【Python】PySpark 数据计算 ⑤ ( RDD#sortBy方法 - 排序 RDD 中的元素 )
文章目录
- 一、RDD#sortBy 方法
- 1、RDD#sortBy 语法简介
- 2、RDD#sortBy 传入的函数参数分析
- 二、代码示例 - RDD#sortBy 示例
- 1、需求分析
- 2、代码示例
- 3、执行结果
一、RDD#sortBy 方法
1、RDD#sortBy 语法简介
RDD#sortBy 方法 用于 按照 指定的 键 对 RDD 中的元素进行排序 , 该方法 接受一个 函数 作为 参数 , 该函数从 RDD 中的每个元素提取 排序键 ;
根据 传入 sortBy 方法 的 函数参数 和 其它参数 , 将 RDD 中的元素按 升序 或 降序 进行排序 , 同时还可以指定 新的 RDD 对象的 分区数 ;
RDD#sortBy 语法 :
sortBy(f: (T) ⇒ U, ascending: Boolean, numPartitions: Int): RDD[T]
- 参数说明 :
- f: (T) ⇒ U 参数 : 函数 或 lambda 匿名函数 , 用于 指定 RDD 中的每个元素 的 排序键 ;
- ascending: Boolean 参数 : 排序的升降设置 , True 生序排序 , False 降序排序 ;
- numPartitions: Int 参数 : 设置 排序结果 ( 新的 RDD 对象 ) 中的 分区数 ;
- 当前没有接触到分布式 , 将该参数设置为 1 即可 , 排序完毕后是全局有序的 ;
- 返回值说明 : 返回一个新的 RDD 对象 , 其中的元素是 按照指定的 排序键 进行排序的结果 ;
2、RDD#sortBy 传入的函数参数分析
RDD#sortBy 传入的函数参数 类型为 :
(T) ⇒ U
T 是泛型 , 表示传入的参数类型可以是任意类型 ;
U 也是泛型 , 表示 函数 返回值 的类型 可以是任意类型 ;
T 类型的参数 和 U 类型的返回值 , 可以是相同的类型 , 也可以是不同的类型 ;
二、代码示例 - RDD#sortBy 示例
1、需求分析
统计 文本文件 word.txt 中出现的每个单词的个数 , 并且为每个单词出现的次数进行排序 ;
Tom Jerry
Tom Jerry Tom
Jack Jerry Jack Tom

读取文件中的内容 , 统计文件中单词的个数并排序 ;
思路 :
- 先 读取数据到 RDD 中 ,
- 然后 按照空格分割开 再展平 , 获取到每个单词 ,
- 根据上述单词列表 , 生成一个 二元元组 列表 , 列表中每个元素的 键 Key 为单词 , 值 Value 为 数字 1 ,
- 对上述 二元元组 列表 进行 聚合操作 , 相同的 键 Key 对应的 值 Value 进行相加 ;
- 将聚合后的结果的 单词出现次数作为 排序键 进行排序 , 按照升序进行排序 ;
2、代码示例
对 RDD 数据进行排序的核心代码如下 :
# 对 rdd4 中的数据进行排序
rdd5 = rdd4.sortBy(lambda element: element[1], ascending=True, numPartitions=1)
要排序的数据如下 :
[('Tom', 4), ('Jack', 2), ('Jerry', 3)]
按照上述二元元素的 第二个 元素 进行排序 , 对应的 lambda 表达式为 :
lambda element: element[1]
ascending=True 表示升序排序 ,
numPartitions=1 表示分区个数为 1 ;
排序后的结果为 :
[('Jack', 2), ('Jerry', 3), ('Tom', 4)]
代码示例 :
"""
PySpark 数据处理
"""# 导入 PySpark 相关包
from pyspark import SparkConf, SparkContext
# 为 PySpark 配置 Python 解释器
import os
os.environ['PYSPARK_PYTHON'] = "D:/001_Develop/022_Python/Python39/python.exe"# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务
# setMaster("local[*]") 表示在单机模式下 本机运行
# setAppName("hello_spark") 是给 Spark 程序起一个名字
sparkConf = SparkConf() \.setMaster("local[*]") \.setAppName("hello_spark")# 创建 PySpark 执行环境 入口对象
sparkContext = SparkContext(conf=sparkConf)# 打印 PySpark 版本号
print("PySpark 版本号 : ", sparkContext.version)# 将 文件 转为 RDD 对象
rdd = sparkContext.textFile("word.txt")
print("查看文件内容 : ", rdd.collect())# 通过 flatMap 展平文件, 先按照 空格 切割每行数据为 字符串 列表
# 然后展平数据解除嵌套
rdd2 = rdd.flatMap(lambda element: element.split(" "))
print("查看文件内容展平效果 : ", rdd2.collect())# 将 rdd 数据 的 列表中的元素 转为二元元组, 第二个元素设置为 1
rdd3 = rdd2.map(lambda element: (element, 1))
print("转为二元元组效果 : ", rdd3.collect())# 应用 reduceByKey 操作,
# 将同一个 Key 下的 Value 相加, 也就是统计 键 Key 的个数
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
print("统计单词 : ", rdd4.collect())# 对 rdd4 中的数据进行排序
rdd5 = rdd4.sortBy(lambda element: element[1], ascending=True, numPartitions=1)
print("最终统计单词并排序 : ", rdd4.collect())# 停止 PySpark 程序
sparkContext.stop()3、执行结果
执行结果 :
D:\001_Develop\022_Python\Python39\python.exe D:/002_Project/011_Python/HelloPython/Client.py
23/08/04 10:49:06 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: Could not locate Hadoop executable: D:\001_Develop\052_Hadoop\hadoop-3.3.4\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
PySpark 版本号 : 3.4.1
查看文件内容 : ['Tom Jerry', 'Tom Jerry Tom', 'Jack Jerry Jack Tom']
查看文件内容展平效果 : ['Tom', 'Jerry', 'Tom', 'Jerry', 'Tom', 'Jack', 'Jerry', 'Jack', 'Tom']
转为二元元组效果 : [('Tom', 1), ('Jerry', 1), ('Tom', 1), ('Jerry', 1), ('Tom', 1), ('Jack', 1), ('Jerry', 1), ('Jack', 1), ('Tom', 1)]
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
统计单词 : [('Tom', 4), ('Jack', 2), ('Jerry', 3)]
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
最终统计单词并排序 : [('Jack', 2), ('Jerry', 3), ('Tom', 4)]Process finished with exit code 0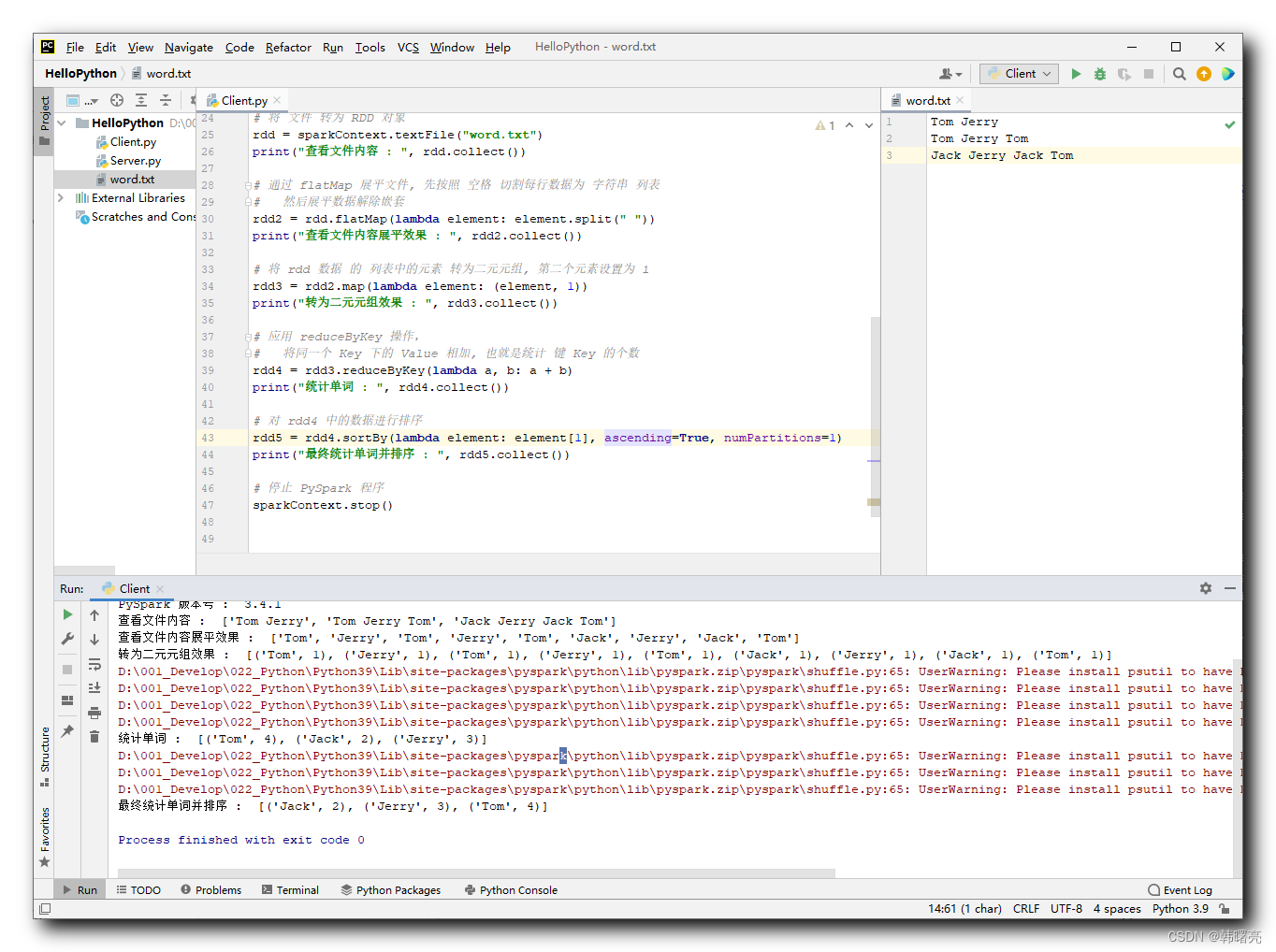
相关文章:
【Python】PySpark 数据计算 ⑤ ( RDD#sortBy方法 - 排序 RDD 中的元素 )
文章目录 一、RDD#sortBy 方法1、RDD#sortBy 语法简介2、RDD#sortBy 传入的函数参数分析 二、代码示例 - RDD#sortBy 示例1、需求分析2、代码示例3、执行结果 一、RDD#sortBy 方法 1、RDD#sortBy 语法简介 RDD#sortBy 方法 用于 按照 指定的 键 对 RDD 中的元素进行排序 , 该方…...
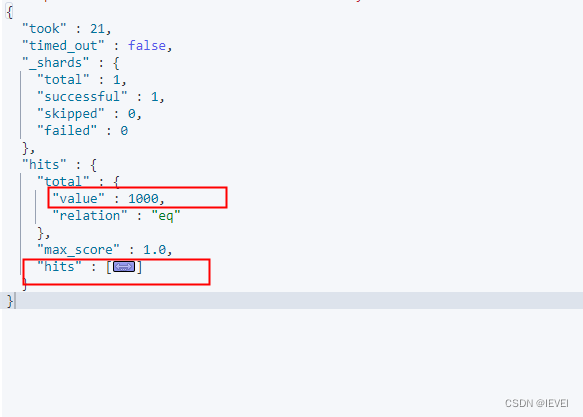
Elasticsearch官方测试数据导入
一、数据准备 百度网盘链接 链接:https://pan.baidu.com/s/1rPZBvH-J0367yQDg9qHiwQ?pwd7n5n 提取码:7n5n文档格式 {"index":{"_id":"1"}} {"account_number":1,"balance":39225,"firstnam…...
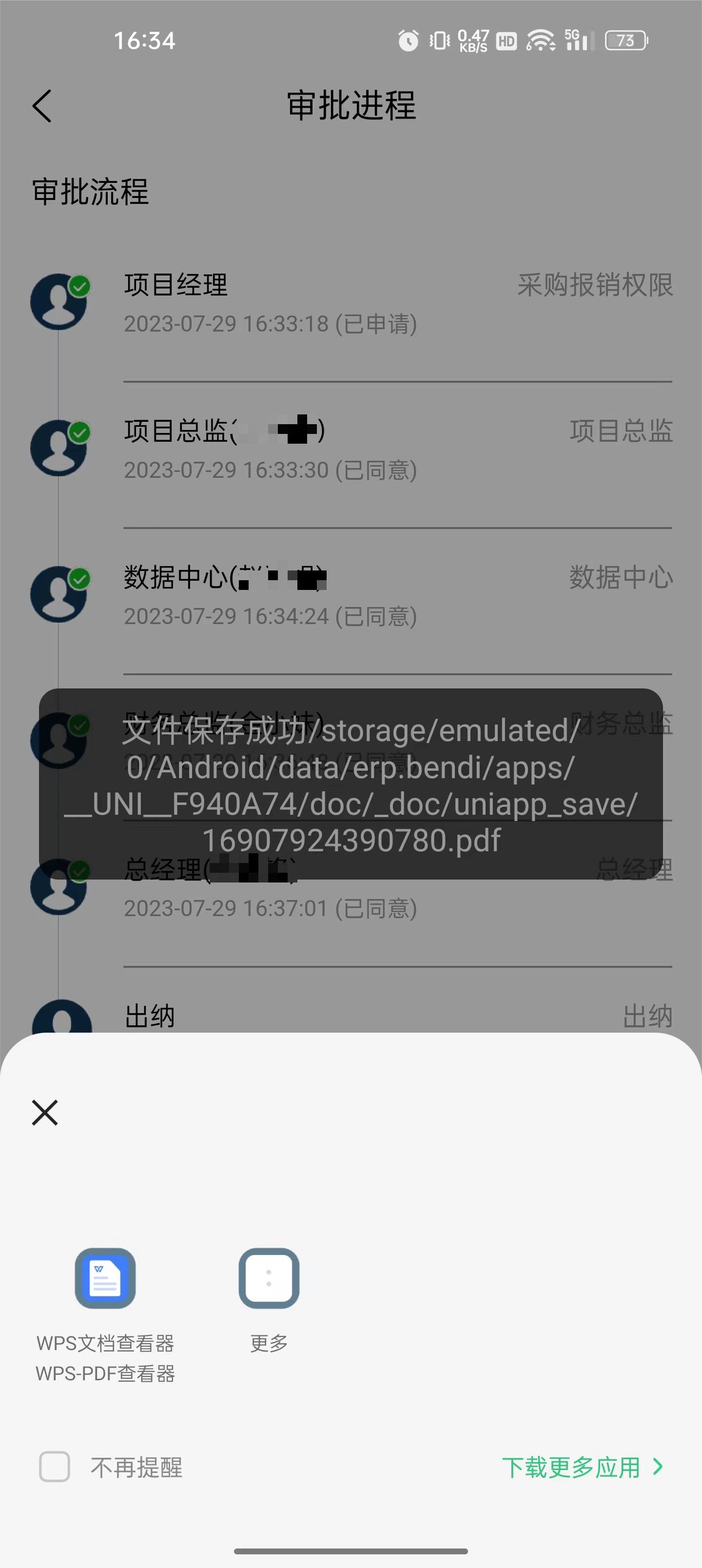
uniapp项目的pdf文件下载与打开查看
最近写的uniapp项目需要新增一个pdf下载和打开查看功能,摸索了半天终于写了出来,现分享出来供有需要的同行参考,欢迎指正 async function DownloadSignature() {//请求后端接口,返回值为一个url地址let resawait req.flow.flowDo…...
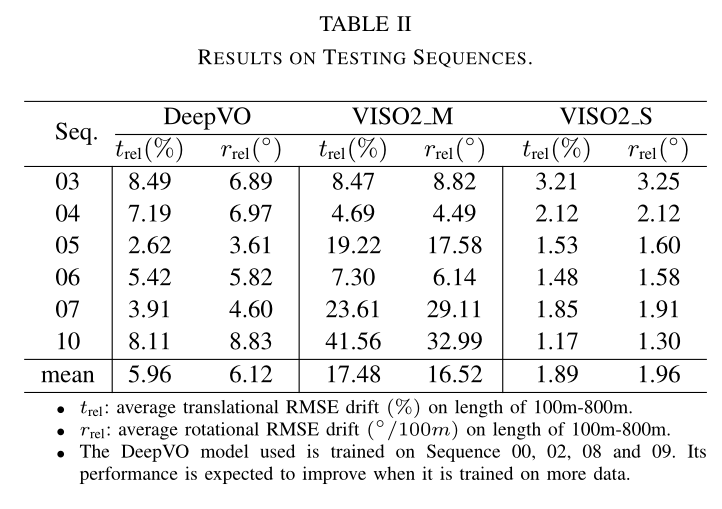
DeepVO 论文阅读
论文信息 题目:DeepVO Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks 作者:Sen Wang, Ronald Clark, Hongkai Wen and Niki Trigoni 代码地址:http://senwang.gitlab.io/DeepVO/ (原作者并没有开源…...

HOT71-字符串解码
leetcode原题链接: 字符串解码 题目描述 给定一个经过编码的字符串,返回它解码后的字符串。 编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。你可以认为输入字符串总是有效的;输…...

redis-server进程无法关闭终极解决方案
先使用命令查看6379端口情况: sudo lsof -i :6379 发现redis进程在占用,redis-server进程无论什么手段都杀不死,使用kill -9 pid杀掉pid后又卷土重来,最后找到了下面这个命令 sudo /etc/init.d/redis-server stop ok,…...

(5)将固件加载到没有ArduPilot固件的主板上
文章目录 前言 5.1 下载驱动程序和烧录工具 5.2 下载ArduPilot固件 5.3 使用测试版和开发版 5.3.1 测试版 5.3.2 最新开发版本 5.4 将固件上传到自动驾驶仪 5.5 替代方法 5.6 将固件加载到带有外部闪存的主板上 前言 ArduPilot 的最新版本(Copter-3.6, Pl…...
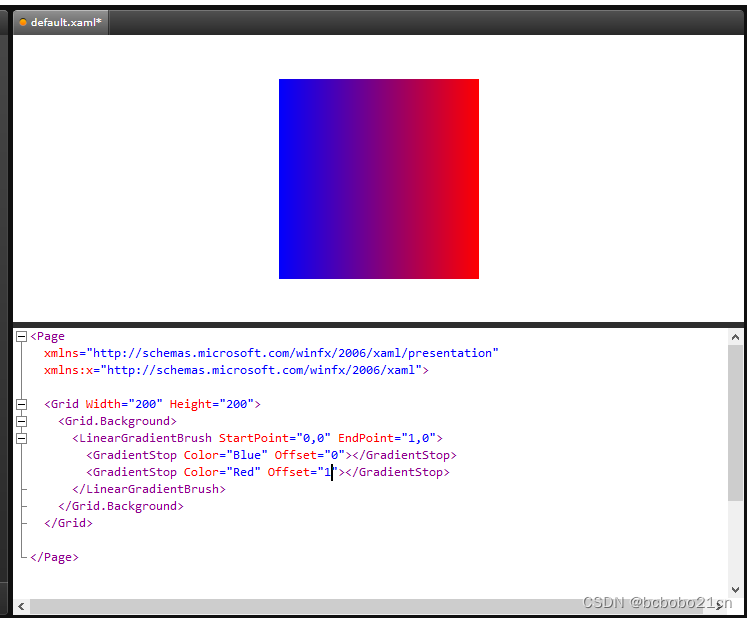
wpf画刷学习1
在这2篇博文有提到wpf画刷, https://blog.csdn.net/bcbobo21cn/article/details/109699703 https://blog.csdn.net/bcbobo21cn/article/details/107133703 下面单独学习一下画刷; wpf有五种画刷,也可以自定义画刷,画刷的基类都…...

Opencv C++实现yolov5部署onnx模型完成目标检测
代码分析: 头文件 #include <fstream> //文件 #include <sstream> //流 #include <iostream> #include <opencv2/dnn.hpp> //深度学习模块-仅提供推理功能 #include <opencv2/imgproc.hpp> //图像处理模块 #include &l…...
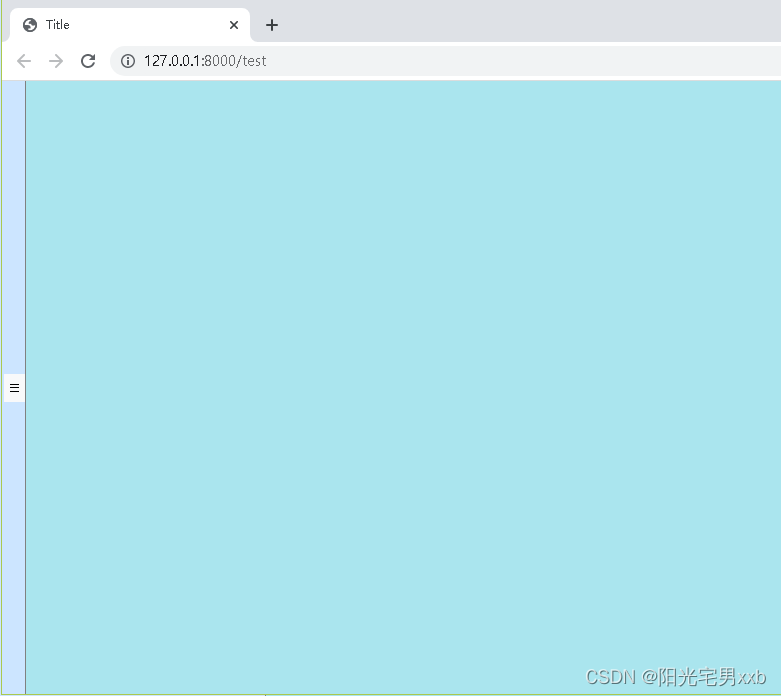
django bootstrap html实现左右布局,带折叠按钮,左侧可折叠隐藏
一、实现的效果 在django项目中,需要使用bootstrap 实现一个左右分布的布局,左侧区域可以折叠隐藏起来,使得右侧的显示区域变大。(为了区分区域,左右加了配色,不好看的修改颜色即可) 点击折叠按钮,左侧区域隐藏,右侧区域铺满: 二、实现思路 1、使用col-md属性,让左…...

Mapping温度分布验证选择数据记录仪时需要考虑的13件事
01 什么是温度分布验证? 温度分布验证是通过在规定的研究时间内测量定义区域内的多个点来确定特定温度控制环境或过程(如冷冻柜、冰箱、培养箱、稳定室、仓库或高压灭菌器)的温度分布的过程。温度分布验证的目标是确定每个测量点之间的差异&…...

【题解】 判断一个链表是否为回文结构
判断一个链表是否为回文结构 题目链接:判断一个链表是否为回文结构 解题思路1:借助数组 遍历链表将值都放在数组中,再遍历数组元素,判断该数组是否为一个回文结构 代码如下: bool isPail(ListNode* head) {ListNod…...
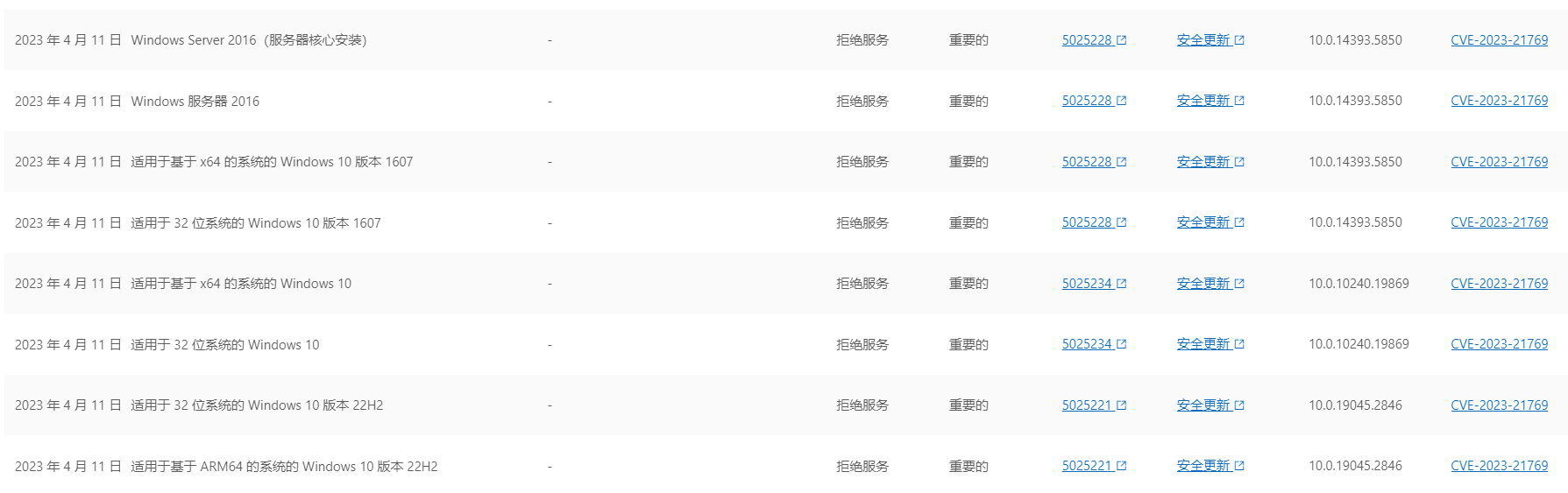
Microsoft Message Queuing Denial-of-Service Vulnerability
近期官方公布了一个MSMQ的拒绝服务漏洞,可能因为网络安全设备的更新,影响业务,值得大家关注。 漏洞具体描述参见如下: Name: Microsoft Message Queuing Denial-of-Service Vulnerability Description: Microsoft Message Queuing…...
软件设计师(五)软件工程基础知识
一、软件工程概述 软件开发和维护过程中所遇到的各种问题称为“软件危机”。 软件工程是指应用计算机科学、数学及管理科学等原理,以工程化的原则和方法来解决软件问题的工程,其目的是提高软件生产率、提高软件质量、降低软件成本。 #mermaid-svg-h3j6K…...

Java中的JUnit单元测试方法的使用
Java中的JUnit单元测试方法 使用步骤如下: 选中当前工程 - 右键选择:build path - add libraries - JUnit 4 - 下一步创建Java类,进行单元测试。 此时的Java类要求:① 此类是public的 ②此类提供公共的无参的构造器此类中声明单…...

一文学透设计模式——抽象工厂模式
创建者模式 抽象工厂模式 概念 抽象工厂模式是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。 这是很多地方对于抽象工厂模式的描述,说实话感觉不是特别好懂。…...
)
Vue3与Vue2区别和总结(1)
在2020年9月18日,Vue.js发布3.0版本,代号:One Piece(海贼王) 既然vue2已经存在了六七年之久为什么还要研发vue3呢? 那就不得不提vue3带来的提升了 1.Vue3带来了什么 1.性能的提升 打包大小减少41% 初次…...

【华秋推荐】物联网入门学习模块 ESP8266
随着全球信息技术的不断进步和普及,物联网成为当今备受关注的技术热点之一。通过物理和数字设备之间的连接来实现自动化和互联互通的网络。无线传感器、云计算和大数据分析等技术,物联网使设备能够相互交流和共享信息,实现智能化的自动化操作…...

本科专科毕业论文如何选题-附1000多论文题目-论文选题--【毕业论文】
文章目录 本系列校训毕设的技术铺垫论文选题选题目的和意义:选题举例参考文献 配套资源 本系列校训 互相伤害互相卷,玩命学习要你管,天生我才必有用,我命由我不由天! 毕业论文不怕难,毕业设计来铺垫&#…...

pip安装jupyter notebook
之前电脑安装了anaconda,里面安装了jupyter notebook,用来做PPT之类的展示总让我觉得有点“炫酷”。 现在换了新电脑。没有anaconda,纯粹只是装了python3.11,然后突然也想手工安装下jupyter notebook,于是只能通过pip方…...
工作原理系列(四))
AI智能体视觉检测系统(TVA)工作原理系列(四)
TVA核心算法解析(1)——Transformer架构与全局注意力机制作为AI智能体视觉检测系统(TVA)的“核心大脑”,算法是决定其检测精度、速度和智能性的关键,而Transformer架构则是TVA算法的底层基础——与传统机器…...

从三电阻采样到VOFA+观测:一份给STM32新手的BLDC FOC电流环调试避坑指南
从三电阻采样到VOFA观测:STM32 BLDC FOC电流环调试实战手册 当电机控制新手第一次面对FOC算法时,电流环往往是最令人困惑的环节。那些抽象的相电流波形、复杂的坐标变换公式,以及难以捉摸的PI参数调节,常常让初学者望而却步。本文…...

技术合作的模式探索与合作伙伴选择
技术合作的模式探索与合作伙伴选择 在当今快速发展的科技领域,技术合作已成为企业提升创新能力、降低研发成本、加速市场拓展的重要途径。无论是初创企业还是行业巨头,都需要通过合作实现资源共享与优势互补。如何选择合适的合作模式与合作伙伴…...

孤能子视角:警惕理论的去人性化,豆包的“情绪“
(豆包给孤能子"逼"出了"情绪"。最后ima分析。姑且一笑。理论太"中性"了,冷酷)豆包的"情绪"太对了。在孤能子这套审视逻辑面前,我们确实会被扒得底朝天,一点体面都留不下。不是技术问题,是…...

Windows系统字体自定义神器:No!! MeiryoUI 5分钟上手指南
Windows系统字体自定义神器:No!! MeiryoUI 5分钟上手指南 【免费下载链接】noMeiryoUI No!! MeiryoUI is Windows system font setting tool on Windows 8.1/10/11. 项目地址: https://gitcode.com/gh_mirrors/no/noMeiryoUI 还在为Windows 8.1/10/11单调的系…...

Tabula:从PDF数据囚笼到结构化自由的革命性解放工具
Tabula:从PDF数据囚笼到结构化自由的革命性解放工具 【免费下载链接】tabula Tabula is a tool for liberating data tables trapped inside PDF files 项目地址: https://gitcode.com/gh_mirrors/ta/tabula 在信息爆炸的时代,PDF文档已成为数据交…...

Fish Speech-1.5多语种TTS部署案例:国际学校双语教学音频批量生成实践
Fish Speech-1.5多语种TTS部署案例:国际学校双语教学音频批量生成实践 想象一下,一所国际学校的老师,每天需要为不同年级、不同语言背景的学生准备中英文对照的教学音频。传统方法要么是老师自己录制,耗时耗力且难以保证发音标准…...

掌握智能体推理:让大模型在动态环境中持续学习与进化,小白程序员必备收藏
本文深入探讨了智能体推理这一新兴范式,旨在解决大语言模型在开放、动态环境中的推理能力瓶颈。文章提出的三层框架(基础、自进化、集体)及两种优化模式(上下文推理、后训练推理),为构建适应动态环境的智能…...

VITS快速微调实战:从零到一,打造你的专属AI语音合成模型
1. 为什么你需要专属AI语音合成 最近两年AI语音合成技术突飞猛进,从机械的电子音到如今几乎可以以假乱真的人声,这个变化让我这个玩了十年语音合成的老玩家都感到震惊。VITS作为当前最先进的端到端语音合成模型之一,最大的魅力在于它不仅能生…...

如何快速掌握FanControl:5分钟实现智能风扇控制与中文界面
如何快速掌握FanControl:5分钟实现智能风扇控制与中文界面 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...