分布式id、系统id、业务id以及主键之间的关系
推荐
连分布式ID都理解不了,你是刚培训出来冒充面试官的吧
1 分布式id、系统id、业务id以及主键之间的关系
- 分布式ID、系统ID、业务ID和主键的关系:
-
分布式ID:在分布式系统中,由于存在多个独立的节点,为了保证每个节点生成的ID都是全局唯一的,就需要用到分布式ID。它是全局唯一的,可以用作数据库的主键。
-
系统ID:一般用来在一个系统或者平台内部区分不同的用户、订单等,不一定是全局唯一的,所以不能用作分布式系统中的主键。
-
业务ID:业务ID是根据业务逻辑生成的ID,它的生成规则可能会包含一些业务信息,如时间、地点等。它可以是全局唯一的,也可以只在某个业务范围内唯一。
-
主键:数据库表中的主键是用来唯一标识一条记录的,它必须是唯一的。在分布式系统中,主键一般会使用分布式ID来保证全局唯一。
2 为什么不能用主键id充当订单id
- 为什么不能用主键ID充当订单ID?
主键ID是数据库中用于唯一标识记录的,而订单ID是业务中用来标识一个订单的。虽然在技术上可能可以使用主键ID作为订单ID,但这样做会有一些问题:
-
从业务逻辑的角度看,订单ID一般需要包含一些业务相关的信息,如时间、订单类型等,而主键ID通常是无业务含义的。
-
主键ID可能会由数据库自动递增生成,如果直接暴露给用户,可能会泄露一些敏感信息,如订单数量等。
-
如果系统升级或迁移,主键ID可能会发生改变,这会影响到业务的持续性。
3 为什么业务id和主键id不能一样
- 为什么业务ID和主键ID不能一样?
业务ID和主键ID的生成规则和用途是不一样的。业务ID是根据业务逻辑生成的,可能会包含一些业务相关的信息,而主键ID一般是数据库自动生成的,没有业务含义。
另外,业务ID可能会因为业务的变化而变化,而主键ID一旦确定,就不应该发生改变。如果把业务ID和主键ID设置为一样的,那么当业务ID需要改变时,就可能会影响到数据库的主键,从而影响到数据的完整性。
4 分布式id是解决什么问题
- 分布式ID是解决什么问题?
分布式ID主要是解决分布式系统中全局唯一标识的问题。在分布式系统中,由于存在多个独立的节点,每个节点可能都需要生成ID,为了保证所有节点生成的ID都是全局唯一的,就需要使用分布式ID。
另外,分布式ID还可以解决一些其它的问题,如:
-
数据库的分片问题:通过合理的设计分布式ID,可以将数据均匀的分布在不同的数据库或者表中,提高查询的效率。
-
订单的生成问题:在电商等需要大量生成订单的业务中,分布式ID可以快速的生成大量的全局唯一的订单号。
-
数据追踪问题:在复杂的系统中,通过分布式ID,可以更容易的追踪一条数据的流转过程。
分库分表和扩展
1. 怎么分库分表:
分库分表是为了解决单一数据库或者单一数据表承载量问题的一种常用的方法。分库是将一个数据库的数据拆分到多个数据库中,分表则是将一个表的数据拆分到多个表中。以下是分库分表的一般步骤:
-
确定拆分的方式:分库还是分表,或者两者同时进行。这主要取决于你的系统瓶颈在哪里,是在单个数据库的处理能力,还是在单个表的数据量。
-
设计拆分规则:这通常需要根据业务特点来进行,常见的方式有按照用户ID、地理位置、时间等进行拆分。
-
修改应用程序:拆分后的数据库和表的结构与原来的不同,需要修改应用程序中的数据库操作代码。
-
数据迁移:将原来的数据按照新的拆分规则迁移到新的数据库和表中。
-
引入中间件:为了使应用程序对分库分表透明,通常会引入一些数据库中间件,如ShardingSphere、Mycat等。
2. 为什么分库分表要考虑引入一个横向扩展的分布式数据库呢?
横向扩展的分布式数据库,或称为数据库分片,能有效地处理大量数据和高并发的情况。通过将数据分散到多个数据库节点上,可以提高系统的处理能力和吞吐量,从而提高系统的可扩展性和稳定性。
另外,引入一个横向扩展的分布式数据库,还可以提高数据的可用性。如果一个节点出现故障,其他节点还可以继续提供服务,从而保证了系统的可用性。
最后,使用分布式数据库,可以简化分库分表的操作。很多分布式数据库产品,如CockroachDB、TiDB等,都提供了内建的分片功能,可以自动进行数据的分布和迁移,大大简化了分库分表的操作。
3. 分库分表跟ID的关系:
分库分表的策略往往与ID有关。ID是一个常用的拆分依据,例如:
-
可以按照用户ID进行拆分,比如将用户ID为奇数的用户的数据存储在一组数据库中,将用户ID为偶数的用户的数据存储在另一组数据库中。
-
可以按照订单ID进行拆分,比如按照订单ID的某几位进行哈希,然后根据哈希值来决定存储到哪个数据库或者哪个表中。
此外,分布式ID生成策略也常被用于分库分表。通过在ID中包含一些特定的信息,比如时间、机器编号等,可以用于直接或间接地决定该数据应该存储在哪个数据库或哪个表中。例如,Twitter的Snowflake算法就是一个常用的分布式ID生成策略。
分库分表、水平划分和垂直划分都是数据库架构中为了解决数据量大或者并发访问量大导致的性能问题而采用的策略。他们之间的关系和特点如下:
-
分库分表:分库是指将一个数据库拆分为多个数据库,分表则是将一个大表拆分为多个小表。分库分表可以既包含水平划分也可以包含垂直划分,具体取决于分库分表的方式。
-
水平划分(Horizontal Partitioning):是指按照数据的行进行拆分,将一个表的数据根据某些规则分散到多个具有相同结构的表中。例如,根据用户ID的奇偶性进行分表,所有奇数ID的用户数据存放在一张表,偶数ID的用户数据存放在另一张表。这种方式是分库分表的一种常用策略。
-
垂直划分(Vertical Partitioning):是指按照数据的列进行拆分,将一个表的某些列数据拆分到另一个或多个表中。例如,一个用户信息表,包含用户的基本信息和详细信息,可以将基本信息和详细信息分别存放在两个表中。垂直划分也可以用于分库,将不同的表放到不同的数据库中。
总结来说,分库分表是为了解决数据库性能问题的一个总体策略,而水平划分和垂直划分则是实现分库分表的具体技术手段。
水平划分和水平扩展数据库很像,都借用了分片吗
是的,水平划分和水平扩展的数据库(也称为分布式数据库或数据库分片)在很多方面是相似的,它们都是通过将数据分散到多个数据库或数据表中来提高系统的性能和可扩展性。实际上,你可以将水平划分看作是水平扩展的一个子集或者具体实现方式。
水平划分是在应用程序层面进行的,它需要应用程序知道如何路由到正确的数据库或表,因此通常需要修改应用程序的代码。而水平扩展的数据库,如Cassandra,MongoDB和Google Cloud Spanner等,通常会提供一个统一的接口,应用程序可以像访问一个单一的数据库一样访问它,由数据库系统自动处理数据的分布和路由。
在水平划分和水平扩展的数据库中,都会使用到分片的概念。分片是指将数据划分为多个独立的部分,每个部分称为一个分片,每个分片可以存储在不同的物理设备上。分片的规则可以根据业务需求来定,常见的规则有按照范围分片、按照哈希分片等。
相关文章:

分布式id、系统id、业务id以及主键之间的关系
推荐 连分布式ID都理解不了,你是刚培训出来冒充面试官的吧 1 分布式id、系统id、业务id以及主键之间的关系 分布式ID、系统ID、业务ID和主键的关系: 分布式ID:在分布式系统中,由于存在多个独立的节点,为了保证每个节…...
)
设计模式七:适配器模式(Adapter Pattern)
适配器模式(Adapter Pattern)是一种结构型设计模式,用于将一个类的接口转换成客户端所期望的另一个接口。它允许不兼容的接口能够协同工作。 适配器模式涉及角色: 目标接口(Target Interface):…...

数据结构---队列
(一)队列之基础补充 队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。 —— 百科 「队列 Queue」是一种…...

chatGPT在软件测试中应用方式有哪些?
ChatGPT可以在软件测试中以以下方式应用: 1. 自动化对话测试:ChatGPT可以用于自动化对话测试,模拟用户与软件系统进行实时对话。它可以扮演用户的角色,向系统发送各种类型的指令和请求,并验证系统的响应是否符合预期。…...

chatgpt 接口使用(一)
使用api实现功能 参考链接:https://platform.openai.com/examples 安装库: pip3 install openai 例如: import os import openaiopenai.api_key os.getenv("OPENAI_API_KEY") response openai.ChatCompletion.create(model&q…...

【个人笔记】Linux 服务管理两种方式service和systemctl
service命令与systemctl 命令 service 命令与传统的 SysVinit 和 Upstart 初始化系统相关。较早期的 Linux 发行版(如早期的 Ubuntu、Red Hat 等)使用了这些初始化系统。service 命令用于启动、停止、重启和查询系统服务的状态。虽然许多现代 Linux 发行…...
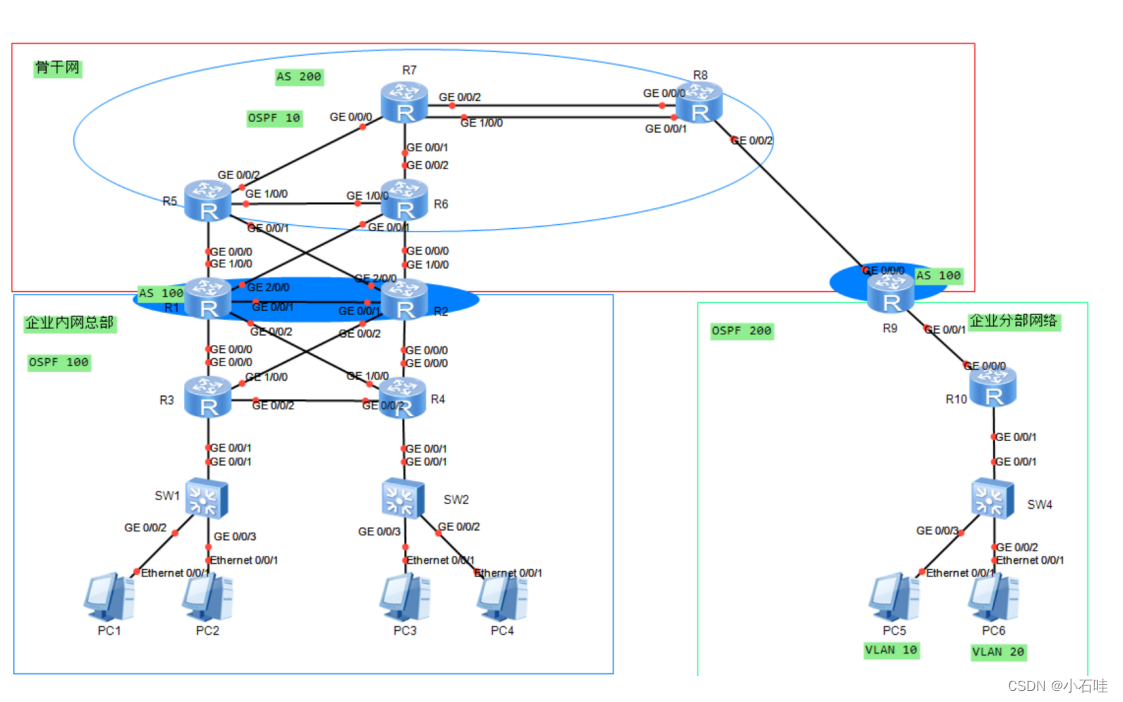
HCIP中期考试实验
考试需求 1、该拓扑为公司网络,其中包括公司总部、公司分部以及公司骨干网,不包含运营商公网部分。 2、设备名称均使用拓扑上名称改名,并且区分大小写。 3、整张拓扑均使用私网地址进行配置。 4、整张网络中,运行OSPF协议或者BGP…...
WebRTC的混音处理)
【WebRTC---源码篇】(二十二)WebRTC的混音处理
音频混音主力 音频混音主体主要通过(重采样) + (混音)为主 音频重采样 内容实现是在webrtc::voe中实现的,下面来对重采样全流程逐一分析 。 void RemixAndResample(const AudioFrame& src_frame,//源音频数据帧PushResampler<int16_t>* resampler,//重采样对…...

MTK system_server 卡死导致手机重启案例分析
和你一起终身学习,这里是程序员Android 经典好文推荐,通过阅读本文,您将收获以下知识点: 一、MTK AEE Log分析工具二、AEE Log分析流程三、system_server 卡死案例分析及解决 本文主要针对 Exception Type: system_server_watchdog , system_…...

加强 Kubernetes 能力:利用 CRD 定义多版本资源的实现方式
姚灿武,Rancher 中国研发工程师,拥有 7 年云计算领域经验,热衷开源技术,在云原生相关技术领域拥有丰富的开发和实践经验。 CRD,即自定义资源定义(Custom Resource Definition),是 Ku…...

区块链应用 DApp 开发需要掌握的技能
文章目录 前言为什么要开发 DAppDApp 的优势DApp 应用范围DApp 开发者技能 前言 前面区块链系列的文章中介绍了区块链技术、智能合约、web3js,Solidity 编程语言,在开发者的角度就是要基于这些知识在Web3时代去开发一个 DApp(去中心化应用程…...

关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题
由于一段时间没有使用Selenium,当再次使用时发现之前写的Selenium元素定位的代码运行之后会报错,发现是Selenium更新到新版本(4.x版本)后,以前的一些常用的代码的语法发生了改变,当然如果没有更新过或是下载…...

c++通过自然语言处理技术分析语音信号音高
对于语音信号的音高分析,可以使用基频提取技术。基频是指一个声音周期的重复率,也就是一个声音波形中最长的周期。 通常情况下,人的声音基频范围是85Hz到255Hz。根据语音信号的基频可以推断出其音高。 C中可以使用数字信号处理库或语音处理库…...
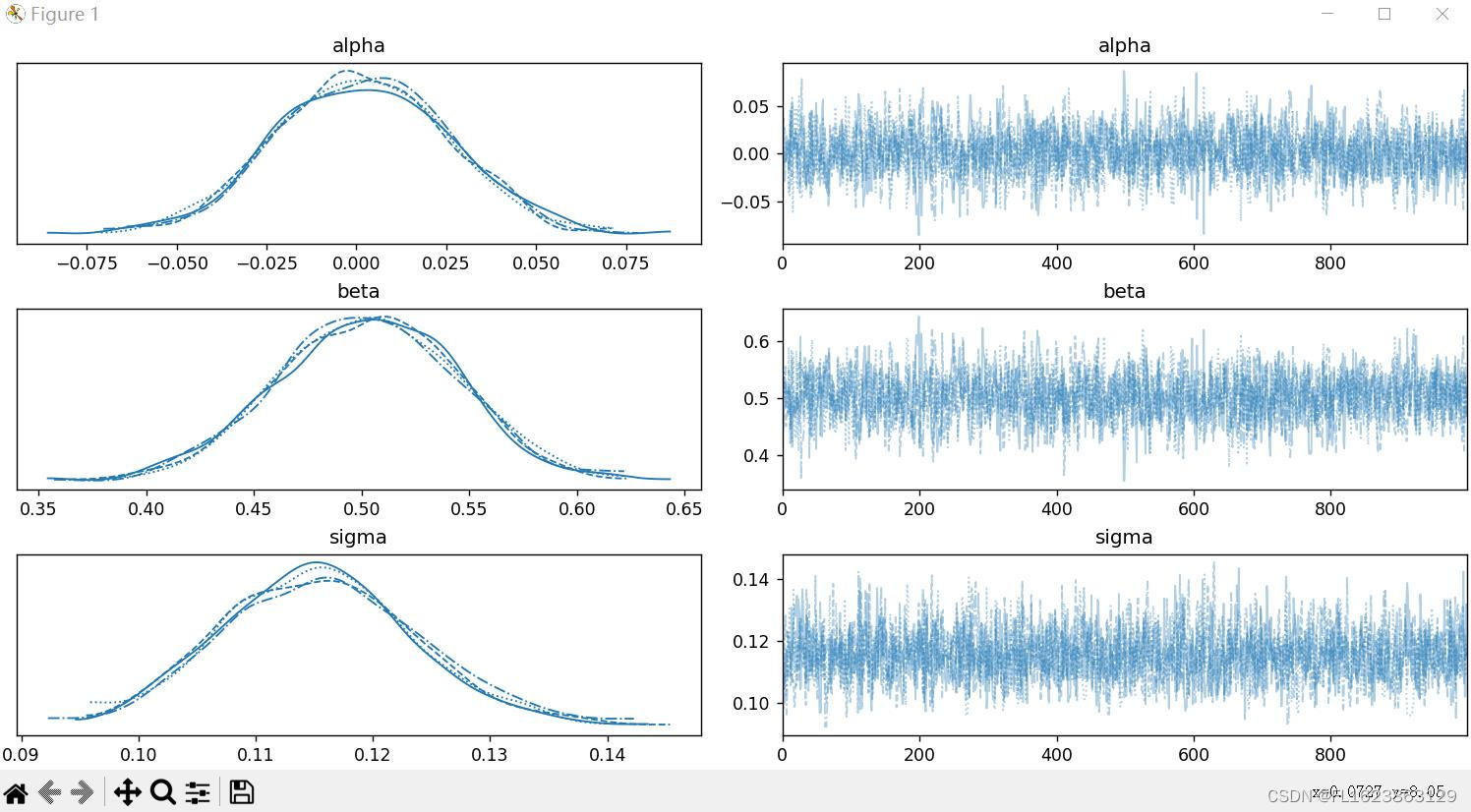
[pymc3][python]pymc3安装后测试代码2
测试环境: pymc33.11.2 代码: import numpy as np import pymc3 as pm import matplotlib.pyplot as pltif __name__ __main__:# 生成随机数据np.random.seed(123)x np.linspace(0, 1, 100)y 0.5 * x np.random.normal(0, 0.1, size100)# 定义概率…...

Go语言time库,时间和日期相关的操作方法
time库 用于处理时间、日期和时区的核心库。在实际开发中,常常需要与时间打交道,例如记录日志、处理时间差、计算时间间隔等等。因此,掌握time库的使用方法对于Go开发者来说非常重要。 在Go语言中,时间表示为time.Time类型&…...
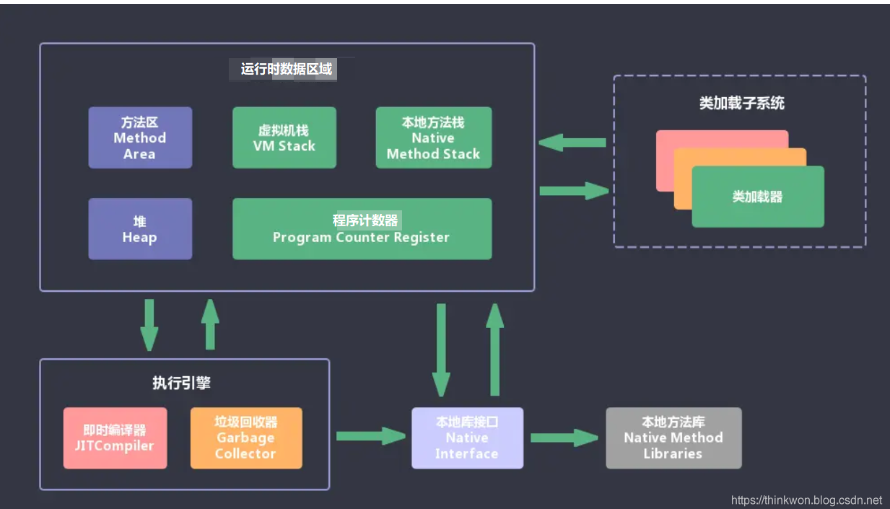
JVM总结笔记
JVM JVM是什么?JVM 的主要组成部分JVM工作流程JVM内存模型直接内存与堆内存的区别:堆栈的区别Java会存在内存泄漏吗?简述Java垃圾回收机制垃圾收集算法轻GC(Minor GC)和重GC(Full GC)新生代gc流程JVM优化与JVM调优 JVM是什么? JVM是Java Virtual Mach…...

C++ 缓存再排序,解决多线程处理后的乱序问题,不知道思路对不对[挠下巴]
C 缓存再排序,解决多线程处理后的乱序问题,不知道思路对不对[挠下巴] 使用map默认会根据key排序的原理作缓存,队列满了依次推出,抛弃掉过时的数据 #include <functional> #include <iostream> #include <map> #…...

华为数通HCIA-地址分类及子网划分
ip地址(逻辑地址) 作用:唯一标识一张网卡 特点:设备天生没有,需要人为配置,可以随时修改 格式:点分十进制 大小:32bit 组成:网络位主机位 网络位:用于标…...

Linux第七章之gdb与makefile使用
一、Linux调试器-gdb使用 1.1背景 程序的发布方式有两种,debug模式和release模式Linux gcc/g出来的二进制程序,默认是release模式要使用gdb调试,必须在源代码生成二进制程序的时候, 加上-g 选项[重要] 1.2开始使用 …...
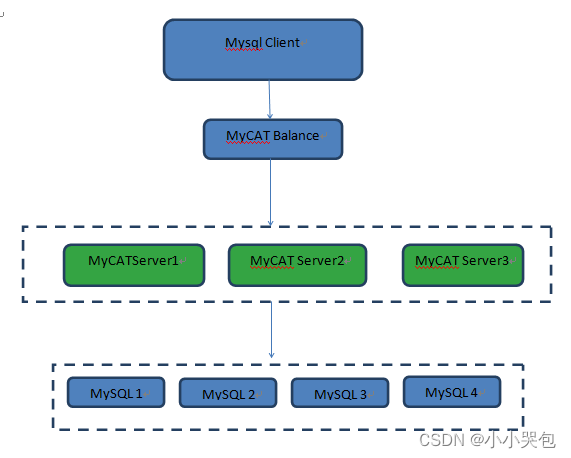
Mycat-Balance使用指南
MyCAT Balance是一个Java NIO的高性能负载均衡器,可以替代普通的硬件的交换机或其LVS类似的复杂机制,实现MyCAT集群的负载均衡。 MyCAT Balance的配置文件在conf目录下,frontend-conf.为前端配置,包括绑定的端口等,js…...

为什么92%的AI音频项目在ElevenLabs声音库选型阶段就失败?——资深AI音频架构师12年踩坑复盘
更多请点击: https://intelliparadigm.com 第一章:为什么92%的AI音频项目在ElevenLabs声音库选型阶段就失败? ElevenLabs 的声音库看似丰富——超 500 个语音模型、多语言支持、情感调节滑块一应俱全,但真实项目落地中࿰…...

设计工程化实践:将设计思维转化为开发者技能的工具探索
1. 项目概述:当设计思维遇上代码技能最近在GitHub上看到一个挺有意思的项目,叫Arthurescc/design-fusion.skill。光看这个名字,就让我这个在设计和开发交叉领域摸爬滚打了十来年的老手眼前一亮。“Design Fusion”直译是“设计融合”…...

各高校论文AI率标准差异解读:从10%到30%不同学校标准差距2026年免费达标方案
各高校论文AI率标准差异解读:从10%到30%不同学校标准差距2026年免费达标方案 关于高校论文AI率标准解读,我系统研究过一段时间,也实际验证过各种说法。 这篇文章把关键的逻辑理清楚——知道了原理,遇到问题就知道该怎么处理了。…...

GaussDB定时任务管理:从基础到高级实践
一、定时任务体系架构1.1 双引擎调度架构GaussDB采用内置调度器外部集成的混合架构:内置调度器:基于PostgreSQL的pgAgent增强实现 外部集成:支持与Linux cron、Kubernetes CronJob联动 分布式调度࿱…...

告别网盘下载烦恼:3步解锁9大网盘高效下载新体验
告别网盘下载烦恼:3步解锁9大网盘高效下载新体验 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 …...

Saga状态机设计失效导致订单丢失?DeepSeek内部SRE团队紧急修复的7个隐性陷阱,你中了几个?
更多请点击: https://intelliparadigm.com 第一章:Saga状态机设计失效导致订单丢失?DeepSeek内部SRE团队紧急修复的7个隐性陷阱,你中了几个? Saga 模式在分布式事务中被广泛采用,但 DeepSeek SRE 团队在一…...

Flyway实战:从零到一构建数据库版本管理流水线
1. 为什么你的项目需要Flyway 第一次接触数据库版本管理这个概念时,我正面临一个典型的开发困境:团队里有5个开发人员在同时修改数据库结构,每次发布新版本都像在玩俄罗斯轮盘赌——永远不知道谁会忘记执行哪个SQL脚本。直到生产环境出现数据…...

基于Arduino与蓝牙的智能夜灯DIY:从硬件到App全流程解析
1. 项目概述:打造你的专属蓝牙智能夜灯如果你对Arduino和物联网项目感兴趣,一直想亲手做一个既能远程控制、又能播放音乐的智能小玩意儿,那么这个“8BitBox”项目绝对值得一试。它本质上是一个由Arduino驱动、通过Android手机蓝牙控制的智能夜…...

AI智能体安全框架实战:从提示词注入防御到工具调用沙箱化
1. 项目概述:当AI智能体需要“安全管家”最近在折腾AI智能体(Agent)的开发,尤其是在尝试让它们接入外部工具和API时,一个绕不开的“老大难”问题就是安全性。你辛辛苦苦训练或调教好的智能体,一旦让它能执行…...

Adobe GenP 3.0终极指南:3步解锁全系列Adobe CC软件
Adobe GenP 3.0终极指南:3步解锁全系列Adobe CC软件 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 还在为Adobe Creative Cloud高昂的订阅费用而烦恼吗…...