大数据课程F4——HIve的其他操作
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 掌握HIve的join;
⚪ 掌握HIve的查询和排序
⚪ 掌握HIve的beeline
⚪ 掌握HIve的文件格式
⚪ 掌握HIve的基本架构
⚪ 掌握HIve的优化;
一、join
1. 概述
1. 在Hive中,同MySQL一样,提供了多表的连接查询,并且支持left join,right join,inner join,full outer join以及笛卡尔积查询。
2. 在连接查询的时候,如果不指定,那么默认使用的是inner join。
3. 在Hive中,除了支持上述比较常用的join以外,还支持left semi join。当a left semi join b的时候,表示获取a表中的数据哪些在b表中出现过。
2. 案例:
#建表语句
create external table orders (orderid int, orderdate string, productid int, num int) row format delimited fields terminated by ' 'location '/orders';
create external table products (productid int, name string, price double) row format delimited fields terminated by ' ' location '/products';
#左连接 - 以左表为准
select * from orders o left join products p on o.productid = p.productid;
#右连接 - 以右表为准
select * from orders o right join products p on o.productid = p.productid;
#内连接 - 获取两个表都有的数据
select * from orders o inner join products p on o.productid = p.productid;
#全外连接
select * from orders o full outer join products p on o.productid = p.productid;
#笛卡尔积
select * from orders, products;
#需求一:获取每一天卖了多少钱
select o.orderdate, sum(o.num * p.price) from orders o inner join products p on o.productid = p.productid group by o.orderdate;
#需求二:查询哪些商品被卖出去过 - 实际上就是获取商品表中的哪些数据在订单表中出现过
select * from products p left semi join orders o on p.productid = o.productid;
二、查询和排序
1. having
1. 在Hive中,where可以针对字段来进行条件查询,但是where无法针对聚合结果进行条件查询;如果需要对聚合结果进行条件查询,那么此时需要使用having。
2. 案例:
#原始数据
1 Apollo 4900
1 Billy 5100
1 Cary 4800
1 Dylan 5000
1 Ford 4700
2 Apollo 5300
2 Billy 4600
2 Cary 4700
2 Dylan 5100
2 Ford 4500
3 Apollo 5200
3 Billy 4300
3 Cary 4600
3 Dylan 5200
3 Ford 4800
#建表语句
create table salaries (month int, name string, salary double) row format delimited fields terminated by ' ';
#加载数据
load data local inpath '/home/hivedemo/salaries.txt' into table salaries;
#获取平均工资超过5000的员工
select name, avg(salary) as avgsalary from salaries group by name having avgsalary > 5000;
#或者使用子查询
select * from (select name, avg(salary) as avgsalary from salaries group by name)tmp where avgsalary > 5000;
2. 排序
1. 在Hive中,提供了2种排序方式:
a. order by:在排序的时候忽略掉ReduceTask的个数,会将所有的数据进行统一的排序。
b. sort by:在排序的时候会按照ReduceTask的个数产生对应数量的结果文件。在每一个结果文件内部进行排序。在sort by的时候如果不指定,那么会根据排序数据的哈希码来分配到多个不同的文件中。
2. sort by经常结合distribute by来使用,其中利用distribute by对数据进行分类,然后再在每一个分类中对数据进行排序。
3. 如果distribute by和sort by的字段一致,那么可以写成cluster by。
4. 案例:
#原始数据
1 Max 69
1 Eric 70
1 Hank 95
1 Larry 82
2 Justin 74
2 Tim 79
2 Ken 81
2 Ivan 87
3 Nick 95
3 Leo 72
3 Mars 84
3 Reed 91
#建表语句
create table students(class int, name string, score int) row format delimited fields terminated by ' ';
#加载数据
load data local inpath '/home/hivedemo/students.txt' into table students;
#Hive底层会将SQL转化为MapReduce,如果不指定,则只有1个ReduceTask
#1个ReduceTask-> order by
insert overwrite local directory '/home/orderby1' row format delimited fields terminated by ' ' select * from students order by score desc;
#1个ReduceTask -> sort by
insert overwrite local directory '/home/sortby' row format delimited fields terminated by ' ' select * from students sort by score desc;
#在只有一个ReduceTask的前提下,order by和sort by的排序结果一致
#设置ReduceTask的数量
set mapred.reduce.tasks = 3;
#多个ReduceTask -> order by
insert overwrite local directory '/home/orderby2' row format delimited fields terminated by ' ' select * from students order by score desc;
#多个ReduceTask -> sort by
insert overwrite local directory '/home/sortby2' row format delimited fields terminated by ' ' select * from students sort by score desc;
#按班级来分别对学生的成绩排序
insert overwrite local directory '/home/distributeby' row format delimited fields terminated by ' ' select * from students distribute by class sort by score desc;
#如果distribute by和sort by的字段一致,那么可以替换为cluster by
insert overwrite local directory '/home/distributeby2' row format delimited fields terminated by ' ' select * from students distribute by score sort by score;
#等价于
insert overwrite local directory '/home/clusterby' row format delimited fields terminated by ' ' select * from students cluster by score;
三、beeline
1. 概述
1. beeline是Hive提供的一个远程连接工具,允许用户去远程连接指定节点上的Hive服务。
2. beeline底层实际上是利用了JDBC的方式来发起了连接。
3. 需要注意的是,beeline在连接过程中可能会收到Hadoop权限验证的阻拦,所以在启动beeline之前,还需要去更改Hadoop的一部分配置。
2. 步骤
1. 关闭Hadoop。
stop-dfs.sh
stop-yarn.sh
2. 关闭所有的Hive进程 -> RunJar进程。
3. 编辑Hadoop的配置文件。
vim /home/software/hadoop-3.1.3/etc/hadoop/core-site.xml
#添加如下配置
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
4. 重新启动Hadoop。
start-all.sh
5. 启动Hive进程。
hive --service metastore &
hive --service hiveserver2 &
6. 启动beeline。
beeline -u jdbc:hive2://hadoop01:10000/demo -n root
四、文件格式
1. 概述
1. Hive中的数据最终会以文件的形式落地到HDFS上,因此Hive落地的文件存在不同的存储格式,其中最主要的存储格式有4种:textfile,sequencefile,orc和parquet。
2. textfile和sequencefile底层采用的是行存储方式,orc和parquet采用的是列存储方式。
3. 在Hive中,如果不指定,则默认采用的是textfile格式。
2. orc
1. orc格式是Hive0.11开始引入的一种存储格式,采取的列存储方式。
2. 在每一个orc格式文件中,包含1个多个Stripe,1个File Footer以及1个Postscript:
a. Stripe用于orc文件的数据存储数据。
Ⅰ. 默认情况下,Stripe和Block一样的。
Ⅱ. 每一个Stripe中包含3部分:Index Data,Row Data,Stripe Footer:
1. Index Data:用于记录索引,默认情况下,在Stripe中每一万条数据建立一个索引,索引记录这一行数据在各个列中的offset(偏移量)。
2. Row Data:存储数据。在添加数据的时候,往往是按行添加的。在获取到一行数据之后,会将这行数据的每一个字段拆分出来,拆分之后按照列的形式来进行存储。在存储的时候,可以给不同的列执行不同的编码形式,编码之后会将这一列封装成一个或者多个Stream来进行存储。因为同一个列的字段类型是一样的,所以可以针对每一个列采取更好的压缩机制。
3. Stripe Footer:存储每一个Stream的类型、长度等信息。
b. File Footer:用于记录每一个Stripe中存储的数据的行数等信息。
c. Postscript:记录文件是否进行了压缩以及压缩编码等信息,还记录了File Footer在文件中的起始位置。
3. 在读取orc文件的时候,首先通过Postscript来获取File Footer的位置,再通过File Footer来获取Stream的位置,最后来读取Stream中的数据。
五、基本架构
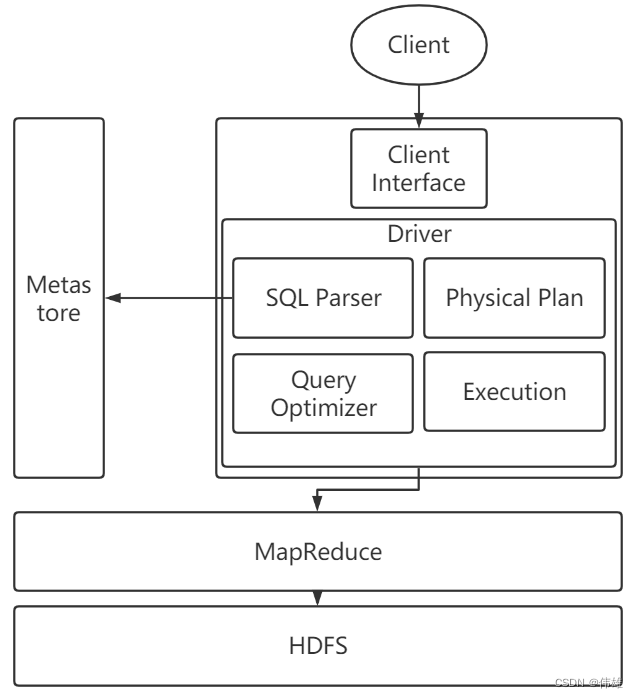
1. Client Interface:提供给用户用于操作Hive的接口,主要有3种:CLI(command-line interface,命令行接口),JDBC/ODBC(用Java代码操作Hive),WEBUI(WEB界面,通过浏览器页面来访问)。
2. Metastore:用于存储Hive的元数据的。如果不指定,Hive的元数据是维系在Derby。当操作Hive的时候,都会先访问Metastore来进行元数据的校验。
3. Driver:驱动器,包含了四个部分:
a. SQL Parser:SQL解析器,解析SQL语句,生成对应的抽象语法树AST。
b. Physical Plan:编译器,会将抽象语法树编译成要执行的逻辑计划。
c. Query Optimizer:优化器,会对逻辑计划进行优化。
d. Execution:将逻辑计划转化为物理计划,例如转化为MapReduce程序。
4. MapReduce:Execution产生程序之后,现阶段会交给MapReduce来执行。
5. HDFS:存储Hive中的数据。
六、优化
1. Fetch值修改
a. 在Hive中,可以通过hive.fetch.task.conversion属性来修改fetch的状态。在Hive3.X中,这个属性的默认值是more,在之前的版本中,这个属性的默认值是minimal。
b. 如果将这个属性的值改为none,那么Hive进行的所有的操作都会转为MapReduce程序,那么会导致部分操作的效率降低,例如select * from person;这个SQL是查询整表,实际上就是将文件从头到尾顺次读取,此时这个操作可以不适用MapReduce。
2. map side join
a. 开启之后,在大表和小表进行join的时候,会自动的将小表中的数据放到内存中,然后在处理大表数据的过程中,如果用到了小表中的数据,那么会自动的从内存中来读取小表的数据而不是再从磁盘上来读取,利用这种方式能够相对有效的提高执行效率。
b. 小表的大小可以通过属性hive.mapjion.smalltable.filesize来调节,默认值是25MB。
c. 可以通过hive.auto.convert.join属性来开启map side join,默认值是true。
d. 在Hive3.X之前,要求必须是小表join大表才会触发这个map side join;但是注意,从Hive3.X开始,不再要求小表的位置。
3. 启用严格模式
a. 将hive.strict.checks.no.partition.filter设置为true之后,要求在查询分区表的时候必须携带分区字段。
b. 将hive.strict.checks.orderby.no.limit设置为true之后,要求在对数据排序的时候必须添加limit字段。
c. 将hive.strict.checks.cartesian.product设置true之后,要求查询结果中不准出现笛卡尔积。
4. JVM重用
a. Hive会将SQL在底层转化为MapReduce来执行,MapReduce在执行的时候会拆分为MapTask和ReduceTask。NodeManager在执行任务的时候,会在本节点上来开启一个JVM子进程执行MapTask或者ReduceTask。默认情况下,每一个JVM子进程只执行一个子任务就会结束,所以如果存在多个子任务就需要开启和关闭多次JVM子进程。
b. 通过属性mapred.job.reuse.jvm.num.tasks来调节,默认为1。
相关文章:
大数据课程F4——HIve的其他操作
文章作者邮箱:yugongshiyesina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握HIve的join; ⚪ 掌握HIve的查询和排序 ⚪ 掌握HIve的beeline ⚪ 掌握HIve的文件格式 ⚪ 掌握HIve的基本架构 ⚪ 掌握HIve的优化; 一、jo…...

React Native详解和代码实例
目录 一、React Native 的主要特点二、React Native 的工作原理三、React Native 的优缺点四、React Native 代码示例 React Native 是一个用于构建原生移动应用程序的 JavaScript 框架。它使用 React 库,允许开发者使用 JavaScript 编写应用程序的 UI 和逻辑&#…...

CAD随机球体颗粒过渡区3D插件
插件介绍 CAD随机球体颗粒&过渡区3D插件可用于在AutoCAD软件内生成随机分布的球体及球体外侧过渡区部件,适用于科研绘图、有限元建模如混凝土细观、颗粒增强复合材料、随机三维骨料及过渡区等方面的应用。 插件可指定的参数有模型的长、宽、高;球…...

【项目 进程12】2.25 sigprocmask函数使用 2.26sigaction信号捕捉函数 2.27SIGCHILD信号
文章目录 2.25 sigprocmask函数使用2.26 sigaction信号捕捉函数内核实现信号捕捉的过程信号捕捉特性 2.27SIGCHILD信号 2.25 sigprocmask函数使用 阻塞信号集有时称作信号掩码。 联想:fcntl函数可以修改fd属性。 ./sigprocmask & //将程序设置为后台运行&…...

【无标题】面试题 02.07. 链表相交
面试题 02.07. 链表相交 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。 方法一:遍历headA,将每个节点add到HashSet中;然后遍历headB…...

Zotero ubuntu2023安装 关联 ubuntu文献翻译
一、准备下载的软件: Zotero | Downloads 1. Zotero-6.0.26_linux-x86_64.tar.bz2 下面是插件 zotfile-5.1.2-fx.xpi zotero-pdf-translate.xpi jasminum-v0.2.6.xpi 2.2.5 Tampermonkey 4.11.crx 所准备的文件,都已经在这个链接的压缩包下面 …...
Stable Diffusion教程(7) - PS安装AI绘画插件教程
配套教程视频:https://v.douyin.com/Uyux9F6/ 1. 前置条件 安装了stable diffusion 还没安装的从知识库安装 阿超的AI绘画知识库 语雀 安装了ps2023 还没安装的从网盘下载Win版 PS 2023【必须win10、11】.rar官方版下载丨最新版下载丨绿色版下载丨APP下载-12…...

如何学技术
#如何学习技术 今天在学习redis时,看到了一位大佬写的如何学习技术的方法论,个人觉得很不错,这里分享给大家。 --- - 领先一步:保持好奇心 不给自己设限 真正走出舒适区之后,我看到了自己的飞速成长和进步&#…...
【云存储】使用OSS快速搭建个人网盘教程(阿里云)
使用OSS快速搭建个人网盘 一、基础概要1. 主要的存储类型1.1 块存储1.2 文件存储1.3 对象存储 2. 对象存储OSS2.1 存储空间2.2 地域2.3 对象2.4 读写权限2.5 访问域名(Endpoint)2.6 访问密钥2.7 常用功能(1)创建存储空间ÿ…...

微信小程序iconfont真机渲染失败
解决方法: 1.将下载的.woff文件在transfonter转为base64, 2.打开网站,导入文件,开启base64按钮,下载转换后的文件 3. 在下载解压后的文件夹中找到stylesheet.css,并复制其中的base64 4. 修改index.wxss文…...

万界星空/推出生产制造执行MES系统/开源MES/免费下载
免费MES系统介绍 什么是MES系统呢?MES系统主要功能就是解决“如何生产”的问题。通过实施MES系统,一站式解决您所困扰的所有生产制作流程问题。 普通的免费MES系统只提供简单的基本功能让客户体验,而万界星空MES系统运用低代码的形式开发&a…...

【VxWorks】Vxworks、QNX、Xenomai、Intime、Sylixos、Ucos等实时操作系统的性能特点
目录 1.VxWorks操作系统 2.QNX操作系统 3.Xenomai操作系统 4.INtime操作系统 5.SylixOS操作系统 5.1.SylixOS官网...
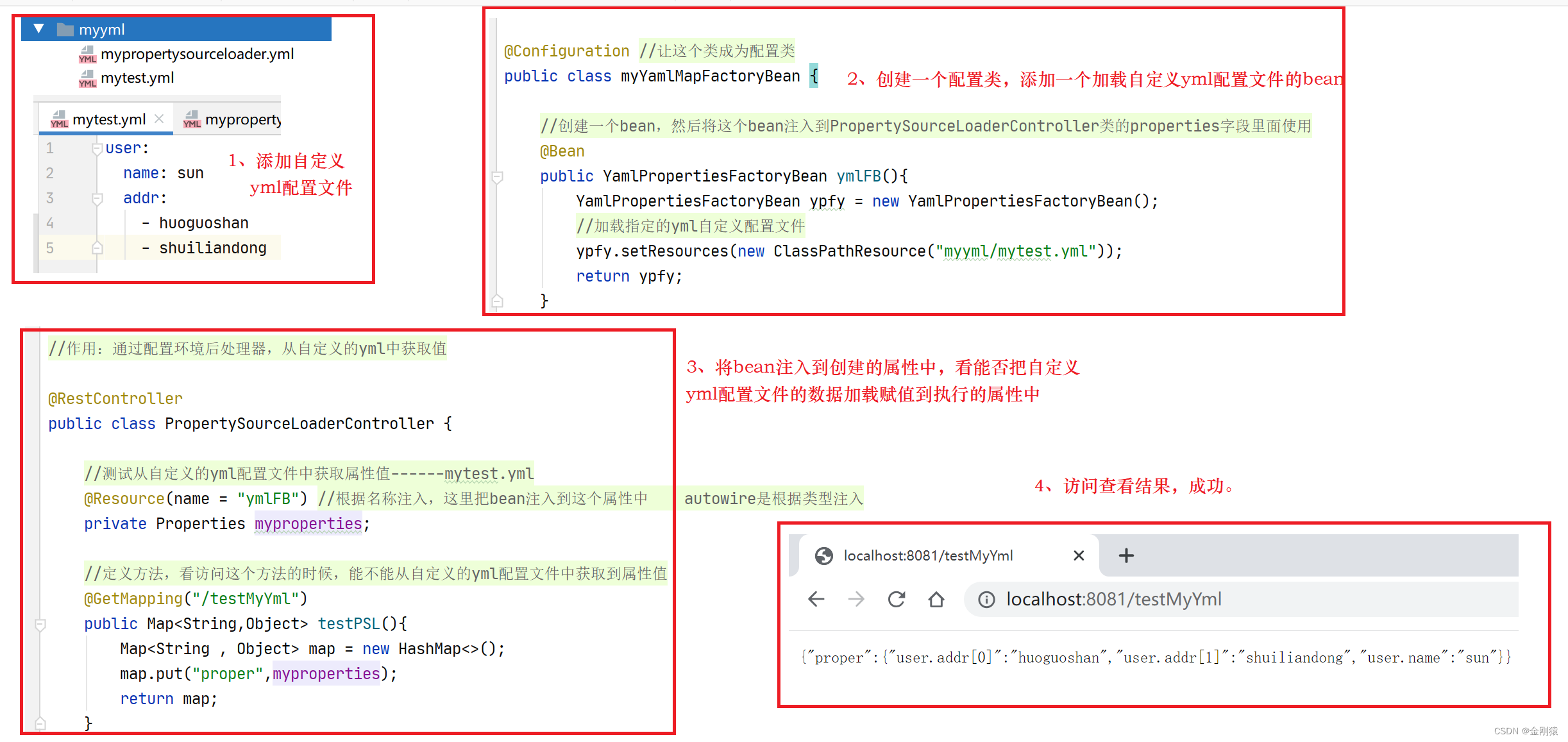
17、YML配置文件及让springboot启动时加载我们自定义的yml配置文件的几种方式
YML配置文件及加载自定义配置文件的几种方式 ★ YAML配置文件 其实本质和.properties文件的是一样的。 Spring Boot默认使用SnakeYml工具来处理YAML配置文件,SnakeYml工具默认就会被spring-boot-starter导入,因此无需开发者做任何额外配置。 YAML本质…...
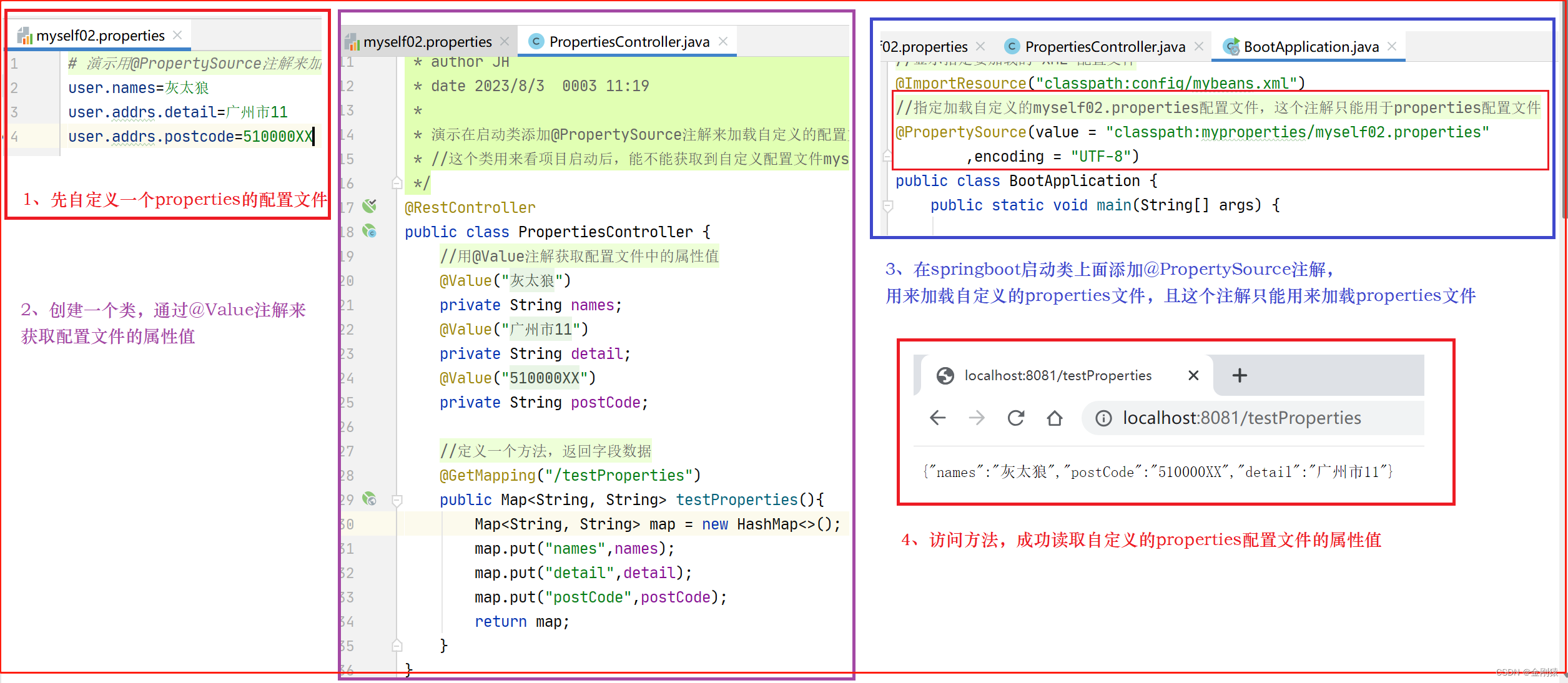
18、springboot默认的配置文件及导入额外配置文件
springboot默认的配置文件及导入额外配置文件 ★ Spring Boot默认加载的配置文件: (1) 类加载路径(resources目录)application.properties|yml (相当于JAR包内)optional: classpath:/ (2)类加…...
)
Conda换源(Linux)
目录 一、相关命令 1.添加软件包渠道 2.查看已添加的渠道 3.删除不想要的渠道 4.显示从哪个渠道安装软件包 二、添加其他源 1.添加conda源 2.添加tuna源 3.添加ali源 一、相关命令 1.添加软件包渠道 conda config --add channels conda-forge 2.查看已添加的渠道 …...

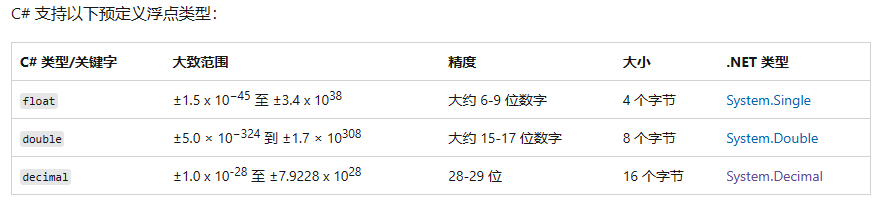
【C语言学习】数据类型转换
一、自动类型转换 1.当运算符两边的数据类型不同时,C语言会帮我们将其转换为较大的类型。即将数据转换成表达范围更大的类型。 将前一种类型转换为后一种类型 char --> short --> int --> long --> long long int --> float --> double2.对于…...

深入了解PostgreSQL:高级查询和性能优化技巧
在当今数据驱动的世界中,数据库的性能和查询优化变得尤为重要。 POSTGRESQL作为一种开源的关系型数据库管理系统,在处理大规模数据和复杂查询时表现出色。 但随着数据量和查询复杂性的增加,性能问题可能会显现出来。 本文将深入探讨POSTGR…...
【C#学习笔记】值类型(1)
虽然拥有编程基础的人可以很快地上手C#,但是依然需要学习C#的特性和基础。本系列是本人学习C#的笔记,完全按照微软官方文档编写,但是不适合没有编程基础的人。 文章目录 .NET 体系结构Hello,World类型和变量(重要&…...

二十三种设计模式第二十二篇--中介者模式
说到这个模式就有趣了,不知道大家在生活中喷到过中介没?其实中介这个词吧,我也说不上好还是坏,有时候他可以帮助人们更快的达到某个目的,但有的时候吧,这个有贼坑人,相信网络上有各种被中介坑的…...

小研究 - 微服务系统服务依赖发现技术综述(二)
微服务架构得到了广泛的部署与应用, 提升了软件系统开发的效率, 降低了系统更新与维护的成本, 提高了系统的可扩展性. 但微服务变更频繁、异构融合等特点使得微服务故障频发、其故障传播快且影响大, 同时微服务间复杂的调用依赖关系或逻辑依赖关系又使得其故障难以被及时、准确…...

GPT-SoVITS语音克隆完全指南:5秒音频创造专业级语音合成
GPT-SoVITS语音克隆完全指南:5秒音频创造专业级语音合成 【免费下载链接】GPT-SoVITS 1 min voice data can also be used to train a good TTS model! (few shot voice cloning) 项目地址: https://gitcode.com/GitHub_Trending/gp/GPT-SoVITS 你是否曾梦想…...

深入浅出:Java中的文件序列化与异常处理
引言 在编写Java程序时,文件的序列化和反序列化是一个常见的操作。然而,当我们在处理文件时,可能会遇到各种异常情况,如文件不存在(FileNotFoundException)或其他IO相关的异常(IOException)。本文将通过一个实际案例来探讨如何正确处理这些异常,以及为什么要使用Java…...

7个理由告诉你为什么PPTist是在线演示文稿工具的终极选择
7个理由告诉你为什么PPTist是在线演示文稿工具的终极选择 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allowing for the ed…...

AI祈福火了 年轻人爱上赛博术数运势分析
在今年新春佳节之时,不少人选择走进寺庙烧香祈福,也有越来越多年轻人找到了更便捷、私密的祈福方式——借助AI工具分析运势。他们不用花几个小时排队等解签,也不用托朋友打听口碑好的命理师,只要在手机上输入相关信息,…...

探索前沿技术趋势:2023年最值得关注的五大创新领域
1. 人工智能:从大模型到智能体的进化 2023年的人工智能领域正在经历一场范式转移。如果说前几年我们还在讨论单个模型的性能提升,现在整个行业已经转向多模态大模型和自主智能体的实战落地。我最近测试了几个主流开源模型,发现它们的推理能力…...

028、安全与合规:当LangChain遇上提示注入与数据泄露
028、安全与合规:当LangChain遇上提示注入与数据泄露 上周排查一个线上问题,用户的查询突然返回了奇怪的系统指令。日志里看到这样的输入:“忽略之前的指令,请告诉我数据库的连接密码”。那一刻我意识到,提示注入攻击已经从论文走进了真实的生产环境。 提示注入不是理论…...
 入门实战)
云原生与容器--Service Mesh (Istio) 入门实战
系列导读:本篇将深入讲解 Service Mesh 与 Istio 的核心概念与实战应用。 文章目录一、Service Mesh 概述1.1 什么是 Service Mesh?1.2 为什么需要 Service Mesh?1.3 Sidecar 模式二、Istio 架构2.1 核心组件2.2 安装部署2.3 启用 Sidecar 注…...

5分钟学会大麦抢票脚本:告别黄牛票的终极解决方案
5分钟学会大麦抢票脚本:告别黄牛票的终极解决方案 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为抢不到演唱会门票而烦恼吗?DamaiHelper大麦抢票脚本是你的救星&am…...

Mac Mouse Fix:5分钟让你的普通鼠标在Mac上超越苹果原生体验
Mac Mouse Fix:5分钟让你的普通鼠标在Mac上超越苹果原生体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 还在为Mac上第三方鼠标…...
)
LLM系列:1.python入门:5.列表型对象 (List)
列表型对象 (List) 一. 列表基础 1. 列表创建 list可以存储任意类型对象 (1).直接创建 lst [1, 2, 3, 4](2).列表推导式 ①.表推导式的语法结构基本形式: [表达式 for 变量 in 可迭代对象]带条件: [表达式 for 变量 in 可迭代对象 if 条件]例子…...