python爬虫——气象数据爬取
一、导入库与全局配置
python
运行
import json
import datetime
import time
import requests
from sqlalchemy import create_engine
import csv
import pandas as pd
作用:
- 引入数据解析、网络请求、时间处理、数据库操作等所需库。
requests:发送 HTTP 请求获取网页数据。sqlalchemy:连接和操作 MySQL 数据库。pandas:处理 CSV 文件和数据清洗。
潜在问题:
- 未处理
requests的超时(可能导致程序卡死)。 - 数据库密码直接写死在代码中(存在安全风险)。
二、核心爬取函数 scraw(code)
python
运行
def scraw(code):url = f'http://www.nmc.cn/rest/weather?stationid={code}&_=1675259309000'response = requests.get(url, headers=headers)try:data = json.loads(response.text)info = data['data']passed = data['data']['passedchart']real = data['data']['real']tempchart = data['data']['tempchart']predict = data['data']['predict']['detail']# 解析24小时天气数据并写入CSVfor i in passed:csv.writer(csv_obj).writerow([names[inx], ...])# 解析实时天气数据并写入CSVcsv.writer(csv_obj2).writerow([names[inx], ...])# 解析7天温度数据并写入CSVfor i in tempchart:csv.writer(csv_obj3).writerow([names[inx], ...])# 解析预报数据并写入CSVfor i in predict:csv.writer(csv_obj4).writerow([names[inx], ...])except:print(f'{code}爬取失败')
功能拆解:
-
URL 构造:
- 拼接城市代码(
stationid)和时间戳参数(_),可能用于防止缓存。 - 问题:时间戳硬编码(
1675259309000),未动态生成,可能导致请求失效。
- 拼接城市代码(
-
数据解析:
- 通过
json.loads()解析 JSON 响应,提取passedchart(历史数据)、real(实时数据)等字段。 - 风险:假设 JSON 结构固定,若网站接口变更会导致解析失败(需添加容错处理)。
- 通过
-
CSV 写入:
- 循环写入不同类型数据到 4 个 CSV 文件(
data24h.csv、dataday.csv等)。 - 问题:
names[inx]依赖全局变量inx,多线程环境下可能引发线程安全问题。
- 循环写入不同类型数据到 4 个 CSV 文件(
三、降雨量爬取函数 scraw_rain24h() & scraw_rain1h()
python
运行
def scraw_rain24h():url = f'http://www.nmc.cn/rest/real/rain/hour24/{date}?_={times}'csv_obj5 = open('csv/rain24h.csv', 'w', ...)response = requests.get(url, headers=headers)data = json.loads(response.text)raindata = data['data']['data']for i in raindata:csv.writer(csv_obj5).writerow([i[0]+i[1], i[5]])csv_obj5.close()def scraw_rain1h():# 逻辑与scraw_rain24h()类似,仅URL和CSV文件不同
关键细节:
- URL 参数:
date由主程序生成(格式为YYYYMMDD08),times为当前时间戳(动态生成)。 - 数据结构:降雨量数据通过
i[0]+i[1]拼接城市名(假设i[0]为省,i[1]为市),i[5]为降雨量。 - 问题:未处理城市名重复或异常数据(如
i[0]或i[1]为空)。
四、数据库存储函数 save()
python
运行
def save():DB_STRING = 'mysql+pymysql://root:mysql@127.0.0.1:3306/tianqi'engine = create_engine(DB_STRING)# 读取CSV文件df = pd.read_csv("csv/data24h.csv")df2 = pd.read_csv("csv/dataday.csv")# ... 读取其他CSV文件# 数据清洗df = df.drop('24h降雨量', axis=1)df2 = df2[df2['体感温度'] != 9999]df3 = df3[df3['最高温度'] != 9999]# 写入数据库df.to_sql('24h', con=engine, if_exists='replace', index=False)# ... 写入其他DataFrame
功能说明:
-
数据库连接:
- 使用 SQLAlchemy 创建数据库引擎,连接本地 MySQL 的
tianqi数据库。 - 风险:密码
mysql硬编码,需通过环境变量或配置文件管理。
- 使用 SQLAlchemy 创建数据库引擎,连接本地 MySQL 的
-
数据清洗:
- 删除无效列(如
24h降雨量)和值为9999的行(假设9999为错误值)。 - 问题:清洗逻辑分散,未统一处理(如其他 CSV 文件可能也存在无效值)。
- 删除无效列(如
-
数据写入:
- 使用
to_sql批量写入,if_exists='replace'会覆盖表数据(可能导致历史数据丢失)。
- 使用
五、主程序逻辑(if __name__ == '__main__')
python
运行
if __name__ == '__main__':df = pd.read_csv('csv/citycode.csv')codes = df.code.tolist()names = df.城市.tolist()date = time.strftime('%Y%m%d', time.gmtime()) + '08'times = int(time.time() * 1000)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; ...)'}# 初始化CSV文件csv_obj = open('csv/data24h.csv', 'w', ...)# ... 初始化其他CSV文件for inx, i in enumerate(codes):scraw(i)print(f"{names[inx]}爬取完毕")# 关闭CSV文件csv_obj.close()# ... 关闭其他CSV文件scraw_rain24h()scraw_rain1h()save()
流程分析:
-
准备阶段:
- 读取城市代码表(
citycode.csv),获取codes(城市代码)和names(城市名)。 - 生成
date(当前日期 +08,可能为北京时间时区调整)和times(毫秒级时间戳)。
- 读取城市代码表(
-
爬取阶段:
- 循环调用
scraw(i)爬取每个城市的数据,依赖全局变量inx和names。 - 问题:未控制爬取频率(可能触发网站反爬机制),建议添加
time.sleep()。
- 循环调用
-
收尾阶段:
- 关闭 CSV 文件句柄(需确保在异常情况下也能关闭,建议用
with语句)。 - 爬取降雨量数据并保存到数据库。
- 关闭 CSV 文件句柄(需确保在异常情况下也能关闭,建议用
六、整体问题总结与改进方向
| 模块 | 问题 | 改进建议 |
|---|---|---|
| 爬取逻辑 | 硬编码时间戳、未处理反爬 | 动态生成时间戳,添加请求头(如Referer)、限制爬取频率 |
| 异常处理 | 全局except捕获,无详细日志 | 细化异常类型,使用logging模块记录错误信息 |
| 资源管理 | CSV 文件未用with语句,可能泄漏资源 | 改用with open(...) as f管理文件 |
| 数据安全 | 数据库密码硬编码 | 使用环境变量(如os.getenv())或配置文件 |
| 代码可维护性 | 全局变量耦合严重,逻辑分散 | 将功能封装为类,分离爬取、解析、存储逻辑 |
| 扩展性 | 难以为新城市或数据类型扩展 | 设计可配置的爬取规则和字段映射 |
通过分块优化,可显著提升代码的健壮性、可维护性和安全性,同时降低对目标网站的影响。
完整代码:
import json
import datetime
import time
import requests
from sqlalchemy import create_engine
import csv
import pandas as pddef scraw(code):# 发送 HTTP 请求,获取网页内容url = f'http://www.nmc.cn/rest/weather?stationid={code}&_=1675259309000'response = requests.get(url, headers=headers)try:data = json.loads(response.text)info = data['data']# 24小时天气情况passed = data['data']['passedchart']# 一天real = data['data']['real']# 最近七天最高低温度tempchart = data['data']['tempchart']# 预测predict = data['data']['predict']['detail']for i in passed:humidity = i['humidity'] # 相对湿度pressure = i['pressure'] # 空气压力rain1h = i['rain1h'] #rain24h = i['rain24h'] #temperature = i['temperature'] # 温度windDirection = i['windDirection']windSpeed = i['windSpeed']time = i['time']tempDiff = i['tempDiff'] # 体感温度csv.writer(csv_obj).writerow([names[inx],humidity, pressure, rain1h, rain24h, temperature, windDirection, windSpeed, time, tempDiff])csv.writer(csv_obj2).writerow([names[inx],datetime.datetime.now().date(), real['weather']['airpressure'], real['weather']['feelst'],real['weather']['humidity'], real['weather']['info'], real['weather']['rain'], real['weather']['temperature'],real['wind']['direct'], real['wind']['power'], real['wind']['speed']])for i in tempchart:time = i['time']max_temp = i['max_temp']min_temp = i['min_temp']csv.writer(csv_obj3).writerow([names[inx],time, max_temp, min_temp])for i in predict:date = i['date']temperatureday = i['day']['weather']['temperature']temperaturenight = i['night']['weather']['temperature']wind = i['day']['wind']['direct']csv.writer(csv_obj4).writerow([names[inx],date, temperatureday, temperaturenight, wind])except:print(f'{code}爬取失败')def scraw_rain24h():url = f'http://www.nmc.cn/rest/real/rain/hour24/{date}?_={times}'csv_obj5 = open('csv/rain24h.csv', 'w', encoding="utf-8",newline='')response = requests.get(url, headers=headers)data = json.loads(response.text)print(data)raindata = data['data']['data']csv.writer(csv_obj5).writerow(["城市",'降雨量'])for i in raindata:csv.writer(csv_obj5).writerow([i[0] +i[1], i[5]])print('爬取数据完毕')csv_obj5.close()def scraw_rain1h():url = f'http://www.nmc.cn/rest/real/rain/hour1/{date}?_={times}'csv_obj6 = open('csv/rain1h.csv', 'w', encoding="utf-8", newline='')response = requests.get(url, headers=headers)data = json.loads(response.text)raindata = data['data']['data']csv.writer(csv_obj6).writerow(["城市", '降雨量'])for i in raindata:csv.writer(csv_obj6).writerow([i[0] + i[1], i[5]])print('爬取数据完毕')csv_obj6.close()def save():# 存入数据库DB_STRING = 'mysql+pymysql://root:mysql@127.0.0.1:3306/tianqi'engine = create_engine(DB_STRING)df = pd.read_csv("csv/data24h.csv")df2 = pd.read_csv("csv/dataday.csv")df3 = pd.read_csv("csv/tempchart.csv")df4 = pd.read_csv("csv/predict.csv")df5 = pd.read_csv("csv/rain24h.csv")df6 = pd.read_csv("csv/rain1h.csv")#删除不正常值# 删除部分列值等于9999的行df = df.drop('24h降雨量',axis=1)df2 = df2[df2['体感温度'] != 9999]df3 = df3[df3['最高温度'] != 9999]df.to_sql('24h', con=engine, if_exists='replace',index=False)df2.to_sql('day', con=engine, if_exists='replace',index=False)df3.to_sql('tempchart', con=engine, if_exists='replace',index=False)df4.to_sql('predict', con=engine, if_exists='replace',index=False)df5.to_sql('rain24h', con=engine, if_exists='replace',index=False)df6.to_sql('rain1h', con=engine, if_exists='replace',index=False)print('保存数据库完毕')if __name__ == '__main__':df = pd.read_csv('csv/citycode.csv')codes = df.code.tolist()names = df.城市.tolist()#北京# codes = [54511]# names = ['北京']date = time.strftime('%Y%m%d', time.gmtime()) +'08'times = int(time.time() * 1000)# # 设置请求头部信息,避免被识别为爬虫headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}csv_obj = open('csv/data24h.csv', 'w', encoding="utf-8",newline='')csv_obj2 = open('csv/dataday.csv', 'w', encoding="utf-8", newline='')csv_obj3 = open('csv/tempchart.csv', 'w', encoding="utf-8", newline='')csv_obj4 = open('csv/predict.csv', 'w', encoding="utf-8", newline='')csv.writer(csv_obj).writerow(["城市","相对湿度", "气压", "一小时降雨量","24h降雨量", "温度", "风向", "风速","时间",'体感温度'])csv.writer(csv_obj2).writerow(["城市","日期","气压", '体感温度',"相对湿度","天气情况","一小时降雨量","温度", "风向", "风强度","风速"])csv.writer(csv_obj3).writerow(["城市","日期","最高温度", '最低温度'])csv.writer(csv_obj4).writerow(["城市","日期","白天温度", '夜晚温度',"风向"])for inx,i in enumerate(codes):scraw(i)print(f"{names[inx]}爬取完毕")csv_obj.close()csv_obj2.close()csv_obj3.close()csv_obj4.close()scraw_rain24h()scraw_rain1h()save()
import csv
import json
import requests
# 设置请求头部信息,避免被识别为爬虫headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}# 发送 HTTP 请求,获取网页内容url = 'http://www.nmc.cn/rest/province/all?_=1678112903659'
response = requests.get(url, headers=headers)
data = json.loads(response.text)
csv_obj = open('allcsv/citycode.csv', 'w', encoding="utf-8", newline='')
csv.writer(csv_obj).writerow(['城市','code'])
for i in data:code = i['code']url = f'http://www.nmc.cn/rest/province/{code}?_=1677854971362'response = requests.get(url, headers=headers)data = json.loads(response.text)for x in data:csv.writer(csv_obj).writerow([x['city'], x['code']])csv_obj.close()相关文章:

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...
给网站添加live2d看板娘
给网站添加live2d看板娘 参考文献: stevenjoezhang/live2d-widget: 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platformEikanya/Live2d-model: Live2d model collectionzenghongtu/live2d-model-assets 前言 网站环境如下,文章也主…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

深入理解Optional:处理空指针异常
1. 使用Optional处理可能为空的集合 在Java开发中,集合判空是一个常见但容易出错的场景。传统方式虽然可行,但存在一些潜在问题: // 传统判空方式 if (!CollectionUtils.isEmpty(userInfoList)) {for (UserInfo userInfo : userInfoList) {…...
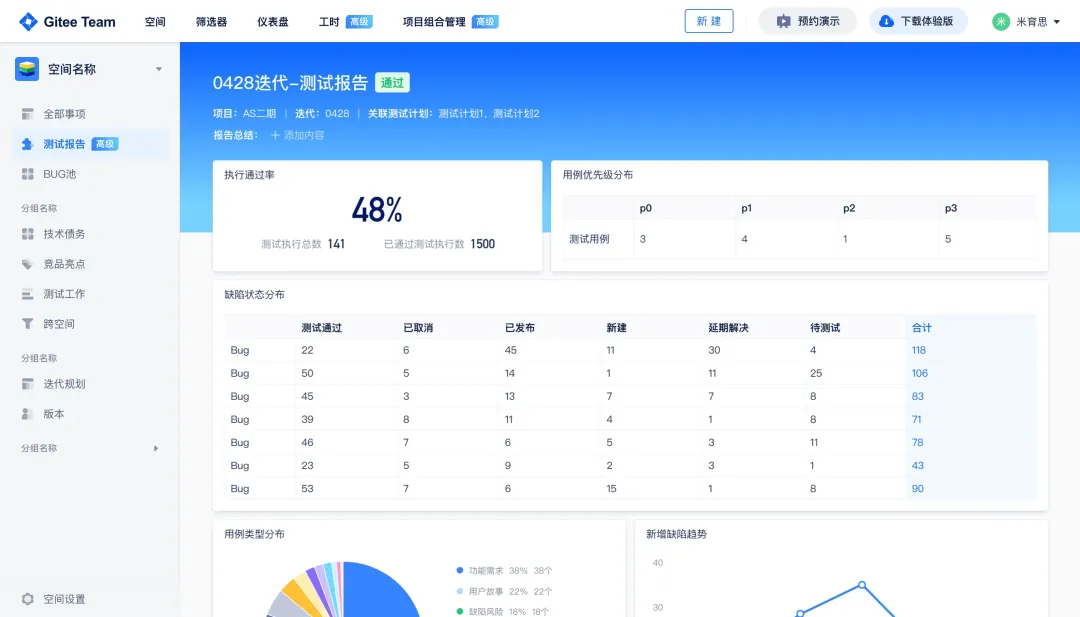
从“安全密码”到测试体系:Gitee Test 赋能关键领域软件质量保障
关键领域软件测试的"安全密码":Gitee Test如何破解行业痛点 在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的"神经中枢"。从国防军工到能源电力,从金融交易到交通管控,这些关乎国计民生的关键领域…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...

Spring AI Chat Memory 实战指南:Local 与 JDBC 存储集成
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和…...

适应性Java用于现代 API:REST、GraphQL 和事件驱动
在快速发展的软件开发领域,REST、GraphQL 和事件驱动架构等新的 API 标准对于构建可扩展、高效的系统至关重要。Java 在现代 API 方面以其在企业应用中的稳定性而闻名,不断适应这些现代范式的需求。随着不断发展的生态系统,Java 在现代 API 方…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...
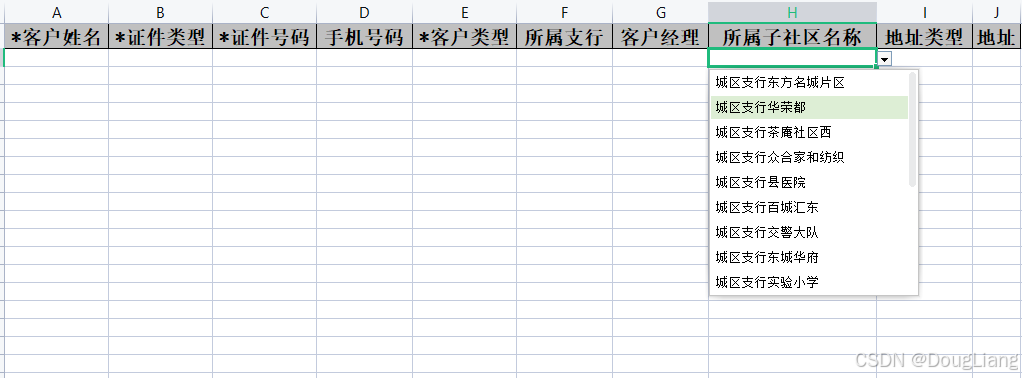
关于easyexcel动态下拉选问题处理
前些日子突然碰到一个问题,说是客户的导入文件模版想支持部分导入内容的下拉选,于是我就找了easyexcel官网寻找解决方案,并没有找到合适的方案,没办法只能自己动手并分享出来,针对Java生成Excel下拉菜单时因选项过多导…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...

掌握 HTTP 请求:理解 cURL GET 语法
cURL 是一个强大的命令行工具,用于发送 HTTP 请求和与 Web 服务器交互。在 Web 开发和测试中,cURL 经常用于发送 GET 请求来获取服务器资源。本文将详细介绍 cURL GET 请求的语法和使用方法。 一、cURL 基本概念 cURL 是 "Client URL" 的缩写…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...
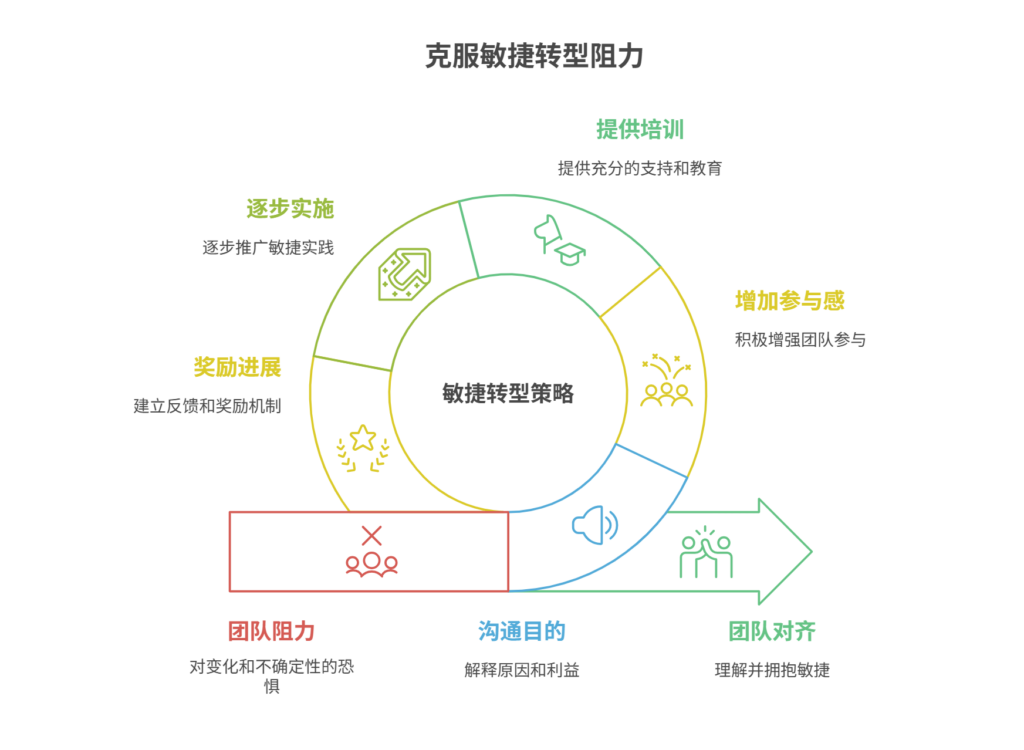
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...
 error)
【前端异常】JavaScript错误处理:分析 Uncaught (in promise) error
在前端开发中,JavaScript 异常是不可避免的。随着现代前端应用越来越多地使用异步操作(如 Promise、async/await 等),开发者常常会遇到 Uncaught (in promise) error 错误。这个错误是由于未正确处理 Promise 的拒绝(r…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...