JVM——对象模型:JVM对象的内部机制和存在方式是怎样的?
引入
在Java的编程宇宙中,“Everything is object”是最核心的哲学纲领。当我们写下new Book()这样简单的代码时,JVM正在幕后构建一个复杂而精妙的“数据实体”——对象。这个看似普通的对象,实则是JVM内存管理、类型系统和多态机制的基石。从字节码加载到内存布局,从锁状态标识到多态实现,对象模型贯穿了Java程序的整个生命周期。
JVM对象基础协议:内存布局的黄金法则
对象大小的强制规范:8字节对齐原则
在JVM中,每个对象的内存占用必须是8字节的整数倍。这一规则并非随意设定,而是由CPU的硬件特性决定:CPU以“字”(Word)为单位读取数据,64位CPU的字长为8字节,且缓存行(Cache Line)通常为64字节(8个字)。若对象未对齐,可能导致CPU读取数据时跨缓存行,增加额外的内存访问开销。
构成对象大小的三要素
对象头(Instance Header):存储元数据,占16字节(64位系统,含指针压缩)。
实例数据(Instance Data):存储字段值,按类型占用不同字节。
对齐填充(Padding):补足至8字节倍数,无实际数据意义。
示例计算:
class SimpleObject { boolean flag = true; // 1字节 short num = 10; // 2字节
}
// 实例数据:1+2=3字节 → 对象头16字节 → 总计19字节 → 填充5字节至24字节(3×8)。对象头:元数据的核心载体
对象头是对象协议中最复杂的部分,由三部分组成,在64位系统中占16字节(未压缩时):
Mark Word:动态变化的运行时数据
Mark Word是一个随对象状态动态变化的数据结构,在不同锁状态下存储不同信息:
| 锁状态 | Mark Word结构(64位) | 核心作用 |
|---|---|---|
| 无锁 | 25位HashCode1位偏向锁标志 | 存储对象标识、分代信息及锁状态 |
| 偏向锁 | 54位线程ID+时间戳1位偏向锁标志 | 记录持有锁的线程及时间戳 |
| 轻量级锁 | 62位指向栈锁记录的指针 | 无阻塞自旋锁的底层实现 |
| 重量级锁 | 62位指向Monitor的指针 | 管理阻塞线程的互斥资源 |
| GC标记 | 62位未定义 | 标识对象正在被GC处理 |
关键细节:
HashCode存储:无锁状态下存储25位HashCode,由System.identityHashCode()生成,与Object.hashCode()的区别在于前者不会因方法重写而改变。
分代年龄:4位字段最大值为15,对象在Survivor区每复制一次加1,达到阈值(默认15)则晋升老年代。
偏向锁标志:1位标识是否启用偏向锁,0表示无偏向锁,1表示偏向锁生效。
Klass指针:对象的“类型身份证”
Klass指针指向方法区中的Klass对象,用于标识对象的具体类型。
在HotSpot中采用OOP-Klass模型:
-
OOP(Ordinary Object Pointer):普通对象指针,代表堆中的对象实例。
-
Klass:存储类的元数据(如继承关系、方法表、字段表),位于方法区(元空间)。 通过Klass指针,JVM可快速判断对象类型,例如在多态调用时确定实际执行的方法。
数组长度(仅数组对象)
数组对象的对象头中额外包含4字节的长度字段,用于记录数组元素个数。例如int[] array = new int[100],对象头中存储长度值100。
实例数据:业务逻辑的载体
实例数据存储对象的字段值,分为两类:
-
基本数据类型:直接存储值,占用固定字节(如
int4字节,double8字节)。 -
引用类型:存储对象的内存地址(指针),32位系统占4字节,64位系统默认占8字节(启用指针压缩时占4字节)。
存储规则:
-
父类字段在前,子类字段在后。
-
相同宽度的字段相邻存储,提升缓存利用率。
class Parent { long id; } // 8字节
class Child extends Parent { int value; } // 父类id(8)+ 子类value(4)→ 共12字节,填充4字节至16字节。对齐填充:以空间换时间的优化
填充的本质是通过额外字节使对象总大小满足8字节对齐,避免CPU非对齐访问。
例如:
-
对象头(16字节)+ 实例数据(5字节)= 21字节 → 填充3字节至24字节(3×8)。
-
CPU读取非对齐数据时可能需要两次内存访问,而对齐后只需一次,尤其在高频访问场景下,填充带来的性能提升显著。
OOP-Klass模型:多态实现的底层架构
模型本质:对象与类的双重抽象
OOP-Klass模型是JVM对Java类的底层实现,将类分为两部分:
-
OOP(对象实例):存储对象头、实例数据和对齐填充,位于堆中,对应Java层的
new操作结果。 -
Klass(类元数据):存储类的结构信息,位于方法区,包含:
-
方法表(Method Table):数组形式存储方法指针,用于动态绑定。
-
字段表(Field Table):记录字段名称、类型及内存偏移量。
-
继承链指针:指向父类Klass,形成类继承树。
-
接口列表:存储该类实现的所有接口Klass指针。
-
多态的底层实现:方法表的动态绑定
以Book类及其子类ColorBook为例:
class Book { public void print() { System.out.println("Common Book"); } }
class ColorBook extends Book { @Override public void print() { System.out.println("Color Book"); } }
Book book = new ColorBook();
book.print(); // 输出“Color Book”方法表的创建时机
类加载的解析阶段,JVM为每个类创建方法表(Method Table),包含所有实例方法的指针。子类会继承父类的方法表,并覆盖重写的方法指针。例如ColorBook的方法表中,print方法的指针指向子类实现,而非父类。
动态绑定的执行流程
-
获取对象实际类型:通过
book的对象头Klass指针,定位到ColorBook的Klass对象。 -
查找方法表:在
ColorBook的方法表中,根据方法名和参数列表查找print方法的指针(偏移量与父类一致)。 -
调用方法:执行指针指向的
ColorBook.print()方法,而非父类方法。
字节码视角:
invokevirtual #6 // 表面调用Book.print(),实际动态解析为ColorBook.print()invokevirtual指令通过对象实际类型动态解析方法,实现多态的核心机制——动态绑定。
指针压缩:64位JVM的内存优化
在64位JVM中,默认启用指针压缩(-XX:+UseCompressedOops),将Klass指针和对象引用从8字节压缩为4字节,节省内存占用:
-
适用条件:堆大小≤32GB(压缩地址范围为0-32GB)。
-
实现原理:通过基址寄存器(如
java.base.address)+ 压缩偏移量计算真实地址。 -
性能影响:压缩后的指针访问需一次额外计算,但现代CPU通过缓存优化,实际损耗可忽略不计。
对象模型与性能优化实践
垃圾回收中的对象生命周期管理
分代年龄判断:对象头的4位年龄字段决定对象晋升老年代的时机。例如,默认情况下,对象在Survivor区经历15次GC后(年龄=15),会被复制到老年代。
-XX:MaxTenuringThreshold=20 // 调整晋升阈值为20次GCGC标记阶段:对象进入标记阶段时,Mark Word设置为GC标记状态(锁标志位11),便于GC扫描识别。
锁优化的底层依据
偏向锁优化:通过Mark Word存储线程ID,避免无竞争场景下的锁膨胀。例如,单线程频繁调用同步方法时,偏向锁可减少CAS操作开销。
轻量级锁升级:当偏向锁竞争加剧时,Mark Word切换为轻量级锁状态,通过CAS操作自旋尝试获取锁,避免立即升级为重量级锁。
重量级锁的Monitor关联:Mark Word指向Monitor对象,通过操作系统互斥锁实现线程阻塞,适用于高竞争场景。
内存布局优化:减少对象空间占用
字段顺序调整
将相同类型或宽度的字段集中声明,减少填充字节:
反例:
class Data { boolean b; long l; int i; }
// 布局:b(1) + l(8) + i(4) → 总13字节,填充3字节至16字节(浪费3字节)。优化后:
class Data { long l; int i; boolean b; }
// 布局:l(8) + i(4) + b(1) → 总13字节,同样填充3字节,但逻辑上更紧凑。避免伪共享(False Sharing)
当多个线程频繁访问同一缓存行中的不同字段时,会导致缓存行频繁失效(伪共享)。通过填充字段使对象独占一个缓存行(64字节):
class CacheLineSafe { volatile long value; // 8字节 long p1, p2, p3, p4, p5, p6, p7; // 56字节填充,共64字节(1个缓存行)
}对象模型的扩展:从基础到高级特性
数组对象的特殊结构
数组对象的对象头包含长度字段,实例数据存储元素值:
-
基本类型数组:如
int[],实例数据直接存储元素值,无额外指针开销。 -
引用类型数组:如
Object[],实例数据存储对象引用(指针),每个元素占4/8字节(取决于是否压缩)。 数组长度通过arraylength字节码指令获取,存储于对象头的长度字段中。
字符串常量池与对象驻留
字符串常量(如"hello")存储于方法区的字符串常量池(StringTable),通过String.intern()方法可将运行时字符串实例驻留到常量池,避免重复创建对象。
例如:
String s1 = "hello"; // 直接从常量池获取
String s2 = new String("hello").intern(); // 手动驻留,s1 == s2为true反射与对象模型的交互
反射机制通过Klass对象获取类元数据,例如:
Book book = new Book();
Class<?> clazz = book.getClass(); // 通过OOP的Klass指针获取Klass对象
Field[] fields = clazz.getDeclaredFields(); // 从Klass的字段表获取字段信息
Method printMethod = clazz.getMethod("print"); // 从Klass的方法表获取方法指针反射的性能损耗源于动态解析Klass元数据,相比直接调用慢约100倍,因此应避免在高频路径中使用。
总结
JVM的对象模型是Java语言特性的底层载体,其设计哲学贯穿于内存管理、类型系统和运行时优化:
-
内存布局:通过对象头、实例数据和对齐填充的精密设计,平衡了CPU访问效率与内存占用。
-
多态实现:OOP-Klass模型与方法表机制,使Java在运行时能够动态绑定方法,实现面向对象的核心特性。
-
性能优化:分代年龄、锁状态标识、指针压缩等设计,为GC、锁优化和多线程编程提供了底层支持。
对于开发者而言,理解对象模型意味着:
-
能够预估对象的内存占用,通过字段顺序调整和填充策略优化对象布局。
-
在分析GC日志时,可根据分代年龄判断对象晋升路径,优化垃圾回收策略。
-
在处理高并发场景时,能基于Mark Word的锁状态选择合适的同步策略,避免性能瓶颈。
从JDK早期的对象头设计到现代JVM的指针压缩与分层编译,对象模型始终是JVM优化的核心领域。
相关文章:

JVM——对象模型:JVM对象的内部机制和存在方式是怎样的?
引入 在Java的编程宇宙中,“Everything is object”是最核心的哲学纲领。当我们写下new Book()这样简单的代码时,JVM正在幕后构建一个复杂而精妙的“数据实体”——对象。这个看似普通的对象,实则是JVM内存管理、类型系统和多态机制的基石。…...

Java求职者面试:微服务技术与源码原理深度解析
Java求职者面试:微服务技术与源码原理深度解析 第一轮:基础概念问题 1. 请解释什么是微服务架构,并说明其优势和挑战。 微服务架构是一种将单体应用拆分为多个小型、独立的服务的软件开发方法。每个服务都运行在自己的进程中,并…...
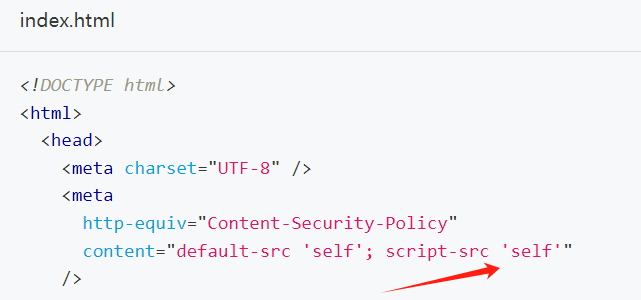
[electron]预脚本不显示内联script
script-src self 是 Content Security Policy (CSP) 中的一个指令,它的作用是限制加载和执行 JavaScript 脚本的来源。 具体来说: self 表示 当前源。也就是说,只有来自当前网站或者当前页面所在域名的 JavaScript 脚本才被允许执行。"…...
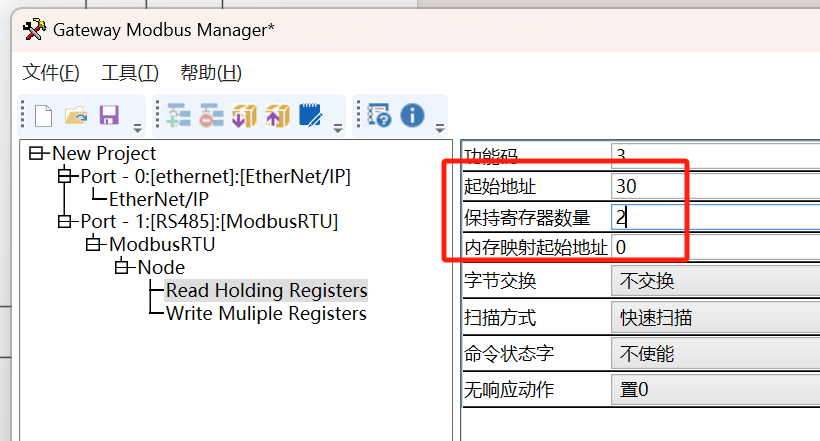
开疆智能Ethernet/IP转Modbus网关连接斯巴拓压力传感器配置案例
本案例是将ModbusRTU协议的压力传感器数据上传到欧姆龙PLC,由于PLC采用的是Ethernet/IP通讯协议,两者无法直接进行数据采集。故使用开疆智能研发的Ethernet转Modbus网关进行数据转换。 配置过程 首先我们开始配置Ethernet/IP主站(如罗克韦尔…...
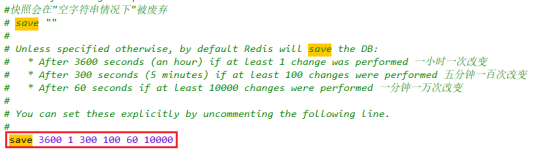
【Redis】Redis 的持久化策略
目录 一、RDB 定期备份 1.2 触发方式 1.2.1 手动触发 1.2.2.1 自动触发 RDB 持久化机制的场景 1.2.2.2 检查是否触发 1.2.2.3 线上运维配置 1.3 检索工具 1.4 RDB 备份实现原理 1.5 禁用 RDB 快照 1.6 RDB 优缺点分析 二、AOF 实时备份 2.1 配置文件解析 2.2 开启…...
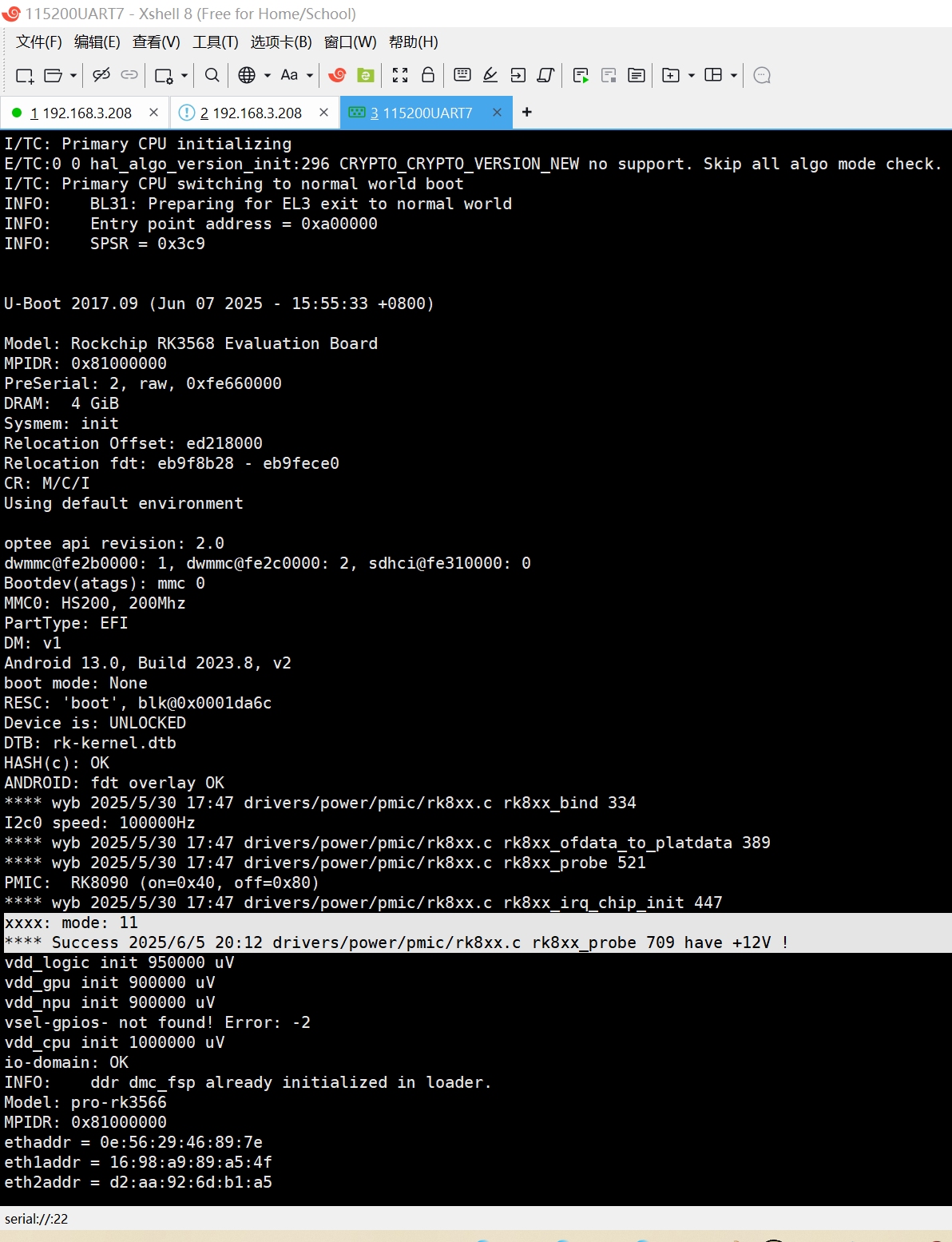
20250607在荣品的PRO-RK3566开发板的Android13系统下实现长按开机之后出现插入适配器不会自动启动的问题的解决
20250607在荣品的PRO-RK3566开发板的Android13系统下实现长按开机之后出现插入适配器不会自动启动的问题的解决 2025/6/7 17:20 缘起: 1、根据RK809的DATASHEET,短按开机【100ms/500ms】/长按关机,长按关机。6s/8s/10s 我在网上找到的DATASHE…...

Asp.net Core 通过依赖注入的方式获取用户
思路:Web项目中,需要根据当前登陆的用户,查询当前用户所属的数据、添加并标识对象等。根据请求头Authorization 中token,获取Redis中存储的用户对象。 本做法需要完成 基于StackExchange.Redis 配置,参考:…...
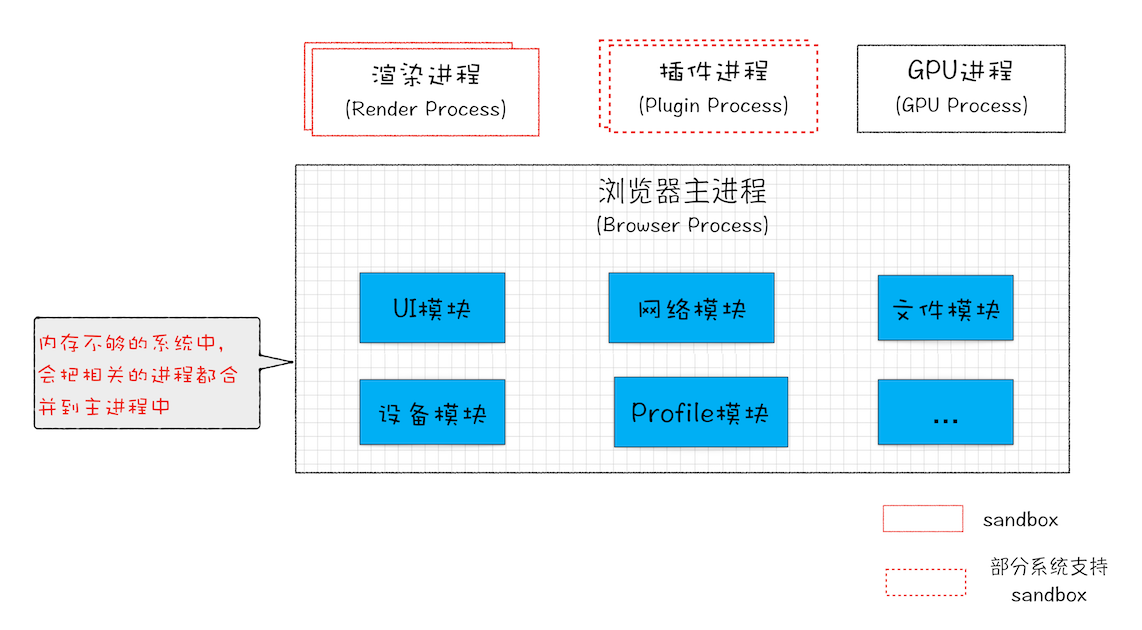
浏览器工作原理01 [#]Chrome架构:仅仅打开了1个页面,为什么有4个进程
引用 浏览器工作原理与实践 Chrome打开一个页面需要启动多少进程?你可以点击Chrome浏览器右上角的“选项”菜单,选择“更多工具”子菜单,点击“任务管理器”,这将打开Chrome的任务管理器的窗口,如下图 和Windows任务管…...

智能问数Text2SQL Vanna windows场景验证
架构 Vanna 是一个开源 Python RAG(检索增强生成)框架,用于 SQL 生成和相关功能。 机制 Vanna 的工作过程分为两个简单步骤 - 在您的数据上训练 RAG“模型”,然后提出问题,这些问题将返回 SQL 查询,这些查…...
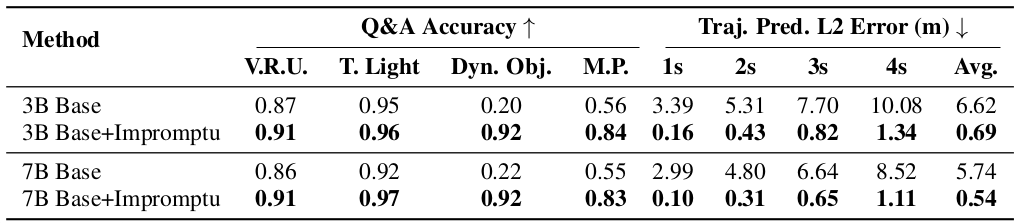
【VLAs篇】02:Impromptu VLA—用于驱动视觉-语言-动作模型的开放权重和开放数据
项目描述论文标题Impromptu VLA:用于驱动视觉-语言-动作模型的开放权重和开放数据 (Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models)研究问题自动驾驶的视觉-语言-动作 (VLA) 模型在非结构化角落案例场景中表现不佳…...

[学习笔记]使用git rebase做分支差异化同步
在一个.NET 项目中,使用了Volo.Abp库,但出于某种原因,需要源码调试,因此,使用源码方式集成的项目做了一个分支archive-abp-source 其中引用方式变更操作的提交为:7de53907 后续,在master分支中…...

Java + Spring Boot + Mybatis 插入数据后,获取自增 id 的方法
在 MyBatis 中使用 useGeneratedKeys"true" 获取新插入记录的自增 ID 值,可通过以下步骤实现: 1. 配置 Mapper XML 在插入语句的 <insert> 标签中设置: xml 复制 下载 运行 <insert id"insertUser" para…...
【Linux应用】Linux系统日志上报服务,以及thttpd的配置、发送函数
【Linux应用】Linux系统日志上报服务,以及thttpd的配置、发送函数 文章目录 thttpd服务安装thttpd配置thttpd服务thttpd函数日志效果和文件附录:开发板快速上手:镜像烧录、串口shell、外设挂载、WiFi配置、SSH连接、文件交互(RADX…...

Nginx 事件驱动理解
在做埋点采集服务的过程中,主要依靠openresty加lua脚本来实现采集。高并发还是主要依靠nginx来实现。而其核心就是事件驱动/多路io复用(epoll机制),不同的linux服务器都有对应的实现方式。 而epoll机制就是,应用启动的…...
Jmeter(四) - 如何在jmeter中创建网络测试计划
1.简介 如何创建基本的 测试计划来测试网站。您将创建五个用户,这些用户将请求发送到JMeter网站上的两个页面。另外,您将告诉用户两次运行测试。 因此,请求总数为(5个用户)x(2个请求)xÿ…...

Amazon RDS on AWS Outposts:解锁本地化云数据库的混合云新体验
在混合云架构成为企业数字化转型标配的今天,如何在本地数据中心享受云数据库的强大能力,同时满足数据本地化、低延迟访问的严苛需求?Amazon RDS on AWS Outposts 给出了完美答案——将AWS完全托管的云数据库服务无缝延伸至您的机房࿰…...
2025年上海市“星光计划”第十一届职业院校技能大赛 网络安全赛项技能操作模块样题
2025年上海市“星光计划”第十一届职业院校技能大赛 网络安全赛项技能操作模块样题 (二)模块 A:安全事件响应、网络安全数据取证、应用安全、系统安全任务一:漏洞扫描与利用:任务二:Windows 操作系统渗透测试 :任务三&…...

jieba实现和用RNN实现中文分词的区别
Jieba 分词和基于 RNN 的分词在技术路线、实现机制、性能特点上有显著差异,以下是核心对比: 1. 技术路线对比 维度Jieba 分词RNN 神经网络分词范式传统 NLP(规则 统计)深度学习(端到端学习)核心依赖词典…...

android计算器代码
本次作业要求实现一个计算器应用的基础框架。以下是布局文件的核心代码: <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"andr…...

leetcode 386. 字典序排数 中等
给你一个整数 n ,按字典序返回范围 [1, n] 内所有整数。 你必须设计一个时间复杂度为 O(n) 且使用 O(1) 额外空间的算法。 示例 1: 输入:n 13 输出:[1,10,11,12,13,2,3,4,5,6,7,8,9]示例 2: 输入:n 2…...

Modbus转ETHERNET IP网关:快速冷却系统的智能化升级密钥
现代工业自动化系统中,无锡耐特森Modbus转Ethernet IP网关MCN-EN3001扮演着至关重要的角色。通过这一技术,传统的串行通讯协议Modbus得以在更高速、更稳定的以太网环境中运行,为快速冷却系统等关键设施的自动化控制提供了强有力的支撑。快速冷…...
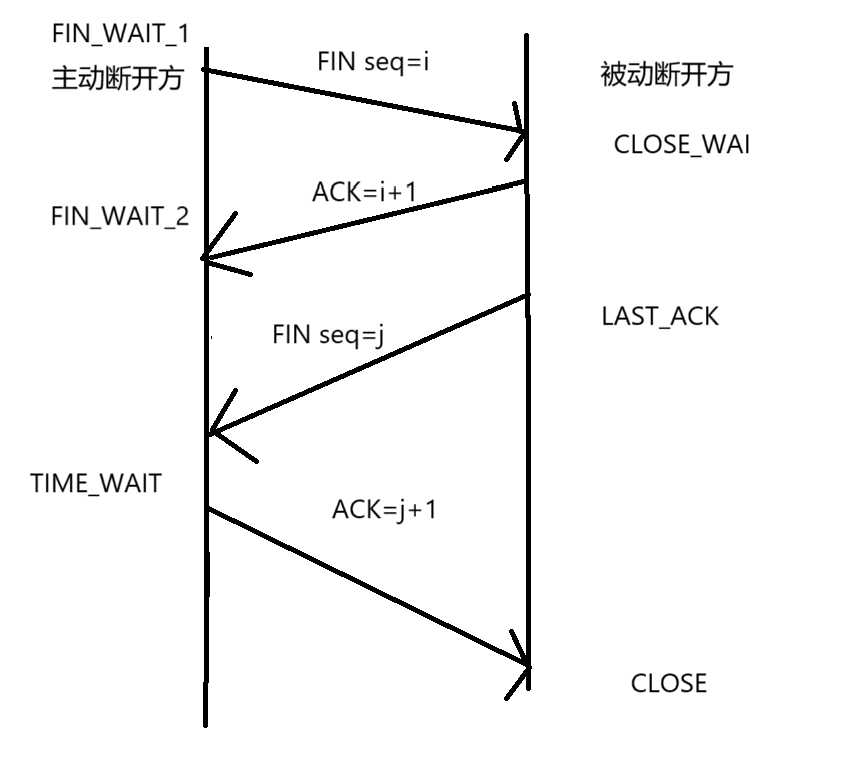
Linux——TCP和UDP
一、TCP协议 1.特点 TCP提供的是面向连接、可靠的、字节流服务。 2.编程流程 (1)服务器端的编程流程 ①socket() 方法创建套接字 ②bind()方法指定套接字使用的IP地址和端口。 ③listen()方法用来创建监听队列。 ④accept()方法处理客户端的连接…...

比较数据迁移后MySQL数据库和PostgreSQL数据仓库中的表
设计一个MySQL数据库和PostgreSQL数据库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较两…...

云原生技术驱动 IT 架构现代化转型:企业实践与落地策略全解
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、背景:IT 架构演进的战略拐点 过去十年,企业 IT 架构经历了从传统集中式架构到分布式架构的转型。进入云计算…...
Android Settings 数据库生成、监听与默认值配置
一、Settings 数据库生成机制 传统数据库生成(Android 6.0 前) 路径:/data/data/com.android.providers.settings/databases/settings.db创建流程: SQL 脚本初始化:通过 sqlite 工具创建数据库文件…...
SeaweedFS S3 Spring Boot Starter
SeaweedFS S3 Spring Boot Starter 源码特性环境要求快速开始1. 添加依赖2. 配置文件3. 使用方式方式一:注入服务类方式二:使用工具类 API 文档SeaweedFsS3Service 主要方法SeaweedFsS3Util 工具类方法 配置参数运行测试构建项目注意事项集成应用更多项目…...

Monorepo架构: 项目管理模式对比与考量
关于 monorepo 相关概念及项目管理模式 在软件开发中,尤其是前端项目,我们会涉及到不同的项目管理模式,这里先介绍几个重要的概念“monorepo”是当前较为热门的一种项目管理方式,虽然很多人可能听说过,但可能在实际项…...

智慧城市项目总体建设方案(Word700页+)
1 背景、现状和必要性 1.1 背景 1.1.1 立项背景情况 1.1.2 立项依据 1.2 现状 1.2.1 党建体系运行现状 1.2.2 政务体系运行现状 1.2.3 社会治理运行现状 1.2.4 安全监管体系现状 1.2.5 环保体系运行现状 1.2.6 城建体系运行现状 1.2.7 社区体系运行现状 1.2.8 园区…...
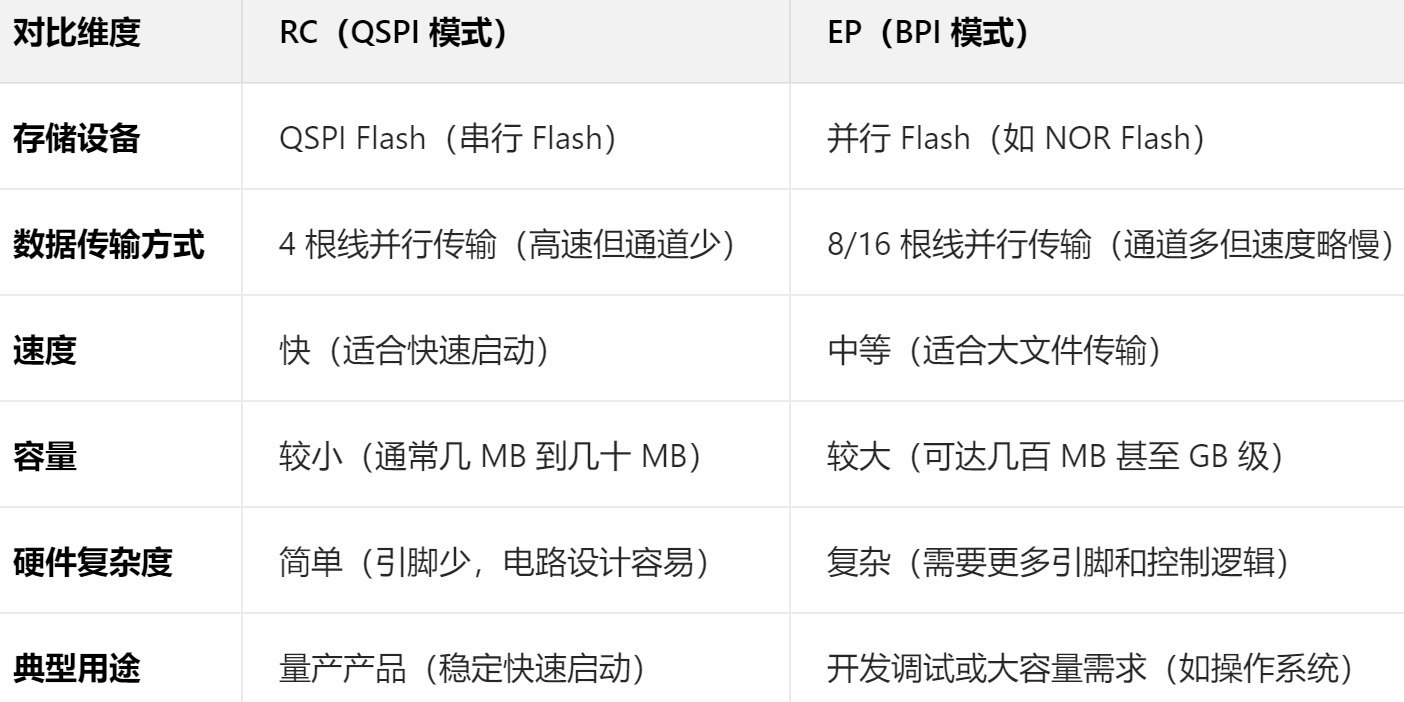
详解ZYNQ中的 RC 和 EP
详解ZYNQ中的 RC 和 EP 一、ZYNQ FPGA 开发板基础( ZC706 ) 1. 核心特点 双核大脑 灵活积木: ZC706 集成了 ARM Cortex-A9 双核处理器(相当于电脑 CPU)和 FPGA 可编程逻辑单元(相当于可自定义的硬件积木…...

CSP信奥赛C++常用系统函数汇总
# CSP信奥赛C常用系统函数汇总## 一、输入输出函数### 1. cin / cout(<iostream>) cpp int x; cin >> x; // 输入 cout << x << endl;// 输出 优化:ios::sync_with_stdio(false); 可提升速度 2. scanf() /…...