MySQL 索引优化(Explain执行计划) 详细讲解
🤟致敬读者
- 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉
📘博主相关
- 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息
文章目录
- MySQL 索引优化(Explain执行计划) 详细讲解
- 一、为什么需要 EXPLAIN?
- 二、如何使用 EXPLAIN?
- 三、EXPLAIN 输出字段详解(核心!面试重点!)
- 四、索引优化核心原则(结合 EXPLAIN)
- 五、面试常见问题及回答思路
- 六、实战分析示例(模拟面试)
- 七、总结 & 面试准备要点
📃文章前言
- 🔷文章均为学习工作中整理的笔记。
- 🔶如有错误请指正,共同学习进步。
MySQL 索引优化(Explain执行计划) 详细讲解

MySQL 的 EXPLAIN 执行计划是理解和优化 SQL 查询性能的核心工具,也是面试中数据库相关岗位(尤其是中高级)几乎必考的重点。掌握它不仅能让你在面试中游刃有余,更能提升实际工作中的数据库优化能力。
下面我将从基础概念、EXPLAIN 输出字段详解、关键性能指标解读、常见优化场景及面试要点等方面进行详细讲解:
一、为什么需要 EXPLAIN?
- 理解查询行为: 数据库是如何执行你的 SQL 语句的?它决定使用哪个索引(或者不用)?它如何连接表?它预估需要扫描多少行?
- 定位性能瓶颈: 查询慢在哪里?是全表扫描?是文件排序?是临时表过大?
EXPLAIN能提供关键线索。 - 验证索引效果: 你创建的索引真的被用到了吗?用到了哪个部分?是否是高效的使用方式?
- 优化查询和索引: 基于
EXPLAIN的分析结果,调整 SQL 写法(如 WHERE 条件顺序、JOIN 顺序)、添加或修改索引、优化表结构等。
二、如何使用 EXPLAIN?
非常简单,在你的 SELECT 语句前加上 EXPLAIN 或 EXPLAIN FORMAT=JSON (获取更详细的结构化信息) 即可:
EXPLAIN SELECT * FROM users WHERE name = '张三' AND age > 30 ORDER BY created_at DESC;
或者在 MySQL Workbench 等图形化工具中,直接点击“解释”按钮。
三、EXPLAIN 输出字段详解(核心!面试重点!)
EXPLAIN 的输出是一个表格(或多行,每行代表查询计划中的一个操作),包含以下重要列:
-
id(查询标识符)- 含义: 标识
SELECT子查询的执行顺序或属于哪个大查询。 - 解读:
id相同:执行顺序从上到下(如普通的 JOIN)。id不同:如果是子查询,id 值越大,优先级越高,越先执行(如SELECT ... (SELECT ...),内层 SELECT 的 id 更大)。id为NULL:表示这是一个“结果行”,例如UNION的结果。
- 含义: 标识
-
select_type(查询类型)- 含义: 说明查询的类型。
- 常见类型及面试要点:
SIMPLE: 最简单的 SELECT,不包含子查询或 UNION。PRIMARY: 查询中最外层的 SELECT(包含子查询时)。SUBQUERY: 在 SELECT 或 WHERE 列表中包含的子查询。DERIVED: 在 FROM 列表中包含的子查询(派生表)。面试点:DERIVED通常意味着 MySQL 需要将子查询的结果物化成一个临时表,可能影响性能。优化方向:尝试用 JOIN 重写。UNION: UNION 中的第二个或后续 SELECT。UNION RESULT: UNION 操作的结果集。DEPENDENT SUBQUERY/UNCACHEABLE SUBQUERY: 依赖于外部查询的子查询(性能通常较差)。
-
table(访问的表)- 含义: 显示这一步访问的是哪个表。
- 解读:
- 表名:直接的表名。
<derivedN>: 指向 id 为 N 的派生表结果。<unionM,N>: 指向 id 为 M 和 N 的 UNION 结果。
-
partitions(匹配的分区)- 含义: 如果表是分区表,显示查询将访问哪些分区。非分区表为
NULL。
- 含义: 如果表是分区表,显示查询将访问哪些分区。非分区表为
-
type(访问/连接类型 - 极其重要!性能关键指标! 面试必问!)- 含义: 表示 MySQL 决定如何查找表中的行。从最好到最差(性能降序)大致如下:
system: 表只有一行(系统表)。是 const 的特例。const: 通过主键(Primary Key)或唯一索引(Unique Index)进行等值查询,最多只返回一行。速度极快。面试点: 这是最理想的情况之一。eq_ref: 在连接查询中,对于来自前表的每一行,使用主键或唯一索引在当前表中进行等值匹配(只找到一行)。常见于PRIMARY KEY或UNIQUE NOT NULL索引的等值连接。性能非常好。ref: 使用非唯一索引进行等值查询,可能返回多行。比eq_ref稍差,但仍然是高效的(如果返回行不多)。面试点: 最常用的高效访问方式之一。ref_or_null: 类似ref,但额外包含了对NULL值的搜索。range: 范围扫描。使用索引检索给定范围(BETWEEN,<,>,IN,LIKE 'prefix%'等)的行。比全表扫描好,但需要关注扫描的行数(rows)。index: 全索引扫描。扫描整个索引树(比全表扫描ALL快,因为索引通常比表数据小)。面试点:- 当查询所需列全部包含在索引中(覆盖索引),且不需要回表时,性能可以接受(
Extra列会显示Using index)。 - 否则,效率可能不高(需要排序或
Using filesort时可能更糟)。
- 当查询所需列全部包含在索引中(覆盖索引),且不需要回表时,性能可以接受(
ALL: 全表扫描。没有使用索引,或者索引失效。性能最差! 面试点: 看到ALL必须警惕!通常意味着需要优化(加索引、修改查询条件等)。在大表上尤其致命。
- 面试要点: 务必熟悉这个顺序!能清晰解释每种类型的含义和性能差异。面试官常问:“
type出现ALL意味着什么?如何优化?”,“ref和eq_ref的区别是什么?”。
- 含义: 表示 MySQL 决定如何查找表中的行。从最好到最差(性能降序)大致如下:
-
possible_keys(可能用到的索引)- 含义: 显示查询可能使用哪些索引来查找行。基于 WHERE 子句、JOIN 条件等分析得出。
- 解读: 这里列出的索引不一定真正被使用。实际使用的索引在
key列中。如果为NULL,表示没有找到适用的索引。
-
key(实际使用的索引 - 重要!)- 含义: 显示 MySQL 实际决定使用的索引。如果为
NULL,表示没有使用索引。 - 面试要点: 对比
possible_keys和key:- 如果
key在possible_keys中:正常。 - 如果
key不在possible_keys中:可能使用了覆盖索引(即使没在 WHERE 中直接用到,但索引包含了 SELECT 需要的所有列),或者优化器基于成本选择了不同的索引。 - 如果
possible_keys有值而key为NULL:意味着虽然有可用索引,但优化器基于成本(如小表扫描更快)或索引选择性差等原因决定不使用索引。需要分析原因!
- 如果
- 含义: 显示 MySQL 实际决定使用的索引。如果为
-
key_len(使用的索引长度)- 含义: 表示 MySQL 在索引中实际使用的字节数。可用于判断索引是否被充分利用(是否使用了索引的全部列或部分列)。
- 解读:
- 计算规则:所有被使用的索引字段的长度之和。对于变长字段(如
VARCHAR),需要考虑字符集和是否允许 NULL(多1字节)。 - 面试点: 如果
key_len小于索引定义的长度,说明只使用了索引的最左前缀(复合索引的部分列)。这是理解最左前缀原则的关键指标!例如,索引(a, b, c),WHERE 条件只有a=1 AND b=2,那么key_len就是a和b的长度,表明c没有被用到。
- 计算规则:所有被使用的索引字段的长度之和。对于变长字段(如
-
ref(与索引比较的列或常量)- 含义: 显示使用
key列指定的索引时,查找值所用到的列或常量。 - 常见值:
const: 常量值(如WHERE id = 10)。func: 使用函数的结果。database_name.table_name.column_name: 来自另一个表的列(常见于 JOIN)。NULL: 例如index扫描(全索引扫描)。
- 含义: 显示使用
-
rows(预估需要扫描的行数 - 重要!性能指标!)- 含义: MySQL 优化器预估执行该查询操作需要扫描的行数(不是精确值,基于统计信息)。对于 InnoDB,这是一个估计值。
- 解读: 这个值非常重要!它直接反映了查询的成本。值越小越好。结合
type看:type=ALL且rows很大:性能灾难!type=index且rows很大:全索引扫描,也可能很慢,要看数据量和Extra。type=const/eq_ref/ref且rows=1:非常高效。
- 面试点: 理解
rows是预估的,实际执行可能不同。关注其数量级(几十、几万、几百万?)。
-
filtered(按条件过滤后剩余行的百分比 - MySQL 5.7+ 重要!)- 含义: 表示存储引擎返回的数据在服务层经过 WHERE 条件或其他过滤后,预估剩余行数的百分比。值在 0 到 100 之间。100 表示没有过滤。
- 解读: 对于单表查询,意义不大(
rows * filtered / 100可以预估最终返回的行数)。对于 JOIN 查询极其重要:- 它表示前一个表返回的行,在连接当前表后,预估能有多少比例的行满足 JOIN 条件或单表 WHERE 条件。
- 例如,前表
rows=1000,filtered=10%,则预估需要连接当前表 1000 * 10% = 100 次。filtered越低,意味着连接次数越少,JOIN 效率可能越高。
- 面试点: 理解
filtered在 JOIN 优化中的意义,特别是评估 JOIN 顺序是否合理时。
-
Extra(额外信息 - 极其重要!包含关键性能线索! 面试必问!)- 含义: 包含 MySQL 解决查询的额外细节信息。这里常常藏着性能问题的答案。
- 常见值及优化方向(面试高频考点):
Using index: 覆盖索引(Covering Index)。查询的列全部包含在使用的索引中,无需回表查询数据行。这是非常理想的情况! 面试点: 解释什么是覆盖索引及其优势(减少I/O,提高速度)。Using where: 在存储引擎返回行之后,服务层还需要应用 WHERE 条件进行过滤。说明索引可能没有完全覆盖 WHERE 条件,或者索引被部分使用。不一定坏,但结合type和rows看。Using temporary: 使用了临时表来保存中间结果。常见于GROUP BY或ORDER BY的列不属于驱动表且没有合适索引,或者DISTINCT、UNION。通常需要优化! 面试点: 为什么临时表不好?如何避免(优化 GROUP BY/ORDER BY 的索引)?Using filesort: 使用了文件排序。无法利用索引完成排序(ORDER BY,GROUP BY),需要在内存或磁盘进行额外排序。通常需要优化! 面试点:filesort为什么慢?如何避免(为 ORDER BY/GROUP BY 创建合适的索引)?注意:有时优化器会选择filesort如果它认为更快(比如行数很少)。Using join buffer (Block Nested Loop)/Using join buffer (Batched Key Access): 使用了连接缓冲区。常见于被驱动表(第二个表)没有有效索引可用时,需要将驱动表的一部分行读入 Join Buffer,然后批量与被驱动表匹配。效率较低! 优化方向: 为被驱动表的连接字段添加索引。Impossible WHERE: WHERE 子句永远为 false,查不到任何行(如WHERE 1=0)。Select tables optimized away: 使用某些聚合函数(如MIN()/MAX())访问仅包含这些值的索引时,优化器可以直接从索引中取值,无需访问表。Distinct/Not exists: 优化了DISTINCT或NOT EXISTS操作。Range checked for each record (index map: N): MySQL 没有找到好的索引可用,但发现在前面的表返回行后,可能可以根据该行的值来使用某个索引进行范围扫描(N 是位图标识哪个索引可能被用)。效率不高。
四、索引优化核心原则(结合 EXPLAIN)
-
最左前缀原则 (Leftmost Prefixing):
- 对于复合索引
(col1, col2, col3),索引可以被用于:- 只包含
col1的查询 (WHERE col1=val) - 包含
col1和col2的查询 (WHERE col1=val1 AND col2=val2) - 包含
col1,col2和col3的查询 (WHERE col1=val1 AND col2=val2 AND col3=val3)
- 只包含
- 不能跳过左边列直接使用右边列 (
WHERE col2=val2 AND col3=val3无法有效使用该索引)。 - EXPLAIN 体现:
key_len会显示实际使用了索引的前几列的长度。 - 面试必考! 必须能清晰解释并举例。
- 对于复合索引
-
避免索引失效(导致全表扫描
ALL或低效index):- 在索引列上做操作: 函数、计算、类型转换(隐式或显式)。如
WHERE YEAR(create_date) = 2023,WHERE amount * 2 > 100,WHERE id = '123'(id 是 INT)。 - 使用
!=或<>: 通常会导致索引失效(除非覆盖索引)。 - 使用
NOT IN,NOT LIKE: 通常会导致索引失效。 OR连接非索引列: 如果 OR 的条件中有一个列没有索引,整个索引可能失效。LIKE以通配符%开头:LIKE '%keyword'无法利用索引(LIKE 'keyword%'可以)。- 字符串不加单引号(隐式类型转换): 如
WHERE name = 123(name 是 VARCHAR)。 - 复合索引未遵循最左前缀原则。
- 优化器认为全表扫描更快: 当表很小,或者索引选择性极低时(如性别列)。
- EXPLAIN 体现:
type=ALL或type=index+ 高rows+Using where。
- 在索引列上做操作: 函数、计算、类型转换(隐式或显式)。如
-
覆盖索引 (Covering Index):
- 创建包含查询所需所有列(SELECT, WHERE, ORDER BY, GROUP BY)的索引。
- 优势: 避免回表(访问数据行),极大提升速度。体现在
EXPLAIN的Extra: Using index。 - 权衡: 索引列越多,索引维护成本(插入/更新/删除)越高,占用空间越大。需平衡查询性能与写入性能/空间开销。
-
为排序和分组创建索引:
ORDER BY和GROUP BY子句的列顺序同样需要遵循最左前缀原则。- 如果排序方向不一致 (
ORDER BY col1 ASC, col2 DESC),可能需要特殊索引或无法充分利用。 - EXPLAIN 体现: 避免
Extra: Using filesort和Using temporary。理想情况是Using index完成排序/分组。
-
JOIN 优化:
- 确保 ON/USING 子句中的列有索引: 通常在被驱动表(第二个及以后的表)的连接字段上建索引。体现在
type=ref/eq_ref。 - 小表驱动大表: 优化器通常会尝试选择小表作为驱动表(第一个表)。手动指定时可以用
STRAIGHT_JOIN(谨慎使用)。 - 关注
filtered列: 高filtered值(接近100%)可能意味着 JOIN 条件选择性差或索引不佳。 - 减少
Using join buffer: 通过为被驱动表添加有效索引。
- 确保 ON/USING 子句中的列有索引: 通常在被驱动表(第二个及以后的表)的连接字段上建索引。体现在
五、面试常见问题及回答思路
-
EXPLAIN是做什么用的?答:
EXPLAIN是 MySQL 提供的用于分析 SQL 查询执行计划的工具。它显示了 MySQL 优化器打算如何执行查询,包括是否使用索引、使用哪个索引、表的连接顺序和方式、预估扫描行数等关键信息。主要目的是帮助我们理解查询行为、定位性能瓶颈、验证索引效果和指导优化。 -
type字段有哪些值?性能从好到坏排序是怎样的?答:
type表示访问表的方式,性能从最优到最差大致是:system>const>eq_ref>ref>ref_or_null>range>index>ALL。const/eq_ref/ref/range通常表示使用了索引且高效;index是全索引扫描,有时可接受(覆盖索引时);ALL是全表扫描,性能最差,必须优化。 -
看到
type=ALL怎么优化?答:
ALL表示全表扫描,是性能瓶颈的信号。优化方向包括:- 检查 WHERE 条件涉及的列,尝试添加合适的索引(单列或复合索引,注意最左前缀)。
- 检查查询条件是否导致索引失效(如函数操作、类型转换、
LIKE '%xx'、违反最左前缀)。 - 如果表很小,
ALL可能比用索引快,但需确认表大小。 - 分析是否真的需要所有列,避免
SELECT *,考虑覆盖索引。
-
Extra列里Using filesort和Using temporary是什么意思?怎么优化?答:
Using filesort:表示 MySQL 无法利用索引完成排序(ORDER BY/GROUP BY),需要在内存或磁盘进行额外排序。优化: 为排序/分组的字段创建合适的索引(顺序遵循最左前缀)。Using temporary:表示 MySQL 创建了临时表来处理查询(常见于GROUP BY,DISTINCT,UNION)。优化: 尝试优化GROUP BY的列使其有索引;避免不必要的DISTINCT/排序;确保UNION子句有索引。临时表消耗内存/磁盘,影响性能。
-
什么是覆盖索引?
EXPLAIN如何体现?有什么好处?答:
- 覆盖索引: 指一个索引包含了查询所需的所有列(SELECT, WHERE, ORDER BY, GROUP BY 涉及的列)。
EXPLAIN体现:Extra列会显示Using index。- 好处: 最大的优势是避免回表(无需访问数据行)。直接从索引中获取数据,减少 I/O 操作,显著提高查询速度。是优化查询的高效手段之一。
-
什么是索引的最左前缀原则?
EXPLAIN如何验证?答:
- 最左前缀原则: 对于复合索引
(col1, col2, col3),查询条件必须包含索引定义中的最左边的连续列才能有效利用该索引。例如,条件col1=val或col1=val1 AND col2=val2可以利用索引;但col2=val2或col2=val2 AND col3=val3无法有效利用(除非跳过扫描,但效率不高)。 EXPLAIN验证: 主要看key_len列。key_len的值代表了实际使用到的索引列的总字节数。如果key_len小于整个复合索引的长度,说明只使用了索引的一部分(最左前缀)。
- 最左前缀原则: 对于复合索引
-
possible_keys有值,key为NULL是什么原因?答:这表示优化器分析后认为有可用的索引 (
possible_keys),但最终决定不使用任何索引 (key=NULL)。常见原因:- 表很小: 全表扫描比走索引更快(如只有几行)。
- 索引选择性差: 索引列的值重复率极高(如状态标志位),走索引后仍需回表扫描大量行,不如直接全表扫。
- 覆盖索引不成立且需要回表: 虽然 WHERE 条件有索引,但 SELECT 的列不在索引中,需要大量回表操作,优化器计算成本后认为全表扫描更优。
- 查询使用了
FORCE INDEX之外的提示但优化器未采纳。
需要结合rows预估值和表大小具体分析。
-
filtered字段有什么用?答:
filtered(MySQL 5.7+) 表示存储引擎返回的行,在服务层经过 WHERE 条件过滤后,预估剩余行的百分比。对于单表查询: 可以用来预估最终结果行数 (rows * filtered / 100)。对于 JOIN 查询(更重要): 它表示前一个表的每一行,在连接当前表时,预估有多少比例的行能满足连接条件或单表 WHERE 条件。filtered值越低(接近0),意味着前表行连接当前表的次数越少,JOIN 效率可能越高。优化 JOIN 顺序时,驱动表(第一个表)应尽量选择filtered小的。
六、实战分析示例(模拟面试)
查询:
EXPLAIN SELECT o.order_id, c.customer_name, p.product_name, oi.quantity
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.order_date BETWEEN '2023-01-01' AND '2023-01-31'
AND c.country = 'China'
ORDER BY o.order_date DESC;
假设 EXPLAIN 结果关键部分(简化):
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | o | range | idx_date | idx_date | 4 | NULL | 1000 | 100.00 | Using where; Using filesort |
| 1 | SIMPLE | c | eq_ref | PRIMARY | PRIMARY | 4 | db.o.customer_id | 1 | 10.00 | Using where |
| 1 | SIMPLE | oi | ref | idx_order | idx_order | 4 | db.o.order_id | 5 | 100.00 | NULL |
| 1 | SIMPLE | p | eq_ref | PRIMARY | PRIMARY | 4 | db.oi.product_id | 1 | 100.00 | NULL |
面试官:分析一下这个查询的执行计划和潜在性能问题?
回答思路:
- 驱动表: 第一个表是
o(orders)。优化器选择它作为驱动表,因为WHERE o.order_date BETWEEN ...使用了范围查询 (type=range),预估扫描rows=1000行。 orders表 (o):type=range:使用了索引idx_date进行范围扫描(好)。Extra=Using where; Using filesort:Using where可能表示索引未完全覆盖 WHERE 条件(比如order_date在索引中,但可能还有其他条件?这里只有日期)。Using filesort是问题! 因为最终的ORDER BY o.order_date DESC无法利用idx_date的排序(因为是范围扫描后结果集,且可能需要与其他表连接后再排序),需要额外文件排序。优化建议: 尝试调整索引或查询,看是否能利用索引消除排序。
customers表 (c):type=eq_ref:使用主键连接,对于驱动表o的每一行 customer_id,精确查找一行。效率很高。filtered=10.00%:表示连接后,只有大约 10% 的行满足c.country='China'条件。这个选择性还不错,意味着驱动表o的 1000 行,大约只需要连接c表 100 次 (1000 * 10%)。
order_items表 (oi):type=ref:使用非唯一索引idx_order(可能在order_id上) 进行连接。预估每个订单有 5 个订单项 (rows=5)。
products表 (p):type=eq_ref:使用主键连接,效率很高。
- 主要性能风险点:
o表的文件排序 (Using filesort): 如果满足日期条件的订单很多(rows=1000是预估,实际可能更多),文件排序可能成为瓶颈,尤其是在内存不足需落盘时。- 连接行数放大: 驱动表
o扫描 1000 行 -> 连接c约 100 次 -> 连接oi约 100 * 5 = 500 次 -> 连接p500 次。最终需要处理的行数可能达到 500 行(结果集),但中间过程需要处理连接。
- 优化建议:
- 解决排序:
- 如果
o.order_date是驱动条件且需要排序,考虑能否让idx_date包含排序方向(但范围查询本身可能破坏顺序)。 - 尝试创建一个包含
(order_date, customer_id)的索引,order_date用于范围查找和排序,customer_id用于连接c表。看EXPLAIN是否能消除filesort(Extra去掉Using filesort) 并保持高效连接。
- 如果
- 覆盖索引检查: 检查
SELECT的列是否被现有索引覆盖,减少回表(当前计划中没有Using index,说明有回表)。 c.country过滤:filtered=10%不错,但如果在customers表上有(country, customer_id)的索引,理论上可以让eq_ref连接更顺畅(虽然主键连接已最优),或者如果country过滤性更强,考虑调整 JOIN 顺序(但优化器通常已经做了最优选择,除非用STRAIGHT_JOIN强制)。
- 解决排序:
七、总结 & 面试准备要点
- 理解每个
EXPLAIN字段的含义: 特别是type,key,rows,filtered,Extra。 - 掌握性能关键指标:
type=ALL/index差,type=const/eq_ref/ref/range好;rows大差小好;Extra中的Using filesort,Using temporary,Using join buffer通常是警告信号;Using index是好的信号。 - 深刻理解索引原理: 最左前缀原则(看
key_len)、覆盖索引(看Using index)、索引失效场景。 - 理解 JOIN 优化: 驱动表选择、被驱动表索引 (
ref/eq_ref)、filtered的意义。 - 能解读
EXPLAIN输出: 按 id 顺序理解执行步骤,分析每个步骤的访问方式和潜在问题。 - 能提出优化建议: 根据
EXPLAIN结果,说出可能的优化方向(加索引、改索引、改写查询、调整 JOIN 顺序等)。 - 动手实践: 在自己环境或在线 SQL 平台多写 SQL,多用
EXPLAIN分析不同写法和索引的影响,加深理解。
通过深入理解 EXPLAIN 的每个细节和背后的优化原理,你就能在面试中自信地应对数据库索引优化相关的问题,并在实际工作中有效提升数据库性能。祝你面试成功!
📜文末寄语
- 🟠关注我,获取更多内容。
- 🟡技术动态、实战教程、问题解决方案等内容持续更新中。
- 🟢《全栈知识库》技术交流和分享社区,集结全栈各领域开发者,期待你的加入。
- 🔵加入开发者的《专属社群》,分享交流,技术之路不再孤独,一起变强。
- 🟣点击下方名片获取更多内容🍭🍭🍭👇
相关文章:
MySQL 索引优化(Explain执行计划) 详细讲解
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 MySQL 索引优化(Explain执行计划…...
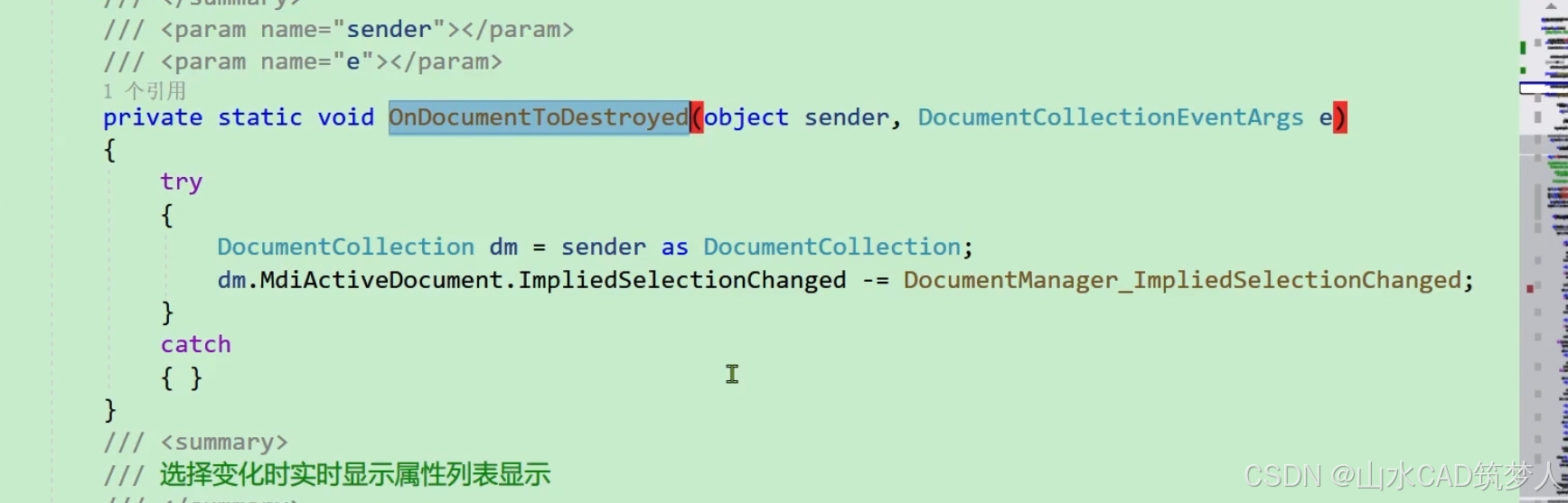
Cad 反应器 cad c#二次开发
在 AutoCAD C# 二次开发中,DocumentCollectionEventHandler 是一个委托(delegate),用于处理与 AutoCAD 文档集合(DocumentCollection)相关的事件。它属于 AutoCAD .NET API 的事件处理机制,本质…...

GitOps 核心思想 - 当 Git 成为唯一信源
GitOps 核心思想 - 当 Git 成为唯一信源 在我们之前的 CI/CD 系列中,我们构建了一条流水线:GitHub Actions 在代码测试和构建通过后,执行 kubectl apply 命令将变更推送 (Push) 到 Kubernetes 集群。这种模式非常普遍且有效,但当系统规模和团队复杂度增加时,它可能会遇到一…...

【websocket】安装与使用
websocket安装与使用 1. 介绍2. 安装3. websocketpp常用接口4. Websocketpp使用4.1 服务端4.2 客户端 1. 介绍 WebSocket 是从 HTML5 开始支持的一种网页端和服务端保持长连接的 消息推送机制。 传统的 web 程序都是属于 “一问一答” 的形式,即客户端给服务器发送…...
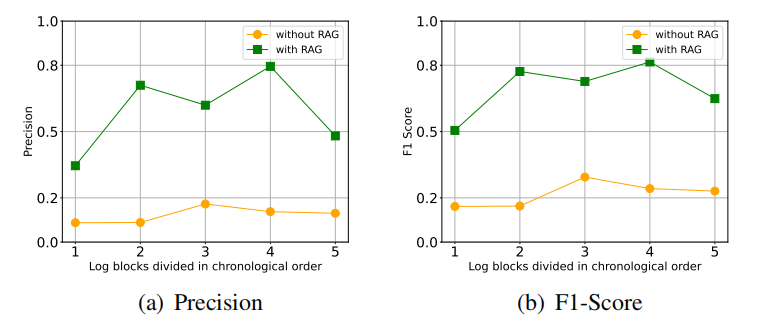
【大模型】LogRAG:基于检索增强生成的半监督日志异常检测
文章目录 A 论文出处B 背景B.1 背景介绍B.2 问题提出B.3 创新点 C 模型结构D 实验设计D.1 数据集/评估指标D.2 SOTAD.3 实验结果 E 个人总结E.1 优点E.2 不足 A 论文出处 论文题目:LogRAG: Semi-Supervised Log-based Anomaly Detection with Retrieval-Augmented …...
基于SpringBoot实现的大创管理系统设计与实现【源码+文档】
基于SpringBootVue实现的大创管理系统采用前后端分离架构方式,系统设计了管理员、学生、指导老师、院系管理员两种角色,系统实现了用户登录与注册、个人中心、学生管理、指导老师管理、院系管理员管理、优秀项目管理、项目类型管理、项目信息管理、项目申…...

国产高云FPGA实现视频采集转UDP以太网输出,FPGA网络摄像头方案,提供2套Gowin工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目国产高云FPGA基础教程国产高云FPGA相关方案推荐我这里已有的以太网方案 3、设计思路框架工程设计原理框图输入Sensor之-->OV7725摄像头输入Sensor之-->OV5640摄…...

【Linux基础知识系列】第十一篇-Linux系统安全
Linux系统安全是指通过一系列技术和管理措施,保护Linux系统免受各种威胁和攻击,确保系统的完整性、可用性和机密性。随着网络攻击手段的多样化和复杂化,Linux系统安全成为了系统管理员和开发者必须面对的重要课题。本文将从用户认证、权限管理…...

02.管理数据库
管理数据库 1. 创建数据库 mysql> create database db1; Query OK, 1 row affected (0.01 sec)mysql> show databases; -------------------- | Database | -------------------- | db1 | | hellodb | | information_schema | | m…...

Webpack依赖
Webpack到底怎么对我们的项目进行打包捏? 在webpack处理应用程序时,会根据命令或者配置文件找到入口文件 从入口开始,会生成一个依赖关系图,这个依赖关系图会包含应用程序中所需的所有模块(.js、css文件、图片、字体…...

自动驾驶科普(百度Apollo)学习笔记
1. 写在前面 在过去的几年里,自动驾驶技术取得飞速发展,人类社会正逐渐走向一个新时代,这个时代中,汽车不仅仅是一个交通工具,更是一个智能的、能够感知环境、做出决策并自主导航的机器伙伴。现在正好也从事这块的工作…...

leetcode_66.加一
题目链接 这道题归类在力扣的数学类中,应该算是一道思维的简单题吧 题是这样的,根据题目我们不难理解,这个题就是在最后一位加 1 然后返回,正如示例所说的那样,当然这很符合我们人的思维,写这种算法题最重要…...

iview-admin静态资源js按需加载配置
iview-admin2.0版本默认加载所有组件的JS,实际情况下,用户访问后台并不会每个页面都浏览。这样就会造成流量及带宽的浪费。可通过修改配置文件vue.config.js来实现按需加载,具体配置如图 image © 著作权归作者所有,转载或内容合作请联系…...

【学习笔记】深入理解Java虚拟机学习笔记——第3章 垃圾收集器与内存分配策略
第3章 垃圾收集器与内存分配策略 3.1 概述 略 3.2 对象已死? “死去”即不可能以任何途径访问到 3.2.1 引用计数算法 每个对象维护一个计数器,引用即加1,引用失效便减1。 3.2.2 可达性分析算法(主流) 即根据GC…...
抖去推--短视频矩阵系统源码开发
一、开发短视频矩阵系统的源码需要以下步骤: 确定系统需求: 根据客户的具体业务目标,明确系统需实现的核心功能模块,例如用户注册登录、视频内容上传与管理、多维度视频浏览与推荐、用户互动(评论、点赞、分享…...

Windows设置之网络路由
在 Windows 系统中,可以通过配置路由表来实现特定 IP 地址通过无线网卡(Wi-Fi)连接,而其他流量通过有线以太网连接。 比如,让101.132.45.129 走无线网卡,其他的走有线以太网的具体步骤如下: 通…...

发送文件脚本源码版本
V1 适配win10和 win11 #SingleInstance Force SendMode Input SetWorkingDir %A_ScriptDir%; Global variables global TaskList : [] global CurrentFileConfig : "current_file.ini" global RemainingFilesConfig : "remaining_files.ini" global File…...
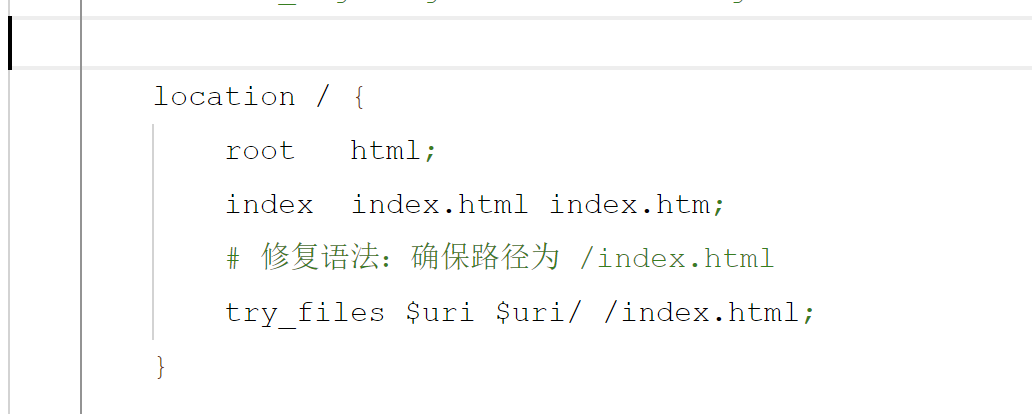
Vue部署到Nginx上及问题解决
一、Vue打包 dist文件即打包文件 二、下载Nginx,将dist内容全部复制到Nginx的html下 三、修改Nginx的nginx.conf配置文件,添加try_files $uri $uri/ /index.html; try_files $uri $uri/ /index.html; 是 Nginx 配置中的一个重要指令,用于处理…...
与提示词撰写)
MCP(Model Context Protocol)与提示词撰写
随着大模型(LLM)在复杂任务中的普及,如何让模型高效调用外部工具和数据成为关键挑战。传统函数调用(Function Calling)依赖开发者手动封装 API,而 MCP(Model Context Protocol) 通过…...

每日一令:Linux 极简通关指南 - 汇总
专栏列表 💻 每日一令:Linux 极简通关指南 (25篇) 【基础】每天掌握一个Linux命令 - nsenter:深入容器与命名空间的利器 发布于 2025-06-08 22:27:04【基础】 每天掌握一个Linux命令 - journalctl:系统日志管理的得力助手 发布于…...

项目-- Json-Rpc框架
目录 项目简介环境搭建Ubuntu-22.04 第三方库使用JsonCppMuduo基础类EventLoop类TcpConnection类Buffer类TcpClient类TcpServer类 服务端基本搭建客户端基本搭建 future 项目设计通用模块设计Rpc功能模块设计发现者设计提供者设计服务注册中心设计 Topic功夫模块设计主题管理中…...

因泰立科技H1X激光雷达:因泰立科技为智慧工业注入新动力
在当今工业领域,精准测量与高效作业是推动产业升级的关键因素。因泰立科技推出的H1X三维轮廓扫描激光雷达,凭借其卓越的性能和广泛的应用场景,正成为智慧工业中不可或缺的高科技装备。 产品简介 H1X三维轮廓扫描激光雷达是因泰立科技基于二维…...

day50 随机函数与广播机制
目录 一、随机张量的生成 1.1 torch.randn() 函数 1.2 其他随机函数 1.3 输出维度测试 二、广播机制 2.1 广播机制的规则 2.2 加法的广播机制 二维张量与一维向量相加 三维张量与二维张量相加 二维张量与标量相加 高维张量与低维张量相加 2.3 乘法的广播机制 批量…...
)
Codeforces Educational 179(ABCDE)
前言 byd这组题纯靠感觉是吧…^_^ b题赛时举了无数个例子都没想明白,然后一直卡到结束,后面题都没看到,结果补题的时候c题d题直接秒了…-_-|| A. Energy Crystals #include <bits/stdc.h> using namespace std;typedef long long …...

基于 actix-web 框架的简单 demo
以下是一个基于 actix-web 框架的简单 demo, 如果你还没有 Rust,我们建议你使用 rustup 来管理你的 Rust 安装。官方 Rust 指南有一个很棒的入门部分。 Actix Web 目前支持的最低 Rust 版本 (MSRV) 为 1.72。运行 rustup update…...

python:Tkinter 开发邮件客户端,能编写邮件,发送邮件带附件
Python Tkinter 邮件客户端 下面是一个使用 Python Tkinter 开发的简单邮件客户端,支持编写邮件和发送邮件功能: 功能说明 这个邮件客户端包含以下功能: 邮件编写功能: 收件人地址输入抄送地址输入邮件主题输入邮件正文编辑区&…...

CMake基础:gcc/g++编译选项详解
目录 1.编译步骤 2.gcc 与 g 区别 3.gcc 命令的常用选项 3.1.基础编译选项 3.2.优化选项 3.3.调试与分析选项 3.4.链接选项 3.5.语言特性选项(C 特化) 3.6.安全增强选项 3.7.架构与指令集优化 3.8.其他常用选项 4.常见编译组合示例 5.常用环…...

深入解析Java21核心新特性(虚拟线程,分代 ZGC,记录模式模式匹配增强)
文章目录 前言一、虚拟线程 (Virtual Threads - JEP 444) - 并发的革命1.1 解决的核心问题🎯1.2 工作原理与核心机制⚙️1.3 使用详解与最佳实践🛠️1.4 注意事项⚠️1.5 总结 📚 二、分代 ZGC (Generational ZGC - JEP 439) - 低延迟新高度2…...
免费批量去水印工具 - 针对文心一言生成图片
免费批量去水印工具 - 针对文心一言生成图片 工具介绍 这是一款免费的批量去水印工具,专门针对文心一言生成的图片进行处理。通过简单的操作,您可以快速去除图片中的水印。 下载链接 您可以通过以下网盘链接下载工具: 链接: https://pa…...

android 之 MediaExtractor
MediaExtractor 是Android多媒体处理的基础组件,解封装是其核心价值。 一、功能与定位 MediaExtractor 是Android多媒体框架中的媒体解封装工具,主要作用是从媒体文件(如MP4、MKV、MP3)中分离音视频轨道数据,为后续解…...