C++11移动构造函数详解
C++11移动构造函数详解
- 拷贝构造函数
- 修改后的拷贝构造函数
- 移动构造函数
- 移动构造函数的优点
当类中同时包含拷贝构造函数和移动构造函数时,如果使用临时对象初始化当前类的对象,编译器会优先调用移动构造函数来完成此操作。只有当类中没有合适的移动构造函数时,编译器才会退而求其次,调用拷贝构造函数。
拷贝构造函数
C++在三种情况下会调用拷贝构造函数(可能有纰漏),第一种情况是函数形实结合时,第二种情况是函数返回时,函数栈区的对象会复制一份到函数的返回去,第三种情况是用一个对象初始化另一个对象时也会调用拷贝构造函数。
除了这三种情况下会调用拷贝构造函数,另外如果将一个对象赋值给另一个对象,这个时候回调用重载的赋值运算符函数。
无论是拷贝构造函数,还是重载的赋值运算符函数,我记得当时在上C++课的时候,老师再三强调,一定要注意指针的浅层复制问题。
这里在简单回忆一下拷贝构造函数中的浅层复制问题
首先看一个浅层复制的代码:
#include <iostream>
#include <cstring>
#include <cstdlib>
#include <vector>using namespace std;class Str{public:char *value;Str(char s[]){cout<<"调用构造函数..."<<endl;int len = strlen(s);value = new char[len + 1];memset(value,0,len + 1);strcpy(value,s);}Str(Str &v){cout<<"调用拷贝构造函数..."<<endl;this->value = v.value;}~Str(){cout<<"调用析构函数..."<<endl;if(value != NULL)delete[] value;}
};int main()
{char s[] = "I love BIT";Str *a = new Str(s);Str *b = new Str(*a);delete a;cout<<"b对象中的字符串为:"<<b->value<<endl;delete b;return 0;
}
输出结果为:
调用构造函数...
调用拷贝构造函数...
调用析构函数...
b对象中的字符串为:
调用析构函数...
首先结果并不符合预期,我们希望b对象中的字符串也是I love BIT但是输出为空,这是因为b->value和a->value指向了同一片内存区域,当delete a的时候,该内存区域已经被收回,所以再用b->value访问那块内存实际上是不合适的,而且,虽然我运行时程序没有崩溃,但是程序存在崩溃的风险呀,因为当delete b的时候,那块内存区域又被释放了一次,两次释放同一块内存,相当危险呀。
因此对于类中的指针数据成员,必须采用深层复制的方式进行拷贝,深层复制的代码如下:
#include <iostream>
#include <cstring>
#include <cstdlib>
#include <vector>using namespace std;class Str{public:char *value;Str(char s[]){cout<<"调用构造函数..."<<endl;int len = strlen(s);value = new char[len + 1];memset(value,0,len + 1);strcpy(value,s);}Str(Str &v){cout<<"调用拷贝构造函数..."<<endl;int len = strlen(v.value);value = new char[len + 1];memset(value,0,len + 1);strcpy(value,v.value);}~Str(){cout<<"调用析构函数..."<<endl;if(value != NULL){delete[] value;value = NULL;}}
};int main()
{char s[] = "I love BIT";Str *a = new Str(s);Str *b = new Str(*a);delete a;cout<<"b对象中的字符串为:"<<b->value<<endl;delete b;return 0;
}
运行结果为:
调用构造函数.. .
调用拷贝构造函数...
调用析构函数...
b对象中的字符串为:l love BIT
调用析构函数...
修改后的拷贝构造函数
有时候我们会遇到这样一种情况,我们用对象a初始化对象b,后对象a我们就不在使用了,但是对象a的空间还在呀(在析构之前),既然拷贝构造函数,实际上就是把a对象的内容复制一份到b中,那么我们可以对指针进行浅复制,这样就避免了新的空间的分配,大大降低了构造的成本。
但是上面提到,指针的浅层复制是非常危险的呀。没错,确实很危险,而且通过上面的例子,我们也可以看出,浅层复制之所以危险,是因为两个指针共同指向一片内存空间,若第一个指针将其释放,另一个指针的指向就不合法了。所以我们只要避免第一个指针释放空间就可以了。避免的方法就是将第一个指针(比如a->value)置为NULL,这样在调用析构函数的时候,由于有判断是否为NULL的语句,所以析构a的时候并不会回收a->value指向的空间(同时也是b->value指向的空间)
所以我们可以把上面的拷贝构造函数的代码修改一下:
#include <iostream>
#include <cstring>
#include <cstdlib>
#include <vector>using namespace std;class Str{public:char *value;Str(char s[]){cout<<"调用构造函数..."<<endl;int len = strlen(s);value = new char[len + 1];memset(value,0,len + 1);strcpy(value,s);}Str(Str &v){cout<<"调用拷贝构造函数..."<<endl;this->value = v.value;v.value = NULL;}~Str(){cout<<"调用析构函数..."<<endl;if(value != NULL)delete[] value;}
};int main()
{char s[] = "I love BIT";Str *a = new Str(s);Str *b = new Str(*a);delete a;cout<<"b对象中的字符串为:"<<b->value<<endl;delete b;return 0;
}
运行结果为:
调用构造函数...
调用拷贝构造函数...
调用析构函数...
b对象中的字符串为:l love BIT
调用析构函数...
修改后的拷贝构造函数,采用了浅层复制,但是结果仍能够达到我们想要的效果,关键在于在拷贝构造函数中,最后我们将v.value置为了NULL,这样在析构a的时候,就不会回收a->value指向的内存空间。
这样用a初始化b的过程中,实际上我们就减少了开辟内存,构造成本就降低了。
但要注意,我们这样使用拷贝构造函数有一个前提是:用a初始化b后,a我们就不需要了,最好是初始化完成后就将a析构。如果说,我们用a初始化了b后,仍要对a进行操作,用这种浅层复制的方法就不合适了。
所以C++引入了移动构造函数,专门处理这种用a初始化b后就将a析构的情况。
移动构造函数
移动构造函数的参数和拷贝构造函数不同,拷贝构造函数的参数是一个左值引用,但是移动构造函数的初值是一个右值引用。这意味着,移动构造函数的参数是一个右值或者将亡值的引用。也就是说,只用用一个右值,或者将亡值初始化另一个对象的时候,才会调用移动构造函数。移动构造函数的例子如下:
#include <iostream>
#include <cstring>
#include <cstdlib>
#include <vector>
using namespace std;class Str{public:char *str;Str(char value[]){cout<<"普通构造函数..."<<endl;str = NULL;int len = strlen(value);str = (char *)malloc(len + 1);memset(str,0,len + 1);strcpy(str,value);}Str(const Str &s){cout<<"拷贝构造函数..."<<endl;str = NULL;int len = strlen(s.str);str = (char *)malloc(len + 1);memset(str,0,len + 1);strcpy(str,s.str);}Str(Str &&s){cout<<"移动构造函数..."<<endl;str = NULL;str = s.str;s.str = NULL;}~Str(){cout<<"析构函数"<<endl;if(str != NULL){free(str);str = NULL;}}
};
int main()
{char value[] = "I love zx";Str s(value);vector<Str> vs;//vs.push_back(move(s));vs.push_back(s);cout<<vs[0].str<<endl;if(s.str != NULL)cout<<s.str<<endl;return 0;
}
在此构造函数中,num 指针变量采用的是浅拷贝的复制方式,同时在函数内部重置了 d.num,有效避免了“同一块对空间被释放多次”情况的发生。
当类中同时包含拷贝构造函数和移动构造函数时,如果使用临时对象初始化当前类的对象,编译器会优先调用移动构造函数来完成此操作。只有当类中没有合适的移动构造函数时,编译器才会退而求其次,调用拷贝构造函数。
使用move()函数,可以将一个左值变成右值,因此a=move(b)调用的是移动构造函数。
移动构造函数的优点
移动构造函数是c++11的新特性,移动构造函数传入的参数是一个右值 用&&标出。
首先讲讲拷贝构造函数:拷贝构造函数是先将传入的参数对象进行一次深拷贝,再传给新对象。这就会有一次拷贝对象的开销,并且进行了深拷贝,就需要给对象分配地址空间。而移动构造函数就是为了解决这个拷贝开销而产生的。移动构造函数首先将传递参数的内存地址空间接管,然后将内部所有指针设置为nullptr,并且在原地址上进行新对象的构造,最后调用原对象的的析构函数,这样做既不会产生额外的拷贝开销,也不会给新对象分配内存空间。
相关文章:

C++11移动构造函数详解
C11移动构造函数详解 拷贝构造函数修改后的拷贝构造函数移动构造函数移动构造函数的优点 当类中同时包含拷贝构造函数和移动构造函数时,如果使用临时对象初始化当前类的对象,编译器会优先调用移动构造函数来完成此操作。只有当类中没有合适的移动构造函数…...

【力扣】19. 删除链表的倒数第 N 个结点 <链表指针、快慢指针>
【力扣】19. 删除链表的倒数第 N 个结点 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5] 示例 2: 输入:head [1], n…...

Vue3和typeScript路由传参
1 params传的参数,页面刷新就消失,而query传的参数,页面刷新还会存在,所以通常用query。 query传参 跳转页面:拿到router对象,调用push方法做跳转. import { useRoute,useRouter} from "vue-router"; export default…...

SQLserver数据库巡检脚本
SQL Server数据库巡检脚本的示例: #!/bin/bash# 设置SQL Server登录凭证 SQL_USER"your_username" SQL_PASSWORD"your_password"# 设置巡检结果输出文件路径 OUTPUT_FILE"/path/to/output.log"# 获取SQL Server版本信息 sql_version…...
Go Ethereum源码学习笔记 001 Geth Start
Go Ethereum源码学习笔记 前言[Chapter_001] 万物的起点: Geth Start什么是 geth?go-ethereum Codebase 结构 Geth Start前奏: Geth Consolegeth 节点是如何启动的NodeNode的关闭 Ethereum Backend附录 前言 首先读者需要具备Go语言基础,至少要通关菜鸟…...
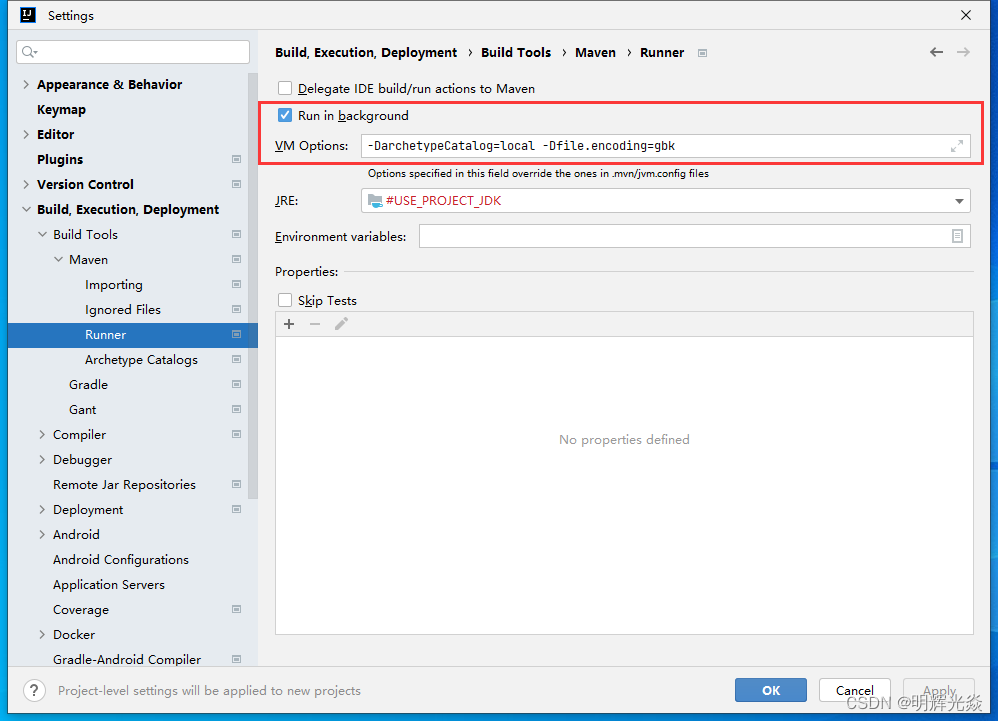
idea如何加快创建Maven项目的速度
一、下载archetype-catalog.xml 下载archetype-catalog.xml的地址 二、配置 以下所说的配置都指全局配置。 配置Maven -DarchetypeCataloglocal -Dfile.encodinggbk...
软件外包开发的GO开发框架
近些年GO语言使用的越来越多,尤其是在web应用开发和高性能服务器的项目里。在开发新项目时掌握一些常用的开发框架可以节省开发时间提高工作效率,也是对软件开发人员基本的技能要求。今天和大家分享一些常见的GO语言开发框架,希望对大家有所帮…...

oracle会话打满
1.查看当前连接情况 col machine for a20 col program for a40 col sql_id for a20 set linesize 300 set pagesize 300 select machine,program,sql_id,count(1) from v$session group by machine,program,sql_id order by 4 desc;MACHINE PROGRAM SQL_ID …...
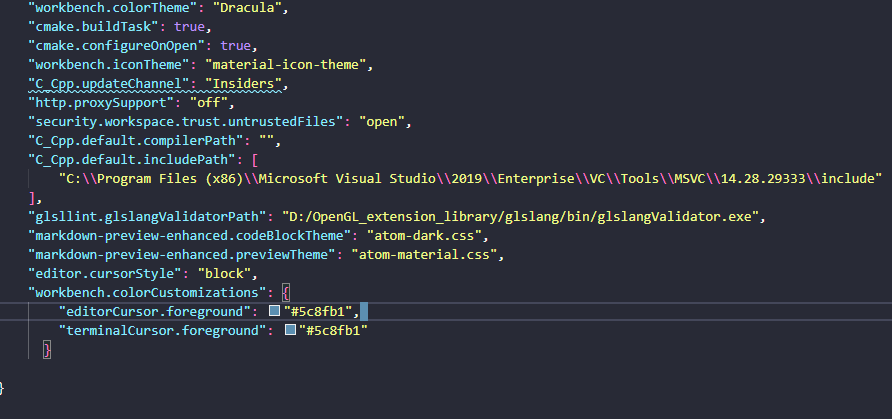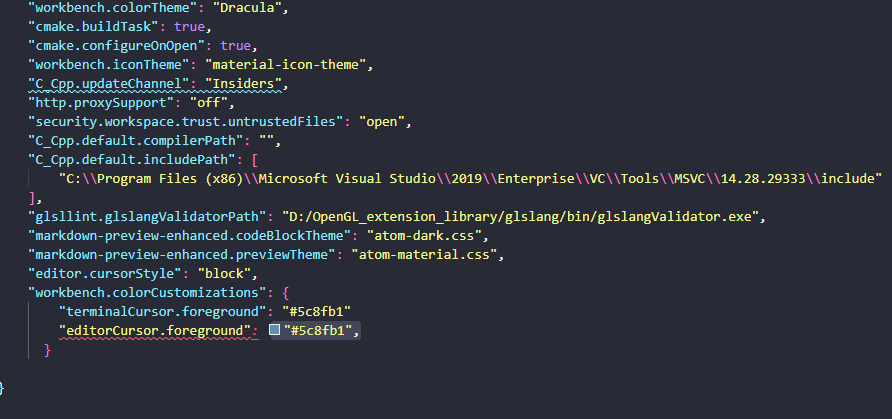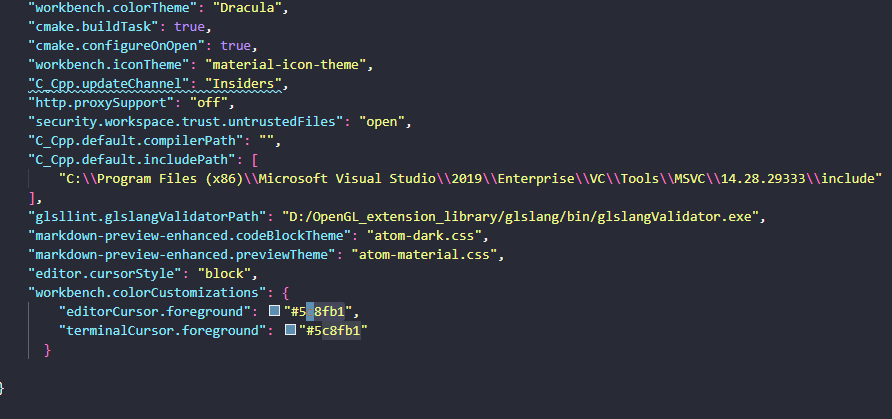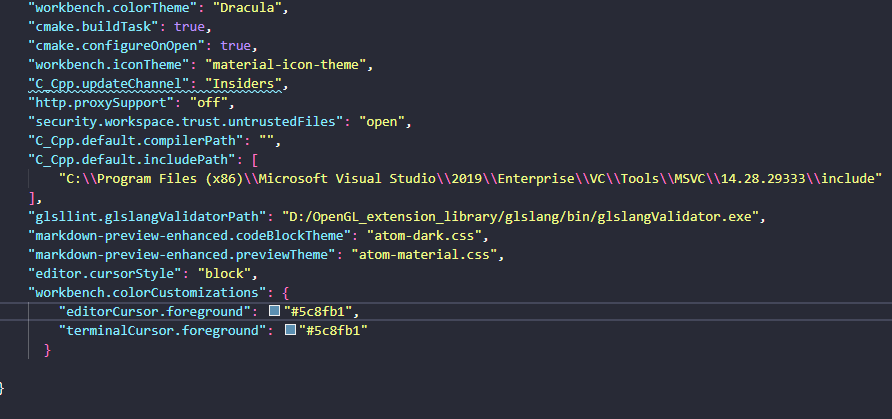
VSCode自定义闪烁光标
打开VSCode 组合键ctrlshiftp搜索"settings.json",打开User Settings 加上这一句 "editor.cursorStyle": "block","workbench.colorCustomizations": {"editorCursor.foreground": "#5c8fb1","terminalCurs…...
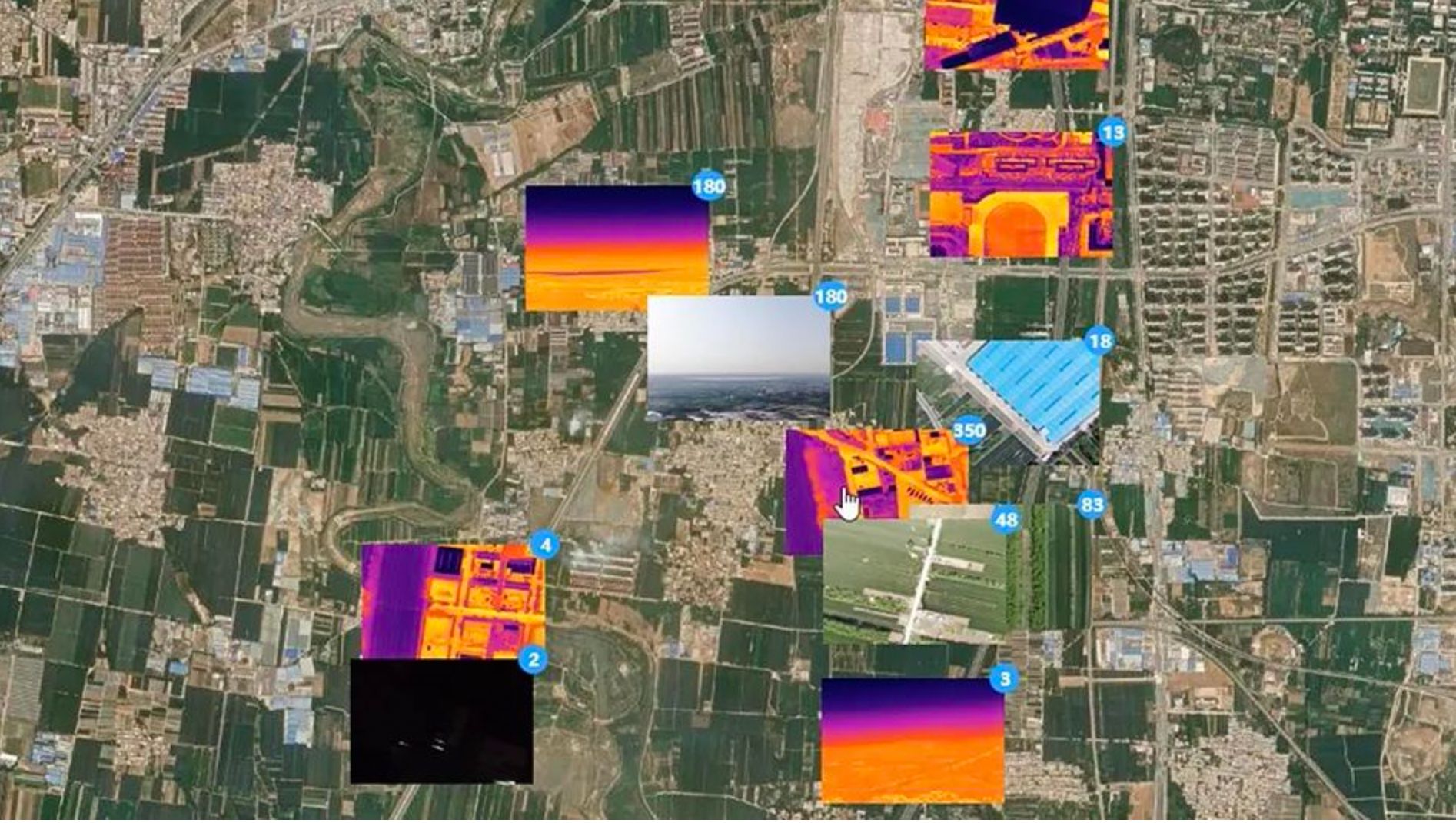
复亚智能打造全新云平台:让无人机任务管理更智能、更简单
复亚智能全新升级的MindView云平台,对航线规划、任务管理、自动飞行、数据管理等各个环节开展可视化、数字化、智能化监管,从任务到结果的“看得清”、“管得住”、“查得准”,带来更轻松的操作,改善作业效率、安全保障和用户体验…...

编程导航第六关——白银挑战
编程导航第六关——白银挑战 树的层次遍历 LeetCode102 题目要求:给你一个二叉树,请你返回其按层序遍历得到的节点值。(即逐层地,从左到右访问所有节点)。思路: 我们根据队列的特点,先进先出;要实现全部节…...
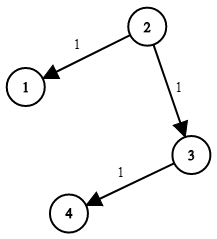
743. 网络延迟时间
有 n 个网络节点,标记为 1 到 n。 给你一个列表 times,表示信号经过 有向 边的传递时间。 times[i] (ui, vi, wi),其中 ui 是源节点,vi 是目标节点, wi 是一个信号从源节点传递到目标节点的时间。 现在,…...
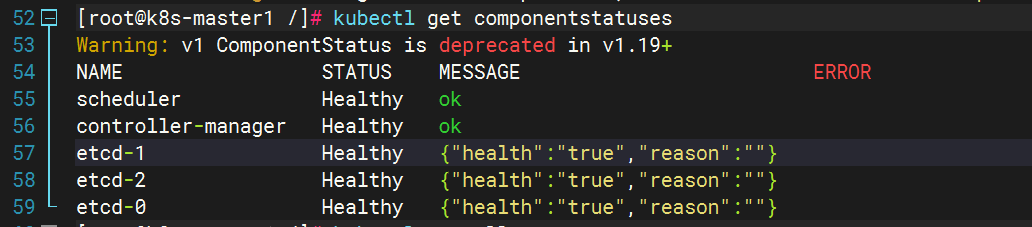
Kubernetes高可用集群二进制部署(四)部署kubectl和kube-controller-manager、kube-scheduler
Kubernetes概述 使用kubeadm快速部署一个k8s集群 Kubernetes高可用集群二进制部署(一)主机准备和负载均衡器安装 Kubernetes高可用集群二进制部署(二)ETCD集群部署 Kubernetes高可用集群二进制部署(三)部署…...
)
在CSDN学Golang场景化解决方案(微服务架构设计)
一,聚合器微服务设计模式 在Golang微服务架构设计中,聚合器(Aggregator)微服务设计模式是一种常见的应用程序体系结构模式。该模式旨在简化客户端与后端微服务之间的通信,并支持更高级别的操作,例如聚合多…...
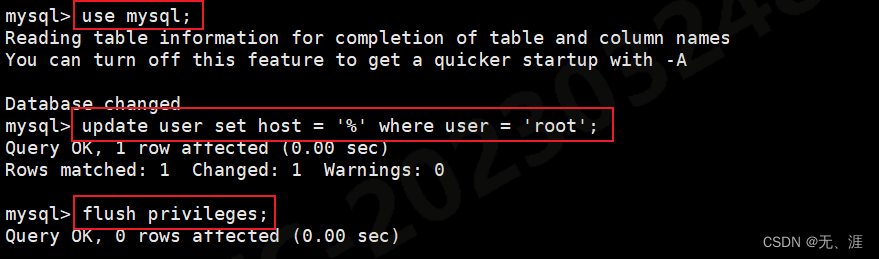
centos7 yum安装mysql5.7
卸载mysql 以下指令查看是否安装过 rpm -qa | grep -i mysql 如果发现已经安装,需要卸载了再安装(据说,这样的卸载是不彻底的。) rpm -e mysql 卸载 mariadb yum -y remove mariadb-libs-1:5.5.68-1.el7.x86_64 下载和安装mys…...
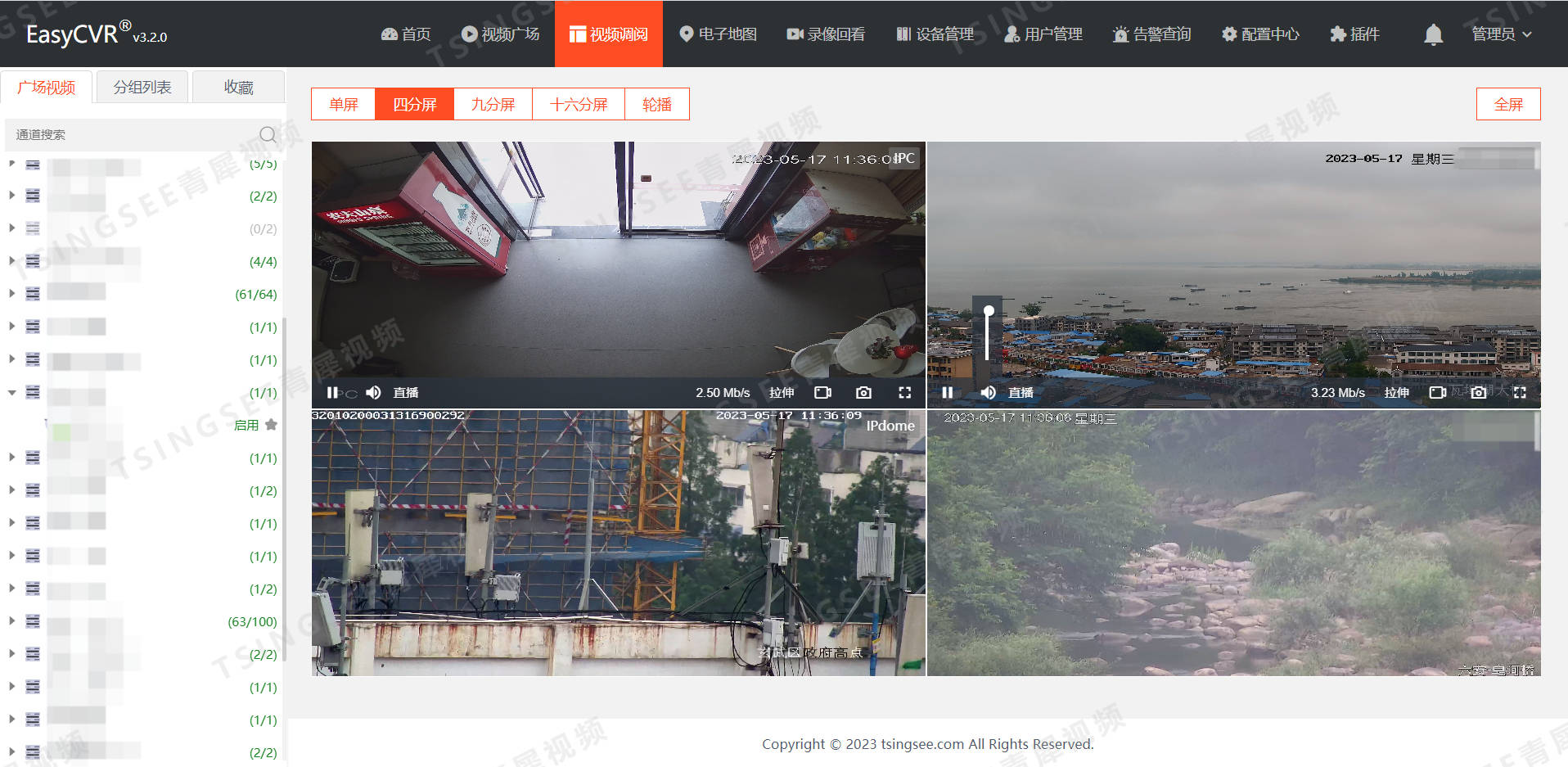
安防视频汇聚平台EasyCVR视频广场面包屑侧边栏支持拖拽操作
智能视频监控平台EasyCVR能在复杂的网络环境中,将海量设备实现集中统一接入与汇聚管理,实现视频的处理与分发、录像与存储、按需调阅、平台级联等。 TSINGSEE青犀视频汇聚平台EasyCVR可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协…...

爬虫007_python中的输出以及格式化输出_以及输入---python工作笔记025
首先看输出 输出这里,注意不能直接上面这样,18需要转换成字符串 可以看到python中这个字符串和数字一起的时候,数字要转换一下成字符串. 然后这里要注意%s 和%d,这个s指的是字符串,d指的是数字 注意后面的内容前面要放个% ,然后多个参数的话,那么这里用(),里面用,号隔开 然…...

485modbus转profinet网关连三菱变频器modbus通讯触摸屏监控
本案例介绍了如何通过485modbus转profinet网关连接威纶通与三菱变频器进行modbus通讯。485modbus转profinet网关提供了可靠的连接方式,使用户能够轻松地将不同类型的设备连接到同一网络中。通过使用这种网关,用户可以有效地管理和监控设备,从…...

话费充值接口文档
话费充值接口文档 接口版本:1.0 ―、引言 文档概述 本文档提供话费充值接口规范说明,提供一整套的完整的接入示例(http 接口)供商户参 考,可以帮助商户开发人员快速完成接口开发与联调,实现与话费充值系统的交易互联。 公司官网…...
windows系统的IP、路由、网关、内外网同时访问路由以及修改系统文件hosts的配置
当我们刚刚入职一家公司的时候、一般公司会给我下发一个ip地址和mac地址、还有访问一些公司的平台需要修改hosts之后的路由配置、以及第一次配置内网、如何内外网同时上网。 目录 一、ip的配置 1.1、IP的配置 1.2、mac地址的配置 1.3、内外网路由的配置(w11系统需…...

Vue2 页面白屏问题详细排查与处理方案
一、什么是「页面白屏」 白屏类型 表现 常见原因 完全白屏 页面一片空白,无任何内容 JS 报错、入口文件加载失败 路由白屏 进入某一路由后空白 路由配置错误、组件加载失败 部分白屏 只有某个区域空白 组件渲染异常、数据未返回 刷新白屏 首次正常,刷新…...

如何快速下载网页视频:VideoDownloadHelper完整使用指南
如何快速下载网页视频:VideoDownloadHelper完整使用指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper VideoDownloadHelper是一…...

如何用Zotero Better Notes打造终极文献笔记管理系统?
如何用Zotero Better Notes打造终极文献笔记管理系统? 【免费下载链接】zotero-better-notes Everything about note management. All in Zotero. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-better-notes 在学术研究和知识管理领域,文…...

Python图像处理入门指南:从基础到实战
1. 为什么选择Python做图像处理? 第一次接触图像处理时,我也纠结过该用什么工具。试过Photoshop这类图形软件后,发现它们虽然功能强大,但没法自动化处理大批量图片。后来转向编程方案,在C和Python之间犹豫了很久&#…...
- 三分钟安装部署好Datax)
从零开始的大数据之路(6)- 三分钟安装部署好Datax
目录 datax的安装包: 从零开始的大数据之路 (0)的葵花宝典 -- 安装包分享 -- 错过就是罪过 [持续更新分享]-CSDN博客 1、上传datax安装包到服务器并分发到其他服务器 2、解压Datax 3、测试Datax 4、测试失败 datax报错解决 解决 再次…...

5分钟掌握B站视频智能转文字:从链接到可编辑文本的完整方案
5分钟掌握B站视频智能转文字:从链接到可编辑文本的完整方案 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 在当今信息爆炸的时代,Bil…...
)
【数据爬取】国家知识产权局专利统计数据的自动化收集与整理(request+lxml+selenium实战)
1. 为什么需要自动化收集专利数据 做数据分析的朋友们应该都深有体会,最头疼的不是写代码分析数据,而是前期收集整理数据的过程。就拿专利数据来说,每次手动下载几十个Excel表格,再一个个整理合并,这种重复劳动不仅效率…...

BEYOND REALITY Z-Image效果实测:1024×1024分辨率下显存占用仅18.2GB
BEYOND REALITY Z-Image效果实测:10241024分辨率下显存占用仅18.2GB 1. 这不是“又一个”文生图模型,而是写实人像的精度拐点 你有没有试过——输入一段精心打磨的提示词,点击生成,等了半分钟,结果画面全黑ÿ…...

【AIAgent TCO控制白皮书】:基于17个生产环境数据验证的8类资源浪费模式与自动化治理方案
第一章:AIAgent架构成本优化策略总览 2026奇点智能技术大会(https://ml-summit.org) AI Agent系统在生产环境中常面临推理延迟高、模型调用频次失控、上下文冗余膨胀等导致的云资源成本陡增问题。成本优化并非仅聚焦于模型压缩或硬件降配,而需贯穿设计、…...

Windows 安装 DeerFlow 2.0
今天有空尝试了下最近很火来自字节开源的 DeerFlow,这框架在 Linux 下安装会顺利很多,只是公司开发电脑是 Windows 11 版本的,所以本地安装折腾了一番功夫才安装上,中间放弃了 2 次不想装了,做其他事去了,做…...