二叉树的相关题目
目录
1、根据二叉树创建字符串
2、二叉树的层序遍历
3、二叉树的最近公共祖先
4、搜索二叉树与双向链表
5、从前序与中序遍历序列构造二叉树
6、 从中序与后序遍历序列构造二叉树
7、二叉树的前序遍历(非递归实现)
8、二叉树的中序遍历(非递归实现)
9、二叉树的后序遍历(非递归实现)
1、根据二叉树创建字符串
题目要求:给你二叉树的根节点
root,请你采用前序遍历的方式,将二叉树转化为一个由括号和整数组成的字符串,返回构造出的字符串。
例1:
前序遍历完应该是"1(2(3)())(5)",但是2没有右孩子,所以可以省略第一个括号
化简为:"1(2(3))(5)"
例2:
前序遍历完应该是"1(2()(3))(5)",但是2没有左孩子,如果省略第一个括号,会辨别不清是左孩子还是右孩子
所以依旧为:"1(2()(3))(5)"
根据上面的样例,可以明白有这样几种情况:
①左右都不为空,则都不省略括号
②左右都为空,都省略括号
③左不为空,右为空,可以省略右括号
④左为空,右不为空,不能省略左括号
总结就是:如果右不为空,无论左边是否为空,右边都需要加括号
如果左不为空或右不为空,则左边需要加括号代码如下:
class Solution { public:string tree2str(TreeNode* root) {//若root为空,则返回一个string的匿名对象if(root == nullptr){return string();}//1、如果左不为空或右不为空,左边需要加括号//2、如果右不为空,右边需要加括号string str;//to_string将val转换为字符变量,以便可以+=str += to_string(root->val);//情况1if(root->left || root->right){str += '(';str += tree2str(root->left);str += ')';}//情况2if(root->right){str += '(';str += tree2str(root->right);str += ')';}return str;} };


2、二叉树的层序遍历
题目要求:给你二叉树的根节点
root,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
思路分析:
我们可以创建一个队列,队列中存的是二叉树的指针,再给一个levelSize,记录每一层的节点数,在循环过程中,创建一个vector<int>的数组,存每一层的结点val值。首先,二叉树若不为空则将root存进队列中,再经过判断将root的左右孩子存进队列中,队列头结点pop前,都将val存入v中,每层结束,都将v的值push_back到vv中,以此类推,具体代码中注释部分有
代码:
class Solution { public:vector<vector<int>> levelOrder(TreeNode* root) {//层序遍历一般会使用队列queue<TreeNode*> q;//levelSize是每一层的节点数size_t levelSize = 0;//如果根节点不为空,则队列中插入root,节点数置为1if(root){q.push(root);levelSize = 1;}//vv是需要返回的vector<vector<int>>vector<vector<int>> vv;//while循环,直到队列为空while(!q.empty()){//创建vector<int> v,存储每一层的结点的valvector<int> v;//for循环保证每次循环一层的结点for(size_t i = 0;i < levelSize; ++i){//由于每次都要删除队列的第一个值//所以front来保留一下指针,以免找不到左右字树TreeNode* front = q.front();q.pop();//每次删除的时候都存进vv.push_back(front->val);//如果删除结点有左右孩子,都存进队列中if(front->left)q.push(front->left);if(front->right)q.push(front->right); }//每循环完一层,就往vv里存一层的val值vv.push_back(v);//接着重新赋值levelSize,即下一层数的节点数levelSize = q.size();}return vv;} };
3、二叉树的最近公共祖先
题目要求:给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
方法一例1:
则最近公共祖先是结点2
方法一例2:
则最近公共祖先是结点4
所以方法一我们可以用下面两个思路:
1、如果一个是左子树中的结点,一个是右子树中的结点,那么它就是最近公共祖先
2、如果一个结点A是结点B的祖先,那么公共祖先就是结点A
方法一的代码:(方法一如果遇到公共祖先在二叉树下面的部分,会导致效率比较低)
class Solution { public:bool Find(TreeNode* root, TreeNode* x){//如果查找的为空,返回nullptrif(root == nullptr)return false;//如果找到了,返回trueif(root == x)return true;//如果没找到,则递归进左右字树找return Find(root->left, x) || Find(root->right, x);}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {if(root == nullptr)return nullptr;//说明公共祖先是root,if((root == p) || (root == q))return root;//p/q在一左一右,则说明当前root是公共祖先//设定4个bool类型变量,与Find结合使用bool pInLeft,pInRight,qInleft,qInRight;pInLeft = Find(root->left, p);pInRight = !pInLeft;//在左就说明不在右,所以可以用!qInleft = Find(root->left, q);qInRight = !qInleft;//一个在左一个在右,则它是公共祖先if((pInLeft && qInRight) || (pInRight && qInleft))return root;//若都在root左或右,则递归进左或右子树中,重新判断上面的条件else if(pInLeft && qInleft)return lowestCommonAncestor(root->left, p, q);else if(pInRight && qInRight)return lowestCommonAncestor(root->right, p, q);//此题不会进入这里,因为p/q都在二叉树中elsereturn nullptr;} };方法二思路:(相比方法一效率高点,O(N))
将p和q的从根结点开始的路径放入栈中,将所得两个结点的较长的路径pop到和较短路径一样长为止,然后依次判断栈顶元素是否相同
思路类似链表相交
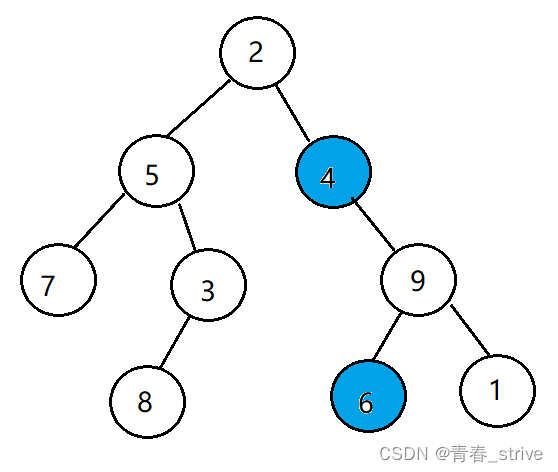
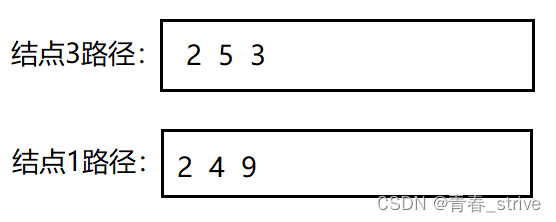
方法二例子:
结点3和结点1的路径放栈里如图:
结点1路径长度大,pop相等后变为:
接着从两个栈顶元素3和9开始判断,不相同,两个都pop,直到遇到2,返回结点2
方法二代码:
class Solution { public:bool FindPath(TreeNode* root, TreeNode* x, stack<TreeNode*>& path){//是空返回falseif(root == nullptr)return false;//不论是不是先入栈,因为后面判断不是路径会poppath.push(root);//如果找到了,返回trueif(root == x)return true;//如果没找到,进入左子树找if(FindPath(root->left,x,path))return true;//如果左子树没找到,进入右子树找if(FindPath(root->right,x,path))return true;//左右字树都没找到,pop掉当前栈顶元素,返回falsepath.pop();return false;}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {//栈的每个元素都是TreeNode*类型stack<TreeNode*> pPath,qPath;//FindPath中传入的pPath和qPath都是p和q从根结点的路径FindPath(root, p, pPath);FindPath(root, q, qPath);//p/q结点的路径长度不同,先变为相同路径长度while(pPath.size() != qPath.size()){if(pPath.size() > qPath.size())pPath.pop();elseqPath.pop();}//相同路径长度一层层判断顶部元素是否相同while(pPath.top() != qPath.top()){pPath.pop();qPath.pop(); }//走到这里说明找到了相同的结点,即最近祖先return pPath.top();} };


4、搜索二叉树与双向链表
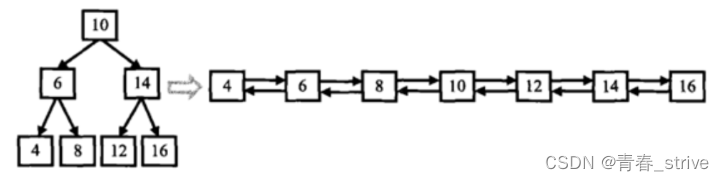
题目要求:输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。如下图所示:
1.要求不能创建任何新的结点,只能调整树中结点指针的指向。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继
2.返回链表中的第一个节点的指针
3.函数返回的TreeNode,有左右指针,其实可以看成一个双向链表的数据结构
思路分析:
由于不能创建新的结点,只能调整树中结点指针的指向,所以我们就不能用先中序排好序以后,再遍历的方法
那么就在中序遍历的过程中,给两个指针,一个prev,一个cur,prev是指向前一个结点,cur是值向当前的结点,每次cur变化前,都将值赋值给prev,然后再将cur->left指向prev,以此类推完成了left指针,当前的prev就是上一个cur,所以prev->right = cur就是相当于上一个cur->right也指向了下一个结点,从而完成了right指针
代码:
class Solution { public://中序遍历,并在过程中调整结点指针的指向//cur是当前结点的指针,prev是前一个结点的指针void Inorder(TreeNode* cur,TreeNode*& prev){if(cur == nullptr)return;//先左子树Inorder(cur->left,prev);//cur->left直接给prev,因为prev是前一个结点指针cur->left = prev;//若prev不为空,且为TreeNode*& prev,是传引用,即://prev->right就完成了上一个cur结点的right指针指向if(prev)prev->right = cur;//在cur指向下一个之前,赋值给prevprev = cur;//再右子树Inorder(cur->right,prev);}TreeNode* Convert(TreeNode* pRootOfTree) {//创建一个prev置空,传入Inorder进行中序排序TreeNode* prev = nullptr;Inorder(pRootOfTree, prev);//head先指定为题目所给的根结点TreeNode* head = pRootOfTree;//顺着left指针找到中序遍历的第一个结点//为了防止pRootOfTree为空,要先判断headwhile(head && head->left)head = head->left;//返回第一个结点指针return head;} };
5、从前序与中序遍历序列构造二叉树
题目要求:给定两个整数数组
preorder和inorder,其中preorder是二叉树的先序遍历,inorder是同一棵树的中序遍历,请构造二叉树并返回其根节点。
思路:
通过前序遍历确定根,通过中序遍历确定左右字树
子树区间确认是否继续递归创建子树,不存在区间则是空树
代码:
class Solution { public://创建_buildTree函数进行递归调用//prei是前序遍历结果的首元素下标,inbegin、inend是中序遍历结果首尾元素的下标TreeNode* _buildTree(vector<int>& preorder, vector<int>& inorder, int& prei, int inbegin, int inend){//如果在前序遍历的结果中找,if(inbegin > inend)return nullptr;//每次递归通过前序遍历结果创建根结点TreeNode* root = new TreeNode(preorder[prei++]);//while循环找到中序遍历的该结点的位置int cur = inbegin;while(cur <= inend){if(inorder[cur] == root->val)break;elsecur++;}//中序遍历的结果中,分成了三个部分,[左子树]根[右子树]//[inbegin, cur-1] cur [cur+1,inend]//所以接下来递归时,传入这两个区间root->left = _buildTree(preorder,inorder,prei,inbegin,cur-1);root->right = _buildTree(preorder,inorder,prei,cur+1,inend);return root;}TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {//前序遍历首元素下标为0int prei = 0;//中序遍历结果首尾元素的下标为0和inorder.size()-1TreeNode* root = _buildTree(preorder,inorder,prei,0,inorder.size()-1);return root;} };
6、 从中序与后序遍历序列构造二叉树
题目要求:给定两个整数数组
inorder和postorder,其中inorder是二叉树的中序遍历,postorder是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
这个题和上面的从前序与中序遍历序列构造二叉树大体思路一样,但是由于是后序确定根结点,所以给定后序遍历结果的下标posi,每次都会posi--,并且是先递归右子树,再递归左子树,因为后序遍历顺序是左子树,右子树,根结点,反过来就是根结点,右子树,左子树
所以代码如下:
class Solution { public:TreeNode* _buildTree(vector<int>& inorder, vector<int>& postorder,int& posi,int inbegin,int inend){if(inbegin > inend)return nullptr;TreeNode* root = new TreeNode(postorder[posi--]);int cur = inbegin;while(cur <= inend){if(root->val == inorder[cur])break;elsecur++;}//[inbegin,cur-1] cur [cur+1,inend]root->right = _buildTree(inorder,postorder,posi,cur+1,inend);root->left = _buildTree(inorder,postorder,posi,inbegin,cur-1);return root;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {int posi = postorder.size()-1;return _buildTree(inorder,postorder,posi,0,inorder.size()-1);} };
7、二叉树的前序遍历(非递归实现)
题目要求:给你二叉树的根节点
root,返回它节点值的 前序 遍历。
思路分析:
采用非递归实现该问题,能提高效率,并且递归调用需要建立栈帧,如果深度比较深会容易崩溃,所以需要掌握非递归的方法
前序遍历中,我们可以将所有结点分为左路结点,以及左路结点的右子树
那么我们第一步就是将左路结点都保存下来,并且存在栈中,接着将存入栈的结点一个一个出栈,并访问右子树,然后重复上面的步骤(左路结点保存,入栈,全部入栈后,然后出栈,访问该出栈结点的右子树)
当左路结点从栈中出来时,表示左子树以及访问过了,该访问该结点和它的右子树了
就相当于转换为了子问题,将所有结点分为左路结点,以及左路结点的右子树,接着将左路结点的右子树又分为:左路结点,以及左路结点的右子树以此类推,从而实现非递归的方法完成前序遍历
代码如下:
class Solution { public:vector<int> preorderTraversal(TreeNode* root) {vector<int> v;stack<TreeNode*> st;TreeNode* cur = root;//循环条件有两个都不符合才结束循环//一是栈里空,表明初始的左路结点的右子树都已访问//二是cur为空,表明访问的栈中的结点的右子树为空while(cur || !st.empty()){//1、左路结点while(cur){v.push_back(cur->val);st.push(cur);cur = cur->left;}//2、左树结点的右子树TreeNode* top = st.top();st.pop();//将左路结点以外的数转化为上面两条的子问题//转换为子问题从而访问栈中结点的右子树cur = top->right;}return v;} };
8、二叉树的中序遍历(非递归实现)
题目要求:给定一个二叉树的根节点
root,返回 它的 中序 遍历 。
中序遍历和前序遍历思路大体相同,但是由于中序遍历是:左子树,根,右子树。所以中序遍历的结果需要在左路结点都入栈后,再依次push_back进数组中,剩下思路和前序遍历相同
代码如下:
class Solution { public:vector<int> inorderTraversal(TreeNode* root) {vector<int> v;stack<TreeNode*> st;TreeNode* cur = root;while(cur || !st.empty()){while(cur){st.push(cur);cur = cur->left;}//左路结点都入栈后,再尾插栈顶元素到数组中//依次取栈顶元素,再pop,转换为子问题循环TreeNode* top = st.top(); st.pop();v.push_back(top->val);cur = top->right;}return v;} };
9、二叉树的后序遍历(非递归实现)
题目要求:给你一棵二叉树的根节点
root,返回其节点值的 后序遍历 。
思路分析:
后序遍历和前序/中序有一点区别,因为后序是左子树,右子树,根,我们先找到左路结点后,无法确认该结点的右子树有没有访问,所以就这一问题可以分类讨论
设定一个prev结点,让他指向cur结点的前一个结点,即每次尾插入数组时都记录当前的结点值,赋值给prev,这样在cur = cur->right以后,prev就是cur所访问的前一个结点。
将所有左路结点全部插入到栈以后,分为两种情况:
第一:该结点的右子树为空或该结点的右子树已经访问过了,第二:该结点的右子树没有被访问过
第一种情况就可以访问这个栈顶结点,否则先访问该结点的右子树,转换为了子问题
代码:
class Solution { public:vector<int> postorderTraversal(TreeNode* root) {vector<int> v;stack<TreeNode*> st;TreeNode* cur = root;TreeNode* prev = nullptr;while(cur || !st.empty()){//左路结点入栈while(cur){st.push(cur);cur = cur->left;}TreeNode* top = st.top();//右子树为空或上一个访问的就是该结点的右子树的根//说明右子树已经访问过了if(top->right == nullptr || top->right == prev){v.push_back(top->val);prev = top;cur = nullptr;st.pop();}//否则先访问栈顶结点的右子树else{cur = top->right;}}return v;} };
相关题目列举这些
相关文章:
二叉树的相关题目
目录 1、根据二叉树创建字符串 2、二叉树的层序遍历 3、二叉树的最近公共祖先 4、搜索二叉树与双向链表 5、从前序与中序遍历序列构造二叉树 6、 从中序与后序遍历序列构造二叉树 7、二叉树的前序遍历(非递归实现) 8、二叉树的中序遍历(…...
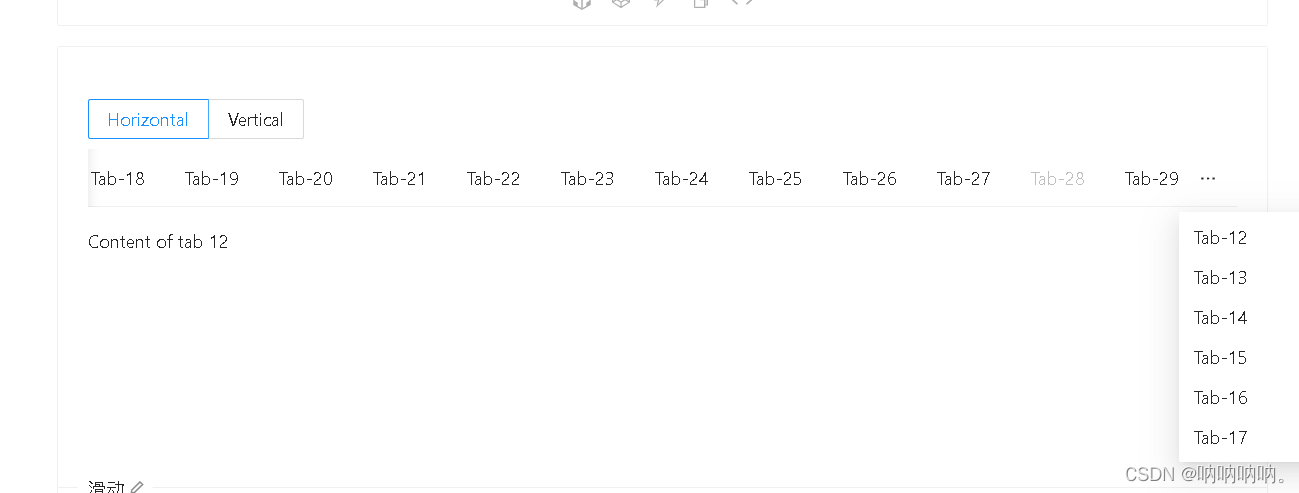
【antd之tabs踩坑篇】Tabs有items时切换不起作用
<TabsdefaultActiveKey"1"tabPosition{mode}style{{ height: 220 }}items{new Array(30).fill(null).map((_, i) > {const id String(i);return {label: Tab-${id},key: id,disabled: i 28,children: Content of tab ${id},};})}/>官网上如果tabs有很多it…...

简单模拟livedata数据倒灌
简单模拟livedata数据倒灌 数据倒灌,就是将旧的或只展示一次的数据再次展现出来。 livedata内部通过版本号更新可见视图数据,而在view在活跃与不活跃之间反复横跳时,livedata也会通知数据。 class MainActivity : AppCompatActivity() {pri…...
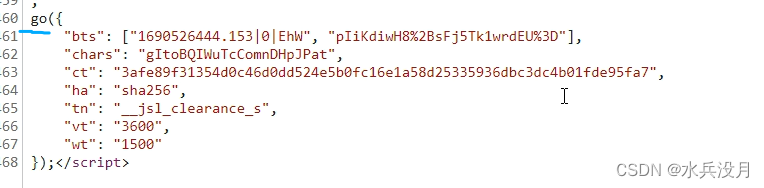
python爬虫-加速乐cookie混淆解析实例小记
注意!!!!某XX网站逆向实例仅作为学习案例,禁止其他个人以及团体做谋利用途!!! 第一步:抓包工具第一次请求页面,得到响应。本次我使用的fiddle进行抓包&#…...

TensorFlow 中前缀 prefix
前缀 prefix 主要用于命名 TensorFlow 中的变量,以避免变量名冲突。在 TensorFlow 中,每个变量都有一个唯一的名称,由变量的作用域和变量的名称组成。作用域可以通过 tf.variable_scope() 函数来创建,而变量的名称通常是由用户指定…...
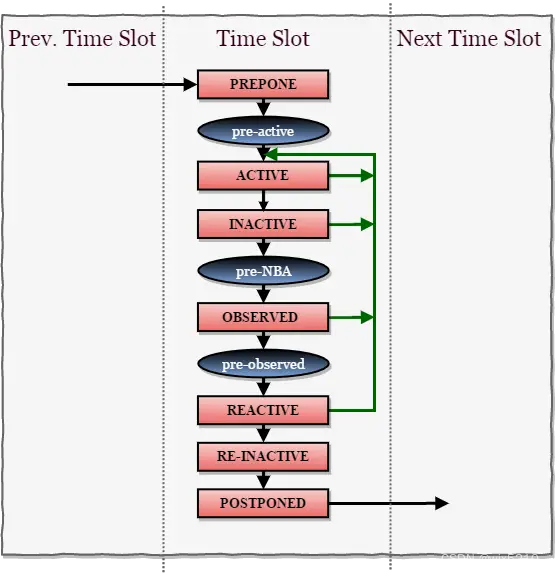
SystemVerilog scheduler
文章目录 简介调度器simulation regionPreponed regionActive regionInactive regionNBA(Non-blocking Assignment Events region)Observed regionReactive regionRe-Inactive Events regionRe-NBA RegionPostponed Region PLI region:Pre-active regionPre-NBA regionPost-NBA…...
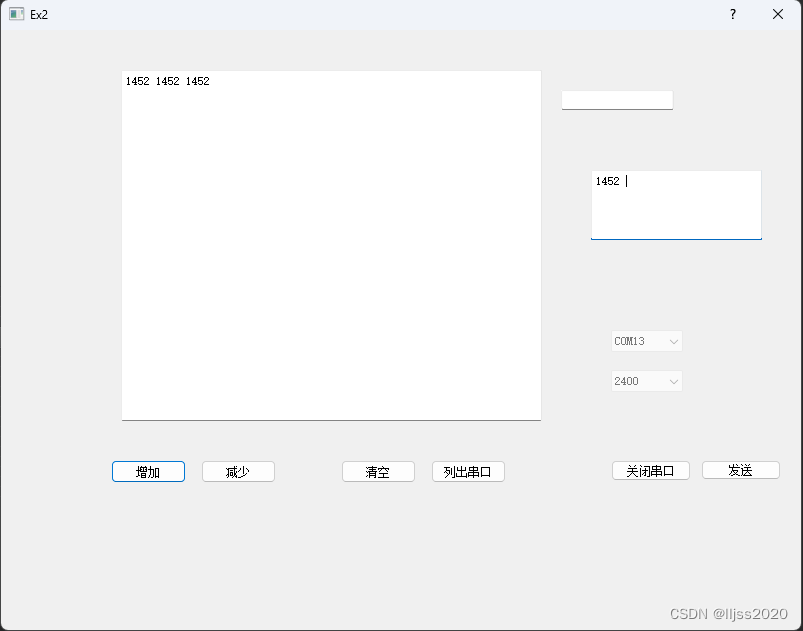
Qt 5. QSerialPort串口收发
1. 代码 //ex2.cpp #include "ex2.h" #include "ui_ex2.h" #include <QtSerialPort/QSerialPort> #include <QtSerialPort/QSerialPortInfo>int static cnt 0;Ex2::Ex2(QWidget *parent): QDialog(parent), ui(new Ui::Ex2) {ui->setupUi…...
?)
什么是Java中的JVMTI(JVM Tool Interface)?
Java中的JNI(Java Native Interface)和JVMTI(JVM Tool Interface)都是与Java运行时环境(JVM)交互的工具,但它们有不同的目的和使用场景。下面我从新手的角度来幽默地解释一下它们的区别和用途。…...

WAF独木难支 RASP与ADR将成应用安全防护2.0时代新宠
曾几何时,黑客攻击大多通过网络层进行,但随着基于网络层的基础安全防护措施趋于严密,防火墙、入侵防御、防病毒等安全软硬件构建起了相对完善的防护体系,想再从网络层钻空子的难度增大。如今,黑客攻击从网络层转入Web为…...
四、Unity中颜色空间
Unity中的设置 通过点击菜单Edit->Project Settings->Player页签->Other Settings下的Rendering部分进行修改,参数Color Space可以选择Gamma或Linear。 当选择Gamma Space时,Unity不会做任何处理。当选择Linear Space时,引擎的渲染…...

Java程序员面试题
Java程序员面试题目 1.Java基础1.1 Java有list,list有很多种,你平时开发喜欢用哪个list?(容易)1.2 Java的map,你知道有哪几种map,你平时喜欢用哪个?(容易) 2.…...
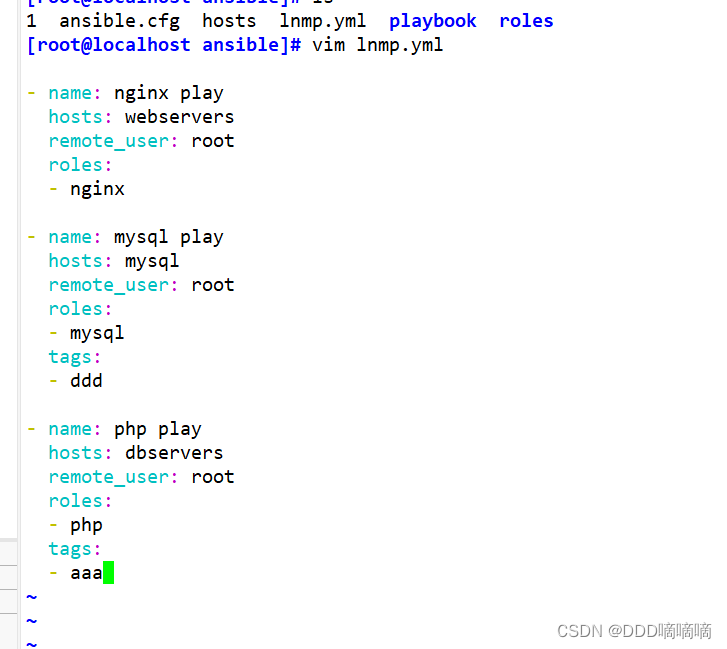
【自动化剧本】Role角色
目录 一、Roles模块1.1roles的目录结构1.2roles 内各目录含义解释1.3在一个 playbook 中使用 roles 的步骤 二、使用Role编写LNMP剧本2.1 搭建Nginx角色2.2搭建Mysql角色2.3搭建php角色2.4lnmp剧本 一、Roles模块 roles用于层次性、结构化地组织playbook。roles能够根据层次型结…...

安全文件传输:如何避免数据泄露和黑客攻击
网络安全问题日益严重,导致许多数据被泄露和黑客袭击的事件频发。为了保证文件传输的安全,需要实施一系列安全文件传输策略来防止数据被泄露和黑客袭击。 第一、选择适合的加密方法是非常关键的 加密是一种将明文转换成密文的过程,这样只有授…...

web基础与http
一,dns与域名 网络基于tcp/ip协议进行通信和连接的,其中主机以ip地址做固定的地址标识,用以区分用户和计算机。ip地址是由32位二进制数组成,不方便记忆。为了方便记忆,采用了域名。但是网络通信的唯一标识是ip地址&…...

寒假作业(蓝桥杯2016年省赛C++A组第6题 )
题目: 注:蓝桥杯2016年省赛CA组第6题 请填写表示方案数目的整数。 题解: 由题可知这是一道全排列问题,因此我们可以使用c的next_permutation函数对于1-13的数字进行全排列即可,并每次排列判断是否满足题意。 注意…...

NUMA架构在kubernetes中的应用
numactl使用 numactl 通过将 CPU 划分多个 node 减少 CPU 对总线资源的竞争,一般使用在高配置服务器部署多个 CPU 消耗性服务使用。 numactl使用,numa常用命令,numa命令行使用 #numactl -H available: 2 nodes (0-1) node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 node 0…...
Gogs Git windos服务搭建指南
Gogs Git服务器搭建指南 背景: 近期在Linux 麒麟 v10 系统上开发;为了团队协同编程;选用了Git服务器;之前在windos开始时候使用的visualSVN server; visualSVN server从4.x.x.x开始收费;限制15个开发者用户ÿ…...

leetcode 983. 最低票价
在一个火车旅行很受欢迎的国度,你提前一年计划了一些火车旅行。在接下来的一年里,你要旅行的日子将以一个名为 days 的数组给出。每一项是一个从 1 到 365 的整数。 火车票有 三种不同的销售方式 : 一张 为期一天 的通行证售价为 costs[0] …...

七种遍历Map的方法
七种遍历Map的方法 import java.util.HashMap; import java.util.Iterator; import java.util.Map;public class Wan {public static void main(String[] args) {Map<String,String> dataMap new HashMap<>();dataMap.put("A","Abb");dataMap…...
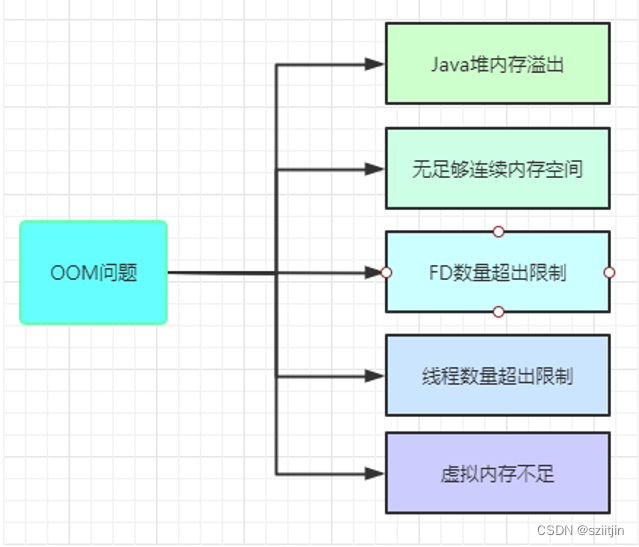
Android性能优化—内存优化
一、App内存组成以及管理 Android 给每个 App 分配一个 VM ,让App运行在 dalvik 上,这样即使 App 崩溃也不会影响到系统。系统给 VM 分配了一定的内存大小, App 可以申请使用的内存大小不能超过此硬性逻辑限制,就算物理内存富余&…...

解决无法访问 GitLab 的难题:我的本地部署与公网接入实战
前言 为什么我选择自建 GitLab 本地版 第一次尝试搭建 GitLab 的时候,我面临的第一个问题就是:为什么我明明已经部署好了,却没法从外部访问? 这个问题的答案其实很简单——我的 GitLab 部署在本地服务器上,默认只允…...

别再到处找了!Win7/Win10/Win Server各版本.NET 4.7.2离线安装包官方与备用下载全指南
彻底解决.NET 4.7.2安装难题:Windows全版本离线包获取与部署实战手册 还在为不同Windows系统寻找匹配的.NET 4.7.2离线安装包而头疼?这份指南将为你节省数小时的搜索时间。无论你使用的是老旧的Windows 7 SP1还是最新的服务器系统,我们都准备…...
)
别再死磕3D建图了!用Cartographer的2D模式搞定北科天汇32线雷达建导航图(附完整lua配置)
3D激光雷达的降维艺术:用Cartographer 2D模式高效构建导航地图 当32线激光雷达遇上Cartographer,大多数开发者第一反应是启用3D建图模式——毕竟硬件支持三维点云采集,软件也提供3D建图功能,这似乎是天经地义的选择。但实际项目中…...

避坑指南:RenderDoc Python扩展插件从开发到加载的完整流程
RenderDoc Python插件开发实战:从零避坑到高级扩展 第一次尝试为RenderDoc开发Python插件时,那种既兴奋又忐忑的心情我至今记忆犹新。看着官方文档里简短的说明,本以为半小时就能搞定的事情,结果花了整整两天时间才让第一个菜单项…...

从原理到实践:掌握IOR折射率,为你的3D渲染材质注入真实灵魂
1. IOR折射率:3D渲染中的"材质指纹" 当你用手指轻触玻璃杯时,那种冰凉光滑的触感从何而来?在3D渲染的世界里,这种真实感的核心密码就是IOR(Index of Refraction)折射率。这个看似专业的物理参数&…...

【实战解析】C# NPOI实现Excel图片插入与智能列宽调整的进阶技巧
1. 电商后台数据导出的痛点与NPOI解决方案 做过电商后台开发的朋友应该都遇到过这样的需求:需要将商品列表导出为Excel报表,并且要在报表中插入商品图片。这个需求看似简单,实际操作中却会遇到不少坑。比如图片插入后单元格大小不合适导致图片…...

C语言编程实战:从入门到精通的50道经典大题解析
1. C语言编程实战入门指南 刚接触C语言时,很多初学者会被指针、内存管理等概念吓到。其实C语言就像搭积木,掌握基础语法后就能构建复杂程序。我们先从最简单的"Hello World"开始: #include <stdio.h> int main() {printf(&qu…...

Pycharm 与 Jupyter 的深度集成:从环境搭建到高效数据分析实战
1. 为什么选择PyCharm作为Jupyter的集成开发环境? 第一次接触Jupyter Notebook是在研究生时期,当时被它的交互式编程体验惊艳到。但随着项目复杂度提升,单纯用浏览器操作Jupyter越来越力不从心——代码补全弱、调试困难、版本控制麻烦。直到发…...

Open WebUI 企业级AI平台实战指南:从零部署到生产环境优化
Open WebUI 企业级AI平台实战指南:从零部署到生产环境优化 【免费下载链接】open-webui User-friendly AI Interface (Supports Ollama, OpenAI API, ...) 项目地址: https://gitcode.com/GitHub_Trending/op/open-webui Open WebUI是一个功能丰富、可完全离…...

3分钟搞定Adobe插件安装:ZXPInstaller跨平台终极指南
3分钟搞定Adobe插件安装:ZXPInstaller跨平台终极指南 【免费下载链接】ZXPInstaller Open Source ZXP Installer for Adobe Extensions 项目地址: https://gitcode.com/gh_mirrors/zx/ZXPInstaller 还在为Adobe插件的复杂安装流程而烦恼吗?Adobe …...