【Python机器学习】实验08 决策树
文章目录
- 决策树
- 1 创建数据
- 2 定义香农信息熵
- 3 条件熵
- 4 信息增益
- 5 计算所有特征的信息增益,选择最优最大信息增益的特征返回
- 6 利用ID3算法生成决策树
- 7 利用数据构造一颗决策树
- Scikit-learn实例
- 决策树分类
- 决策树回归
- Scikit-learn 的决策树参数
- 决策树调参
- 实验1 通过sklearn来做breast_cancer数据集的决策树分类器训练
- 准备数据
- 训练模型
- 测试模型
- 实验2 构造下面的数据,并调用前面手写代码实现决策树分类器
- 采用下面的样本进行测试
决策树
1.分类决策树模型是表示基于特征对实例进行分类的树形结构。决策树可以转换成一个if-then规则的集合,也可以看作是定义在特征空间划分上的类的条件概率分布。
2.决策树学习旨在构建一个与训练数据拟合很好,并且复杂度小的决策树。因为从可能的决策树中直接选取最优决策树是NP完全问题。现实中采用启发式方法学习次优的决策树。
决策树学习算法包括3部分:特征选择、树的生成和树的剪枝。常用的算法有ID3、C4.5和CART。
3.特征选择的目的在于选取对训练数据能够分类的特征。特征选择的关键是其准则。常用的准则如下:
(1)样本集合 D D D对特征 A A A的信息增益(ID3)
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D, A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
H ( D ) = − ∑ k = 1 K ∣ C k ∣ ∣ D ∣ log 2 ∣ C k ∣ ∣ D ∣ H(D)=-\sum_{k=1}^{K} \frac{\left|C_{k}\right|}{|D|} \log _{2} \frac{\left|C_{k}\right|}{|D|} H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣
H ( D ∣ A ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ H ( D i ) H(D | A)=\sum_{i=1}^{n} \frac{\left|D_{i}\right|}{|D|} H\left(D_{i}\right) H(D∣A)=i=1∑n∣D∣∣Di∣H(Di)
其中, H ( D ) H(D) H(D)是数据集 D D D的熵, H ( D i ) H(D_i) H(Di)是数据集 D i D_i Di的熵, H ( D ∣ A ) H(D|A) H(D∣A)是数据集 D D D对特征 A A A的条件熵。 D i D_i Di是 D D D中特征 A A A取第 i i i个值的样本子集, C k C_k Ck是 D D D中属于第 k k k类的样本子集。 n n n是特征 A A A取 值的个数, K K K是类的个数。
(2)样本集合 D D D对特征 A A A的信息增益比(C4.5)
g R ( D , A ) = g ( D , A ) H ( D ) g_{R}(D, A)=\frac{g(D, A)}{H(D)} gR(D,A)=H(D)g(D,A)
其中, g ( D , A ) g(D,A) g(D,A)是信息增益, H ( D ) H(D) H(D)是数据集 D D D的熵。
(3)样本集合 D D D的基尼指数(CART)
Gini ( D ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 \operatorname{Gini}(D)=1-\sum_{k=1}^{K}\left(\frac{\left|C_{k}\right|}{|D|}\right)^{2} Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
特征 A A A条件下集合 D D D的基尼指数:
Gini ( D , A ) = ∣ D 1 ∣ ∣ D ∣ Gini ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ Gini ( D 2 ) \operatorname{Gini}(D, A)=\frac{\left|D_{1}\right|}{|D|} \operatorname{Gini}\left(D_{1}\right)+\frac{\left|D_{2}\right|}{|D|} \operatorname{Gini}\left(D_{2}\right) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
4.决策树的生成。通常使用信息增益最大、信息增益比最大或基尼指数最小作为特征选择的准则。决策树的生成往往通过计算信息增益或其他指标,从根结点开始,递归地产生决策树。这相当于用信息增益或其他准则不断地选取局部最优的特征,或将训练集分割为能够基本正确分类的子集。
5.决策树的剪枝。由于生成的决策树存在过拟合问题,需要对它进行剪枝,以简化学到的决策树。决策树的剪枝,往往从已生成的树上剪掉一些叶结点或叶结点以上的子树,并将其父结点或根结点作为新的叶结点,从而简化生成的决策树。
import numpy as np
import pandas as pd
import math
from math import log
1 创建数据
def create_data():datasets = [['青年', '否', '否', '一般', '否'],['青年', '否', '否', '好', '否'],['青年', '是', '否', '好', '是'],['青年', '是', '是', '一般', '是'],['青年', '否', '否', '一般', '否'],['中年', '否', '否', '一般', '否'],['中年', '否', '否', '好', '否'],['中年', '是', '是', '好', '是'],['中年', '否', '是', '非常好', '是'],['中年', '否', '是', '非常好', '是'],['老年', '否', '是', '非常好', '是'],['老年', '否', '是', '好', '是'],['老年', '是', '否', '好', '是'],['老年', '是', '否', '非常好', '是'],['老年', '否', '否', '一般', '否'],]labels = [u'年龄', u'有工作', u'有自己的房子', u'信贷情况', u'类别']# 返回数据集和每个维度的名称return datasets, labels
datasets, labels = create_data()
train_data = pd.DataFrame(datasets, columns=labels)
train_data
| 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 | |
|---|---|---|---|---|---|
| 0 | 青年 | 否 | 否 | 一般 | 否 |
| 1 | 青年 | 否 | 否 | 好 | 否 |
| 2 | 青年 | 是 | 否 | 好 | 是 |
| 3 | 青年 | 是 | 是 | 一般 | 是 |
| 4 | 青年 | 否 | 否 | 一般 | 否 |
| 5 | 中年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 好 | 否 |
| 7 | 中年 | 是 | 是 | 好 | 是 |
| 8 | 中年 | 否 | 是 | 非常好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 老年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 好 | 是 |
| 12 | 老年 | 是 | 否 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 非常好 | 是 |
| 14 | 老年 | 否 | 否 | 一般 | 否 |
2 定义香农信息熵
def calc_ent(datasets):data_length = len(datasets)label_count = {}for i in range(data_length):label = datasets[i][-1]if label not in label_count:label_count[label] = 0label_count[label] += 1ent = -sum([(p / data_length) * log(p / data_length, 2)for p in label_count.values()])return ent
3 条件熵
def cond_ent(datasets, axis=0):data_length = len(datasets)feature_sets = {}for i in range(data_length):feature = datasets[i][axis]if feature not in feature_sets:feature_sets[feature] = []feature_sets[feature].append(datasets[i])cond_ent = sum([(len(p) / data_length) * calc_ent(p)for p in feature_sets.values()])return cond_ent
calc_ent(datasets)
0.9709505944546686
4 信息增益
def info_gain(ent, cond_ent):return ent - cond_ent
5 计算所有特征的信息增益,选择最优最大信息增益的特征返回
def info_gain_train(datasets):count = len(datasets[0]) - 1ent = calc_ent(datasets)best_feature = []for c in range(count):c_info_gain = info_gain(ent, cond_ent(datasets, axis=c))best_feature.append((c, c_info_gain))print('特征({}) 的信息增益为: {:.3f}'.format(labels[c], c_info_gain))# 比较大小best_ = max(best_feature, key=lambda x: x[-1])return '特征({})的信息增益最大,选择为根节点特征'.format(labels[best_[0]])
info_gain_train(np.array(datasets))
特征(年龄) 的信息增益为: 0.083
特征(有工作) 的信息增益为: 0.324
特征(有自己的房子) 的信息增益为: 0.420
特征(信贷情况) 的信息增益为: 0.363'特征(有自己的房子)的信息增益最大,选择为根节点特征'
6 利用ID3算法生成决策树
# 定义节点类 二叉树
class Node:def __init__(self, root=True, label=None, feature_name=None, feature=None):self.root = rootself.label = labelself.feature_name = feature_nameself.feature = featureself.tree = {}self.result = {'label:': self.label,'feature': self.feature,'tree': self.tree}def __repr__(self):return '{}'.format(self.result)def add_node(self, val, node):self.tree[val] = nodedef predict(self, features):if self.root is True:return self.labelcurrent_tree=self.tree[features[self.feature]]features.pop(self.feature)return current_tree.predict(features)class DTree:def __init__(self, epsilon=0.1):self.epsilon = epsilonself._tree = {}# 熵@staticmethoddef calc_ent(datasets):data_length = len(datasets)label_count = {}for i in range(data_length):label = datasets[i][-1]if label not in label_count:label_count[label] = 0label_count[label] += 1ent = -sum([(p / data_length) * log(p / data_length, 2) for p in label_count.values()])return ent# 经验条件熵def cond_ent(self, datasets, axis=0):data_length = len(datasets)feature_sets = {}for i in range(data_length):feature = datasets[i][axis]if feature not in feature_sets:feature_sets[feature] = []feature_sets[feature].append(datasets[i])cond_ent = sum([(len(p) / data_length) * self.calc_ent(p) for p in feature_sets.values()])return cond_ent# 信息增益@staticmethoddef info_gain(ent, cond_ent):return ent - cond_entdef info_gain_train(self, datasets):count = len(datasets[0]) - 1ent = self.calc_ent(datasets)best_feature = []for c in range(count):c_info_gain = self.info_gain(ent, self.cond_ent(datasets, axis=c))best_feature.append((c, c_info_gain))# 比较大小best_ = max(best_feature, key=lambda x: x[-1])return best_def train(self, train_data):"""input:数据集D(DataFrame格式),特征集A,阈值etaoutput:决策树T"""_, y_train, features = train_data.iloc[:,:-1], train_data.iloc[:,-1], train_data.columns[:-1]# 1,若D中实例属于同一类Ck,则T为单节点树,并将类Ck作为结点的类标记,返回Tif len(y_train.value_counts()) == 1:return Node(root=True, label=y_train.iloc[0])# 2, 若A为空,则T为单节点树,将D中实例树最大的类Ck作为该节点的类标记,返回Tif len(features) == 0:return Node(root=True,label=y_train.value_counts().sort_values(ascending=False).index[0])# 3,计算最大信息增益 同5.1,Ag为信息增益最大的特征max_feature, max_info_gain = self.info_gain_train(np.array(train_data))max_feature_name = features[max_feature]# 4,Ag的信息增益小于阈值eta,则置T为单节点树,并将D中是实例数最大的类Ck作为该节点的类标记,返回Tif max_info_gain < self.epsilon:return Node(root=True,label=y_train.value_counts().sort_values(ascending=False).index[0])# 5,构建Ag子集node_tree = Node(root=False, feature_name=max_feature_name, feature=max_feature)feature_list = train_data[max_feature_name].value_counts().indexfor f in feature_list:sub_train_df = train_data.loc[train_data[max_feature_name] == f].drop([max_feature_name], axis=1)# 6, 递归生成树sub_tree = self.train(sub_train_df)node_tree.add_node(f, sub_tree)return node_treedef fit(self, train_data):self._tree = self.train(train_data)return self._treedef predict(self, X_test):return self._tree.predict(X_test)
7 利用数据构造一颗决策树
datasets, labels = create_data()
data_df = pd.DataFrame(datasets, columns=labels)
dt = DTree()
tree = dt.fit(data_df)
data_df
| 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 | |
|---|---|---|---|---|---|
| 0 | 青年 | 否 | 否 | 一般 | 否 |
| 1 | 青年 | 否 | 否 | 好 | 否 |
| 2 | 青年 | 是 | 否 | 好 | 是 |
| 3 | 青年 | 是 | 是 | 一般 | 是 |
| 4 | 青年 | 否 | 否 | 一般 | 否 |
| 5 | 中年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 好 | 否 |
| 7 | 中年 | 是 | 是 | 好 | 是 |
| 8 | 中年 | 否 | 是 | 非常好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 老年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 好 | 是 |
| 12 | 老年 | 是 | 否 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 非常好 | 是 |
| 14 | 老年 | 否 | 否 | 一般 | 否 |
tree
{'label:': None, 'feature': 2, 'tree': {'否': {'label:': None, 'feature': 1, 'tree': {'否': {'label:': '否', 'feature': None, 'tree': {}}, '是': {'label:': '是', 'feature': None, 'tree': {}}}}, '是': {'label:': '是', 'feature': None, 'tree': {}}}}有无房子否 是 ↓ ↓有无工作 是否 是↓ ↓否 是
tree.predict(['老年', '否', '否', '一般'])
'否'
datasets
[['青年', '否', '否', '一般', '否'],['青年', '否', '否', '好', '否'],['青年', '是', '否', '好', '是'],['青年', '是', '是', '一般', '是'],['青年', '否', '否', '一般', '否'],['中年', '否', '否', '一般', '否'],['中年', '否', '否', '好', '否'],['中年', '是', '是', '好', '是'],['中年', '否', '是', '非常好', '是'],['中年', '否', '是', '非常好', '是'],['老年', '否', '是', '非常好', '是'],['老年', '否', '是', '好', '是'],['老年', '是', '否', '好', '是'],['老年', '是', '否', '非常好', '是'],['老年', '否', '否', '一般', '否']]
labels
['年龄', '有工作', '有自己的房子', '信贷情况', '类别']
dt.predict(['老年', '否', '否', '一般'])
'否'
Scikit-learn实例
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
使用Iris数据集,我们可以构建如下树:
# data
def create_data():iris = load_iris()df = pd.DataFrame(iris.data, columns=iris.feature_names)df['label'] = iris.targetdf.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']data = np.array(df.iloc[:100, [0, 1, -1]])# print(data)return data[:, :2], data[:, -1],iris.feature_names[0:2]X, y,feature_name= create_data()
X, y,feature_name
(array([[5.1, 3.5],[4.9, 3. ],[4.7, 3.2],[4.6, 3.1],[5. , 3.6],[5.4, 3.9],[4.6, 3.4],[5. , 3.4],[4.4, 2.9],[4.9, 3.1],[5.4, 3.7],[4.8, 3.4],[4.8, 3. ],[4.3, 3. ],[5.8, 4. ],[5.7, 4.4],[5.4, 3.9],[5.1, 3.5],[5.7, 3.8],[5.1, 3.8],[5.4, 3.4],[5.1, 3.7],[4.6, 3.6],[5.1, 3.3],[4.8, 3.4],[5. , 3. ],[5. , 3.4],[5.2, 3.5],[5.2, 3.4],[4.7, 3.2],[4.8, 3.1],[5.4, 3.4],[5.2, 4.1],[5.5, 4.2],[4.9, 3.1],[5. , 3.2],[5.5, 3.5],[4.9, 3.6],[4.4, 3. ],[5.1, 3.4],[5. , 3.5],[4.5, 2.3],[4.4, 3.2],[5. , 3.5],[5.1, 3.8],[4.8, 3. ],[5.1, 3.8],[4.6, 3.2],[5.3, 3.7],[5. , 3.3],[7. , 3.2],[6.4, 3.2],[6.9, 3.1],[5.5, 2.3],[6.5, 2.8],[5.7, 2.8],[6.3, 3.3],[4.9, 2.4],[6.6, 2.9],[5.2, 2.7],[5. , 2. ],[5.9, 3. ],[6. , 2.2],[6.1, 2.9],[5.6, 2.9],[6.7, 3.1],[5.6, 3. ],[5.8, 2.7],[6.2, 2.2],[5.6, 2.5],[5.9, 3.2],[6.1, 2.8],[6.3, 2.5],[6.1, 2.8],[6.4, 2.9],[6.6, 3. ],[6.8, 2.8],[6.7, 3. ],[6. , 2.9],[5.7, 2.6],[5.5, 2.4],[5.5, 2.4],[5.8, 2.7],[6. , 2.7],[5.4, 3. ],[6. , 3.4],[6.7, 3.1],[6.3, 2.3],[5.6, 3. ],[5.5, 2.5],[5.5, 2.6],[6.1, 3. ],[5.8, 2.6],[5. , 2.3],[5.6, 2.7],[5.7, 3. ],[5.7, 2.9],[6.2, 2.9],[5.1, 2.5],[5.7, 2.8]]),array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.,1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]),['sepal length (cm)', 'sepal width (cm)'])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((70, 2), (30, 2), (70,), (30,))
决策树分类
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz
#1 导入相关包
from sklearn import tree
#2 构建一个决策树分类器模型
clf = DecisionTreeClassifier(criterion="entropy")
#3 采用数据来构建决策树
clf.fit(X_train, y_train)
#4 对决策树模型进行测试
clf.score(X_test, y_test)
0.9
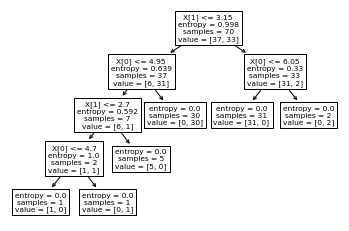
一旦经过训练,就可以用 plot_tree函数绘制树:
tree.plot_tree(clf)
[Text(0.6, 0.9, 'X[1] <= 3.15\nentropy = 0.998\nsamples = 70\nvalue = [37, 33]'),Text(0.4, 0.7, 'X[0] <= 4.95\nentropy = 0.639\nsamples = 37\nvalue = [6, 31]'),Text(0.3, 0.5, 'X[1] <= 2.7\nentropy = 0.592\nsamples = 7\nvalue = [6, 1]'),Text(0.2, 0.3, 'X[0] <= 4.7\nentropy = 1.0\nsamples = 2\nvalue = [1, 1]'),Text(0.1, 0.1, 'entropy = 0.0\nsamples = 1\nvalue = [1, 0]'),Text(0.3, 0.1, 'entropy = 0.0\nsamples = 1\nvalue = [0, 1]'),Text(0.4, 0.3, 'entropy = 0.0\nsamples = 5\nvalue = [5, 0]'),Text(0.5, 0.5, 'entropy = 0.0\nsamples = 30\nvalue = [0, 30]'),Text(0.8, 0.7, 'X[0] <= 6.05\nentropy = 0.33\nsamples = 33\nvalue = [31, 2]'),Text(0.7, 0.5, 'entropy = 0.0\nsamples = 31\nvalue = [31, 0]'),Text(0.9, 0.5, 'entropy = 0.0\nsamples = 2\nvalue = [0, 2]')]
也可以导出树
tree_pic = export_graphviz(clf, out_file="mytree.pdf")
with open('mytree.pdf') as f:dot_graph = f.read()
或者,还可以使用函数 export_text以文本格式导出树。此方法不需要安装外部库,而且更紧凑:
from sklearn.tree import export_text
r = export_text(clf)
print(r)
|--- feature_1 <= 3.15
| |--- feature_0 <= 4.95
| | |--- feature_1 <= 2.70
| | | |--- feature_0 <= 4.70
| | | | |--- class: 0.0
| | | |--- feature_0 > 4.70
| | | | |--- class: 1.0
| | |--- feature_1 > 2.70
| | | |--- class: 0.0
| |--- feature_0 > 4.95
| | |--- class: 1.0
|--- feature_1 > 3.15
| |--- feature_0 <= 6.05
| | |--- class: 0.0
| |--- feature_0 > 6.05
| | |--- class: 1.0
决策树回归
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
rng = np.random.RandomState(1)
rng
RandomState(MT19937) at 0x1AD2E576840
X = np.sort(5 * rng.rand(80, 1), axis=0)
# Create a random dataset
rng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80, 1), axis=0)
y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - rng.rand(16))
X.shape,y.shape
((80, 1), (80,))
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
X_test.shape
(500, 1)
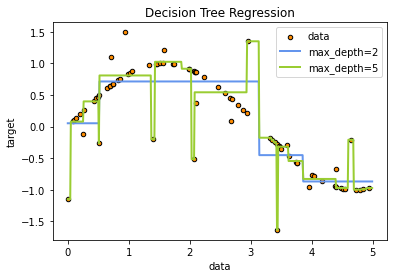
# Fit regression model
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_1.fit(X, y)
regr_2.fit(X, y)# Predict
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)# Plot the results
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black", c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
Scikit-learn 的决策树参数
DecisionTreeClassifier(criterion=“gini”,
splitter=“best”,
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.,
min_impurity_split=None,
class_weight=None,
presort=False)
参数含义:
- criterion:string, optional (default=“gini”)
(1).criterion=‘gini’,分裂节点时评价准则是Gini指数。
(2).criterion=‘entropy’,分裂节点时的评价指标是信息增益。 - max_depth:int or None, optional (default=None)。指定树的最大深度。
如果为None,表示树的深度不限。直到所有的叶子节点都是纯净的,即叶子节点
中所有的样本点都属于同一个类别。或者每个叶子节点包含的样本数小于min_samples_split。 - splitter:string, optional (default=“best”)。指定分裂节点时的策略。
(1).splitter=‘best’,表示选择最优的分裂策略。
(2).splitter=‘random’,表示选择最好的随机切分策略。 - min_samples_split:int, float, optional (default=2)。表示分裂一个内部节点需要的做少样本数。
(1).如果为整数,则min_samples_split就是最少样本数。
(2).如果为浮点数(0到1之间),则每次分裂最少样本数为ceil(min_samples_split * n_samples) - min_samples_leaf: int, float, optional (default=1)。指定每个叶子节点需要的最少样本数。
(1).如果为整数,则min_samples_split就是最少样本数。
(2).如果为浮点数(0到1之间),则每个叶子节点最少样本数为ceil(min_samples_leaf * n_samples) - min_weight_fraction_leaf:float, optional (default=0.)
指定叶子节点中样本的最小权重。 - max_features:int, float, string or None, optional (default=None).
搜寻最佳划分的时候考虑的特征数量。
(1).如果为整数,每次分裂只考虑max_features个特征。
(2).如果为浮点数(0到1之间),每次切分只考虑int(max_features * n_features)个特征。
(3).如果为’auto’或者’sqrt’,则每次切分只考虑sqrt(n_features)个特征
(4).如果为’log2’,则每次切分只考虑log2(n_features)个特征。
(5).如果为None,则每次切分考虑n_features个特征。
(6).如果已经考虑了max_features个特征,但还是没有找到一个有效的切分,那么还会继续寻找
下一个特征,直到找到一个有效的切分为止。 - random_state:int, RandomState instance or None, optional (default=None)
(1).如果为整数,则它指定了随机数生成器的种子。
(2).如果为RandomState实例,则指定了随机数生成器。
(3).如果为None,则使用默认的随机数生成器。 - max_leaf_nodes: int or None, optional (default=None)。指定了叶子节点的最大数量。
(1).如果为None,叶子节点数量不限。
(2).如果为整数,则max_depth被忽略。 - min_impurity_decrease:float, optional (default=0.)
如果节点的分裂导致不纯度的减少(分裂后样本比分裂前更加纯净)大于或等于min_impurity_decrease,则分裂该节点。
加权不纯度的减少量计算公式为:
min_impurity_decrease=N_t / N * (impurity - N_t_R / N_t * right_impurity
- N_t_L / N_t * left_impurity)
其中N是样本的总数,N_t是当前节点的样本数,N_t_L是分裂后左子节点的样本数,
N_t_R是分裂后右子节点的样本数。impurity指当前节点的基尼指数,right_impurity指
分裂后右子节点的基尼指数。left_impurity指分裂后左子节点的基尼指数。 - min_impurity_split:float
树生长过程中早停止的阈值。如果当前节点的不纯度高于阈值,节点将分裂,否则它是叶子节点。
这个参数已经被弃用。用min_impurity_decrease代替了min_impurity_split。 - class_weight:dict, list of dicts, “balanced” or None, default=None
类别权重的形式为{class_label: weight}
(1).如果没有给出每个类别的权重,则每个类别的权重都为1。
(2).如果class_weight=‘balanced’,则分类的权重与样本中每个类别出现的频率成反比。
计算公式为:n_samples / (n_classes * np.bincount(y))
(3).如果sample_weight提供了样本权重(由fit方法提供),则这些权重都会乘以sample_weight。 - presort:bool, optional (default=False)
指定是否需要提前排序数据从而加速训练中寻找最优切分的过程。设置为True时,对于大数据集
会减慢总体的训练过程;但是对于一个小数据集或者设定了最大深度的情况下,会加速训练过程。
决策树调参
# 导入库
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeRegressor
from sklearn import metrics
# 导入数据集
X = datasets.load_iris() # 以全部字典形式返回,有data,target,target_names三个键
data = X.data
target = X.target
name = X.target_names
x, y = datasets.load_iris(return_X_y=True) # 能一次性取前2个
print(x.shape, y.shape)
(150, 4) (150,)
# 数据分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state=100)
# 用GridSearchCV寻找最优参数(字典)
param = {'criterion': ['gini'],'max_depth': [30, 50, 60, 100],'min_samples_leaf': [2, 3, 5, 10],'min_impurity_decrease': [0.1, 0.2, 0.5]
}
grid = GridSearchCV(DecisionTreeClassifier(), param_grid=param, cv=6)
grid.fit(x_train, y_train)
print('最优分类器:', grid.best_params_, '最优分数:', grid.best_score_) # 得到最优的参数和分值
最优分类器: {'criterion': 'gini', 'max_depth': 50, 'min_impurity_decrease': 0.2, 'min_samples_leaf': 10} 最优分数: 0.9416666666666665
param = {'criterion': ['gini',"entropy"],'max_depth': [30, 50, 60, 100,80],'min_samples_leaf': [2, 3, 5, 10],'min_impurity_decrease': [0.1, 0.2, 0.5,0.8],"splitter":["random","best"]
}
grid=GridSearchCV(DecisionTreeClassifier(),param_grid=param,cv=5)
grid.fit(x_train,y_train)
print(grid.best_params_,grid.best_score_,grid.n_splits_)
{'criterion': 'entropy', 'max_depth': 50, 'min_impurity_decrease': 0.1, 'min_samples_leaf': 10, 'splitter': 'random'} 0.95 5
实验1 通过sklearn来做breast_cancer数据集的决策树分类器训练
准备数据
from sklearn.datasets import load_breast_cancer
bst = load_breast_cancer()
data=bst.data
bst.feature_names
array(['mean radius', 'mean texture', 'mean perimeter', 'mean area','mean smoothness', 'mean compactness', 'mean concavity','mean concave points', 'mean symmetry', 'mean fractal dimension','radius error', 'texture error', 'perimeter error', 'area error','smoothness error', 'compactness error', 'concavity error','concave points error', 'symmetry error','fractal dimension error', 'worst radius', 'worst texture','worst perimeter', 'worst area', 'worst smoothness','worst compactness', 'worst concavity', 'worst concave points','worst symmetry', 'worst fractal dimension'], dtype='<U23')
data.shape
(569, 30)
x=data[:,:2]
labels=bst.feature_names[:2]
labels
array(['mean radius', 'mean texture'], dtype='<U23')
y=bst.target
datasets=np.insert(x,x.shape[1],y,axis=1)
datasets.shape
(569, 3)
data_df = pd.DataFrame(datasets,columns=['mean radius', 'mean texture',"结果"])
data_df
| mean radius | mean texture | 结果 | |
|---|---|---|---|
| 0 | 17.99 | 10.38 | 0.0 |
| 1 | 20.57 | 17.77 | 0.0 |
| 2 | 19.69 | 21.25 | 0.0 |
| 3 | 11.42 | 20.38 | 0.0 |
| 4 | 20.29 | 14.34 | 0.0 |
| ... | ... | ... | ... |
| 564 | 21.56 | 22.39 | 0.0 |
| 565 | 20.13 | 28.25 | 0.0 |
| 566 | 16.60 | 28.08 | 0.0 |
| 567 | 20.60 | 29.33 | 0.0 |
| 568 | 7.76 | 24.54 | 1.0 |
569 rows × 3 columns
# 数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
X_train.shape,X_test.shape,y_train.shape,y_test.shape
((398, 2), (171, 2), (398,), (171,))
训练模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz
clf = DecisionTreeClassifier(criterion="entropy")
clf.fit(X_train, y_train)
DecisionTreeClassifier(criterion='entropy')
测试模型
#4 对决策树模型进行测试
clf.score(X_test, y_test)
0.8713450292397661
实验2 构造下面的数据,并调用前面手写代码实现决策树分类器
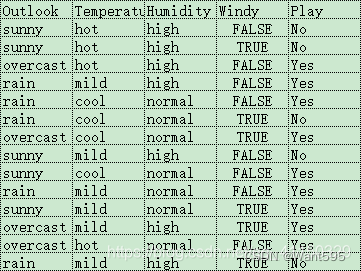
def create_demo():datasets=[['sunny','hot','high','False','No'],['sunny','hot','high','True','No'],['overcast','hot','high','False','Yes'],['rain','mild','high','False','Yes'],['rain','cool','normal','False','Yes'],['rain','cool','normal','True','No'],['overcast','cool','normal','True','Yes'],['sunny','mild','high','False','No'],['sunny','cool','normal','False','Yes'],['rain','mild','normal','True','Yes'],['sunny','mild','normal','False','Yes'],['overcast','mild','high','True','Yes'],['overcast','hot','normal','False','Yes'],['rain','mild','high','True','No']]labels=['Outlook','Temperature','Humidity','Windy','Play']return datasets,labels
datasets,labels=create_demo()
data_df = pd.DataFrame(datasets,columns=labels)
data_df
| Outlook | Temperature | Humidity | Windy | Play | |
|---|---|---|---|---|---|
| 0 | sunny | hot | high | False | No |
| 1 | sunny | hot | high | True | No |
| 2 | overcast | hot | high | False | Yes |
| 3 | rain | mild | high | False | Yes |
| 4 | rain | cool | normal | False | Yes |
| 5 | rain | cool | normal | True | No |
| 6 | overcast | cool | normal | True | Yes |
| 7 | sunny | mild | high | False | No |
| 8 | sunny | cool | normal | False | Yes |
| 9 | rain | mild | normal | True | Yes |
| 10 | sunny | mild | normal | False | Yes |
| 11 | overcast | mild | high | True | Yes |
| 12 | overcast | hot | normal | False | Yes |
| 13 | rain | mild | high | True | No |
train_data=pd.DataFrame(datasets,columns=labels)
dt = DTree()
tree = dt.fit(data_df)
tree
{'label:': None, 'feature': 0, 'tree': {'sunny': {'label:': None, 'feature': 1, 'tree': {'high': {'label:': 'No', 'feature': None, 'tree': {}}, 'normal': {'label:': 'Yes', 'feature': None, 'tree': {}}}}, 'rain': {'label:': None, 'feature': 2, 'tree': {'True': {'label:': None, 'feature': 0, 'tree': {'mild': {'label:': None, 'feature': 0, 'tree': {'normal': {'label:': 'Yes', 'feature': None, 'tree': {}}, 'high': {'label:': 'No', 'feature': None, 'tree': {}}}}, 'cool': {'label:': 'No', 'feature': None, 'tree': {}}}}, 'False': {'label:': 'Yes', 'feature': None, 'tree': {}}}}, 'overcast': {'label:': 'Yes', 'feature': None, 'tree': {}}}}Outlooksunny rain overcast↓ ↓ ↓Humidity Windy Yeshigh normal True False↓ ↓ ↓ ↓No Yes Temperature Yesmild cool↓ ↓Humidity Nonormal high ↓ ↓Yes No
采用下面的样本进行测试
test=["sunny","hot","normal","True"]
tree.predict(test)
'Yes'
相关文章:
【Python机器学习】实验08 决策树
文章目录 决策树1 创建数据2 定义香农信息熵3 条件熵4 信息增益5 计算所有特征的信息增益,选择最优最大信息增益的特征返回6 利用ID3算法生成决策树7 利用数据构造一颗决策树Scikit-learn实例决策树分类决策树回归Scikit-learn 的决策树参数决策树调参 实验1 通过sk…...

MySQL的innoDB存储引擎如何解决幻读的问题?
MySQL的innoDB存储引擎如何解决幻读的问题 基本情况 MySQL有四种事务隔离级别,这四种隔离级别代表当存在多个事务并发冲突时,可能出现的脏读、不可重复读、幻读的问题InnoDB 在 RR 的隔离级别下 ,解决了幻读的问题幻读是指在同一个事务中&a…...

Web3.0:重新定义互联网的未来
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! Web3.0:重新定义互联网的未来 Web3.0是指下一代互联网,也称为“分布式互联网”。相比于Web1.0和Web2.0,Web3.0具有更强的去中心化、…...

2023年还能选择前端吗?
前言 在Github2022的 Octoverse年度报告上,稳居最多使用榜首的语言可以看到是JavaScript,作为前端中最为关键的一部分,这说明即使现在,前端这一块仍然是大量的人涌进来,依然是火热,但是,一门语…...
sheetJs / xlsx-js-style 纯前端实现导出 excel 表格及自定义单元格样式
文章目录 一、安装二、创建基础工作表三、设置单元格宽度/高度/隐藏单元格四、分配数字格式五、超链接六、单元格注释七、公式八、合并单元格九、自定义单元格样式十、项目地址 一、安装 xlsx 地址:https://www.npmjs.com/package/xlsxSheetJs 地址:htt…...
Redis 报错 RedisConnectionException: Unable to connect to x.x.x.x:6379
文章目录 Redis报错类型可能解决方案 Redis报错类型 org.springframework.data.redis.connection. spingboot调用redis出错 PoolException: Could not get a resource from the pool; 连接池异常:无法从池中获取资源; nested exception is io.lettuce.core. 嵌套异常 RedisConn…...

Stable Diffusion - 真人照片的高清修复 (StableSR + GFPGAN) 最佳实践
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/132032216 GFPGAN (Generative Facial Prior GAN) 算法,用于实现真实世界的盲脸恢复的算法,利用预训练的面部 GAN…...
细讲一个 TCP 连接能发多少个 HTTP 请求(一)
一道经典的面试题是从 URL 在浏览器被被输入到页面展现的过程中发生了什么,大多数回答都是说请求响应之后 DOM 怎么被构建,被绘制出来。但是你有没有想过,收到的 HTML 如果包含几十个图片标签,这些图片是以什么方式、什么顺序、建…...

了解 CVSS:通用漏洞评分系统的应用
漏洞威胁管理至关重要,因为网络犯罪是一种持续存在的全球风险。网络犯罪分子愿意利用软件中的任何漏洞来访问网络和设备。对使用该软件的软件开发人员和组织的影响可能很严重。用户必须处理攻击的结果,例如赎金或数据盗窃,并且还可能面临法律…...
Xilinx FPGA电源设计与注意事项
1 引言 随着半导体和芯片技术的飞速发展,现在的FPGA集成了越来越多的可配置逻辑资源、各种各样的外部总线接口以及丰富的内部RAM资源,使其在国防、医疗、消费电子等领域得到了越来越广泛的应用。当采用FPGA进行设计电路时,大多数FPGA对上电的…...
前端:地图篇(一)
1、前言 在很多的出行程序中,都会使用到地图这一个功能,在实际的开发中我们也不会去开发一个自己的地图模型。如果自己开发一个地图模型,那么需要投入的成本、人力都是非常巨大的。所以我们很多网站和APP中使用的都是第三方的接口和JS&#…...
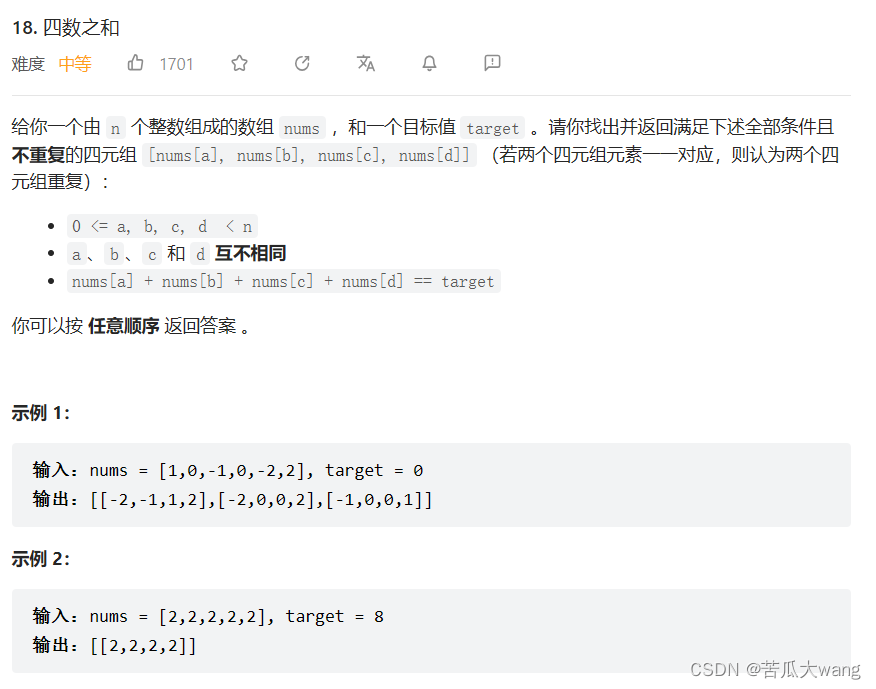
刷题笔记 day6
力扣 57 和为s的两个整数 class Solution { public:vector<int> twoSum(vector<int>& nums, int target) {vector<int> v;int i 0 , j nums.size()-1;while(i < j){if(nums[i] nums[j] > target){--j;}else if(nums[i] nums[j] < target){i…...

Drools用户手册翻译——第四章 Drools规则引擎(十一)复杂事件处理(CEP)的属性更改设置和监听器
甩锅声明:本人英语一般,翻译只是为了做个笔记,所以有翻译错误的地方,错就错了,如果你想给我纠正,就给我留言,我会改过来,如果懒得理我,就直接划过即可。 事实类型的属性…...

[数据分析与可视化] Python绘制数据地图4-MovingPandas入门指北
MovingPandas是一个基于Python和GeoPandas的开源地理时空数据处理库,用于处理移动物体的轨迹数据。它提供了一组强大的工具,可以轻松地加载、分析和可视化移动物体的轨迹。通过使用MovingPandas,用户可以轻松地处理和分析移动对象数据&#x…...

基于SpringBoot+Vue的MOBA类游戏攻略分享平台设计与实现(源码+LW+部署文档等)
博主介绍: 大家好,我是一名在Java圈混迹十余年的程序员,精通Java编程语言,同时也熟练掌握微信小程序、Python和Android等技术,能够为大家提供全方位的技术支持和交流。 我擅长在JavaWeb、SSH、SSM、SpringBoot等框架…...

Linux sed 命令详解
Linux sed(Stream Editor)是一种强大的文本处理工具,它在命令行中执行对文本进行搜索、替换和编辑等操作。sed的设计理念是按行处理文本,可以将输入文本逐行读取并应用指定的操作,然后输出结果。 sed命令有多种选项和…...
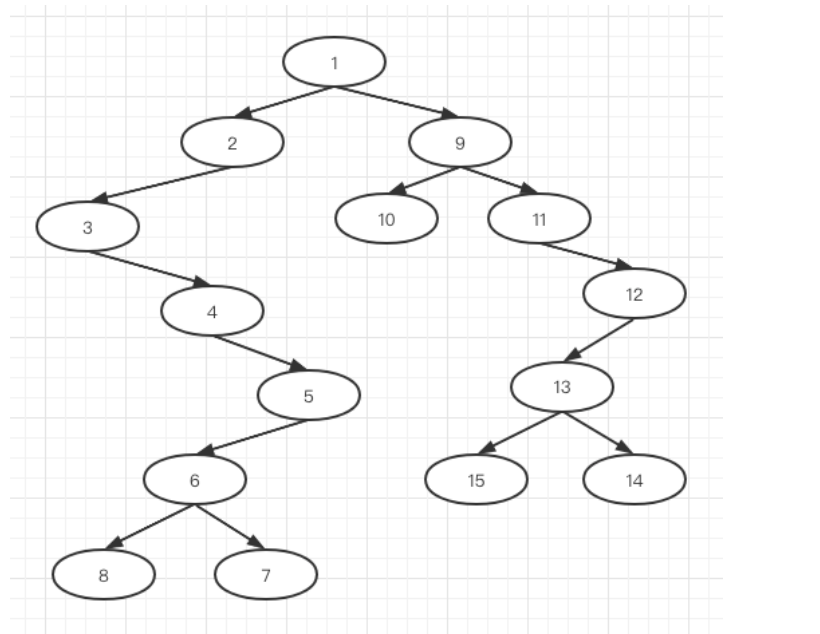
算法通关村——如何使用中序和后序来恢复一棵二叉树
通过序列构造二叉树 给出以下三个二叉树遍历的序列: (1) 前序: 1 2 3 4 5 6 8 7 9 10 11 12 13 15 14 (2) 中序: 3 4 8 6 7 5 2 1 10 9 11 15 13 14 12 (3) 后序: 8 7 6 5 4 3 2 10 15 14 13 12 11 9 1 前中序复原二叉树 所需序列 (1) 前序: 1 2 3 4 5 6 8 7 9 10 …...

TypeScript的基本类型
typescript的定义 以JavaScript为基础构建的语言是js的超集可以在任何支持js的平台执行ts 拓展了js并增加了类型Ts不能被js解析器直接执行。 TS> 编译为js 执行的还是js. js 不易于维护,而ts易于维护。 可提高项目的可维护性。 类似less、sass 完善的语法写 样…...

Docker实战-如何去访问Docker仓库?
导语 仓库在之前的分享中我们介绍过,它主要的作用就是用来存放镜像文件,又可以分为是公共的仓库和私有仓库。有点类似于Maven的中央仓库和公司内部私服。 下面我们就来介绍一下在Docker中如何去访问各种仓库。 Docker Hub 公共镜像仓库 Docker Hub 是Docker官方提供的最…...

【力扣】722. 删除注释
以下为力扣官方题解,及本人代码 722. 删除注释 题目题意示例 1示例 2提示 官方题解模拟思路与算法复杂度 本人代码Java提交结果:通过 题目 题意 给一个 C C C 程序,删除程序中的注释。这个程序 s o u r c e source source 是一个数组&a…...

从零到一:ESP-Drone开源无人机终极开发指南
从零到一:ESP-Drone开源无人机终极开发指南 【免费下载链接】esp-drone Mini Drone/Quadcopter Firmware for ESP32 and ESP32-S Series SoCs. 项目地址: https://gitcode.com/GitHub_Trending/es/esp-drone 你是否曾经梦想亲手打造一架属于自己的智能无人机…...

【StableDiffusion】从SD1.5到SDXL Turbo:模型演进如何重塑AI绘画的创作边界
1. Stable Diffusion的进化之路:从像素模糊到高清实时 第一次用SD1.5生成图片时,我盯着屏幕上512x512分辨率的模糊人脸哭笑不得——这哪是AI绘画,简直是AI抽象派。但短短两年后,当SDXL Turbo在0.5秒内吐出1024x1024的精致插画时&a…...

保姆级教程:手把手教你用Node.js + WebSocket搭建自己的WebRTC信令服务器
从零构建WebRTC信令服务器:Node.js实战指南 WebRTC技术已经彻底改变了实时通信的格局,让浏览器之间的点对点音视频传输成为可能。但很多开发者在掌握了getUserMedia和RTCPeerConnection的基本用法后,往往会卡在一个关键环节——如何让两个浏览…...

基于FPGA的蓝牙避障循迹小车设计与实现
1. 项目背景与核心功能 这个小车项目最吸引人的地方在于它把FPGA的并行处理能力和多种传感器完美结合。想象一下,你手里拿着手机用蓝牙控制小车前进,突然前方出现障碍物,小车能自动避开;或者放在地上,它能沿着黑线自动…...

2025年的大模型论文的经典性
2025 年最值得优先读的一批,基本集中在三条主线:推理与 agentic 能力、多模态统一建模、以及新一代高难度评测。([arXiv][1]) 一、推理与 Agentic 主线 1. DeepSeek-R1 这是 2025 年最有代表性的“推理模型”论文之一。它的关键点不是单纯把模型做大&…...

终极免费音频标注工具:Audio Annotator三步快速上手指南
终极免费音频标注工具:Audio Annotator三步快速上手指南 【免费下载链接】audio-annotator A JavaScript interface for annotating and labeling audio files. 项目地址: https://gitcode.com/gh_mirrors/au/audio-annotator Audio Annotator是一款基于Java…...

Ubuntu 20.04下编译Ceres 2.2.0,手把手解决CUDA路径和依赖问题
Ubuntu 20.04下Ceres 2.2.0编译实战:从CUDA路径配置到依赖问题全解析 在机器人SLAM、三维重建和计算机视觉领域,Ceres Solver作为非线性优化库的标杆工具,其GPU加速能力直接影响大规模优化问题的求解效率。本文将带您深入解决Ubuntu 20.04环境…...

AI风口已至!5大核心岗位解析:薪资高、需求旺,普通人如何抓住黄金转行窗口?
文章详细解析了AI行业五大核心岗位(AI产品经理、解决方案专家、应用工程师、算法工程师、运营/数据运营)的职责、薪资与技能要求。指出当前是入局AI的最佳时机,尤其对有产品、技术或行业背景的人士。AI产品经理需理解模型原理、掌握数据准备、…...

收藏!程序员必看:AI冲击下,如何不被大厂裁员和低薪offer淘汰?
文章指出当前IT市场因大厂降本增效、AI编程工具发展、供过于求及业务增长放缓等因素,导致程序员求职难度加大、薪资增长空间缩小。文章强调AI并未完全取代程序员,而是提高了对程序员的能力要求,如业务理解、架构能力等。建议程序员积极拥抱AI…...
)
差分隐私实战:用Python+Laplace噪声保护你的敏感数据(附完整代码)
差分隐私实战:用PythonLaplace噪声保护敏感数据 在数据驱动的时代,保护用户隐私已成为开发者不可回避的责任。想象一下,当你的应用需要分析员工薪资分布或处理医疗记录时,如何在保证数据价值的同时避免泄露个体信息?差…...