VGG卷积神经网络-笔记
VGG卷积神经网络-笔记
VGG是当前最流行的CNN模型之一,
2014年由Simonyan和Zisserman提出,
其命名来源于论文作者所在的实验室Visual Geometry Group。
测试结果为:
通过运行结果可以发现,在眼疾筛查数据集iChallenge-PM上使用VGG,loss能有效的下降,
经过5个epoch的训练,在验证集上的准确率可以达到94%左右。
实测准确率为0.94左右
[validation] accuracy/loss: 0.9400/0.1871
PS E:\project\python> & D:/ProgramData/Anaconda3/python.exe e:/project/python/PM/VGG_PM.py
W0803 17:19:47.159580 3832 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 12.2, Runtime API Version: 10.2
W0803 17:19:47.168586 3832 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
start training ...
epoch: 0, batch_id: 0, loss is: 0.7140
epoch: 0, batch_id: 20, loss is: 0.6399
[validation] accuracy/loss: 0.8675/0.3249
epoch: 1, batch_id: 0, loss is: 0.2456
epoch: 1, batch_id: 20, loss is: 0.3115
[validation] accuracy/loss: 0.9250/0.2395
epoch: 2, batch_id: 0, loss is: 0.2267
epoch: 2, batch_id: 20, loss is: 0.1179
[validation] accuracy/loss: 0.9050/0.3038
epoch: 3, batch_id: 0, loss is: 0.2367
epoch: 3, batch_id: 20, loss is: 0.3747
[validation] accuracy/loss: 0.9200/0.2123
epoch: 4, batch_id: 0, loss is: 0.3089
epoch: 4, batch_id: 20, loss is: 0.0130
[validation] accuracy/loss: 0.9400/0.1871
VGG网格 子图层结构
[Conv2D(3, 64, kernel_size=[3, 3], padding=1, data_format=NCHW),
Conv2D(64, 64, kernel_size=[3, 3], padding=1, data_format=NCHW),
MaxPool2D(kernel_size=2, stride=2, padding=0), Conv2D(64, 128, kernel_size=[3, 3], padding=1, data_format=NCHW),
Conv2D(128, 128, kernel_size=[3, 3], padding=1, data_format=NCHW),
MaxPool2D(kernel_size=2, stride=2, padding=0), Conv2D(128, 256, kernel_size=[3, 3], padding=1, data_format=NCHW),
Conv2D(256, 256, kernel_size=[3, 3], padding=1, data_format=NCHW),
Conv2D(256, 256, kernel_size=[3, 3], padding=1, data_format=NCHW),
MaxPool2D(kernel_size=2, stride=2, padding=0), Conv2D(256, 512, kernel_size=[3, 3], padding=1, data_format=NCHW),
Conv2D(512, 512, kernel_size=[3, 3], padding=1, data_format=NCHW),
Conv2D(512, 512, kernel_size=[3, 3], padding=1, data_format=NCHW),
MaxPool2D(kernel_size=2, stride=2, padding=0), Conv2D(512, 512, kernel_size=[3, 3], padding=1, data_format=NCHW),
Conv2D(512, 512, kernel_size=[3, 3], padding=1, data_format=NCHW),
Conv2D(512, 512, kernel_size=[3, 3], padding=1, data_format=NCHW),
MaxPool2D(kernel_size=2, stride=2, padding=0), Linear(in_features=25088, out_features=4096, dtype=float32),
ReLU(),
Dropout(p=0.5, axis=None, mode=upscale_in_train), Linear(in_features=4096, out_features=4096, dtype=float32),
ReLU(),
Dropout(p=0.5, axis=None, mode=upscale_in_train), Linear(in_features=4096, out_features=1, dtype=float32)](10, 3, 224, 224)
[10, 3, 224, 224]
#VGG网格 子图层shape[N,Cout,H,W],w参数[Cout,Ci,Kh,Kw],b参数[Cout]
conv2d_0 [10, 64, 224, 224] [64, 3, 3, 3] [64]
conv2d_1 [10, 64, 224, 224] [64, 64, 3, 3] [64]
max_pool2d_0 [10, 64, 112, 112]
conv2d_2 [10, 128, 112, 112] [128, 64, 3, 3] [128]
conv2d_3 [10, 128, 112, 112] [128, 128, 3, 3] [128]
max_pool2d_1 [10, 128, 56, 56]
conv2d_4 [10, 256, 56, 56] [256, 128, 3, 3] [256]
conv2d_5 [10, 256, 56, 56] [256, 256, 3, 3] [256]
conv2d_6 [10, 256, 56, 56] [256, 256, 3, 3] [256]
max_pool2d_2 [10, 256, 28, 28]
conv2d_7 [10, 512, 28, 28] [512, 256, 3, 3] [512]
conv2d_8 [10, 512, 28, 28] [512, 512, 3, 3] [512]
conv2d_9 [10, 512, 28, 28] [512, 512, 3, 3] [512]
max_pool2d_3 [10, 512, 14, 14]
conv2d_10 [10, 512, 14, 14] [512, 512, 3, 3] [512]
conv2d_11 [10, 512, 14, 14] [512, 512, 3, 3] [512]
conv2d_12 [10, 512, 14, 14] [512, 512, 3, 3] [512]
max_pool2d_4 [10, 512, 7, 7]
linear_0 [10, 4096] [25088, 4096] [4096]
re_lu_0 [10, 4096]
dropout_0 [10, 4096]
linear_1 [10, 4096] [4096, 4096] [4096]
re_lu_1 [10, 4096]
dropout_1 [10, 4096]
linear_2 [10, 1] [4096, 1] [1]
PS E:\project\python>
测试源代码如下所示:
# -*- coding:utf-8 -*-# VGG模型代码
import numpy as np
import paddle
# from paddle.nn import Conv2D, MaxPool2D, BatchNorm, Linear
from paddle.nn import Conv2D, MaxPool2D, BatchNorm2D, Linear# 定义vgg网络
class VGG(paddle.nn.Layer):def __init__(self, num_classes=1):super(VGG, self).__init__()in_channels = [3, 64, 128, 256, 512, 512]# 定义第一个block,包含两个卷积self.conv1_1 = Conv2D(in_channels=in_channels[0], out_channels=in_channels[1], kernel_size=3, padding=1, stride=1)self.conv1_2 = Conv2D(in_channels=in_channels[1], out_channels=in_channels[1], kernel_size=3, padding=1, stride=1)self.pool1 = MaxPool2D(stride=2, kernel_size=2)# 定义第二个block,包含两个卷积self.conv2_1 = Conv2D(in_channels=in_channels[1], out_channels=in_channels[2], kernel_size=3, padding=1, stride=1)self.conv2_2 = Conv2D(in_channels=in_channels[2], out_channels=in_channels[2], kernel_size=3, padding=1, stride=1)self.pool2 = MaxPool2D(stride=2, kernel_size=2)# 定义第三个block,包含三个卷积self.conv3_1 = Conv2D(in_channels=in_channels[2], out_channels=in_channels[3], kernel_size=3, padding=1, stride=1)self.conv3_2 = Conv2D(in_channels=in_channels[3], out_channels=in_channels[3], kernel_size=3, padding=1, stride=1)self.conv3_3 = Conv2D(in_channels=in_channels[3], out_channels=in_channels[3], kernel_size=3, padding=1, stride=1)self.pool3 = MaxPool2D(stride=2, kernel_size=2)# 定义第四个block,包含三个卷积self.conv4_1 = Conv2D(in_channels=in_channels[3], out_channels=in_channels[4], kernel_size=3, padding=1, stride=1)self.conv4_2 = Conv2D(in_channels=in_channels[4], out_channels=in_channels[4], kernel_size=3, padding=1, stride=1)self.conv4_3 = Conv2D(in_channels=in_channels[4], out_channels=in_channels[4], kernel_size=3, padding=1, stride=1)self.pool4 = MaxPool2D(stride=2, kernel_size=2)# 定义第五个block,包含三个卷积self.conv5_1 = Conv2D(in_channels=in_channels[4], out_channels=in_channels[5], kernel_size=3, padding=1, stride=1)self.conv5_2 = Conv2D(in_channels=in_channels[5], out_channels=in_channels[5], kernel_size=3, padding=1, stride=1)self.conv5_3 = Conv2D(in_channels=in_channels[5], out_channels=in_channels[5], kernel_size=3, padding=1, stride=1)self.pool5 = MaxPool2D(stride=2, kernel_size=2)# 使用Sequential 将全连接层和relu组成一个线性结构(fc + relu)# 当输入为224x224时,经过五个卷积块和池化层后,特征维度变为[512x7x7]=25088#self.fc1 = paddle.nn.Sequential(paddle.nn.Linear(512 * 7 * 7, 4096), paddle.nn.ReLU())self.fc1 = paddle.nn.Linear(512 * 7 * 7, 4096)self.relu1=paddle.nn.ReLU()self.drop1_ratio = 0.5self.dropout1 = paddle.nn.Dropout(self.drop1_ratio, mode='upscale_in_train')# 使用Sequential 将全连接层和relu组成一个线性结构(fc + relu)#self.fc2 = paddle.nn.Sequential(paddle.nn.Linear(4096, 4096), paddle.nn.ReLU())self.fc2 = paddle.nn.Linear(4096, 4096)self.relu2=paddle.nn.ReLU()self.drop2_ratio = 0.5self.dropout2 = paddle.nn.Dropout(self.drop2_ratio, mode='upscale_in_train')self.fc3 = paddle.nn.Linear(4096, 1)#self.relu = paddle.nn.ReLU()#self.pool = MaxPool2D(stride=2, kernel_size=2)def forward(self, x):x = self.relu1(self.conv1_1(x))x = self.relu1(self.conv1_2(x))x = self.pool1(x)x = self.relu1(self.conv2_1(x))x = self.relu1(self.conv2_2(x))x = self.pool2(x)x = self.relu1(self.conv3_1(x))x = self.relu1(self.conv3_2(x))x = self.relu1(self.conv3_3(x))x = self.pool3(x)x = self.relu1(self.conv4_1(x))x = self.relu1(self.conv4_2(x))x = self.relu1(self.conv4_3(x))x = self.pool4(x)x = self.relu1(self.conv5_1(x))x = self.relu1(self.conv5_2(x))x = self.relu1(self.conv5_3(x))x = self.pool5(x)x = paddle.flatten(x, 1, -1)x = self.dropout1(self.relu1(self.fc1(x)))x = self.dropout2(self.relu2(self.fc2(x)))x = self.fc3(x)return x
#
import PM
# 创建模型
model = VGG()
# opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
opt = paddle.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameters=model.parameters())# 启动训练过程
PM.train_pm(model, opt) # 输入数据形状是 [N, 3, H, W]
# 这里用np.random创建一个随机数组作为输入数据
x = np.random.randn(*[10,3,224,224])
x = x.astype('float32')
# 创建CNN类的实例,指定模型名称和分类的类别数目
#model = VGG(1)
#
PM.DisplayCNN_layers(model,x)
#
PM.py源代码
#数据处理
#==============================================================================================
import cv2
import random
import numpy as np
import os
from paddle.nn import Conv2D, MaxPool2D, Linear, Dropout
## 组网
import paddle.nn.functional as F# 对读入的图像数据进行预处理
def transform_img(img):# 将图片尺寸缩放道 224x224img = cv2.resize(img, (224, 224))# 读入的图像数据格式是[H, W, C]# 使用转置操作将其变成[C, H, W]img = np.transpose(img, (2,0,1))img = img.astype('float32')# 将数据范围调整到[-1.0, 1.0]之间img = img / 255.img = img * 2.0 - 1.0return img# 定义训练集数据读取器
def data_loader(datadir, batch_size=10, mode = 'train'):# 将datadir目录下的文件列出来,每条文件都要读入filenames = os.listdir(datadir)def reader():if mode == 'train':# 训练时随机打乱数据顺序random.shuffle(filenames)batch_imgs = []batch_labels = []for name in filenames:filepath = os.path.join(datadir, name)img = cv2.imread(filepath)img = transform_img(img)if name[0] == 'H' or name[0] == 'N':# H开头的文件名表示高度近似,N开头的文件名表示正常视力# 高度近视和正常视力的样本,都不是病理性的,属于负样本,标签为0label = 0elif name[0] == 'P':# P开头的是病理性近视,属于正样本,标签为1label = 1else:raise('Not excepted file name')# 每读取一个样本的数据,就将其放入数据列表中batch_imgs.append(img)batch_labels.append(label)if len(batch_imgs) == batch_size:# 当数据列表的长度等于batch_size的时候,# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出imgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arraybatch_imgs = []batch_labels = []if len(batch_imgs) > 0:# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batchimgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arrayreturn reader# 定义验证集数据读取器
def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'):# 训练集读取时通过文件名来确定样本标签,验证集则通过csvfile来读取每个图片对应的标签# 请查看解压后的验证集标签数据,观察csvfile文件里面所包含的内容# csvfile文件所包含的内容格式如下,每一行代表一个样本,# 其中第一列是图片id,第二列是文件名,第三列是图片标签,# 第四列和第五列是Fovea的坐标,与分类任务无关# ID,imgName,Label,Fovea_X,Fovea_Y# 1,V0001.jpg,0,1157.74,1019.87# 2,V0002.jpg,1,1285.82,1080.47# 打开包含验证集标签的csvfile,并读入其中的内容filelists = open(csvfile).readlines()def reader():batch_imgs = []batch_labels = []for line in filelists[1:]:line = line.strip().split(',')name = line[1]label = int(line[2])# 根据图片文件名加载图片,并对图像数据作预处理filepath = os.path.join(datadir, name)img = cv2.imread(filepath)img = transform_img(img)# 每读取一个样本的数据,就将其放入数据列表中batch_imgs.append(img)batch_labels.append(label)if len(batch_imgs) == batch_size:# 当数据列表的长度等于batch_size的时候,# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出imgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arraybatch_imgs = []batch_labels = []if len(batch_imgs) > 0:# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batchimgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arrayreturn reader# -*- coding: utf-8 -*-
# 识别眼疾图片
import os
import random
import paddle
import numpy as npDATADIR = './PM/palm/PALM-Training400/PALM-Training400'
DATADIR2 = './PM/palm/PALM-Validation400'
CSVFILE = './PM/labels.csv'
# 设置迭代轮数
EPOCH_NUM = 5# 定义训练过程
def train_pm(model, optimizer):# 开启0号GPU训练use_gpu = Truepaddle.device.set_device('gpu:0') if use_gpu else paddle.device.set_device('cpu')print('start training ... ')model.train()# 定义数据读取器,训练数据读取器和验证数据读取器train_loader = data_loader(DATADIR, batch_size=10, mode='train')valid_loader = valid_data_loader(DATADIR2, CSVFILE)for epoch in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):x_data, y_data = dataimg = paddle.to_tensor(x_data)label = paddle.to_tensor(y_data)#print('image.shape=',img.shape)# 运行模型前向计算,得到预测值logits = model(img)loss = F.binary_cross_entropy_with_logits(logits, label)avg_loss = paddle.mean(loss)if batch_id % 20 == 0:print("epoch: {}, batch_id: {}, loss is: {:.4f}".format(epoch, batch_id, float(avg_loss.numpy())))# 反向传播,更新权重,清除梯度avg_loss.backward()optimizer.step()optimizer.clear_grad()model.eval()accuracies = []losses = []for batch_id, data in enumerate(valid_loader()):x_data, y_data = dataimg = paddle.to_tensor(x_data)label = paddle.to_tensor(y_data)# 运行模型前向计算,得到预测值logits = model(img)# 二分类,sigmoid计算后的结果以0.5为阈值分两个类别# 计算sigmoid后的预测概率,进行loss计算pred = F.sigmoid(logits)loss = F.binary_cross_entropy_with_logits(logits, label)# 计算预测概率小于0.5的类别pred2 = pred * (-1.0) + 1.0# 得到两个类别的预测概率,并沿第一个维度级联pred = paddle.concat([pred2, pred], axis=1)acc = paddle.metric.accuracy(pred, paddle.cast(label, dtype='int64'))accuracies.append(acc.numpy())losses.append(loss.numpy())print("[validation] accuracy/loss: {:.4f}/{:.4f}".format(np.mean(accuracies), np.mean(losses)))model.train()paddle.save(model.state_dict(), 'palm.pdparams')paddle.save(optimizer.state_dict(), 'palm.pdopt')
# 定义评估过程
def evaluation(model, params_file_path):# 开启0号GPU预估use_gpu = Truepaddle.device.set_device('gpu:0') if use_gpu else paddle.device.set_device('cpu')print('start evaluation .......')#加载模型参数model_state_dict = paddle.load(params_file_path)model.load_dict(model_state_dict)model.eval()eval_loader = data_loader(DATADIR, batch_size=10, mode='eval')acc_set = []avg_loss_set = []for batch_id, data in enumerate(eval_loader()):x_data, y_data = dataimg = paddle.to_tensor(x_data)label = paddle.to_tensor(y_data)y_data = y_data.astype(np.int64)label_64 = paddle.to_tensor(y_data)# 计算预测和精度prediction, acc = model(img, label_64)# 计算损失函数值loss = F.binary_cross_entropy_with_logits(prediction, label)avg_loss = paddle.mean(loss)acc_set.append(float(acc.numpy()))avg_loss_set.append(float(avg_loss.numpy()))# 求平均精度acc_val_mean = np.array(acc_set).mean()avg_loss_val_mean = np.array(avg_loss_set).mean()print('loss={:.4f}, acc={:.4f}'.format(avg_loss_val_mean, acc_val_mean))
#==============================================================================================
#定义显示CNN模型参数结构
#======================================================
def DisplayCNN_layers(model,x):# 通过调用CNN从基类继承的sublayers()函数,# 查看CNN中所包含的子层print(model.sublayers())print(x.shape)x = paddle.to_tensor(x)print(x.shape)for item in model.sublayers():# item是CNN类中的一个子层# 查看经过子层之后的输出数据形状try:x = item(x)except:x = paddle.reshape(x, [x.shape[0], -1])x = item(x)if len(item.parameters())==2:# 查看卷积和全连接层的数据和参数的形状,# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数bprint(item.full_name(), x.shape, item.parameters()[0].shape, item.parameters()[1].shape)else:# 池化层没有参数print(item.full_name(), x.shape)
#====================================================== 相关文章:
VGG卷积神经网络-笔记
VGG卷积神经网络-笔记 VGG是当前最流行的CNN模型之一, 2014年由Simonyan和Zisserman提出, 其命名来源于论文作者所在的实验室Visual Geometry Group。 测试结果为: 通过运行结果可以发现,在眼疾筛查数据集iChallenge-PM上使用VGG…...

Python爬虫如何实现IP代理池搭建
大家好,作为一名IP代理产品供应商,我知道很多人在使用Python爬虫时遇到了一些麻烦。有时候,我们的爬虫在爬取过程中会被目标网站识别并封禁IP,导致我们的爬取任务受阻。今天我要分享的就是如何搭建一个高效稳定的IP代理池…...

单例模式:保证一个类只有一个实例
单例模式:保证一个类只有一个实例 什么是单例模式? 在软件开发中,有些类只需要一个实例,比如数据库连接池、线程池等。单例模式就是一种设计模式,用于确保一个类只有一个实例,并提供一个全局访问点。 实…...
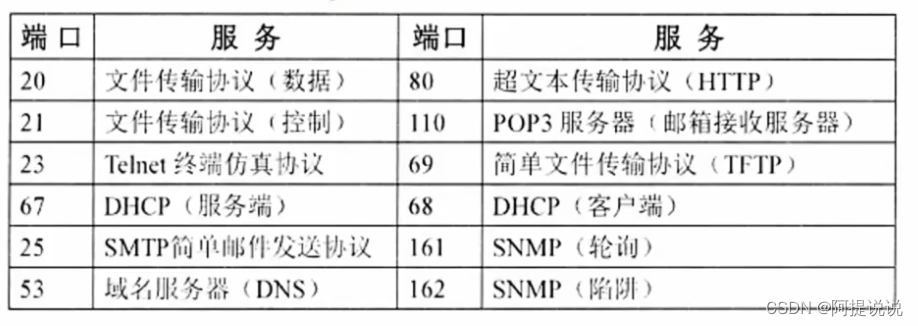
【新版系统架构补充】-七层模型
网络功能和分类 计算网络的功能 :数据通信、资源共享、管理集中化、实现分布式处理、负载均衡 网络性能指标:速率、带宽(频带宽度或传送线路速率)、吞吐量、时延、往返时间、利用率 网络非性能指标:费用、质量、标准化…...

第2章 C语言概述
本章介绍以下内容: 运算符: 函数:main()、printf() 编写一个简单的C程序 创建整型变量,为其赋值并在屏幕上显示其值 换行字符 如何在程序中写注释,创建包含多个函数的程序,发现程序的错误 什么是关键字 C程…...
)
vscode vue3开发常用插件(附Prettier格式化配置)
必不可少插件(名称可能不全): 1、Chinese (Simplified) (简体中文) Language 2、Prettier - Code formatter 3、Vue 3 Snippets 4、Vue Language Features (Volar) 可选插件: 5、Auto Close Tag 6、Vue Theme Prettier格式化配置: 按ctr…...

【微信小程序】van-uploader实现文件上传
使用van-uploader和wx.uploadFile实现文件上传,后端使用ThinkPHP。 1、前端代码 json:引入van-uploader {"usingComponents": {"van-uploader": "vant/weapp/uploader/index"} }wxml:deletedFile是删除文件函…...

人工智能在计算机视觉中的应用与挑战
引言 计算机视觉是人工智能领域的一个重要分支,旨在让计算机能够像人一样理解和解释视觉信息,实现图像和视频的自动识别、理解和分析。计算机视觉技术已经在许多领域产生了深远的影响,如人脸识别、自动驾驶、医学影像分析等。本篇博客将深入…...
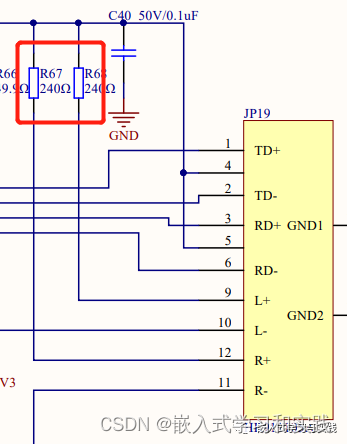
以太网接口指示灯状态分析和电路设计
一、RJ45以太网连接器介绍 以带网络隔离变压器的RJ45接头为例,如HR911105A,其技术参数如下 原理框图 指示灯部分 二、PHY芯片 phy芯片以DP83848CVV/NOPB为例,查看数据手册。引脚26,引脚27和引脚28和LED灯相关,如下截…...
Redis的基础
一、进入redis 内部 / 关闭 # 方式一: // 进入redis redis-cli // 有密码输入密码 :auth [username] password auth 123456 # 方式二: // 进入redis 并且输入密码 redis-cli -a 123456// 如果在docker 里面的则可以 docker exec -it redis…...

LeetCode 626. 换座位
题目链接:LeetCode 626. 换座位 题目描述 表名:Seat 编写SQL查询来交换每两个连续的学生的座位号。如果学生的数量是奇数,则最后一个学生的id不交换。 按 id 升序 返回结果表。 查询结果格式如下所示。 示例1: 题目分析 如…...
华为、阿里巴巴、字节跳动 100+ Python 面试问题总结(六)
系列文章目录 个人简介:机电专业在读研究生,CSDN内容合伙人,博主个人首页 Python面试专栏:《Python面试》此专栏面向准备面试的2024届毕业生。欢迎阅读,一起进步!🌟🌟🌟 …...

hash 模式和 history 模式的实现原理
hash 模式和 history 模式的实现原理: #后面的 hash 值的变化不会导致浏览器向服务器发出请求,浏览器不发出请求,就不会刷新页面。通过监听 hashchange 事件的变化可以知道 hash 值发生了哪些变化,然后根据 hash 值的变化来实现更…...

并发编程Part 2
1. JMM 问题:请你谈谈你对volatile的理解? volitile 是 Java 虚拟机提供的一种轻量级的同步机制 ,三大特性: 保证可见性 不保证原子性 禁止指令重排 线程之间如何通信? 通信是指线程之间以如何来交换信息。一般线程之间的通信…...

springboot异步多线程的实现
1、配置线程池相关参数 package com.xxx.test.config;import lombok.extern.slf4j.Slf4j; import org.springframework.aop.interceptor.AsyncUncaughtExceptionHandler; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation…...
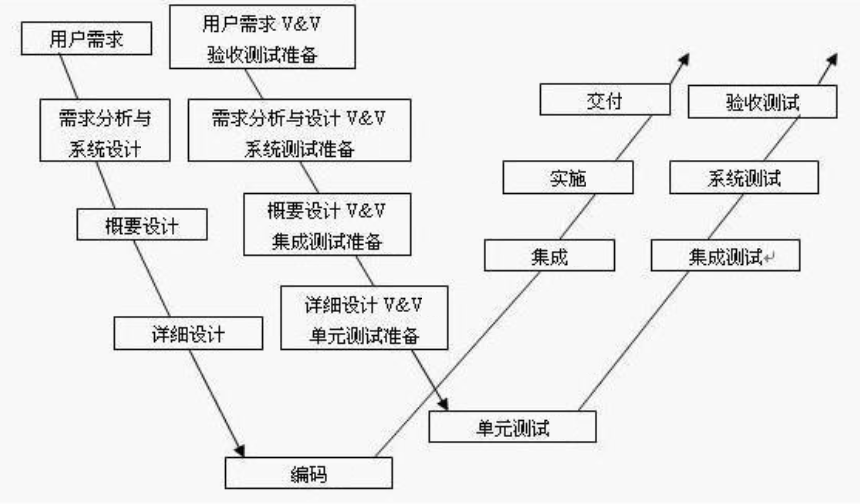
测试相关基础概念与常见开发模型
目录 1. 什么是需求 1.1 需求的定义 1.2 为什么有需求?为什么需求对软件测试人员如此重要? 1.3 测试人员眼里的需求(重要) 1.4 如何深入了解需求 2. 测试用例 2.1 什么是测试用例 2.2 为什么有测试用例 3. 什么是BUG 3.1 BUG定义 3.2 如何描述一个BUG 3.3 如何定义bug的级别 …...

MySQL安装详细教程!!!
安装之前,先卸载你之前安装过的数据库程序,否则会造成端口号占用的情况。 1.首先下载MySQL:MySQL :: Download MySQL Community Server(下载路径) 2.下载版本不一样,安装方法略有不同;(版本5的安装基本一致,…...

前端下载文化部几种方法(excel,zip,html,markdown、图片等等)和导出 zip 压缩包
文章目录 1、location.href2、location.href3、a标签4、请求后端的方式5、文件下载的方式6、Blob和Base647、下载附件方法(excel,zip,html,markdown)8、封装下载函数9、导出 zip 压缩包相关方法(流方式) 总结 1、location.href //get请求 window.location.href url;2、locati…...
)
铠甲网络面试(部分)
如何用Redis实现分布式锁的?如果设置的超时时间到了,但占有锁的任务还未完成,怎么办?答案:定时任务进行检测与续约,具体参考 本博----《专题三分布式系统》之《第三章 集中式缓存Redis》之 《第三节 Redis底…...

elasticsearch 将时间类型为时间戳保存格式的时间字段格式化返回
dsl查询用法如下: GET /your_index/_search {"_source": {"includes": ["timestamp", // Include the timestamp field in the search results// Other fields you want to include],"excludes": []},"query": …...

DwarFS库开发指南:如何集成reader、writer和extractor API
DwarFS库开发指南:如何集成reader、writer和extractor API 【免费下载链接】dwarfs A fast high-compression read-only file system for Linux, FreeBSD, macOS and Windows 项目地址: https://gitcode.com/gh_mirrors/dw/dwarfs DwarFS是一款适用于Linux、…...

org.openpnp.vision.pipeline.stages.DetectFixedCirclesHough
文章目录org.openpnp.vision.pipeline.stages.DetectFixedCirclesHough功能参数固定参数(在 XML 中配置)动态参数(必须通过 pipeline.setProperty() 预先设置)例子效果ENDorg.openpnp.vision.pipeline.stages.DetectFixedCirclesH…...

报价单外发失控:商业机密是怎么从邮件里流出去的
报价单发出去三天后,老板让我查一下那家客户——说采购在问能不能再降三个点。 我心里咯噔一下。 那份报价单我亲手发的,PDF格式,对方说"收到啦谢谢",然后就没有然后了。结果现在采购开口就是三个点,明显是知…...
)
从期末考题到实战:聊聊计算机视觉在农业里的那些‘接地气’应用(附霍夫变换、RANSAC代码)
计算机视觉如何重塑现代农业:从算法原理到田间代码实践 当无人机掠过郁郁葱葱的苹果园,摄像头捕捉到的不仅是美丽的田园风光,更是数以万计待分析的图像数据点。这些看似普通的果园巡检画面,背后隐藏着霍夫变换对果梗的精准定位、R…...

终极指南:PyPortfolioOpt离散分配算法如何将理论权重转化为实际持仓
终极指南:PyPortfolioOpt离散分配算法如何将理论权重转化为实际持仓 【免费下载链接】PyPortfolioOpt Financial portfolio optimisation in python, including classical efficient frontier, Black-Litterman, Hierarchical Risk Parity 项目地址: https://gitc…...

通义千问2.5-7B低成本上线:共享GPU资源部署案例
通义千问2.5-7B低成本上线:共享GPU资源部署案例 想体验最新最强的开源大模型,但被动辄几十GB的显存需求和昂贵的专业显卡劝退?这可能是很多开发者和创业团队面临的现实困境。今天,我们就来分享一个极具性价比的解决方案ÿ…...

爱毕业aibiye及其他六家专业辅导团队,凭借高效的在线服务在国内论文指导市场占据重要地位
核心工具对比速览 工具名称 核心优势 适用场景 降重效果 处理速度 aibiye 专业术语保留度高 理工科论文 40%→7% 快速 aicheck 逻辑结构保持好 社科类论文 38%→6% 极快 askpaper 上下文连贯性强 人文类论文 45%→8% 中等 秒篇 多语种支持 外语论文 42%…...

RAGflow核心机制解析及普通RAG系统优化方案
前言在RAG(检索增强生成)技术落地过程中,很多开发者都会遇到一个共性问题:检索时机不合理、判断逻辑僵硬,导致要么检索冗余浪费资源,要么漏检影响回答准确性。这也是当前普通RAG系统的普遍痛点,…...
 在 MySQL 与 Hive 中的高效应用)
从实战出发:掌握 dense_rank() 在 MySQL 与 Hive 中的高效应用
1. 为什么你需要掌握dense_rank()函数 记得去年我接手一个电商平台的用户活跃度分析项目,当时需要给平台上的百万用户做活跃度排名。最初我用的是简单的order by配合limit,结果发现当大量用户活跃度相同时,排名结果完全不符合业务需求——第1…...

全文降AI的好处有哪些?推荐3款支持全文处理的降AI工具
全文降AI的好处有哪些?推荐3款支持全文处理的降AI工具 2026年的毕业季,AI检测已经不是"可能查"而是"一定查"。从知网到维普,从万方到大雅,几乎所有主流检测平台都上线了AIGC检测功能。面对这种局面࿰…...