7.4.分块查找
一.分块查找的算法思想:
1.实例:
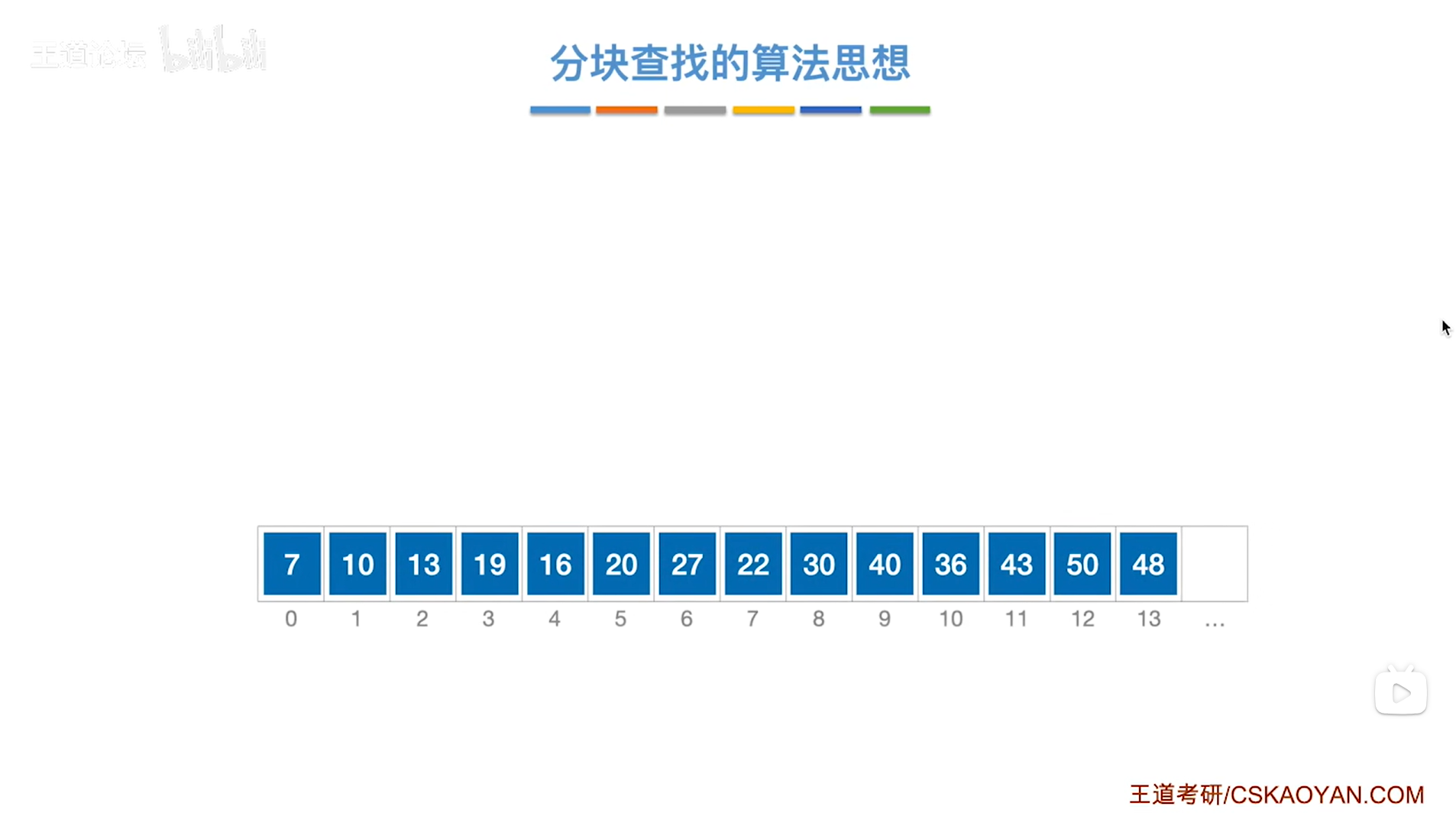
以上述图片的顺序表为例,
该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间,
第一个区间[0,1]索引上的数据元素都是小于等于10的,
第二个区间[2,5]索引上的数据元素都是小于等于20的,
第三个区间[6,8]索引上的数据元素都是小于等于30的,
第四个区间[9,10]索引上的数据元素都是小于等于40的,
第五个区间[11,13]索引上的数据元素都是小于等于50的,以此类推,
因此该顺序表虽然整体看起来是乱序的,但是当我们把顺序表分成一块一块的小区间之后,会发现各个区间之间其实是有序的,
可以给这个顺序表(查找表)建立上一级的索引,如下图:
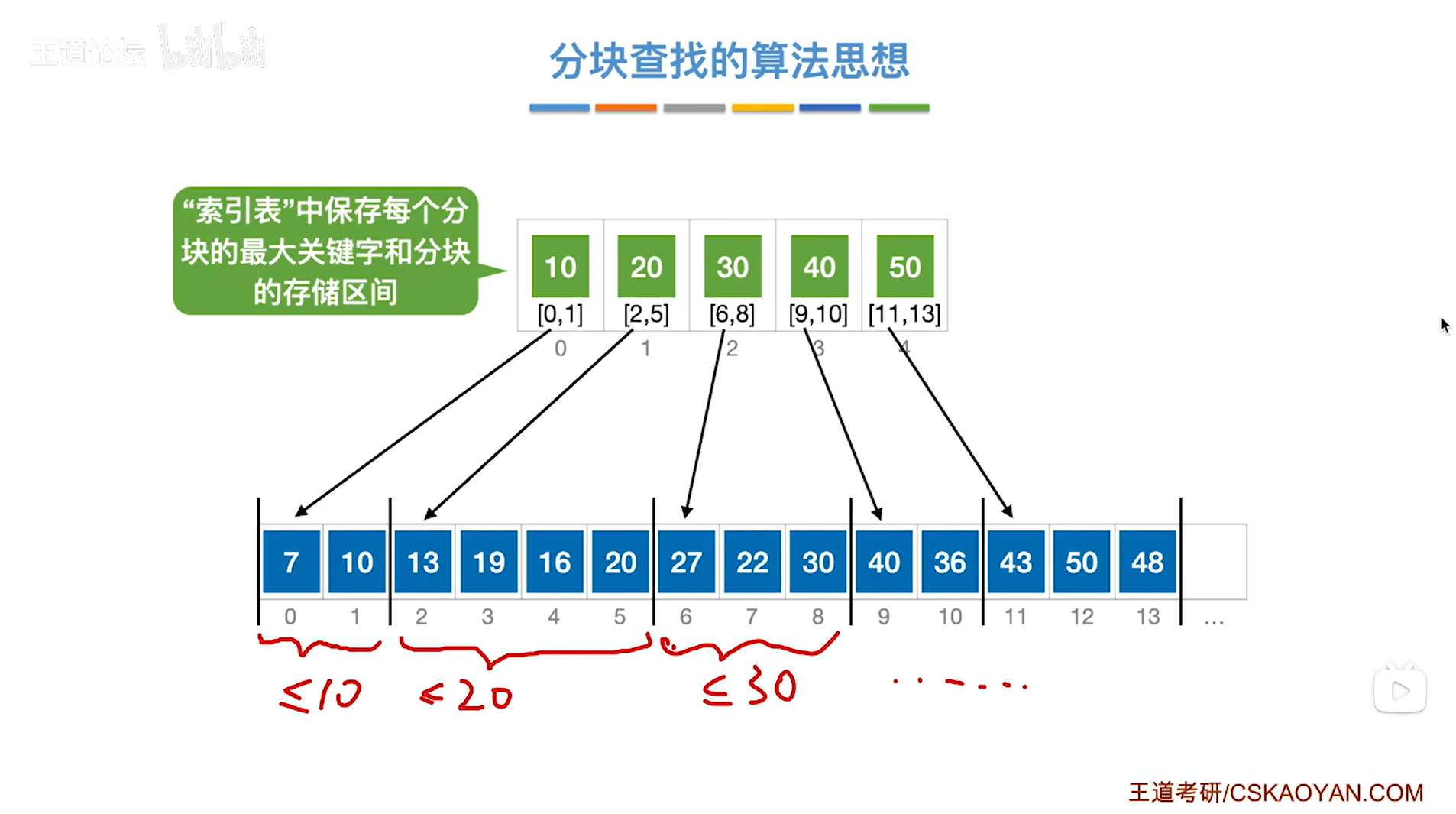
如上图,
"索引表"当中保存的是每一分块中最大的关键字,和对应的分块的存储区间,
比如"索引表"的2索引中保存了30和[6,8],也就是说顺序表中第3个分块中出现的最大关键字是30,且该分块的存储区间是[6,8],其他同理,
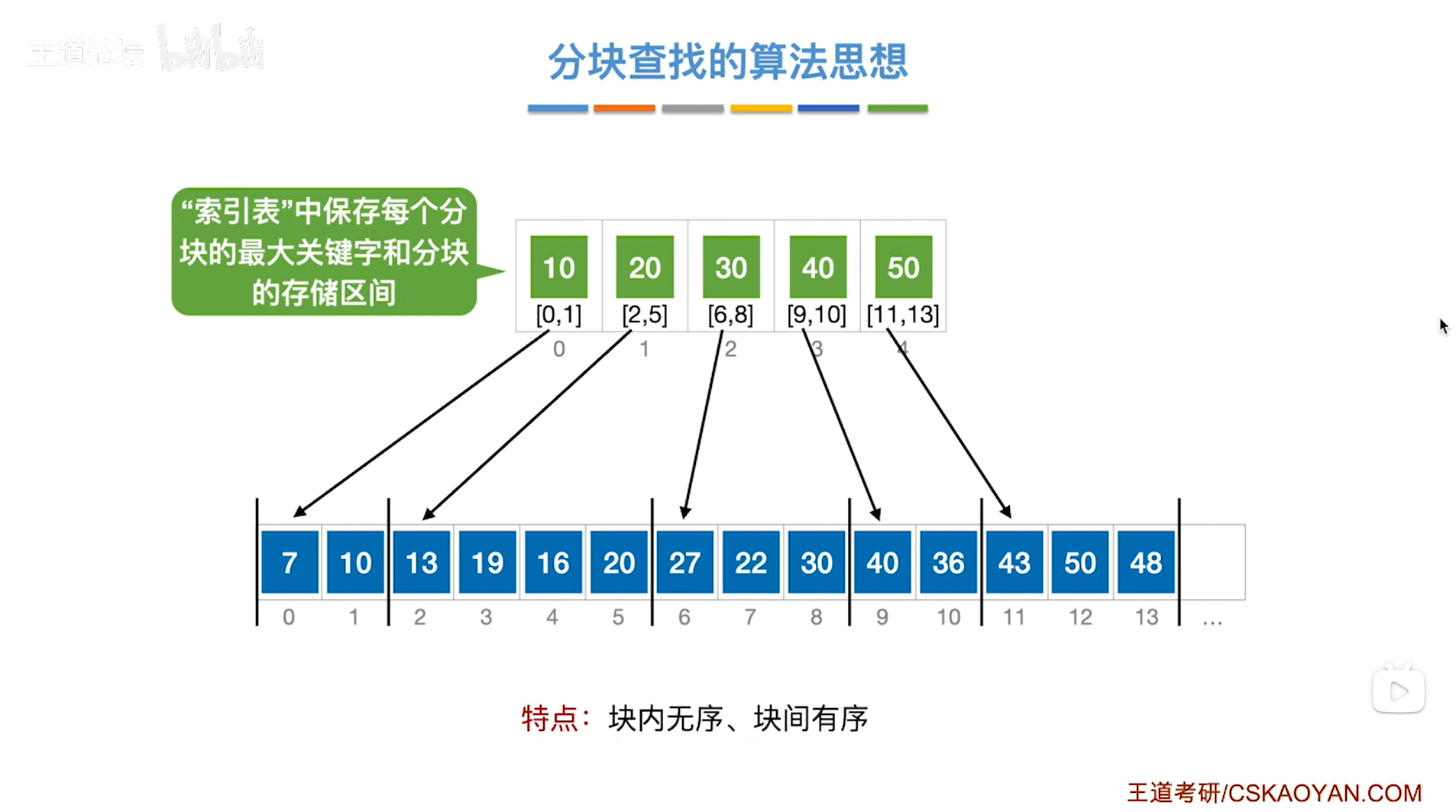
所以分块查找的特点是"块内无序、块间有序",如果看每一个分块之间,通过"索引表"可知各个分块中存储的最大关键字是递增的,也可以是递减的,
如下图:
2."索引表"的代码实现:
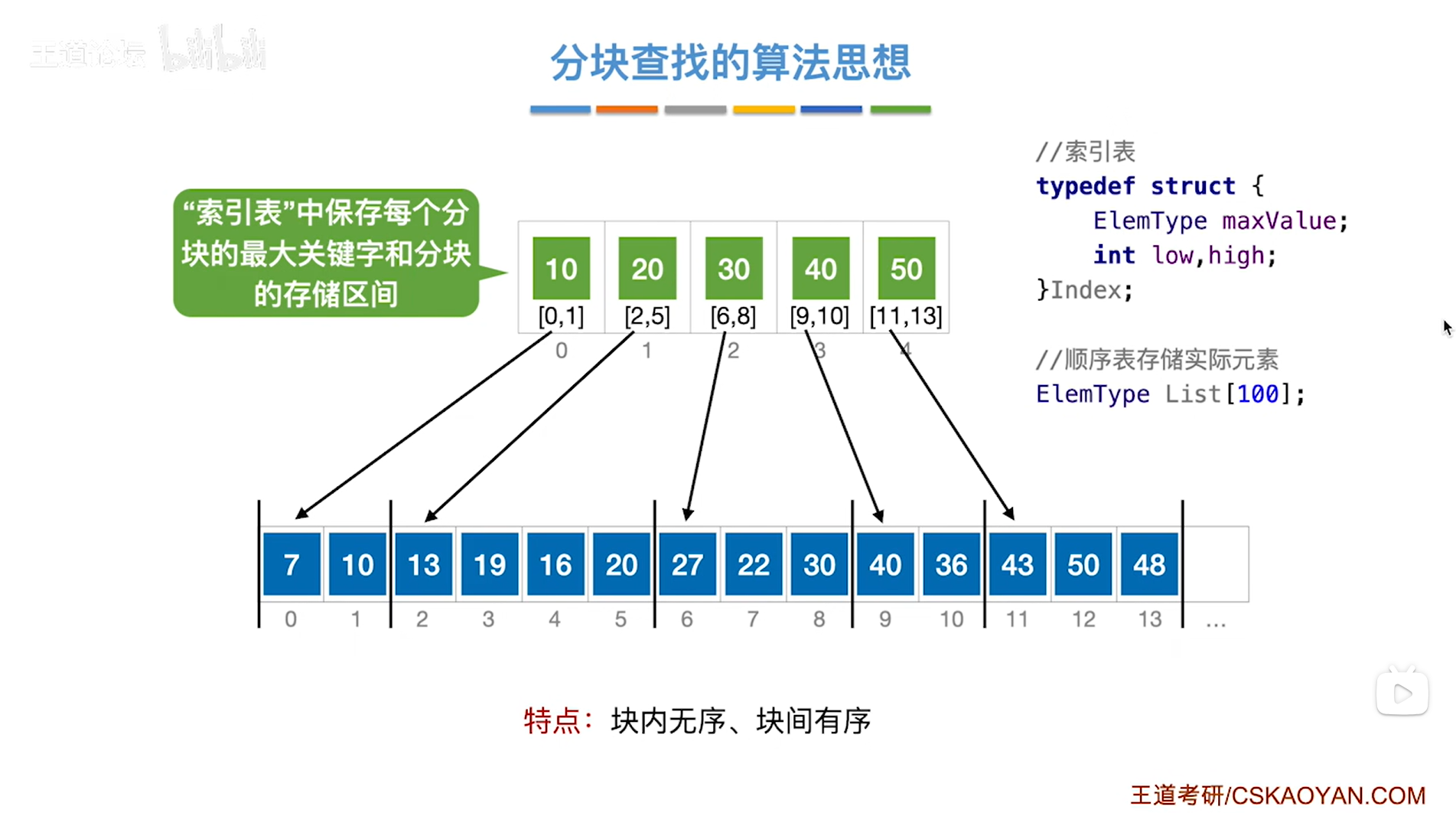
#include<stdio.h>
//索引表
typedef struct
{int maxValue; //顺序表中每一分块的最大关键字,该关键字的数据类型不固定,但要与顺序表里的元素类型保持一致 int low,high; //low和high指的是当前所指的分块的区间范围[low,high]
}Index; //索引表的类型
//顺序表存储的实际元素
int List[100];
int main()
{return 0;
}二.分块查找的演示:
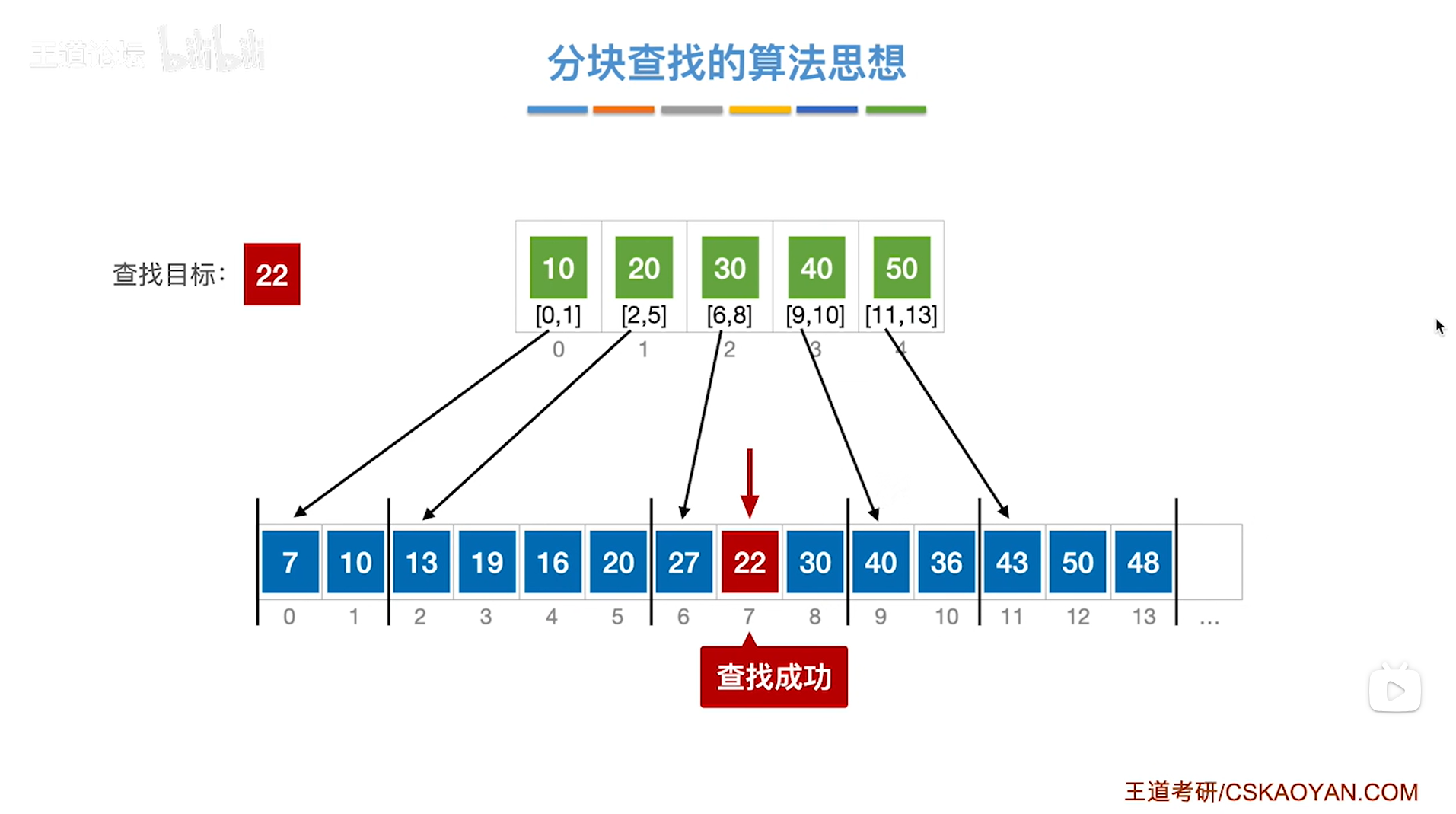
1.例一:对索引表采取顺序查找来判断要查找的目标关键字所属的分块
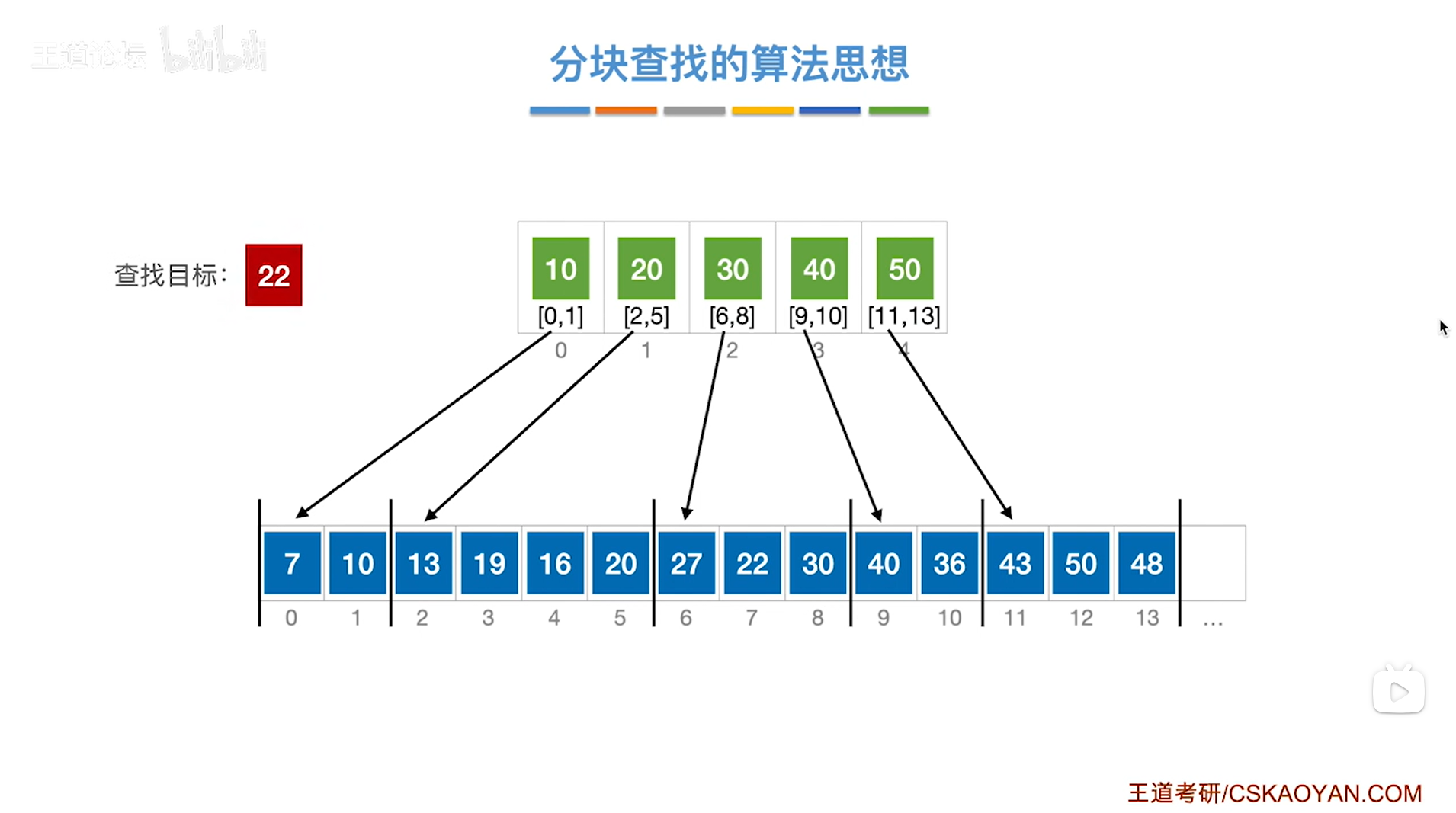
如上图,
如果本次要查找的目标关键字是22,需要先查找"索引表",从"索引表"的第一个元素依次往后找,
第一个元素是10即该分块内的元素都是小于等于10的,所以关键字22不可能在该分块内;
第二个元素是20即该分块内的元素都是小于等于20的,所以关键字22不可能在该分块内;
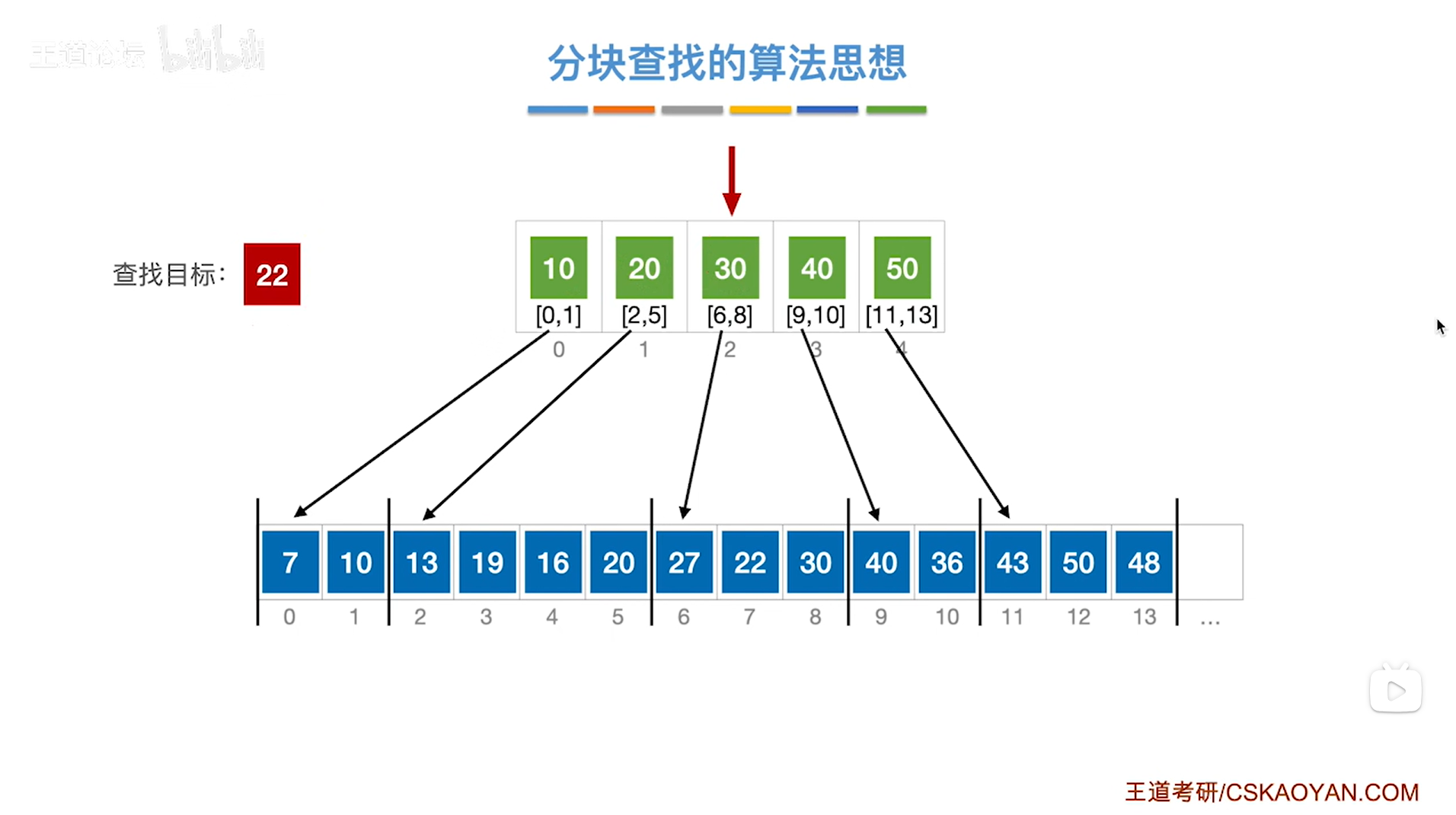
第三个元素是30即该分块内的元素都是小于等于30的,所以如果22存在于该顺序表中,那么只可能在该分块内,
因此接下来就从该分块的起始位置即数组的6索引的位置开始查找,
如下图:
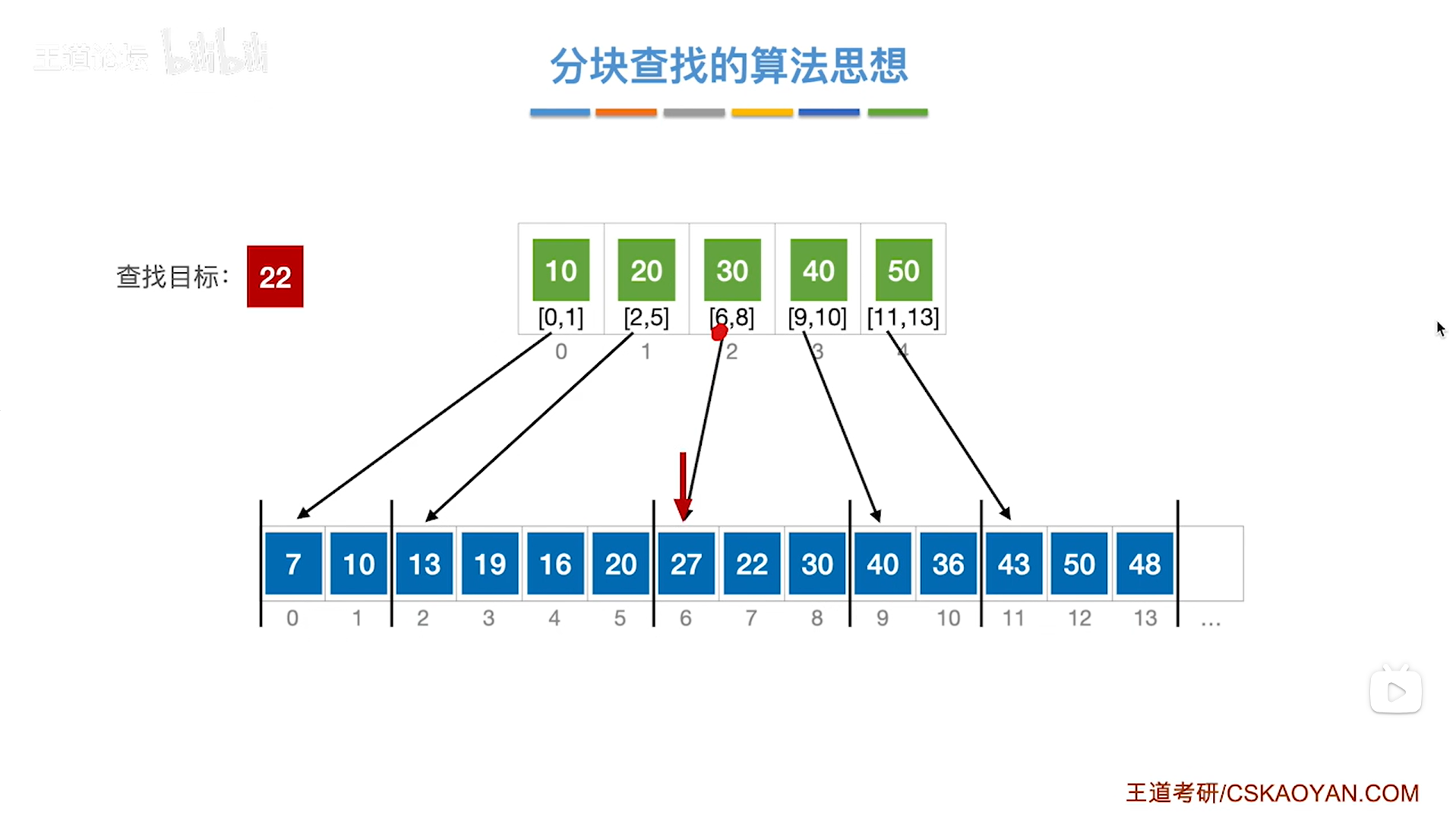
如上图,顺序表里的6索引上的元素27不等于要查找的目标关键字22,
所以要往后找一个索引,因此接下来是7索引上的元素22,与要查找的目标关键字22相等,
至此,查找成功,
如下图:
2.例二:对索引表采取顺序查找来判断要查找的目标关键字所属的分块
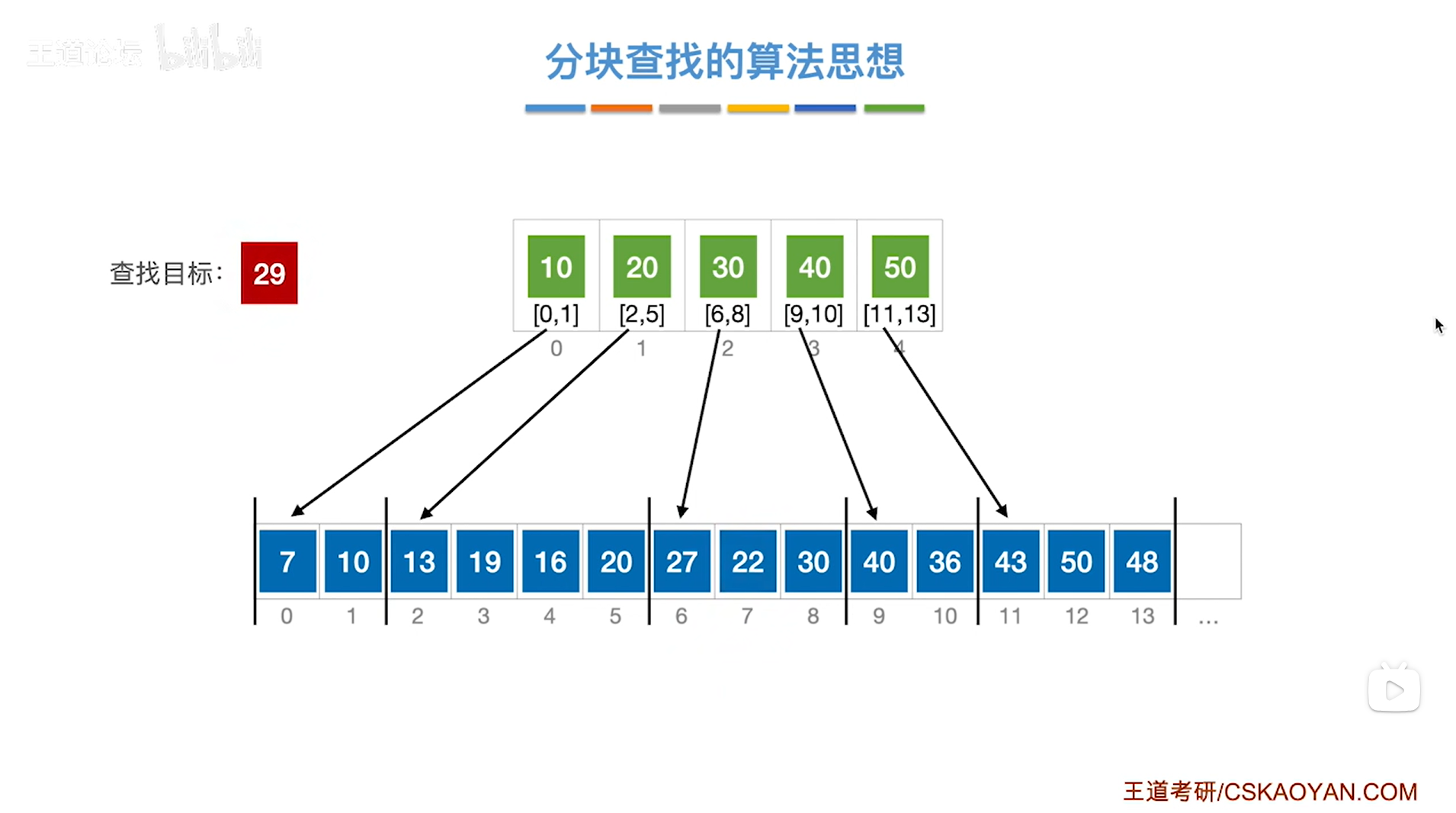
如上图,
如果本次要查找的目标关键字是29,需要先查找"索引表",从"索引表"的第一个元素依次往后找,
第一个元素是10即该分块内的元素都是小于等于10的,所以关键字29不可能在该分块内;
第二个元素是20即该分块内的元素都是小于等于20的,所以关键字29不可能在该分块内;
第三个元素是30即该分块内的元素都是小于等于30的,所以如果29存在于该顺序表中,那么只可能在该分块内,
因此接下来就从该分块的起始位置即数组的6索引的位置开始查找,
如下图:
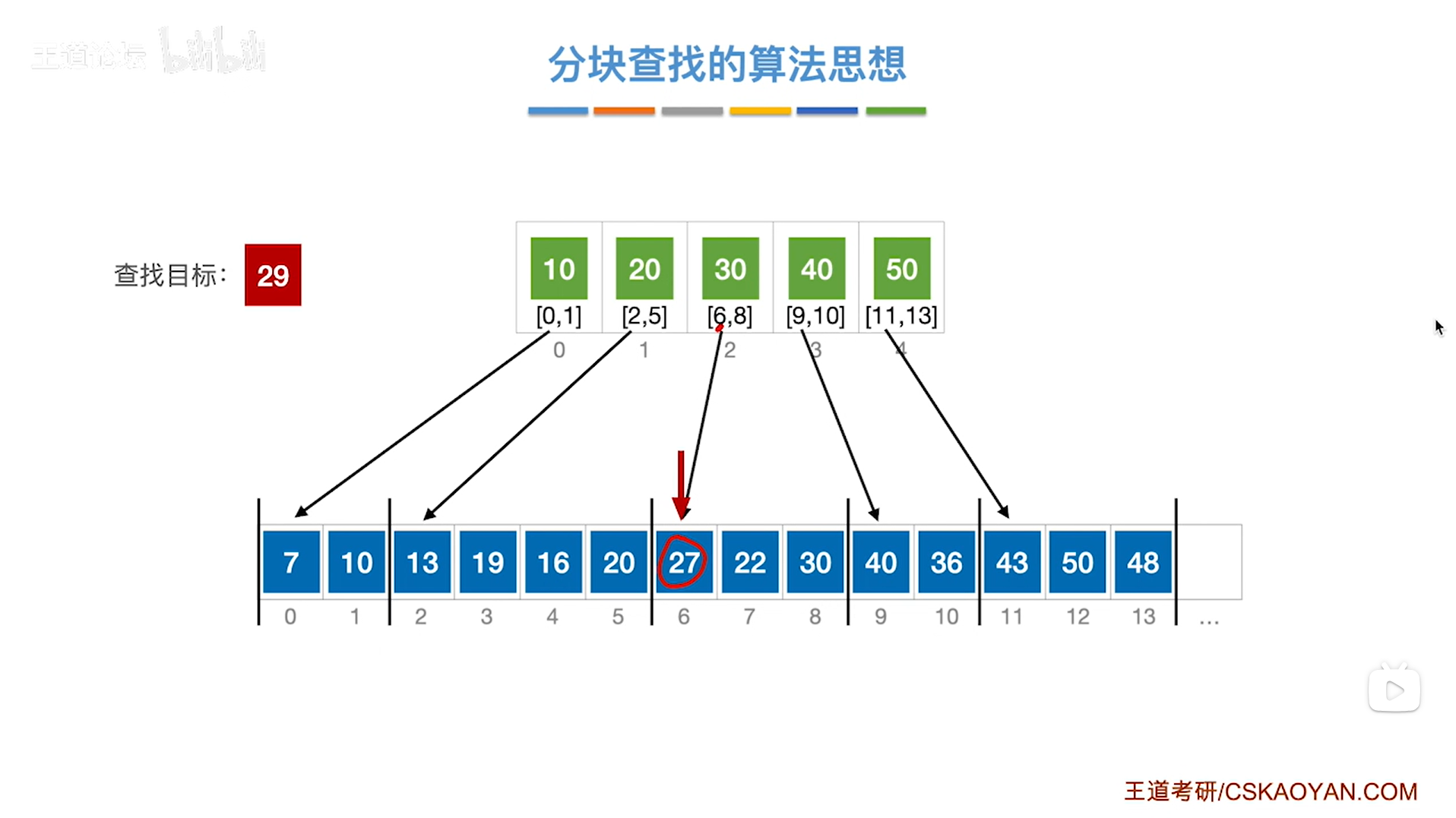
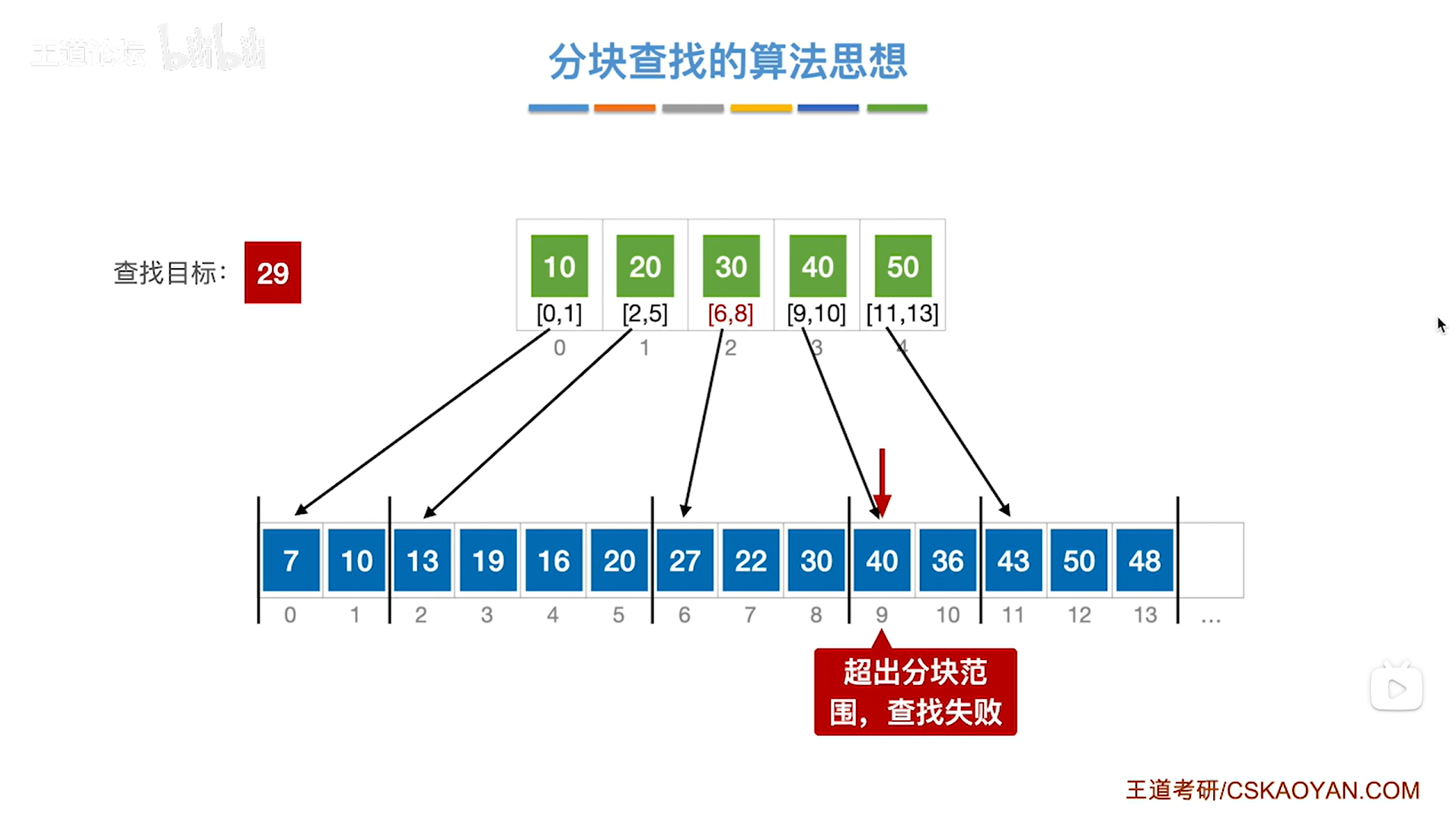
如上图:
在第三个分块内即顺序表的6索引到8索引上,不存在要查找的目标关键字29,
再往后就指向了9索引上的元素,此时已经超出了第三个分块范围,说明查找失败,
如下图:
3.例三:对索引表采取折半查找来判断要查找的目标关键字所属的分块
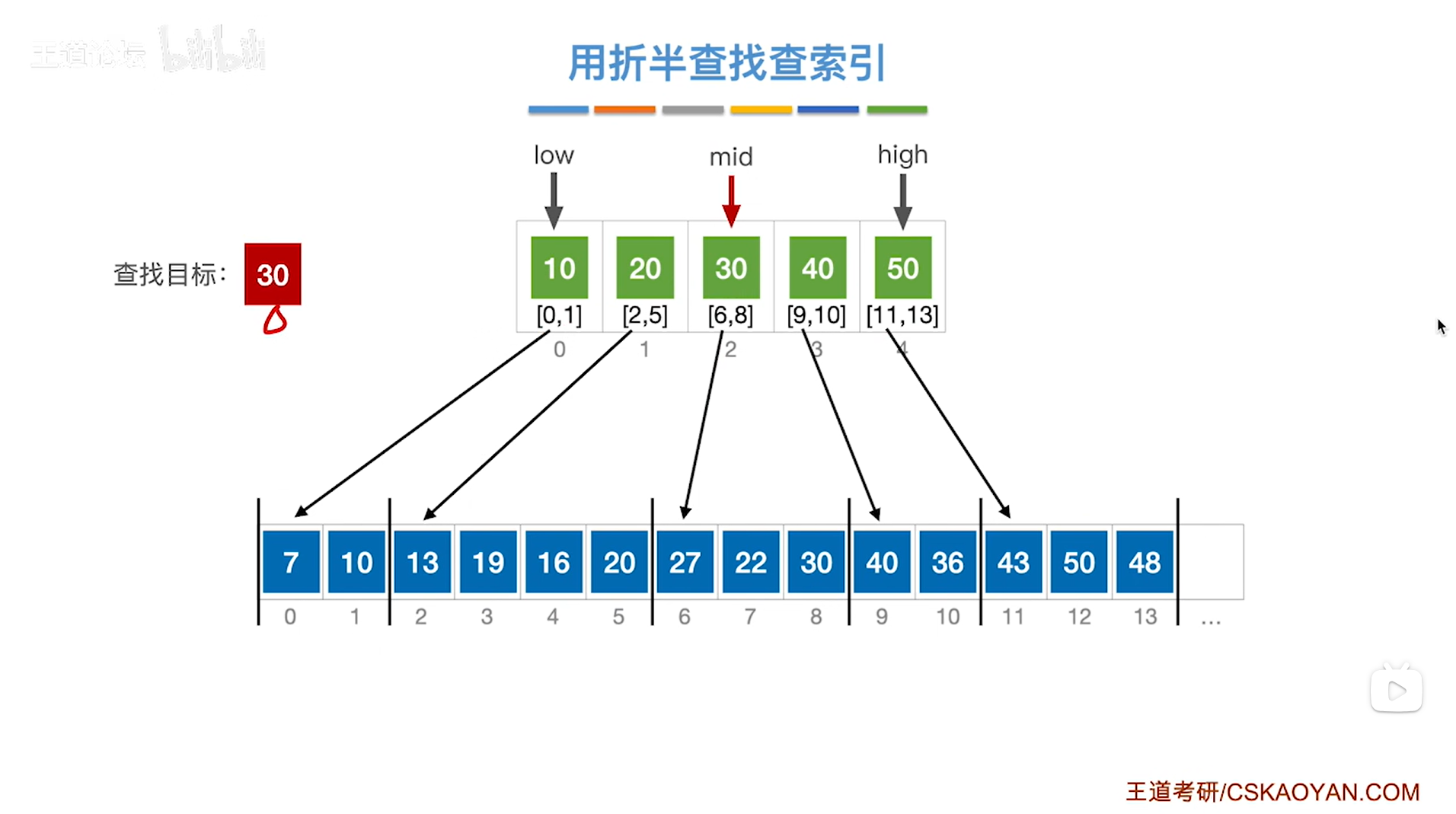
如上图,
如果本次要查找的目标关键字是30,需要先查找"索引表",
根据折半查找规则,初始需要通过索引表的开头即low指针指向的位置和索引表的末尾即high指针指向的位置来求出中间指针mid的位置,再尝试找到30这个关键字所属的分块,
初始时low为0,high为4,根据mid=(low+high)/2可知mid等于2,
所以mid初始指向的元素是索引表上2索引的元素30即该分块内的元素都是小于等于30的,所以如果30存在于该顺序表中,那么只可能在该分块内(因为要查找的目标关键字30等于该分块的最大元素30),
所以接下来会从该分块内即顺序表的6索引到8索引上依次往后查找,
如下图:

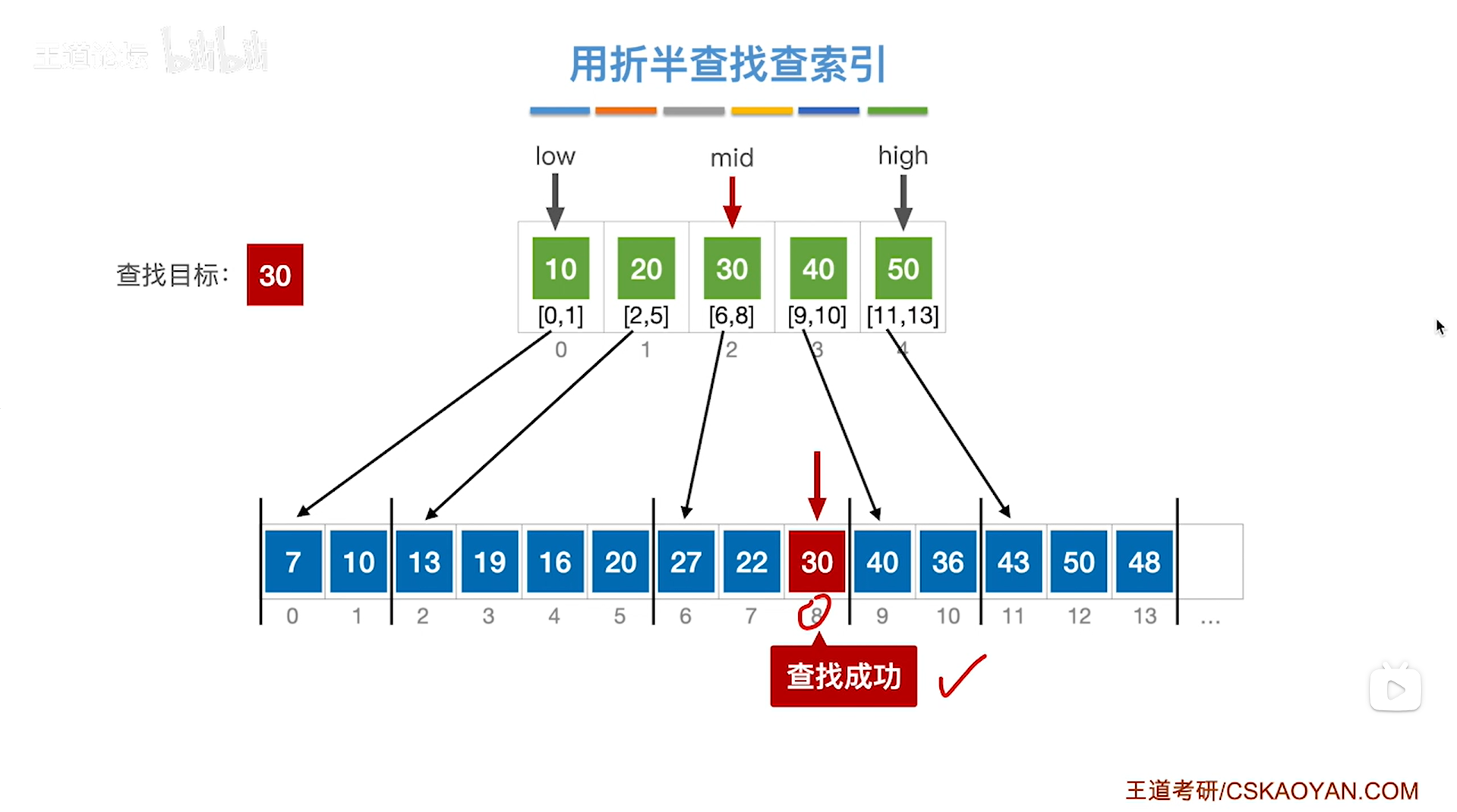
如上图,
在该分块内通过查找发现顺序表里8索引上的元素30等于要查找的目标关键字30,
至此,查找成功,
如下图:
4.例四:对索引表采取折半查找来判断要查找的目标关键字所属的分块
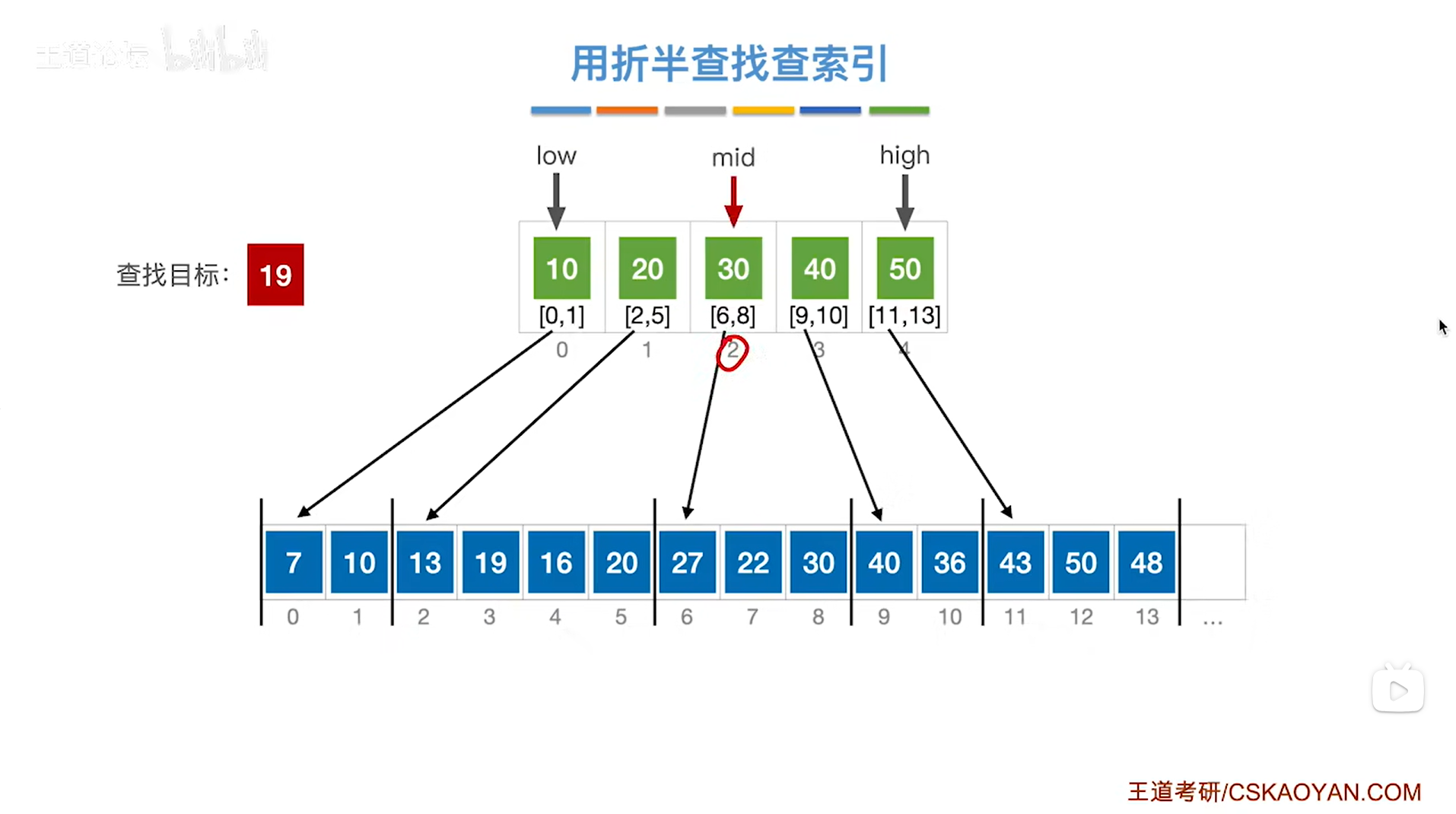
如上图,
如果本次要查找的目标关键字是19,显然19存在于顺序表中(注:不是索引表),但和例三不一样的是,例三中要查找的目标关键字30,这个要查找的目标关键字30可以直接在索引表中找到,但是现在要查找的目标关键字19并没有被直接包含在索引表中,
首先需要查找"索引表",
根据折半查找规则,初始需要通过索引表的开头即low指针指向的位置和索引表的末尾即high指针指向的位置来求出中间指针mid的位置,再尝试找到19这个关键字所属的分块,
初始时low为0,high为4,根据mid=(low+high)/2可知mid等于2,
所以mid初始指向的元素是索引表上2索引的元素30即该分块内的元素都是小于等于30的,
但19是小于索引表中的30的,
根据分块查找的规则要把high指针指向mid-1的位置即high指针指向1索引,low指针不变,
(注:索引表是按照升序排列的)
如下图:
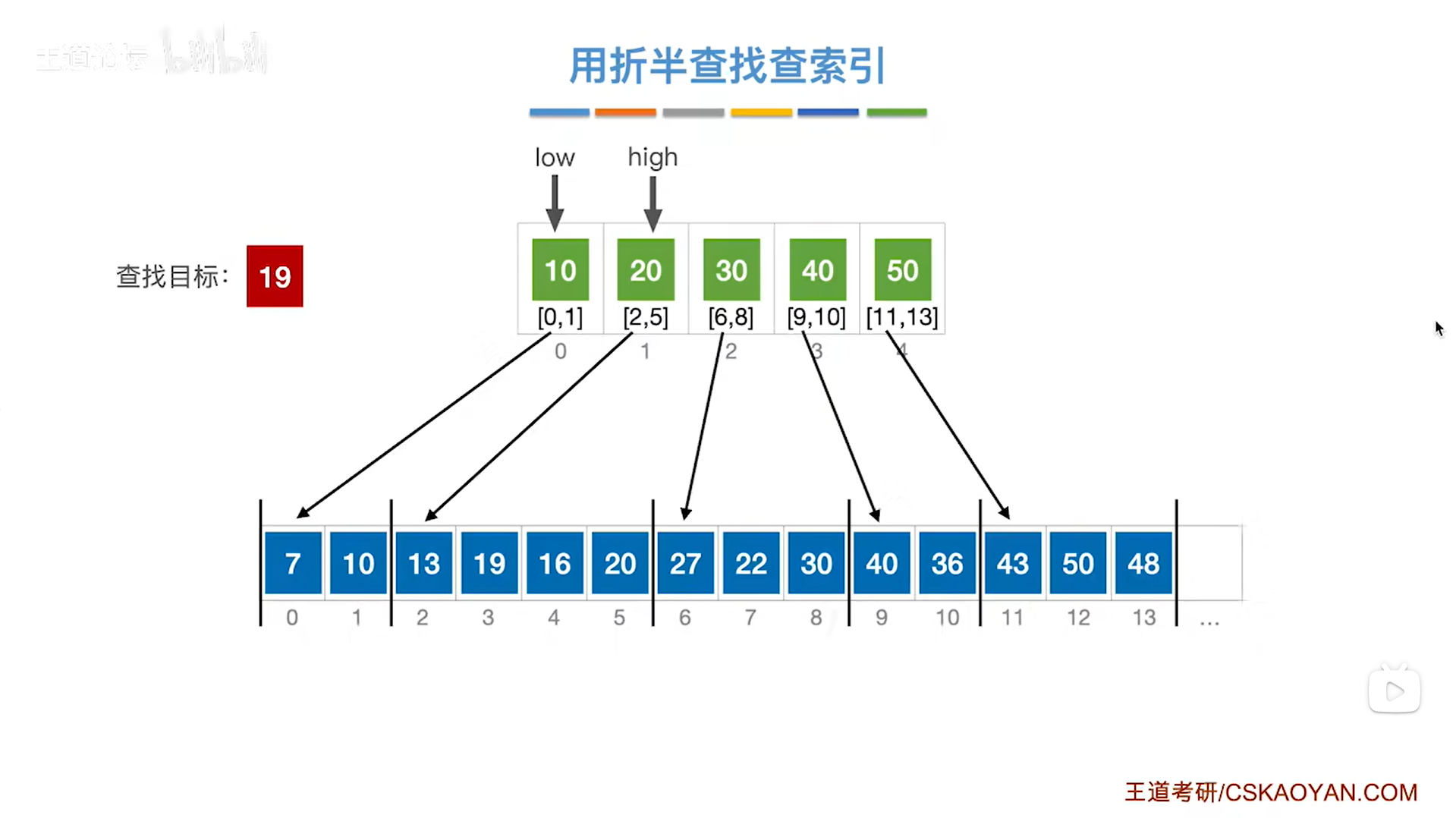
如上图,
此时low指针指向0索引上的元素即low为0,high指针指向1索引上的元素即high为1,
根据mid=(low+high)/2可知mid等于0,
所以mid指向的元素是索引表上0索引的元素10即该分块内的元素都是小于等于10的,
但19是大于索引表中的10的,
根据分块查找的规则要把low指针指向mid+1的位置即low指针指向1索引,high指针不变,
(注:索引表是按照升序排列的)
如下图:
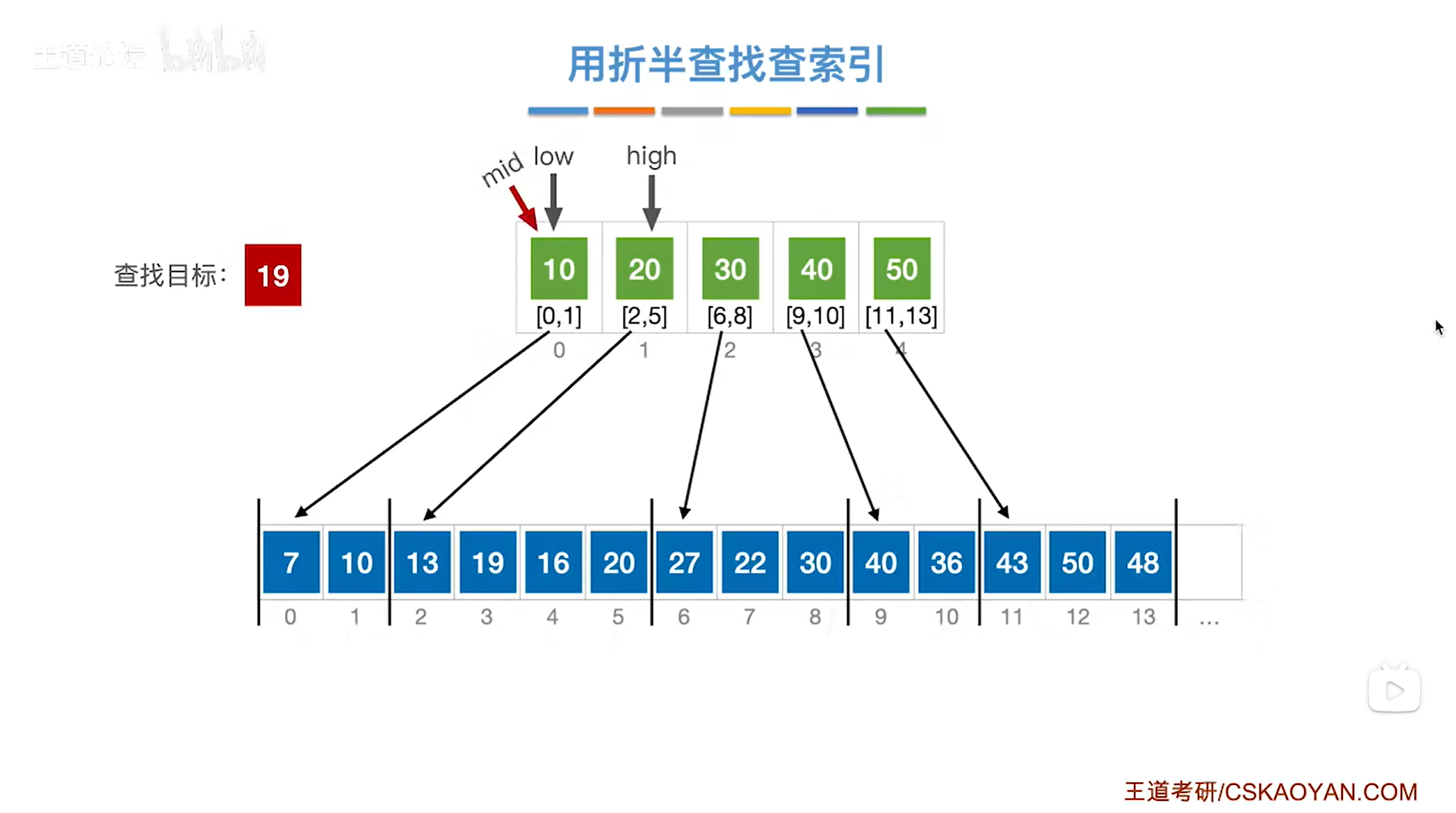
如上图,
此时low指针指向1索引上的元素即low为1,high指针指向1索引上的元素即high为1,
根据mid=(low+high)/2可知mid等于1,
所以mid指向的元素是索引表上1索引的元素20即该分块内的元素都是小于等于20的,
但19是小于索引表中的20的,
根据分块查找的规则要把high指针指向mid-1的位置即high指针指向0索引,low指针不变,
(注:索引表是按照升序排列的)
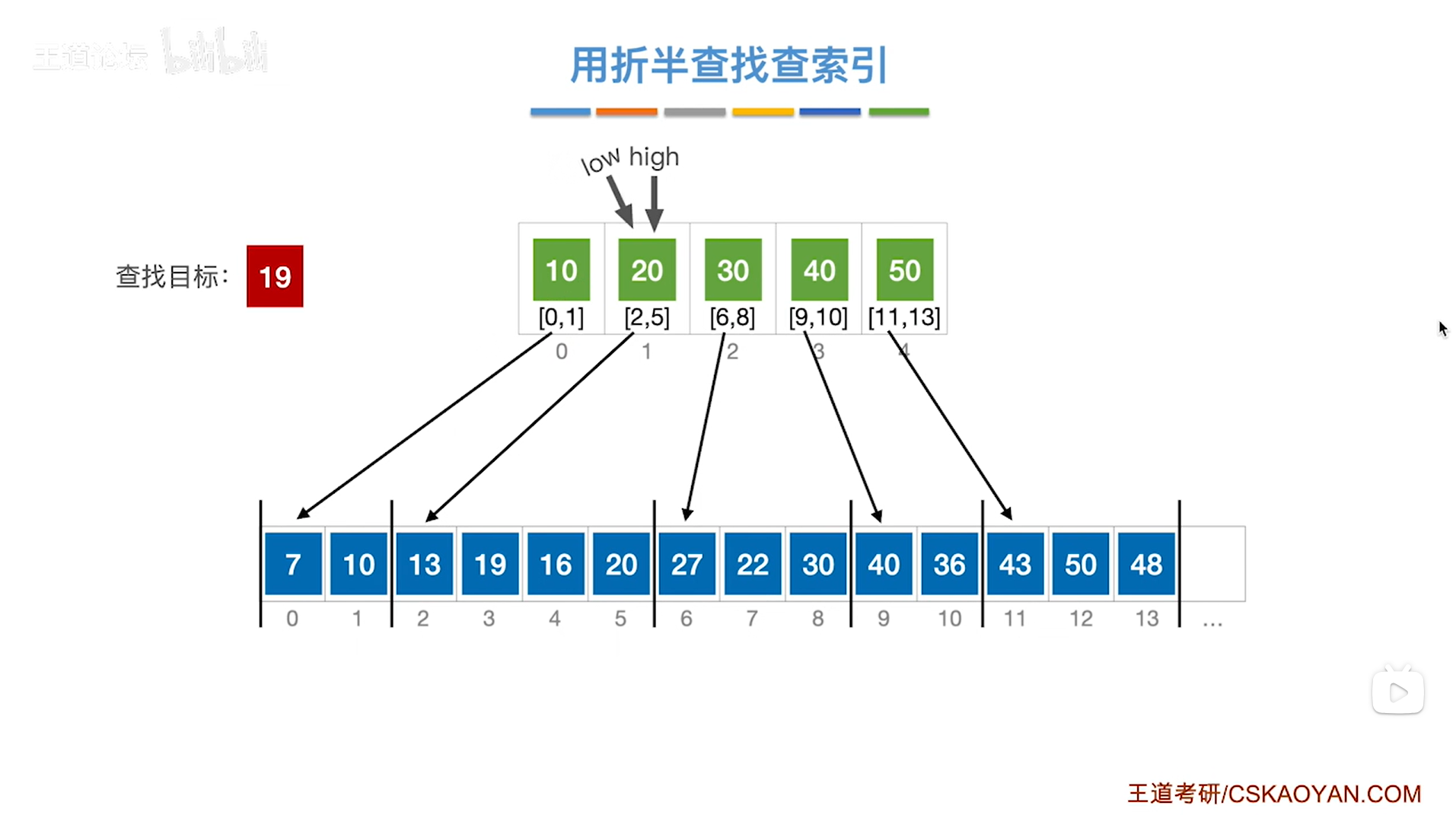
如下图:
如上图,
此时low指针指向1索引上的元素即low为1,high指针指向0索引上的元素即high为0,
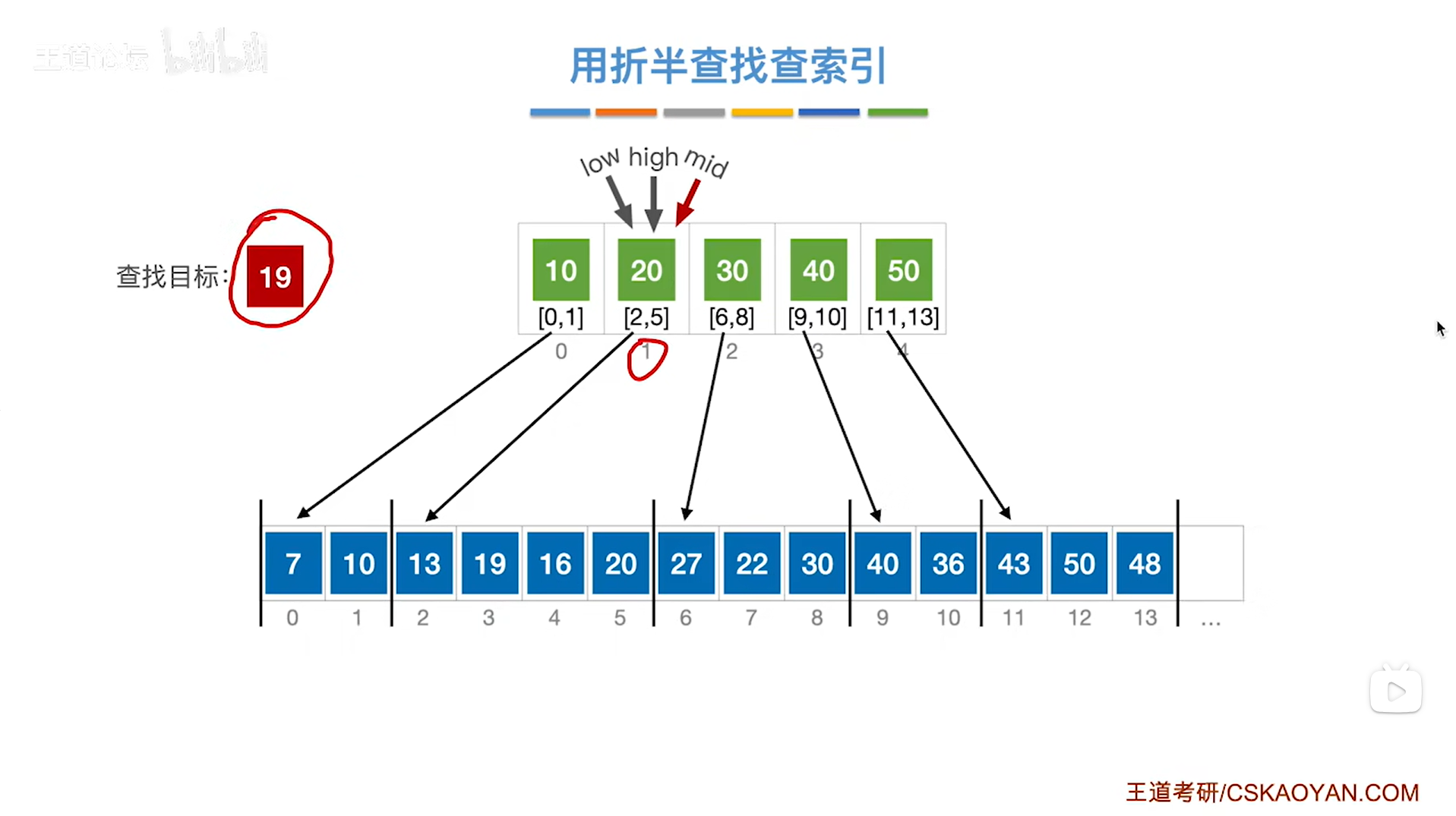
会发现low>high,按照折半查找的规则,到这一步意味着折半查找失败,但实际上要查找的目标关键字19其实是在low指针指向的分块中,所以接下来应该在low指向的分块中进行查找,
如下图:
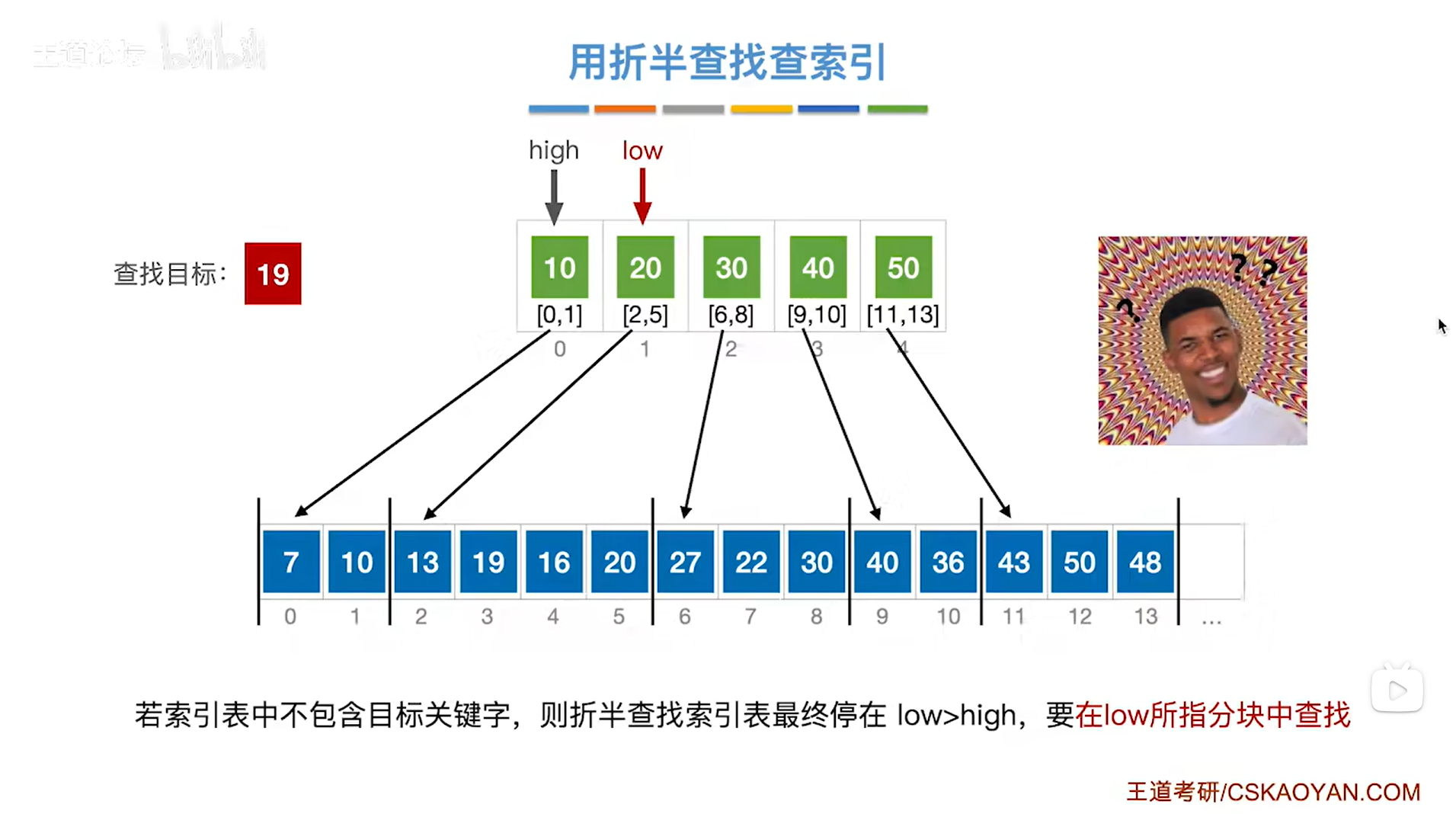
如上图,
类似本例,如果要查找的目标关键字并没有被直接地包含在索引表中,那么对索引表进行折半查找,最终会导致折半查找出现在low>high的情况,
每当发生这种情况的时候,需要在low指针所指的分块中进行下一步的查找,
具体原因如下:
折半查找失败最终的结果是low>high(详情见"7.3.折半查找(二分查找)"),但是在low>high之前的那一步肯定是low=high,所以当low=high时,mid、low、high三个指针指向的是同一个位置,此时可能发生两种情况:假设mid=low=high=a,且索引表中的元素是升序排序
-
第一种情况是中间指针mid所指的分块的最大值小于要查找的目标关键字key,这种情况会让low指针指向mid+1的位置即a+1,high指针不变即high为a,此时mid=(low+high)/2=(a+1+a)=a(C语言会取整),最终low所指的元素一定要比mid所指的元素更大
-
第二种情况是中间指针mid所指的分块的最大值大于要查找的目标关键字key,这种情况会让high指针指向mid-1的位置即a-1,low指针不变即low为a,此时mid=(low+high)/2=(a+a-1)/2=a(C语言会取整),最终low>high的时候,low指针所指向的位置a上的关键字一定会大于要查找的目标关键字(参考例四)
-
注:这种情况下中间指针mid所指的分块的最大值不会等于要查找的目标关键字key(因为题目要求)
再结合索引表的特性,索引表当中保存的是每一个分块中最大的关键字,所以要对索引表中比目标关键字大的那个分块进行查找才有可能找到目标关键字,
通过刚才的分析可知,无论发生哪种情况,当low>high即折半查找失败时,一定是low指针指向的那个分块的关键字比要查找的目标关键字更大,所以这就是为什么最终要查找low指针指向的分块,
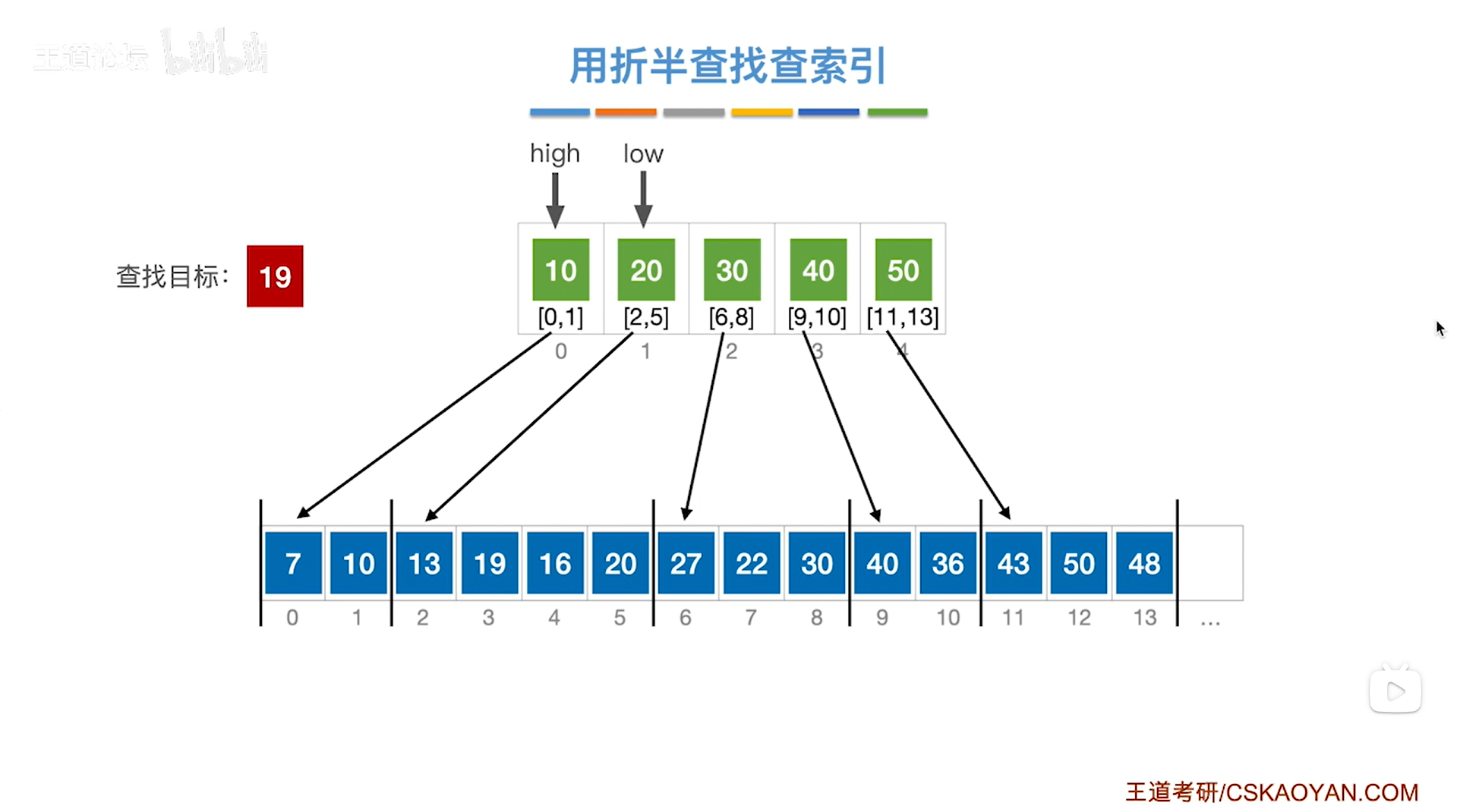
如下图:
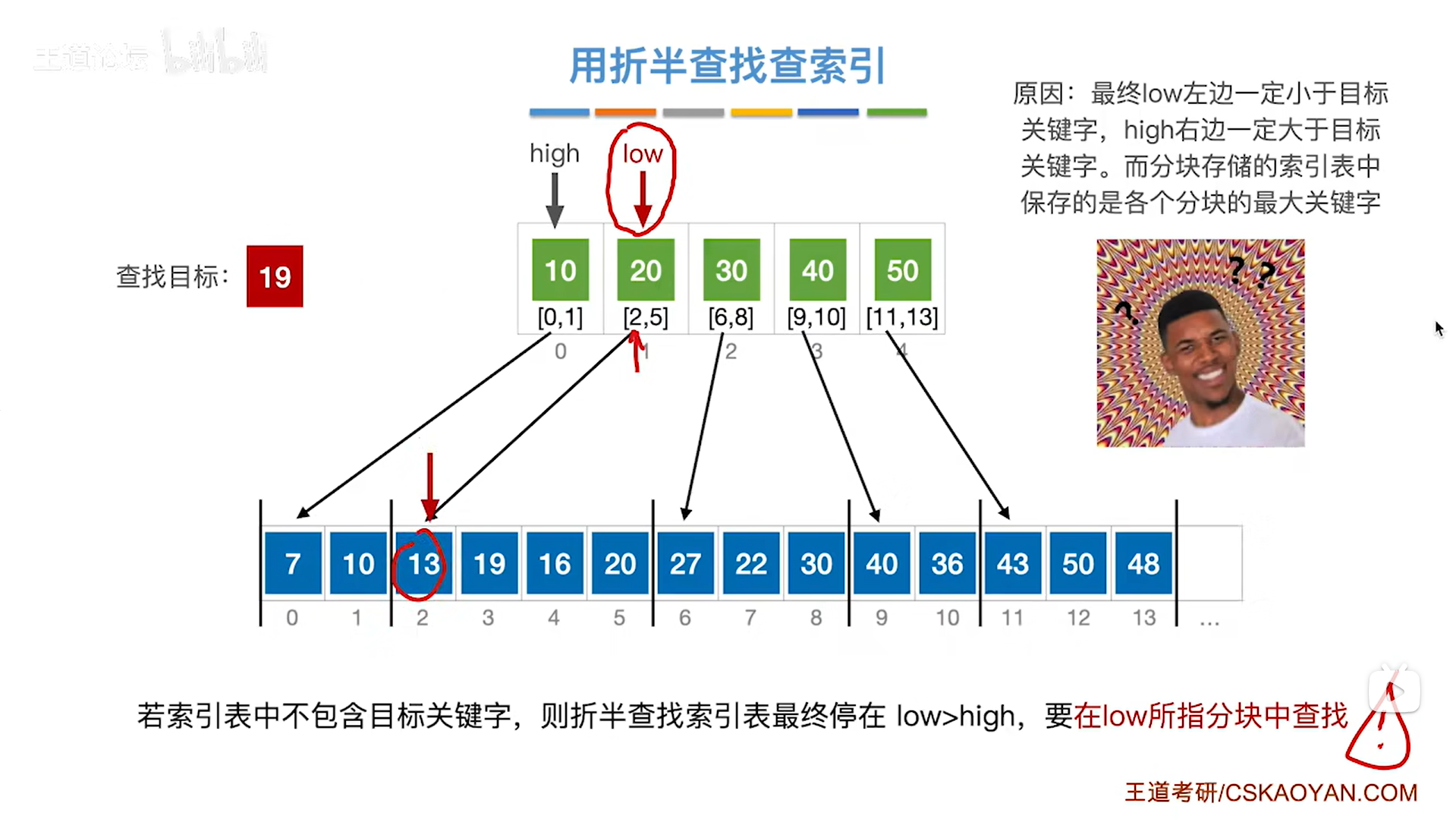
如上图:
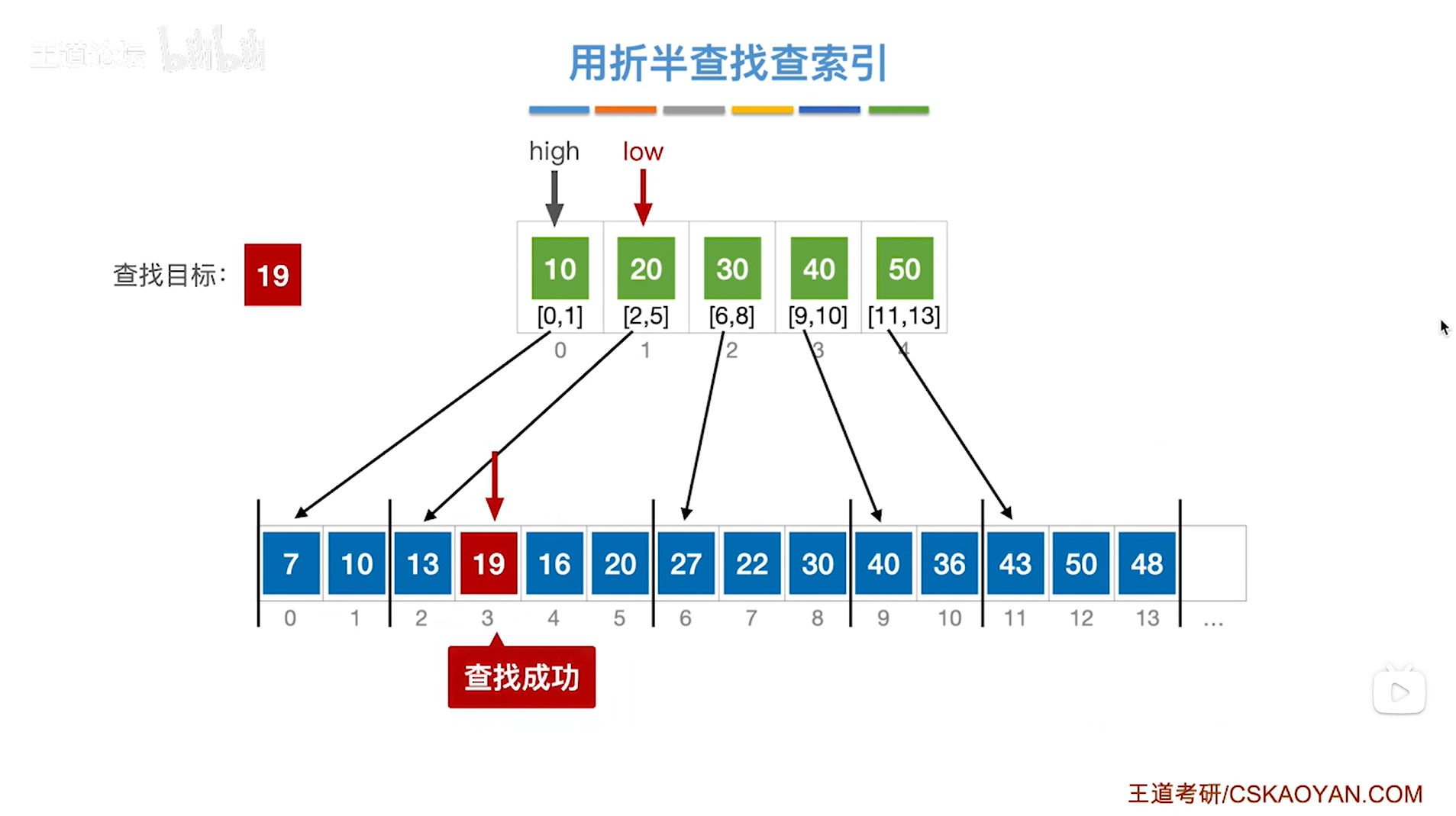
继续例四,通过之前的分析可知,要在low指针指向的分块即顺序表中2索引到5索引的位置上进行顺序查找目标关键字,
首先顺序表里的2索引上的元素13不等于要查找的目标关键字19,
所以要往后找一个索引,因此接下来是3索引上的元素19,与要查找的目标关键19相等,
至此,查找成功,
如下图:
5.例五:对索引表采取折半查找来判断要查找的目标关键字所属的分块
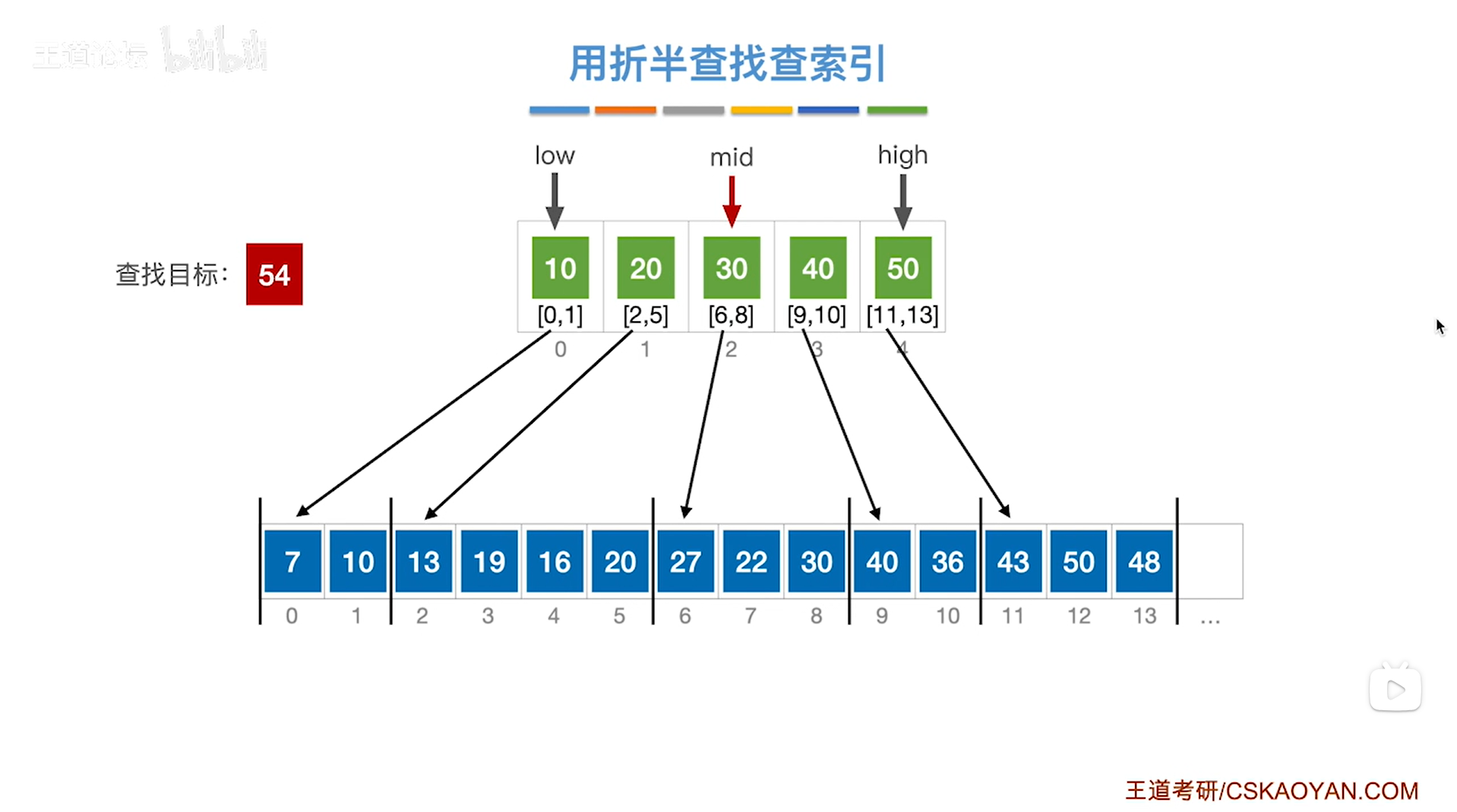
如上图,
如果本次要查找的目标关键字是54,
首先需要查找"索引表",
根据折半查找规则,初始需要通过索引表的开头即low指针指向的位置和索引表的末尾即high指针指向的位置来求出中间指针mid的位置,再尝试找到54这个关键字所属的分块,
初始时low为0,high为4,根据mid=(low+high)/2可知mid等于2,
所以mid初始指向的元素是索引表上2索引的元素30即该分块内的元素都是小于等于30的,
之后根据折半查找的规则(可参考例四),"索引表"最终的查找结果如下,
(注:索引表是按照升序排列的)
如下图:
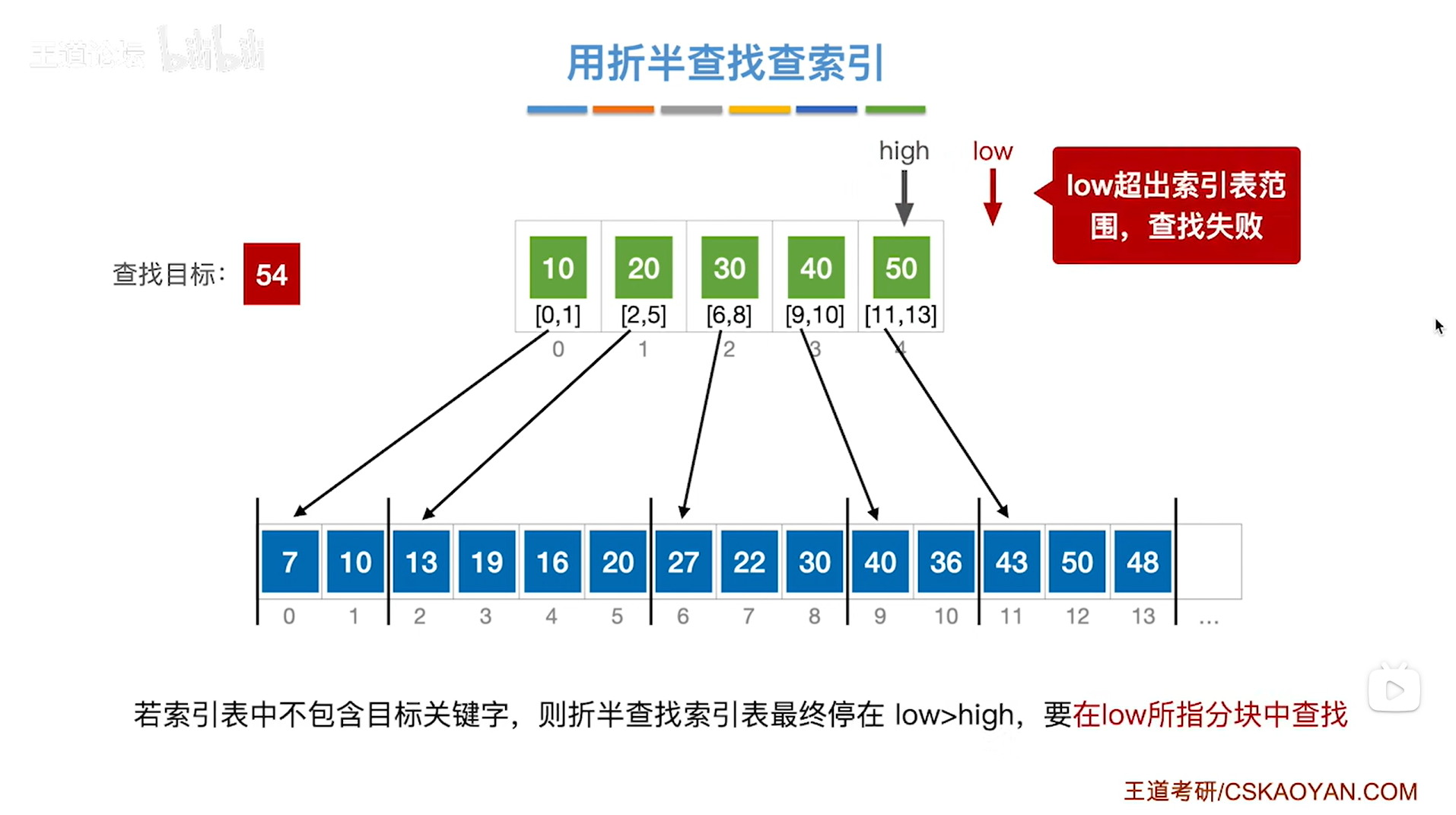
如上图,
最终是high为4,low为5,同样是low>high,
由之前的分析可知,最终要在low所指的分块中进行查找,但是由于现在low所指的分块已经超出了索引表,
因此low指针为空,所以这种情况就意味着查找失败。
6.总结:
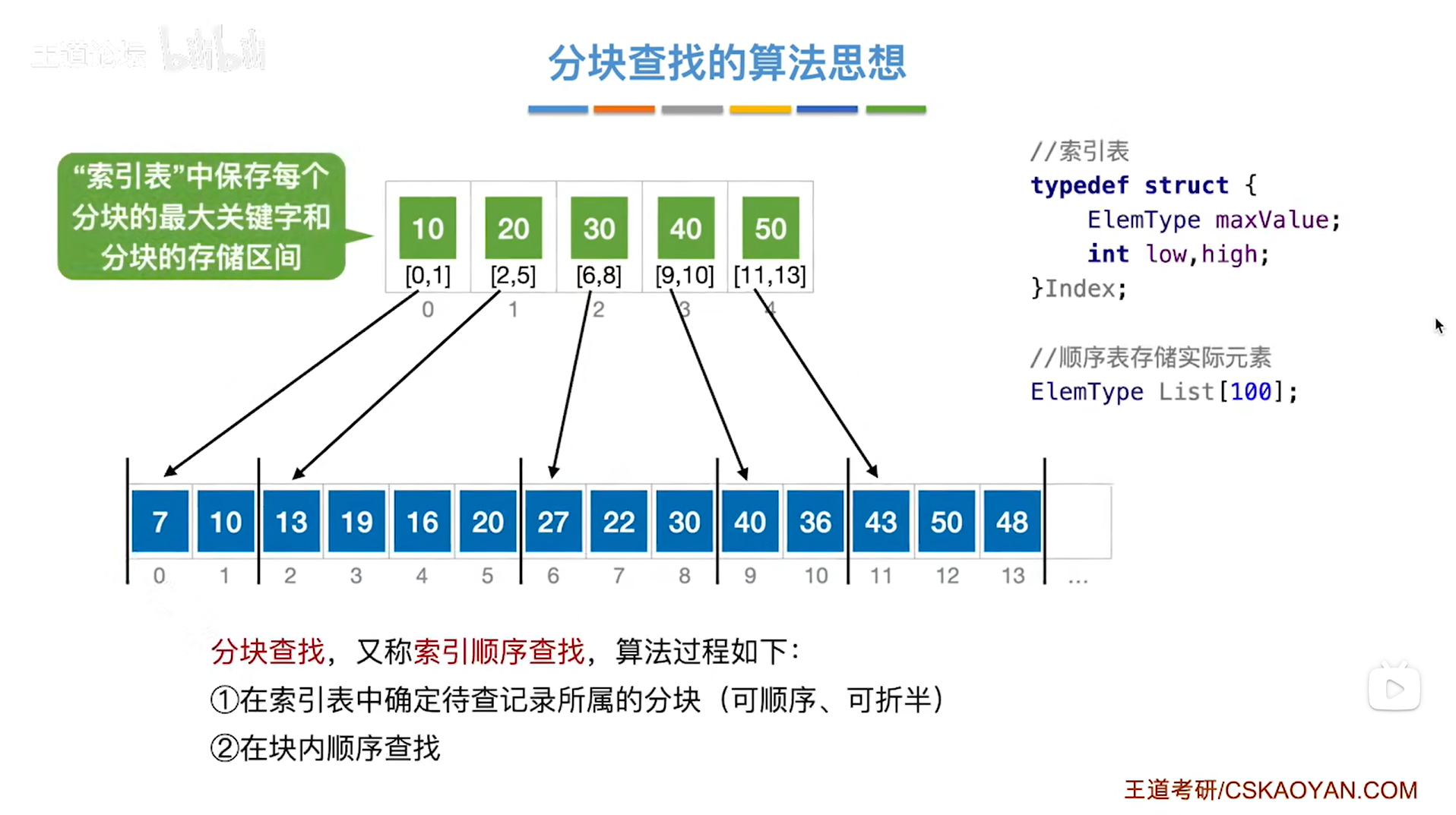
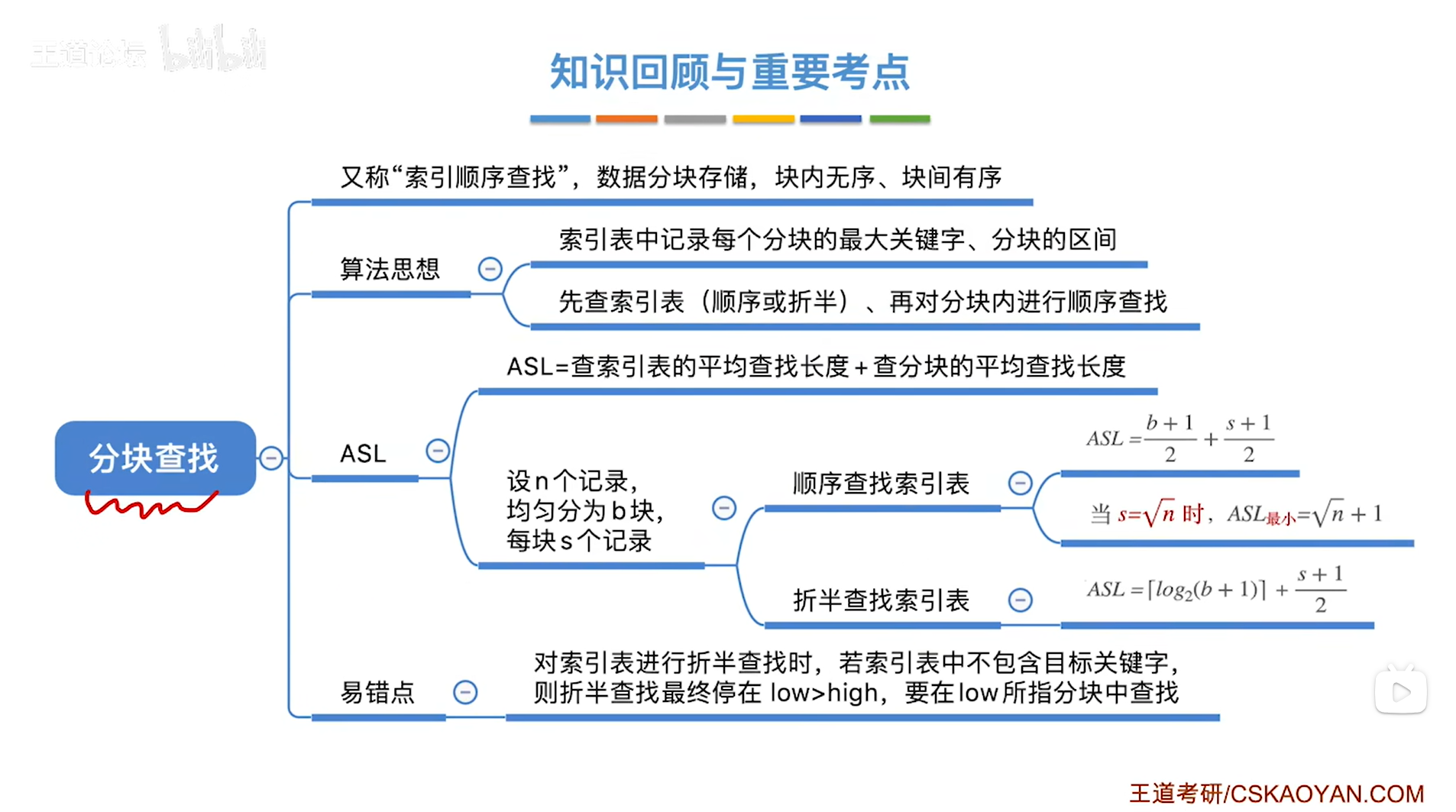
分块查找,又称索引顺序查找(因为刚开始查找的是索引表,然后是在顺序表中顺序查找索引表所指向的分块),算法过程如下:
步骤一:在索引表中确定待查记录所属的分块(注:判断待查记录在哪一个分块,可以通过顺序查找,也可以通过折半查找,因为索引表中保存的元素是有序的,并且索引表是用数组的形式即顺序存储来实现的,所以对索引表的查找也可以使用折半查找)
步骤二:在所属的分块内进行顺序查找(因为分块内的元素大多是乱序存放的,所以只能采取顺序查找来依次往后对比查找)
三.分块查找的查找效率分析(ASL):
1."索引表"采用顺序查找的情况下(查找成功):
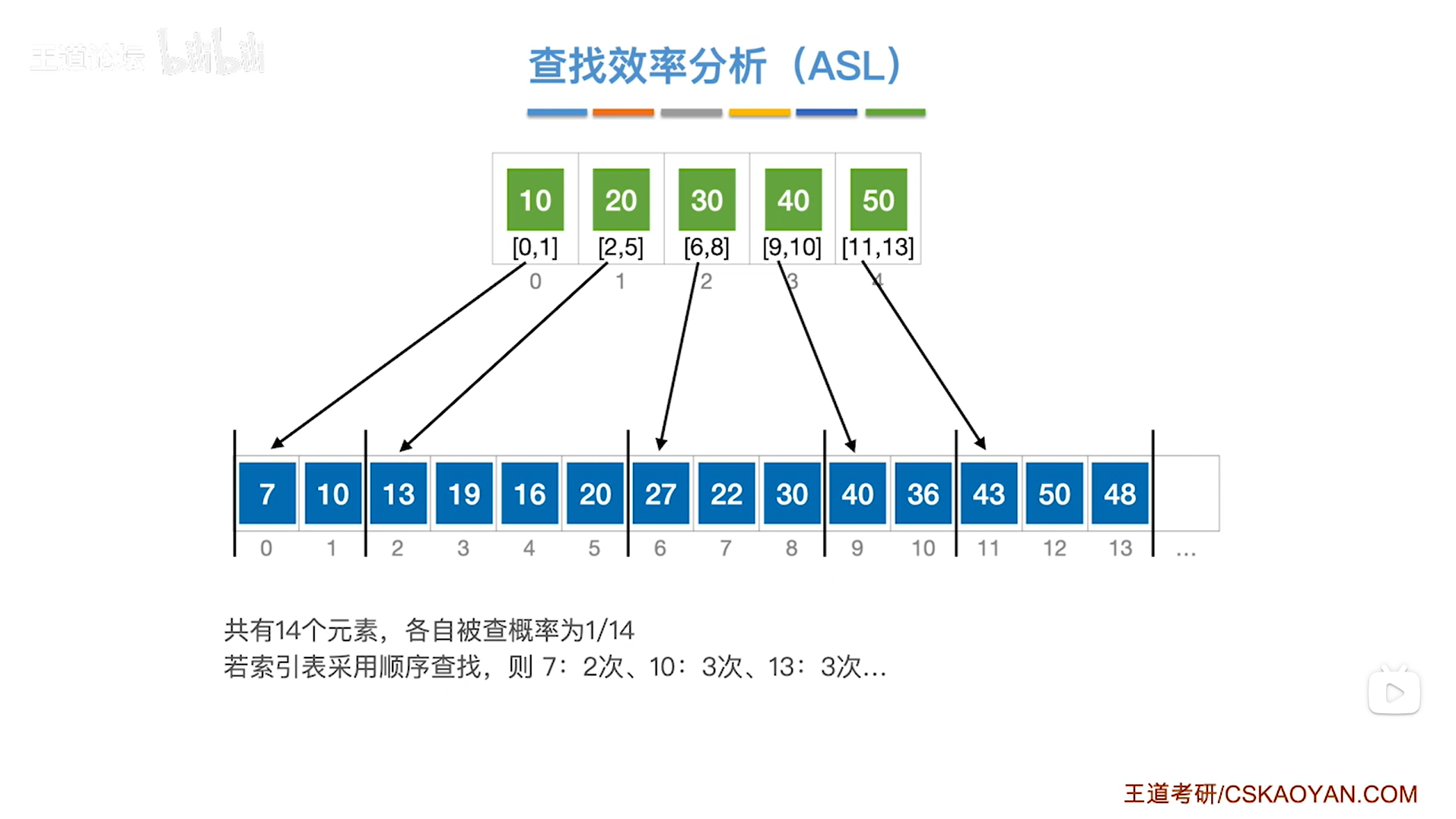
以上述图片的顺序表为例,对应的"索引表"已给出,
顺序表中共有14个数据元素有可能被查找,假设每一个数据元素被查找的概率相等,那么每一个数据元素的查找概率Pi为1/14,
如果对"索引表"采取顺序查找的方式,
假设此时要查找的目标关键字为7,总共需要对比关键字的次数(查找长度)为2次:在"索引表"中对比到第一个关键字就可以确定7所属的分块(此时共对比了1次关键字),在对应的分块中顺序对比到第一个关键字就找到了最终目标7(此时共对比了2次关键字),所以总共需要对比2次关键字即C1为2->所以ASL中的第一项为P1 * C1 = 1/14 * 2;
假设此时要查找的目标关键字为10,总共需要对比关键字的次数(查找长度)为3次:在"索引表"中对比到第一个关键字就可以确定10所属的分块(此时共对比了1次关键字),在对应的分块中顺序对比到第二个关键字就找到了最终目标10(此时共对比了3次关键字),所以总共需要对比3次关键字即C2为3->所以ASL中的第二项为P2 * C2 = 1/14 * 3;
假设此时要查找的目标关键字为13,总共需要对比关键字的次数(查找长度)为3次:在"索引表"中对比到第二个关键字就可以确定13所属的分块(此时共对比了2次关键字),在对应的分块中顺序对比到第一个关键字就找到了最终目标13(此时共对比了3次关键字),所以总共需要对比3次关键字即C3为3->所以ASL中的第三项为P3 * C3 = 1/14 * 3;
之后以此类推,
总之给出特定的例子,就可以分别找出查找每一个关键字所需要对比关键字的次数Ci,再乘以对应的被查找的概率Pi,最后把所有关键字的Pi * Ci相加就可以得到查找成功下的ASL。
2."索引表"采用折半查找的情况下(查找成功):
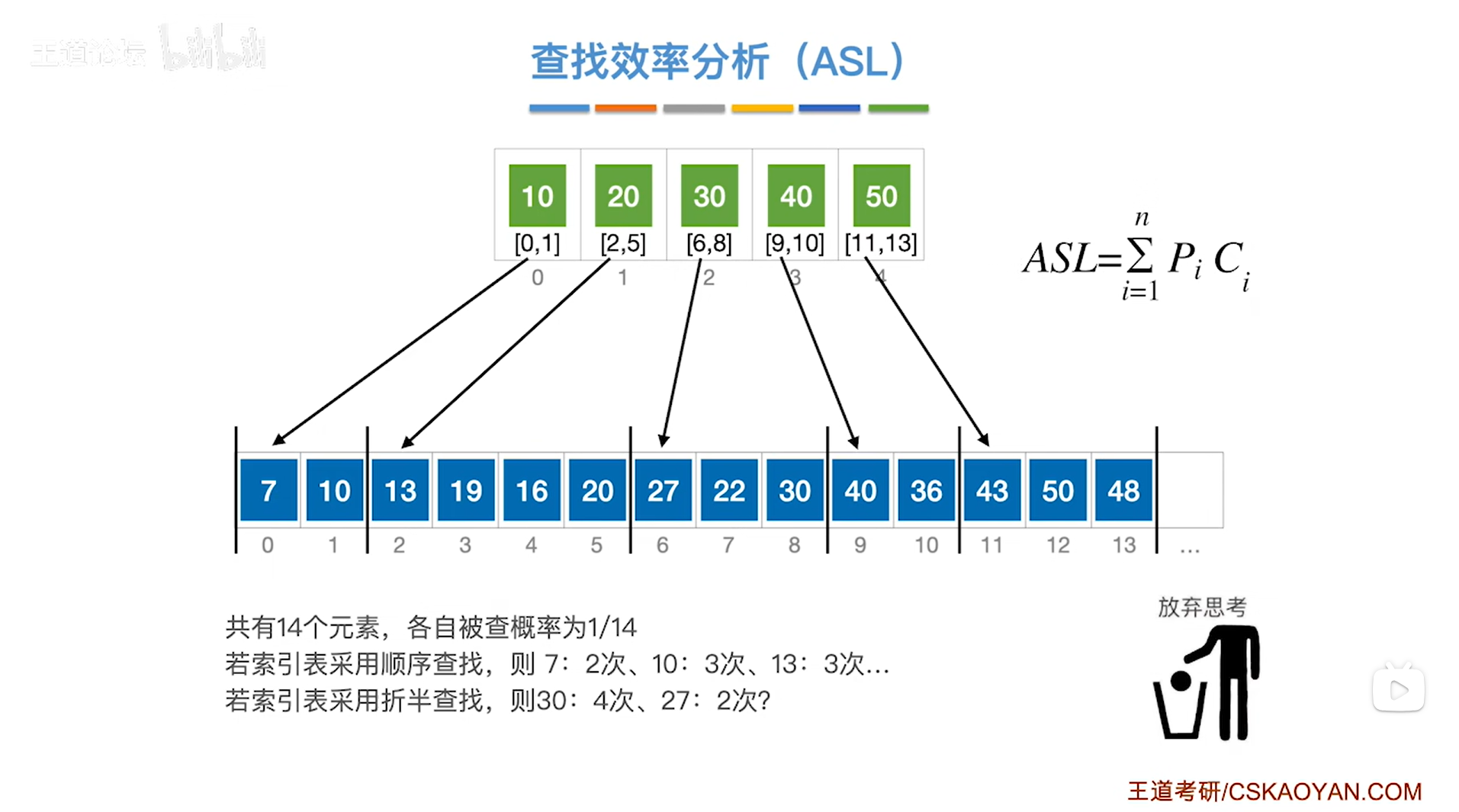
以上述图片的顺序表为例,对应的"索引表"已给出,
顺序表中共有14个数据元素有可能被查找,假设每一个数据元素被查找的概率相等,那么每一个数据元素的查找概率Pi为1/14,
如果对"索引表"采取折半查找的方式,
假设此时要查找的目标关键字为30,根据折半查找的规则可知"索引表"中第一个检查的表象就是2索引上的30即该分块内的元素小于等于30,刚好与要查找的目标关键字30相等,所以经过这1次对比就可以确定要查找的目标关键字30所在于该分块内(2索引上的分块),在该分块内继续需要进行3次关键字的对比即可找到目标关键字30,所以总共需要4次关键字的对比即Ci为4;
类似地,
假设此时要查找的目标关键字为27,根据折半查找的规则可知"索引表"中第一个检查的表象就是2索引上的30即该分块内的元素小于等于30,要查找的目标关键字27比30小,因此可以确定要在该分块内进行查找,所以经过这1次对比就可以确定要查找的目标关键字27所在于该分块内(2索引上的分块),在该分块内继续需要进行1次关键字的对比即可找到目标关键字27,所以总共需要2次关键字的对比即Ci为2,但实际上这是错误的,因为虽然27比30小,但27也比28、29等数要小,无法确定查找27一定就要在30这个分块内查找,如果有28、29等分块,也可能在这些分块内查找,正确的如下->
对于要查找的目标关键字27,根据折半查找的规则可知"索引表"中第一个检查的表象就是中间指针mid即2索引上的30即该分块内的元素小于等于30,第一次对比了30这个表象之后会发现,当前表象的值要比目标关键字27更大,所以要让尾指针即high指针指向中间指针mid-1的位置即1索引处,头指针即low指针不变即指向0索引处,所以折半查找的第一轮并不能确定27所属的分块,必须在折半查找执行到high<low即"索引表"中折半查找失败的情况下,最终是high指向1,low指向2的时候,才可以确定27也是在30所属的分块内,因此要找27的话,对比2次关键字是错误的,具体需要对比几次与之前同理(详情见本篇的"二.4.例四");
之后以此类推,
总之给出特定的例子,就可以分别找出查找每一个关键字所需要对比关键字的次数Ci,再乘以对应的被查找的概率Pi,最后把所有关键字的Pi * Ci相加就可以得到查找成功下的ASL。
3.分块查找中对于查找失败的情况非常复杂,一般不考:
对于分块查找来说,查找失败的情况就很难划分了,
因为"索引表"会出现查找失败的情况,
在各个分块之间,每一个分块里的元素是乱序的,查找时必须采用顺序查找,要得出查找失败也是需要很高的时间复杂度,
所以查找失败的情况不像之前折半查找能够明确划分出由哪些区间导致查找失败,在分块查找中如果要分析查找失败的ASL,分析起来要比查找成功的情况复杂得多。
4.特殊情况1:用顺序查找查索引表
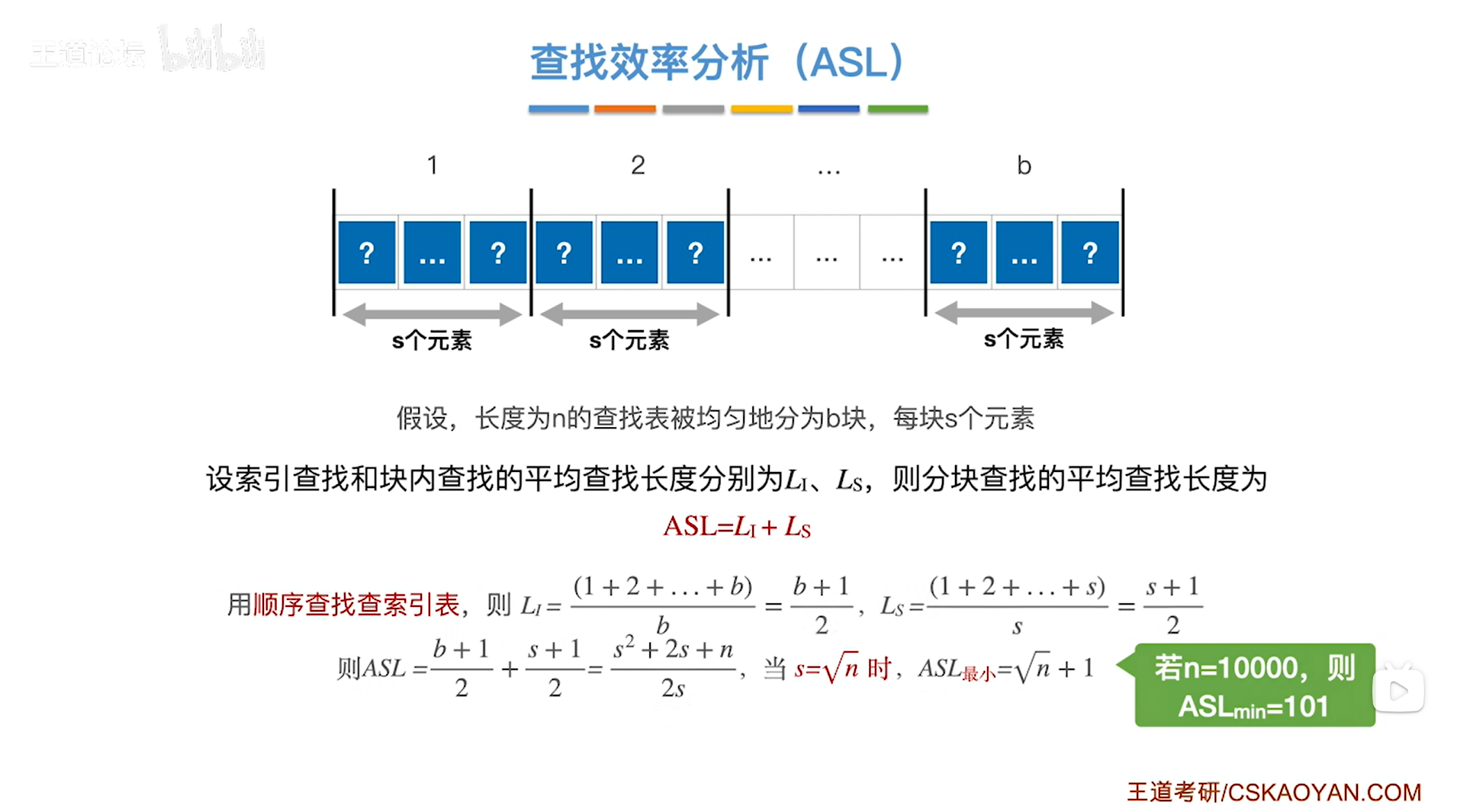
通常情况下分块查找中每一个分块中的数据元素的个数都不相等,因此只能各个分块分开计算,
但是如果各个分块中数据元素的个数是相等的,这种情况下要计算分块查找的ASL,只需要把查找索引表的ASL和查找对应分块内的ASL进行相加,就可以得到总的分块查找的ASL,
以上述图片为例,
假设有一个长度为n的查找表,即查找表中共有n个数据元素,
现在把查找表均匀地分为b块,每块都有s个数据元素,所以就有n = s * b,
如果采用顺序查找的方式查找"索引表",由于总共有b个分块即"索引表"共有b个数据元素,那么查找"索引表"的ASL为Li = (1+2+...+b) * 1/b = (b+1)/2,计算详解如下:
-
"索引表"共有b个数据元素可能被查找,假设每一个数据元素被查找的概率相等,那么每一个数据元素被查找的概率Pi为1/b,由于对"索引表"采用顺序查找,那么"索引表"中查找第一个数据元素的话只需要对比1次关键字即C1为1,查找第二个数据元素的话只需要对比2次关键字即C2为2,以此类推,查找第b个数据元素的话只需要对比b次关键字即Cb为b,所以查找"索引表"的ASL为Li = 1/b * 1 + 1/b * 2 +...+ 1/b * b = (1+2+...+b) * 1/b = (b+1)/2
在确定分块之后,还需要在长度为s的分块内进行顺序查找,对应的ASL为Ls = (1+2+...+s) * 1/s = (s+1)/2,计算详解如下:
-
每一个分块中都有s个数据元素可能被查找,假设每一个数据元素被查找的概率相等,那么每一个数据元素被查找的概率Pi为1/s,由于分块内只能采用顺序查找,那么查找第一个数据元素的话只需要对比1次关键字即C1为1,查找第二个数据元素的话只需要对比2次关键字即C2为2,以此类推,查找第s个数据元素的话只需要对比s次关键字即Cs为s,所以查找分块内的ASL为Ls = 1/s * 1 + 1/s * 2 +...+ 1/s * s = (1+2+...+s) * 1/s = (s+1)/2
最终把查找索引表的ASL和查找对应分块内的ASL相加,就可以得到分块查找的一个完整的ASL,即ASL = (b+1)/2 + (s+1)/2,
由于查找表总共有n个数据元素,被均匀地分为b块,每块都有s个数据元素,因此n = s * b,所以b = n/s,把b = n/s带入ASL = (b+1)/2 + (s+1)/2即可得到ASL = (s * s + 2s + n)/2s,
ASL = (s * s + 2s + n)/2s = s/2 + 1 + n/2s,这就是分块查找在查找成功情况下的ASL。
现在要思考的问题是在什么情况下该ASL最小?其实就是求最值的问题,
根据均值不等式(也可以求导得出,注:n、s、b都是大于等于0的)
ASL = s/2 + 1 + n/2s >= 1+2√s/2 * n/2s = 1+√n,当且仅当s/2=n/2s即s=√n时取等,因此ASL的最小值为1+√n,
所以分块查找的ASL在把n个数据元素分为b块即b=n/s=n/√n=√n块,每一分块中有s即√n个数据元素时ASL最小,ASL的最小值为1+√n。
->比如n=10000即查找表中有10000个数据元素,那么最优的一种分块方案是把这10000个数据元素分成√10000=100块,然后每一块中有√10000=100个数据元素,这种情况下可以得到最小的ASL为1+√10000=1+100=101,意味着平均要对比101次关键字即可找到目标关键字。
相比于顺序查找来说,分块查找的效率提升了很多,如果有10000个数据元素,采用顺序查找的话ASL=1/10000 * 1 + 1/10000 * 2 + ... + 1/10000 * 10000 = (1+2+...+10000)/10000=50000.5,意味着平均要对比50000.5次才可以找到目标关键字,所以采用分块查找要比顺序查找高效得多。
5.特殊情况2:用折半查找查索引表
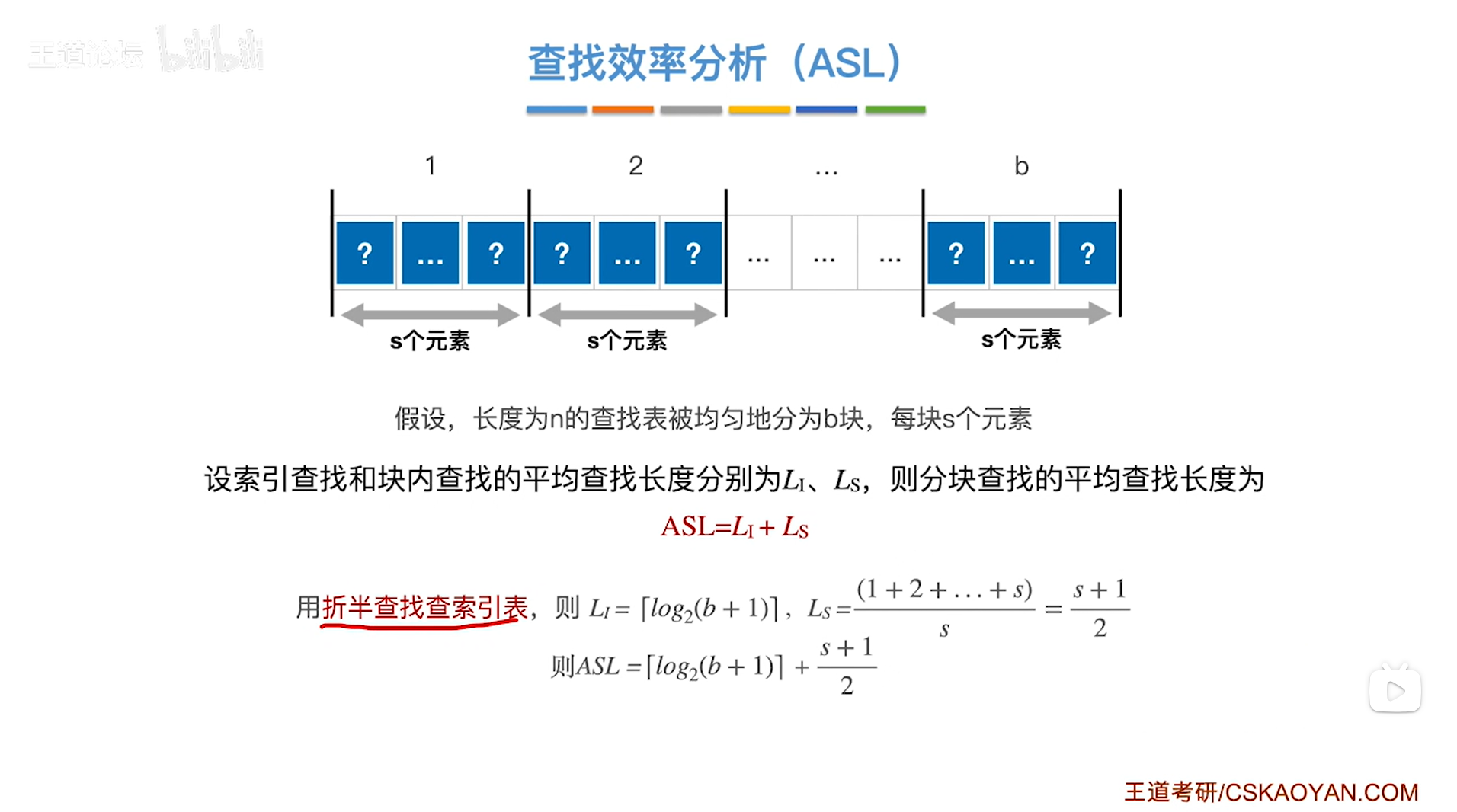
如上图,如果采用折半查找查"索引表",最终可以得到在查找成功的情况下ASL=⌈log₂(b+1)⌉+(s+1)/2。
四.总结:
五.拓展思考:
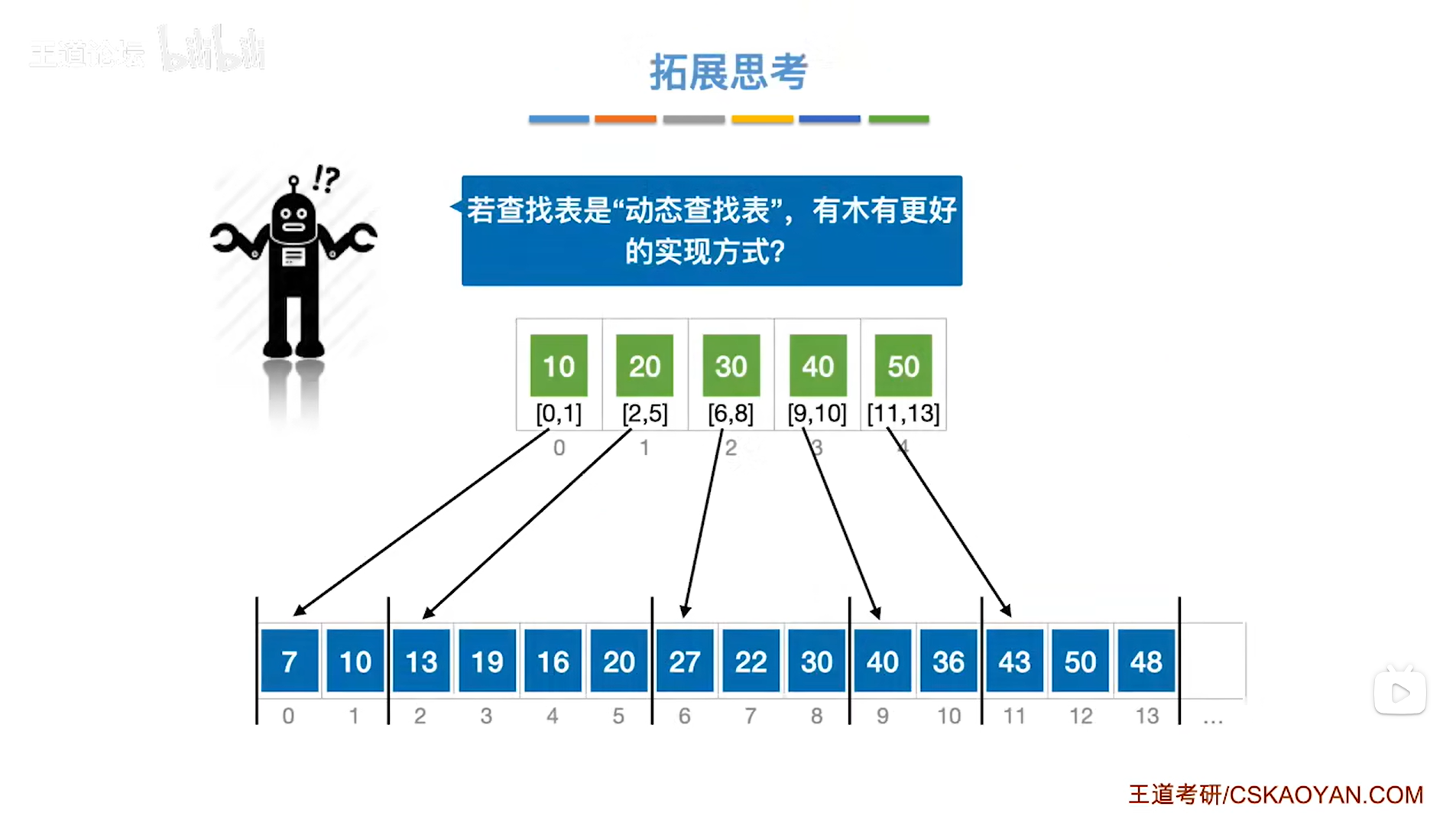
以上述图片为例,
该例中查找表里的数据元素采用了顺序存储,
如果该查找表需要进行元素的增加或者删除时就会效率很低,因为
比如要增加一个数据元素,该数据元素的值是8,
那么数据元素8要插在查找表的末尾吗?显然不对,因为分块查找必须保证块间有序,把数据元素8插在查找表末尾时块间就无序了,
所以如果要插入数据元素8,那么只能在第一个分块内找一个位置插入数据元素8(因为第一个分块存小于等于10的数据元素),这时需要把数据元素8后面的元素全部后移一位,其中产生的时间复杂度会很大,效率很低,
所以采用顺序存储的方式来实现分块查找,只要查找表是动态查找表即需要插入或者删除数据元素,那么要维护整个查找表的块间有序的特点就需要付出很大的代价,因此需要优化,
如下图:
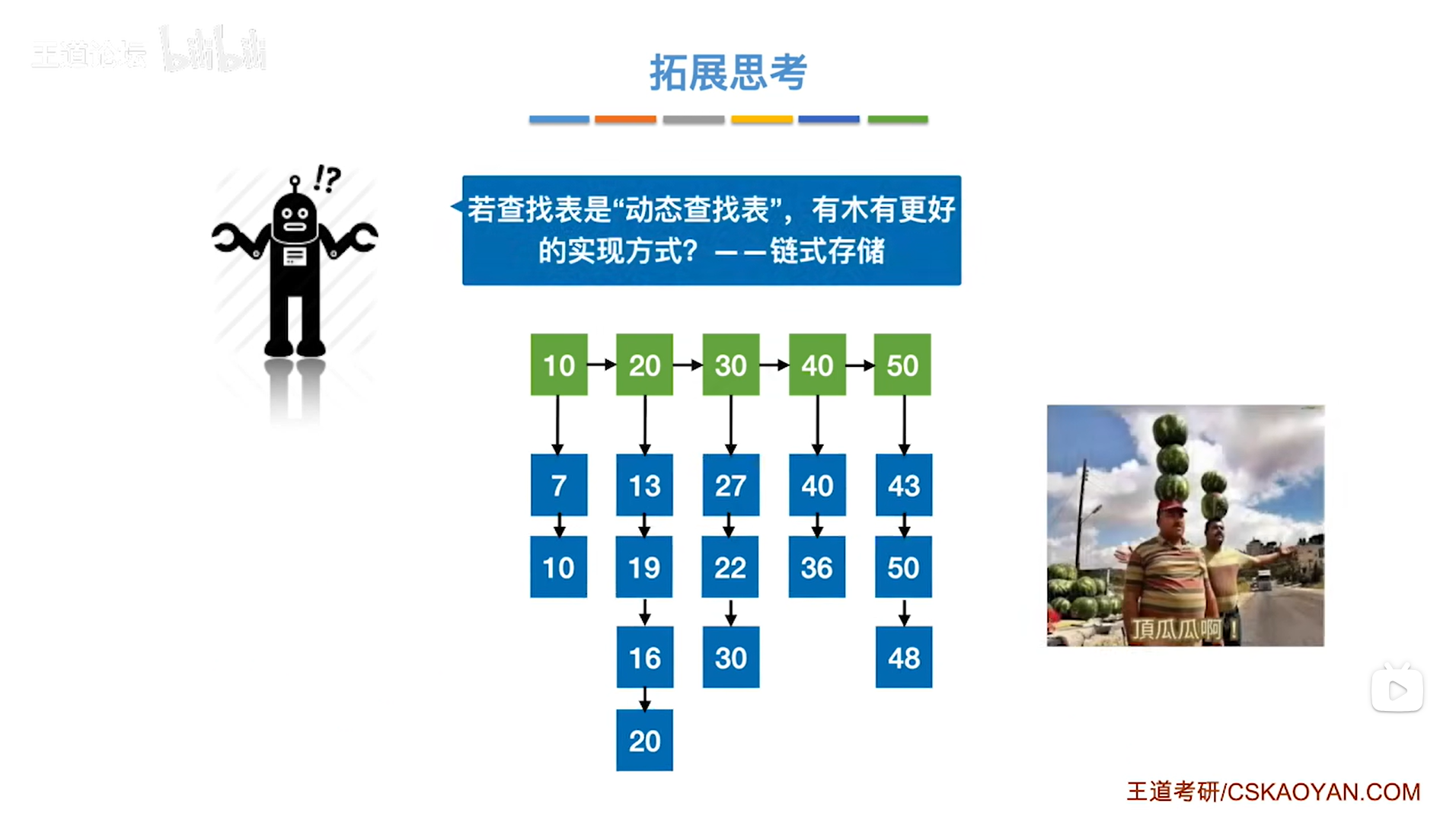
如上图,
可以采用链式存储进行优化查找表以及"索引表",因为链式存储便于插入或者删除数据元素(详情见"2.6.单链表的插入和删除"),
对于索引表的表象可以使用链式存储(也可以使用顺序存储)把它用指针连接起来(上述图片的绿块部分就是"索引表"),各个分块内的数据元素即查找表也可以采用链式存储,
在这种情况下,要插入数据元素8,首先第一步要在索引表中确定数据元素8应该放在哪一个分块,显然是要放入第一个分块,之后只需要把8连接到第一个分块中最后的位置即可,
如下图:

如上图,
同样地,要删除一个数据元素也很简单,
甚至采用链式存储的方式,当某一个分块内元素太多时,就可以很方便地把一个分块进行拆分然后连接到另一个分块上。
相关文章:
7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...