JDK8新特性之Steam流
这里写目录标题
- 一、Stream流概述
- 1.1、传统写法
- 1.2、Stream写法
- 1.3、Stream流操作分类
- 二、Stream流获取方式
- 2.1、根据Collection获取
- 2.2、通过Stream的of方法
- 三、Stream常用方法介绍
- 3.1、forEach
- 3.2、count
- 3.3、filter
- 3.4、limit
- 3.5、skip
- 3.6、map
- 3.7、sorted
- 3.8、distinct
- 3.9、match
- 3.10、find
- 3.11、max和min
- 3.12、reduce方法
- 3.12.1、 map和reduce的组合
- 3.13、mapToInt
- 3.14、concat
- 3.15、综合案例
- 4.1、结果收集到集合中
- 四、Stream结果手集
- 4.1、结果收集到集合中
- 4.2、结构收集到数组中
- 4.3、对流中数据做聚合操作
- 4.4、对流中数据做分组操作
- 4.5、对流中数据做分区操作
- 4.6、对流中数据做拼接
- 五、并行Stream流
- 5.1、串行的Stream流
- 5.2、并行流
- 5.2.1、获取并行流
- 5.2.3、并行流操作
- 5.3、并行流和串行流对比
- 5.4、线程安全
一、Stream流概述
Java 中,Stream 是一个来自java.util.stream包的接口,用于对集合(如List、Set等)或数组等数据源进行操作的一种抽象层。
Stream流(和IO流没有任何关系)主要是对数据进行加工处理的。Stream API能让我们快速完成许多复杂的操作,如筛选、切片、映射、查找、去除重复,统计,匹配和归约。
1.1、传统写法
现在有需求:对list中姓张,名字长度为3的信息打印:
public static void main(String[] args) {//定义一个List集合List<String> list = Arrays.asList("张三","张三丰","张无忌","李四","王五");//获取姓张,名字长度为3的信息,添加到列表中List<String> list1=new ArrayList<>();for (String s : list) {if(s.startsWith("张")&&s.length()==3){list1.add(s);}}for (String s : list1) {System.out.println(s);}}
1.2、Stream写法
public static void main(String[] args) {//定义一个List集合List<String> list = Arrays.asList("张三","张三丰","张无忌","李四","王五");list.stream().filter(s -> s.startsWith("张")).filter(s -> s.length()== 3).forEach(System.out::println);}
上面的SteamAPI代码的含义:获取流,过滤张,过滤长度,逐一打印。代码相比于上面的案例更加的简洁直观。
1.3、Stream流操作分类
- 生成操作
通过数据源(集合、数组等)生成流。 - 中间操作
对流进行某种程度的过滤/映射,并返回一个新的流。 - 终结操作
执行某个终结操作,一个流只能有一个终结操作。
二、Stream流获取方式
2.1、根据Collection获取
java.util.Collection 接口中加入了default方法 stream,也就是说Collection接口下的所有的实现都可以通过steam方法来获取Stream流。(java集合框架主要包括两种类型的容器,一种是集合,存储一个元素集合(Collection),另一种是图(Map),存储键/值对映射)。
public static void main(String[] args) {List<String> list=new ArrayList<>();Stream<String> stream=list.stream();Set<String> set=new HashSet<>();Stream<String> stream1=set.stream();Vector vector=new Vector();vector.stream();}
Map接口别没有实现Collection接口,这时我们可以根据Map获取对应的key value的集合。
public static void main(String[] args) {Map<String,Object> map=new HashMap<>();Stream<String> stream=map.keySet().stream();//keyStream<Object> stream1=map.values().stream();//valueStream<Map.Entry<String,Object>> stream2=map.entrySet().stream();//entry}
2.2、通过Stream的of方法
由于数组对象不可能添加默认方法,所有Stream接口中提供了静态方法of操作到数组中的数据
public static void main(String[] args) {Stream<String> a1= Stream.of("a1","a2","a3");String[] arr1 = {"aa","bb","cc"};Stream<String> arr11 = Stream.of(arr1);Integer[] arr2 = {1,2,3,4};Stream<Integer> arr21 = Stream.of(arr2);arr21.forEach(System.out::println);// 注意:基本数据类型的数组是不行的int[] arr3 = {1,2,3,4};Stream.of(arr3).forEach(System.out::println);}
三、Stream常用方法介绍
Stream常用方法
| 方法名 | 方法作用 | 返回值类型 | 防范种类 |
|---|---|---|---|
| count | 统计个数 | long | 终结 |
| forEach | 逐一处理 | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取用前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
| 注意: |
- 这里把常用的API分为“终结方法”和“非终结方法”
- “终结方法”:返回值类型不再是 Stream 类型的方法,不再支持链式调用。
- “非终结方法”:返回值类型仍然是 Stream 类型的方法,支持链式调用。
- Stream方法返回的是新的流。
- Stream不调用终结方法,中间的操作不会执行。
3.1、forEach
forEach用来遍历流中的数据的。
void forEach(Consumer<? super T> action);
该方法接受一个Consumer接口,会将每一个流元素交给函数处理。
public static void main(String[] args) {Stream<String> a1=Stream.of("aa","bb","cc");a1.forEach(System.out::println);}
3.2、count
Stream流中的count方法用来统计其中的元素个数的。
long count();
该方法返回一个long值,代表元素的个数。
public static void main(String[] args) {long count = Stream.of("a1", "a2", "a3").count();System.out.println(count);}
3.3、filter
filter方法的作用是用来过滤数据的。返回符合条件的数据。
可以通过filter方法将一个流转换成另一个子集流。
public static void main(String[] args) {Stream<String> stream =Stream.of("aa", "ab", "bc","a1","b2","c3").filter(s -> s.contains("a"));stream.forEach(System.out::println);}
该接口接收一个Predicate函数式接口参数作为筛选条件。
3.4、limit
limit方法可以对流进行截取处理,支取前n个数据,
Stream<T> limit(long maxSize);
参数式一个long类型的数值,如果集合当前长度大于参数就进行截取,否则不操作:
public static void main(String[] args) {Stream.of("a1", "a2", "a3","bb","cc","aa","dd").limit(3).forEach(System.out::println);}
3.5、skip
如果希望跳过前面几个元素,可以使用skip方法获取一个截取之后的新流:
Stream<T> skip(long n);
示例:
public static void main(String[] args) {Stream.of("a1","b2","c3","aa","bb","cc").skip(3).forEach(System.out::println);}
3.6、map
如果需要将流中的元素映射到另一个流中,可以使用map方法:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
该接口需要一个Function函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的数据
public static void main(String[] args) {Stream.of("1","2","3","4","5")//.map(s -> Integer.parseInt(s)).map(Integer::parseInt).forEach(System.out::println);}
3.7、sorted
如果需要将数据排序,可以使用sorted方法:
Stream<T> sorted();
在使用的时候可以根据自然规则排序,也可以通过比较强来指定对应的排序规则
public static void main(String[] args) {Stream.of("1","2","7","9","3","4","6").map(Integer::parseInt).sorted((o1, o2) -> (o1 - o2)).forEach(System.out::println);}
3.8、distinct
如果要去掉重复数据,可以使用distinct方法
Stream<T> distinct();
Stream流中的distinct方法对于基本数据类型式可以直接去重的,但是对于自定义类型,我们需要重写hashCode和equals方法来移除重复数据。
public static void main(String[] args) {Stream.of("1","2","4","5","2","3","4").sorted().distinct().forEach(System.out::println);System.out.println("----------------");Stream.of(new Person("张三",18),new Person("李四",18),new Person("王五",20),new Person("张三",18)).distinct().forEach(System.out::println);}
3.9、match
如果需要判断数据是否匹配指定的条件,可以使用match相关的方法:
boolean anyMatch(Predicate<? super T> predicate); // 元素是否有任意一个满足条件
boolean allMatch(Predicate<? super T> predicate); // 元素是否都满足条件
boolean noneMatch(Predicate<? super T> predicate); // 元素是否都不满足条件
使用:
public static void main(String[] args) {boolean b = Stream.of("1","2","3","4","5","7").map(Integer::parseInt)//.anyMatch(s-> s > 4);//.allMatch(s-> s > 4);.noneMatch(s-> s > 4);System.out.println(b);}
注:match是一个终结方法。
3.10、find
如果我们需要找到某些数据,可以使用find方法来实现
Optional<T> findFirst();Optional<T> findAny();
使用:
public static void main(String[] args) {Optional<String> first = Stream.of("a", "b", "c").findFirst();System.out.println(first.get());Optional<String> any = Stream.of("a", "b", "c","d").findAny();System.out.println(any.get());}
注:
3.11、max和min
如果我们想要获取最大值和最小值,那么可以使用max和min方法
public static void main(String[] args) {Optional<Integer> max= Stream.of(1,2,3,4).max(Integer::compareTo);System.out.println(max.get());Optional<Integer> min= Stream.of(1,2,3,4).min(Integer::compareTo);System.out.println(min.get());}
3.12、reduce方法
如果需要将所有数据归纳得到一个数据,可以使用reduce方法:
public static void main(String[] args) {Integer sum = Stream.of(4,5,3,7)//identity默认值//第一次的时候会将默认值赋给x//之后每次将上一次的操作结果赋值给x y,就是每次从数据中获取的元素.reduce(0, (x, y) -> {System.out.println("x="+x+",y="+y);return x + y;});System.out.println("sum = " + sum);// 获取最大值Integer max = Stream.of(4,5,3,9).reduce(0,(x,y) ->{return x>y?x:y;});System.out.println("max = " + max);}
3.12.1、 map和reduce的组合
在实际开发中我们经常会将map和reduce一块来使用:
public static void main(String[] args) {//1、求出所有年龄总和Integer sumAge= Stream.of(new Person("张三", 20),new Person("李四", 21),new Person("王五", 22),new Person("赵六", 23)).map(Person::getAge).reduce(0,Integer::sum);System.out.println(sumAge);//2、求出所有年龄最大值Integer maxAge= Stream.of(new Person("张三", 20),new Person("李四", 21),new Person("王五", 22),new Person("赵六", 23)).map(Person::getAge).reduce(Integer::max).get();System.out.println(maxAge);//3、统计字符 a 出现的次数Integer countA= Stream.of("a","b","c","d","e","a","a","a").map(ch -> ch.equals("a")?1:0).reduce(0,Integer::sum);System.out.println(countA);}
3.13、mapToInt
如果需要将Sream中的Integer类型转换成int类型,可以使用mapToInt方法来实现
public static void main(String[] args) {//Integer 占用的内存比int多很多,在Stream流操作中会自动装修和拆箱操作Integer arr[] ={1,2,3,4,6,7,8};Stream.of(arr).filter(x -> x > 0).forEach(System.out::println);//为了提高程序代码效率,可以先将流中Integer数据转为为int数据IntStream intStream = Stream.of(arr).mapToInt(Integer::intValue);intStream.forEach(System.out::println);}
3.14、concat
如果有两个流,希望合并成为一个流,那么可以使用Stream接口防范concat
public static void main(String[] args) {Stream<String> steam1=Stream.of("a","b","c");Stream<String> steam2=Stream.of("x","y","z");//通过concat方法将两个流合并成一个新的流Stream.concat(steam1,steam2).forEach(System.out::println);}
3.15、综合案例
4.1、结果收集到集合中
public static void main(String[] args) {List<String> list1 = Arrays.asList("迪丽热巴", "宋远桥", "苏星河", "老子","庄子", "孙子", "洪七公");List<String> list2 = Arrays.asList("古力娜扎", "张无忌", "张三丰", "赵丽颖","张二狗", "张天爱", "张三");Stream<String> stream1 = list1.stream().filter(s -> s.length() == 3).limit(3);Stream<String> stream2 =list2.stream().filter(s -> s.startsWith("张")).skip(2);Stream.concat(stream1,stream2)//.map(s -> new Person(s)).map(Person::new).forEach(System.out::println);}
四、Stream结果手集
4.1、结果收集到集合中
@Testpublic void test01(){//收集到list集合中List<String> list= Stream.of("a","b","c").collect(Collectors.toList());System.out.println(list);//收集到set集合中Set<String> set = Stream.of("aa","bb","cc","dd").collect(Collectors.toSet());System.out.println(set);//如果需要获取的类型为具体实现ArrayList<String> arrayList = Stream.of("aaa","bbb","ccc")//.collect(Collectors.toCollection(() -> new ArrayList<>()));.collect(Collectors.toCollection(ArrayList::new));System.out.println(arrayList);}
4.2、结构收集到数组中
Stream中提供了toArray方法来将结果放到一个数组中,返回值类型是Object[]。
如果我们要指定返回的类型,那么可以使用另一个重载的toArray(IntFunction f)方法。
@Testpublic void test02(){//收集结果到数组中,数据类型是ObjectObject[] objects = Stream.of("aaa","bbb","ccc").toArray();System.out.println(Arrays.toString(objects));//收集结构到数组中,数据类型是StringString[] strings = Stream.of("aaa","bbb","ccc").toArray(String[]::new);System.out.println(Arrays.toString(strings));}
4.3、对流中数据做聚合操作
当我们使用Stream流处理数据后,可以根据某个属性将数据分组
@Testpublic void test03(){//获取年龄最大值List<Person> personList= Arrays.asList(new Person("张三",20),new Person("李四",25),new Person("王五",30),new Person("赵六",35));Optional<Person> maxAgePerson = personList.stream()//.collect(Collectors.maxBy(Comparator.comparingInt(Person::getAge)));.collect(Collectors.maxBy((p1,p2)->p1.getAge()-p2.getAge()));System.out.println("最大年龄: "+maxAgePerson.get());//获取年龄最小值Optional<Person> minAgePerson = personList.stream().collect(Collectors.minBy((p1,p2)->p1.getAge()-p2.getAge()));System.out.println("最小年龄: "+minAgePerson.get());//求所有人的年龄之和Integer sumAge = personList.stream().collect(Collectors.summingInt(Person::getAge));System.out.println("年龄总和:" + sumAge);//求所有人的年龄平均值Double avgAge = personList.stream().collect(Collectors.averagingInt(Person::getAge));System.out.println("年龄的平均值:" + avgAge);//统计数量Long count = personList.stream().filter(p-> p.getAge() > 20).collect(Collectors.counting());System.out.println("满足条件的记录数:" + count);}
4.4、对流中数据做分组操作
当我们使用Stream流处理数据后,可以根据某个属性将数据分组
public void test04(){List<Person> personList= Arrays.asList(new Person("张三", 18, 175), new Person("李四", 22, 177), new Person("张三", 14, 165), new Person("李四", 15, 166), new Person("张三", 19, 182));//根据姓名对数据分组Map<String,List<Person>> map1= personList.stream().collect(Collectors.groupingBy(Person::getName));map1.forEach((k,v)-> System.out.println("k=" + k +"\t"+ "v=" + v));System.out.println("-----------");Map<String, List<Person>> map2 = personList.stream().collect(Collectors.groupingBy(p -> p.getAge() >= 18 ? "成年" : "未成年"));map2.forEach((k,v)-> System.out.println("k=" + k +"\t"+ "v=" + v));}
多级分组
@Testpublic void test05(){List<Person> personList= Arrays.asList(new Person("张三", 16, 175), new Person("李四", 22, 177), new Person("张三", 14, 165), new Person("李四", 15, 166), new Person("张三", 19, 182));//先根据name分组,然后根据age(成年和未成年)分组Map<String,Map<Object,List<Person>>> map= personList.stream().collect(Collectors.groupingBy(Person::getName,Collectors.groupingBy(p-> p.getAge() >= 18 ? "成年" : "未成年")));map.forEach((k,v)->{System.out.println("k=" + k);v.forEach((kk,vv) -> System.out.println("\t"+"kk="+kk+"\tvv="+vv));});
4.5、对流中数据做分区操作
Collectors.partitioningBy会根据值是否为true,把集合中的数据分割为两个列表,一个true列表,一个
false列表
@Testpublic void test06(){List<Person> personList= Arrays.asList(new Person("张三", 16, 175), new Person("李四", 22, 177), new Person("张三", 14, 165), new Person("李四", 15, 166), new Person("张三", 19, 182));Map<Boolean, List<Person>> map = personList.stream().collect(Collectors.partitioningBy(p -> p.getAge() > 18));map.forEach((k,v)-> System.out.println(k+"\t" + v));}
4.6、对流中数据做拼接
Collectors.joining会根据指定的连接符,将所有的元素连接成一个字符串
@Testpublic void test07(){List<Person> personList= Arrays.asList(new Person("张三", 18, 175), new Person("李四", 22, 177), new Person("张三", 14, 165), new Person("李四", 15, 166), new Person("张三", 19, 182));String s1 = personList.stream().map(Person::getName).collect(Collectors.joining());// 张三李四张三李四张三System.out.println(s1);String s2 = personList.stream().map(Person::getName).collect(Collectors.joining("_"));// 张三_李四_张三_李四_张三System.out.println(s2);String s3 = personList.stream().map(Person::getName).collect(Collectors.joining("_", "###", "$$$"));// ###张三_李四_张三_李四_张三$$$System.out.println(s3);}
五、并行Stream流
5.1、串行的Stream流
我们前面使用的Stream流都是串行,也就是在一个线程上面执行。
@Testpublic void test01(){long count = Stream.of(5,6,7,4,2,1,9).filter(s ->{System.out.println(Thread.currentThread().getName() + ":" + s);return s > 3;}).count();System.out.println(count);}
5.2、并行流
parallelStream其实就是一个并行执行的流,它通过默认的ForkJoinPool,可以提高多线程任务的速
度。
5.2.1、获取并行流
@Testpublic void test02(){List<Integer> list=new ArrayList<>();//通过list接口直接获取并行流Stream<Integer> stram=list.parallelStream();//将已有的串行流转换为并行流Stream<Integer> parallel=Stream.of(1,2,3).parallel();}
5.2.3、并行流操作
@Testpublic void test03(){long count = Stream.of(5,6,7,4,2,1,9).parallel().filter(s ->{System.out.println(Thread.currentThread().getName() + ":" + s);return s > 3;}).count();System.out.println(count);}
5.3、并行流和串行流对比
我们通过for循环,串行Stream流,并行Stream流来对500000000亿个数字求和。来看消耗时间
public class StresmTest24 {private static long times=500000000;private long start;@Beforepublic void before(){start=System.currentTimeMillis();}@Afterpublic void end(){long end=System.currentTimeMillis();System.out.println("消耗时间:"+(end - start));}@Testpublic void test01(){System.out.println("普通for循坏:");long res= 0;for (int i = 0;i<times;i++){res+=1;}}@Testpublic void test02(){System.out.println("串行流:serialStream");LongStream.rangeClosed(0,times).reduce(0,Long::sum);}@Testpublic void test03(){LongStream.rangeClosed(0,times).parallel().reduce(0,Long::sum);}}
5.4、线程安全
在多线程的处理下,肯定会出现数据安全问题。如下:
@Testpublic void test01(){List<Integer> list = new ArrayList<>();for (int i = 0; i < 1000; i++) {list.add(i);}System.out.println(list.size());List<Integer> listNew =new ArrayList<>();list.parallelStream().forEach(listNew::add);System.out.println(listNew.size());}
这个会抛出异常
java.lang.ArrayIndexOutOfBoundsException
针对这个问题,我们的解决方案有哪些呢?
- 加同步锁
- 使用线程安全的容器
- 通过Stream中的toArray/collect操作
实现:
@Testpublic void test02(){List<Integer> listNew = new ArrayList<>();Object obj = new Object();IntStream.rangeClosed(1,1000).parallel().forEach(i->{synchronized (obj){listNew.add(i);}});System.out.println(listNew.size());}@Testpublic void test03(){Vector v = new Vector();Object obj = new Object();IntStream.rangeClosed(1,1000).parallel().forEach(i->{synchronized (obj){v.add(i);}});System.out.println(v.size());}@Testpublic void test04(){List<Integer> listNew = new ArrayList<>();// 将线程不安全的容器包装为线程安全的容器List<Integer> synchronizedList = Collections.synchronizedList(listNew);Object obj = new Object();IntStream.rangeClosed(1,1000).parallel().forEach(i->{synchronizedList.add(i);});System.out.println(synchronizedList.size());}@Testpublic void test05(){List<Integer> listNew = new ArrayList<>();Object obj = new Object();List<Integer> list = IntStream.rangeClosed(1, 1000).parallel().boxed().collect(Collectors.toList());System.out.println(list.size());}
相关文章:

JDK8新特性之Steam流
这里写目录标题 一、Stream流概述1.1、传统写法1.2、Stream写法1.3、Stream流操作分类 二、Stream流获取方式2.1、根据Collection获取2.2、通过Stream的of方法 三、Stream常用方法介绍3.1、forEach3.2、count3.3、filter3.4、limit3.5、skip3.6、map3.7、sorted3.8、distinct3.…...
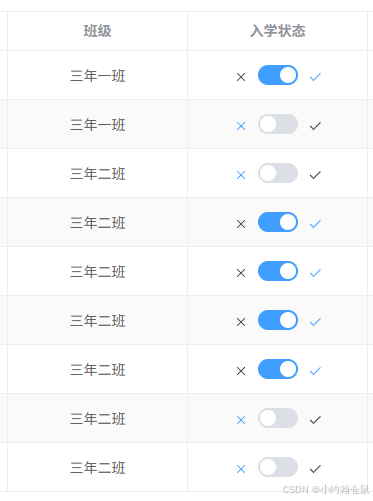
vue3表格使用Switch 开关
本示例基于vue3 element-plus 注:表格数据返回状态值为0、1。开关使用 v-model"scope.row.state 0" 会报错 故需要对写法做些修改,效果图如下 <el-table-column prop"state" label"入学状态" width"180" …...

【11408学习记录】考研写作双核引擎:感谢信+建议信复合结构高分模板(附16年真题精讲)
感谢信建议信 英语写作2016年考研英语(二)真题小作文题目分析写作思路第一段第二段锦囊妙句9:锦囊妙句12:锦囊妙句13:锦囊妙句18: 第三段 妙句成文 每日一句词汇第一步:找谓语第二步:…...

一套个人知识储备库构建方案
写文章的初心是做知识沉淀。 好记性不如烂笔头,将阶段性的经验总结成文章,下次遇到相同的问题时,查起来比再次去搜集资料快得多。 然而,当文章越来越多时,有一个问题逐渐开始变得“严峻”起来。 比如,我…...

行李箱检测数据集VOC+YOLO格式2083张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2083 标注数量(xml文件个数):2083 标注数量(txt文件个数):2083 …...

QT进阶之路:带命名空间的自定义控件在Qt设计器与qss中的使用技巧
文章目录 0.前言1.带命名空间Qt自定义类在QT设计器中的使用技巧1.1 定义一个带命令空间QLabel自定义类1.2 在QT设计器中引入自定义控件类 2.带命名空间Qt自定义类在qss中的使用技巧2.1 命名空间在 QSS 中的特殊语法2.1 在QSS中定义带命名空间的样式 3.在项目中使用带命名空间的…...

矩阵详解:从基础概念到实际应用
矩阵详解:从基础概念到实际应用 目录 矩阵的基本概念矩阵的类型矩阵运算特殊矩阵矩阵的逆与伴随矩阵的秩与等价分块矩阵矩阵的应用 矩阵知识体系思维导图 mindmaproot((矩阵))基本概念定义mn数表元素aij矩阵记号基本术语行数和列数方阵与非方阵矩阵相等矩阵类型…...

Prompt工程学习之自我一致性
自我一致性 (Self-consistency) 概念:该技术通过对同一问题采样不同的推理路径,并通过多数投票选择最一致的答案,来解决大语言模型(LLM)输出的可变性问题。通过使用不同的温度(temp…...

实践提炼,EtherNet/IP转PROFINET网关实现乳企数字化工厂增效
乳企数字化工厂的核心技术应用 1. 智能质检:机器视觉协议网关的协同 液态奶包装线(利乐罐装)的漏码检测生产线,其高速产线(20,000包/小时)需实时识别微小缺陷,但视觉系统(康耐视Ca…...

从以物换物到DeFi:交易的演变与Arbitrum的DeFi生态
交易的本质:从以物换物到现代金融 交易是人类社会经济活动的核心,是通过交换资源(如货物、服务或货币)满足各方需求的行为。其本质是价值交换,旨在实现资源的优化配置。交易的历史可以追溯到人类文明的起源࿰…...

一文掌握 Tombola 抽象基类的自动化子类测试策略
深入解析 Python 抽象基类的自动化测试框架设计 在 Python 开发中,抽象基类(ABC)是定义接口规范的强大工具。本文将以 Tombola 抽象基类为例,详细解析其子类的自动化测试框架设计,展示如何通过 Python 的内省机制实现…...

vue.js not detected解决方法
如果你在开发环境中遇到“Vue.js not detected”的错误,这通常意味着你的项目没有正确设置或者配置以识别Vue.js。下面是一些解决这个问题的步骤: 1. 确认Vue.js已正确安装 首先,确保你的项目中已经正确安装了Vue.js。你可以通过以下命令来…...

Redis 知识点一
参考 Redis - 常见缓存问题 - 知乎 Redis的缓存更新策略 - Sherlock先生 - 博客园 三种缓存策略:Cache Aside 策略、Read/Write Through 策略、Write Back 策略-CSDN博客 1.缓存问题 1.1.缓存穿透 大量请求未命中缓存,直接访问数据库。 解决办法&…...

分类场景数据集大全「包含数据标注+训练脚本」 (持续原地更新)
一、作者介绍:六年算法开发经验、AI 算法经理、阿里云专家博主。擅长:检测、分割、理解、大模型 等算法训练与推理部署任务。 二、数据集介绍: 质量高:高质量图片、高质量标注数据,吐血标注、整理,可以作为…...
)
数据结构与算法——二叉树高频题目(1)
前言: 简单记录一下自己学习算法的历程,主要根据左老师自己的视频课进行,由于大部分课程涉及题目较多,所以分文章进行记录。 本文将简单记录一下二叉树的层序遍历和 Z 形层次遍历。 参考视频: 算法讲解036【必备】…...

Web后端开发(SpringBootWeb、HTTP、Tomcat快速入门)
目录 SpringBootWeb入门 Spring 需求: 步骤: HTTP协议: 概述: 请求协议: 响应协议: 协议解析: Web服务器-Tomcat: 简介: 基本使用: SpringBootWeb…...

CppCon 2015 学习:Memory and C++ debugging at Electronic Arts
这是关于 C 游戏开发中内存接口与调试工具演进 的介绍,主要回顾了从早期到现在平台上的内存与调试策略变化: 游戏平台演进与内存接口编程风格 2000年 (PlayStation 2) 编程风格偏向嵌入式 C 风格。系统资源有限(例如 32MB RAM)…...
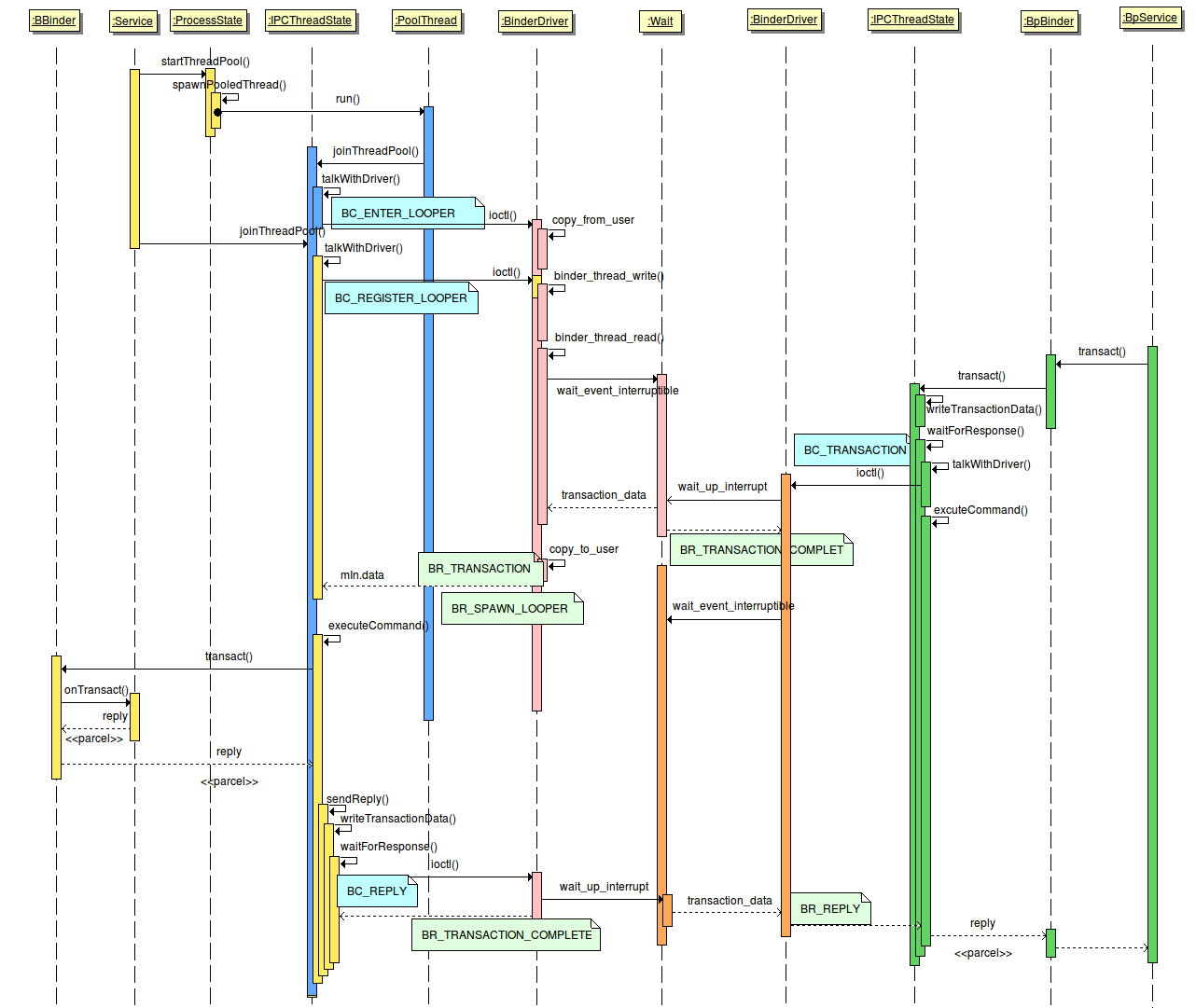
android binder(四)binder驱动详解2
二、情景分析 1、ServiceManager 启动过程 2. 服务注册 服务注册过程(addService)核心功能:在服务所在进程创建binder_node,在servicemanager进程创建binder_ref。其中binder_ref的desc在同一个进程内是唯一的: 每个进程binder_proc所记录的…...

4G无线网络转串口模块 DTU-1101
4G无线网络转串口模块概述 4G无线网络转串口模块是一种工业通信设备,通过4G网络将串口(如RS232/RS485)设备接入互联网,实现远程数据传输与控制。适用于物联网(IoT)、工业自动化、远程监控等场景。 核心功能…...

机器学习方法实现数独矩阵识别器
目录 导包 工具函数构建说明 1. 基础图像处理工具 2. 图像预处理模块 3. 数独轮廓检测与定位 4. 网格划分与单元格提取 5. 数字特征提取 6. 多网格处理流程 数据流分析 核心算法详解 核心机器视觉方法 1. 透视变换校正算法 2. 数字区域提取算法 3. 多网格检测算法…...

OpenEuler服务器警告邮件自动化发送:原理、配置与安全实践
OpenEuler服务器警告邮件自动化发送:原理、配置与安全实践 在服务器的运维管理过程中,及时感知系统异常状态至关重要。当OpenEuler系统运行时,将服务器的警告信息实时推送至邮箱,能帮助运维人员快速响应潜在问题,保障…...

随机访问介质访问控制:网络中的“自由竞争”艺术
想象一场自由辩论赛——任何人随时可以发言,但可能多人同时开口导致混乱。这正是计算机网络中随机访问协议的核心挑战:如何让多个设备在共享信道中高效竞争?本文将深入解析五大随机访问技术及其智慧。 一、核心思想:自由竞争 冲突…...

【Redis】笔记|第9节|Redis Stack扩展功能
Redis Stack 扩展功能笔记(基于 Redis 7) 一、Redis Stack 概述 定位:Redis OSS 扩展模块(JSON、搜索、布隆过滤器等),提供高级数据处理能力。核心模块: RedisJSON:原生 JSON 支持…...
【Vmwrae】快速安装windows虚拟机
前言 虚拟机是我们在使用电脑进行开发或者平常工作时经常使用到的工具 它可以自定义各种硬件,运行各种不同的系统,且无论发生什么都不会影响到实体机。 教程主要讲了如何在零基础的情况下快速安装一台虚拟机。 下载安装 VMware Workstation Pro17 …...
多线程3(Thread)
wait / notify 线程调度是随机的,但是我们可以使用wait/notify进行规划。 join是控制线程结束顺序,而wait/notify是控制详细的代码块,例如: 线程1执行完一段代码,让线程2继续执行,此时线程2就通过wait进…...
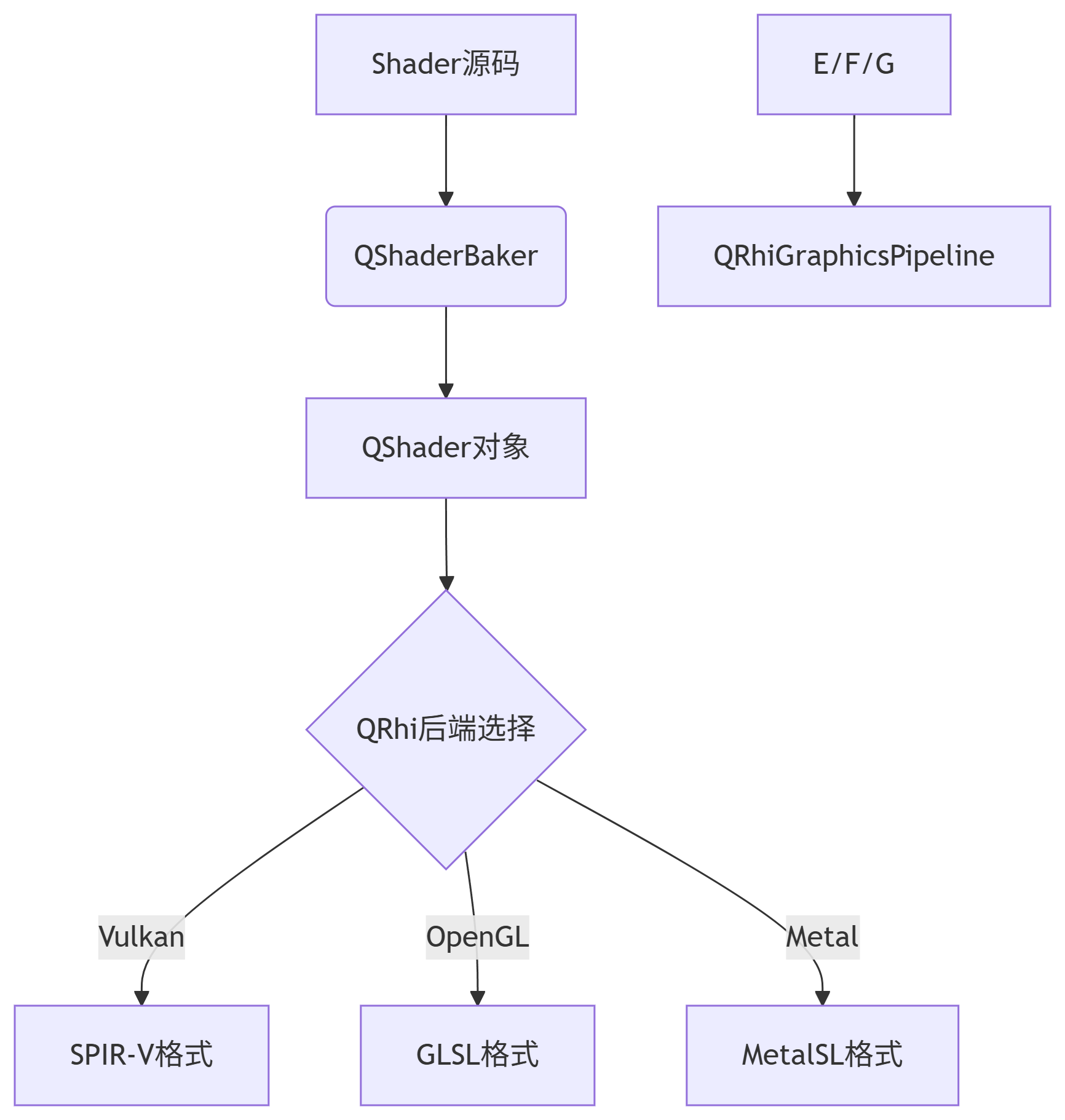
附加模块--Qt Shader Tools功能及架构解析
Qt 6.0 引入了全新的 Shader Tools 模块,为着色器管理提供了现代化、跨平台的解决方案。 一、主要功能 核心功能 跨平台着色器编译 支持 GLSL、HLSL 和 MetalSL 着色器语言 可在运行时或构建时进行着色器编译 自动处理不同图形API的着色器变体 SPIR-V 支持 能…...
:裁剪与合并命令)
ffmpeg(五):裁剪与合并命令
裁剪(剪切) 精准裁剪(有转码,支持任意起止时间) # 从第 10 秒到第 30 秒,重新编码 ffmpeg -i input.mp4 -ss 00:00:10 -to 00:00:30 -c:v libx264 -c:a aac output.mp4快速裁剪(无转码&#x…...

CCPC guangdongjiangsu 2025 F
题目链接:https://codeforces.com/gym/105945/problem/F 题目背景: 你知道自己队伍的过题数、罚时,还知道另一个队伍的每次提交记录(三种状态:ac:通过,rj:未通过,pb&…...
 技术简介)
SSE (Server-Sent Events) 技术简介
一、SSE 技术概述 Server-Sent Events (SSE) 是一种允许服务器向客户端实时推送数据的 Web 技术,它基于 HTTP 协议实现服务器到客户端的单向通信。 基本特点 ● 单向通信:仅服务器→客户端方向 ● 基于HTTP:使用标准HTTP协议,无需…...
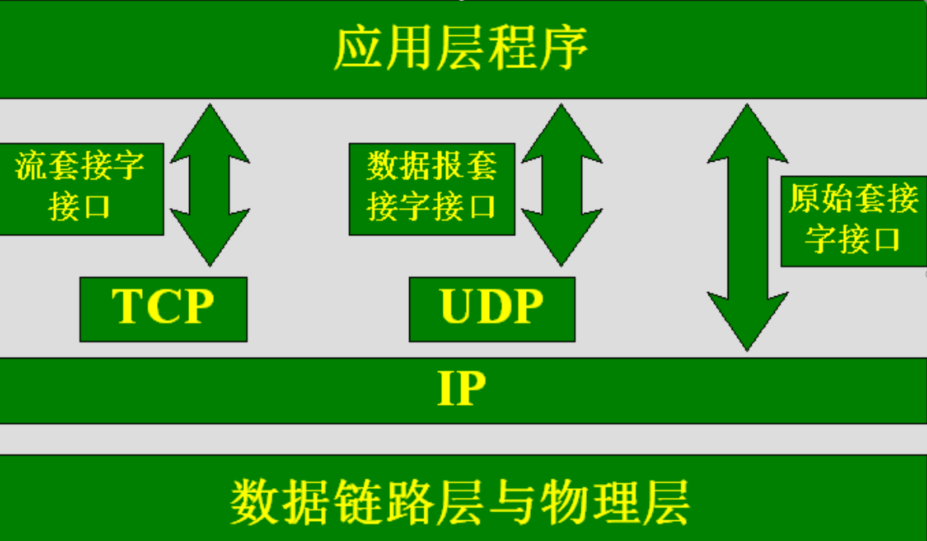
网络编程(计算机网络基础)
思维导图 认识网络 1.网络发展史 ARPnetA(阿帕网)->internet(因特网)->移动互联网->物联网 2.局域网与广域网 局域网 概念:的缩写是LAN(local area network),顾名思义,是个本地的网络,只能实现…...