tensorflow1.13分布式训练 参考资料 -教程原理
前言
对于数据量较大的时候,通过分布式训练可以加速训练。相比于单机单卡、单机多卡只需要用with tf.device(‘/gpu:0’)来指定GPU进行计算的情况,分布式训练因为涉及到多台机器之间的分工交互,所以更麻烦一些。本文简单介绍了多机(单卡/多卡不重要)情况下的分布式Tensorflow训练方法。
对于分布式训练与单机训练主要有两个不同 :1. 如何开始训练;2. 训练时如何进行分工。分别会在下面两节进行介绍。
1. 确认彼此
单机训练直接可以通过一个脚本就告诉机器“我要开始训练啦”就可以,但是对于分布式训练而言,多台机器需要互相通信,就需要先“见个面认识一下”。就需要给每一台机器一个“名单”,让他去找其他机器。这个“名单”就是所谓的ClusterSpec,让他去找其他机器就是说每一台机器都要运行一次脚本。
下面我们来举一个例子,假设我们用本地机器的两个端口"localhost:2222","localhost:2223"来模拟集群中的两个机器,两个机器的工作内容都是简单的print一句话。首先写两个脚本,第一个脚本长这样
import tensorflow as tf# 每台机器要做的内容(为了简化,不训练了,只print一下)
c = tf.constant("Hello from server1")# 集群的名单
cluster = tf.train.ClusterSpec({"local":["localhost:2222", "localhost:2223"]})
# 服务的声明,同时告诉这台机器他是名单中的谁
server = tf.train.Server(cluster, job_name="local", task_index=0)
# 以server模式打开会话环境
sess = tf.Session(server.target, config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
server.join()
然后第二个脚本长这样:
import tensorflow as tf# 每台机器要做的内容(为了简化,不训练了,只print一下)
c = tf.constant("Hello from server2")# 集群的名单
cluster = tf.train.ClusterSpec({"local":["localhost:2222", "localhost:2223"]})
# 服务的声明,同时告诉这台机器他是名单中的谁
server = tf.train.Server(cluster, job_name="local", task_index=1)
# 以server模式打开会话环境
sess = tf.Session(server.target, config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
server.join()
我们来简单说明一下脚本中的内容。这两个脚本其实长的差不多,都是拿着同一个“名单”,即
# 声明集群的“名单”
cluster = tf.train.ClusterSpec({"local":["localhost:2222", "localhost:2223"]})不同之处只是在创建Server的时候,指定了不同的index,相当于告诉他名单里哪一个名字是自己。其实原理上就是在每一台机器上起一个服务,然后通过这个服务和名单来实现通信。
# 第一个脚本的服务
server = tf.train.Server(cluster, job_name="local", task_index=0)
# 第二个脚本的服务
server = tf.train.Server(cluster, job_name="local", task_index=1)
现在有两个脚本了(对于多机情况,这两个脚本是分别放在不同机器上的,但是本例使用单机的两个端口模仿多机,所以两个脚本可以放在一起)。然后我们让这个“集群”启动起来吧!首先打开一个命令行窗口,在该路径下运行第一个脚本:
# 运行第一台机器(控制台窗口)
$ python3 server1.py# 输出内容
# 此处省略 N 行内容
2020-04-24 14:58:58.841179: I tensorflow/core/distributed_runtime/master.cc:268] CreateSession still waiting for response from worker: /job:local/replica:0/task:1
2020-04-24 14:59:08.844255: I tensorflow/core/distributed_runtime/master.cc:268] CreateSession still waiting for response from worker: /job:local/replica:0/task:1
2020-04-24 14:59:18.847998: I tensorflow/core/distributed_runtime/master.cc:268] CreateSession still waiting for response from worker: /job:local/replica:0/task:1
2020-04-24 14:59:28.852471: I tensorflow/core/distributed_runtime/master.cc:268] CreateSession still waiting for response from worker: /job:local/replica:0/task:1
2020-04-24 14:59:38.852649: I tensorflow/core/distributed_runtime/master.cc:268] CreateSession still waiting for response from worker: /job:local/replica:0/task:1
2020-04-24 14:59:48.856933: I tensorflow/core/distributed_runtime/master.cc:268] CreateSession still waiting for response from worker: /job:local/replica:0/task:1
忽略WARNING部分,命令行中不断输出内容CreateSession still waiting for response from worker表示这个服务正在等待集群中其他机器,毕竟我们还没有让第二台机器加入进来。下面我们重新打开一个命令行窗口(表示另一台机器),并在目录下启动另一个脚本:
# 运行第二台机器(控制台窗口)
$ python3 server2.py# 输出内容
# 此处省略 N 行内容
Const: (Const): /job:local/replica:0/task:0/device:CPU:0
2020-04-24 15:02:27.653508: I tensorflow/core/common_runtime/placer.cc:54] Const: (Const): /job:local/replica:0/task:0/device:CPU:0
b'Hello from server2'
我们看到当第二个脚本开始运行时,集群中所有(两台)机器都到齐了,于是就开始工作了。第二台机器直接print出了内容b’Hello from server2’。同时此时第一台机器也开始了工作
# 第二个台机器(控制台窗口)加入到集群之后,第一台机器的输出
Const: (Const): /job:local/replica:0/task:0/device:CPU:0
2020-04-24 15:02:28.732132: I tensorflow/core/common_runtime/placer.cc:54] Const: (Const): /job:local/replica:0/task:0/device:CPU:0
b'Hello from server1'
综上,对于分布式训练来说,第一步就是每一个机器都应该有一个脚本;第二 步给每台机器一个相同的“名单”,也就是ClusterSpec;第三步在每台机器上分别运行脚本,起服务;最后多台机器之间就可以通信了。
2. 密切配合
第一节介绍了集群之间的机器如何相互确认,并一起开始工作的。本节主要介绍,集群之间的机器如明确分工,相互配合完成训练的。在前面的例子中,两台机器的名单是通过ClusterSpec来声明的,两台机器没有复杂的角色分工,都是print一句话。
tf.train.ClusterSpec({"local":["localhost:2222", "localhost:2223"]})
实际上在复杂的训练过程中会更复杂,我们要为每台机器分配不同的工作,一般会分成ps机和worker机。其中ps机负责保存网络参数、汇总梯度值、更新网络参数,而worker机主要负责正向传导和反向计算提督。这时在创建ClusterSpec的时候就需要这样做
# 通常将机器分工为ps和worker,不过可以根据实际情况灵活分工。
# 只是在编写代码时明确每种分工的机器要做什么事情就可以
tf.train.ClusterSpec({"ps":["localhost:2222"], # 用来保存、更新参数的机器"worker":["localhost:2223", "localhost:2224"] # 用来正向传播、反向计算梯度的机器
})
本例中仍然采用本机的三个端口模拟三台机器。ClusterSpec的参数字典的key为集群分工的名称,value为该分工下的机器列表。
已经知道了如何定义一个集群,下面我们来看看如何给每一个机器分配任务。在第一节的例子中我们写了两个相似脚本,但是如果在大规模集群上这很费力,且不宜与维护。最好是只写一份脚本,然后在不同的机器上运行时,通过参数告诉机器“分工”(ps or worker)和“名字”(ip:port)就可以。分布式训练的方式分为异步训练和同步训练。下面我们分别介绍:
2.1 异步分布式训练
我们还是据一个简单的DNN来分类MNIST数据集的例子,脚本应该长这样:
# 异步分布式训练
#coding=utf-8
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data # 数据的获取不是本章重点,这里直接导入FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string("job_name", "worker", "ps or worker")
tf.app.flags.DEFINE_integer("task_id", 0, "Task ID of the worker/ps running the train")
tf.app.flags.DEFINE_string("ps_hosts", "localhost:2222", "ps机")
tf.app.flags.DEFINE_string("worker_hosts", "localhost:2223,localhost:2224", "worker机,用逗号隔开")# 全局变量
MODEL_DIR = "./distribute_model_ckpt/"
DATA_DIR = "./data/mnist/"
BATCH_SIZE = 32# main函数
def main(self):# ========== STEP1: 读取数据 ========== #mnist = input_data.read_data_sets(DATA_DIR, one_hot=True, source_url='http://yann.lecun.com/exdb/mnist/') # 读取数据# ========== STEP2: 声明集群 ========== ## 构建集群ClusterSpec和服务声明ps_hosts = FLAGS.ps_hosts.split(",")worker_hosts = FLAGS.worker_hosts.split(",")cluster = tf.train.ClusterSpec({"ps":ps_hosts, "worker":worker_hosts}) # 构建集群名单server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_id) # 声明服务# ========== STEP3: ps机内容 ========== ## 分工,对于ps机器不需要执行训练过程,只需要管理变量。server.join()会一直停在这条语句上。if FLAGS.job_name == "ps":with tf.device("/cpu:0"):server.join()# ========== STEP4: worker机内容 ========== ## 下面定义worker机需要进行的操作is_chief = (FLAGS.task_id == 0) # 选取task_id=0的worker机作为chief# 通过replica_device_setter函数来指定每一个运算的设备。# replica_device_setter会自动将所有参数分配到参数服务器上,将计算分配到当前的worker机上。device_setter = tf.train.replica_device_setter(worker_device="/job:worker/task:%d" % FLAGS.task_id,cluster=cluster)# 这一台worker机器需要做的计算内容with tf.device(device_setter):# 输入数据x = tf.placeholder(name="x-input", shape=[None, 28*28], dtype=tf.float32) # 输入样本像素为28*28y_ = tf.placeholder(name="y-input", shape=[None, 10], dtype=tf.float32) # MNIST是十分类# 第一层(隐藏层)with tf.variable_scope("layer1"):weights = tf.get_variable(name="weights", shape=[28*28, 128], initializer=tf.glorot_normal_initializer())biases = tf.get_variable(name="biases", shape=[128], initializer=tf.glorot_normal_initializer())layer1 = tf.nn.relu(tf.matmul(x, weights) + biases, name="layer1")# 第二层(输出层)with tf.variable_scope("layer2"):weights = tf.get_variable(name="weights", shape=[128, 10], initializer=tf.glorot_normal_initializer())biases = tf.get_variable(name="biases", shape=[10], initializer=tf.glorot_normal_initializer())y = tf.add(tf.matmul(layer1, weights), biases, name="y")pred = tf.argmax(y, axis=1, name="pred")global_step = tf.contrib.framework.get_or_create_global_step() # 必须手动声明global_step否则会报错# 损失和优化cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, axis=1))loss = tf.reduce_mean(cross_entropy)train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss, global_step=global_step)if is_chief:train_op = tf.no_op()hooks = [tf.train.StopAtStepHook(last_step=10000)]config = tf.ConfigProto(allow_soft_placement=True, # 设置成True,那么当运行设备不满足要求时,会自动分配GPU或者CPU。log_device_placement=False, # 设置为True时,会打印出TensorFlow使用了哪种操作)# ========== STEP5: 打开会话 ========== ## 对于分布式训练,打开会话时不采用tf.Session(),而采用tf.train.MonitoredTrainingSession()# 详情参考:https://www.cnblogs.com/estragon/p/10034511.htmlwith tf.train.MonitoredTrainingSession(master=server.target,is_chief=is_chief,checkpoint_dir=MODEL_DIR,hooks=hooks,save_checkpoint_secs=10,config=config) as sess:print("session started!")start_time = time.time()step = 0while not sess.should_stop():xs, ys = mnist.train.next_batch(BATCH_SIZE) # batch_size=32_, loss_value, global_step_value = sess.run([train_op, loss, global_step], feed_dict={x:xs, y_:ys})if step > 0 and step % 100 == 0:duration = time.time() - start_timesec_per_batch = duration / global_step_valueprint("After %d training steps(%d global steps), loss on training batch is %g (%.3f sec/batch)" % (step, global_step_value, loss_value, sec_per_batch))step += 1if __name__ == "__main__":tf.app.run()
代码虽然比较长,但是整体结构还是很清晰的。结构上分5个步骤:1. 读取数据、2. 声明集群、3. ps机内容、4. worker机内容、5. 打开会话。其中第四步“worker机内容”包含了网络结构的定义,比较复杂。
接下来只需要将脚本放在集群的三个不同机器上,然后分别运行即可,首先运行ps机脚本:
# ps机脚本
$ python3 distribute_train.py --job_name=ps --task_id=0 --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224# 输出
2020-04-24 17:16:44.530325: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2020-04-24 17:16:44.546565: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x102ccad20 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2020-04-24 17:16:44.546582: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2020-04-24 17:16:44.548075: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:258] Initialize GrpcChannelCache for job ps -> {0 -> localhost:2222}
2020-04-24 17:16:44.548088: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:258] Initialize GrpcChannelCache for job worker -> {0 -> localhost:2223, 1 -> localhost:2224}
2020-04-24 17:16:44.548525: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:365] Started server with target: grpc://localhost:2222
然后运行第一个worker机脚本,开始运行之后他会等待worker其他机的加入:
# 第一个worker机
$ python3 distribute_train.py --job_name=worker --task_id=0 --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224# 这里省略 N 行输出
2020-04-24 17:25:41.174507: I tensorflow/core/distributed_runtime/master.cc:268] CreateSession still waiting for response from worker: /job:worker/replica:0/task:1
2020-04-24 17:25:51.176111: I tensorflow/core/distributed_runtime/master.cc:268] CreateSession still waiting for response from worker: /job:worker/replica:0/task:1
2020-04-24 17:26:01.180872: I tensorflow/core/distributed_runtime/master.cc:268] CreateSession still waiting for response from worker: /job:worker/replica:0/task:1
2020-04-24 17:26:11.184377: I tensorflow/core/distributed_runtime/master.cc:268] CreateSession still waiting for response from worker: /job:worker/replica:0/task:1
然后运行第二个worker机的脚本:
# 第二个worker机
$ python3 distribute_train.py --job_name=worker --task_id=0 --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224# 输出
session started!
After 100 training steps(100 global steps), loss on training batch is 1.59204 (0.004 sec/batch)
After 200 training steps(200 global steps), loss on training batch is 1.10218 (0.003 sec/batch)
After 300 training steps(300 global steps), loss on training batch is 0.71179 (0.003 sec/batch)
After 400 training steps(400 global steps), loss on training batch is 0.679103 (0.002 sec/batch)
After 500 training steps(500 global steps), loss on training batch is 0.50411 (0.002 sec/batch)
# 这里省略 N 行输出
2.2 同步分布式训练
同样是采用DNN进行MNIST数据集的分类任务:
# 异步分布式训练
#coding=utf-8
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data # 数据的获取不是本章重点,这里直接导入FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string("job_name", "worker", "ps or worker")
tf.app.flags.DEFINE_integer("task_id", 0, "Task ID of the worker/ps running the train")
tf.app.flags.DEFINE_string("ps_hosts", "localhost:2222", "ps机")
tf.app.flags.DEFINE_string("worker_hosts", "localhost:2223,localhost:2224", "worker机,用逗号隔开")# 全局变量
MODEL_DIR = "./distribute_model_ckpt/"
DATA_DIR = "./data/mnist/"
BATCH_SIZE = 32# main函数
def main(self):# ========== STEP1: 读取数据 ========== #mnist = input_data.read_data_sets(DATA_DIR, one_hot=True, source_url='http://yann.lecun.com/exdb/mnist/') # 读取数据# ========== STEP2: 声明集群 ========== ## 构建集群ClusterSpec和服务声明ps_hosts = FLAGS.ps_hosts.split(",")worker_hosts = FLAGS.worker_hosts.split(",")cluster = tf.train.ClusterSpec({"ps":ps_hosts, "worker":worker_hosts}) # 构建集群名单server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_id) # 声明服务n_workers = len(worker_hosts) # worker机的数量# ========== STEP3: ps机内容 ========== ## 分工,对于ps机器不需要执行训练过程,只需要管理变量。server.join()会一直停在这条语句上。if FLAGS.job_name == "ps":with tf.device("/cpu:0"):server.join()# ========== STEP4: worker机内容 ========== ## 下面定义worker机需要进行的操作is_chief = (FLAGS.task_id == 0) # 选取task_id=0的worker机作为chief# 通过replica_device_setter函数来指定每一个运算的设备。# replica_device_setter会自动将所有参数分配到参数服务器上,将计算分配到当前的worker机上。device_setter = tf.train.replica_device_setter(worker_device="/job:worker/task:%d" % FLAGS.task_id,cluster=cluster)# 这一台worker机器需要做的计算内容with tf.device(device_setter):# 输入数据x = tf.placeholder(name="x-input", shape=[None, 28*28], dtype=tf.float32) # 输入样本像素为28*28y_ = tf.placeholder(name="y-input", shape=[None, 10], dtype=tf.float32) # MNIST是十分类# 第一层(隐藏层)with tf.variable_scope("layer1"):weights = tf.get_variable(name="weights", shape=[28*28, 128], initializer=tf.glorot_normal_initializer())biases = tf.get_variable(name="biases", shape=[128], initializer=tf.glorot_normal_initializer())layer1 = tf.nn.relu(tf.matmul(x, weights) + biases, name="layer1")# 第二层(输出层)with tf.variable_scope("layer2"):weights = tf.get_variable(name="weights", shape=[128, 10], initializer=tf.glorot_normal_initializer())biases = tf.get_variable(name="biases", shape=[10], initializer=tf.glorot_normal_initializer())y = tf.add(tf.matmul(layer1, weights), biases, name="y")pred = tf.argmax(y, axis=1, name="pred")global_step = tf.contrib.framework.get_or_create_global_step() # 必须手动声明global_step否则会报错# 损失和优化cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, axis=1))loss = tf.reduce_mean(cross_entropy)# **通过tf.train.SyncReplicasOptimizer函数实现函数同步更新**opt = tf.train.SyncReplicasOptimizer(tf.train.GradientDescentOptimizer(0.01),replicas_to_aggregate=n_workers,total_num_replicas=n_workers)sync_replicas_hook = opt.make_session_run_hook(is_chief)train_op = opt.minimize(loss, global_step=global_step)if is_chief:train_op = tf.no_op()hooks = [sync_replicas_hook, tf.train.StopAtStepHook(last_step=10000)] # 把同步更新的hook加进来config = tf.ConfigProto(allow_soft_placement=True, # 设置成True,那么当运行设备不满足要求时,会自动分配GPU或者CPU。log_device_placement=False, # 设置为True时,会打印出TensorFlow使用了哪种操作)# ========== STEP5: 打开会话 ========== ## 对于分布式训练,打开会话时不采用tf.Session(),而采用tf.train.MonitoredTrainingSession()# 详情参考:https://www.cnblogs.com/estragon/p/10034511.htmlwith tf.train.MonitoredTrainingSession(master=server.target,is_chief=is_chief,checkpoint_dir=MODEL_DIR,hooks=hooks,save_checkpoint_secs=10,config=config) as sess:print("session started!")start_time = time.time()step = 0while not sess.should_stop():xs, ys = mnist.train.next_batch(BATCH_SIZE) # batch_size=32_, loss_value, global_step_value = sess.run([train_op, loss, global_step], feed_dict={x:xs, y_:ys})if step > 0 and step % 100 == 0:duration = time.time() - start_timesec_per_batch = duration / global_step_valueprint("After %d training steps(%d global steps), loss on training batch is %g (%.3f sec/batch)" % (step, global_step_value, loss_value, sec_per_batch))step += 1if __name__ == "__main__":tf.app.run()
同步分布式训练与异步分布式训练几乎一样,只有两点差别:
- 优化器要用tf.train.SyncReplicasOptimizer代替tf.train.GradientDescentOptimizer
- hooks要将sync_replicas_hook = opt.make_session_run_hook(is_chief)也加进来
其他的都和异步分布式训练一样,这里就不做赘述了。
不错的例子及说明:
https://github.com/TracyMcgrady6/Distribute_MNIST/tree/master
相关文章:

tensorflow1.13分布式训练 参考资料 -教程原理
前言 对于数据量较大的时候,通过分布式训练可以加速训练。相比于单机单卡、单机多卡只需要用with tf.device(‘/gpu:0’)来指定GPU进行计算的情况,分布式训练因为涉及到多台机器之间的分工交互,所以更麻烦一些。本文简单介绍了多机(单卡/多卡…...

DP学习第五篇之礼物的最大价值
DP学习第五篇之礼物的最大价值 剑指 Offer 47. 礼物的最大价值 - 力扣(LeetCode) 一.题目解析 二. 算法原理 状态表示 tips: 经验题目要求。以[i,j]位置为结尾,。。。 dp[i][j]: 到达[i, j]位置时,此时的最大礼物价值 状态转移…...
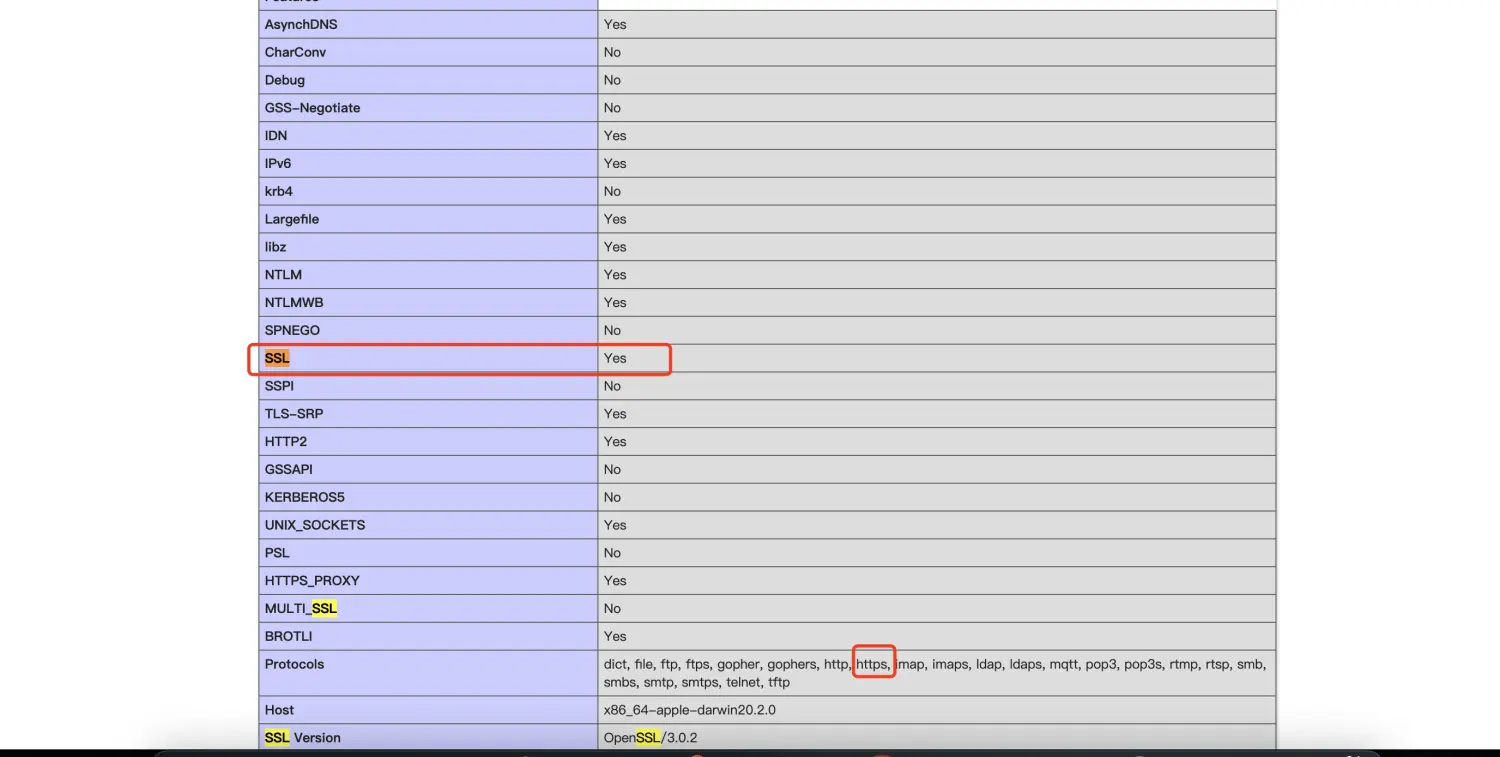
cURL error 1: Protocol “https“ not supported or disabled in libcurl
1、php项目composer update报错 2、curl -V检查 发现curl已经支持了https了 3、php版本检查 4、php插件检查 插件也已经含有openssl组件了 5、phpinfo检查 curl是否开启ssl 定位到问题所在,php7.4的 curl扩展不支持 https 需要重装 php7.4的curl扩展 6、curl下载 下…...

XCode升级后QT无法编译的问题
原因是SDK的版本变了,Qt配置的版本要修改。 解决办法如下: 1.找到 /Users/*/Qt/5.15.2/clang_64/mkspecsqdevice.pri 这个文件打开编辑, 在文件末尾追加一句 !host_build:QMAKE_MAC_SDKmacosx13.1 至于这个版本号13.1是怎么来的呢࿱…...

springboot编写mp4视频播放接口
简单粗暴方式 直接读取指定文件,用文件流读取视频文件,输出到响应中 GetMapping("/display1/{fileName}")public void displayMp41(HttpServletRequest request, HttpServletResponse response,PathVariable("fileName") String fi…...

华为OD机试真题 JavaScript 实现【机器人活动区域】【2023Q1 200分】,附详细解题思路
目录 一、题目描述二、输入描述三、输出描述四、解题思路五、JavaScript算法源码六、效果展示1、输入2、输出 华为OD机试 2023B卷题库疯狂收录中,刷题点这里 刷的越多,抽中的概率越大,每一题都有详细的答题思路、详细的代码注释、样例测试&am…...

C++中的静态分配和动态分配
为什么不是 LaoJiaHelper mydalnew LaoJiaHelper (); 而是LaoJiaHelper mydal? 这个都没有new ,对象为什么能用?在 C 中,有两种创建对象的方式:静态分配和动态分配。 静态分配: 当你使用类似 LaoJiaHelpe…...

【Android常见问题(五)】- Flutter项目性能优化
文章目录 知识回顾前言源码分析1. 渲染过程2. 分析工具3. 优化方法合理使用const关键词合理使用组件管理着色器编译垃圾 知识回顾 前言 项目迭代开发一定程度后,性能优化是重中之重,其中包括了包体积,UI 渲染、交互等多个方面。 通过 Flutt…...
)
JSON转换:实体类和JSONObject互转,List和JSONArray互转(fastjson版)
//1.java对象转化成String String sJSONObject.toJSONString(javaObject.class); //2. java对象转化成Object Object strJSONObject.toJSON(javaObject.class); //3.String类型转json对象 JSONObject jsonObject JSONObject.parseObject(str); //4. String…...

Java单例模式几种代码详解
在软件开发中,单例模式是一种常见的设计模式,它的目的是确保一个类在任何情况下都只有一个实例,同时提供一个全局访问点。在Java中,有几种常见的实现单例模式的方式,下面将逐一进行详细解释。 懒汉式(非线…...
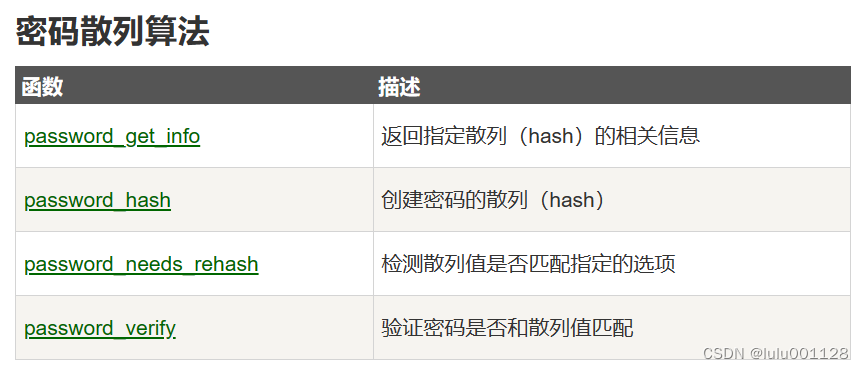
PHP代码审计--理论
提供资料: php 基础 : https://www.runoob.com/php/php-tutorial.html php是什么? PHP 是服务器端脚本语言。 首先在学习PHP前需要对HTML 和CSS有一定的认识 PHP 能做什么? PHP 可以生成动态页面内容PHP 可以创建、打开、读取、写入、关…...

在云服务器上,clone github时报Connection timed outexit code: 128
文章目录 问题解决方案 问题 在执行pip install安装依赖时,需要clone github代码,此时报了Connection timed out&exit code: 128错误,原因是访问超时了,此时需要使用代理 fatal: unable to access https://github.com/hugg…...
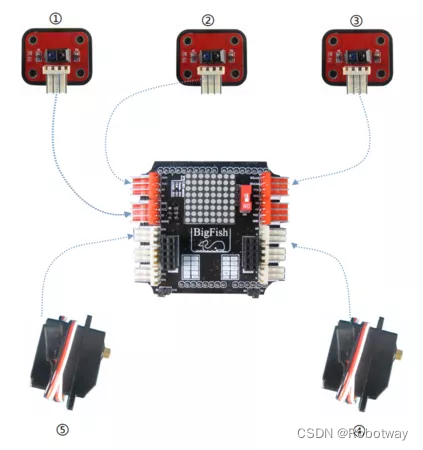
小型双轮差速底盘寻迹功能的实现
1. 功能说明 寻迹机器人是一种能够跟踪特定物体或线路的机器人。它们通常具有以下功能和特点: ① 传感器:寻迹机器人配备了用于感知环境的传感器,如摄像头、灰度传感器等。这些传感器可以探测地面上的标记、颜色、纹理或其他特定特征…...

第七篇:k8s集群使用helm3安装Prometheus Operator
安装Prometheus Operator 目前网上主要有两种安装方式,分别为:1. 使用kubectl基于manifest进行安装 2. 基于helm3进行安装。第一种方式比较繁琐,需要手动配置yaml文件,特别是需要配置pvc相关内容时,涉及到的yaml文件太…...
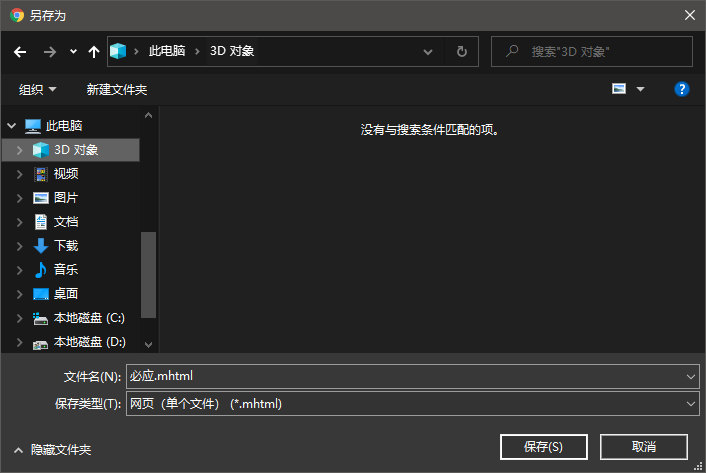
Chrome 75不支持保存成mhtml的解决方法
在Chrome 75之前,可以设置chrome://flags -> save as mhtml来保存网页为mhtml。 升级新版,发现无法另存为/保存网页为MHTML了。 在网上搜索无果后,只得从chromium项目的commits中查找,原来chrome搞了个"Chrome Flag Owner…...

工程监测振弦采集仪应用于岩土工程监测案例
振弦采集仪是一种用于测量地面或岩土中振动参数的仪器,可以对地基、土壤和岩体的性质及其变化进行监测。在岩土工程监测中,振弦传感器被广泛应用于测量土体或岩体的振动情况,以了解地震或其他自然灾害的影响。 以下是一个振弦采集仪应用岩土工…...

配置HDFS单机版,打造数据存储的强大解决方案
目录 简介:步骤:安装java下载安装hadoop配置hadoop-env.sh配置 core-site.xml配置hdfs-site.xml初始化hdfs文件系统启动hdfs服务验证hdfs 结论: 简介: Hadoop分布式文件系统(HDFS)是Hadoop生态系统中的一个…...
U盘删除的文件怎么找回?4个简单方法分享!
“在u盘里不小心删除的文件到底还能不能找回来呀?真的好着急啊!这个u盘对我来说真的很重要,怎么恢复里面的数据呢?请各位大佬帮帮我吧!” 作为一个便捷的存储工具,u盘逐渐获得大众的青睐。在互联网时代&…...
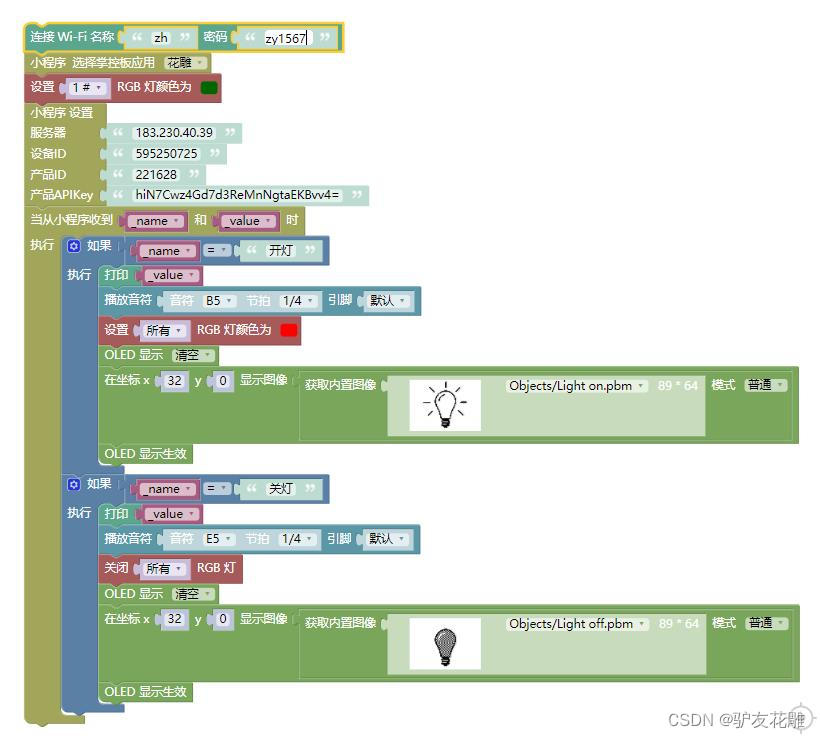
【雕爷学编程】MicroPython动手做(27)——物联网之掌控板小程序2
知识点:什么是掌控板? 掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED…...

形参动态内存开辟和柔性数组
//柔性数组 //定义:结构体最后一个成员允许是未知大小的数组 // 优点;在开辟空间时,连续开辟,便于释放空间,不会因多次开辟,导致释放空间出错 // 开辟空间时,节省动态开辟次数,节省空间&am…...

一键部署开源 AI 项目教程:OpenClaw 下载安装启动卸载全流程
AIStarter 是什么?一文彻底讲清楚很多朋友第一次看到 AIStarter 和 PanelAI 都比较懵:这到底是个什么工具?简单来说,AIStarter 是一款专为本地 AI 部署打造的一键安装管理平台,它能帮助开发者快速下载、安装、启动各种…...

Promptfoo的搭建与测试,2026-0521成功版很简单
可能写的有点粗糙,但是我搞通了,有不懂的可以问我,懒得再更新了 其实我也是520当天搭建好的,现在的教程也不多,我就搜了搜,没什么具体的步骤,我想用windows感觉更方便一点但是一直不行各种版本…...

Wireshark深度解析:HTTP/1.1协议层隐写与pcapng元数据取证
1. 这不是一次普通的数据包分析,而是一场“协议层藏宝游戏”Wireshark实战:解密http1.pcapng中的隐藏flag——光看标题,你可能以为这只是又一篇教你怎么点开Filter框、输http然后截图的入门教程。但实际操作中,我连续三次在http1.…...

C语言内联函数与宏的深度解析:性能、安全与工程实践
1. 项目概述:为什么我们需要关注内联与宏?在C语言的日常开发中,尤其是性能敏感或嵌入式领域的项目里,我们经常面临一个选择:为了实现一个简单的、频繁调用的功能,是写一个函数,还是用一个宏来搞…...

影刀RPA跨境店群运营架构:Python协同Chromium底层调度与高并发容器化实战
定了。在跨境电商自动化的技术角斗场里,我们终于打破了“商业指纹浏览器单机RPA”的低效垄断,实现了一套足以支撑万级店铺矩阵的分布式微服务调度架构。 这几天,科技圈被“DeepSeek V4 首发华为昇腾芯片,国产 AI 开始打破英伟达 …...

chatgpt-web-midjourney-proxy的移动端PWA应用:离线AI工具开发指南
chatgpt-web-midjourney-proxy的移动端PWA应用:离线AI工具开发指南 chatgpt-web-midjourney-proxy项目是一个强大的AI工具集成平台,将ChatGPT、Midjourney绘图和GPTs功能统一在一个界面中。通过PWA技术,这个项目可以轻松转换为移动端离线应用…...

软考高项案例分析9:项目采购管理
软考高项案例分析9:项目采购管理 一、项目采购管理过程 1、规划采购管理; 2、实施采购管理; 3、控制采购; 二、案例分析知识点 1. 采购管理的过程及定义作用 规划采购管理:是记录项目采购决策、明确采购方法,及识别潜在卖方的过程。作用:确定是否从项目外部获取货物…...

Nova垃圾收集器终极教程:安全点GC设计与实现原理
Nova垃圾收集器终极教程:安全点GC设计与实现原理 【免费下载链接】nova JS engine lolz 项目地址: https://gitcode.com/gh_mirrors/nova14/nova Nova是一款高性能JavaScript引擎,其垃圾收集器(GC)采用了先进的安全点设计&…...

Zed与VSCode争议背后真相:性能瓶颈到底是谁的锅
别被骗了!Zed比VS Code快?真正的原因让你哭笑不得!本文深入分析开发者社区对Zed编辑器与VS Code的争议,澄清性能瓶颈的真相在于语言服务器协议(LSP)而非编辑器本身,揭示Zed真正的优势在于原生Vim模式和架构简洁性&…...

D2001UK,1GHz频段下2.5W高功率输出的单端式硅DMOS RF FET射频晶体管
简介今天我要向大家介绍的是 Semelab 的硅DMOS RF FET晶体管——D2001UK。这是一款专为VHF/UHF通信频段(50 MHz至1 GHz)设计的单端式射频功率场效应管,在28V工作电压、1GHz频率下可提供2.5W的输出功率。作为一款高性能射频器件,它…...