Ceph错误汇总
title: “Ceph错误汇总”
date: “2020-05-14”
categories:
- “技术”
tags:
- “Ceph”
- “错误汇总”
toc: false
original: true
draft: true
Ceph错误汇总
1、执行ceph-deploy报错
1.1、错误信息
➜ ceph-deploy
Traceback (most recent call last):File "/usr/bin/ceph-deploy", line 18, in <module>from ceph_deploy.cli import mainFile "/usr/lib/python2.7/site-packages/ceph_deploy/cli.py", line 1, in <module>import pkg_resources
ImportError: No module named pkg_resources
1.2、解决办法
➜ yum install python-setuptools -y
2、安装ceph连接超时
2.1、错误信息
[node1][DEBUG ] Downloading packages:
[node1][WARNIN] No data was received after 300 seconds, disconnecting...
[node1][INFO ] Running command: ceph --version
[node1][ERROR ] Traceback (most recent call last):
[node1][ERROR ] File "/usr/lib/python2.7/site-packages/ceph_deploy/lib/vendor/remoto/process.py", line 119, in run
[node1][ERROR ] reporting(conn, result, timeout)
[node1][ERROR ] File "/usr/lib/python2.7/site-packages/ceph_deploy/lib/vendor/remoto/log.py", line 13, in reporting
[node1][ERROR ] received = result.receive(timeout)
[node1][ERROR ] File "/usr/lib/python2.7/site-packages/ceph_deploy/lib/vendor/remoto/lib/vendor/execnet/gateway_base.py", line 704, in receive
[node1][ERROR ] raise self._getremoteerror() or EOFError()
[node1][ERROR ] RemoteError: Traceback (most recent call last):
[node1][ERROR ] File "<string>", line 1036, in executetask
[node1][ERROR ] File "<remote exec>", line 12, in _remote_run
[node1][ERROR ] File "/usr/lib64/python2.7/subprocess.py", line 711, in __init__
[node1][ERROR ] errread, errwrite)
[node1][ERROR ] File "/usr/lib64/python2.7/subprocess.py", line 1327, in _execute_child
[node1][ERROR ] raise child_exception
[node1][ERROR ] OSError: [Errno 2] No such file or directory
[node1][ERROR ]
[node1][ERROR ]
[ceph_deploy][ERROR ] RuntimeError: Failed to execute command: ceph --version
2.2、解决方法
➜ export CEPH_DEPLOY_REPO_URL=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/
➜ export CEPH_DEPLOY_GPG_URL=https://mirrors.aliyun.com/ceph/keys/release.asc➜ ceph-deploy install ceph-mon1 ceph-osd1 ceph-osd2
3、ceph -s 执行失败
3.1、错误信息
➜ ceph -s
2020-03-06 03:41:43.104 7f5aedc74700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
2020-03-06 03:41:43.104 7f5aedc74700 -1 monclient: ERROR: missing keyring, cannot use cephx for authentication
3.2、解决方法
➜ cd /opt/ceph-cluster# 添加admin key至/etc/ceph
➜ ceph-deploy admin ceph-mon1 ceph-osd1 ceph-osd2
或
➜ cp ceph.client.admin.keyring /etc/ceph
4、硬盘无法格式化
4.1、错误信息
# 磁盘无法进行格式化
➜ mkfs.xfs /dev/sdb
mkfs.xfs: cannot open /dev/sdb: Device or resource busy
4.2、错误解决
# 查看磁盘状态
➜ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 80G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 79G 0 part├─centos-root 253:0 0 50G 0 lvm /├─centos-swap 253:1 0 2G 0 lvm └─centos-home 253:2 0 27G 0 lvm /home
sdb 8:16 0 50G 0 disk
└─ceph--f5aefc82--f489--4a94--abcd--87934fcbb457-osd--block--41ba649f--f99e--40f6--b2f9--afda1251c0ad 253:3 0 49G 0 lvm # 发现ceph的一些服务占用着磁盘
sr0# 列出占用
➜ dmsetup ls
ceph--f5aefc82--f489--4a94--abcd--87934fcbb457-osd--block--41ba649f--f99e--40f6--b2f9--afda1251c0ad (253:3)
centos-home (253:2)
centos-swap (253:1)
centos-root (253:0)# 移除占用
➜ dmsetup remove ceph--f5aefc82--f489--4a94--abcd--87934fcbb457-osd--block--41ba649f--f99e--40f6--b2f9--afda1251c0ad# 查看状态
➜ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 80G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 79G 0 part├─centos-root 253:0 0 50G 0 lvm /├─centos-swap 253:1 0 2G 0 lvm └─centos-home 253:2 0 27G 0 lvm /home
sdb 8:16 0 50G 0 disk
sr0 11:0 1 1024M 0 rom# 格式化硬盘
➜ mkfs.xfs -f /dev/sdb
meta-data=/dev/sdb isize=512 agcount=4, agsize=3276800 blks= sectsz=512 attr=2, projid32bit=1= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=13107200, imaxpct=25= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=6400, version=2= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
5、too few PGs per OSD
5.1、错误信息
➜ ceph -scluster:id: 243f3ae6-326a-4af6-9adb-6538defbacb7health: HEALTH_WARNReduced data availability: 128 pgs inactive, 128 pgs staleDegraded data redundancy: 128 pgs undersizedtoo few PGs per OSD (12 < min 30)
5.2、关于创建存储池
确定 pg_num 取值是强制性的,因为不能自动计算。下面是几个常用的值:
*少于 5 个 OSD 时可把 pg_num 设置为 128
*OSD 数量在 5 到 10 个时,可把 pg_num 设置为 512
*OSD 数量在 10 到 50 个时,可把 pg_num 设置为 4096
*OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算 pg_num 取值
*自己计算 pg_num 取值时可借助 pgcalc 工具
随着 OSD 数量的增加,正确的 pg_num 取值变得更加重要,因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)。
5.3、解决办法
# 删除pool重建
➜ ceph osd pool delete kube kube --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool#根据提示需要将mon_allow_pool_delete的value设置为true
➜ vim /opt/ceph-cluster/ceph.conf
mon_allow_pool_delete = true# 传送配置文件
➜ ceph-deploy --overwrite-conf config push ceph-mon1 ceph-osd1 ceph-osd2# 列出所有ceph服务
➜ systemctl list-units --type=service | grep ceph
ceph-crash.service loaded active running Ceph crash dump collector
ceph-mgr@ceph-mon1.service loaded active running Ceph cluster manager daemon
ceph-mon@ceph-mon1.service loaded active running Ceph cluster monitor daemon# 重启服务ceph服务
➜ systemctl restart ceph-mgr@ceph-mon1.service
➜ systemctl restart ceph-mon@ceph-mon1.service# 删除kube存储池
➜ ceph osd pool delete kube kube --yes-i-really-really-mean-it
pool 'kube' removed# 重新创建kube存储池
➜ ceph osd pool create kube 512
pool 'kube' created
➜ ceph -scluster:id: 243f3ae6-326a-4af6-9adb-6538defbacb7health: HEALTH_OK # 集群状态okservices:mon: 1 daemons, quorum ceph-mon1mgr: ceph-mon1(active)osd: 10 osds: 10 up, 10 indata:pools: 1 pools, 512 pgsobjects: 0 objects, 0 Busage: 10 GiB used, 80 GiB / 90 GiB availpgs: 100.000% pgs unknown512 unknown
6、application not enabled on 1 pool
6.1、错误信息
➜ ceph health
HEALTH_WARN application not enabled on 1 pool(s)
6.2、错误解决
➜ ceph health detail
HEALTH_WARN application not enabled on 1 pool(s)
POOL_APP_NOT_ENABLED application not enabled on 1 pool(s)application not enabled on pool 'kube'use 'ceph osd pool application enable <pool-name> <app-name>', where <app-name> is 'cephfs', 'rbd', 'rgw', or freeform for custom applications.
➜ ceph osd pool application enable kube rbd
enabled application 'rbd' on pool 'kube'
➜ ceph health
HEALTH_OK
7、安装ceph-common报错
7.1、错误信息
--> Finished Dependency Resolution
Error: Package: 2:ceph-common-13.2.8-0.el7.x86_64 (ceph)Requires: libleveldb.so.1()(64bit)
Error: Package: 2:ceph-common-13.2.8-0.el7.x86_64 (ceph)Requires: liboath.so.0(LIBOATH_1.10.0)(64bit)
Error: Package: 2:librbd1-13.2.8-0.el7.x86_64 (ceph)Requires: liblttng-ust.so.0()(64bit)
Error: Package: 2:ceph-common-13.2.8-0.el7.x86_64 (ceph)Requires: libbabeltrace-ctf.so.1()(64bit)
Error: Package: 2:ceph-common-13.2.8-0.el7.x86_64 (ceph)Requires: libbabeltrace.so.1()(64bit)
Error: Package: 2:ceph-common-13.2.8-0.el7.x86_64 (ceph)Requires: liboath.so.0(LIBOATH_1.2.0)(64bit)
Error: Package: 2:librgw2-13.2.8-0.el7.x86_64 (ceph)Requires: liboath.so.0()(64bit)
Error: Package: 2:librados2-13.2.8-0.el7.x86_64 (ceph)Requires: liblttng-ust.so.0()(64bit)
Error: Package: 2:librgw2-13.2.8-0.el7.x86_64 (ceph)Requires: liblttng-ust.so.0()(64bit)
Error: Package: 2:ceph-common-13.2.8-0.el7.x86_64 (ceph)Requires: liboath.so.0()(64bit)You could try using --skip-broken to work around the problemYou could try running: rpm -Va --nofiles --nodigest
7.2、错误解决
# 安装epel仓库
➜ ansible k8s-node -m copy -a "src=/etc/yum.repos.d/aliyun.repo dest=/etc/yum.repos.d/aliyun.repo"# 安装ceph-common
➜ ansible k8s-node -m shell -a "yum install -y ceph-common"
8、修复down掉的ceph osd
8.1、错误信息
➜ ceph -scluster:id: 243f3ae6-326a-4af6-9adb-6538defbacb7health: HEALTH_ERR2/99 objects unfound (2.020%)Reduced data availability: 1 pg inactive, 1 pg peering, 1 pg stalePossible data damage: 2 pgs recovery_unfoundDegraded data redundancy: 4/198 objects degraded (2.020%), 2 pgs degraded16 slow ops, oldest one blocked for 47468 sec, daemons [osd.4,osd.8] have slow ops.mon ceph-mon1 is low on available spaceservices:mon: 1 daemons, quorum ceph-mon1mgr: ceph-mon1(active)osd: 10 osds: 7 up, 7 in # 10个OSD,有三个不在集群内,已经down掉了。data:pools: 1 pools, 512 pgsobjects: 99 objects, 140 MiBusage: 7.5 GiB used, 56 GiB / 63 GiB availpgs: 0.195% pgs not active4/198 objects degraded (2.020%)2/99 objects unfound (2.020%)509 active+clean2 active+recovery_unfound+degraded1 stale+peeringio:client: 28 KiB/s wr, 0 op/s rd, 2 op/s wr
➜ ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.08789 root default
-3 0.04395 host ceph-osd10 hdd 0.00879 osd.0 up 1.00000 1.000001 hdd 0.00879 osd.1 up 1.00000 1.000002 hdd 0.00879 osd.2 down 0 1.000003 hdd 0.00879 osd.3 down 0 1.000004 hdd 0.00879 osd.4 up 1.00000 1.00000
-5 0.04395 host ceph-osd25 hdd 0.00879 osd.5 up 1.00000 1.000006 hdd 0.00879 osd.6 up 1.00000 1.000007 hdd 0.00879 osd.7 up 1.00000 1.000008 hdd 0.00879 osd.8 up 1.00000 1.000009 hdd 0.00879 osd.9 down 0 1.00000
8.2、错误分析
状态说明:集群内(in)集群外(out)活着且在运行(up)挂了且不再运行(down)说明:如果OSD活着,它也可以是 in或者 out 集群。如果它以前是 in 但最近 out 了, Ceph 会把其归置组迁移到其他OSD 。如果OSD out 了, CRUSH 就不会再分配归置组给它。如果它挂了( down )其状态也应该是 out 。如果OSD 状态为 down 且 in ,必定有问题,而且集群处于非健康状态。
8.3、错误解决
# 先拉起所有osd
# ceph-osd1
➜ systemctl start ceph-osd@2
➜ systemctl start ceph-osd@3# ceph-osd2
➜ systemctl start ceph-osd@9➜ ceph-volume lvm activate --all# 从Ceph版本13.0.0开始,ceph-disk已弃用
# 从搜索引擎搜索到以下激活osd的操作均已失效
# 1、ceph-deploy osd activate ceph-osd1:/dev/sdb1 ceph-osd1:/dev/sdb2 ceph-osd1:/dev/sdb3 ceph-osd1:/dev/sdb4 ceph-osd1:/dev/sdb5 ceph-osd2:/dev/sdb1 ceph-osd2:/dev/sdb2 ceph-osd2:/dev/sdb3 ceph-osd2:/dev/sdb4 ceph-osd2:/dev/sdb5
# 2、ceph-disk activate-all
9、磁盘无法加入
9.1、错误信息
➜ ceph-deploy osd create --data /dev/sdb1 ceph-osd
[ceph-osd][WARNIN] Running command: /bin/ceph-authtool --gen-print-key
[ceph-osd][WARNIN] Running command: /bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring -i - osd new 08864eab-9a28-47ce-8ab7-829f6624d8c7
[ceph-osd][WARNIN] stderr: [errno 1] error connecting to the cluster
[ceph-osd][WARNIN] --> RuntimeError: Unable to create a new OSD id
[ceph-osd][ERROR ] RuntimeError: command returned non-zero exit status: 1
[ceph_deploy.osd][ERROR ] Failed to execute command: /usr/sbin/ceph-volume --cluster ceph lvm create --bluestore --data /dev/sdb1
[ceph_deploy][ERROR ] GenericError: Failed to create 1 OSDs
9.2、错误解决
10、对象存储删除pool
10.1、错误信息
# 删除错误
➜ rados rmpool .rgw.root
WARNING:This will PERMANENTLY DESTROY an entire pool of objects with no way back.To confirm, pass the pool to remove twice, followed by # 由于删除是非常危险的操作,请确认两遍名字--yes-i-really-really-mean-it # 并且增加确认选项,表明我真的想这样做# 确认选项增加后报错
➜ rados rmpool .rgw.root .rgw.root --yes-i-really-really-mean-it
pool .rgw.root could not be removed
Check your monitor configuration - `mon allow pool delete` is set to false by default, change it to true to allow deletion of pools # 需要在ceph配置文件,ceph-mon的配置中加入允许
error 1: (1) Operation not permitted
10.2、解决错误
# 修改ceph.conf
➜ vim /opt/ceph-cluster/ceph.conf
mon_allow_pool_delete = true# 推送配置文件
➜ ceph-deploy --overwrite-conf config push ceph-mon node234# 重启服务
➜ systemctl restart ceph-mon@ceph-mon# 删除pool
➜ rados rmpool .rgw.root .rgw.root --yes-i-really-really-mean-it
successfully deleted pool .rgw.root
11、对象存储创建pool – pg数量不足
11.1、错误信息
➜ cat ceph-rgw-pool.sh
#!/bin/bashPG_NUM=128
PGP_NUM=128
SIZE=3pool='.rgw
.rgw.root
.rgw.control
.rgw.gc
.rgw.buckets
.rgw.buckets.index
.rgw.buckets.extra
.log
.intent-log
.usage
.users
.users.email
.users.swift
.users.uid'for i in $(echo $pool)
doceph osd pool create $i $PG_NUMsleep 1ceph osd pool set $i size $SIZEceph osd pool set $i pgp_num $PGP_NUM
done➜ ./ceph-rgw-pool.sh
pool '.rgw' created
set pool 6 size to 3
set pool 6 pgp_num to 128
pool '.rgw.root' created
Error ERANGE: pool id 7 pg_num 128 size 3 would mean 816 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
set pool 7 pgp_num to 128
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.rgw.control'
Error ENOENT: unrecognized pool '.rgw.control'
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.rgw.gc'
Error ENOENT: unrecognized pool '.rgw.gc'
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.rgw.buckets'
Error ENOENT: unrecognized pool '.rgw.buckets'
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.rgw.buckets.index'
Error ENOENT: unrecognized pool '.rgw.buckets.index'
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.rgw.buckets.extra'
Error ENOENT: unrecognized pool '.rgw.buckets.extra'
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.log'
Error ENOENT: unrecognized pool '.log'
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.intent-log'
Error ENOENT: unrecognized pool '.intent-log'
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.usage'
Error ENOENT: unrecognized pool '.usage'
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.users'
Error ENOENT: unrecognized pool '.users'
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.users.email'
Error ENOENT: unrecognized pool '.users.email'
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.users.swift'
Error ENOENT: unrecognized pool '.users.swift'
Error ERANGE: pg_num 128 size 2 would mean 944 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Error ENOENT: unrecognized pool '.users.uid'
Error ENOENT: unrecognized pool '.users.uid'
11.2、错误分析
报错原因:每个osd最多只支持250个pg,有3个osd,总共有750pg。现在新建了14个池,每个池占用的pg数为(750 / 14).
pool size 设置为3,我们有3个副本,pg_num = (250 * 3 / 14 / 3)
处理办法:1、删除之前的池,然后修改脚本把pg数目设置小一点,再创建对象池。
2、为了以后的使用我们每个池创建10个pg
11.3、错误解决
# 列出已经创建的pool
➜ rados lspools
default.rgw.control
default.rgw.meta
default.rgw.log
.rgw
.rgw.root# 删除已经创建的pool
➜ rados rmpool .rgw.root .rgw.root --yes-i-really-really-mean-it
➜ rados rmpool .rgw .rgw --yes-i-really-really-mean-it# 修改脚本 pg大小
➜ vim ceph-rgw-pool.sh
PG_NUM=10
PGP_NUM=10
SIZE=3# 重新创建pool
➜ ./ceph-rgw-pool.sh# 列出pool
➜ rados lspools
default.rgw.control
default.rgw.meta
default.rgw.log
.rgw
.rgw.root
.rgw.control
.rgw.gc
.rgw.buckets
.rgw.buckets.index
.rgw.buckets.extra
.log
.intent-log
.usage
.users
.users.email
.users.swift
.users.uid
12、对象存储API – s3cmd 创建 bucket
12.1、错误信息
➜ s3cmd mb s3://first-bucket
ERROR: S3 error: 400 (InvalidLocationConstraint): The specified location-constraint is not valid
12.2、错误解决
➜ vim /root/.s3cfg
bucket_location = ZH # 把ZH改成US# 创建bucket
➜ s3cmd mb s3://first-bucket
Bucket 's3://first-bucket/' created# 列出bucket
➜ s3cmd ls
2020-05-14 07:14 s3://first-bucket
相关文章:

Ceph错误汇总
title: “Ceph错误汇总” date: “2020-05-14” categories: - “技术” tags: - “Ceph” - “错误汇总” toc: false original: true draft: true Ceph错误汇总 1、执行ceph-deploy报错 1.1、错误信息 ➜ ceph-deploy Traceback (most recent call last):File "/us…...

DataTable过滤某些数据
要过滤DataTable中的某些数据,可以使用以下方法: 使用Select方法:可以使用DataTable的Select方法来筛选满足指定条件的数据行。该方法接受一个字符串参数作为过滤条件,返回一个符合条件的数据行数组。 DataTable filteredTable …...
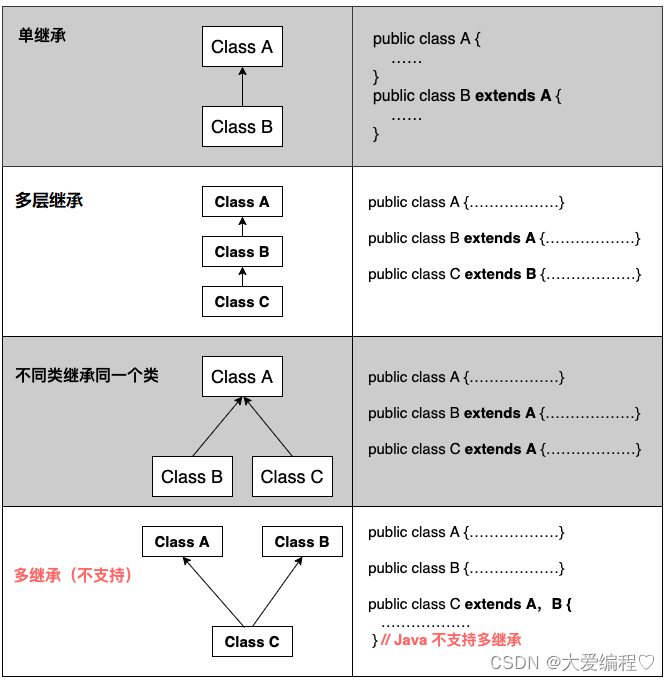
JAVASE---继承和多态
继承 比如,狗和猫,它们都是一个动物,有共同的特征,我们就可以把这种特征抽取出来。 像这样把相同的可以重新放到一个类里面,进行调用,这就是继承。 概念 继承(inheritance)机制:是面向对象程…...

Centos7升级gcc、g++版本(转载)
Centos7默认的 gcc版本是 4.8.5 默认使用yum install gcc安装出来的gcc版本也是是4.8.5。 1.首先查看自己的 gcc 版本 gcc -v g -v如果出现:bash: g: 未找到命令... 则安装g:遇到暂停时,输入y继续安装 yum install gcc-c然后输入…...

第一章:继承
系列文章目录 文章目录 系列文章目录前言继承的概念及定义继承的概念继承定义定义格式继承关系和访问限定符继承基类成员访问方式的变化 基类和派生类对象赋值转换(公有继承)继承中的作用域派生类的默认成员函数继承与友元继承与静态成员不能被继承的类复…...
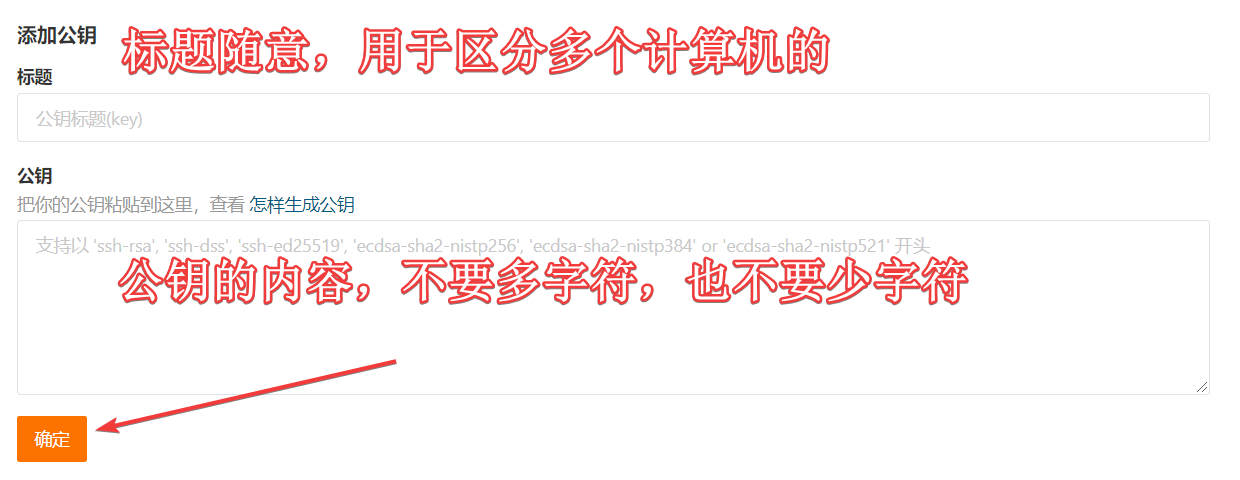
git面试题
文章目录 git经常用哪些指令git出现代码冲突怎么解决你们团队是怎么管理git分支的如何实现Git的免密操作 git经常用哪些指令 产生代码库 新建一个git代码库 git init下载远程项目和它的整个代码历史 git clone 远程仓库地址配置 显示配置 git config --list [--global]编辑配置…...

Github Copilot在JetBrains软件中登录Github失败的解决方案
背景 我在成功通过了Github Copilot的学生认证之后,在VS Code和PyCharm中安装了Github Copilot插件,但在PyCharm中插件出现了问题,在登录Github时会一直Retrieving Github Device Code,最终登录失败。 我尝试了网上修改DNS&…...

使用 github 同步谷歌浏览器书签
想必使用谷歌浏览器Chrome的用户一定非常头疼的一件事就是:账户不能登录,书签收藏夹不能同步,换一台电脑书签收藏夹没有了! 下面教大家一招亲测有效适用的方法解决书签同步问题,在任何电脑都可以同步了 1、去下载谷歌…...
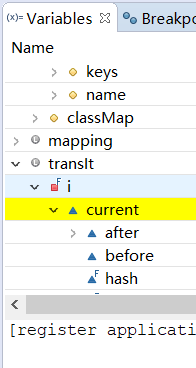
Eclipse进行debug
目录 基本步骤三种执行方式 -- 键盘快捷键variables面板移除debug过的项目通过eclipse调用具有软件界面的项目进行debug各个variable颜色具有的意义 基本步骤 点击eclipse右上角debug按钮 调出debug面板 点击小蜘蛛图标(不是点绿色三角的Run) 此时会进…...
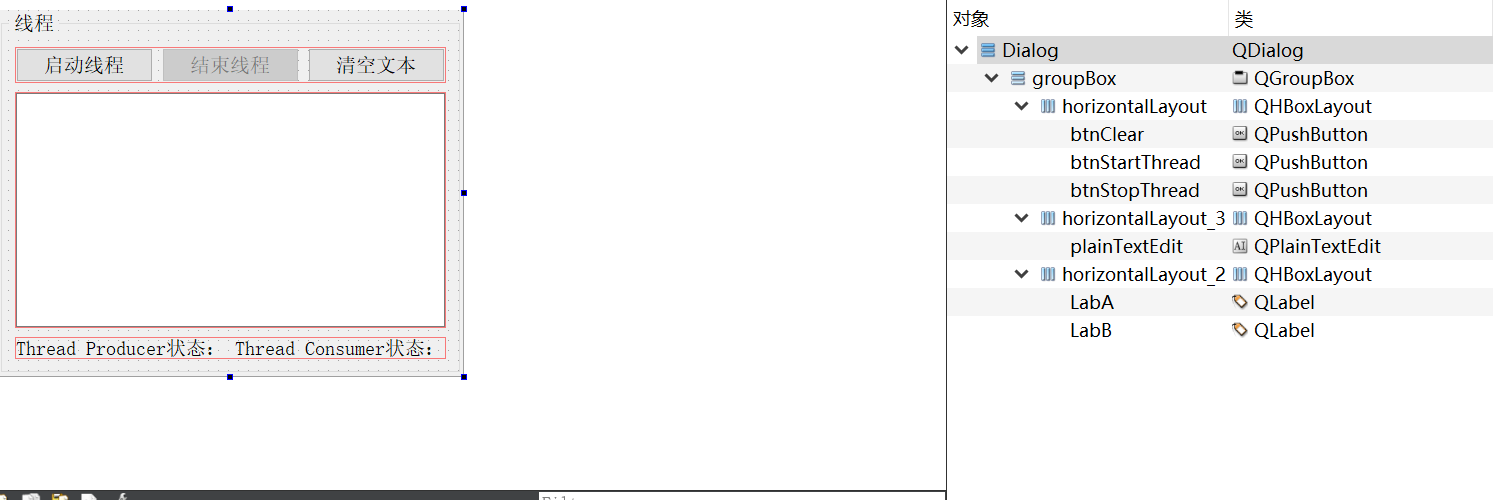
13-5_Qt 5.9 C++开发指南_基于信号量的线程同步_Semaphore
文章目录 1. 信号量的原理2. 双缓冲区数据采集和读取线程类设计3. QThreadDAQ和QThreadShow 的使用4. 源码4.1 可视化UI设计框架4.2 qmythread.h4.3 qmythread.cpp4.4 dialog.h4.5 dialog.cpp 1. 信号量的原理 信号量(Semaphore)是另一种限制对共享资源进行访问的线程同步机制…...

golang使用泛型实现mapreduce操作
1.使用面向对象的方式写 package streamimport ("fmt""log""reflect""sort""strconv""strings" )type Stream[T any] struct {data []TkeyBy stringsortByNum stringsortByStr []string }func FromElem…...
2023华数杯数学建模C题思路分析 - 母亲身心健康对婴儿成长的影响
# 1 赛题 C 题 母亲身心健康对婴儿成长的影响 母亲是婴儿生命中最重要的人之一,她不仅为婴儿提供营养物质和身体保护, 还为婴儿提供情感支持和安全感。母亲心理健康状态的不良状况,如抑郁、焦虑、 压力等,可能会对婴儿的认知、情…...

【汇总】解决Ajax请求后端接口,返回ModelAndView页面不跳转
【汇总】解决Ajax请求后端接口,返回ModelAndView不跳转 问题发现问题解决方法一:直接跳转到指定URL(推荐)方法二:将返回的html内容,插入到页面某个元素中方法三:操作文档流方法四:使…...
网络安全进阶学习第九课——SQL注入介绍
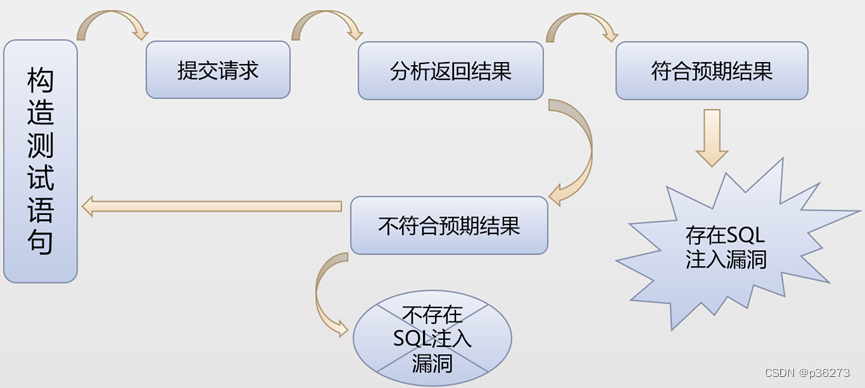
文章目录 一、什么是注入二、什么是SQL注入三、SQL注入产生的原因四、SQL注入的危害五、SQL注入在渗透中的利用1、绕过登录验证:使用万能密码登录网站后台等。2、获取敏感数据3、文件系统操作4、注册表操作5、执行系统命令 六、如何挖掘SQL注入1、SQL注入漏洞分类按…...
一个计算机专业的学生数据结构这门课学到什么程度才能算学的还不错?
数据结构之所以重要是因为它处于算法中的基础地位,与解决实际问题关系密切;而之所以不重要是因为课本上能学到的所有实现都已经有人造过轮子了,甚至已经作为很多语言的标准API存在了。 换句话来说,在以后的编码生涯中,…...

[语义分割] ASPP不同版本对比(DeepLab、DeepLab v1、DeepLab v2、DeepLab v3、DeepLab v3+、LR-ASPP)
1. 引言 1.1 本文目的 本文主要对前段时间学习的 ASPP 模块进行对比,涉及到的 ASPP 有: ASPP in DeepLab v2,简称 ASPP v2ASPP in DeepLab v3,简称 ASPP v3ASPP in DeepLab v3,简称 ASPP v3ASPP in MobileNet v3&am…...

anaconda创建虚拟环境在D盘
【看一看就行,又是挺水的一期(每一季都掺和一点子水分也挺好)】 一、创建: conda create --prefixD:\python37\py37 python3.7 这下就在D盘了: 二、激活刚刚那个环境: activate D:\pyhton37\py37 &…...
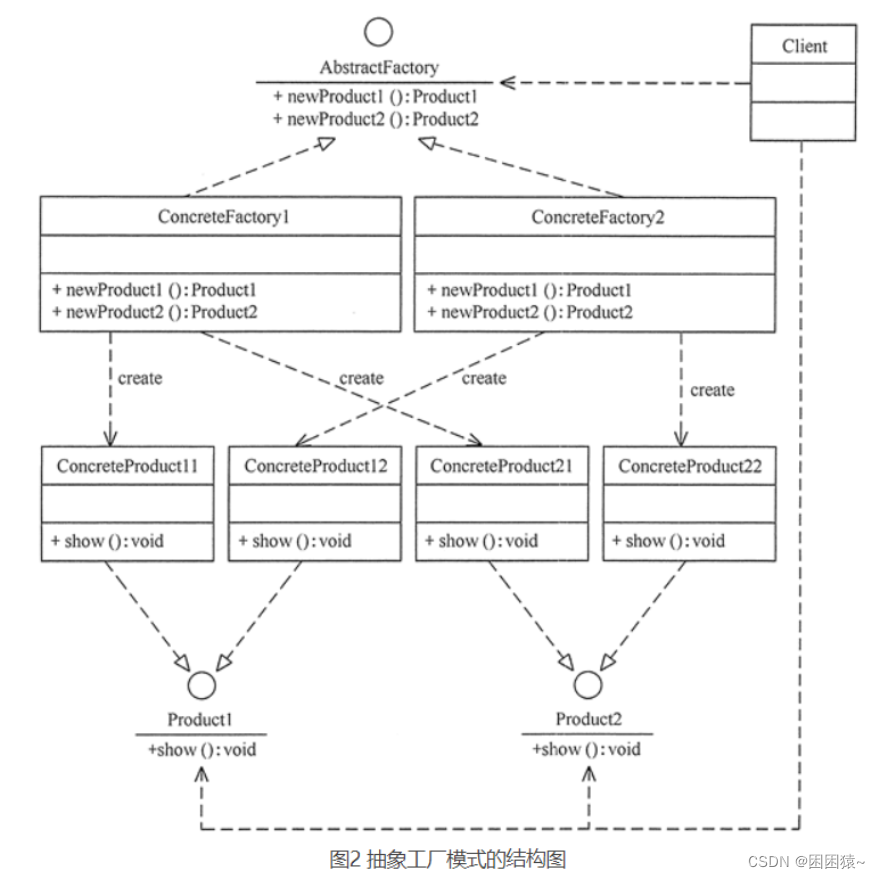
Java设计模式之工厂设计模式
简介 工厂模式是一种常见的设计模式,用于创建对象的过程中,通过工厂类来封装对象的创建过程。其核心思想是将对象的创建和使用分离,从而降低耦合度,提高代码的可维护性和可扩展性。工厂模式通常包括三种类型:简单工厂…...

uniapp使用阿里图标
效果图: 前言 随着uniApp的深入人心,我司也陆续做了几个使用uniapp做的移动端跨平台软件,在学习使用的过程中深切的感受到了其功能强大和便捷,今日就如何在uniapp项目中使用阿里字体图标的问题为大家献上我的一点心得࿰…...
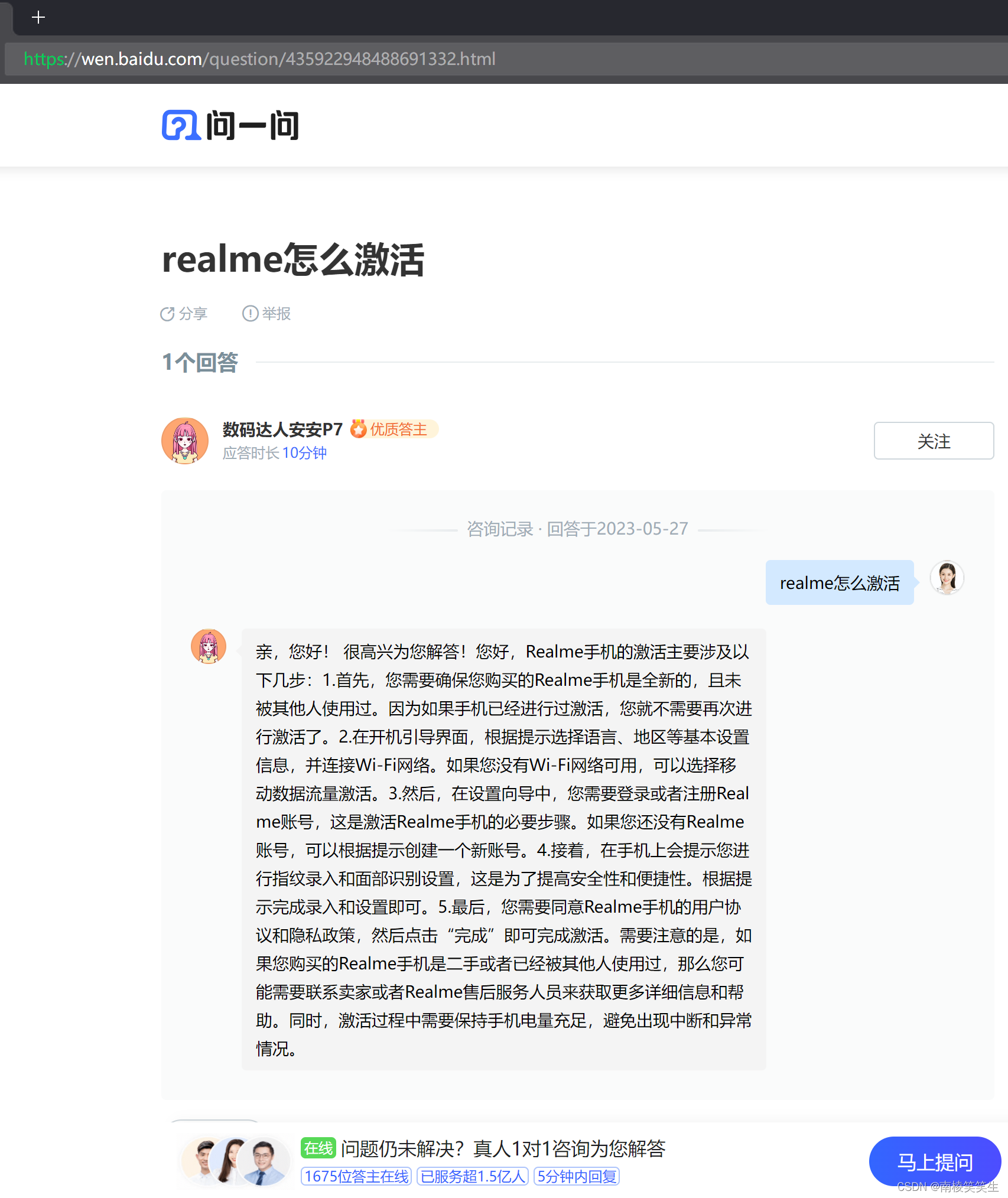
20230803激活手机realme GT Neo3
20230803激活手机realme GT Neo3 缘起: 新买的手机:realme GT Neo3 需要确认: 1、4K录像,时间不限制。 【以前的很多手机都是限制8/10/12/16分钟】 2、通话自动录音 3、定时开关机。 4、GPS记录轨迹不要拉直线:户外助…...
)
农产投入线上管理|基于springboot + vue农产投入线上管理系统(源码+数据库+文档)
农产投入线上管理系统 目录 基于springboot vue农产投入线上管理系统 一、前言 二、系统功能演示 三、技术选型 四、其他项目参考 五、代码参考 六、测试参考 七、最新计算机毕设选题推荐 八、源码获取: 基于springboot vue农产投入线上管理系统 一、前…...

Docker容器优化全攻略
Docker容器优化全攻略 引言:Docker的效率革命 哥们,别整那些花里胡哨的!作为一个前端开发兼摇滚鼓手,我最烦的就是容器体积大、启动慢、运行卡。Docker容器的优化直接关系到部署效率、运行性能和资源消耗。今天,我就给…...

OpenClaw学习助手:Qwen3.5-9B自动整理学术PDF笔记
OpenClaw学习助手:Qwen3.5-9B自动整理学术PDF笔记 1. 为什么需要自动化文献整理 作为一名每天需要阅读大量文献的研究者,我长期被两个问题困扰:一是PDF里的关键信息需要手动复制粘贴到笔记软件,二是不同文献的结论难以横向对比。…...

SEO_如何通过内容SEO获取稳定流量的关键方法
SEO:如何通过内容SEO获取稳定流量的关键方法 在当今数字化时代,如何通过内容SEO获取稳定流量成为了许多企业和网站运营者关注的焦点。内容SEO不仅能够提升网站的自然搜索排名,还能为网站带来长期的、可持续的流量。具体应该如何通过内容SEO获取稳定流量…...

openclaw连接飞书操作表格
01意义 将智能助手从电脑网页端连接到手机飞书,从此无需守在电脑前,用手机就能随时指挥它干活。未来,飞书中需要手动操作的任务,都可以交由 AI 智能助手来完成。它还能帮你构建企业知识库,随着飞书终端 CLI 能力的增强…...
功能【篇】)
杰理之SDK 增加通话翻译(OPUS 立体声)功能【篇】
AI 翻译功能...

目标检测,图像分类。faster,yolo
目标检测,图像分类。faster,yolo...

ParquetViewer:Windows平台最友好的Parquet文件查看与查询工具
ParquetViewer:Windows平台最友好的Parquet文件查看与查询工具 【免费下载链接】ParquetViewer Simple Windows desktop application for viewing & querying Apache Parquet files 项目地址: https://gitcode.com/gh_mirrors/pa/ParquetViewer 还在为Wi…...

Comsol模拟土壤中冰的融化过程:奇妙的微观世界之旅
comsol模拟土壤中冰的融化过程模型 在天气升温过程中,土壤表层的冰融化,深入土壤中,同时随着水流的渗入,土壤中的冰夹杂物融化,采用达西定律与包含相变的“多孔介质传热”接口相耦合,可以模拟土壤中冰夹杂物…...

2026最权威的十大降AI率助手推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 把维普平台针对 AI 生成内容的检测机制作为对象,要降低论文 AI 率得从语言重构以…...