机器学习深度学习——softmax回归从零开始实现
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——向量求导问题
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
就跟之前从零开始实现线性回归一样,softmax回归也很重要,因此也进行一次从0开始实现。之前的章节中,我们已经引入了Fashion-MNIST数据集,并设置数据迭代器的批量大小为256。
import torch
from IPython import display
from d2l import torch as d2lbatch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
softmax回归的从零开始实现
- 初始化模型参数
- 定义softmax操作
- 回顾sum运算符
- 构建softmax运算函数
- 定义模型
- 定义损失函数
- NumPy的整数数组索引
- 交叉熵损失函数定义
- 分类精度
- 训练
- 预测
初始化模型参数
和之前线性回归例子一样,每个样本都用固定长度的向量表示,则之前数据集中每个样本都是28×28的图像,将要进行展平,把他们看做是长度为784的向量。(在这里我们暂且把每个像素的位置都看作是一个特征,其实严格意义上要讨论其空间结构的,在这不做讨论)
而在softmax回归中,我们的输出和类别一样多,因为数据集由10个类别,所以网络输出维度为10。因此,权重将构成一个784×10的矩阵,偏置将构成一个1×10的行向量。与线性回归一样,我们将使用正态分布初始化我们的权重W,偏置初始化为0。
num_inputs = 784
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs),requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
定义softmax操作
回顾sum运算符
按照之前的线性代数的内容,给定一个矩阵X,我们可以利用sum函数给所有元素求和(默认)。也可以对同一列(轴0)或同一行(轴1)进行求和。用例子表示:
X = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
print(X.sum(0, keepdim=True), X.sum(1, keepdim=True)) # keepdim表示还保留着之前维度即二维
结果:
tensor([[5., 7., 9.]]) tensor([[ 6.],
[15.]])
构建softmax运算函数
回想一下softmax的三个步骤:
1、对每个项求幂(使用exp);
2、对每一行求和(因为小批量中每一行就是一个样本),得到每个样本的规范化常数
3、将每一行除以其规范化常数,确保结果的和为1
回顾一下表达式:
s o f t m a x ( X ) i j = e x p ( X i j ) ∑ k e x p ( X i k ) softmax(X)_{ij}=\frac{exp(X_{ij})}{\sum_kexp(X_{ik})} softmax(X)ij=∑kexp(Xik)exp(Xij)
def softmax(X):X_exp = torch.exp(X)partition = X_exp.sum(1, keepdim=True)return X_exp / partition # 广播机制
可以验证上述的代码:
X = torch.normal(0, 1, (2, 5))
X_prob = softmax(X)
print(X_prob, '\n', X_prob.sum(1))
结果:
tensor([[0.0152, 0.1212, 0.6149, 0.0877, 0.1610],
[0.1921, 0.0852, 0.1945, 0.4261, 0.1020]])
tensor([1.0000, 1.0000])
根据概率原理易得每行的和为1
注意:数学上看起来很正确,但是代码实现太草率了。矩阵中的非常大或非常小的元素可能造成数值上溢或下溢,但是这里没有采取措施来防止这一点。
定义模型
也就是直接将y=XW+b进行softmax运算得到,注意下面的X要使用reshape来将每张原始图像展平为向量(轴0放个-1让他自己根据列长度=784来进行运算,这里应为256,因为批量大小为256,每个批量(图像)都被展开成了784的向量)
def net(X):return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
定义损失函数
引入交叉熵函数,这在深度学习中很可能是最常见的损失函数了(目前分类问题数量远超回归问题数量)
回顾一下,交叉熵采用真实标签的预测概率的负对数似然。这边我们不使用for循环这种低效的方式,而是通过一个运算符选择所有函数。在这里我们先介绍下NumPy的整数数组索引。
NumPy的整数数组索引
整数数组索引,它可以选择数组中的任意一个元素,比如,选择第几行第几列的某个元素,示例如下:
import numpy as np
#创建二维数组
x = np.array([[1, 2], [3, 4], [5, 6]])
#[0,1,2]代表行索引;[0,1,0]代表列索引
y = x[[0,1,2],[0,1,0]]
print (y)
结果:
[1 4 5]
对着样例做简单分析:将行、列索引组合会得到 (0,0)、(1,1) 和 (2,0) ,它们分别对应着输出结果在原数组中的索引位置。
下面,我们创建一个数据样本y_hat,其中包含2个样本在3个类别的预测概率,以及它们对应的标签y。然后使用y作为y_hat中概率的索引,我们选择第一个样本中第一个类的概率和第二个样本中第三个类的概率:
y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
print(y_hat[[0, 1], y])
输出:
tensor([0.1000, 0.5000])
交叉熵损失函数定义
那么现在只需要一行就可以实现交叉熵函数了:
def cross_entropy(y_hat, y):return -torch.log(y_hat[range(len(y_hat)), y])
注意,原来的交叉熵损失函数实际上是:
l ( y , y ^ ) = − ∑ j = 1 q y j l o g y ^ j l(y,\hat{y})=-\sum_{j=1}^qy_jlog\hat{y}_j l(y,y^)=−j=1∑qyjlogy^j
其中,q是独热编码的长度,那么容易知道,那个求和符号其实没啥用,因为利用独热编码的话,除了中标的那一项,其他的y中元素全是0。所以引变为代码中的:
l ( y , y ^ ) = − l o g y ^ j l(y,\hat{y})=-log\hat{y}_j l(y,y^)=−logy^j
验证:
print(cross_entropy(y_hat, y))
结果:
tensor([2.3026, 0.6931])
分类精度
给定预测概率分布y_hat,我们要给出硬预测时,通常选择预测概率最高的类。
当预测和标签分类y一致时,就是正确的。分类精度即正确预测数量与总预测数量之比。虽然直接优化精度可能很难(精度计算不可导),但我们总是要关注他。
我们可以进行下面的操作:
若y_hat是矩阵,假定第二维度存储每个类的预测分数,我们就可以使用argmax来获得每行的最大元素的索引,用来获得预测的类别。然后和真实的y比较。(注意,由于等式运算符号"=="对数据类型很敏感,因此我们需要将数据类型转换为一致的。)结果会是一个包含0和1的张量,求和就可以得到正确预测的数量了。
def accuracy(y_hat, y): #@save"""计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1: # 判断是矩阵y_hat = y_hat.argmax(axis=1)cmp = y_hat.astype(y.dtype) == yreturn float(cmp.astype(y.dtype).sum())
我们将继续使用之前定义的变量y_hat和y分别作为预测的概率分布和标签。 可以看到,第一个样本的预测类别是2(该行的最大元素为0.6,索引为2),这与实际标签0不一致。 第二个样本的预测类别是2(该行的最大元素为0.5,索引为2),这与实际标签2一致。 因此,这两个样本的分类精度率为0.5。
print(accuracy(y_hat, y) / len(y))
结果:
0.5
同样,对于任意数据迭代器data_iter可访问的数据集,我们可以评估在任意模型net的精度。
我们先定义一个实用程序类Accumulator用于对多个变量进行累加:
class Accumulator: #@save"""在n个变量上累加"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args): # *号会拆解为元组self.data = [a + float(b) for a, b in zip(self.data, args)] # zip就是把两元组组合起来def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
接着我们定义evaluate_accuracy函数用于计算在指定数据集上模型的精度:
def evaluate_accuracy(net, data_iter): #@save"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]
在上面的evaluate_accuracy函数中,我们在Accumulator实例中创建了2个变量,分别用于存储正确预测的数量和预测的总数量。当我们遍历数据集时,两者都将随着时间的推移而累加。
训练
首先,我们定义一个函数来训练一个迭代周期。(注意:updater是更新模型参数的常用函数,它接受批量大小作为参数。它可以是d2l.sgd函数,也可以是框架的内置优化函数。)
def train_epoch_ch3(net, train_iter, loss, updater): #@save"""训练模型一个迭代周期"""# 将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()# 训练损失总和、训练准确度总和、样本数metric = Accumulator(3)for X, y in train_iter:# 计算梯度并更新参数y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):# 使用Pytorch内置的优化器和损失函数updater.zero_grad()l.mean().backward() # 损失后向传播updater.step() # 更新网络参数else:# 使用定制的优化器和损失函数l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度return metric[0] / metric[2], metric[1] / metric[2]
在展示训练函数实现前,定义一个在动画中绘制数据的应用程序类Animator(会用就行):
class Animator: #@save"""在动画中绘制数据"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):# 增量地绘制多条线if legend is None:legend = []d2l.use_svg_display()self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]# 使用lambda函数捕获参数self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):# 向图表中添加多个数据点if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()display.display(self.fig)d2l.plt.draw()d2l.plt.pause(0.001)display.clear_output(wait=True)
接下来,实现一个训练函数,它会在train_iter访问到的训练数据集上训练一个模型net。该训练函数会运行多个迭代周期。在每个迭代周期结束时,利用test_iter访问到的测试数据集对模型进行评估。我们利用Animator类来可视化训练进度。
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save"""训练模型"""animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch_ch3(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metrics# assert语句表示断言,表达式为False时会触发AssertionError异常assert train_loss < 0.5, train_lossassert train_acc <= 1 and train_acc > 0.7, train_accassert test_acc <= 1 and test_acc > 0.7, test_acc
我们使用之前定义的小批量随机梯度下降来优化模型的损失函数,设学习率为0.1:
lr = 0.1def updater(batch_size):return d2l.sgd([W, b], lr, batch_size)
现在,训练10个迭代周期:
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
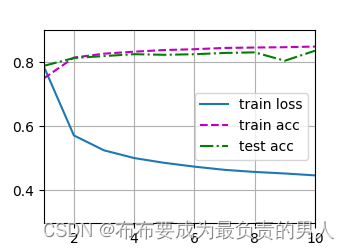
这边是可以跑出动图的,如果跑不出来动态的效果,解决方案:
File ——> Settings ——> Tools ——> Python Scientific ——> 取消勾选 Show plots in toolwindow
(电脑快跑炸了)
预测
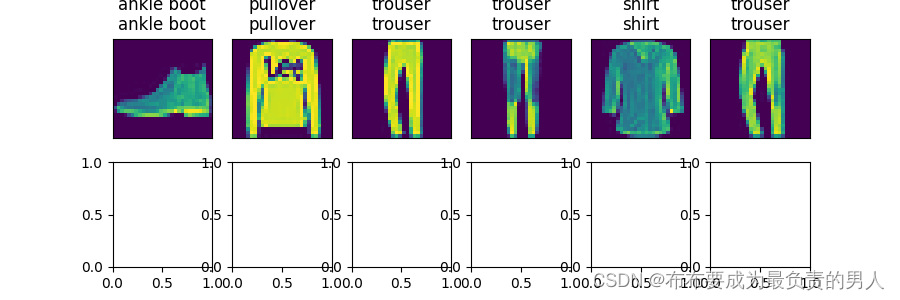
训练已经完成,我们的模型可以进行分类预测了,给定一系列图像,我们将比较它们的实际标签(文本输出的第一行)和模型预测(文本输出的第二行)。
def predict_ch3(net, test_iter, n=6): #@save"""预测标签(定义见第3章)"""for X, y in test_iter:breaktrues = d2l.get_fashion_mnist_labels(y)preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))titles = [true +'\n' + pred for true, pred in zip(trues, preds)]d2l.show_images(X[0:n].reshape((n, 28, 28)), 2, n, titles=titles[0:n])predict_ch3(net, test_iter)
相关文章:
机器学习深度学习——softmax回归从零开始实现
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——向量求导问题 📚订阅专栏:机器学习&&深度学习 希望文章对你们有所帮助 …...

Windows如何安装Django及如何创建项目
目录 1、Windows安装Django--pip命令行 2、创建项目 2.1、终端创建项目 2.2、在Pycharm中创建项目 2.3、二者创建的项目有何不同 2.4、项目目录说明 1、Windows安装Django--pip命令行 安装Django有两种方式: pip命令行【推荐--简单】手动安装【稍微复杂一丢丢…...
)
在CSDN学Golang云原生(监控解决方案Prometheus)
一,记录规则配置 在golang云原生中,通常使用日志库记录应用程序的日志。其中比较常见的有logrus、zap等日志库。这些库一般支持自定义的输出格式和级别,可以根据需要进行配置。 对于云原生应用程序,我们通常会采用容器化技术将其…...
双重for循环优化
项目中有段代码逻辑是个双重for循环,发现数据量大的时候,直接导致数据接口响应超时,这里记录下不断优化的过程,算是抛砖引玉吧~ Talk is cheap,show me your code! 双重for循环优化 1、数据准备2、原始双重for循环3、…...
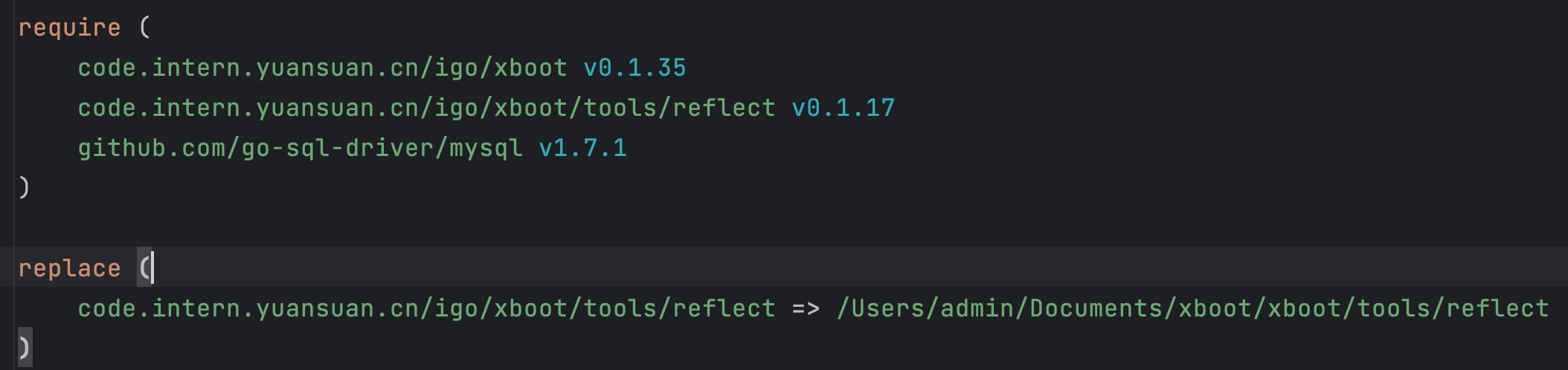
golang利用go mod巧妙替换使用本地项目的包
问题 拉了两个项目下来,其中一个项目依赖另一个项目,因为改动了被依赖的项目,想重新导入测试一下。 解决办法 go.mod文件的require中想要被代替的包名在replace中进行一个替换,注意:用来替换的需要用绝对路径…...

使用 docker 一键部署 MySQL
目录 1. 前期准备 2. 导入镜像 3. 创建部署脚本文件 4. MySQL 服务器配置文件模板 5. 执行脚本创建容器 6. 后续工作 7. 基本维护 1. 前期准备 新部署前可以从仓库(repository)下载 MySQL 镜像,或者从已有部署中的镜像生成文件&#x…...

MyBatis-Plus 查询PostgreSQL数据库jsonb类型保持原格式
文章目录 前言数据库问题背景后端返回实体对象前端 实现后端返回List<Map<String, Object>>前端 前言 在这篇文章,我们保存了数据库的jsonb类型:MyBatis-Plus 实现PostgreSQL数据库jsonb类型的保存与查询 这篇文章介绍了模糊查询json/json…...

Linux操作系统1-命令篇
不同领域的主流操作系统 桌面操作系统 Windos Mac os Linux服务器操作系统 Unix Linux(免费、稳定、占有率高) Windows Server移动设备操作系统 Android(基于Linux,开源) ios嵌入式操作系统 Linux(机顶盒、路由器、交换机) Linux 特点:免费、开源、多用户、多任务…...
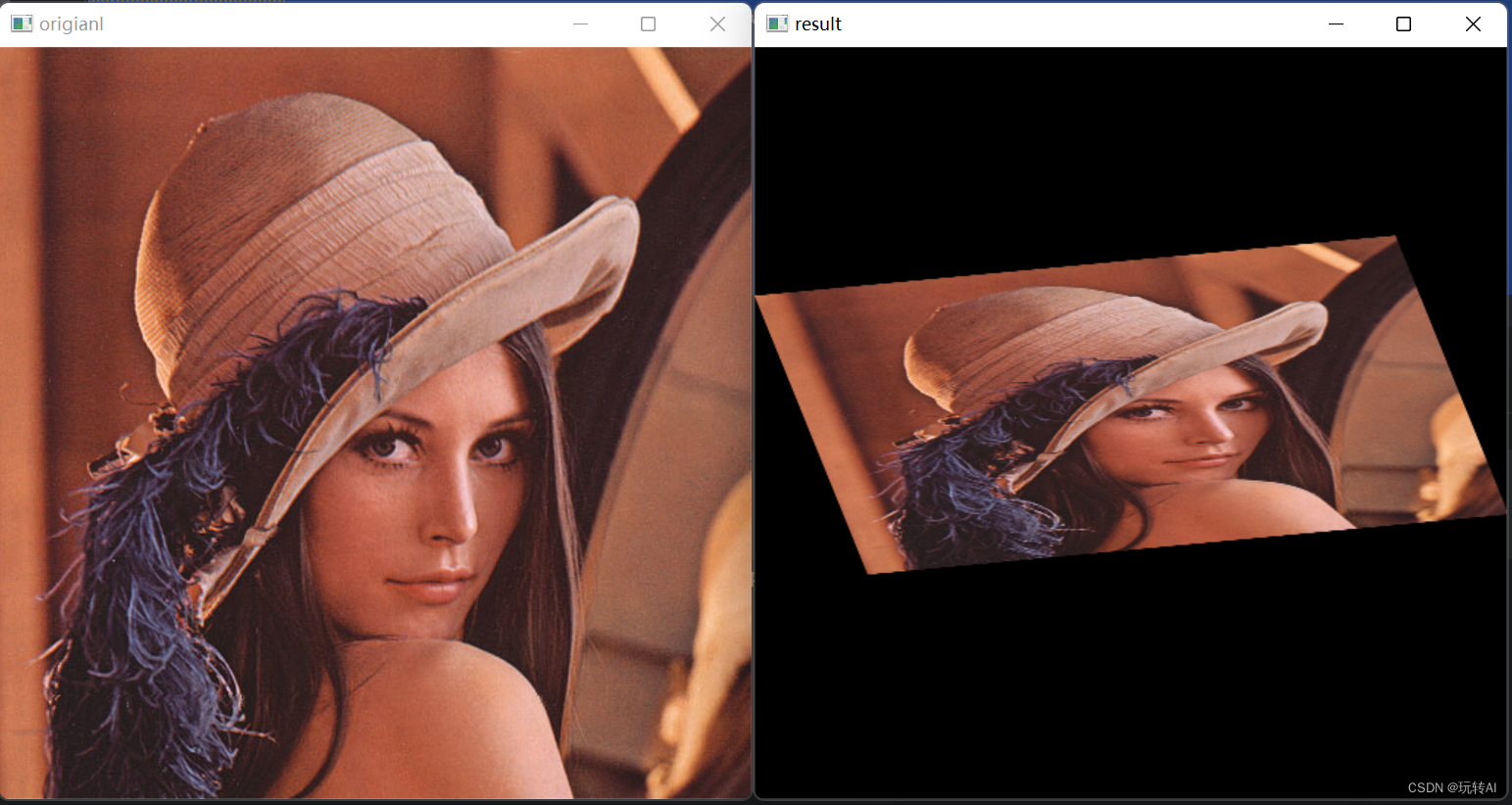
opencv-24 图像几何变换03-仿射-cv2.warpAffine()
什么是仿射? 仿射变换是指图像可以通过一系列的几何变换来实现平移、旋转等多种操作。该变换能够 保持图像的平直性和平行性。平直性是指图像经过仿射变换后,直线仍然是直线;平行性是指 图像在完成仿射变换后,平行线仍然是平行线。…...

前端常用的条件限制方法小笔记
手机号的正则表达式(以1开头的11位数字) function checkPhone(){ var phone document.getElementById(phone).value;if(!(/^1[3456789]\d{9}$/.test(phone))){ alert("手机号码有误,请重填"); return false; } }限制输入大于0且最小值要小于最大值 c…...

【LeetCode 算法】Minimum Operations to Halve Array Sum 将数组和减半的最少操作次数-Greedy
文章目录 Minimum Operations to Halve Array Sum 将数组和减半的最少操作次数问题描述:分析代码TLE优先队列 Tag Minimum Operations to Halve Array Sum 将数组和减半的最少操作次数 问题描述: 给你一个正整数数组 nums 。每一次操作中,你…...

Doc as Code (3):业内人士的观点
作者 | Anne-Sophie Lardet 在技术传播国际会议十周年之际,Fluid Topics 的认证技术传播者和功能顾问 Gaspard上台探讨了“docOps 作为实现Doc as Code的中间结构”的概念。在他的演讲中,观众提出了几个问题,我们想分享Gaspard的见解&#x…...
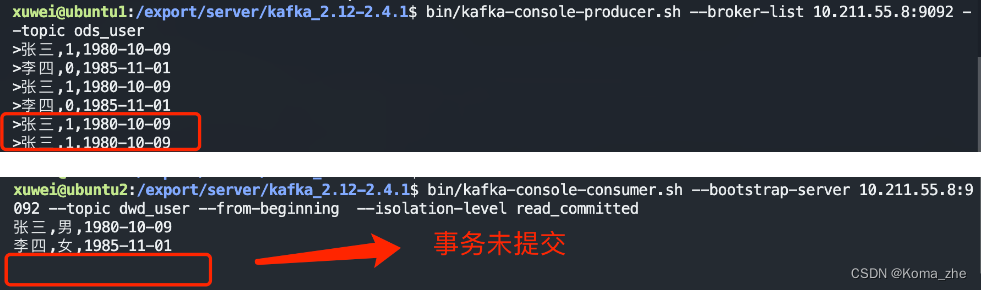
【Kafka】消息队列Kafka基础
目录 消息队列简介消息队列的应用场景异步处理系统解耦流量削峰日志处理 消息队列的两种模式点对点模式发布订阅模式 Kafka简介及应用场景Kafka比较其他MQ的优势Kafka目录结构搭建Kafka集群编写Kafka一键启动/关闭脚本 Kafka基础操作创建topic生产消息到Kafka从Kafka消费消息使…...
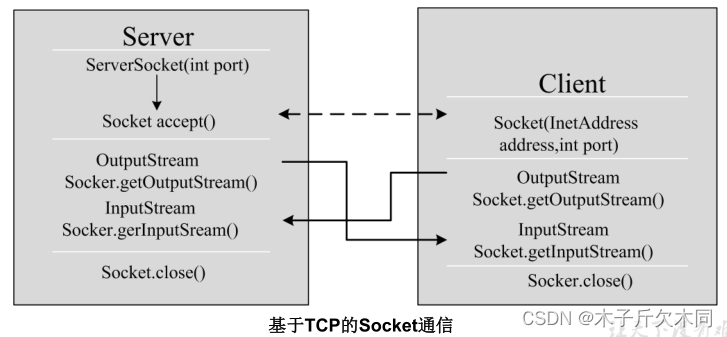
Java的第十五篇文章——网络编程(后期再学一遍)
目录 学习目的 1. 对象的序列化 1.1 ObjectOutputStream 对象的序列化 1.2 ObjectInputStream 对象的反序列化 2. 软件结构 2.1 网络通信协议 2.1.1 TCP/IP协议参考模型 2.1.2 TCP与UDP协议 2.2 网络编程三要素 2.3 端口号 3. InetAddress类 4. Socket 5. TCP网络…...

【深度学习】High-Resolution Image Synthesis with Latent Diffusion Models,论文
13 Apr 2022 论文:https://arxiv.org/abs/2112.10752 代码:https://github.com/CompVis/latent-diffusion 文章目录 PS基本概念运作原理 AbstractIntroductionRelated WorkMethodPerceptual Image CompressionLatent Diffusion Models Conditioning Mec…...

前端学习——Vue (Day6)
路由进阶 路由的封装抽离 //main.jsimport Vue from vue import App from ./App.vue import router from ./router/index// 路由的使用步骤 5 2 // 5个基础步骤 // 1. 下载 v3.6.5 // 2. 引入 // 3. 安装注册 Vue.use(Vue插件) // 4. 创建路由对象 // 5. 注入到new Vue中&…...
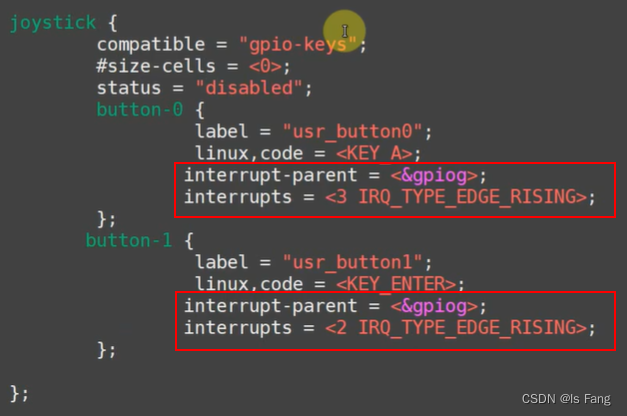
STM32MP157驱动开发——按键驱动(tasklet)
文章目录 “tasklet”机制:内核函数定义 tasklet使能/ 禁止 tasklet调度 tasklet删除 tasklet tasklet软中断方式的按键驱动程序(stm32mp157)tasklet使用方法:button_test.cgpio_key_drv.cMakefile修改设备树文件编译测试 “tasklet”机制: …...
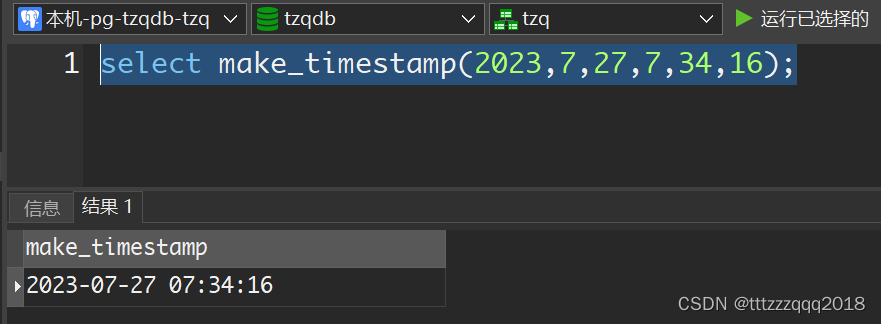
PostgreSQL构建时间
– PostgreSQL构建时间 select make_timestamp(2023,7,27,7,34,16);...

2023-将jar包上传至阿里云maven私有仓库(云效制品仓库)
一、背景介绍 如果要将平时积累的代码工具jar包,上传至云端,方便团队大家一起使用,一般的方式就是上传到Maven中心仓库(但是这种方式步骤多,麻烦,而且上传之后审核时间比较长,还不太容易通过&a…...

嵌入式linux之OLED显示屏SPI驱动实现(SH1106,ssd1306)
周日业余时间太无聊,又不喜欢玩游戏,大家的兴趣爱好都是啥?我觉得敲代码也是一种兴趣爱好。正巧手边有一块儿0.96寸的OLED显示屏,一直在吃灰,何不把玩一把?于是说干就干,最后在我的imax6ul的lin…...

Kubernetes成本优化与资源管理:降低云原生基础设施成本
Kubernetes成本优化与资源管理:降低云原生基础设施成本 一、成本优化概述 Kubernetes成本优化是通过合理配置资源、优化调度策略、选择合适的实例类型等方式,降低云原生基础设施的运营成本。 1.1 成本组成 成本类型说明优化方向计算成本CPU、内存资源…...

遗传算法融合线性规划:超参数调优的高效双层优化策略
1. 项目概述:当遗传算法遇上线性规划,超参数调优的新思路在机器学习项目的落地过程中,有一个环节既让人着迷又令人头疼,那就是超参数调优。模型架构的层数、神经元的数量、学习率、正则化强度……这些“旋钮”的微小转动ÿ…...

上下文是新的算力吗?
在过去六个月里,前沿级AI能力的推理成本下降了约85%。来自Meta、阿里巴巴等公司的开放权重模型,如今在关键基准测试上已经能匹敌上个季度最好的闭源模型。一个曾经每月花费数千美元运行在领先专有模型上的生产工作负载,现在可以用开源替代方案…...

昇腾CANN cann-recipes-infer Continuous Batching:从静态 Padding 到动态调度,吞吐翻 10 倍
LLM 推理服务线上最大的浪费:静态 batching。一个 batch 里 8 个请求,序列长度从 12 到 2048——短的 12 个 token 2ms 就算完了,然后等长的那条跑完。190ms 算力闲置,GPU/NPU 空转。Continuous Batching 的解法:不等—…...

昇腾CANN catlass 模板元编程:零成本抽象的算子融合实战
CUTLASS 是 NVIDIA 的矩阵乘模板库,catlass 是昇腾的对应物——用 C 模板元编程在编译期生成算子,运行时零开销。核心思路:把算子拆成可组合的模板参数,编译期决定一切(tile 大小、数据布局、指令选择)&…...

基于个性化机器学习与智能穿戴数据的痴呆症行为预测系统
1. 项目概述:当智能手表学会“预见”痴呆症患者的情绪风暴在痴呆症照护的漫长征途中,照护者最棘手的挑战往往不是记忆的衰退,而是那些突如其来、难以捉摸的行为与心理症状。想象一下,你照顾的长辈平时温和安静,却在某个…...

老师上课没空做笔记?2026年这3款AI整理工具,下课直接梳理课堂重点
相信很多同学和我一样,上课最纠结的就是记笔记这件事。老师讲课节奏很快,知识点一环扣一环,一边要认真听讲、跟上课堂思路,一边又要低头写字,稍微分心就错过关键考点。遇到网课、回放课就更头疼了,整节课视…...

多路召回RAG系统
项目采用 多路召回 Rerank的RAG架构,核心入口是 RagSpecialistAgent.java,当用户与问答助手进行语言交流时,输入查询,首先先进行意图识别,判断是单任务还是多任务,并且判断是否需要RAG检索,因为…...
)
AI动态简报之算力基建篇(2026.05.24)
关注方向:大模型 GPU算力 AI芯片 云计算 大模型API⚡ 第1条:全球九大云厂商资本支出上调至8300亿美元,年增79%核心信息:TrendForce集邦咨询最新报告将2026年全球九大CSP(谷歌、AWS、Meta、微软、甲骨文、字节跳动、…...

基于IoT、DRL与3DCNN的智能森林火灾监测系统设计与实践
1. 项目概述:一个融合感知、决策与验证的智能防火哨兵森林火灾的早期发现是遏制其蔓延、减少生态与经济损失的关键。传统的人工瞭望塔监测方式不仅效率低下、覆盖范围有限,而且严重依赖人力,难以实现全天候、大范围的持续监控。近年来&#x…...