梯度的一半。
三、 Grad-CAM
Grad-CAM (Gradient-weighted Class Activation Mapping) 算法是一种强大的可视化技术,用于解释卷积神经网络 (CNN) 的决策过程。它通过计算特征图的梯度来生成类激活映射(Class Activation Mapping,简称 CAM ),直观地显示图像中哪些区域对模型的特定预测贡献最大。
Grad-CAM 的核心思想是:通过反向传播得到的梯度信息,来衡量每个特征图对目标类别的重要性。
1. 梯度信息:通过计算目标类别对特征图的梯度,得到每个特征图的重要性权重。
2. 特征加权:用这些权重对特征图进行加权求和,得到类激活映射。
3. 可视化:将激活映射叠加到原始图像上,高亮显示对预测最关键的区域。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image# 设置随机种子确保结果可复现
# 在深度学习中,随机种子可以让每次运行代码时,模型初始化参数、数据打乱等随机操作保持一致,方便调试和对比实验结果
torch.manual_seed(42)
np.random.seed(42)# 加载CIFAR-10数据集
# 定义数据预处理步骤,先将图像转换为张量,再进行归一化操作
# 归一化的均值和标准差是(0.5, 0.5, 0.5),这里的均值和标准差是对CIFAR-10数据集的经验值,使得数据分布更有利于模型训练
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 加载测试集,指定数据集根目录为'./data',设置为测试集(train=False),如果数据不存在则下载(download=True),并应用上述定义的预处理
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform
)# 定义类别名称,CIFAR-10数据集包含这10个类别
classes = ('飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车')# 定义一个简单的CNN模型
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 第一个卷积层,输入通道为3(彩色图像),输出通道为32,卷积核大小为3x3,填充为1以保持图像尺寸不变self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)# 第二个卷积层,输入通道为32,输出通道为64,卷积核大小为3x3,填充为1self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)# 第三个卷积层,输入通道为64,输出通道为128,卷积核大小为3x3,填充为1self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)# 最大池化层,池化核大小为2x2,步长为2,用于下采样,减少数据量并提取主要特征self.pool = nn.MaxPool2d(2, 2)# 第一个全连接层,输入特征数为128 * 4 * 4(经过前面卷积和池化后的特征维度),输出为512self.fc1 = nn.Linear(128 * 4 * 4, 512)# 第二个全连接层,输入为512,输出为10(对应CIFAR-10的10个类别)self.fc2 = nn.Linear(512, 10)def forward(self, x):# 第一个卷积层后接ReLU激活函数和最大池化操作,经过池化后图像尺寸变为原来的一半,这里输出尺寸变为16x16x = self.pool(F.relu(self.conv1(x))) # 第二个卷积层后接ReLU激活函数和最大池化操作,输出尺寸变为8x8x = self.pool(F.relu(self.conv2(x))) # 第三个卷积层后接ReLU激活函数和最大池化操作,输出尺寸变为4x4x = self.pool(F.relu(self.conv3(x))) # 将特征图展平为一维向量,以便输入到全连接层x = x.view(-1, 128 * 4 * 4)# 第一个全连接层后接ReLU激活函数x = F.relu(self.fc1(x))# 第二个全连接层输出分类结果x = self.fc2(x)return x# 初始化模型
model = SimpleCNN()
print("模型已创建")# 如果有GPU则使用GPU,将模型转移到对应的设备上
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)# 训练模型(简化版,实际应用中应该进行完整训练)
def train_model(model, epochs=1):# 加载训练集,指定数据集根目录为'./data',设置为训练集(train=True),如果数据不存在则下载(download=True),并应用前面定义的预处理trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)# 创建数据加载器,设置批量大小为64,打乱数据顺序(shuffle=True),使用2个线程加载数据trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,shuffle=True, num_workers=2)# 定义损失函数为交叉熵损失,用于分类任务criterion = nn.CrossEntropyLoss()# 定义优化器为Adam,用于更新模型参数,学习率设置为0.001optimizer = torch.optim.Adam(model.parameters(), lr=0.001)for epoch in range(epochs):running_loss = 0.0for i, data in enumerate(trainloader, 0):# 从数据加载器中获取图像和标签inputs, labels = data# 将图像和标签转移到对应的设备(GPU或CPU)上inputs, labels = inputs.to(device), labels.to(device)# 清空梯度,避免梯度累加optimizer.zero_grad()# 模型前向传播得到输出outputs = model(inputs)# 计算损失loss = criterion(outputs, labels)# 反向传播计算梯度loss.backward()# 更新模型参数optimizer.step()running_loss += loss.item()if i % 100 == 99:# 每100个批次打印一次平均损失print(f'[{epoch + 1}, {i + 1}] 损失: {running_loss / 100:.3f}')running_loss = 0.0print("训练完成")# 训练模型(可选,如果有预训练模型可以加载)
# 取消下面这行的注释来训练模型
# train_model(model, epochs=1)# 或者尝试加载预训练模型(如果存在)
try:# 尝试加载名为'cifar10_cnn.pth'的模型参数model.load_state_dict(torch.load('cifar10_cnn.pth'))print("已加载预训练模型")
except:print("无法加载预训练模型,使用未训练模型或训练新模型")# 如果没有预训练模型,可以在这里调用train_model函数train_model(model, epochs=1)# 保存训练后的模型参数torch.save(model.state_dict(), 'cifar10_cnn.pth')# 设置模型为评估模式,此时模型中的一些操作(如dropout、batchnorm等)会切换到评估状态
model.eval()# Grad-CAM实现
class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.gradients = Noneself.activations = None# 注册钩子,用于获取目标层的前向传播输出和反向传播梯度self.register_hooks()def register_hooks(self):# 前向钩子函数,在目标层前向传播后被调用,保存目标层的输出(激活值)def forward_hook(module, input, output):self.activations = output.detach()# 反向钩子函数,在目标层反向传播后被调用,保存目标层的梯度def backward_hook(module, grad_input, grad_output):self.gradients = grad_output[0].detach()# 在目标层注册前向钩子和反向钩子self.target_layer.register_forward_hook(forward_hook)self.target_layer.register_backward_hook(backward_hook)def generate_cam(self, input_image, target_class=None):# 前向传播,得到模型输出model_output = self.model(input_image)if target_class is None:# 如果未指定目标类别,则取模型预测概率最大的类别作为目标类别target_class = torch.argmax(model_output, dim=1).item()# 清除模型梯度,避免之前的梯度影响self.model.zero_grad()# 反向传播,构造one-hot向量,使得目标类别对应的梯度为1,其余为0,然后进行反向传播计算梯度one_hot = torch.zeros_like(model_output)one_hot[0, target_class] = 1model_output.backward(gradient=one_hot)# 获取之前保存的目标层的梯度和激活值gradients = self.gradientsactivations = self.activations# 对梯度进行全局平均池化,得到每个通道的权重,用于衡量每个通道的重要性weights = torch.mean(gradients, dim=(2, 3), keepdim=True)# 加权激活映射,将权重与激活值相乘并求和,得到类激活映射的初步结果cam = torch.sum(weights * activations, dim=1, keepdim=True)# ReLU激活,只保留对目标类别有正贡献的区域,去除负贡献的影响cam = F.relu(cam)# 调整大小并归一化,将类激活映射调整为与输入图像相同的尺寸(32x32),并归一化到[0, 1]范围cam = F.interpolate(cam, size=(32, 32), mode='bilinear', align_corners=False)cam = cam - cam.min()cam = cam / cam.max() if cam.max() > 0 else camreturn cam.cpu().squeeze().numpy(), target_classimport warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 选择一个随机图像
# idx = np.random.randint(len(testset))
idx = 102 # 选择测试集中的第101张图片 (索引从0开始)
image, label = testset[idx]
print(f"选择的图像类别: {classes[label]}")# 转换图像以便可视化
def tensor_to_np(tensor):img = tensor.cpu().numpy().transpose(1, 2, 0)mean = np.array([0.5, 0.5, 0.5])std = np.array([0.5, 0.5, 0.5])img = std * img + meanimg = np.clip(img, 0, 1)return img# 添加批次维度并移动到设备
input_tensor = image.unsqueeze(0).to(device)# 初始化Grad-CAM(选择最后一个卷积层)
grad_cam = GradCAM(model, model.conv3)# 生成热力图
heatmap, pred_class = grad_cam.generate_cam(input_tensor)# 可视化
plt.figure(figsize=(12, 4))# 原始图像
plt.subplot(1, 3, 1)
plt.imshow(tensor_to_np(image))
plt.title(f"原始图像: {classes[label]}")
plt.axis('off')# 热力图
plt.subplot(1, 3, 2)
plt.imshow(heatmap, cmap='jet')
plt.title(f"Grad-CAM热力图: {classes[pred_class]}")
plt.axis('off')# 叠加的图像
plt.subplot(1, 3, 3)
img = tensor_to_np(image)
heatmap_resized = np.uint8(255 * heatmap)
heatmap_colored = plt.cm.jet(heatmap_resized)[:, :, :3]
superimposed_img = heatmap_colored * 0.4 + img * 0.6
plt.imshow(superimposed_img)
plt.title("叠加热力图")
plt.axis('off')plt.tight_layout()
plt.savefig('grad_cam_result.png')
plt.show()# print("Grad-CAM可视化完成。已保存为grad_cam_result.png")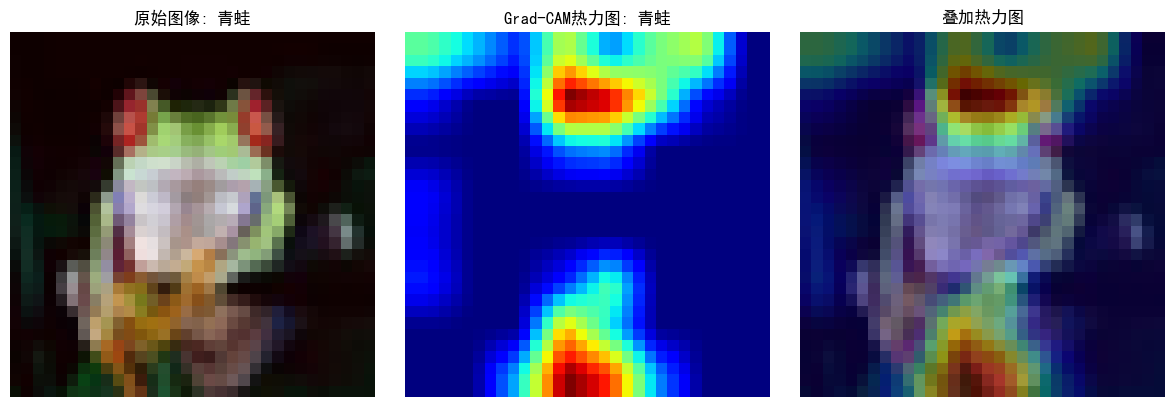
可以看到通过腿和头部判断是青蛙
相关文章:
【DAY42】Grad-CAM与Hook函数
内容来自浙大疏锦行python打卡训练营 浙大疏锦行 知识点: 回调函数lambda函数hook函数的模块钩子和张量钩子Grad-CAM的示例 作业:理解下今天的代码即可 在深度学习中,我们经常需要查看或修改模型中间层的输出或梯度。然而,标准的前向传播和反…...
如何生成和制作PDF文件
在数字化办公的今天,PDF文件已经成为我们工作和学习中不可或缺的一部分。无论是合同、报告、简历,还是电子书、表单,PDF格式都以其跨平台兼容性、不可编辑性和清晰的排版而被广泛使用。但你是否知道,生成和制作PDF文件其实并不复杂…...

【K8S系列】Kubernetes 中 Pod(Java服务)启动缓慢的深度分析与解决方案
本文针对 Kubernetes 中 Java 服务启动时间慢的深度分析与解决方案文章,结合了底层原理、常见原因及具体优化策略: Kubernetes 中 Java 服务启动缓慢的深度分析与高效解决方案 在 Kubernetes 上部署 Java 应用时,启动时间过长是常见痛点,尤其在需要快速扩缩容或滚动更新的…...

【Java学习笔记】StringBuilder类(重点)
StringBuilder(重点) 1. 基本介绍 是一个可变的字符串序列。该类提供一个与 StringBuffer 兼容的 API,但不保证同步(StringBuilder 不是线程安全的) 该类被设计用作 StringBuffer 的一个简易替换,用在字符…...

JavaScript ES6 解构:优雅提取数据的艺术
JavaScript ES6 解构:优雅提取数据的艺术 在 JavaScript 的世界中,ES6(ECMAScript 2015)的推出为开发者带来了许多革命性的特性,其中“解构赋值”(Destructuring Assignment)无疑是最受欢迎的功…...

iview Switch Tabs TabPane 使用提示Maximum call stack size exceeded堆栈溢出
在vue项目中使用iview 框架部分组件时,直接引入使用报Maximum call stack size exceeded image.png 堆栈溢出 解决方案 更换组件名称就可以了 image.png 或 image.png 就可以了 猜测是因为和vue自己提供的组件名称一致了,重名问题导致的,具体…...
基于Halcon深度学习之分类
***** ***环境准备*** ***系统:win7以上系统 ***显卡:算力3.0以上 ***显卡驱动:10.1以上版本(nvidia-smi查看指令)***读取深度学习模型*** read_dl_model (pretrained_dl_classifier_compact.hdl, DLModelHandle) ***获…...
)
零基础在实践中学习网络安全-皮卡丘靶场(第十五期-URL重定向模块)
本期内容和之前的CSRF,File inclusion有联系,复习后可以更好了解 介绍 不安全的url跳转 不安全的url跳转问题可能发生在一切执行了url地址跳转的地方。如果后端采用了前端传进来的(可能是用户传参,或者之前预埋在前端页面的url地址)参数作为了跳转的目…...

技巧小结:根据寄存器手册写常用外设的驱动程序
需求:根据STM32F103寄存器手册写DMA模块的驱动程序 一、分析标准库函数的写法: 各个外设的寄存器地址定义在stm32f10x.h文件中:此文件由芯片厂家提供;内核的有关定义则定义在core_cm3.h文件中:ARM提供; 1、查看外设区域多级划分…...
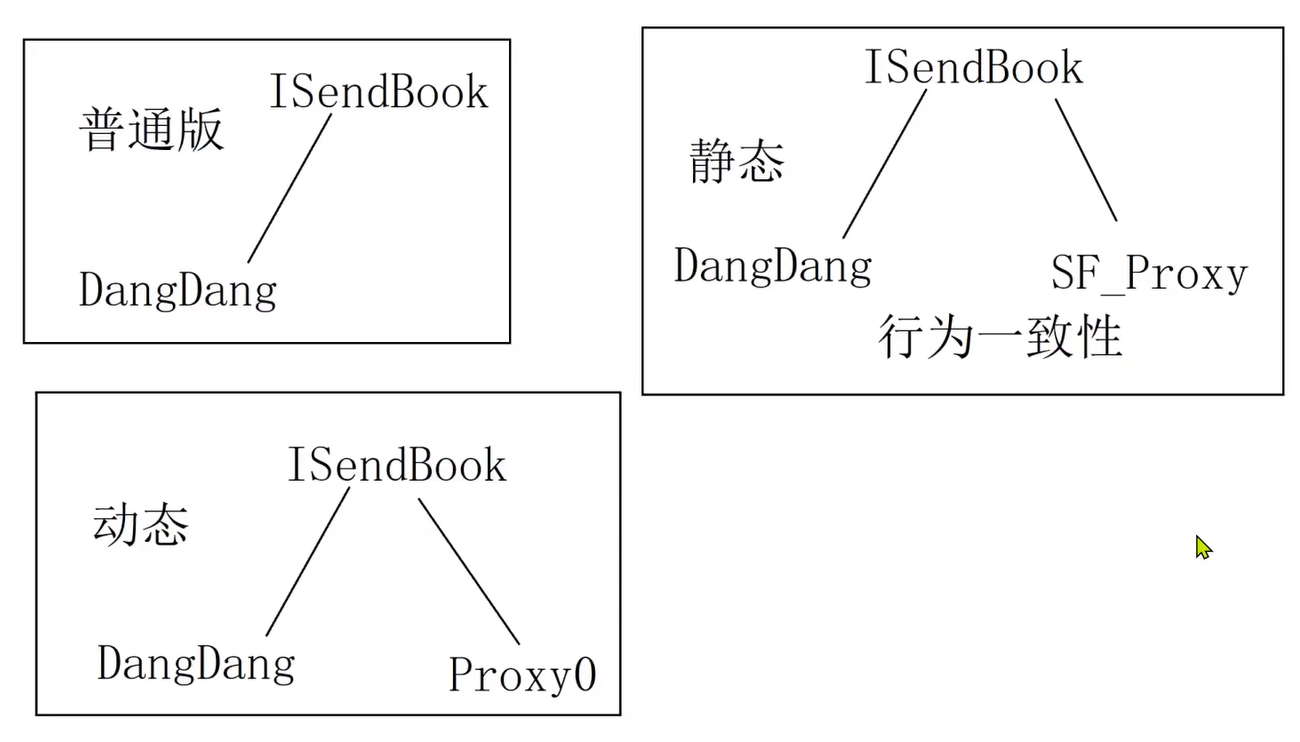
设计模式(代理设计模式)
代理模式解释清楚,所以如果想对一个类进行功能上增强而又不改变原来的代码情况下,那么只需要让这个类代理类就是我们的顺丰,对吧?并行增强就可以了。具体增强什么?在哪方面增强由代理类进行决定。 代码实现就是使用代理对象代理相关的逻辑…...
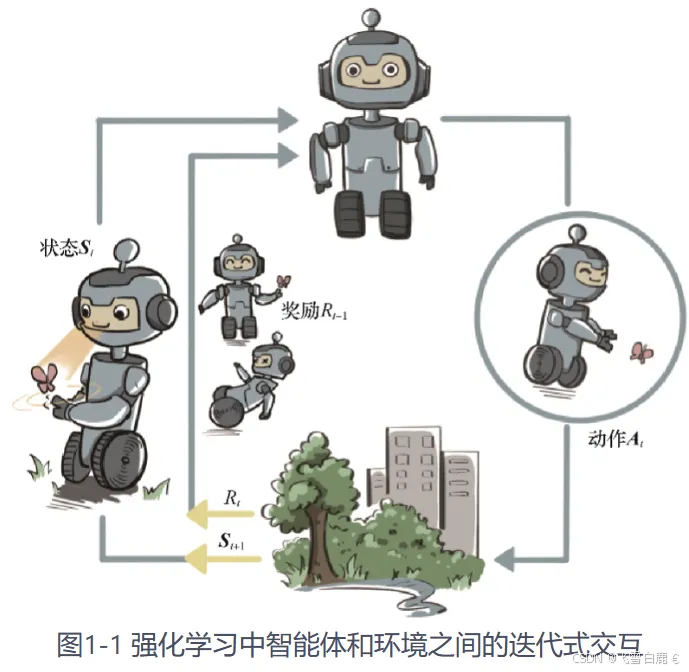
从代码学习深度强化学习 - 初探强化学习 PyTorch版
文章目录 前言强化学习的概念强化学习的环境强化学习中的数据强化学习的独特性总结前言 本文将带你初步了解强化学习 (Reinforcement Learning, RL) 的基本概念,并通过 PyTorch 实现一些简单的强化学习算法。强化学习是一种让智能体 (agent) 通过与环境 (environment) 的交互…...

AI大神吴恩达-提示词课程笔记
如何有效编写提示词 在学习如何与语言模型(如ChatGPT)交互时,编写清晰且高效的提示词(Prompt)是至关重要的。本课程由ESA提供,重点介绍了提示词工程(Prompt Engineering)的两个核心…...

ArcGIS Pro 3.4 二次开发 - 地图探索
环境:ArcGIS Pro SDK 3.4 + .NET 8 文章目录 地图探索1 地图视图1.1 测试视图是否为3D1.2 设置视图模式1.3 启用视图链接2 更新地图视图范围2.1 返回上一个相机视图2.2 切换到下一个相机视角2.3 缩放到全图范围2.4 固定放大2.5 固定缩小2.6 缩放到范围2.7 缩放到一个点2.8 缩放…...
ELK日志管理框架介绍
在小铃铛的毕业设计中涉及到了ELK日志管理框架,在调研期间发现在中文中没有很好的对ELK框架进行介绍的文章,因此拟在本文中进行较为详细的实现的介绍。 理论知识 ELK 框架介绍 ELK 是一个流行的开源日志管理解决方案堆栈,由三个核心组件组…...
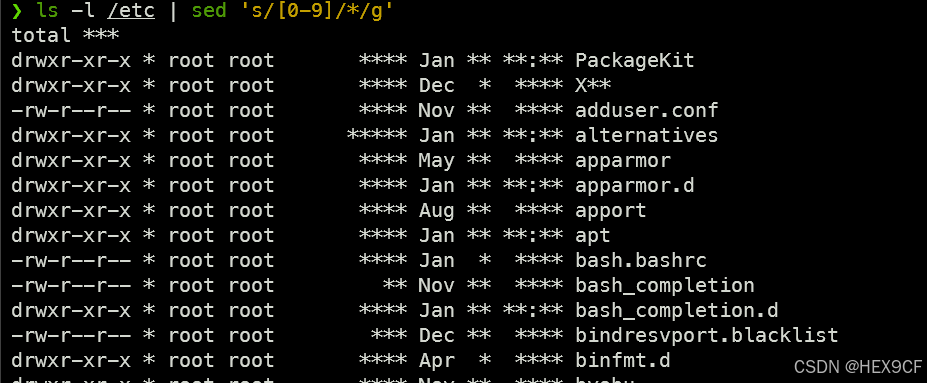
【Linux】sed 命令详解及使用样例:流式文本编辑器
【Linux】sed 命令详解及使用样例:流式文本编辑器 引言 sed 是 Linux/Unix 系统中一个强大的流式文本编辑器,名称来源于 “Stream EDitor”(流编辑器)。它允许用户在不打开文件的情况下对文本进行筛选和转换,是命令行…...
机器学习:聚类算法及实战案例
本文目录: 一、聚类算法介绍二、分类(一)根据聚类颗粒度分类(二)根据实现方法分类 三、聚类流程四、K值的确定—肘部法(一)SSE-误差平方和(二)肘部法确定 K 值 五、代码重…...
)
预览pdf(url格式和blob格式)
<template><div class"pdf-container"><div v-if"loading" class"loading-state"><a-spin size"large" /></div><div v-else-if"error" class"loading-state">加载失败&…...
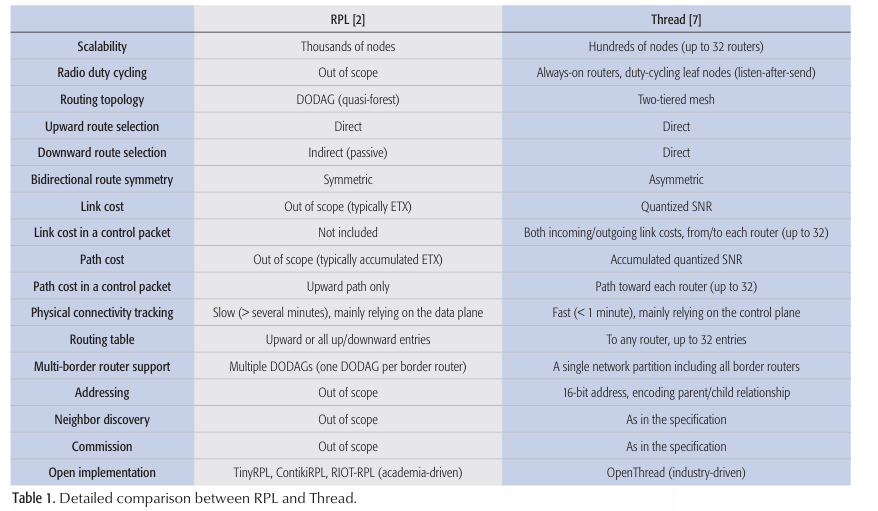
【p2p、分布式,区块链笔记 MESH】 论文阅读 Thread/OpenThread Low-Power Wireless Multihop Net
paperauthorThread/OpenThread: A Compromise in Low-Power Wireless Multihop Network Architecture for the Internet of ThingsHyung-Sin Kim, Sam Kumar, and David E. Culler 目录 引言RPL 标准设计目标与架构设计选择与特性shortcomIngs of RPL设计选择的反面影响sImulta…...

for AC500 PLCs 3ADR025003M9903的安全说明
1安全说明 必须遵守特殊的环境条件(例如,由于爆炸性物质、重污染或腐蚀影响的危险区域)。必须在指定的技术数据和系统数据范围内处理和操作设备。该装置不含可维修部件,不得打开。除非另有规定,否则操作过程中必须关闭可拆卸的盖子。拒绝对不…...
moon游戏服务器-demo运行
下载地址 https://github.com/sniper00/MoonDemo redis安装 Redis-x64-3.0.504.msi 服务器配置文件 D:\gitee\moon_server_demo\serverconf.lua 貌似不修改也可以的,redis不要设置密码 windows编译 安装VS2022 Community 下载premake5.exe放MoonDemo\server\moon 双…...
学习笔记(CLASS 7):vuex)
前端(vue)学习笔记(CLASS 7):vuex
vuex概述 vuex是一个vue的状态管理工具,状态就是数据 大白话:vuex是一个插件,可以帮我们管理vue通用的数据(多组件共享的数据) 场景 1、某个状态在很多个组件来使用(个人信息) 2、多个组件…...
)
[特殊字符] 在 React Native 项目中封装 App Icon 一键设置命令(支持参数与默认路径)
📦 前置依赖 使用的是社区维护的 CLI 工具: @bam.tech/react-native-make它扩展了 react-native 命令,支持 set-icon 功能。 安装: yarn add -D "@bam.tech/react-native-make"🧠 封装目标 我们希望能够通过以下方式调用: # 默认使用 ./icon.png yarn …...
的医学图像分割系统设计与实现:超声心脏分割)
基于深度学习(Unet和SwinUnet)的医学图像分割系统设计与实现:超声心脏分割
基于深度学习的医学图像分割系统设计与实现 摘要 本文提出了一种基于深度学习的医学图像分割系统,该系统采用U-Net和Swin-Unet作为核心网络架构,实现了高效的医学图像分割功能。系统包含完整的训练、验证和推理流程,并提供了用户友好的图形界面。实验结果表明,该系统在医…...
Qt学习及使用_第1部分_认识Qt---学习目的及技术准备
前言 学以致用,通过QT框架的学习,一边实践,一边探索编程的方方面面. 参考书:<Qt 6 C开发指南>(以下称"本书") 标识说明:概念用粗体倾斜.重点内容用(加粗黑体)---重点内容(红字)---重点内容(加粗红字), 本书原话内容用深蓝色标识,比较重要的内容用加粗倾…...

如何把本地服务器变成公网服务器?内网ip网址转换到外网连接访问
内网IP只能在本地内部网络连接访问,当本地搭建服务器部署好相关网站或应用后,在局域网内可以通过内网IP访问,但在外网是无法直接访问异地内网IP端口应用的,只有公网IP和域名才能实现互联网上的访问。那么需要如何把本地服务器变…...

Java+Access综合测评系统源码分享:含论文、开题报告、任务书全套资料
JAVAaccess综合测评系统毕业设计 一、系统概述 本系统采用Java Swing开发前端界面,结合Access数据库实现数据存储,专为教育机构打造的综合测评解决方案。系统包含学生管理、题库管理、在线测评、成绩分析四大核心模块,实现了测评流程的全自…...
湖北理元理律师事务所:债务咨询中的心理支持技术应用
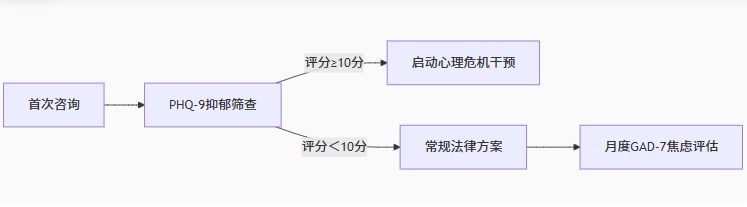
债务危机往往伴随心理崩溃。世界卫生组织研究显示,长期债务压力下抑郁症发病率提升2.3倍。湖北理元理律师事务所将心理干预技术融入法律咨询,构建“法律方案心理支持”的双轨服务模型。 一、债务压力下的心理危机图谱 通过对服务对象的追踪发现&#x…...

时间序列预测:LSTM与Prophet对比实验
时间序列预测:LSTM与Prophet对比实验 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 时间序列预测:LSTM与Prophet对比实验摘要引言实验设计1. 数据集选择2. 实验流程 模型架构对比1. LSTM架…...

阿里云域名怎么绑定
阿里云服务器绑定域名全攻略:一步步轻松实现网站“零”障碍上线! 域名,您网站在云端的“身份证”! 在数字化浪潮中,拥有一个属于自己的网站或应用,是个人展示、企业运营不可或缺的一环。而云服务器&#x…...
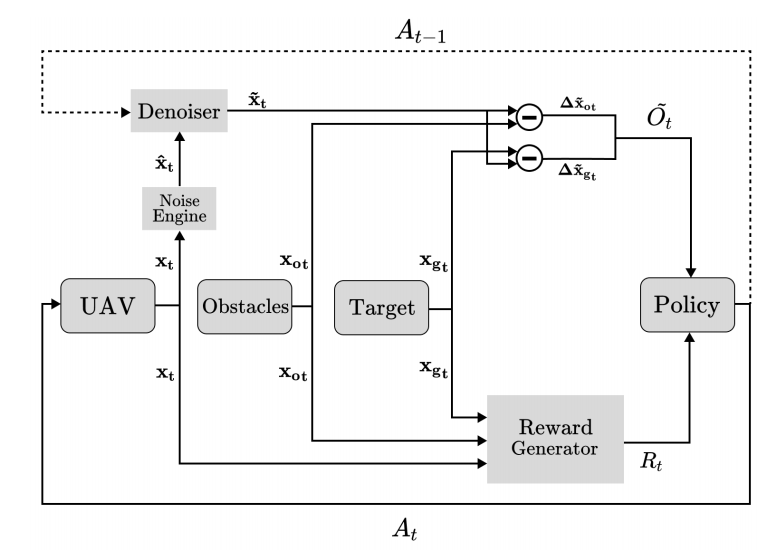
能上Nature封面的idea!强化学习+卡尔曼滤波
2025深度学习发论文&模型涨点之——强化学习卡尔曼滤波 强化学习(Reinforcement Learning, RL)与卡尔曼滤波(Kalman Filtering, KF)的交叉研究已成为智能控制与状态估计领域的重要前沿方向。 强化学习通过试错机制优化决策策…...