BLEU评分:机器翻译质量评估的黄金标准
BLEU评分:机器翻译质量评估的黄金标准
1. 引言
在自然语言处理(NLP)领域,衡量一个机器翻译模型的性能至关重要。BLEU (Bilingual Evaluation Understudy) 作为一种自动化评估指标,自2002年由IBM的Kishore Papineni等人提出以来,已成为机器翻译系统评估的事实标准。对于从事NLP开发的程序员而言,理解BLEU的工作原理不仅有助于评估翻译质量,还能指导模型优化方向。
本文将深入剖析BLEU评分的理论基础、计算方法、实现细节,并通过具体的代码示例展示其实际应用,同时探讨其局限性和替代方案。
2. BLEU的基本原理
BLEU评分的核心思想是比较机器翻译输出与一个或多个参考翻译之间的相似度。其基本假设是:好的翻译应该与人工翻译在用词和短语使用上有较高的重合度。
2.1 n-gram精确度
BLEU的基础是n-gram精确度,即衡量机器翻译中的n个连续词组在参考翻译中出现的比例。其中:
- 1-gram (unigram) 对应单个词的匹配
- 2-gram (bigram) 对应两个连续词的匹配
- 3-gram (trigram) 对应三个连续词的匹配
- 4-gram 对应四个连续词的匹配
通常,BLEU结合了1-gram到4-gram的精确度,以平衡考虑词汇准确性和语法结构。
2.2 简单精确度的缺陷与修正
初始的精确度计算存在一个明显问题:如果机器翻译重复使用高频词,可能会不合理地获得高分。例如,假设参考翻译包含两次"the",而机器翻译包含七次"the",简单计算会认为所有七次"the"都是匹配的。
为解决这个问题,BLEU引入了**裁剪计数(Clipped Count)**概念:对于每个n-gram,其匹配次数上限为该n-gram在参考翻译中出现的最大次数。
2.3 短句惩罚
另一个问题是:极短的翻译可能获得不合理的高精确度。为抑制这种情况,BLEU引入了简短惩罚(Brevity Penalty, BP),当译文长度短于参考翻译时,会给予惩罚。
3. BLEU的数学表达
3.1 修正的精确度计算
对于n-gram精确度,其数学表达式为:
P n = ∑ C ∈ { C a n d i d a t e s } ∑ n - g r a m ∈ C C o u n t c l i p ( n - g r a m ) ∑ C ′ ∈ { C a n d i d a t e s } ∑ n - g r a m ′ ∈ C ′ C o u n t ( n - g r a m ′ ) P_n = \frac{\sum_{C \in \{Candidates\}} \sum_{n\text{-}gram \in C} Count_{clip}(n\text{-}gram)}{\sum_{C' \in \{Candidates\}} \sum_{n\text{-}gram' \in C'} Count(n\text{-}gram')} Pn=∑C′∈{Candidates}∑n-gram′∈C′Count(n-gram′)∑C∈{Candidates}∑n-gram∈CCountclip(n-gram)
其中:
- C o u n t c l i p ( n - g r a m ) Count_{clip}(n\text{-}gram) Countclip(n-gram) 是裁剪后的n-gram计数
- C o u n t ( n - g r a m ′ ) Count(n\text{-}gram') Count(n-gram′) 是候选翻译中n-gram的总数
3.2 短句惩罚因子
B P = { 1 if c > r e 1 − r / c if c ≤ r BP = \begin{cases} 1 & \text{if } c > r \\ e^{1-r/c} & \text{if } c \leq r \end{cases} BP={1e1−r/cif c>rif c≤r
其中:
- c c c 是候选翻译的长度
- r r r 是参考翻译的长度(如有多个参考翻译,取最接近候选翻译长度的那个)
3.3 BLEU分数计算
最终的BLEU分数结合了多个n-gram的精确度,通常为1-gram到4-gram的几何平均值:
B L E U = B P ⋅ exp ( ∑ n = 1 N w n log P n ) BLEU = BP \cdot \exp\left(\sum_{n=1}^{N} w_n \log P_n\right) BLEU=BP⋅exp(n=1∑NwnlogPn)
其中:
- N N N 通常取4
- w n w_n wn 是各n-gram精确度的权重,一般情况下均为 1 N \frac{1}{N} N1
4. Python实现BLEU评分
以下是使用NLTK库实现BLEU评分计算的示例:
import nltk
from nltk.translate.bleu_score import sentence_bleu, corpus_bleu, SmoothingFunction# 确保已下载必要的NLTK数据
try:nltk.data.find('tokenizers/punkt')
except LookupError:nltk.download('punkt')# 示例:计算单句的BLEU评分
def calculate_sentence_bleu(reference, candidate):# 分词处理reference_tokens = [nltk.word_tokenize(reference)]candidate_tokens = nltk.word_tokenize(candidate)# 使用平滑函数避免零精确度情况smoothie = SmoothingFunction().method1# 计算不同n-gram的BLEU分数bleu1 = sentence_bleu(reference_tokens, candidate_tokens, weights=(1, 0, 0, 0), smoothing_function=smoothie)bleu2 = sentence_bleu(reference_tokens, candidate_tokens, weights=(0.5, 0.5, 0, 0), smoothing_function=smoothie)bleu3 = sentence_bleu(reference_tokens, candidate_tokens, weights=(0.33, 0.33, 0.33, 0), smoothing_function=smoothie)bleu4 = sentence_bleu(reference_tokens, candidate_tokens, weights=(0.25, 0.25, 0.25, 0.25), smoothing_function=smoothie)return {'bleu1': bleu1,'bleu2': bleu2,'bleu3': bleu3,'bleu4': bleu4}# 示例:计算语料库的BLEU评分
def calculate_corpus_bleu(references, candidates):# 参考翻译列表,每个样本可能有多个参考翻译references_tokenized = [[nltk.word_tokenize(ref) for ref in refs] for refs in references]# 候选翻译列表candidates_tokenized = [nltk.word_tokenize(candidate) for candidate in candidates]# 使用平滑函数smoothie = SmoothingFunction().method1# 计算BLEU-4分数(同时考虑1-gram到4-gram)bleu_score = corpus_bleu(references_tokenized, candidates_tokenized, weights=(0.25, 0.25, 0.25, 0.25),smoothing_function=smoothie)return bleu_score# 使用示例
if __name__ == "__main__":# 单句示例reference = "The cat is sitting on the mat."candidate1 = "The cat sits on the mat."candidate2 = "On the mat there is a cat."print("Example 1 - Similar translation:")results1 = calculate_sentence_bleu(reference, candidate1)print(f"BLEU-1: {results1['bleu1']:.4f}")print(f"BLEU-2: {results1['bleu2']:.4f}")print(f"BLEU-3: {results1['bleu3']:.4f}")print(f"BLEU-4: {results1['bleu4']:.4f}")print("\nExample 2 - Different word order:")results2 = calculate_sentence_bleu(reference, candidate2)print(f"BLEU-1: {results2['bleu1']:.4f}")print(f"BLEU-2: {results2['bleu2']:.4f}")print(f"BLEU-3: {results2['bleu3']:.4f}")print(f"BLEU-4: {results2['bleu4']:.4f}")# 语料库示例references = [["The cat is sitting on the mat."],["He eats fish for breakfast."],["The sky is blue and the clouds are white."]]candidates = ["The cat sits on the mat.","Fish is eaten by him for breakfast.","The blue sky has white clouds."]print("\nCorpus BLEU score:")corpus_score = calculate_corpus_bleu(references, candidates)print(f"BLEU: {corpus_score:.4f}")
5. BLEU评分的自定义实现
为了更深入理解BLEU的内部工作机制,以下是一个简化的BLEU实现(不依赖NLTK):
import math
from collections import Counterdef count_ngrams(sentence, n):"""计算句子中所有n-gram及其出现次数"""tokens = sentence.split()ngrams = [tuple(tokens[i:i+n]) for i in range(len(tokens)-n+1)]return Counter(ngrams)def modified_precision(references, candidate, n):"""计算n-gram修正精确度"""# 候选翻译中的n-gram计数candidate_ngrams = count_ngrams(candidate, n)# 如果候选翻译没有n-gram,返回0if not candidate_ngrams:return 0# 计算每个参考翻译中n-gram的最大出现次数max_ref_counts = Counter()for reference in references:ref_ngrams = count_ngrams(reference, n)for ngram, count in ref_ngrams.items():max_ref_counts[ngram] = max(max_ref_counts.get(ngram, 0), count)# 计算裁剪后的匹配计数clipped_counts = {ngram: min(count, max_ref_counts.get(ngram, 0)) for ngram, count in candidate_ngrams.items()}# 总的裁剪计数和候选翻译中n-gram总数numerator = sum(clipped_counts.values())denominator = sum(candidate_ngrams.values())return numerator / denominator if denominator > 0 else 0def brevity_penalty(references, candidate):"""计算简短惩罚"""candidate_length = len(candidate.split())reference_lengths = [len(reference.split()) for reference in references]# 找到最接近候选翻译长度的参考翻译长度closest_ref_length = min(reference_lengths, key=lambda x: abs(x - candidate_length))# 计算BPif candidate_length > closest_ref_length:return 1else:return math.exp(1 - closest_ref_length / candidate_length) if candidate_length > 0 else 0def bleu_score(references, candidate, weights=(0.25, 0.25, 0.25, 0.25)):"""计算BLEU评分"""# 计算各n-gram精确度precisions = [modified_precision(references, candidate, n+1) for n in range(len(weights))]# 对精确度求加权几何平均if min(precisions) > 0:p_log_sum = sum(w * math.log(p) for w, p in zip(weights, precisions))geo_mean = math.exp(p_log_sum)else:geo_mean = 0# 计算简短惩罚bp = brevity_penalty(references, candidate)return bp * geo_mean# 使用示例
if __name__ == "__main__":references = ["The cat is sitting on the mat."]candidate = "The cat sits on the mat."# 计算BLEU-4分数score = bleu_score(references, candidate)print(f"Custom BLEU implementation score: {score:.4f}")# 计算各n-gram精确度for n in range(1, 5):precision = modified_precision(references, candidate, n)print(f"{n}-gram precision: {precision:.4f}")
6. BLEU评分的实际应用
6.1 模型评估与比较
BLEU最常见的应用是评估和比较不同机器翻译模型的性能。在以下场景中尤为重要:
- 模型开发:跟踪模型迭代过程中的性能变化
- 模型比较:客观评估不同翻译系统的优劣
- 超参数调优:在不同超参数配置下评估模型性能
- 学术对比:为论文提供标准化的评估指标
6.2 集成到训练流程
在神经机器翻译模型的训练过程中,可以将BLEU评分集成到验证流程中:
import torch
from torch.utils.data import DataLoader
from transformers import MarianMTModel, MarianTokenizer
from nltk.translate.bleu_score import corpus_bleu, SmoothingFunctiondef evaluate_model(model, dataloader, tokenizer, device):model.eval()references_all = []hypotheses_all = []with torch.no_grad():for batch in dataloader:# 获取源语言输入和目标语言参考翻译source_ids = batch["input_ids"].to(device)source_mask = batch["attention_mask"].to(device)target_texts = batch["target_texts"]# 生成翻译outputs = model.generate(input_ids=source_ids,attention_mask=source_mask,max_length=128,num_beams=5,early_stopping=True)# 解码生成的ID序列为文本hypotheses = [tokenizer.decode(output, skip_special_tokens=True) for output in outputs]# 收集参考翻译和模型生成的翻译for target, hyp in zip(target_texts, hypotheses):references_all.append([target.split()])hypotheses_all.append(hyp.split())# 计算BLEU分数smoothie = SmoothingFunction().method1bleu = corpus_bleu(references_all, hypotheses_all, weights=(0.25, 0.25, 0.25, 0.25),smoothing_function=smoothie)return bleu# 在训练循环中使用
def train_loop(model, train_loader, val_loader, optimizer, num_epochs, device):best_bleu = 0.0tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")for epoch in range(num_epochs):model.train()# 训练代码省略...# 评估当前模型bleu_score = evaluate_model(model, val_loader, tokenizer, device)print(f"Epoch {epoch+1}, BLEU: {bleu_score:.4f}")# 保存最佳模型if bleu_score > best_bleu:best_bleu = bleu_scoretorch.save(model.state_dict(), "best_translation_model.pt")print(f"New best BLEU score: {best_bleu:.4f}, model saved.")
7. BLEU的局限性
尽管BLEU被广泛采用,但它存在一些内在局限性:
7.1 语义理解缺失
BLEU仅基于n-gram重叠度,不考虑语义等同性。例如,以下两个句子意思相近但BLEU分数可能较低:
- “The economy is growing rapidly.”
- “Economic growth is accelerating.”
7.2 语法结构不敏感
BLEU对语法结构变化敏感度不够。例如,被动语态转换可能导致分数显著降低,即使意思保持不变。
7.3 适用于语言对的差异
BLEU在不同语言对之间的表现不一致。特别是对于与英语结构差异较大的语言(如中文、日语),BLEU可能不够准确。
7.4 与人类判断的相关性有限
研究显示,BLEU与人类评判的相关性在某些情况下可能较弱,特别是当翻译质量较高时。
8. BLEU的替代和扩展方案
为了克服BLEU的局限性,研究人员提出了多种替代评价指标:
- METEOR: 考虑同义词、词干和释义,与人类判断相关性更强
- TER (Translation Edit Rate): 衡量将候选翻译转换为参考翻译所需的最少编辑操作数
- chrF: 基于字符n-gram的F-score,对形态丰富的语言更友好
- BERT-Score: 利用预训练语言模型BERT的上下文嵌入来衡量语义相似度
- COMET: 基于神经网络的评估指标,结合了多种特征
9. 实际工程中的最佳实践
在实际工程应用中,建议采取以下最佳实践:
9.1 多指标结合评估
不要仅依赖BLEU,而应结合多种自动评价指标,如BLEU、METEOR、chrF等,以获得更全面的评估。
from nltk.translate.meteor_score import meteor_score
from nltk.translate.bleu_score import sentence_bleu
from nltk.translate.chrf_score import sentence_chrfdef comprehensive_evaluate(reference, candidate):# 分词ref_tokens = reference.split()cand_tokens = candidate.split()# 计算BLEUbleu = sentence_bleu([ref_tokens], cand_tokens)# 计算METEORmeteor = meteor_score([ref_tokens], cand_tokens)# 计算chrFchrf = sentence_chrf(reference, candidate)return {'bleu': bleu,'meteor': meteor,'chrf': chrf}
9.2 人工评估辅助
在关键决策点,结合有经验的评估人员进行人工评估,特别是在以下情况:
- 发布新版本翻译系统前
- 选择最终产品模型时
- 评估针对特定领域的翻译质量
9.3 领域适应性考虑
针对特定领域的翻译系统,可以调整BLEU的权重或选择更适合的评价指标:
- 技术文档翻译:强调术语准确性,可增加1-gram和2-gram的权重
- 文学翻译:强调流畅性,可增加3-gram和4-gram的权重
10. 结论
BLEU作为机器翻译评估的先驱指标,尽管存在局限性,但仍然是行业标准和研究基准。对于从事NLP的程序员,深入理解BLEU的工作原理有助于:
- 准确评估和比较翻译模型性能
- 指导模型优化和迭代方向
- 理解其局限性并适当补充其他评估方法
随着深度学习技术的发展,翻译质量评估方法也在不断演进。将BLEU与新兴的基于神经网络的评估方法结合使用,能够为机器翻译系统提供更全面、更准确的质量评估。
作为程序员,我们不仅要知道如何使用这些指标,还应理解它们的内部工作机制,以便在实际工程中做出合理的技术选择和权衡。
相关文章:

BLEU评分:机器翻译质量评估的黄金标准
BLEU评分:机器翻译质量评估的黄金标准 1. 引言 在自然语言处理(NLP)领域,衡量一个机器翻译模型的性能至关重要。BLEU (Bilingual Evaluation Understudy) 作为一种自动化评估指标,自2002年由IBM的Kishore Papineni等人提出以来,…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

MySQL 索引底层结构揭秘:B-Tree 与 B+Tree 的区别与应用
文章目录 一、背景知识:什么是 B-Tree 和 BTree? B-Tree(平衡多路查找树) BTree(B-Tree 的变种) 二、结构对比:一张图看懂 三、为什么 MySQL InnoDB 选择 BTree? 1. 范围查询更快 2…...

C语言中提供的第三方库之哈希表实现
一. 简介 前面一篇文章简单学习了C语言中第三方库(uthash库)提供对哈希表的操作,文章如下: C语言中提供的第三方库uthash常用接口-CSDN博客 本文简单学习一下第三方库 uthash库对哈希表的操作。 二. uthash库哈希表操作示例 u…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...
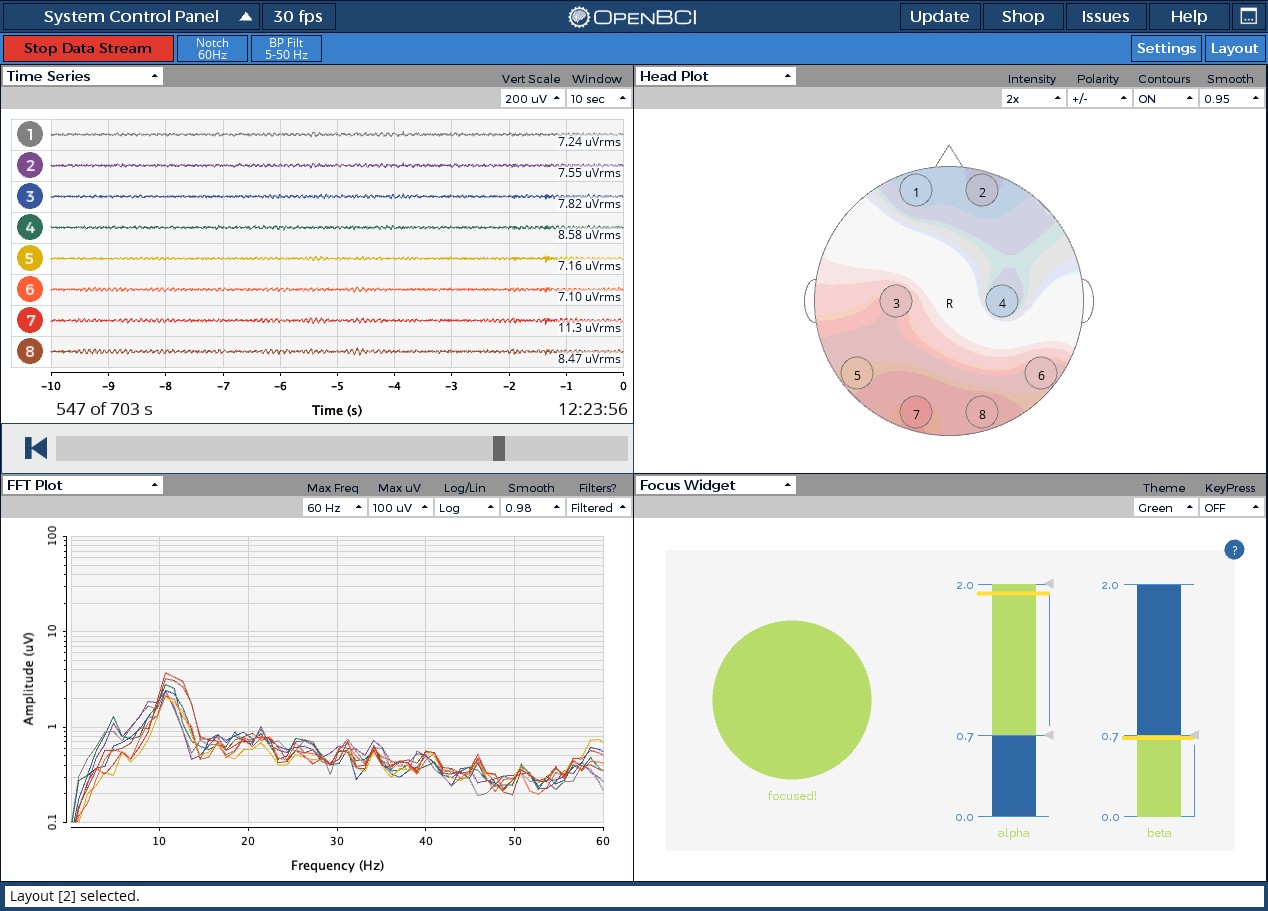
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...

Unity UGUI Button事件流程
场景结构 测试代码 public class TestBtn : MonoBehaviour {void Start(){var btn GetComponent<Button>();btn.onClick.AddListener(OnClick);}private void OnClick(){Debug.Log("666");}}当添加事件时 // 实例化一个ButtonClickedEvent的事件 [Formerl…...

Bean 作用域有哪些?如何答出技术深度?
导语: Spring 面试绕不开 Bean 的作用域问题,这是面试官考察候选人对 Spring 框架理解深度的常见方式。本文将围绕“Spring 中的 Bean 作用域”展开,结合典型面试题及实战场景,帮你厘清重点,打破模板式回答,…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...
淘宝扭蛋机小程序系统开发:打造互动性强的购物平台
淘宝扭蛋机小程序系统的开发,旨在打造一个互动性强的购物平台,让用户在购物的同时,能够享受到更多的乐趣和惊喜。 淘宝扭蛋机小程序系统拥有丰富的互动功能。用户可以通过虚拟摇杆操作扭蛋机,实现旋转、抽拉等动作,增…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...

根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的----NTFS源代码分析--重要
根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的 第一部分: 0: kd> g Breakpoint 9 hit Ntfs!ReadIndexBuffer: f7173886 55 push ebp 0: kd> kc # 00 Ntfs!ReadIndexBuffer 01 Ntfs!FindFirstIndexEntry 02 Ntfs!NtfsUpda…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...
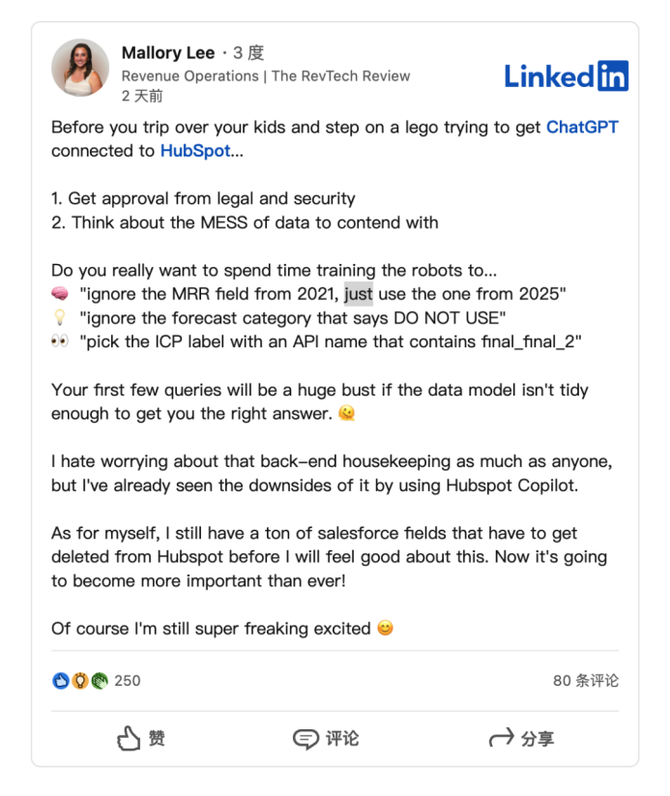
HubSpot推出与ChatGPT的深度集成引发兴奋与担忧
上周三,HubSpot宣布已构建与ChatGPT的深度集成,这一消息在HubSpot用户和营销技术观察者中引发了极大的兴奋,但同时也存在一些关于数据安全的担忧。 许多网络声音声称,这对SaaS应用程序和人工智能而言是一场范式转变。 但向任何技…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...
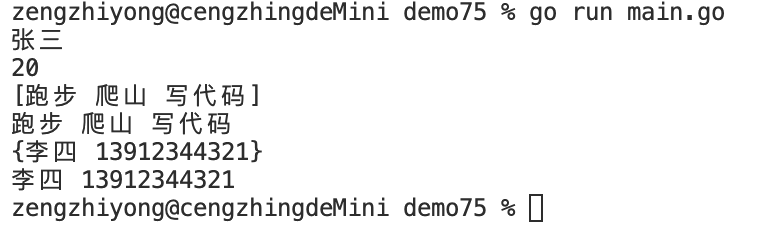
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...