【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述
Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通过累积历史梯度的平方信息,动态调整每个参数的学习率,使得频繁更新的参数学习率较小,稀疏更新的参数学习率较大。这种自适应特性使其在训练深度神经网络时表现优异,尤其在自然语言处理和推荐系统中广泛应用。
二.Adagrad的优缺点
Adagrad的主要优势在于自适应学习率,尤其适合稀疏数据或非平稳目标的优化问题。其缺点在于累积的梯度平方会持续增长,导致后期学习率过小,可能过早停止训练,为了改善这个问题,可以使用RMSProp方法。RMSProp 方法并不是将过去所有的梯度一视同仁地相加,而是逐渐地遗忘过去的梯度,在做加法运算时将新梯度的信息更多地反映出来。这种操作从专业上讲,称为“指数移动平均”,呈指数函数式地减小过去的梯度的尺度。后续改进算法如RMSProp和Adam通过引入衰减机制解决了这一问题。尽管如此,Adagrad仍为自适应优化算法的发展奠定了基础。
三.算法原理与特性
3.1 基本核心思想
自适应梯度算法(Adaptive Gradient Algorithm)通过累积历史梯度信息实现参数级学习率调整。其主要创新点在于:
$$g_{t,i} = \sum_{\tau=1}^t \nabla_\theta J(\theta_{\tau,i})^2$$
$$\theta_{t+1,i} = \theta_{t,i} - \frac{\eta}{\sqrt{g_{t,i} + \epsilon}} \nabla_\theta J(\theta_{t,i})$$
其中$$i$$表示参数索引,$$\eta$$为全局学习率, $$\epsilon$$为数值稳定常数(通常取 1e-8)
3.2 算法的特性
- 参数级自适应:每个参数独立动态调整学习率,而不是固定学习率
- 梯度敏感度:更新率较大的动态调整为较小的学习率,更新率较小的动态调整为较大的学习率
- 累积记忆:通过历史梯度的平方和持续积累增长
3.3 更新规则
Adagrad的更新公式基于参数的历史梯度信息,具体表现为对学习率的分母项进行累积。对于每个参数θᵢ,其更新规则如下:
# Adagrad更新公式
grad_squared += gradient ** 2
adjusted_lr = learning_rate / (sqrt(grad_squared) + epsilon)
theta -= adjusted_lr * gradient
其中,grad_squared是梯度平方的累积,epsilon是为数值稳定性添加的常数,防止出现梯度为0导致分母变成无限大的情况,通常采用1e-8。Adagrad的累积特性使其对初始学习率的选择相对鲁棒,但长期训练可能导致学习率过小。
四、代码实现
4.1 测试函数设置
使用非凸函数: f(x) = x**2 / 20.0 + y**2
4.2 收敛速度可视化
import numpy as np
from collections import OrderedDict
import matplotlib.pyplot as pltclass AdaGrad:"""AdaGrad"""def __init__(self, lr=1.5):self.lr = lrself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] += grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)optimizers= AdaGrad()init_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0x_history = []
y_history = []def f(x, y):return x**2 / 20.0 + y**2def df(x, y):return x / 10.0, 2.0*yfor i in range(30):x_history.append(params['x'])y_history.append(params['y'])grads['x'], grads['y'] = df(params['x'], params['y'])optimizers.update(params, grads)x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)X, Y = np.meshgrid(x, y)
Z = f(X, Y)# for simple contour line
mask = Z > 7
Z[mask] = 0idx = 1# plot
plt.subplot(2, 2, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="red")
plt.contour(X, Y, Z)
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
# colorbar()
# spring()
plt.title("AdaGrad")
plt.xlabel("x")
plt.ylabel("y")plt.show()
收敛效果如下:
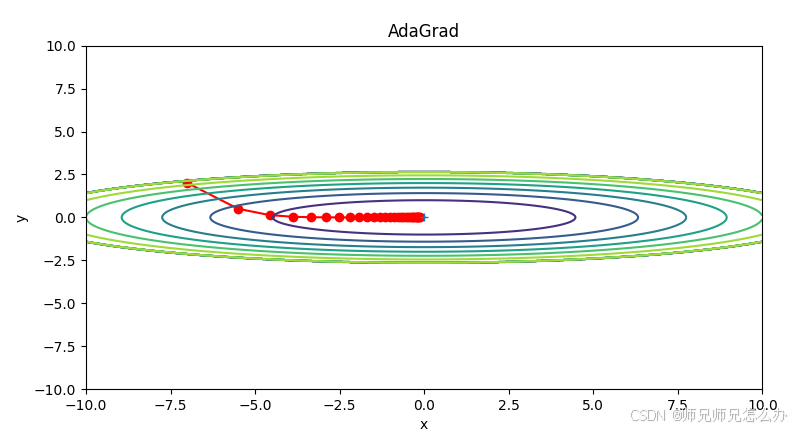
五、Adagrad算法优缺点分析
5.1 优势特征
- 稀疏梯度优化:适合NLP等稀疏数据场景
- 自动学习率调整:减少超参调优成本
- 早期快速收敛:梯度累积未饱和时效率高
5.2 局限与改进
- 学习率单调衰减:后期更新停滞
- 内存消耗:需存储历史梯度平方和
- 梯度突变敏感:可能错过最优解
5.3 常用场景以及建议
- 推荐场景:自然语言处理、推荐系统
- 参数设置:
- 初始学习率:0.01-0.1
- 批量大小:128-512
- 配合技术:梯度裁剪+权重衰减
六. 各优化器对比
| 优化器 | 收敛速度 | 震荡幅度 | 超参敏感性 | 内存消耗 |
|---|---|---|---|---|
| SGD | 慢 | 大 | 高 | 低 |
| Momentum | 中等 | 中等 | 中等 | 低 |
| Adagrad | 快(初期) | 小 | 低 | 中 |
| RMSProp | 稳定 | 较小 | 中等 | 中 |
| Adam | 最快 | 最小 | 低 | 高 |
七、全部优化器的对比代码
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cmdef test_function(x, y):return x ** 2 / 20.0 + y ** 2def compare_optimizers():# 初始化参数init_params = np.array([3.0, 4.0])epochs = 200optimizers = {'SGD': SGD(lr=0.1),'Momentum': Momentum(lr=0.1, momentum=0.9),'Adagrad': Adagrad(lr=0.1),'RMSProp': RMSProp(lr=0.001, decay=0.9),'Adam': Adam(lr=0.1, beta1=0.9, beta2=0.999)}# 训练过程plt.figure(figsize=(14,10))ax = plt.axes(projection='3d')X = np.linspace(-4, 4, 100)Y = np.linspace(-4, 4, 100)X, Y = np.meshgrid(X, Y)Z = test_function(X, Y)ax.plot_surface(X, Y, Z, cmap=cm.coolwarm, alpha=0.6)for name, opt in optimizers.items():params = init_params.copy()trajectory = []for _ in range(epochs):grad = compute_gradient(params)params = opt.update(params, grad)trajectory.append(params.copy())trajectory = np.array(trajectory)ax.plot3D(trajectory[:,0], trajectory[:,1], test_function(trajectory[:,0], trajectory[:,1]), label=name, linewidth=2)ax.legend()ax.set_xlabel('x')ax.set_ylabel('y')ax.set_zlabel('z')plt.show()def compute_gradient(params):x, y = paramsdx = x / 10.0dy = 2.0*yreturn np.array([dx, dy])# 各优化器实现类
class SGD:def __init__(self, lr=0.01):self.lr = lrdef update(self, params, grads):return params - self.lr * gradsclass Momentum:def __init__(self, lr=0.01, momentum=0.9):self.lr = lrself.momentum = momentumself.v = Nonedef update(self, params, grads):if self.v is None:self.v = np.zeros_like(params)self.v = self.momentum*self.v + self.lr*gradsreturn params - self.vclass Adagrad:def __init__(self, lr=0.01, eps=1e-8):self.lr = lrself.eps = epsself.cache = Nonedef update(self, params, grads):if self.cache is None:self.cache = np.zeros_like(params)self.cache += grads**2return params - self.lr / (np.sqrt(self.cache) + self.eps) * gradsclass RMSProp:def __init__(self, lr=0.001, decay=0.9, eps=1e-8):self.lr = lrself.decay = decayself.eps = epsself.cache = Nonedef update(self, params, grads):if self.cache is None:self.cache = np.zeros_like(params)self.cache = self.decay*self.cache + (1-self.decay)*grads**2return params - self.lr / (np.sqrt(self.cache) + self.eps) * gradsclass Adam:def __init__(self, lr=0.001, beta1=0.9, beta2=0.999, eps=1e-8):self.lr = lrself.beta1 = beta1self.beta2 = beta2self.eps = epsself.m = Noneself.v = Noneself.t = 0def update(self, params, grads):if self.m is None:self.m = np.zeros_like(params)self.v = np.zeros_like(params)self.t += 1self.m = self.beta1*self.m + (1-self.beta1)*gradsself.v = self.beta2*self.v + (1-self.beta2)*grads**2m_hat = self.m / (1 - self.beta1**self.t)v_hat = self.v / (1 - self.beta2**self.t)return params - self.lr * m_hat / (np.sqrt(v_hat) + self.eps)if __name__ == "__main__":compare_optimizers()
效果图如下:

观察图示可以得出以下结论:
- Adagrad初期收敛速度明显快于SGD
- 中后期被Adam、RMSProp超越
- 在平坦区域表现出更稳定的更新方向
- 对于陡峭方向能自动减小步长
相关文章:
【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...