(学习笔记-内存管理)内存分段、分页、管理与布局
内存分段
程序是由若干个逻辑分段组成的,比如可由代码分段、数据分段、栈段、堆段组成。不同的段是有不同的属性的,所以就用分段的形式把这些分段分离出来。
分段机制下,虚拟地址和物理地址是如何映射的?
分段机制下的虚拟地址由两部分组成,段选择因子和段内偏移量

- 段选择因子:保存在段寄存器里面。段选择因子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级等。
- 虚拟地址中的段内偏移量应该位于 0 和段界限之间,如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
上图中展示了虚拟地址与物理地址通过段表映射关系,分段机制会把程序的虚拟地址分成 4 个段,每个段在段表中有一个项,在这一项找到段的基地址,再加上偏移量,于是就能找到物理内存中的地址,如下图:
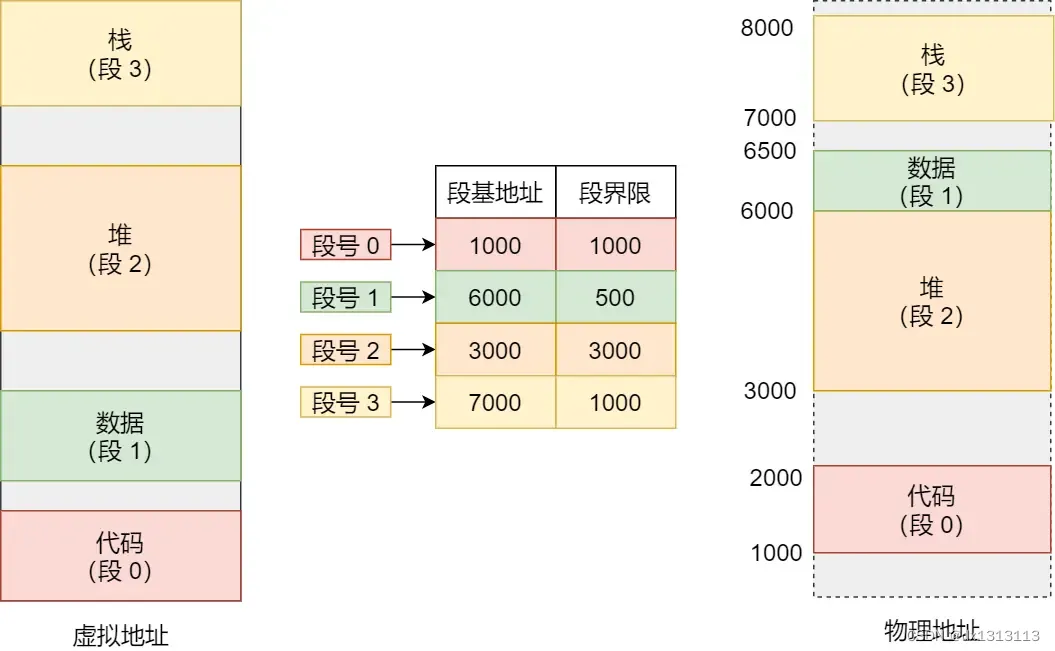
如果要访问段3中偏移量为 500 的虚拟地址,我们可以计算出物理地址为:7000(段3基地址) + 500(偏移量) = 7500。
分段的方法很好,解决了程序本身不需要关心具体的物理内存地址的问题,但是也有一些不足之处:
- 内存碎片问题
- 内存交换的效率低
分段产生的内存碎片问题
假设有 1 G的物理内存,用户执行了多个程序,其中:
- 游戏占用了 512MB 内存
- 浏览器占用了 128MB 内存
- 音乐占用了 256 MB 内存
这个时候,如果我们关闭了浏览器,空闲内存还有1024-512-256 = 256MB。
如果这个256MB不是连续的,被分成了两段128MB内存,这就会导致没有空间再打开一个200MB的程序。

内存分段会出现内存碎片吗?
内存碎片主要分为:内部内存碎片和外部内存碎片
内存分段管理可以做到段根据实际需求分配内存,所以有多少需求就分配多大的段,所以就不会出现内部内存碎片。
但是由于每个段的长度不固定,所以多个段未必能恰好使用所有的内存空间,会产生多个不连续的小物理内存,导致新的程序无法被装载,所以会出现外部内存碎片的问题。
解决[外部内存碎片]的问题就是内存交换。
可以把音乐程序占用的那256MB内存写到硬盘上,然后再从硬盘上读回内存里。不过再读回时,不能装载到原来的位置,而是紧紧地跟在已经被占用的512MB内存后面。这样就能空缺出连续的256MB内存空间,于是新的200MB程序就可以装载进来。
这个内存交换空间,在Linux系统里,也就是常看到的Swap空间,这块空间是从硬盘划分出来的,用于内存与硬盘的空间交换。
分段导致的内存交换效率低的问题
对于多进程的系统来说,用分段这个方式,外部内存碎片是很容易产生的,产生了外部内存碎片,那不得不重新 Swap 内存区域,这个过程会产生性能瓶颈。
因为硬盘的访问速度比内存慢太多了,每一次内存交换,都需要把一大段连续的内存数据写到硬盘上。
所以,如果内存交换的时候,交换的是一个占用内存空间很大的程序,这样整个机器就会显得卡顿。
为了解决内存分段的[外部内存碎片和内存交换效率低]的问题,就出现了内存分页。
内存分页
分段的好处是能产生连续的内存空间,但是会出现 [外部内存碎片和内存交换·的空间太大] 的问题。
要解决这些问题,那么就要想出能少一些内存碎片的办法。另外,当需要进行内存交换的时候,让需要写入或者从磁盘装载的数据更少一点,这样就解决问题了。这个办法也就是内存分页
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页。在Linux下,每一页的大小为 4KB 。
虚拟地址与物理地址之间通过页表来映射,如图:

页表是存储在内存里的,内存管理单元(MMU)就做将虚拟内存地址转换成物理地址的工作。
当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入系统内核空间分配物理内存,更新进程页表,最后再返回用户空间,恢复进程的运行。
分页如何解决[外部内存碎片和内存交换效率低]的问题?
内存分页是由于内存空间都是预先划分好的,也就不会像内存分段那样,在段与段之间产生间隙非常小的内存,这正是分段会产生外部内存碎片的原因。而采用了分页,页与页之间是紧密排列的,所以不会有外部碎片。
但是,因为内存分页机制分配内存的最小单位是一页,即使不足一页大小,我们最少只能分配一页,所以页内会出现内存浪费,所以针对内存分页机制会有内部内存碎片的现象
如果内存空间不够,操作系统会把其他正在运行的进程中的[最近没被使用]的内存页面给释放掉,也就是暂时写在硬盘上,称为换出(wap out)。一旦需要的时候,再加载进来,称为换入(swap in)。所以,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,内存交换的效率就相对比较高。

更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性把程序都加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
分页机制下,虚拟地址和物理地址是如何映射的?
在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个地址与页内偏移的组合就形成了物理内存地址,如下图:

总结:对于一个内存地址转换,其实就是这样三个步骤:
- 把虚拟内存地址,切分成页号和偏移量
- 根据页号,从页表里面,查询对应的物理号
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。

但放到实际的操作系统重,这样简单的分页肯定是有问题的。
简单分页的缺陷
有空间上的缺陷。
因为操作系统是可以同时运行非常多的进程的,这就意味着页表会非常庞大。
在32位的环境下,虚拟地址空间有 4 GB ,假设一个页的大小是 4KB,那么就需要大约100万个页,每个[页表项]需要四个字节大小来存储,那么整个4GB空间的映射就需要有4MB的内存来存储页表。
这4MB大小的页表看起来不是很大,但是要知道每个进程都是有自己的虚拟地址空间的,也就是说都有自己的页表。那么 100 个进程的话,就需要 400MB 的内存来存储页表,这已经是非常大的内存了,更别说64位系统了。
多级页表
要解决上面的问题就需要采用一种叫做多级页表的解决方案。(可以理解为将单级页表进行分组,下面例子中是每1024个单级页分为一组,如果某一组页表项没被用到,就不需要创建该组的二级页表,节省了页表的总空间)
在前面我们知道了,对于单页表的实现方式,在32位和页大小为4KB的环境下,一个进程的页表需要装下100多万个[页表项],并且每个页表项是占用 4 字节大小的,于是相当于每个页表需占用 4MB 大小的空间。
我们把这个100多万个[页表项]的单级页表再分页,将页表(一级页表)分为 1024 个页(二级页表),每个表(二级页表)中包含1024个[页表项],形成二级分页:

分了二级表,映射4GB地址空间就需要4KB(一级页表)+4MB(二级页表)的内存,这样占用空间不是更大了吗?
如果4GB的虚拟地址都映射到了物理内存上的话,二级分页占用空间确实更大了,但是我们往往不会为一个进程分配那么多的内存。
每个进程都有4GB的虚拟地址空间,而显然对于大多数程序来说,其使用的空间远达不到4GB,因为会存在部分对应的页表项都是空的根本没有分配,对于已分配的页表项,如果存在最近一定时间未访问的页表,在物理内存紧张的情况下,操作系统会将页面换出到硬盘,也就是说不会占用物理内存。
如果使用了二级分页,一级页表就可以覆盖整个 4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表对应的二级页表了,即可以在需要时才创建二级页表。做个简单计算,假设只有20%的一级1页表项被用到了,那么页表占用的内存空间就只有4KB(一级页表) + 20%*4MB(二级页表) = 0.804MB,这对比单级页表的 4MB 节省了大量的空间。
为什么不分级的页表就做不到这样节约内存呢?
我们从页表的性质来看,保存在内存中的页表承担的职责是将虚拟地址翻译成物理地址。假如虚拟地址在页表中找不到对应的页表项,计算机系统就不能工作了。所以页表一定要覆盖全部的虚拟地址空间,不分级的页表就需要有100多万个页表项来映射,而二级分页则只需要1024个页表项(此时一级页表覆盖了全部的虚拟地址空间,二级页表在需要时创建)
对于64位的系统,两级分页肯定不够,就变成了四级目录,分别是:
- 全局页目录项 PGD
- 上层页目录项 PUD
- 中间页目录项 PMD
- 页表项 PTE
TLB
多级页表虽然解决了空间上的问题,但是虚拟地址到物理地址的先转换就多了几道转换的工序,显然就降低了这两地址的转换速度,也就是带来了时间上的开销。
程序是有局部性的,即在一段时间内,整个程序的执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域。
我们就可以利用这一特性,把最常访问的几个页表存储到访问速度更快的硬件,于是在CPU芯片中,加入了一个专门存放程序最常访问页表项 的 cache,这个cache就是TLB ,通常成为页表缓存、转址旁路缓存、快表等。
在CPU芯片里面,封装了内存管理单元(MMU)芯片,它用来完成地址转换和TLB的访问和交互
有了TLB后,CPU寻址时,会先查TLB,如果没找到,才会继续查常规的页表。
TLB的命中率其实是很高的,因为程序最常访问的页就那么几个。
段页式内存管理
内存分段和内存分页并不是对立的,它们是可以组合起来再同一个系统中使用的,那么组合起来后,通常成为段页式内存管理。
段页式内存管理实现方式:
- 先将程序划分为多个有逻辑意义的段,也就是前面提到的分段机制
- 接着再把每个段划分为多个页,也就是对分段划分出来的连续空间,再划分固定大小的页
这样地址结构就由 段号、段内页号和页内位移 三部分组成。
用于段页式地址变换的数据结构是每个程序一张段表,每个段又建立一张页表,段表中的地址是页表的起始地址,而页表中的地址为某页的物理页号,如图:

段页式地址变换中要得到物理地址须经过三次内存访问:
- 第一次访问段表,得到页表起始地址;
- 第二次访问页表,得到物理页号
- 第三次将物理页号与页内位移组合,得到物理地址。
可用软、硬件相结合的方法实现段页式地址的变换,这样虽然增加了硬件成本和系统开销,但提高了内存的利用率。
Linux内存布局
intel处理器额的发展历史
早期的intel的处理器从80286开始使用的是段式内存管理。但是很快发现光有段式内存管理而没有页式内存管理是不够的,这会使X86系列失去市场的竞争力。因此,在不久以后得80386中就实现了页式内存管理。也就是说,80386除了完成并完善从80286开始的段式内存管理的同时还实现了页式内存管理。
但是这个80386的页式内存管理设计时,没有绕开段式内存管理,而是建立在段式内存管理的基础上,这就意味着,页式内存管理的作用是在由段式内存管理所映射而成的地址上再加上一层地址映射。
此时由段式内存管理映射而成的地址不再是 物理地址 了,Intel就称之为 线性地址 (也称为虚拟地址),于是,段式内存管理先将逻辑地址映射成线性地址,然后再由分页内存管理将线性地址映射成物理地址。
- 程序所使用的地址,通常是没被段式内存管理映射的地址,称为逻辑地址
- 通过段式内存管理映射的地址,称为线性地址,或者虚拟地址

Linux内存主要采用的是页式内存管理,但同时也不可避免地涉及了段机制。
这主要是上面Intel处理器发展历史导致的,因为Intel X86CPU一律对程序中使用的地址先进行段式映射,然后才能进行页式映射。
但事实上,Linux内核所采取的办法是使段式映射的过程实际上不起什么作用。
Linux系统中的每个段都从0地址开始的整个 4GB 虚拟空间(32位环境下),也就是所有的段的起始地址都是一样的。这意味着,Linux系统中的代码,包括操作系统本身的代码和应用程序代码,所面对的地址空间都是线性地址空间(虚拟地址),这种做法相当于屏蔽了处理器中逻辑地址的概念,段只被用于访问控制盒内存保护。
Linux的虚拟地址空间如何分布?
在Linux操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同位数的系统,地址空间的范围也不同。比如常见的32位和64位系统,如下图所示:

这里可以看出:
- 32 位系统的内核空间占 1G ,位于最高处,剩下的 3G 是用户空间
- 64 位系统的内核空间和用户空间都是128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
内核空间和用户间的区别:
- 进程在用户态时,只能访问用户空间内存
- 只有在进入内核态的时候才能访问内核空间的内存
虽然每个程序都有自己独立的虚拟地址,但是每个虚拟内存中的内核地址,其实关联的都是相同的物理内存,这样,进程在切换到内核态后,就可以很方便地访问内核空间内存。

进一步了解虚拟空间的划分情况,用户空间和内核空间划分的方式是不同的。
以32位操作系统为例,用户空间分布的情况如图所示:
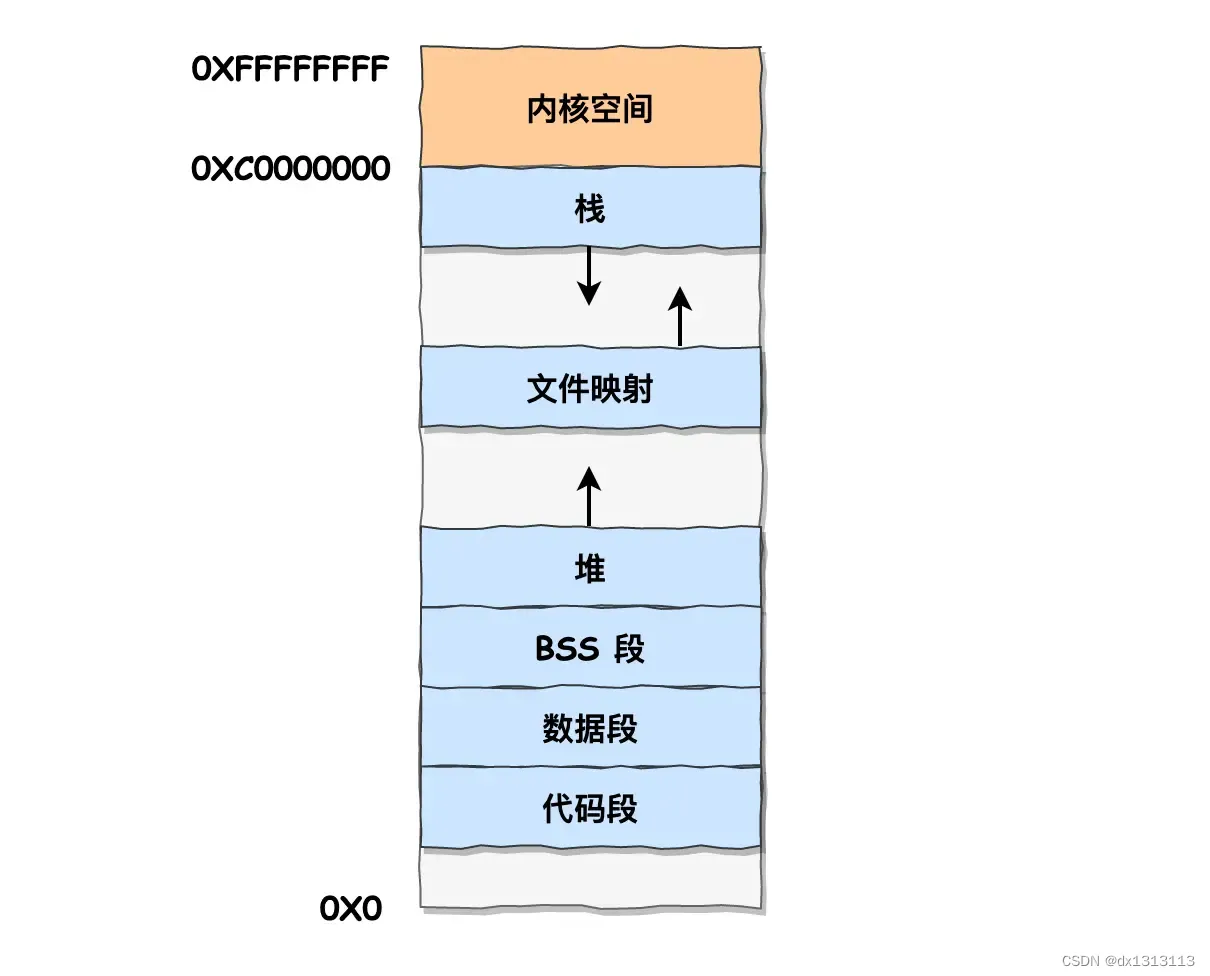
通过这张图,可以看到,用户空间内存从低到高分别是6种不同的内存段:
- 代码段,包括二进制可执行代码
- 数据段,包括已初始化的静态常量和全局变量
- BSS段,包括未初始化的静态变量和全局变量
- 堆段,包括动态分配的内存,从低地址开始向上增长
- 文件映射段,包括动态库、共享内存等,从低地址开始向上增长
- 栈段,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8MB。当然系统也提供了参数,以便我们自定义大小;
上图中的内存布局可以看到,代码段下面还有一段内存空间(灰色部分),这一块区域是[保留区],之所以要有保留区是因为在大多数系统里,我们认为比较小数值的地址不是一个合法地址。例如我们通常在C的代码里会将无效的指针赋值位NULL。因此,这里会出现一段不可访问的内存保留区,防止程序因为出现BUG,导致读或写了一些小内存地址的数据。
总结
为了在多进程的环境下,使得进程之间的内存地址不受影响,相互隔离,于是操作系统就为每个进程单独分配一套虚拟内存地址,每个程序只关心自己的虚拟地址就可以,实际上大家的虚拟地址都是一样的,但分布到的物理内存地址是不一样的。
每个进程都有自己的虚拟空间,而物理内存只有一个,所以当启用了大量的进程,物理内存必然会很紧张,于是操作系统会通过内存交换技术,把不常使用的内存暂时存放到硬盘(换出),在需要的时候再装载回物理内存(换入)。
既然有了虚拟内存地址,那必然要把虚拟地址[映射]到物理地址,这个过程通常由操作系统维护。
那么对于虚拟地址和物理地址的映射关系,可以有分页和分段的方式,同时结合两者[段页式]也可以。
内存分段是根据程序的逻辑角度,分成了栈段、堆段、数据段、代码段等,这样可以分离出不同属性的段,同时是一块连续的空间。但是每个段的大小都不是统一的,这就会导致外部内存碎片和内存交换效率低的问题。
于是,就出现了内存分页,把虚拟空间和物理空间分成大小固定的页,如在 Linux 系统中,每一页的大小为 4KB。由于分了页后,就不会产生细小的内存碎片,解决了内存分段的外部内存碎片问题。同时在内存交换的时候,写入硬盘也就一个页或几个页,这就大大提高了内存交换的效率。
为了解决简单分页产生的页表过大的问题,就有了多级页表,它解决了空间上的问题,但这就会导致 CPU 在寻址的过程中,需要有很多层表参与,加大了时间上的开销。于是根据程序的局部性原理,在 CPU 芯片中加入了 TLB,负责缓存最近常被访问的页表项,大大提高了地址的转换速度。
Linux 系统主要采用了分页管理,但是由于 Intel 处理器的发展史,Linux 系统无法避免分段管理。于是 Linux 就把所有段的基地址设为 0,也就意味着所有程序的地址空间都是线性地址空间(虚拟地址),相当于屏蔽了 CPU 逻辑地址的概念,所以段只被用于访问控制和内存保护。
另外,Linux 系统中虚拟空间分布可分为用户态和内核态两部分,其中用户态的分布:代码段、全局变量、BSS、函数栈、堆内存、映射区。
相关文章:
(学习笔记-内存管理)内存分段、分页、管理与布局
内存分段 程序是由若干个逻辑分段组成的,比如可由代码分段、数据分段、栈段、堆段组成。不同的段是有不同的属性的,所以就用分段的形式把这些分段分离出来。 分段机制下,虚拟地址和物理地址是如何映射的? 分段机制下的虚拟地址由…...
PHP使用Redis实战实录1:宝塔环境搭建、6379端口配置、Redis服务启动失败解决方案
宝塔环境搭建、6379端口配置、Redis服务启动失败解决方案 前言一、Redis安装部署1.安装Redis2.php安装Redis扩展3.启动Redis 二、避坑指南1.6379端口配置2.Redis服务启动(1)Redis服务启动失败(2)Redis启动日志排查(3&a…...
【数据结构】这堆是什么
目录 1.二叉树的顺序结构 2.堆的概念及结构 3.堆的实现 3.1 向上调整算法与向下调整算法 3.2 堆的创建 3.3 建堆的空间复杂度 3.4 堆的插入 3.5 堆的删除 3.6 堆的代码的实现 4.堆的应用 4.1 堆排序 4.2 TOP-K问题 首先,堆是一种数据结构,一种特…...
FFmpeg 音视频开发工具
目录 FFmpeg 下载与安装 ffmpeg 使用快速入门 ffplay 使用快速入门 FFmpeg 全套下载与安装 1、FFmpeg 是处理音频、视频、字幕和相关元数据等多媒体内容的库和工具的集合。一个完整的跨平台解决方案,用于录制、转换和流式传输音频和视频。 官网:http…...

Go 语言 select 都能做什么?
原文链接: Go 语言 select 都能做什么? 在 Go 语言中,select 是一个关键字,用于监听和 channel 有关的 IO 操作。 通过 select 语句,我们可以同时监听多个 channel,并在其中任意一个 channel 就绪时进行相…...
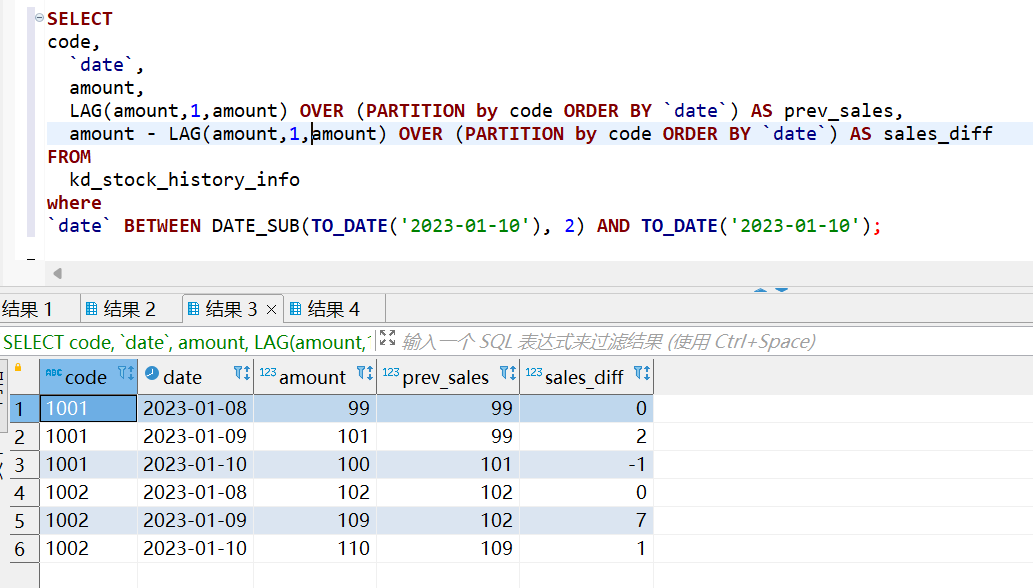
Hive之窗口函数lag()/lead()
一、函数介绍 lag()与lead函数是跟偏移量相关的两个分析函数 通过这两个函数可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤,该操作可代替表的自联接,且效率更高 lag()/lead() lag(c…...

Vite+Typescript+Vue3学习笔记
ViteTypescriptVue3学习笔记 1、项目搭建 1.1、创建项目(yarn) D:\WebstromProject>yarn create vite yarn create v1.22.19 [1/4] Resolving packages... [2/4] Fetching packages... [3/4] Linking dependencies... [4/4] Building fresh packages...success Installed…...
二、SQL-6.DCL-2).权限控制
*是数据库和表的通配符,出现在数据库位置上表示所有数据库,出现在表名位置上,表示所有表 %是主机名的通配符,表示所有主机。 e.g.所有数据库(*)的所有表(*)的所有权限(a…...

[OpenStack] GPU透传
GPU透传本质就是PCI设备透传,不算是什么新技术。之前按照网上方法都没啥问题,但是这次测试NVIDIA A100遇到坑了。 首先是禁用nouveau 把intel_iommuon rdblacklistnouveau写入/etc/default/grub的cmdline,然后grub2-mkconfig -o /etc/grub2.c…...

无涯教程-jQuery - Progressbar组件函数
小部件进度条功能可与JqueryUI中的小部件一起使用。一个简单的进度条显示有关进度的信息。一个简单的进度条如下所示。 Progressbar - 语法 $( "#progressbar" ).progressbar({value: 37 }); Progressbar - 示例 以下是显示进度条用法的简单示例- <!doctype …...

[SQL挖掘机] - 窗口函数 - rank
介绍: rank() 是一种常用的窗口函数,它为结果集中的每一行分配一个排名(rank)。这个排名基于指定的排序顺序,并且在遇到相同的值时,会跳过相同的排名。 用法: rank() 函数的语法如下: rank() over ([pa…...

VBAC多层防火墙技术的研究-状态检测
黑客技术的提升和黑客工具的泛滥,造成大量的企业、机构和个人的电脑系统遭受程度不同的入侵和攻击,或面临随时被攻击的危险。迫使大家不得不加强对自身电脑网络系统的安全防护,根据系统管理者设定的安全规则把守企业网络,提供强大的、应用选通、信息过滤、流量控制、网络侦…...
PHP8的数据类型-PHP8知识详解
在PHP8中,变量不需要事先声明,赋值即声明。 不同的数据类型其实就是所储存数据的不同种类。在PHP8.0、8.1中都有所增加。以下是PHP8的15种数据类型: 1、字符串(String):用于存储文本数据,可以使…...

明晚直播:可重构计算芯片的AI创新应用分享!
大模型技术的不断升级及应用落地,正在推动人工智能技术发展进入新的阶段,而智能化快速增长和发展的市场对芯片提出了更高的要求:高算力、高性能、灵活性、安全性。可重构计算区别于传统CPU、GPU,以指令驱动的串行执行方式…...
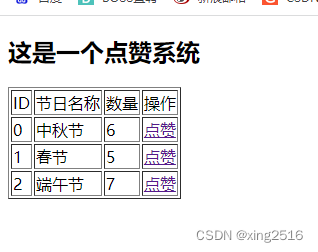
flask 点赞系统
dianzan.html页面 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>点赞系统</title> </head> <body><h2>这是一个点赞系统</h2><table border"1"><…...
关于Java的多线程实现
多线程介绍 进程:进程指正在运行的程序。确切的来说,当一个程序进入内存运行,即变成一个进程,进程是处于运行过程中的程序,并且具有一定独立功能。 线程:线程是进程中的一个执行单元,负责当前进…...

如何判断某个视频是深度伪造的?
目录 一、前言 二、仔细检查面部动作 三、声音可以提供线索 四、观察视频中人物的身体姿势 五、小心无意义的词语 深造伪造危险吗? 一、前言 制作深度伪造视频就像在Word文档中编辑文本一样简单。换句话说,您可以拍下任何人的视频,让他…...

ESP32(MicroPython) 四足机器人(一)
最近决定研究一下四足机器人,但市面上的产品,要么性价比低,要么性能达不到要求。本人就另外买了零件,安装到之前的一个麦克纳姆轮底盘的底板上。(轮子作为装饰,使用铜柱固定) 舵机使用MG996R&a…...
力扣刷题记录---利用python实现链表的基本操作
文章目录 前言一、利用python实现链表的基本操作1.节点的定义使用类实现:1.链表的定义使用类实现:3.判断是否为空函数实现:4.链表长度函数实现:5.遍历链表函数实现:6.头插法函数实现:7.尾插法函数实现&…...

OpenAI重磅官宣ChatGPT安卓版本周发布,现已开启下载预约,附详细预约教程
7月22号,OpenAI 突然宣布,安卓版 ChatGPT 将在下周发布!换句话说,本周安卓版 ChatGPT正式上线! 最早,ChatGPT仅有网页版。 今年5月,iOS版ChatGPT正式发布,当时OpenAI表示Android版将…...

两个世界的同一种崩溃:从窗口黑屏到宇宙热寂的同构联想
一、两个世界的同一种崩溃 一段着色器代码中 cell.xy 的缩放因子从 9 被修改为 99。着色器随即呈现完全黑屏——既无报错信息,也无渲染异常,只有纯粹、彻底、连噪点都不存在的黑色。在屏幕的某个抽象维度上,发生了一件与理论物理学家在黑板上…...

Zookeeper集群启动失败?从myid配置到防火墙,保姆级排错指南来了
Zookeeper集群启动失败?从myid配置到防火墙,保姆级排错指南来了当你满怀期待地执行bin/zkServer.sh start命令,却只看到一堆晦涩的错误日志时,那种挫败感我太熟悉了。Zookeeper作为分布式系统的"神经中枢",其…...

统计分析方法与假设检验
统计分析方法与假设检验 1. 技术分析 1.1 统计分析概述 统计分析是数据科学的基础方法: 统计分析类型描述统计: 数据概括推断统计: 假设检验回归分析: 变量关系时间序列: 时序数据统计方法:参数检验: t检验、方差分析非参数检验: Mann-Whitney、卡方检验相关性分…...

AI Agent Harness Engineering 在房地产中的应用:智能推荐与价值评估
AI Agent Harness Engineering 在房地产中的应用:智能推荐与价值评估 引言:房地产数字化转型的「最后一公里」——智能决策的人机协同闭环 痛点引入:千亿级赛道下的三大决策「卡脖子」难题 房地产作为全球规模最大的实体产业之一(据CBRE世邦魏理仕2024年全球房地产市场报…...

Qwen模型 LeetCode 2585. 获得分数的方法数 TypeScript实现
哇!TypeScript版本来啦~这道题用TS写起来特别优雅,类型安全又清晰!让我给你展示一个高效又易读的实现!typescript function waysToReachTarget(target: number, types: number[][]): number {const MOD 1000000007;//…...

2026论文写作工具红黑榜:AI论文网站怎么选?清单来了
2026年论文写作工具竞争白热化,红榜优先选千笔AI、ThouPen、豆包,适配国内学术规范,内容严谨且格式合规;黑榜需避开低质免费工具、无真实引用平台、过度依赖全文生成的工具。选择时可按需求匹配度 - 数据可信度 - 成本承受力三维模…...
专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢)
项目介绍 基于java+vue的跨境电商销售预测与可视化平台设计与实现(含模型描述及部分示例代码)专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢
基于javavue的跨境电商销售预测与可视化平台设计与实现的详细项目实例 请注意此篇内容只是一个项目介绍 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面(含完整的程序,GUI设计和代码详解) 跨境电商销售预测…...

AI正在重构工程师岗位:被替代的不是“人”,而是低维度能力
过去很多人认为,AI更适合写文案、做客服、生成图片,而真正复杂的工程领域——尤其是工业、制造、自动化系统——依然离不开工程师。 但最近一个劳动仲裁案例,让越来越多工程技术人员开始重新思考这个问题: 一位从事测绘工作15年的工程师,因为企业全面导入AI自动化测绘系…...

CANN算子开发调试实战:从“Segmentation Fault“到定位根因的完整流程
写Ascend C算子最怕的不是编译失败——编译失败有明确的错误信息。最怕的是运行时Segmentation Fault,什么都没告诉你,NPU直接挂了。没有堆栈、没有日志、只有一行"Killed"。 这篇整理了算子开发中常见的运行时错误、调试方法、以及定位根因的…...

【光学】偏振光线追迹Matlab仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...