分库分表的取舍
文章目录
- 大数据量下采用**水平分表**的缺点
- **1. 跨表查询复杂性与性能下降**
- **2. 数据分布不均衡**
- **3. 分布式事务与一致性问题**
- **4. 扩展性受限**
- **5. 查询条件限制与索引管理复杂**
- **6. 数据迁移与维护成本高**
- **7. 业务逻辑复杂度增加**
- **总结**
- shardingJdbc分片策略
- **1. 标准分片策略(Standard)**
- **2. 复合分片策略(Complex)**
- **3. 行表达式分片策略(Inline)**
- **4. Hint分片策略(Hint)**
- **5. 不分片策略(None)**
- **分片策略选择建议**
- **注意事项**
- shardingJdbc和shardingProxy的区别
- **1. 架构与部署方式**
- **2. 侵入性与透明性**
- **3. 性能对比**
- **4. 配置与管理**
- **5. 功能支持**
- **6. 适用场景**
- **7. 配置示例对比**
- **Sharding-JDBC(YAML配置)**
- **Sharding-Proxy(server.yaml配置)**
- **总结选择建议**
大数据量下采用水平分表的缺点
1. 跨表查询复杂性与性能下降
- 问题:当查询需要跨多个分表(如
JOIN操作或跨分表的聚合查询)时,需合并多个表的结果,导致查询逻辑复杂化,且性能显著下降。- 原因:水平分表后,数据分散在不同表或不同数据库中,传统的 SQL 语句无法直接关联这些分表,需要应用层或中间件处理,增加了网络开销和计算复杂度。
- 示例:若用户订单表按
用户ID分表,查询某用户的历史订单需遍历所有分表,或需应用层合并结果。
2. 数据分布不均衡
- 问题:若分表规则设计不合理(如按时间范围或固定区间分表),可能导致某些分表数据量远超其他分表,引发资源不均衡。
- 原因:
- 热点分表:例如按时间范围分表时,新数据可能集中在最新分表,导致写入压力集中(如交易流水表)。
- 哈希分表的局限性:若业务数据天然存在分布不均(如某些用户数据量远超其他用户),哈希分表可能无法完全避免倾斜。
- 影响:部分分表成为性能瓶颈,甚至引发单点故障。
- 原因:
3. 分布式事务与一致性问题
- 问题:跨分表的事务操作难以保证原子性和一致性。
- 原因:
- 水平分表后,若数据分布在不同数据库或节点上,需依赖分布式事务(如两阶段提交,2PC),但会显著增加延迟和复杂度。
- MySQL 本身不支持跨分表的事务,需通过应用层或中间件实现,可能导致性能下降或数据不一致风险。
- 示例:转账操作涉及两个用户的分表,若其中一个分表操作失败,需手动回滚,容易引发数据不一致。
- 原因:
4. 扩展性受限
- 问题:扩容或调整分表策略时面临挑战。
- 哈希分表的扩展问题:
- 若分表数量增加(如从3个分表扩展到4个),需重新计算所有数据的哈希值并迁移数据,导致停机或性能下降(如[5]中一致性哈希的复杂性)。
- 范围分表的扩展问题:
- 新增分表需定义新的范围,但历史数据无法自动迁移,可能需手动调整查询逻辑。
- 哈希分表的扩展问题:
5. 查询条件限制与索引管理复杂
- 问题:
- 查询条件依赖分片键:若查询条件不包含分片键(如按
订单金额查询),需全表扫描所有分表,性能极差。 - 索引维护成本高:每个分表需独立维护索引,索引碎片化和维护成本成倍增加。
- 查询条件依赖分片键:若查询条件不包含分片键(如按
- 示例:若分片键是
用户ID,但业务需按商品ID查询,则需扫描所有分表。
6. 数据迁移与维护成本高
- 问题:
- 初始分表成本:将原有大表拆分为多个分表并迁移数据,需停机或复杂的数据迁移工具支持。
- 后期维护复杂:备份、恢复、数据迁移、索引优化等操作需针对每个分表单独执行,管理成本显著上升(如[3]提到的“数据库维护复杂”)。
7. 业务逻辑复杂度增加
- 问题:
- 路由逻辑复杂:需在应用层或中间件实现分片键到具体分表的映射(如哈希计算、范围判断)。
- 中间表映射的缺陷:若依赖中间表记录分片规则,可能引发中间表数据膨胀或查询性能下降(如[5]提到的中间表映射策略的缺点)。
总结
水平分表在解决单表数据量过大、提升查询性能和扩展性方面有显著优势,但其缺点主要集中在跨分片操作复杂性、数据分布不均、事务一致性挑战、扩展性限制以及维护成本上升。因此,在实施水平分表时需谨慎设计分片策略(如选择合适的分片键、采用一致性哈希等),并结合垂直分表、缓存、读写分离等方案综合优化系统架构。
shardingJdbc分片策略
ShardingJDBC的分片策略是其核心功能之一,用于实现数据分库分表的路由逻辑。根据知识库中的信息,以下是 分片策略的分类、特点及使用场景 的详细说明:
1. 标准分片策略(Standard)
-
定义:适用于单一分片键的场景,支持 精确查询(
=,IN)和 范围查询(BETWEEN,>,<等)。 -
配置要求
:
- 必须指定 分片键(
shardingColumn)和 分片算法名称(shardingAlgorithmName)。 - 支持两种算法:
- 精准分片算法(
PreciseShardingAlgorithm):处理=和IN的查询,必须实现。 - 范围分片算法(
RangeShardingAlgorithm):处理BETWEEN等范围查询,可选。若未配置,范围查询会全库扫描。
- 精准分片算法(
- 必须指定 分片键(
-
适用场景
:
- 单一字段分片(如
order_id分库分表)。 - 需要支持范围查询的场景(如按时间范围分表)。
- 单一字段分片(如
-
配置示例
(YAML):
yaml
深色版本
spring:shardingsphere:rules:sharding:tables:t_order:actual-data-nodes: db$->{0..1}.t_order_$->{0..10}databaseStrategy:standard:shardingColumn: order_idshardingAlgorithmName: db-inlinetableStrategy:standard:shardingColumn: order_idshardingAlgorithmName: table-inline
2. 复合分片策略(Complex)
-
定义:支持 多分片键 的组合分片,适用于跨表关联查询的场景。
-
特点
:
- 分片键为多个字段(如
user_id和order_time)。 - 需要开发者自定义分片算法(
ComplexShardingAlgorithm),直接处理分片键的组合逻辑。 - 适用于绑定表(如
t_order和t_order_item)的关联查询,避免笛卡尔积。
- 分片键为多个字段(如
-
适用场景
:
- 需要多条件联合分片的复杂查询(如
user_id和order_time)。 - 绑定表的跨表关联查询。
- 需要多条件联合分片的复杂查询(如
-
注意事项
:
- 复合分片会增加路由复杂度,需确保分片键组合能均匀分布数据。
- 需自行实现分片算法逻辑。
3. 行表达式分片策略(Inline)
-
定义:通过 Groovy表达式 简化分片配置,无需编写Java代码。
-
特点
:
- 支持单分片键,仅支持
=和IN的精确查询(不支持范围查询)。 - 表达式语法示例:
t_order_${order_id % 4}。
- 支持单分片键,仅支持
-
适用场景
:
- 简单的分片规则(如取模分表)。
- 避免编写复杂算法的场景。
-
配置示例
(YAML):
yaml
深色版本
spring:shardingsphere:rules:sharding:tables:t_order:actual-data-nodes: db0.t_order_$->{0..3}tableStrategy:inline:shardingColumn: order_idalgorithmExpression: t_order_${order_id % 4}
4. Hint分片策略(Hint)
-
定义:通过 代码提示 指定分片目标,无需依赖SQL解析。
-
特点
:
- 适用于无法通过SQL解析获取分片键的场景(如动态路由)。
- 需配合
HintManagerAPI 显式指定分片值。
-
适用场景
:
- 需要动态指定分片的场景(如根据用户ID路由到特定库表)。
- 避免SQL解析限制的场景(如SQL中包含函数或复杂表达式)。
-
使用示例
(Java代码):
java
深色版本
try (Connection conn = dataSource.getConnection()) {HintManager hintManager = HintManager.getInstance();hintManager.addDatabaseShardingValue("t_order", "user_id", 1001);// 执行SQL }
5. 不分片策略(None)
-
定义:指定某张表或某个操作 不分片,数据全部存储在单个库表中。
-
适用场景
:
- 广播表(如字典表、配置表)。
- 特定操作需要跨分片聚合时,需将结果汇总到单表。
-
配置示例
(YAML):
yaml
深色版本
spring:shardingsphere:rules:sharding:tables:t_dict:databaseStrategy:none: {}tableStrategy:none: {}
分片策略选择建议
- 单分片键 + 精准/范围查询 → 标准分片策略。
- 多分片键组合分片 → 复合分片策略。
- 简单规则(如取模) → 行表达式分片策略。
- 动态路由或复杂场景 → Hint分片策略。
- 广播表或无需分片的表 → 不分片策略。
注意事项
- 范围查询风险:若标准分片策略未配置范围分片算法,范围查询会全库扫描,性能极差。
- 复合分片复杂度:需确保多分片键的组合能均匀分布数据,避免热点。
- SQL兼容性:某些SQL函数或操作符可能导致分片失效,需避免使用或结合Hint策略。
shardingJdbc和shardingProxy的区别
1. 架构与部署方式
| 特性 | Sharding-JDBC | Sharding-Proxy |
|---|---|---|
| 定位 | Java框架,以JAR包形式集成到应用中 | 独立的数据库代理服务器,无需修改应用代码 |
| 部署方式 | 直接嵌入应用,与应用进程共存 | 独立部署为中间件服务,应用通过代理连接 |
| 网络通信 | 应用直接连接数据库,一次网络跳转 | 应用连接Proxy,Proxy再连接数据库,两次网络跳转 |
2. 侵入性与透明性
| 特性 | Sharding-JDBC | Sharding-Proxy |
|---|---|---|
| 侵入性 | 需要在应用中集成配置,对应用有一定侵入性 | 对应用完全透明,无需修改代码,无侵入性 |
| 透明性 | 仅支持Java应用,需依赖Sharding-JDBC驱动 | 支持任何兼容MySQL/PostgreSQL协议的客户端 |
3. 性能对比
| 特性 | Sharding-JDBC | Sharding-Proxy |
|---|---|---|
| 网络开销 | 一次网络跳转(应用直连数据库) | 两次网络跳转(应用→Proxy→数据库),性能略低 |
| 适用场景 | 高性能OLTP场景(如高频交易系统) | OLAP分析、运维管理、多语言支持场景 |
4. 配置与管理
| 特性 | Sharding-JDBC | Sharding-Proxy |
|---|---|---|
| 配置方式 | 通过代码或Spring配置文件(如YAML/XML) | 通过配置文件(如server.yaml)或注册中心(如ZooKeeper)动态配置 |
| 动态调整 | 需重启应用或重新加载配置 | 支持热更新,无需重启Proxy |
| 管理友好性 | 开发者主导,适合开发阶段 | 对DBA友好,支持工具(如ShardingSphere-UI) |
5. 功能支持
| 特性 | Sharding-JDBC | Sharding-Proxy |
|---|---|---|
| 分片能力 | 完全支持分库分表、读写分离、柔性事务等 | 完全支持分库分表、读写分离、柔性事务等 |
| 多语言支持 | 仅支持Java生态(如Spring、MyBatis) | 支持任何MySQL/PostgreSQL客户端(如Python、Go、Navicat) |
| 分布式治理 | 支持配置中心、熔断、动态失效转移 | 同样支持,但通过代理层实现 |
| SQL兼容性 | 完全兼容JDBC和ORM框架 | 兼容MySQL/PostgreSQL协议,需注意SQL语法限制 |
6. 适用场景
| 场景 | 推荐使用Sharding-JDBC | 推荐使用Sharding-Proxy |
|---|---|---|
| 技术栈 | 纯Java应用(如Spring Boot) | 多语言应用、需要DBA管理或第三方工具访问 |
| 性能要求 | 高并发、低延迟的OLTP场景 | 分析查询、运维管理、跨语言协作场景 |
| 扩展性需求 | 需要与应用强耦合,快速迭代 | 需要集中管理分片规则,支持动态调整 |
7. 配置示例对比
Sharding-JDBC(YAML配置)
spring:shardingsphere:datasource:names: ds0, ds1ds0:url: jdbc:mysql://localhost:3306/ds0username: rootpassword: rootdriver-class-name: com.mysql.cj.jdbc.Driverrules:sharding:tables:t_order:actual-data-nodes: ds$->{0..1}.t_order_$->{0..2}table-strategy:standard:sharding-column: order_idsharding-algorithm-name: t_order-inlinesharding-algorithms:t_order-inline:type: INLINEprops:algorithm-expression: t_order_$->{order_id % 3}
Sharding-Proxy(server.yaml配置)
schema-name: sharding_db
dataSources:ds0:url: jdbc:mysql://localhost:3306/ds0username: rootpassword: rootconnectionTimeoutSeconds: 30idleTimeoutSeconds: 60maxLifetimeSeconds: 1800maxPoolSize: 50
shardingRule:tables:t_order:actualDataNodes: ds$->{0..1}.t_order_$->{0..2}tableStrategy:standard:shardingColumn: order_idshardingAlgorithmName: t_order_inlineshardingAlgorithms:t_order_inline:type: INLINEprops:algorithm-expression: t_order_$->{order_id % 3}
总结选择建议
-
选Sharding-JDBC:
- 纯Java应用,追求高性能和低延迟。
- 需要与业务代码深度集成,如Spring Boot项目。
- 对分片规则的动态调整需求较低,或能接受重启应用。
-
选Sharding-Proxy:
- 多语言应用或需要DBA直接管理分片规则。
- 需要动态调整分片策略且无需重启服务。
- 需要通过工具(如Navicat、MySQL Workbench)直接操作分片数据。
相关文章:

分库分表的取舍
文章目录 大数据量下采用**水平分表**的缺点**1. 跨表查询复杂性与性能下降****2. 数据分布不均衡****3. 分布式事务与一致性问题****4. 扩展性受限****5. 查询条件限制与索引管理复杂****6. 数据迁移与维护成本高****7. 业务逻辑复杂度增加****总结** shardingJdbc分片策略**1…...

随机算法一文深度全解
随机算法一文深度全解 一、随机算法基础1.1 定义与核心特性1.2 算法优势与局限 二、随机算法经典案例2.1 随机化快速排序原理推导问题分析与策略代码实现(Python、Java、C) 2.2 蒙特卡罗方法计算 π 值原理推导问题分析与策略代码实现(Python…...
在 Conda 环境下配置 Jupyter Notebook 环境和工作目录
作为数据科学家或Python开发者,Jupyter Notebook 是我们日常工作的得力工具。本文将详细介绍如何在 Conda 环境中配置 Jupyter Notebook,包括环境设置和工作目录管理,帮助你打造高效的工作流程。 为什么要在 Conda 环境中使用 Jupyter Noteb…...
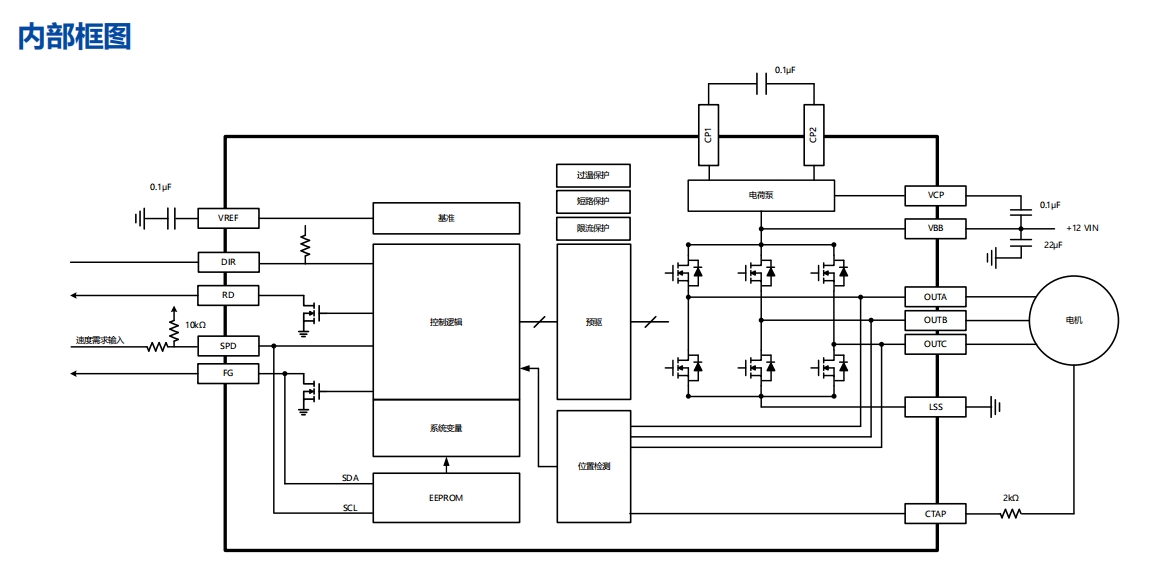
MS39531N 是一款正弦驱动的三相无感直流电机驱动器,具有最小振动和高效率的特点
MS39531N 是一款正弦驱动的三相无感直流电机驱动器,具有最小振动和高效率的特点 简述 MS39531 是一款正弦驱动的 三相无感直流电机驱动器 ,具有最小振动和高效率的特点。该驱动器内部集成了基本的闭环速度控制功能,能够根据特定的应用定制电…...
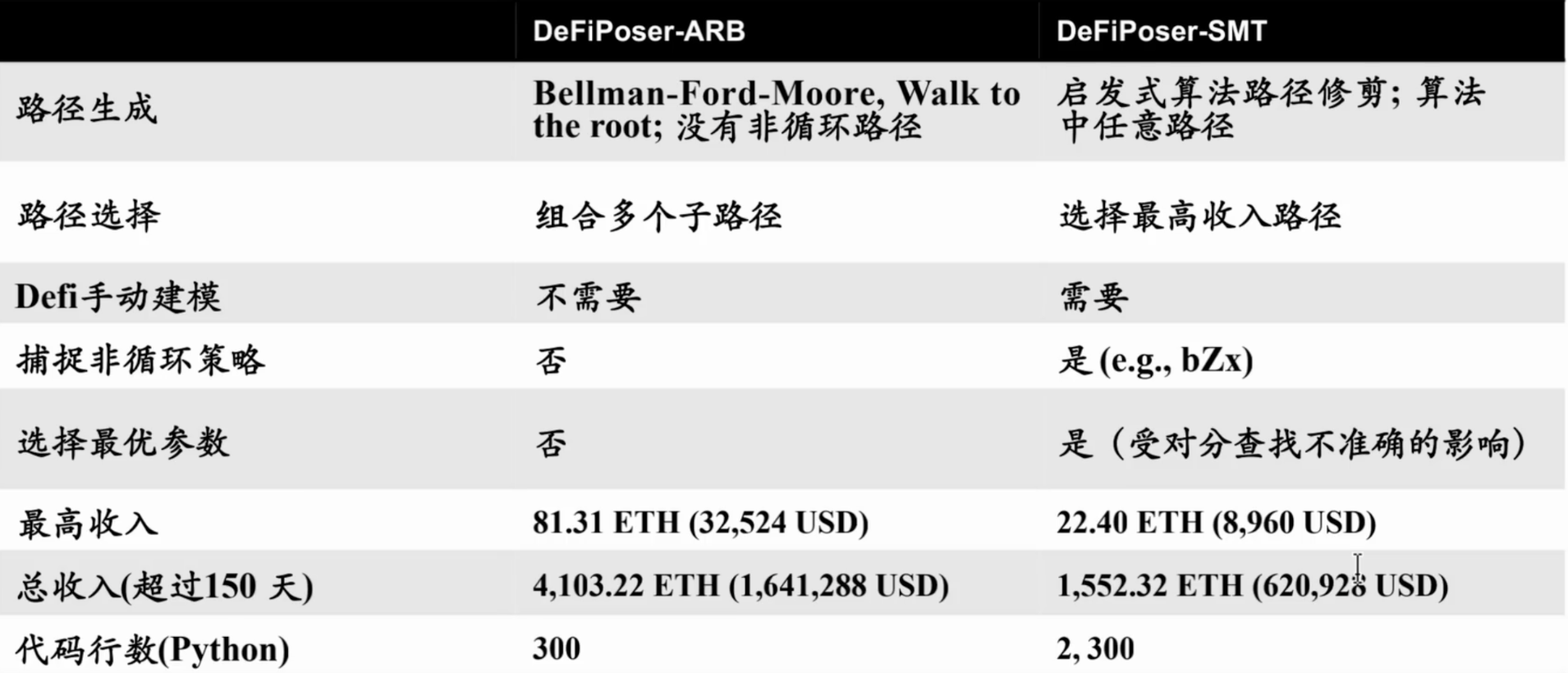
web3-基于贝尔曼福特算法(Bellman-Ford )与 SMT 的 Web3 DeFi 套利策略研究
web3-基于贝尔曼福特算法(Bellman-Ford )与 SMT 的 Web3 DeFi 套利策略研究 如何找到Defi中的交易机会 把defi看做是一个完全开放的金融产品图表,可以看到所有的一切东西;我们要沿着这些金融图表找到一些最优的路径,就…...
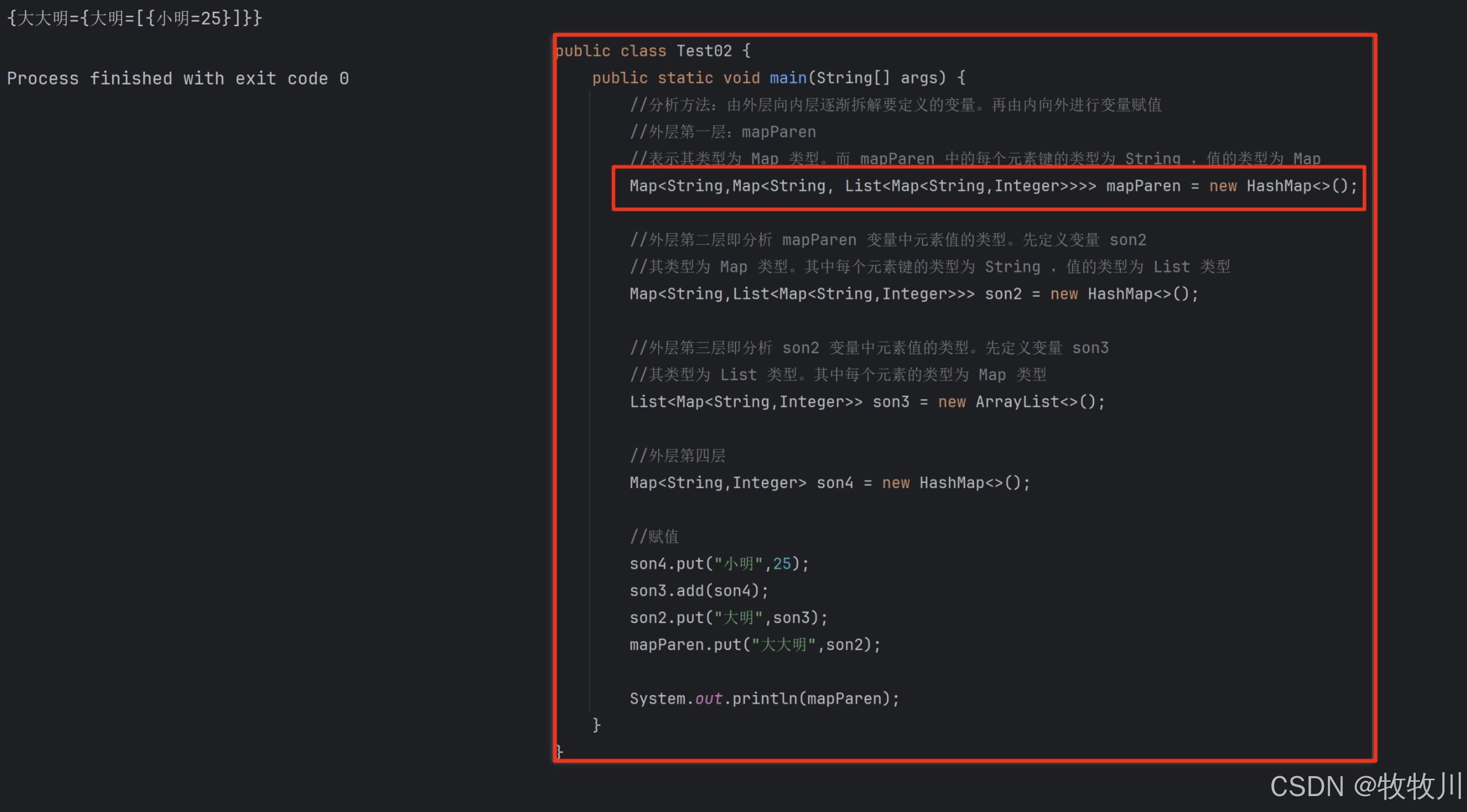
分析 java 的 Map<String,Map<String, List<Map<String,Integer>>>>
import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map;public class Test02 {public static void main(String[] args) {//分析方法:由外层向内层逐渐拆解要定义的变量。再由内向外进行变量赋值//外层第一层&#x…...

ChatterBox - 轻巧快速的语音克隆与文本转语音模型,支持情感控制 支持50系显卡 一键整合包下载
ChatterBox 是一个近期备受关注的开源语音克隆与文本转语音(TTS)模型,由 Resemble AI 推出,具备体积轻巧及超快的推理速度等特色。它也是首个支持情感夸张控制的开放源代码 TTS 模型,这一强大功能能让您的声音脱颖而出…...

前端开发面试题总结-HTML篇
文章目录 HTML面试高频问答一、HTML 的 src 和 href 属性有什么区别?二、什么是 HTML 语义化?三、HTML的 script 标签中 defer 和 async 有什么区别?四、HTML5 相比于 HTML有哪些更新?五、HTML行内元素有哪些? 块级元素有哪些? 空(void)元素有哪些?六、iframe有哪些优点…...
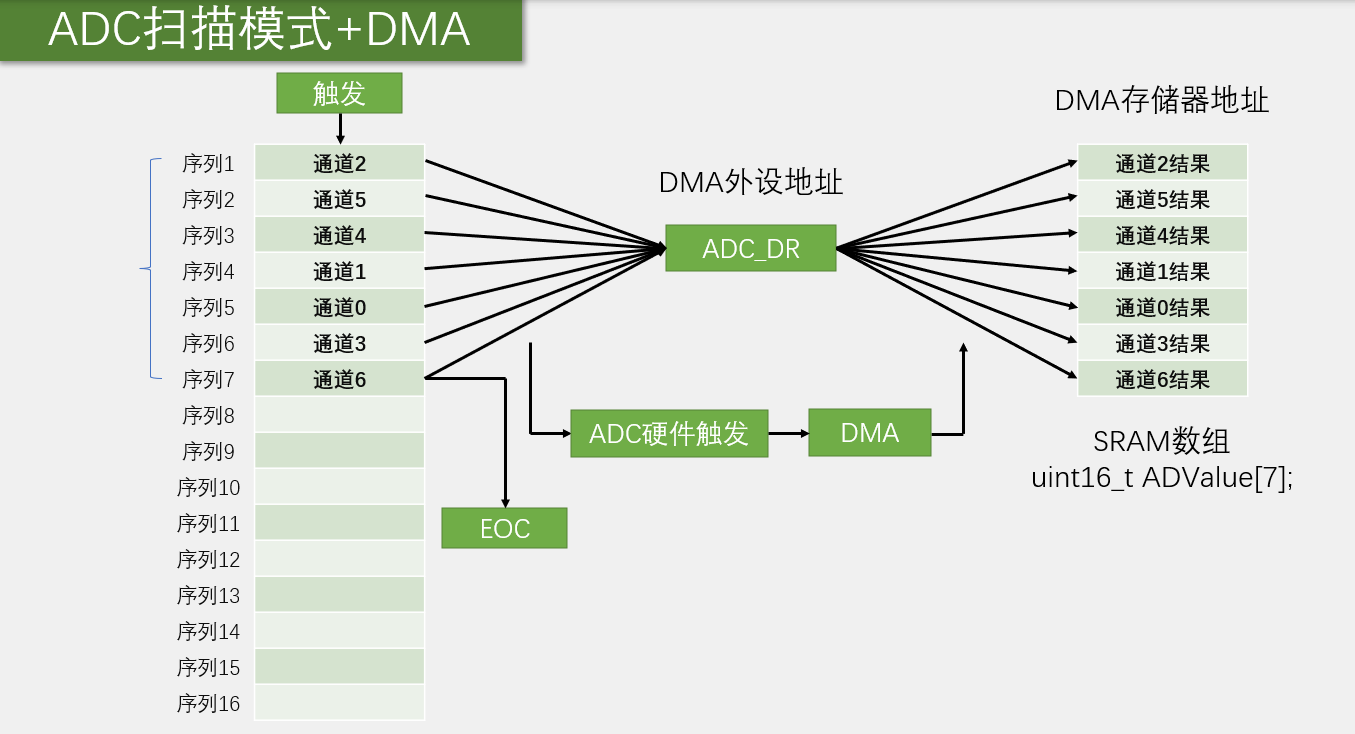
嵌入式学习--江协stm32day4
只能说拖延没有什么好结果,欠下的债总是要还的。 ADC 模拟信号转化为数字信号,例如温度传感器将外部温度的变化(模拟信号),转换为内部电压的变化(数字信号) IN是八路输入,下方是选择…...
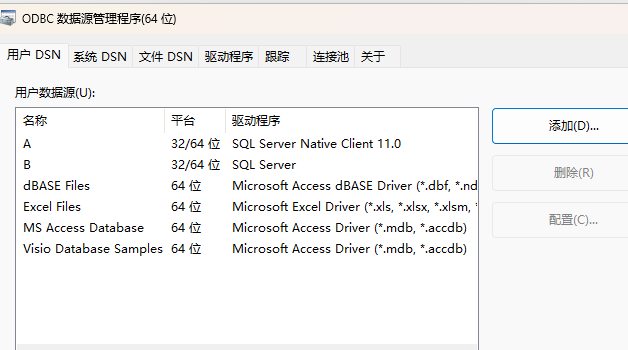
【Matlab】连接SQL Server 全过程
文章目录 一、下载与安装1.1 SQL Server1.2 SSMS1.3 OLE DB 驱动程序 二、数据库配置2.1 SSMS2.2 SQL Server里面设置2.3 设置防火墙2.4 设置ODBC数据源 三、matlab 链接测试 一、下载与安装 微软的,所以直接去微软官方下载即可。 1.1 SQL Server 下载最免费的Ex…...

MS8551/MS8552/MS8554 单电源、轨到轨输入输出、高精度运放,可替代AD8551/AD8552/AD8554
MS8551/MS8552/MS8554 单电源、轨到轨输入输出、高精度运放,可替代AD8551/AD8552/AD8554 简述 MS8551/8552/8554 是轨到轨输入输出的高精度运算放大器,它有极低的输入失调电压和偏置电流,单电源电压范围为 1.8V 到 5V 。 MS8551/8552/85…...

什么是 Ansible 主机和组变量
Ansible 是一款强大的自动化工具,可简化配置管理、应用程序部署和预配等 IT 任务。其最有价值的功能之一是能够定义变量,从而为不同的主机和组定制剧本。本文将解释 Ansible 中组变量和主机变量的概念,并通过实际示例说明它们的用法。 Ansib…...

F#语言的区块链
F#语言在区块链中的应用 引言 区块链技术在过去十年中迅速崛起,成为了推动金融、供应链、物联网等多个领域创新的重要力量。近年来,随着区块链技术的普及,各种编程语言也纷纷被应用于区块链的开发中。F#语言作为一种功能性编程语言…...

9.RV1126-OPENCV 视频的膨胀和腐蚀
一.膨胀 1.视频流的膨胀流程 之前膨胀都是在图片中进行的,现在要在视频中进行也简单,大概思路就是:获取VI数据,然后把VI数据给Mat化发给VENC模块,然后VENC模块获取,这样就完成了。流程图: 2.代…...

查找 Vue 项目中未使用的依赖
在 Vue 项目中查找未使用的依赖可以通过以下几种方法: 1. 使用 depcheck 工具 depcheck 是一个专门用于查找项目中未使用依赖的工具。 安装: bash npm install -g depcheck使用: bash depcheck它会列出: 未使用的依赖缺失…...
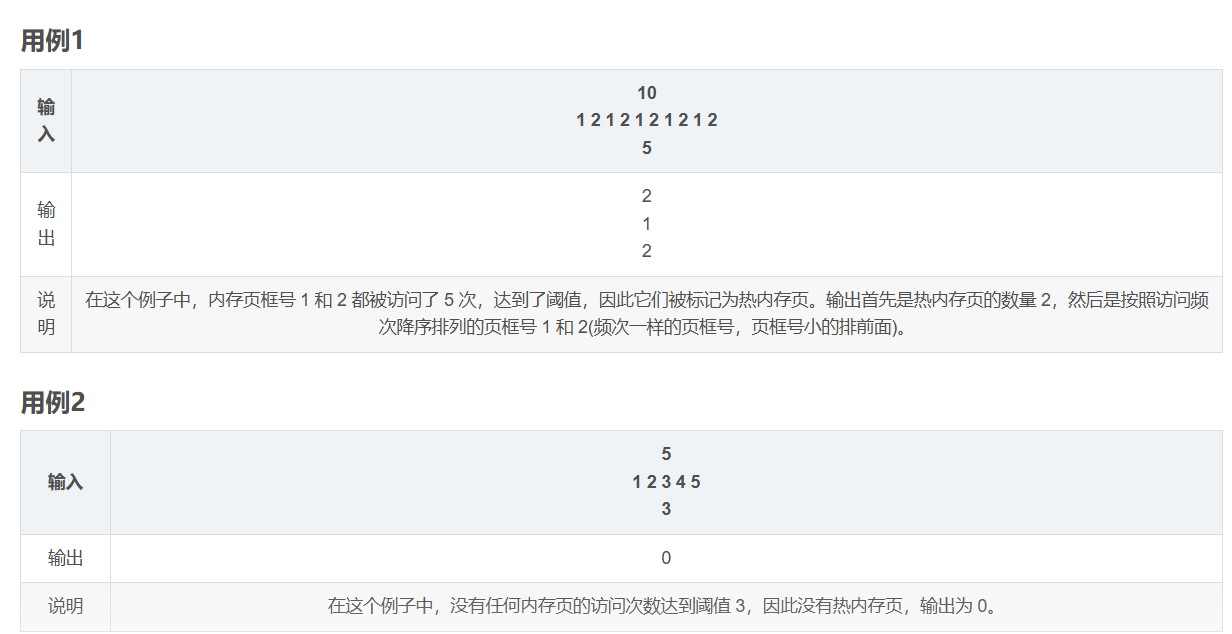
华为OD机考-内存冷热标记-多条件排序
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextInt();int[] arr new int[a];for(int…...

UDP 与 TCP 调用接口的差异:面试高频问题解析与实战总结
在日常开发中,我们经常使用封装良好的 TCP 协议栈,比如 HTTP 客户端、Moudou 网络库等,因此很少从“裸 API”角度深入了解 TCP 和 UDP 的套接字调用流程。但在一些系统底层开发或者网络编程面试中,常被问到“TCP 和 UDP 的调用流程…...

AI时代:学习永不嫌晚,语言多元共存
最近看到两个关于AI的两个问题,“现在开始学习AI,是不是为时已晚?”、“AI出现以后,翻译几乎已到末路,那么,随着时代的进步,中文会一统全球吗?” 联想到自己正在做的“万能AI盒”小程…...

『React』Fragment的用法及简写形式
在 React 渲染组件时,每个组件只能返回一个根节点(root element)。传统上,如果我们需要渲染多条并列的元素,通常会使用一个多余的 <div> 或者其他容器标签将它们包裹起来。但是,这样会在最终的 HTML …...

强化学习入门:交叉熵方法数学推导
前言 最近想开一个关于强化学习专栏,因为DeepSeek-R1很火,但本人对于LLM连门都没入。因此,只是记录一些类似的读书笔记,内容不深,大多数只是一些概念的东西,数学公式也不会太多,还望读者多多指教…...

CSS3 的特性
目录 CSS3 的特性CSS3 的三大特性1. 层叠性2. 继承性3. 优先级 CSS3 新增特性1. 选择器2. 盒模型3. 背景4. 渐变5. 过渡6. 动画7. 2D/3D 变换8. 弹性布局9. 网格布局10. 媒体查询11. 多列布局12. 文字阴影和盒子阴影 CSS3 的特性 CSS3 的三大特性 1. 层叠性 定义:…...

Vue前端篇——Vue 3的watch深度解析
📌 前言 在 Vue.js 的世界中,“数据驱动”是其核心理念之一。而在这一理念下,watch 扮演着一个非常关键的角色。它允许我们监听响应式数据的变化,并在其发生变化时执行特定的业务逻辑。 本文将通过实际代码示例,深入…...
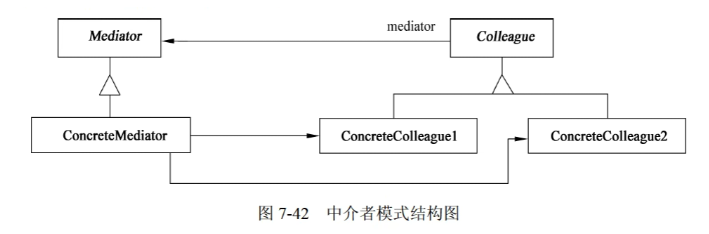
行为型设计模式之Mediator(中介者)
行为型设计模式之Mediator(中介者) 1)意图 用一个中介对象来封装一系列的对象的交互。中介者使各对象不需要显示的相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。 2)结构 其中ÿ…...

三维图形、地理空间、激光点云渲染技术术语解析笔记
三维图形、地理空间、激光点云渲染技术术语解析笔记 code review! 文章目录 三维图形、地理空间、激光点云渲染技术术语解析笔记1. Minecraft风格的方块渲染2. Meshing(网格化)3. Mipmapping(多级纹理映射)4. Marching Cubes&…...
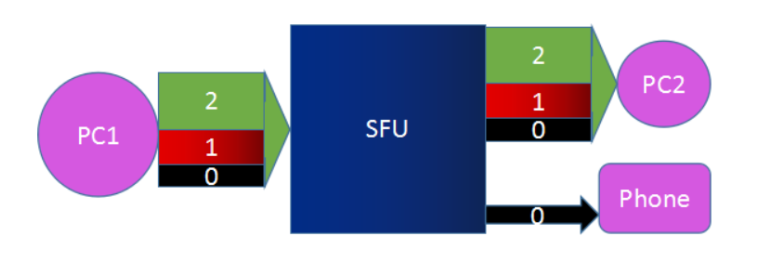
从webrtc到janus简介
1.基础知识 1.1 信令的基础知识 在 WebRTC(Web Real-Time Communication) 中,信令(Signaling) 是实现浏览器之间实时通信的关键机制,负责在通信双方(或多方)之间传递控制信息&…...

JVM 核心概念深度解析
最近正在复习Java八股,所以会将一些热门的八股问题,结合ai与自身理解写成博客便于记忆 一、JVM内存结构/运行时数据区 JVM运行时数据区主要分为以下几个部分: 程序计数器(PC Register) 线程私有,记录当前线程执行的字节码行号唯…...
api将token设置为环境变量
右上角 可以新增或者是修改当前的环境 环境变量增加一个token,云端值和本地值可以不用写 在返回token的接口里设置后执行操作,通常是登录的接口 右侧也有方法提示 //设置环境变量 apt.environment.set("token", response.json.data.token); 在需要传t…...

SIFT算法详细原理与应用
SIFT算法详细原理与应用 1 SIFT算法由来 1.1 什么是 SIFT? SIFT,全称为 Scale-Invariant Feature Transform(尺度不变特征变换),是一种用于图像特征检测和描述的经典算法。它通过提取图像中的局部关键点,…...
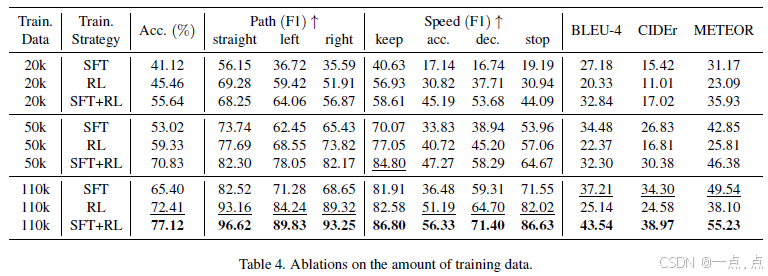
AlphaDrive:通过强化学习和推理释放自动驾驶中 VLM 的力量
AlphaDrive: Unleashing the Power of VLMs in Autonomous Driving via Reinforcement Learning and Reasoning 25年3月来自华中科技大学和地平线的论文 OpenAI 的 o1 和 DeepSeek R1 在数学和科学等复杂领域达到甚至超越了人类专家水平,其中强化学习(R…...

【八股消消乐】如何解决SQL线上死锁事故
😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本专栏《八股消消乐》旨在记录个人所背的八股文,包括Java/Go开发、Vue开发、系统架构、大模型开发、具身智能、机器学习、深度学习、力扣算法等相关知识点ÿ…...