Python 训练营打卡 Day 47
注意力热力图可视化
在day 46代码的基础上,对比不同卷积层热力图可视化的结果
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集:仅进行必要的标准化,保持数据原始特性,标准化不损失数据信息,可还原
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform # 测试集不使用增强
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# ===================== 新增:通道注意力模块(SE模块) =====================
class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_ratio=16):"""参数:in_channels: 输入特征图的通道数reduction_ratio: 降维比例,用于减少参数量"""super(ChannelAttention, self).__init__()# 全局平均池化 - 将空间维度压缩为1x1,保留通道信息self.avg_pool = nn.AdaptiveAvgPool2d(1)# 全连接层 + 激活函数,用于学习通道间的依赖关系self.fc = nn.Sequential(# 降维:压缩通道数,减少计算量nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),nn.ReLU(inplace=True),# 升维:恢复原始通道数nn.Linear(in_channels // reduction_ratio, in_channels, bias=False),# Sigmoid将输出值归一化到[0,1],表示通道重要性权重nn.Sigmoid())def forward(self, x):"""参数:x: 输入特征图,形状为 [batch_size, channels, height, width]返回:加权后的特征图,形状不变"""batch_size, channels, height, width = x.size()# 1. 全局平均池化:[batch_size, channels, height, width] → [batch_size, channels, 1, 1]avg_pool_output = self.avg_pool(x)# 2. 展平为一维向量:[batch_size, channels, 1, 1] → [batch_size, channels]avg_pool_output = avg_pool_output.view(batch_size, channels)# 3. 通过全连接层学习通道权重:[batch_size, channels] → [batch_size, channels]channel_weights = self.fc(avg_pool_output)# 4. 重塑为二维张量:[batch_size, channels] → [batch_size, channels, 1, 1]channel_weights = channel_weights.view(batch_size, channels, 1, 1)# 5. 将权重应用到原始特征图上(逐通道相乘)return x * channel_weights # 输出形状:[batch_size, channels, height, width]# 4. 模型的定义
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # ---------------------- 第一个卷积块 ----------------------self.conv1 = nn.Conv2d(3, 32, 3, padding=1)self.bn1 = nn.BatchNorm2d(32)self.relu1 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca1 = ChannelAttention(in_channels=32, reduction_ratio=16) self.pool1 = nn.MaxPool2d(2, 2) # ---------------------- 第二个卷积块 ----------------------self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca2 = ChannelAttention(in_channels=64, reduction_ratio=16) self.pool2 = nn.MaxPool2d(2) # ---------------------- 第三个卷积块 ----------------------self.conv3 = nn.Conv2d(64, 128, 3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()# 新增:插入通道注意力模块(SE模块)self.ca3 = ChannelAttention(in_channels=128, reduction_ratio=16) self.pool3 = nn.MaxPool2d(2) # ---------------------- 全连接层(分类器) ----------------------self.fc1 = nn.Linear(128 * 4 * 4, 512)self.dropout = nn.Dropout(p=0.5)self.fc2 = nn.Linear(512, 10)def forward(self, x):# ---------- 卷积块1处理 ----------x = self.conv1(x) x = self.bn1(x) x = self.relu1(x) x = self.ca1(x) # 应用通道注意力x = self.pool1(x) # ---------- 卷积块2处理 ----------x = self.conv2(x) x = self.bn2(x) x = self.relu2(x) x = self.ca2(x) # 应用通道注意力x = self.pool2(x) # ---------- 卷积块3处理 ----------x = self.conv3(x) x = self.bn3(x) x = self.relu3(x) x = self.ca3(x) # 应用通道注意力x = self.pool3(x) # ---------- 展平与全连接层 ----------x = x.view(-1, 128 * 4 * 4) x = self.fc1(x) x = self.relu3(x) x = self.dropout(x) x = self.fc2(x) return x # 重新初始化模型,包含通道注意力模块
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)# 早停机制实现if epoch == 0:best_acc = epoch_test_accpatience_counter = 0else:if epoch_test_acc > best_acc:best_acc = epoch_test_accpatience_counter = 0# 保存最佳模型torch.save(model.state_dict(), 'best_model.pth')else:patience_counter += 1if patience_counter >= 5: # 连续5个epoch测试准确率没有提升则停止训练print(f'Early stopping at epoch {epoch+1}, best accuracy: {best_acc:.2f}%')breakprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 50 # 增加训练轮次为了确保收敛
print("开始使用CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_cnn_model.pth')
# print("模型已保存为: cifar10_cnn_model.pth")我们关注的不只是精度的差异,还包含了同精度下训练时长的差异等,在大规模数据集上推理时长、训练时长都非常重要。因为资源是有限的。可视化部分同理,在训练完成后通过钩子函数取出权重or梯度,即可进行特征图的可视化、Grad-CAM可视化、注意力热图可视化
# 可视化空间注意力热力图(显示模型关注的图像区域)
def visualize_attention_map(model, test_loader, device, class_names, num_samples=3):"""可视化模型的注意力热力图,展示模型关注的图像区域"""model.eval() # 设置为评估模式with torch.no_grad():for i, (images, labels) in enumerate(test_loader):if i >= num_samples: # 只可视化前几个样本breakimages, labels = images.to(device), labels.to(device)# 创建一个钩子,捕获中间特征图activation_maps = []def hook(module, input, output):activation_maps.append(output.cpu())# 为最后一个卷积层注册钩子(获取特征图)hook_handle = model.conv3.register_forward_hook(hook)# 前向传播,触发钩子outputs = model(images)# 移除钩子hook_handle.remove()# 获取预测结果_, predicted = torch.max(outputs, 1)# 获取原始图像img = images[0].cpu().permute(1, 2, 0).numpy()# 反标准化处理img = img * np.array([0.2023, 0.1994, 0.2010]).reshape(1, 1, 3) + np.array([0.4914, 0.4822, 0.4465]).reshape(1, 1, 3)img = np.clip(img, 0, 1)# 获取激活图(最后一个卷积层的输出)feature_map = activation_maps[0][0].cpu() # 取第一个样本# 计算通道注意力权重(使用SE模块的全局平均池化)channel_weights = torch.mean(feature_map, dim=(1, 2)) # [C]# 按权重对通道排序sorted_indices = torch.argsort(channel_weights, descending=True)# 创建子图fig, axes = plt.subplots(1, 4, figsize=(16, 4))# 显示原始图像axes[0].imshow(img)axes[0].set_title(f'原始图像\n真实: {class_names[labels[0]]}\n预测: {class_names[predicted[0]]}')axes[0].axis('off')# 显示前3个最活跃通道的热力图for j in range(3):channel_idx = sorted_indices[j]# 获取对应通道的特征图channel_map = feature_map[channel_idx].numpy()# 归一化到[0,1]channel_map = (channel_map - channel_map.min()) / (channel_map.max() - channel_map.min() + 1e-8)# 调整热力图大小以匹配原始图像from scipy.ndimage import zoomheatmap = zoom(channel_map, (32/feature_map.shape[1], 32/feature_map.shape[2]))# 显示热力图axes[j+1].imshow(img)axes[j+1].imshow(heatmap, alpha=0.5, cmap='jet')axes[j+1].set_title(f'注意力热力图 - 通道 {channel_idx}')axes[j+1].axis('off')plt.tight_layout()plt.show()# 调用可视化函数
visualize_attention_map(model, test_loader, device, class_names, num_samples=3)相关文章:

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...
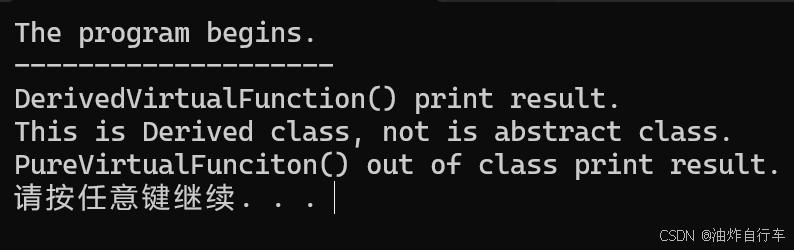
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...

springboot 日志类切面,接口成功记录日志,失败不记录
springboot 日志类切面,接口成功记录日志,失败不记录 自定义一个注解方法 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;/***…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...
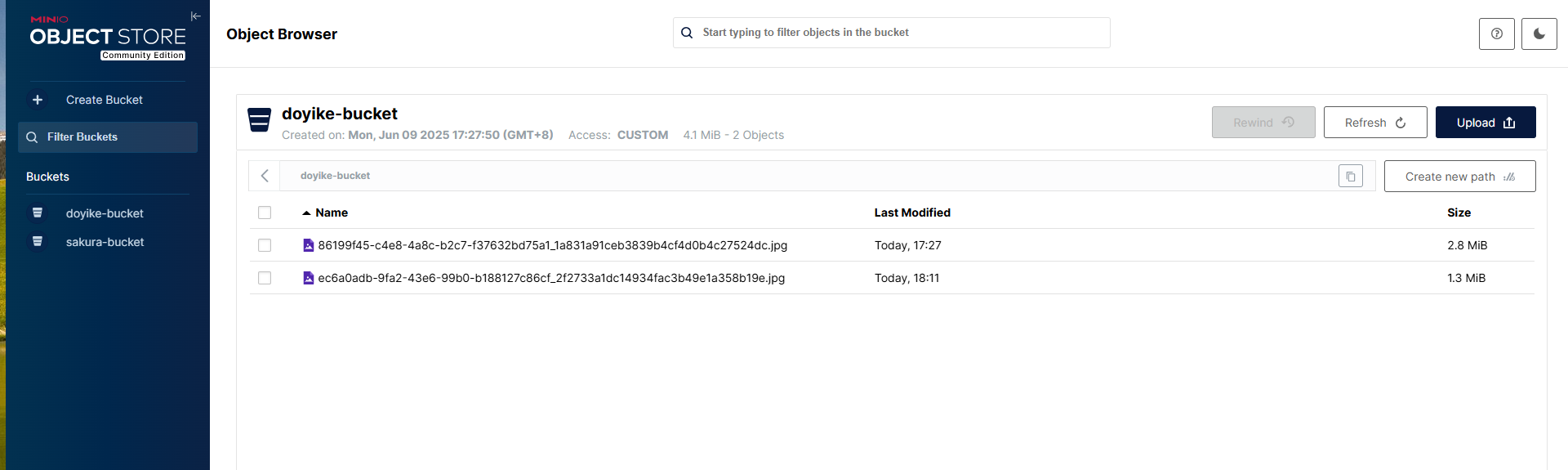
Linux部署私有文件管理系统MinIO
最近需要用到一个文件管理服务,但是又不想花钱,所以就想着自己搭建一个,刚好我们用的一个开源框架已经集成了MinIO,所以就选了这个 我这边对文件服务性能要求不是太高,单机版就可以 安装非常简单,几个命令就…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...

Vue 模板语句的数据来源
🧩 Vue 模板语句的数据来源:全方位解析 Vue 模板(<template> 部分)中的表达式、指令绑定(如 v-bind, v-on)和插值({{ }})都在一个特定的作用域内求值。这个作用域由当前 组件…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...

HTML前端开发:JavaScript 获取元素方法详解
作为前端开发者,高效获取 DOM 元素是必备技能。以下是 JS 中核心的获取元素方法,分为两大系列: 一、getElementBy... 系列 传统方法,直接通过 DOM 接口访问,返回动态集合(元素变化会实时更新)。…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...
)
uniapp 集成腾讯云 IM 富媒体消息(地理位置/文件)
UniApp 集成腾讯云 IM 富媒体消息全攻略(地理位置/文件) 一、功能实现原理 腾讯云 IM 通过 消息扩展机制 支持富媒体类型,核心实现方式: 标准消息类型:直接使用 SDK 内置类型(文件、图片等)自…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...
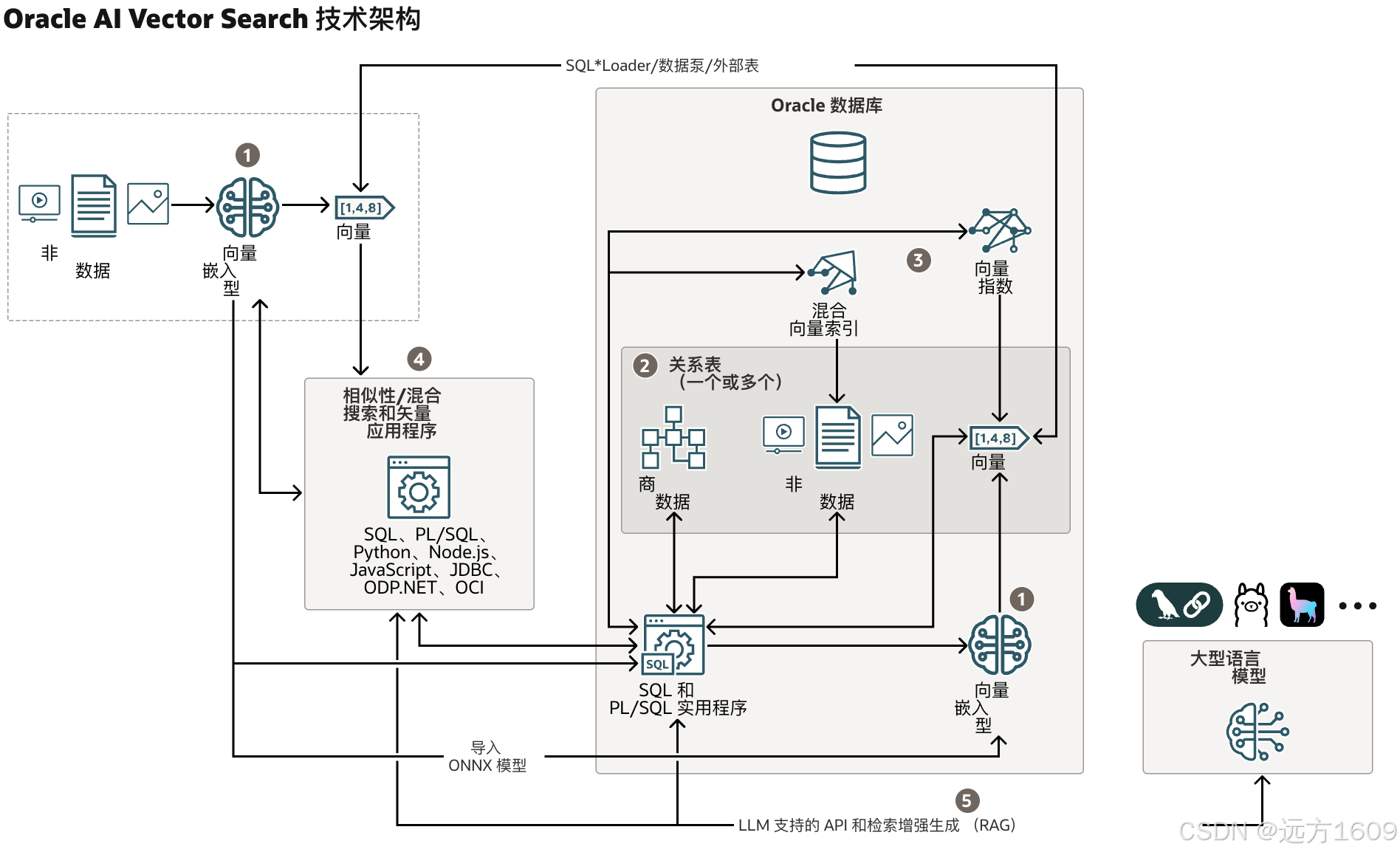
9-Oracle 23 ai Vector Search 特性 知识准备
很多小伙伴是不是参加了 免费认证课程(限时至2025/5/15) Oracle AI Vector Search 1Z0-184-25考试,都顺利拿到certified了没。 各行各业的AI 大模型的到来,传统的数据库中的SQL还能不能打,结构化和非结构的话数据如何和…...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...

SQL Server 触发器调用存储过程实现发送 HTTP 请求
文章目录 需求分析解决第 1 步:前置条件,启用 OLE 自动化方式 1:使用 SQL 实现启用 OLE 自动化方式 2:Sql Server 2005启动OLE自动化方式 3:Sql Server 2008启动OLE自动化第 2 步:创建存储过程第 3 步:创建触发器扩展 - 如何调试?第 1 步:登录 SQL Server 2008第 2 步…...
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...

DBLP数据库是什么?
DBLP(Digital Bibliography & Library Project)Computer Science Bibliography是全球著名的计算机科学出版物的开放书目数据库。DBLP所收录的期刊和会议论文质量较高,数据库文献更新速度很快,很好地反映了国际计算机科学学术研…...

redis和redission的区别
Redis 和 Redisson 是两个密切相关但又本质不同的技术,它们扮演着完全不同的角色: Redis: 内存数据库/数据结构存储 本质: 它是一个开源的、高性能的、基于内存的 键值存储数据库。它也可以将数据持久化到磁盘。 核心功能: 提供丰…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...

Xela矩阵三轴触觉传感器的工作原理解析与应用场景
Xela矩阵三轴触觉传感器通过先进技术模拟人类触觉感知,帮助设备实现精确的力测量与位移监测。其核心功能基于磁性三维力测量与空间位移测量,能够捕捉多维触觉信息。该传感器的设计不仅提升了触觉感知的精度,还为机器人、医疗设备和制造业的智…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...

Docker拉取MySQL后数据库连接失败的解决方案
在使用Docker部署MySQL时,拉取并启动容器后,有时可能会遇到数据库连接失败的问题。这种问题可能由多种原因导致,包括配置错误、网络设置问题、权限问题等。本文将分析可能的原因,并提供解决方案。 一、确认MySQL容器的运行状态 …...

vue3 daterange正则踩坑
<el-form-item label"空置时间" prop"vacantTime"> <el-date-picker v-model"form.vacantTime" type"daterange" start-placeholder"开始日期" end-placeholder"结束日期" clearable :editable"fal…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...