四、Sqoop 导入表数据子集
作者:IvanCodes
日期:2025年6月4日
专栏:Sqoop教程
当不需要将关系型数据库中的整个表一次性导入,而是只需要表中的一部分数据时,Sqoop 提供了多种方式来实现数据子集的导入。这通常通过过滤条件或选择特定列来完成。
一、导入子集的核心方法
主要通过以下两种参数组合实现:
-
使用
--table配合--where子句:- 这是最直接和常用的方式,用于从单个表中根据行级别的条件筛选数据。
- Sqoop 会将
--where条件附加到从源表SELECT数据的SQL语句中。
-
使用
--table配合--columns参数:- 用于从单个表中选择特定的列进行导入。
-
使用
--query参数:- 提供最大的灵活性,允许你编写任意复杂的SQL查询语句,可以包含 WHERE 子句、列选择、多表连接、函数等,从而精确定义要导入的数据子集。
二、关键参数详解 (针对子集导入)
-
--table <db-table-name>: (方法1和2使用) 指定要从中导入数据的源表名。 -
--where "<sql-where-condition>": (配合--table使用)- 定义一个SQL的WHERE子句 (不包含
WHERE关键字本身) 来过滤行。 - 示例:
--where "status = 'active' AND age > 30" - 注意: 如果条件中包含字符串,确保正确引用 (通常是单引号)。如果条件本身包含引号,可能需要转义。
- 定义一个SQL的WHERE子句 (不包含
-
--columns "<col1>,<col2>,<col_n>": (配合--table使用)- 指定要导入的列名列表,列名之间用逗号分隔。
- 示例:
--columns "id,name,email" - 如果不指定此参数,Sqoop 默认导入表中的所有列。
-
--query "<custom-sql-select-query>": (方法3使用)- 直接提供一个完整的SELECT查询语句。
- 示例:
--query "SELECT o.order_id, c.customer_name, o.order_total FROM orders o JOIN customers c ON o.customer_id = c.customer_id WHERE o.order_date >= '2023-01-01' AND \$CONDITIONS" - 重要提示:
- 使用
--query时,必须指定--target-dir(即使是导入到Hive,也建议指定一个临时HDFS目录)。 - 如果使用多个Mapper (
-m > 1) 进行并行导入,查询语句中必须包含\$CONDITIONS占位符,并且需要配合--split-by(以及可能的--boundary-query) 来有效分割查询结果集。如果-m 1,则\$CONDITIONS不是必需的。
- 使用
-
其他参数如
--connect,--username,--password,--target-dir,--hive-import,-m,--split-by, 文件格式和压缩参数等,与全量导入时的用法基本相同。
三、导入数据子集示例 (MySQL)
场景: 假设MySQL数据库 mydb 中有表 employees (id INT PK, name STRING, department VARCHAR(50), salary DECIMAL(10,2), hire_date DATE)。
1. 使用 --table 和 --where 导入满足条件的行
(A) 导入 ‘Sales’ 部门且薪水大于60000的员工到HDFS
sqoop import \
--connect jdbc:mysql://localhost:3306/mydb \
--username dbuser \
-P \
--table employees \
--where "department = 'Sales' AND salary > 60000" \
--target-dir /data/sales_high_salary_employees \
-m 1
- 说明:这里
-m 1是因为没有指定--split-by,Sqoop可能难以安全地并行化任意WHERE条件。如果id是主键且适合分割,可以尝试-m > 1并添加--split-by id。
2. 使用 --table 和 --columns 导入特定列
(A) 仅导入所有员工的 id, name, 和 department 列到HDFS
sqoop import \
--connect jdbc:mysql://localhost:3306/mydb \
--username dbuser \
-P \
--table employees \
--columns "id,name,department" \
--target-dir /data/employee_subset_columns \
-m 2 \
--split-by id
- 说明:只选择了三列数据进行导入。
3. 结合 --table, --where, 和 --columns
(A) 导入 ‘HR’ 部门员工的 name 和 hire_date 列到Hive表 hr_employees_info
sqoop import \
--connect jdbc:mysql://localhost:3306/mydb \
--username dbuser \
-P \
--table employees \
--columns "name,hire_date" \
--where "department = 'HR'" \
--hive-import \
--hive-table default.hr_employees_info \
--create-hive-table \
--target-dir /temp/hr_staging \
-m 1
4. 使用 --query 导入复杂子集
(A) 导入2022年后入职且薪水排名前10的员工的ID、姓名和薪水到HDFS,按薪水降序
sqoop import \
--connect jdbc:mysql://localhost:3306/mydb \
--username dbuser \
-P \
--query "SELECT id, name, salary FROM employees WHERE hire_date >= '2022-01-01' ORDER BY salary DESC LIMIT 10 AND \$CONDITIONS" \
--target-dir /data/top_recent_employees \
-m 1
# 注意: 这里的 ORDER BY 和 LIMIT 是在源数据库执行的。
# 如果要并行化(-m > 1),需要 \$CONDITIONS 和 --split-by (split-by的列必须在SELECT中)
# 且这种带 LIMIT 的查询并行化会比较复杂,通常对于这种取TOP N的场景,-m 1更直接。
# 或者,先全量/较大范围导入,再用Hive/Spark处理排序和LIMIT。
- 说明:
\$CONDITIONS在-m 1时可以省略。如果需要并行,并且id是主键,可以添加--split-by id。但对于已经包含ORDER BY LIMIT的查询,并行分割的意义和实现需要仔细考虑,可能不如单mapper直接。
四、核心注意事项
--where和--query中的SQL语法:确保遵循源数据库的SQL语法。- 并行化与
\$CONDITIONS:当使用--query并行导入 (-m > 1) 时,\$CONDITIONS占位符至关重要,它允许Sqoop为每个Map任务生成不同的数据范围。同时,必须配合--split-by(指定用于分割的列,该列必须在--query的SELECT列表中) 和可选的--boundary-query(如果Sqoop无法自动获取分割列的边界)。 --split-by列的选择:无论是--table还是--query模式,选择一个合适的--split-by列对于并行导入的效率和数据均衡非常重要。理想的列是有索引、数据分布均匀的数值型或日期型列。- Hive表创建:当使用
--columns或--query导入到Hive并使用--create-hive-table时,Sqoop会根据选择的列来创建Hive表结构。 - 性能考虑:复杂的
--where条件或--query可能会增加源数据库的查询负载。如果可能,尽量利用源数据库的索引。
练习题与解析
假设环境:
- MySQL数据库
ecommerce,包含表orders(order_id INT PRIMARY KEY, customer_id INT, order_date DATE, total_amount DECIMAL(10,2), status VARCHAR(20), shipping_city VARCHAR(100))。 - Hadoop集群已配置。
- MySQL连接信息:
jdbc:mysql://db.example.com:3306/ecommerce,用户importer,密码存储在HDFS文件/user/sqoop_pass/ecommerce.pass。
题目:
-
练习题1:按条件过滤行导入HDFS
请编写Sqoop命令,将ecommerce.orders表中所有状态 (status) 为 ‘COMPLETED’ 并且订单金额 (total_amount) 大于 1000 的订单数据,导入到HDFS的/retail_data/completed_high_value_orders目录下。使用默认的并行度,并尝试让Sqoop自动选择分割列 (假设order_id是主键)。 -
练习题2:选择特定列并按条件导入Hive
请编写Sqoop命令,仅导入ecommerce.orders表中shipping_city为 ‘New York’ 的订单的order_id,customer_id, 和order_date这三列数据。将这些数据导入到Hive表mart.ny_orders_subset。如果Hive表不存在则创建,如果存在则追加 (注意:Sqoop默认是覆盖,追加需要特定技巧或多步骤,这里假设我们接受覆盖或手动处理追加)。使用单个Map任务。 -
练习题3:使用自定义查询导入特定列和行到HDFS
请编写Sqoop命令,使用自定义查询从ecommerce.orders表中选择2023年1月份 (即order_date在 ‘2023-01-01’ 和 ‘2023-01-31’ 之间) 的所有订单的order_id和total_amount。将结果导入到HDFS的/finance_reports/jan_2023_orders_summary目录,并确保使用2个Map任务并行处理,以order_id进行分割。
解析:
- 练习题1答案与解析:
sqoop import \
--connect jdbc:mysql://db.example.com:3306/ecommerce \
--username importer \
--password-file /user/sqoop_pass/ecommerce.pass \
--table orders \
--where "status = 'COMPLETED' AND total_amount > 1000" \
--target-dir /retail_data/completed_high_value_orders
# 默认 -m 4,Sqoop会尝试使用主键 order_id 进行分割
--table orders --where "...": 从orders表中根据status和total_amount进行过滤。--password-file: 使用密码文件。- 没有显式指定
-m,Sqoop将使用默认的4个mapper。 - 没有显式指定
--split-by,Sqoop会尝试使用主键 (order_id)进行数据分割。
- 练习题2答案与解析:
sqoop import \
--connect jdbc:mysql://db.example.com:3306/ecommerce \
--username importer \
--password-file /user/sqoop_pass/ecommerce.pass \
--table orders \
--columns "order_id,customer_id,order_date" \
--where "shipping_city = 'New York'" \
--hive-import \
--hive-table mart.ny_orders_subset \
--create-hive-table \
# --hive-overwrite (如果需要覆盖)
# 要实现追加,通常需要先导入到HDFS临时目录,再用Hive的LOAD DATA INPATH ... INTO TABLE ... APPEND
# 或者使用Sqoop的--append参数(但这通常用于增量导入场景,且对目标HDFS目录有要求)
# 为简单起见,这里只演示创建/覆盖,如果题目明确要求追加,则需要更复杂操作或说明其限制。
# 此题中说“如果存在则追加”,但Sqoop import到hive的行为默认是覆盖(如果用了--hive-overwrite)或失败(如果表已存在且没用--hive-overwrite)。
# 若要严格追加,一般做法是:
# 1. sqoop import --table ... --where ... --columns ... --target-dir /temp/ny_orders_subset_new -m 1
# 2. hive -e "LOAD DATA INPATH '/temp/ny_orders_subset_new' INTO TABLE mart.ny_orders_subset;" (如果表已存在)
# 或者,如果表不存在,先创建再加载。
# 为了简化sqoop命令本身,我们这里假设--create-hive-table会处理,或者如果表已存在就覆盖。
--target-dir /temp/hive_staging_ny_orders \
-m 1
--columns "order_id,customer_id,order_date": 只选择这三列。--where "shipping_city = 'New York'": 过滤出纽约市的订单。--hive-import --hive-table mart.ny_orders_subset --create-hive-table: 导入到Hive,如果表不存在则创建。--target-dir /temp/hive_staging_ny_orders: 为Hive导入指定一个HDFS上的临时/暂存目录。-m 1: 使用单个Map任务。- 关于追加:Sqoop 的
--append参数主要用于增量导入到HDFS目录,并且要求目标数据是基于上次导入的最大值进行追加的。直接通过sqoop import --hive-import实现对Hive表的“追加”比较tricky,通常如果表已存在且没有--hive-overwrite,命令会失败。如果用了--hive-overwrite则是覆盖。要实现纯粹的追加,标准做法是先用Sqoop将子集导入HDFS的一个新目录,然后使用Hive的LOAD DATA INPATH ... INTO TABLE ...(不带OVERWRITE)命令将HDFS的数据加载到Hive表中。
- 练习题3答案与解析:
sqoop import \
--connect jdbc:mysql://db.example.com:3306/ecommerce \
--username importer \
--password-file /user/sqoop_pass/ecommerce.pass \
--query "SELECT order_id, total_amount FROM orders WHERE order_date >= '2023-01-01' AND order_date <= '2023-01-31' AND \$CONDITIONS" \
--split-by order_id \
--target-dir /finance_reports/jan_2023_orders_summary \
-m 2
--query "...": 使用自定义查询选择1月份的订单ID和总金额,并包含\$CONDITIONS。--split-by order_id: 告知Sqoop根据order_id列来分割自定义查询的结果集给2个Map任务。--target-dir ...: 数据导入到HDFS的指定目录。-m 2: 使用2个Map任务。
相关文章:

四、Sqoop 导入表数据子集
作者:IvanCodes 日期:2025年6月4日 专栏:Sqoop教程 当不需要将关系型数据库中的整个表一次性导入,而是只需要表中的一部分数据时,Sqoop 提供了多种方式来实现数据子集的导入。这通常通过过滤条件或选择特定列来完成。 …...
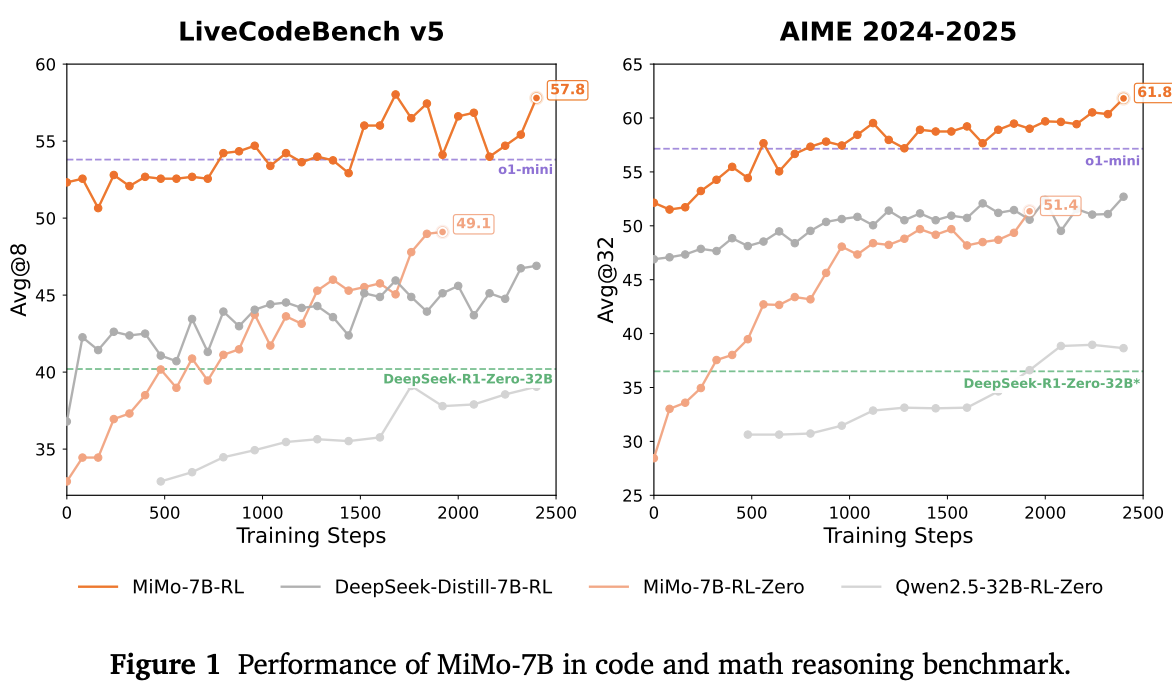
【读代码】从预训练到后训练:解锁语言模型推理潜能——Xiaomi MiMo项目深度解析
项目开源地址:https://github.com/XiaomiMiMo/MiMo 一、基本介绍 Xiaomi MiMo是小米公司开源的7B参数规模语言模型系列,专为复杂推理任务设计。项目包含基础模型(MiMo-7B-Base)、监督微调模型(MiMo-7B-SFT)和强化学习模型(MiMo-7B-RL)等多个版本。其核心创新在于通过…...
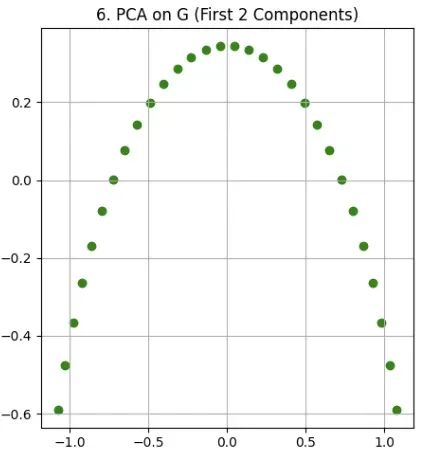
DROPP算法详解:专为时间序列和空间数据优化的PCA降维方案
DROPP (Dimensionality Reduction for Ordered Points via PCA) 是一种专门针对有序数据的降维方法。本文将详细介绍该算法的理论基础、实现步骤以及在降维任务中的具体应用。 在现代数据分析中,高维数据集普遍存在特征数量庞大的问题。这种高维特性不仅增加了计算…...

DeepSeek11-Ollama + Open WebUI 搭建本地 RAG 知识库全流程指南
🛠️ Ollama Open WebUI 搭建本地 RAG 知识库全流程指南 💻 一、环境准备 # 1. 安装 Docker 和 Docker Compose sudo apt update && sudo apt install docker.io docker-compose -y# 2. 添加用户到 docker 组(避免 sudo 权限&…...
【AI大模型】Transformer架构到底是什么?
引言 —— 想象一台能瞬间读懂整本《战争与和平》、精准翻译俳句中的禅意、甚至为你的设计草图生成前端代码的机器——这一切并非科幻,而是过去七年AI领域最震撼的技术革命:Transformer架构创造的奇迹。 当谷歌在2017年揭开Transformer的神秘面纱时&…...

code-server安装使用,并配置frp反射域名访问
为什么使用 code-server是VSCode网页版开发软件,可以在浏览器访问编程,可以使用vscode中的插件。如果有自己的服务器,使用frp透传后,域名访问在线编程,使用方便,打开的服务端口不需要单独配置,可…...
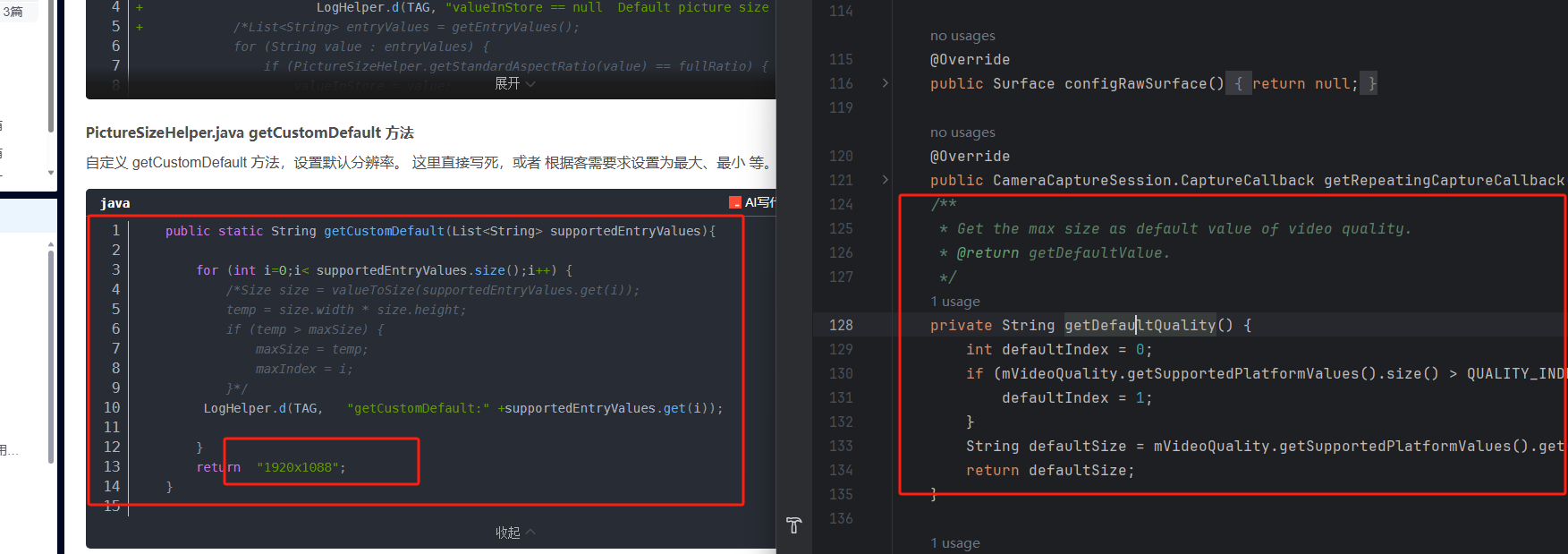
MTK-Android12-13 Camera2 设置默认视频画质功能实现
MTK-Android12-13 Camera2 设置默认视频画质功能实现 场景:部分客户使用自己的mipi相机安装到我们主板上,最大分辨率为1280720,但是视频画质默认的是640480。实际场景中,在默认视频分辨率情况下拍出来的视频比较模糊、预览也不清晰…...
)
Kafka 消息模式实战:从简单队列到流处理(一)
一、Kafka 简介 ** Kafka 是一种分布式的、基于发布 / 订阅的消息系统,由 LinkedIn 公司开发,并于 2011 年开源,后来成为 Apache 基金会的顶级项目。它最初的设计目标是处理 LinkedIn 公司的海量数据,如用户活动跟踪、消息传递和…...
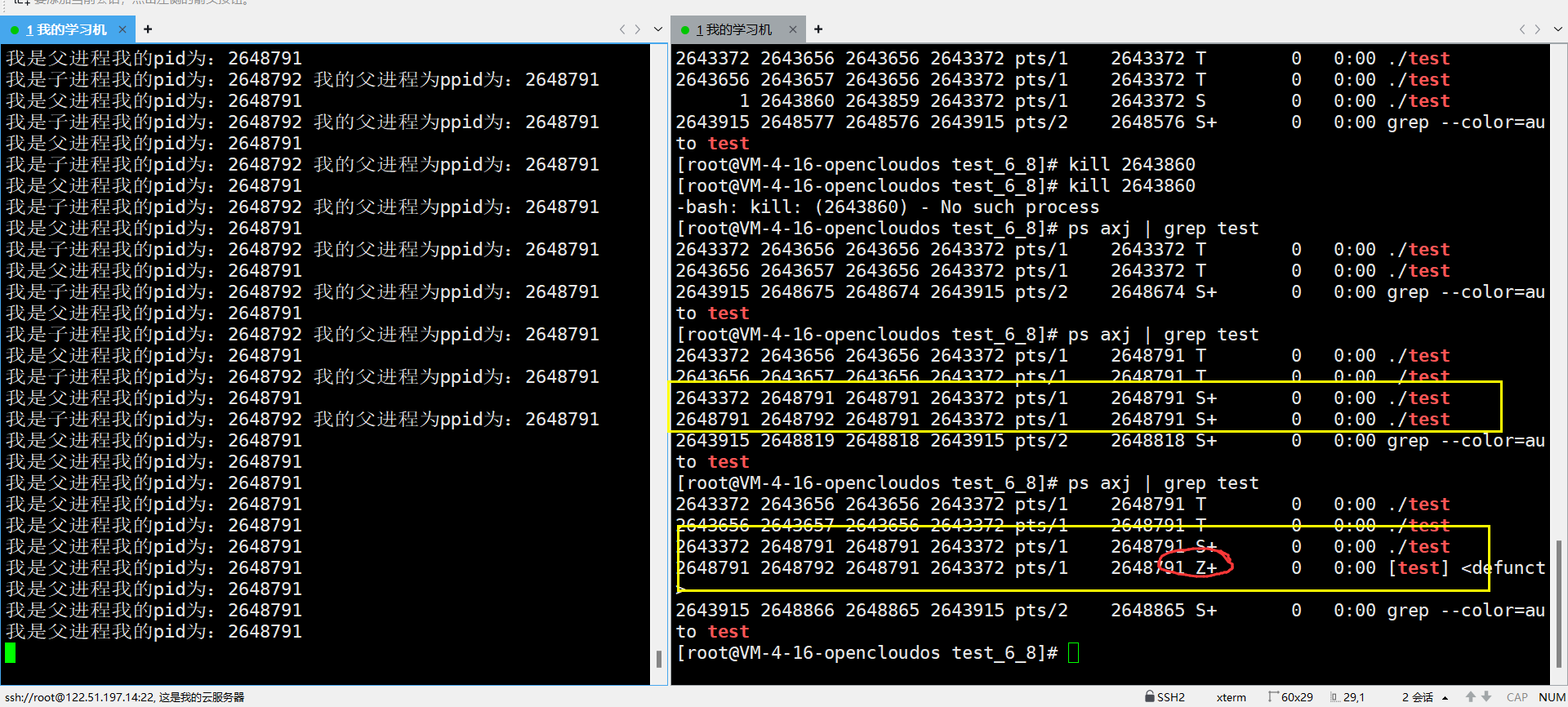
Linux知识回顾总结----进程状态
本章将会介绍进程的一些概念:冯诺伊曼体系结构、进程是什么,怎么用、怎么表现得、进程空间地址、物理地址、虚拟地址、为什么存在进程空间地址、如何感性得去理解进程空间地址、环境变量是如何使用的。 目录 1. 冯诺伊曼体系结构 1.1 是什么 1.2 结论 …...
Linux 进程管理学习指南:架构、计划与关键问题全解
Linux 进程管理学习指南:架构、计划与关键问题全解 本文面向初学者,旨在帮助你从架构视角理解 Linux 进程管理子系统,构建系统化学习路径,并通过结构化笔记方法与典型问题总结,夯实基础、明确方向,逐步掌握…...
)
【异常】极端事件的概率衰减方式(指数幂律衰减)
在日常事件中,极端事件的概率衰减方式并非单一模式,而是取决于具体情境和数据生成机制。以下是科学依据和不同衰减形式的分析: 1. 指数衰减(Exponential Decay) 典型场景:当事件服从高斯分布(正态分布)或指数分布时,极端事件的概率呈指数衰减。 数学形式:概率密度函数…...

Git 使用大全:从入门到精通
Git 是目前最流行的分布式版本控制系统,被广泛应用于软件开发中。本文将全面介绍 Git 的各种功能和使用方法,包含大量代码示例和实践建议。 文章目录 Git 基础概念版本控制系统Git 的特点Git 的三个区域Git 文件状态 Git 安装与配置安装 GitLinuxmacOSWi…...
奈飞工厂官网,国内Netflix影视在线看|中文网页电脑版入口
奈飞工厂是一个专注于提供免费Netflix影视资源的在线播放平台,致力于为国内用户提供的Netflix热门影视内容。该平台的资源与Netflix官网基本同步,涵盖电影、电视剧、动漫和综艺等多个领域。奈飞工厂的界面简洁流畅,资源分类清晰,方…...
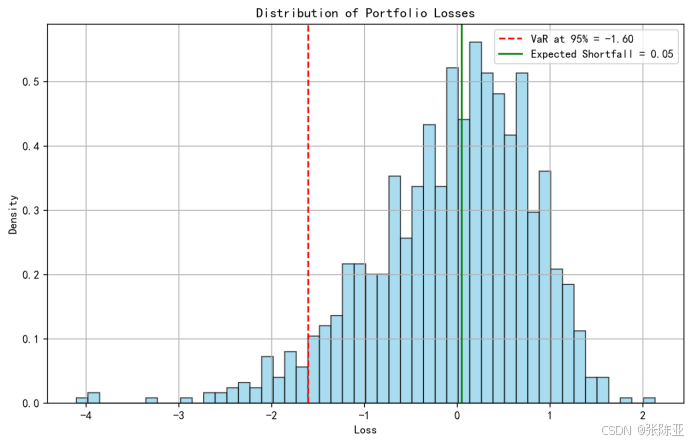
Python基于蒙特卡罗方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融投资中,风险管理是确保资产安全和实现稳健收益的关键环节。随着市场波动性的增加,传统…...

【bat win系统自动运行脚本-双击启动docker及其它】
win系统自动化运行脚本 创建一个 startup.bat右键编辑,输入以下示例 echo off start "" "C:\Program Files\Docker\Docker\Docker Desktop.exe"timeout /t 5docker start your_container_namestart cmd /k "conda activate your_conda_e…...

SpringBoot离线应用的5种实现方式
在当今高度依赖网络的环境中,离线应用的价值日益凸显。无论是在网络不稳定的区域运行的现场系统,还是需要在断网环境下使用的企业内部应用,具备离线工作能力已成为许多应用的必备特性。 本文将介绍基于SpringBoot实现离线应用的5种不同方式。…...

js 比较两个对象的值,不相等就push对象的key
在JavaScript中,比较两个对象(object)的值并找出不相等的key,可以通过多种方法实现。下面是一些常用的方法: 方法1:使用JSON.stringify 这种方法适用于简单的对象,其中对象的值是基本类型或可…...

SQL 注入开放与修复
开发: SQL 注入是一种数据库攻击手段。攻击者通过向应用程序提交恶意代码来改变原 SQL 语句的含义, 进而执行任意 SQL 命令,达到入侵数据库乃至操作系统的目的。 例如:下面代码片段中,动态构造并执行了一个 SQ…...

【学习记录】Office 和 WPS 文档密码破解实战
文章目录 📌 引言📁 Office 与 WPS 支持的常见文件格式Microsoft Office 格式WPS Office 格式 🛠 所需工具下载地址(Windows 官方编译版)🔐 破解流程详解步骤 1:提取文档的加密哈希值步骤 2&…...
AGV|无人叉车工业语音播报器|预警提示器LBE-LEX系列性能与接线说明
LBE-LEX系列AGV|无人叉车工业语音播报器|预警提示器,涵盖LBE-LEI-M-00、LBE-LESM-00、LBE-LES-M-01、LBE-LEC-M-00、LBE-KEI-M-00、LBE-KES-M-00、LBE-KES-M-01、LBE-KEC-M-00等型号,适用于各种需要语音提示的场景,主要有AGV、AMR机器人、无人…...

【电路笔记】-变压器电压调节
变压器电压调节 文章目录 变压器电压调节1、概述2、变压器电压调节3、变压器电压调节示例14、变压器电压调节示例25、变压器电压调节示例36、总结变压器电压调节是变压器输出端电压因连接负载电流的变化而从其空载值向上或向下变化的比率或百分比值。 1、概述 电压调节是衡量变…...

多层PCB技术解析:从材料选型到制造工艺的深度实践
在电子设备集成度与信号传输要求不断提升的背景下,多层PCB凭借分层布局优势,成为高速通信、汽车电子、工业控制等领域的核心载体。其通过导电层、绝缘层的交替堆叠,实现复杂电路的立体化设计,显著提升空间利用率与信号完整性。 一…...

(33)课54:3 张表的 join-on 连接举例,多表查询总结。数据库编程补述及游标综合例题。静态 sqL与动态sqL(可带参数)
(112)3 张表的 join-on 连接举例 : (113) 多表查询总结 : (114)数据库编程补述 : 综合例题 : 以上没有动手练习,不知道这样的语法是否…...

Vue3 hooks
export default function(){ let name; function getName(){ return name; } return {name,getName} } use it ----------------------------------------------- import useName from hooks/useName const {name,getName} useName(); 这段代码展示了一个自定义 Vue3钩…...
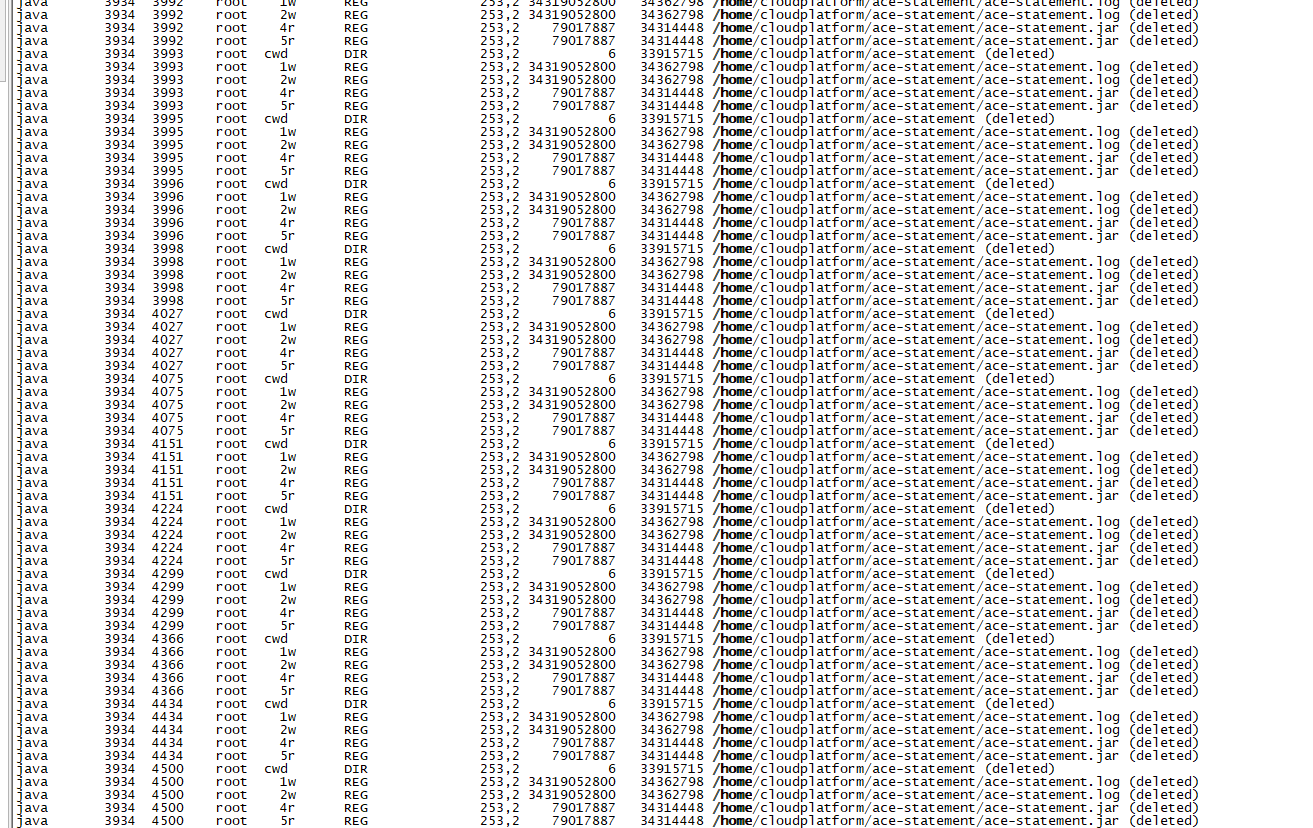
centos挂载目录满但实际未满引发系统宕机
测试服务器应用系统突然挂了,经过排查发现是因为磁盘“满了”导致的,使用df -h查看磁盘使用情况/home目录使用率已经到了100%,但使用du -sh /home查看发现实际磁盘使用还不到1G,推测有进程正在写入或占用已删除的大文件(Linux 系统…...
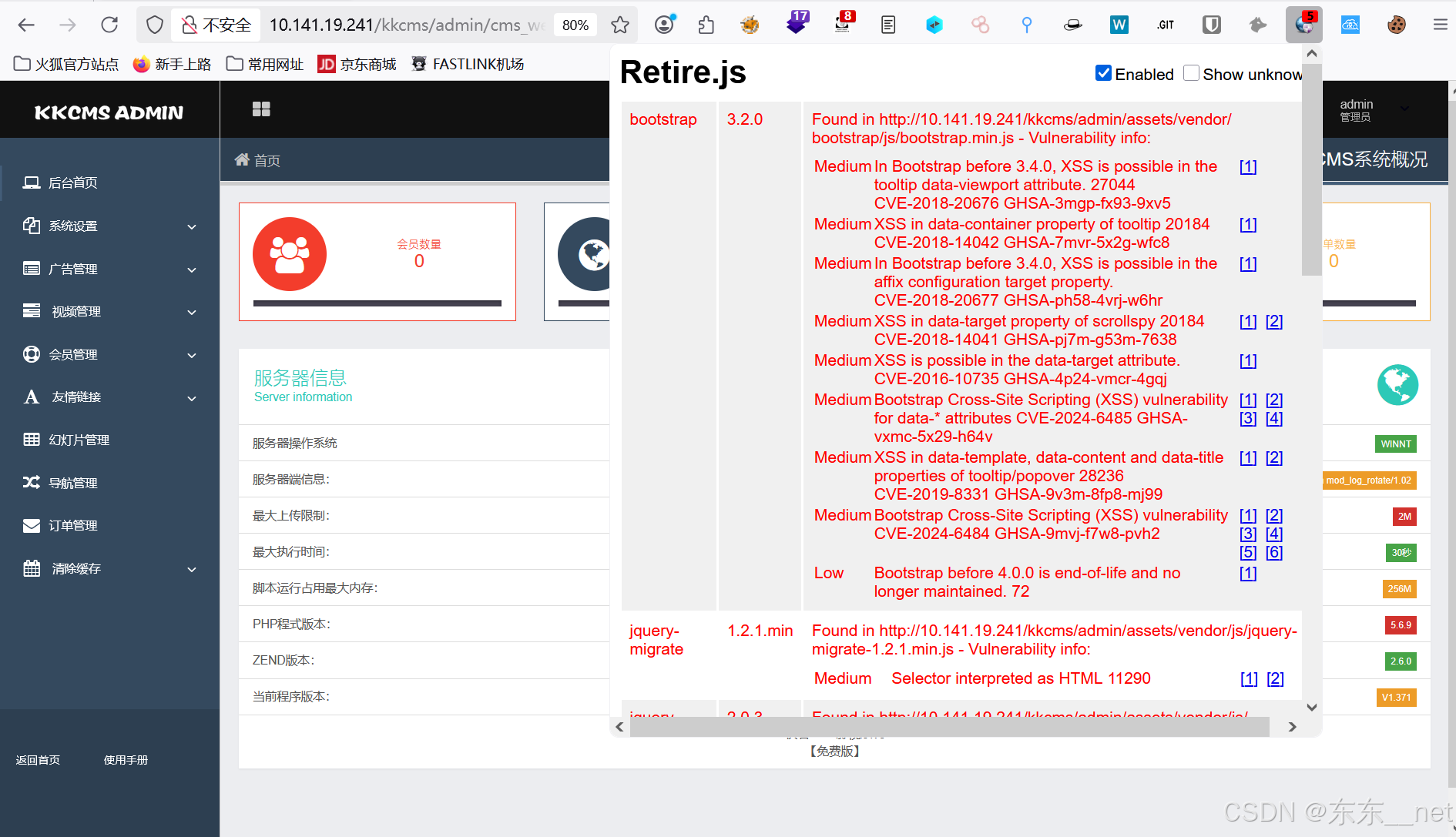
KKCMS部署
目录 账号 网站目录 快看CMS使用手册 http://10.141.19.241/kkcms/install/ 常规思路:页面点点观察url变化,参数 常规思路:点一个功能模块抓包看什么东西,正确是什么样,错误的是什么样,构造参数。 账号…...

NamedParameterJdbcTemplate 使用方法及介绍
NamedParameterJdbcTemplate是 Spring 框架中用于数据库操作的核心类之一,它拓展了JdbcTemplate,通过封装实现命名参数特性,相比传统占位符?,命名参数可读性和维护性更强,能有效避免参数顺序混淆问题。 一、核心支持…...

【web笔记】JavaScript实现有动画效果的进度条
文章目录 1 实现效果2 实现代码 1 实现效果 2 实现代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"utf-8"><style>#progress {width: 300px;height: 20px;border-radius: 0; /* 移除圆角 */-webkit-appearance…...
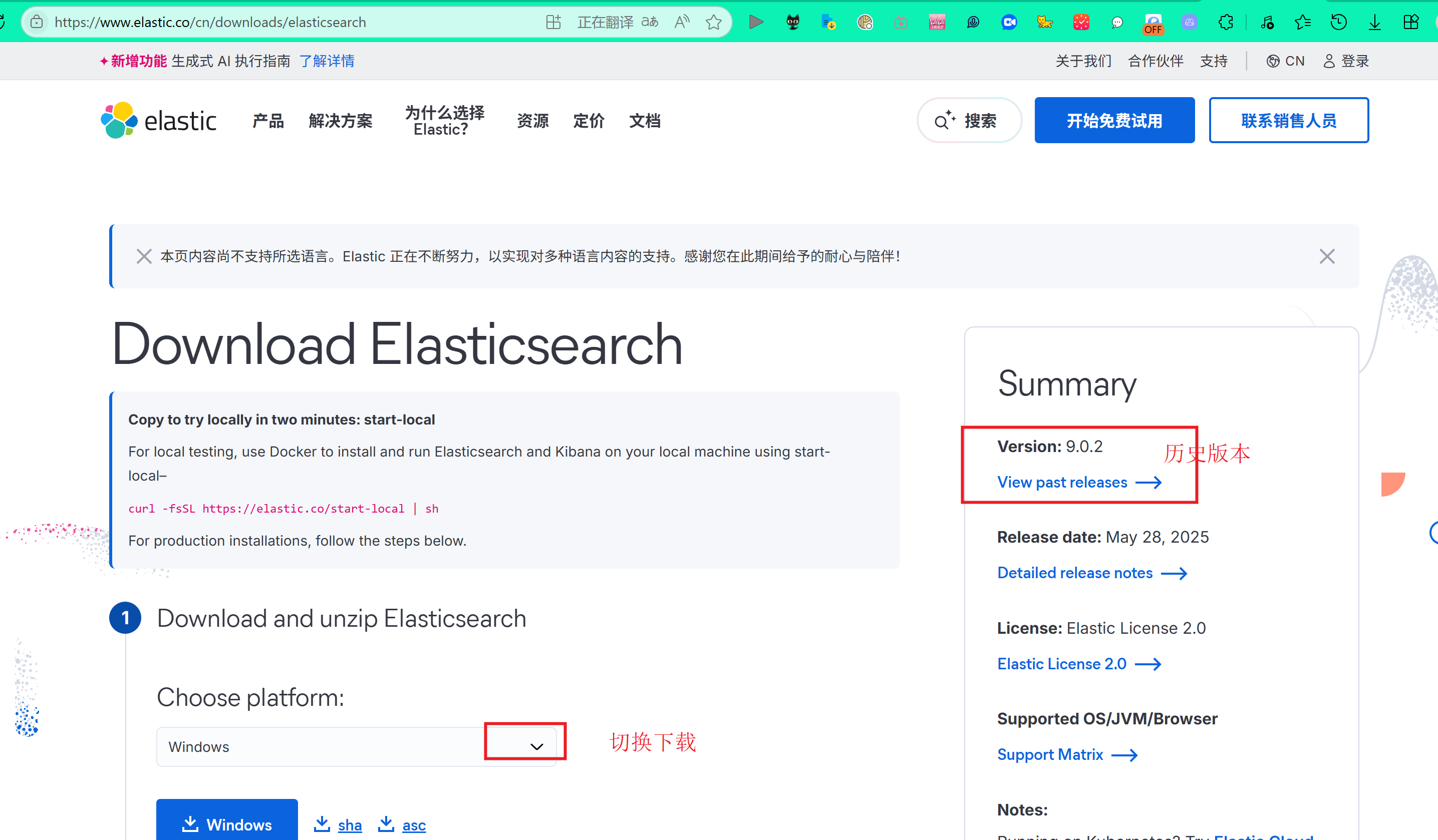
安装最新elasticsearch-8.18.2
1.环境我的环境是linux麒麟服务器 (安装 es 7.8以上 java环境必须11以上,可以单独配置es的java目录) 2.下载 官网的地址:下载 Elastic 产品 | Elastic Download Elasticsearch | Elastic Elasticsearch 入门 | Elasticsearch 中文文档 文档 3.我下载的是8.18的 Elasti…...
-Hive数据分析)
大数据学习(129)-Hive数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...