selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】

文章目录
- selenium学习实战【Python爬虫】
- 一、声明
- 二、学习目标
- 三、安装依赖
- 3.1 安装selenium库
- 3.2 安装浏览器驱动
- 3.2.1 查看Edge版本
- 3.2.2 驱动安装
- 四、代码讲解
- 4.1 配置浏览器
- 4.2 加载更多
- 4.3 寻找内容
- 4.4 完整代码
- 五、报告文件爬取
- 5.1 提取下载链接
- 5.2 下载报告
- 六、总结
一、声明
本爬虫项目仅用于学习用途。严禁将本项目用于任何非法目的,包括但不限于恶意攻击网站、窃取用户隐私数据、破坏网站正常运营、商业侵权等行为。
二、学习目标
1.爬取网站链接:https://report.iresearch.cn;
2.爬取不付费的报告信息,标题、行业、作者、摘要和报告原件;
三、安装依赖
3.1 安装selenium库
只介绍主要的,别的库百度自行安装。
打开vscode终端,运行下面命令:
pip install -i https://pypi.douban.com/simple selenium
3.2 安装浏览器驱动
针对不同的浏览器,需要安装不同的驱动。下面列举了常见的浏览器与对应的驱动程序下载链接,部分网址需要 “科学上网” 才能打开哦(dddd)。
Firefox 浏览器驱动:https://github.com/mozilla/geckodriver/releases
Chrome 浏览器驱动:https://chromedriver.storage.googleapis.com/index.html
IE 浏览器驱动:http://selenium-release.storage.googleapis.com/index.html
Edge 浏览器驱动:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
PhantomJS 浏览器驱动:https://phantomjs.org/
Opera 浏览器驱动:https://github.com/operasoftware/operachromiumdriver/releases
我用的时Edge浏览器,所以安装Edge驱动
3.2.1 查看Edge版本
点击三个点,再点击设置
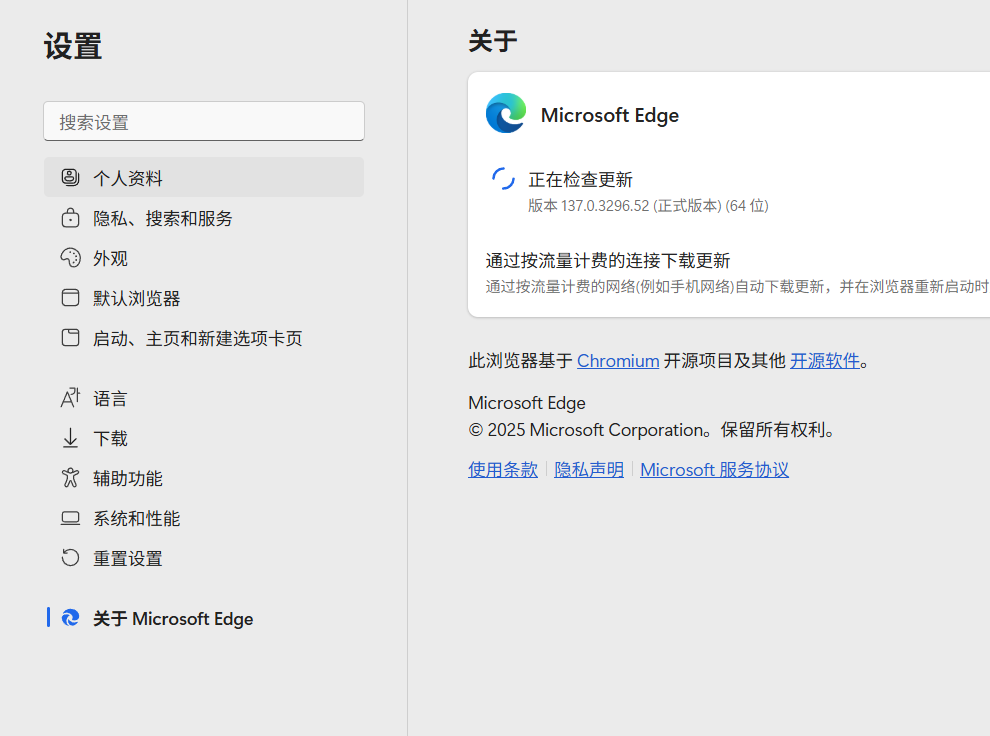
点击左侧最下面关于Edge
3.2.2 驱动安装
下载好双击安装就行。
四、代码讲解
4.1 配置浏览器
# 创建 EdgeOptions 对象,用于配置浏览器选项
edge_options = Options()
# 添加参数忽略证书错误
edge_options.add_argument('--ignore-certificate-errors')
# 添加参数禁用扩展
edge_options.add_argument('--disable-extensions')
# 添加参数禁用沙盒模式
edge_options.add_argument('--no-sandbox')
# 添加参数禁用 GPU 加速
edge_options.add_argument('--disable-gpu')# 创建 Edge 浏览器驱动实例
driver = webdriver.Edge(options=edge_options)
4.2 加载更多
打开艾瑞网的报告页面,我们会发现加载更多这个按钮,我们可以用代码点击按钮加载,直到自己需要的数量,我这里设置加载10次
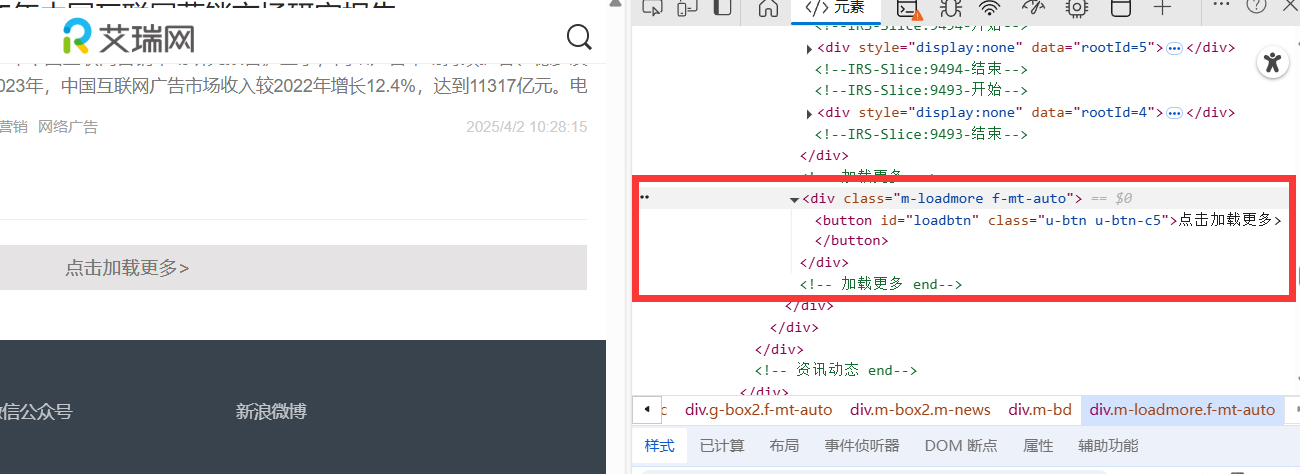
鼠标右键点击页面–>点击检查,加载更多按钮定义在这里
# 打开指定 URL 的网页
driver.get(url)try:# 用于保存找到的元素信息found_elements_info = []found_links = []wait = WebDriverWait(driver, 10)# 1. 点击"加载更多"按钮10次load_count = 0while load_count < 10:try:# 定位"加载更多"按钮load_more_btn = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'button#loadbtn') # 根据实际页面调整选择器))# 点击按钮load_more_btn.click()load_count += 1print(f"已点击加载更多 {load_count}/10 次")# 等待新内容加载(根据页面加载速度调整)time.sleep(2)except Exception as e:print(f"点击加载更多失败: {e}")break# 2. 等待所有内容加载完成print("等待内容加载完成...")time.sleep(3) # 额外等待确保所有内容加载完成
4.3 寻找内容
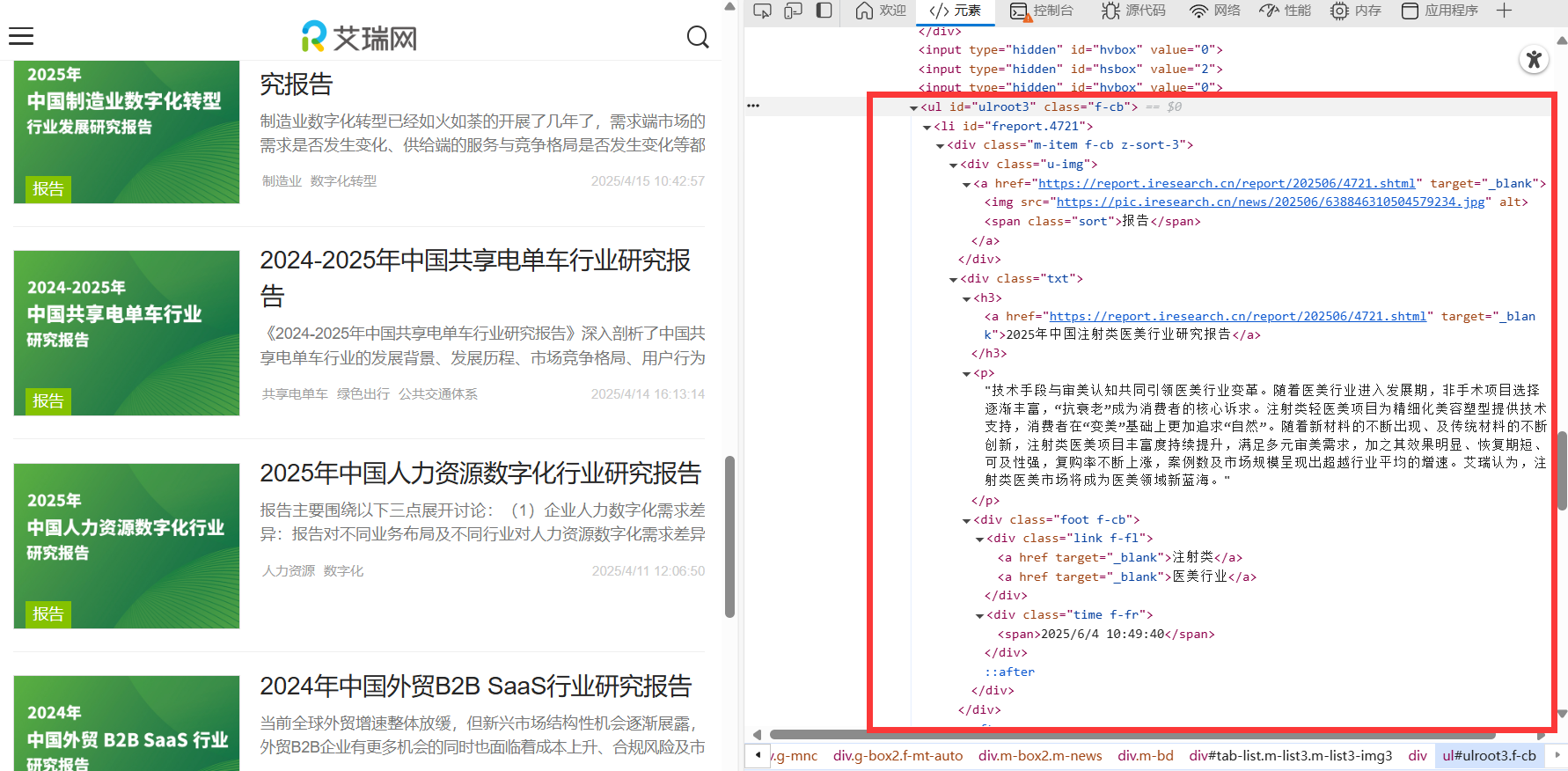
4.4 完整代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pandas as pd# 创建 EdgeOptions 对象,用于配置浏览器选项
edge_options = Options()
edge_options.add_argument('--ignore-certificate-errors')
edge_options.add_argument('--disable-extensions')
edge_options.add_argument('--no-sandbox')
edge_options.add_argument('--disable-gpu')# 创建 Edge 浏览器驱动实例
driver = webdriver.Edge(options=edge_options)url = 'https://report.iresearch.cn/'# 打开指定 URL 的网页
driver.get(url)try:data_list = [] # 用于保存字典数据wait = WebDriverWait(driver, 10)load_count = 0# 点击"加载更多"按钮10次while load_count < 11:try:load_more_btn = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'button#loadbtn')))load_more_btn.click()load_count += 1print(f"已点击加载更多 {load_count}/10 次")time.sleep(2)except Exception as e:print(f"点击加载更多失败: {e}")breakprint("等待内容加载完成...")time.sleep(3)# 定位所有目标元素elements = driver.find_elements(By.CSS_SELECTOR, 'li[id^="freport."]')print(f"共找到 {len(elements)} 个元素")found_links = []if elements:for elem in elements:try:# 提取元素信息title = elem.find_element(By.CSS_SELECTOR, 'h3').text.strip() # 标题link = elem.find_element(By.CSS_SELECTOR, 'a').get_attribute('href') # 链接desc = elem.find_element(By.CSS_SELECTOR, 'p').text.strip() if elem.find_elements(By.CSS_SELECTOR, 'p') else "" # 摘要tags = [tag.text for tag in elem.find_elements(By.CSS_SELECTOR, '.link a')] # 标签timestamp = elem.find_element(By.CSS_SELECTOR, '.time span').text.strip() # 时间戳found_links.append(link)# 构建字典data_dict = {"标题": title,"链接": link,"描述": desc,"标签": ", ".join(tags),"时间": timestamp}data_list.append(data_dict)print(f"找到元素:{title[:30]}...") except Exception as e:print(f"处理元素失败: {e}")continue# 将找到的链接信息保存到文件with open('found_links.txt', 'w', encoding='utf-8') as f:for link in found_links:f.write(link + '\n')print("已将找到的链接信息保存到 found_links.txt")# 将列表转换为DataFramedf = pd.DataFrame(data_list)# 保存为CSV文件(也可改为Excel等其他格式)df.to_csv('iresearch_reports.csv', encoding='utf-8-sig', index=False)print(f"\n成功保存 {len(data_list)} 条数据到 iresearch_reports.csv")# 打印DataFrame前5行(可选)print("\n数据预览:")print(df.head())else:print("未找到符合条件的元素。")except Exception as e:print("定位元素失败:", e)with open('page_source.html', 'w', encoding='utf-8') as f:f.write(driver.page_source)print("已保存页面源代码到 page_source.html")finally:time.sleep(2)driver.quit()
运行后我们得到两个文件,报告链接文件和报告信息
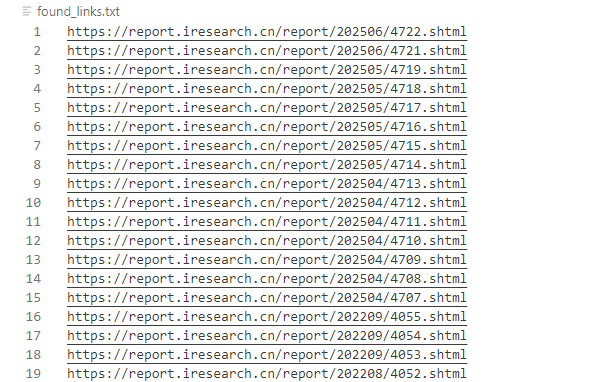
内容格式如下:

五、报告文件爬取
通过前面的学习,我们已经得到了链接文件,从中提取出我们需要的下载链接,然后通过爬虫去遍历这些链接,下载报告原件
5.1 提取下载链接
import re# 读取文件内容
with open('found_links.txt', 'r', encoding='utf-8') as f:links = f.readlines()# 定义正则表达式
pattern = re.compile(r'https?://[^/]+/report/.+?/(\d+)\.shtml')# 提取数字ID
extracted_ids = []
for link in links:link = link.strip() # 去除换行符match = pattern.search(link)if match:extracted_ids.append(match.group(1)) # 取第一个捕获组else:print(f"未匹配到ID:{link}")# 输出结果
print("提取的数字ID列表:")
print(extracted_ids)link_template = 'https://report.iresearch.cn/include/ajax/user_ajax.ashx?reportid={}&work=rdown&url=https%3A%2F%2Freport.iresearch.cn%2Freport%2F202505%2F{}.shtml'# 生成替换后的链接列表
new_links = []
for report_id in extracted_ids:new_link = link_template.format(report_id, report_id)new_links.append(new_link)print(f"生成链接: {new_link}")# 保存结果到文件
with open('generated_links.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(new_links))
print("已保存生成的链接到 generated_links.txt")

5.2 下载报告
下载报告需要登录,cookie值的设置绕过登录操作
from selenium import webdriver
from selenium.webdriver.edge.options import Options
import random
import time# 创建 EdgeOptions 对象,用于配置浏览器选项
edge_options = Options()
# 添加参数忽略证书错误
edge_options.add_argument('--ignore-certificate-errors')
# 添加参数禁用扩展
edge_options.add_argument('--disable-extensions')
# 添加参数禁用沙盒模式
edge_options.add_argument('--no-sandbox')
# 添加参数禁用 GPU 加速
edge_options.add_argument('--disable-gpu')# 创建 Edge 浏览器驱动实例
driver = webdriver.Edge(options=edge_options)# 先访问站点基础页面(比如首页),让浏览器先有站点的基础上下文,再设置 Cookie 更有效
driver.get('https://report.iresearch.cn/') # 替换为实际站点域名# 逐个设置关键 Cookie
cookies = [{'name': 'iRsUserType', 'value': '49'},{'name': 'iRsUserPhoto', 'value': ''}, # 替换为完整真实值{'name': 'iRsUserPassword', 'value': ''},{'name': 'iRsUserNick', 'value': ''}, # 补全真实值{'name': 'iRsUserRName', 'value': ''},{'name': 'iRsUserId', 'value': ''},{'name': 'iRsUserGroup', 'value': '48'},{'name': 'iRsUserDate', 'value': ''},{'name': 'iRsUserAccount', 'value': ''},{'name': 'Hm_lvt_c33e4c1e69eca76a2e522c20e59773f6', 'value': '‘},{'name': 'Hm_lpvt_c33e4c1e69eca76a2e522c20e59773f6', 'value': ''},{'name': 'HMACCOUNT', 'value': ''},
]for cookie in cookies:try:driver.add_cookie(cookie)except Exception as e:print(f"设置 Cookie {cookie['name']} 失败:{e}")# 重新加载页面,让设置的 Cookie 生效,尝试绕过登录
driver.refresh()
time.sleep(3) # 等待页面加载# 读取文件中的链接(假设链接文件为当前目录下的generated_links.txt)
def read_links():with open("generated_links.txt", "r", encoding="utf-8") as f:links = [line.strip() for line in f if line.strip()]return list(set(links)) # 去重处理# 模拟浏览器遍历链接
def browse_links(links):try:for idx, link in enumerate(links, 1):try:driver.get(link)print(f"{idx}/{len(links)}正在访问:{link}")# 模拟真实用户行为time.sleep(random.uniform(3, 7)) # 随机停留3-7秒scroll_height = driver.execute_script("return document.body.scrollHeight")driver.execute_script(f"window.scrollTo(0, {random.randint(0, scroll_height)})") # 随机滚动# 偶尔模拟刷新(增加随机性)if random.random() < 0.2:driver.refresh()time.sleep(2)except Exception as e:print(f"访问失败:{link} | 错误:{str(e)[:50]}...")continue # 跳过当前链接finally:time.sleep(2)driver.quit()print("\n所有链接遍历完成!")# 主程序入口
if __name__ == "__main__":links = read_links()if links:print(f"检测到 {len(links)} 个链接,开始遍历...")browse_links(links)else:print("未找到有效链接")
六、总结
基本完成了任务目标,但是并没有进行模块化处理。
相关文章:
selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...