PyTorch Lightning教程六:优化代码
有时候模型训练很慢,代码写得冗长之后,没法诶个检查到底那块出现了占用了时空间,本节通过利用Lightning的一些方法,检查分析是那块代码出现了问题,从而来进一步指导和优化代码
本节主要基于性能分析方法,通过捕获分析信息(例如函数花费的时间或使用了多少内存)帮助我们找到代码中的瓶颈。
找到训练时候的瓶颈
最基本的性能分析配置文件,包含训练中Callback、DataModules和LightningModule中的所有关键方法。可以通过如下方法引入
trainer = Trainer(profiler="simple")
一旦执行.fit()方法,则可以看到如下类似结果
FIT Profiler Report
-----------------------------------------------------------------------------------------------
| Action | Mean duration (s) | Total time (s) |
-----------------------------------------------------------------------------------------------
| [LightningModule]BoringModel.prepare_data | 10.0001 | 20.00 |
| run_training_epoch | 6.1558 | 6.1558 |
| run_training_batch | 0.0022506 | 0.015754 |
| [LightningModule]BoringModel.optimizer_step | 0.0017477 | 0.012234 |
| [LightningModule]BoringModel.val_dataloader | 0.00024388 | 0.00024388 |
| on_train_batch_start | 0.00014637 | 0.0010246 |
| [LightningModule]BoringModel.teardown | 2.15e-06 | 2.15e-06 |
| [LightningModule]BoringModel.on_train_start | 1.644e-06 | 1.644e-06 |
| [LightningModule]BoringModel.on_train_end | 1.516e-06 | 1.516e-06 |
| [LightningModule]BoringModel.on_fit_end | 1.426e-06 | 1.426e-06 |
| [LightningModule]BoringModel.setup | 1.403e-06 | 1.403e-06 |
| [LightningModule]BoringModel.on_fit_start | 1.226e-06 | 1.226e-06 |
-----------------------------------------------------------------------------------------------
在这个打印出来的报告中,我们可以看到最慢的函数是prepare_data,现在我们可以弄清楚为什么数据准备会减慢训练速度。执行profiler="simple",会包括:
- on_train_epoch_start
- on_train_epoch_end
- on_train_batch_start
- model_backward
- on_after_backward
- optimizer_step
- on_train_batch_end
- on_training_end
- 等等……
分析每个函数内的时间
要分析每个函数花费的时间,使用构建在Python的cProfiler之上的AdvancedProfiler,如下引用:
trainer = Trainer(profiler="advanced")
执行fit后,会出现如下结果
Profiler ReportProfile stats for: get_train_batch4869394 function calls (4863767 primitive calls) in 18.893 seconds
Ordered by: cumulative time
List reduced from 76 to 10 due to restriction <10>
ncalls tottime percall cumtime percall filename:lineno(function)
3752/1876 0.011 0.000 18.887 0.010 {built-in method builtins.next}1876 0.008 0.000 18.877 0.010 dataloader.py:344(__next__)1876 0.074 0.000 18.869 0.010 dataloader.py:383(_next_data)1875 0.012 0.000 18.721 0.010 fetch.py:42(fetch)1875 0.084 0.000 18.290 0.010 fetch.py:44(<listcomp>)60000 1.759 0.000 18.206 0.000 mnist.py:80(__getitem__)60000 0.267 0.000 13.022 0.000 transforms.py:68(__call__)60000 0.182 0.000 7.020 0.000 transforms.py:93(__call__)60000 1.651 0.000 6.839 0.000 functional.py:42(to_tensor)60000 0.260 0.000 5.734 0.000 transforms.py:167(__call__)
如果分析器报告变得太长,可以将报告流式传输到一个文件:
from lightning.pytorch.profilers import AdvancedProfilerprofiler = AdvancedProfiler(dirpath=".", filename="perf_logs")
trainer = Trainer(profiler=profiler)
很方便!
分析加速器使用情况
另一种检测瓶颈的有用技术,是确保正在使用加速器(GPU/TPU/IPU/HPU)的全部容量。这可以用DeviceStatsMonitor来测量:
from lightning.pytorch.callbacks import DeviceStatsMonitortrainer = Trainer(callbacks=[DeviceStatsMonitor()])
CPU指标将在CPU加速器上默认跟踪。设置DeviceStatsMonitor(cpu_stats=True)为其他加速器启用它。要禁用记录CPU指标,可以指定DeviceStatsMonitor(cpu_stats=False)。
相关文章:

PyTorch Lightning教程六:优化代码
有时候模型训练很慢,代码写得冗长之后,没法诶个检查到底那块出现了占用了时空间,本节通过利用Lightning的一些方法,检查分析是那块代码出现了问题,从而来进一步指导和优化代码 本节主要基于性能分析方法,通…...
基于linux下的高并发服务器开发(第四章)- 多线程实现并发服务器
>>了解文件描述符 文件描述符分为两类,一类是用于监听的,一类是用于通信的,在服务器端既有监听的,又有通信的。而且在服务器端只有一个用于监听的文件描述符,用于通信的文件描述符是有n个。和多少个客户端建立了…...

YUV 色彩空间中U 和 V 分量的范围
在YUV色彩空间中,U分量和V分量的范围通常是-0.5到0.5。 具体来说,对于标准的YUV色彩空间(例如YUV420),取样是按照4:2:0的比例进行的。这意味着在水平和垂直方向上,U和V分量的取样比Y分量少一半。因此&…...

【云原生】K8S二进制搭建一
目录 一、环境部署1.1操作系统初始化 二、部署etcd集群2.1 准备签发证书环境在 master01 节点上操作在 node01与02 节点上操作 三、部署docker引擎四、部署 Master 组件4.1在 master01 节点上操 五、部署Worker Node组件 一、环境部署 集群IP组件k8s集群master01192.168.243.1…...

自动化应用杂志自动化应用杂志社自动化应用编辑部2023年第11期目录
数据处理与人工智能 大数据视域下无轨设备全生命周期健康管理技术的研究 赖凡; 1-3 三维激光扫描结合无人机倾斜摄影在街区改造测绘中的技术应用 张睿; 4-6 井上变电站巡检机器人的设计与应用 刘芳; 7-9 《自动化应用》投稿邮箱:cnqikantg126.com 基于机…...
Tensorflow2-初识
TensorFlow2是一个深度学习框架,可以理解为一个工具,有谷歌的全力支持,具有易用、灵活、可扩展、性能优越、良好的社区资源等优点。 1、环境的搭建 1.1 Anaconda3的安装 https://www.anaconda.com/ Python全家桶,包括Python环境和…...
idea-常用插件汇总
idea-常用插件汇总 码云插件 这个插件是码云提供的ps-码云是国内的一款类似github的代码托管工具。 Lombok Lombok是一个通用Java类库,能自动插入编辑器并构建工具,简化Java开发。通过添加注解的方式,不需要为类编写getter或setter等方法…...
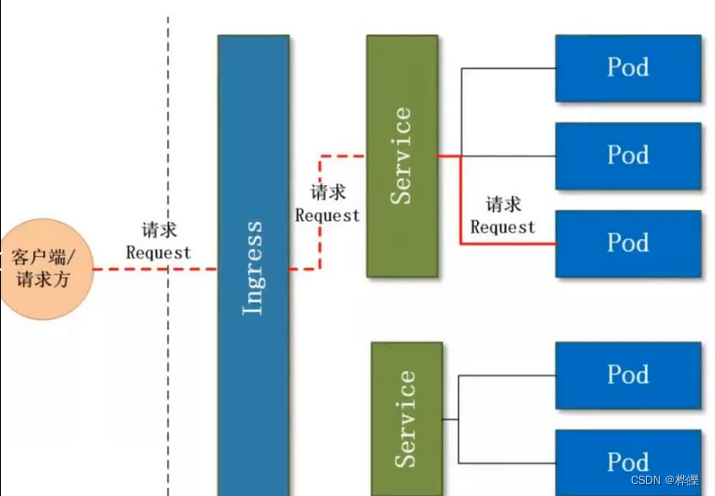
【Kubernetes】
目录 一、Kubernetes 概述1、K8S 是什么?2、为什么要用 K8S?3、Kubernetes 集群架构与组件 二、核心组件1、Master 组件2、Node 组件3、K8S创建Pod的工作流程?(重点)4、K8S资源对象(重点)5、Kubernetes 核…...

使用逗号方式、JOIN方式和USING方式进行多表连接查询时哪个方式更好
在Oracle中,使用逗号方式、JOIN方式和USING方式进行多表连接查询时,性能上没有明显的差异。这是因为Oracle优化器会自动将这些语法转换为内部执行计划,以获得最佳的查询性能。 逗号方式:逗号方式是最简单的连接语法,它…...
MacOS上用docker运行mongo及mongo-express
MongoDB简介 MongoDB 是一个基于分布式文件存储的数据库。由 C 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。 MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。 前提 要求…...

海康视频插件VideoWebPlugin在vue中的实现
一,将js文件放在public文件下 二,在index中全局引入 三.在视频页面写方法,创建实例,初始化,我写的是1*4屏的 <template><!--视频窗口展示--><div idplayWnd classNameplayWnd refplayWnd styleleft: 0; bottom: 0;height: 902px;width: 60vw></div>&…...
swagger相关问题
swagger相关问题 swagger版本为: <dependency><groupId>com.github.xiaoymin</groupId><artifactId>swagger-bootstrap-ui</artifactId><version>1.9.6</version> </dependency> <dependency><groupId&…...

Scala关键字lazy的见解
Scala中使用关键字lazy来定义惰性变量,实现延迟加载(懒加载)。 惰性变量只能是不可变变量,并且只有在调用惰性变量时,才会去实例化这个变量。 在Java中,要实现延迟加载(懒加载),需要自己手动实现。一般的做法是这样的…...

sql分类 DDL、DML、DCL
DDL (Data Definition Language 数据定义语言) 这些语句定了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构 如: CREATE \ DROP \ ALTER \ RENAME \ TRUNCATE 等 DML(Data Manipulation Langua…...

C++ 性能优化
要系统地提升C项目的性能,可以采取以下步骤: 分析和度量:首先,你需要通过性能分析工具来确定项目中的性能瓶颈。使用工具如gprof、perf等,来识别代码中消耗时间和资源最多的部分。 选择合适的数据结构和算法ÿ…...

435. 无重叠区间
435. 无重叠区间 给定一个区间的集合 intervals ,其中 intervals[i] [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。 示例 1: 输入: intervals [[1,2],[2,3],[3,4],[1,3]] 输出: 1 解释: 移除 [1,3] 后,剩下的区间…...

winform使用SetParent 嵌入excel,打开的excel跟随dpi 25%*125%缩放了两次,目前微软官方没有好的解决方案,为什么
双重缩放问题在将 Excel 嵌入到 WinForm 中时确实可能会出现,这是因为两个不同的应用程序(WinForm 和 Excel)之间的 DPI 缩放逻辑不一致,导致双重缩放的结果。 在 Windows 操作系统中,DPI 缩放是一种全局的设置&#…...

MySQL 数据库、表的基本操作
目录 数据库 关系数据库SQL 关系数据库常用词汇 常用命令语句 数据库操作 查看数据库 创建数据库 修改数据库编码 删除数据库 数据表操作 查看数据表 创建数据表 表中数据操作 增 删 改 查 数据库 数据库是在数据管理和程序开发过程中,一种非常重要…...
html5播放器视频切换和连续播放的实例
当前播放器实例可以使用changeVid接口切换正在播放的视频。当有多个视频,在上一个视频播放完毕时,自动播放下一个视频时也可采用该处理方式。 const option {vid: 88083abbf5bcf1356e05d39666be527a_8,//autoplay: true,//playsafe: , //PC端播放加密视…...

什么是无服务器架构技术
什么是无服务器架构技术 无服务器架构(Serverless Architecture)是jin年来逐渐兴起的一种软件架构方案,它采用了一种全新的方式来处理应用程序的部署、运行和扩展。与传统的服务器架构相比,无服务器架构具有很多优势,包…...

.NET 诊断技巧 | 日志框架原理、手写日志框架学习汕
一、 什么是 AI Skills:从工具级到框架级的演化 AI Skills(AI 技能) 的概念最早在 Claude Code 等前沿 Agent 实践中被强化。最初,Skills 被视为“工具级”的增强,如简单的文件读写或终端操作,方便用户快速…...

【笔试真题】- 团子-2026.04.11-研发岗
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围在线刷题 bishipass.com 团子-2026.04.11-研发岗 这套 4 月 11 日的美团研发岗整体不算偏难,但题型切得很开。第一题是典型热身,第二题开始考你能不能把局部约束整理成可执行的构造,…...

C# 面试高频题:装箱和拆箱是如何影响性能的?痛
OCP原则 ocp指开闭原则,对扩展开放,对修改关闭。是七大原则中最基本的一个原则。 依赖倒置原则(DIP) 什么是依赖倒置原则 核心是面向接口编程、面向抽象编程, 不是面向具体编程。 依赖倒置原则的目的 降低耦合度&#…...

CW大鹏无人机地面站智能航线规划实战指南
1. 认识CW大鹏无人机地面站 第一次接触CW大鹏无人机地面站时,我被它强大的功能震撼到了。这不仅仅是一个简单的遥控软件,而是一个完整的飞行任务指挥中心。通过地面站,我们可以完成从航线规划到飞行监控的全流程操作,特别适合农业…...
)
光电对抗:多模/复合制导及其集成技术(2)
第二节:复合制导集成技术进展和前沿及攻关方向和趋势多模复合制导的集成、协调、协同技术进展,以及高效、协同、低成本的发展方向,是该领域的核心和前沿。一、集成协同技术前沿进展多模复合制导的“集成、协调、协同”,其核心是让…...
)
【仅开放至Q3末】SITS2026改造原始日志脱敏包+Prompt工程checklist(含17个金融/政务场景特化模板)
第一章:SITS2026案例:大模型客服系统改造 2026奇点智能技术大会(https://ml-summit.org) 某大型金融集团原有客服系统基于规则引擎与传统NLU模块构建,响应准确率不足68%,平均首次解决时长(FTTR)达4.7分钟…...

【限时解密】2026奇点大会闭门论坛纪要:头部AI实验室正秘密迁移至“神经符号视觉架构”,传统端到端VLM或于Q3被淘汰
第一章:2026奇点智能技术大会:大模型视觉理解 2026奇点智能技术大会(https://ml-summit.org) 多模态视觉理解范式的跃迁 本届大会首次系统性展示了基于世界模型(World Model)驱动的视觉理解新架构——VLM-Ω(Vision-…...

【技术干货】Hermes Agent 0.8 深度解析:开源自主 AI 代理的生产级进化
摘要 本文深度解析 Hermes Agent 0.8 版本的核心技术升级,涵盖异步任务通知、动态模型切换、工具调用优化等关键特性,并提供基于 Python 的完整实战代码示例,助力开发者快速构建生产级 AI Agent 应用。背景介绍 Hermes Agent 是由 Nous Resea…...

BERT中文文本分割效果惊艳展示:学术论文讲义自动划分为‘引言-方法-结论’
BERT中文文本分割效果惊艳展示:学术论文讲义自动划分为引言-方法-结论 1. 效果惊艳开场:让杂乱文本秒变结构清晰 你有没有遇到过这样的情况:拿到一份长达几十页的学术讲座录音转写稿,密密麻麻的文字堆在一起,找不到开…...

3步轻松解密网易云NCM加密音乐:ncmdump工具全攻略
3步轻松解密网易云NCM加密音乐:ncmdump工具全攻略 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否遇到过这样的困扰:从网易云音乐下载的歌曲只能在特定客户端播放,无法在车载音响、手机自带…...