Python批量查字典和爬取双语例句
最近,有网友反映,我的批量查字典工具换到其它的网站就不好用了。对此,我想说的是,互联网包罗万象,网站的各种设置也有所不同,并不是所有的在线字典都可以用Python爬取的。事实上,很多网站为了防止被爬取内容,早就提高了网站的安全级别,不会让用户轻意爬取内容的。
由于这名网友想要的是韩语翻译,所以我就不能拿原来的网站来操作了,只好去网上查询网速快、又不对爬虫有限制的网站来操作。终于,探索出了爬取某字典网站上内容的方法。
一、用BeautifulSoup获取翻译
这是一个字典网站,也是一个双语句库网站,对于汉语的韩语翻译,我们可以通过requests来获取网页源文,再用BeautifulSoup进行解析,然后用soup.find()查找想要的标签信息和Class,提取文本信息,然后再写入到xls文件就可以了,代码如下:
import xlwt
import requests
from bs4 import BeautifulSoupheaders = {"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Mobile Safari/537.36 Edg/114.0.1823.37"}def get_word(word):url=f"https://zh.glosbe.com/zh/ko/{word}"resp = requests.get(url,headers=headers)soup = BeautifulSoup(resp.text, 'html.parser')# 查找查询结果result = soup.find('div', class_="inline leading-10")if result:return result.text.split()[0]else:return "未找到翻译"def process_txt_file(filename):# 创建工作簿wb = xlwt.Workbook()# 创建表单sh = wb.add_sheet("sheet 1")with open(filename, 'r', encoding='utf-8') as file:words = [i.strip() for i in file.readlines()]for index,word in enumerate(words):sh.write(index,0,word)sh.write(index,1,get_word(word))wb.save('translation_results.xls')
#调用函数并传入txt文件路径
process_txt_file('words.txt')二、用openpyxl来写入xlsx文件
上面的代码中采用的是xlwt来写入到xls文件,我们也可以改用openpyxl,同时,我们还可以通过soup.h3.string来更快地定位所需要的位置信息。这次我们把查询的内容由韩语改为英文,代码优化如下:
import requests
from bs4 import BeautifulSoup
import openpyxl
headers = {"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Mobile Safari/537.36 Edg/114.0.1823.37"}
def get_word(word):url=f"https://zh.glosbe.com/zh/en/{word}"resp = requests.get(url,headers=headers)soup = BeautifulSoup(resp.text, 'html.parser')# 查找查询结果#results = soup.find_all('div', class_="py-2 flex")results = soup.h3.stringif results:return results.strip()else:return "未找到翻译"
# if results:
# for result in results:
# print(result.replace("\n\n\n","\n").strip())
# else:
# return "未找到翻译"
def process_txt_file(filename):workbook = openpyxl.Workbook()sheet = workbook.activewith open(filename, 'r', encoding='utf-8') as file:words = [i.strip() for i in file.readlines()]for index, word in enumerate(words):translation = get_word(word)sheet.cell(row=index + 1, column=1).value = wordsheet.cell(row=index + 1, column=2).value = translationworkbook.save('translation_results.xlsx')#调用函数并传入txt文件路径
process_txt_file('words.txt')三、提取双语例句到xlsx文件
先上效果,以下是多个关键词及其相关例句的图示:

相关代码如下:
import requests
from bs4 import BeautifulSoup
import openpyxl
headers = {"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Mobile Safari/537.36 Edg/114.0.1823.37"}
def get_word(word):url=f"https://zh.glosbe.com/zh/en/{word}"resp = requests.get(url,headers=headers)soup = BeautifulSoup(resp.text, 'html.parser')# 查找查询结果results = soup.find_all('div', class_="py-2 flex")lst=[]if results:for result in results:text = result.text.replace("\n\n\n","\n").strip()lst.append(text.split("\n"))return lstelse:return "未找到翻译"def process_txt_file(filename):workbook = openpyxl.Workbook()sheet = workbook.activewith open(filename, 'r', encoding='utf-8') as file:words = [i.strip() for i in file.readlines()]for word in words:sheet.append([word])paras = get_word(word)for para in paras:sheet.append(para)workbook.save('translation.xlsx')#调用函数并传入txt文件路径
process_txt_file("words.txt")四、学后的反思
1. 爬虫不是万能的,不能完全依靠爬虫去获取一切网上的信息,毕竟有很多网站的案例防御机制是针对爬虫的
2. 利用BeautifulSoup是很不错的解析、提取网页标签的方法,如果无法完全获取网页信息就要考虑带上headers,cookies等信息。
3. 写入excel文件有多种 方法,列表写入Excel可以考虑sheet.append()方法,简单实用。
相关文章:
Python批量查字典和爬取双语例句
最近,有网友反映,我的批量查字典工具换到其它的网站就不好用了。对此,我想说的是,互联网包罗万象,网站的各种设置也有所不同,并不是所有的在线字典都可以用Python爬取的。事实上,很多网站为了防…...

uni-app、H5实现瀑布流效果封装,列可以自定义
文章目录 前言一、效果二、使用代码三、核心代码总结前言 最近做项目需要实现uni-app、H5实现瀑布流效果封装,网上搜索有很多的例子,但是代码都是不够完整的,下面来封装一个uni-app、H5都能用的代码。在小程序中,一个个item渲染可能出现问题,也通过加锁来解决问题。 一、…...
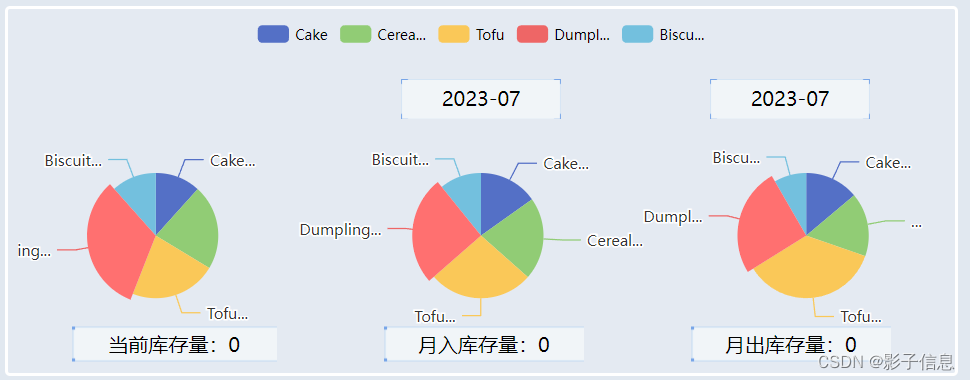
vue echart3个饼图
概览:根据UI设计需要做3个饼图且之间有关联,并且处理后端返回的数据。 参考链接: echart 官网的一个案例,3个饼图 实现思路: 根据案例,把数据处理成对应的。 参考代码: 1.处理后端数据&am…...
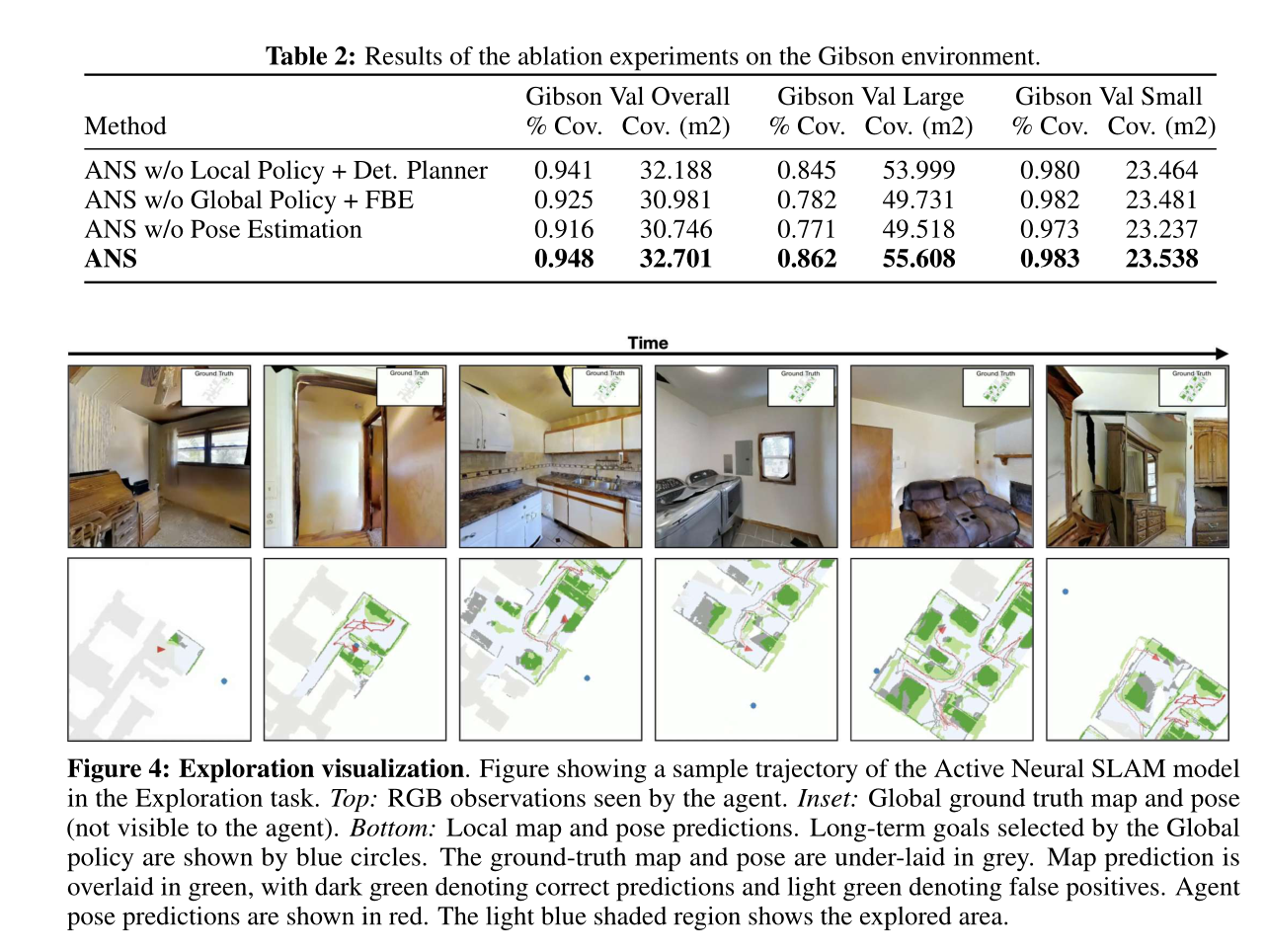
LEARNING TO EXPLORE USING ACTIVE NEURAL SLAM 论文阅读
论文信息 题目:LEARNING TO EXPLORE USING ACTIVE NEURAL SLAM 作者:Devendra Singh Chaplot, Dhiraj Gandhi 项目地址:https://devendrachaplot.github.io/projects/Neural-SLAM 代码地址:https://github.com/devendrachaplot/N…...
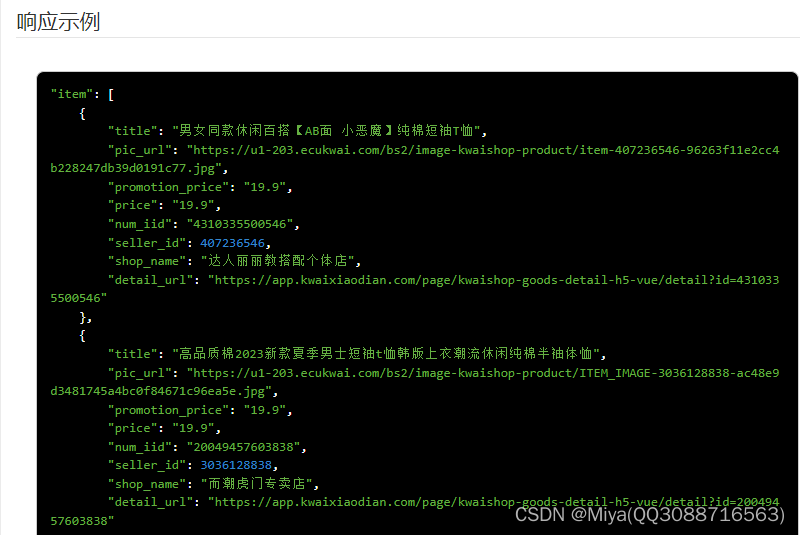
item_search-ks-根据关键词取商品列表
一、接口参数说明: item_search-根据关键词取商品列表,点击更多API调试,请移步注册API账号点击获取测试key和secret 公共参数 请求地址: https://api-gw.onebound.cn/ks/item_search 名称类型必须描述keyString是调用key(http:…...

windows运行WPscan报错:无法打开库libcurl.dll
windows运行WPscan报错:无法打开库libcurl.dll 1.问题背景2.解决方案1.问题背景 在Windows上启动WPScan时: wpscan --url xxx.ru提示如下错误: Could not open library libcurl.dll: �� ������ ��������� ������. . Could not open library libcu...
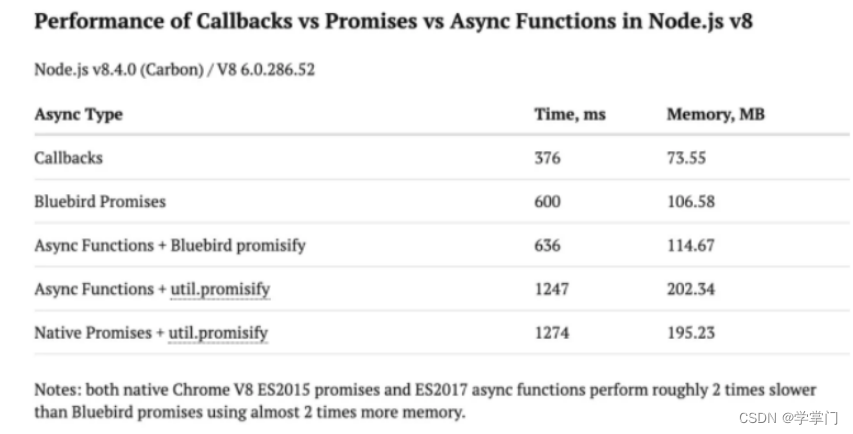
web前端框架Javascript之JavaScript 异步编程史
早期的 Web 应用中,与后台进行交互时,需要进行 form 表单的提交,然后在页面刷新后给用户反馈结果。在页面刷新过程中,后台会重新返回一段 HTML 代码,这段 HTML 中的大部分内容与之前页面基本相同,这势必造成…...
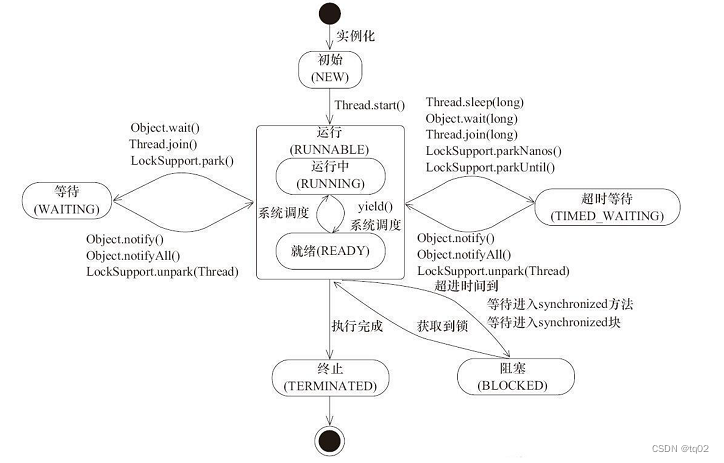
Java多线程(1)---多线程认识、四种创建方式以及线程状态
目录 前言 一.Java的多线程 1.1多线程的认识 1.2Java多线程的创建方式 1.3Java多线程的生命周期 1.4Java多线程的执行机制 二.创建多线程的四种方式 2.1继承Thread类 ⭐创建线程 ⭐Thread的构造方法和常见属性 2.2.实现Runnable接口 ⭐创建线程 ⭐使用lambda表达…...

搭建Django+pyhon+vue自动化测试平台
Django安装 使用管理员身份运行pycharm使用local 1 pip install django -i https://pypi.tuna.tsinghua.edu.cn/simple 检查django是否安装成功 1 python -m django --version 创建项目 1 1 django-admin startproject test cd 切换至创建的项目中启动django项目…...
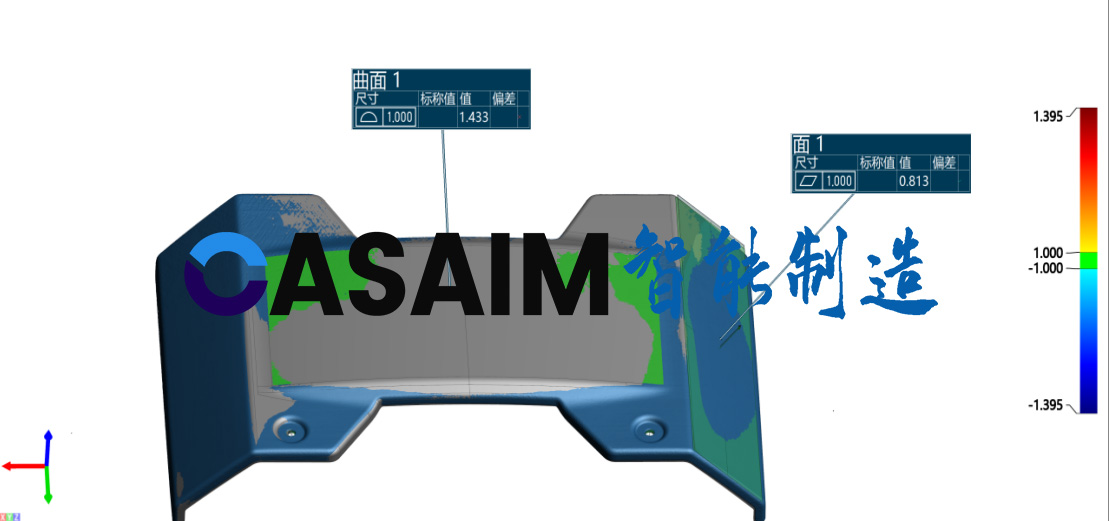
CASAIM自动化平面度检测设备3D扫描零部件形位公差尺寸测量
平面度是表面形状的度量,指示沿该表面的所有点是否在同一平面中,当两个表面需要连接在一起形成紧密连接时,平面度检测至关重要。 CASAIM自动化平面度检测设备通过搭载领先的激光三维测头和智能检测软件自动获取零部件高质量测量数据…...

PostgreSql pg_ctl 命令
一、概述 控制 PostgreSQL 服务的工具。 二、语法 --初始化数据库实例 pg_ctl init[db] [-D datadir] [-s] [-o initdb-options]--启动数据库实例 pg_ctl start [-D datadir] [-l filename] [-W] [-t seconds] [-s] [-o options] [-p path] [-c]--停止数据库实例 pg_ctl sto…...

MySQL中的MVCC具体指的是什么?
在MySQL中,MVCC是指多版本并发控制(Multi-Version Concurrency Control)。它是一种用于处理并发读写操作的数据库事务管理技术。 MVCC通过在数据库中维护多个版本的数据来实现并发控制,每个事务在执行期间看到的数据版本是确定性…...
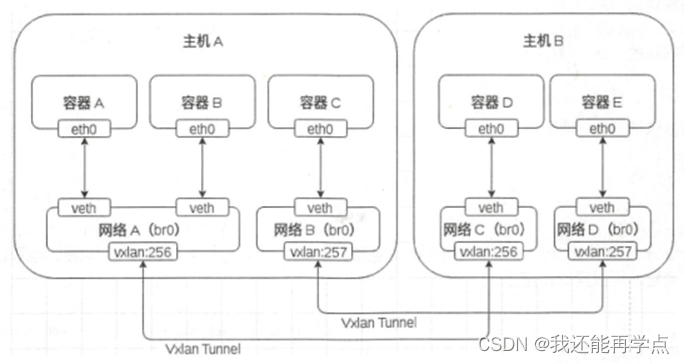
Docker网络模型详解
目录 一、Docker网络基础 1、端口映射 使用-P选项时Docker会随机映射一个端口至容器内部的开放端口 使用docker logs查看Nginx的日志 查看映射的随机端口范围 2、使用-p可以指定要映射到的本地端口。 Local_Port:Container_Port : 端口映射参数中指定了宿主…...
如何打造属于自己的个人IP?
在当今信息爆炸的时代,个人 IP 已经成为人们在网络世界中的独特标签。无论是在职场上、创业中,还是在社交生活中,拥有个人 IP 的人都能脱颖而出,吸引更多的关注和机会。那么,如何打造属于自己的个人 IP 呢?…...

全网最全最细的jmeter接口测试教程以及接口测试流程详解
一、Jmeter简介 Jmeter是由Apache公司开发的一个纯Java的开源项目,即可以用于做接口测试也可以用于做性能测试。 Jmeter具备高移植性,可以实现跨平台运行。 Jmeter可以实现分布式负载。 Jmeter采用多线程,允许通过多个线程并发取样或通过…...

【Linux命令200例】whereis用于搜索以及定位二进制文件
🏆作者简介,黑夜开发者,全栈领域新星创作者✌,阿里云社区专家博主,2023年6月csdn上海赛道top4。 🏆本文已收录于专栏:Linux命令大全。 🏆本专栏我们会通过具体的系统的命令讲解加上鲜…...
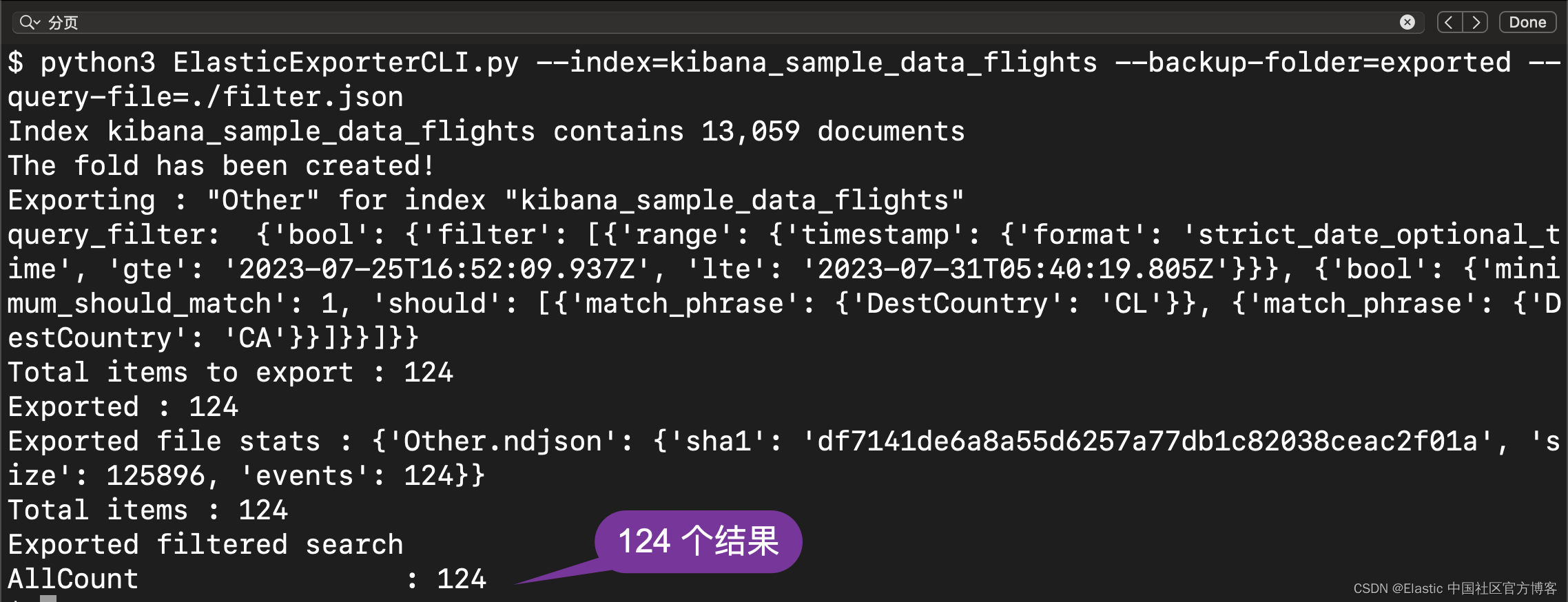
Elasticsearch:如何将整个 Elasticsearch 索引导出到文件 - Python 8.x
在实际的使用中,我们有时希望把 Elasticsearch 的索引保存到 JSON 文件中。在之前,我写了一篇管如何备份 Elasticsearch 索引的文章 “Elasticsearch:索引备份及恢复”。在今天,我们使用一种 Python 的方法来做进一步的探讨。你可…...

cmd 实现启动mysql时保留窗口
因为mysql启动后, 只有在任务管理器里能看到进程, 关的时候还需要找一下 所以基于 start cmd /k 命令实现了该效果 :: Author: admin :: Date: 2022-08-30 :: Version v1.2 :: ::启动 :: :: echo off::配置变量 set mysqlC:\mysql-5.7.38-winx64\bin\mysqld.exe::打印配置…...
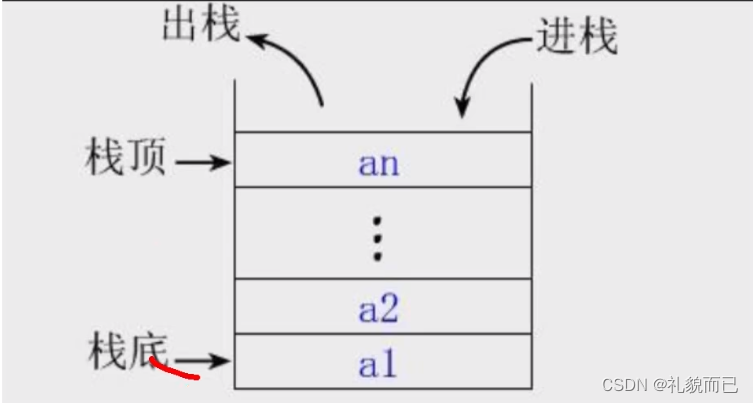
JavaScript数据结构与算法——栈
文章目录 一、初始栈结构1.1 特性1.2 注意事项 二、栈结构的封装2.1 封装简单栈结构2.2 利用栈将十进制转二进制 一、初始栈结构 1.1 特性 类似于汉诺塔,后进先出,每次只能操作栈顶的元素。关键词:压栈、退栈 简单示意图: 1.…...

Elasticsearch分词详解:ES分词介绍、倒排索引介绍、分词器的作用、停用词
详见:https://blog.csdn.net/weixin_40612128/article/details/123476053...

告别HTML/CSS:NiceGUI让Python开发者5分钟搞定动态图表网页
用Python重塑数据可视化:NiceGUI零前端开发动态仪表盘实战 在数据驱动的时代,如何快速将分析结果转化为可交互的视觉呈现成为每个Python开发者的必备技能。传统方式需要掌握HTML、CSS和JavaScript整套技术栈,而NiceGUI的出现彻底改变了这一局…...
从零开始:为Pixel设备编译定制AOSP系统的完整指南
1. 环境准备:搭建AOSP编译基础 编译AOSP系统就像盖房子需要先打地基,准备工作直接影响后续所有环节的顺畅度。我曾在不同配置的电脑上尝试过十几次编译,深刻体会到环境配置的重要性。首先需要一台性能足够的Linux机器,推荐Ubuntu …...
,业务系统不直接接触私钥)
FISCO BCOS 日常操作使用托管签名服务(如WeBASE-Sign),业务系统不直接接触私钥
实战:如何通过WeBASE-Sign实现私钥托管与安全签名 目录 引言 一、为什么需要签名分离 1.1 传统签名的安全困境 1.2 签名分离的架构优势 1.3 适用场景 二、WeBASE-Sign 签名服务核心原理 2.1 整体架构 2.2 核心接口 2.3 交易流程中的签名位置 三、实战:完整接入流程…...
)
【2026唯一通过ISO/IEC 23894 AI治理认证的低代码平台】:SITS2026演示全程技术白皮书级解读(含实时审计链路图)
第一章:SITS2026演示:AI原生低代码平台 2026奇点智能技术大会(https://ml-summit.org) SITS2026 是面向企业级AI应用构建的全新一代AI原生低代码平台,深度融合大语言模型推理能力与可视化编排引擎,支持从自然语言需求描述到可部…...
)
不止于登录:用钉钉扫码打通Vue3后台与企微/飞书(OAuth2.0统一方案)
构建企业级统一身份认证中台:Vue3多平台扫码登录架构设计 当企业同时使用钉钉、企业微信和飞书作为办公平台时,如何为Vue3后台系统设计一套统一的扫码登录方案?这个问题困扰着许多中大型企业的技术团队。我曾参与过某跨国企业的身份认证系统重…...

微波管参数全解析:什么是噪声系数?
摘要:上一篇我们聊了决定卫星生死的核心参数「效率」,今天来讲决定雷达、卫星性能下限的关键指标 ——噪声系数。为什么地面雷达能看清几百公里外一架几米长的飞机?为什么卫星能接收到地面几瓦发射机传来的微弱信号?答案从来不是 …...

为什么92%的AI研发团队知识平台半年内废弃?深度拆解3个致命设计盲区及修复方案
第一章:AI原生软件研发知识管理平台搭建 2026奇点智能技术大会(https://ml-summit.org) AI原生软件研发对知识的实时性、上下文感知性与可追溯性提出全新要求。传统Wiki或文档中心难以支撑模型训练日志、提示工程迭代、RAG索引变更、微调参数谱系等多模态研发资产的…...
|WPS宏支持|适配WPS2024+Win10 64位)
日立电梯05版规格表智能计算工具(升级版)|WPS宏支持|适配WPS2024+Win10 64位
温馨提示:文末有联系方式日立电梯05规格表工具升级版正式发布 全新优化的日立电梯05规格表计算软件现已上线,专为电梯设计、安装与维保工程师打造,大幅提升参数录入与校验效率。功能标识更直观,操作一目了然 所有计算模块、输入项…...
)
DDR5内存实战:如何优化读操作性能(附BL32模式配置指南)
DDR5内存实战:如何优化读操作性能(附BL32模式配置指南) 在服务器和高性能计算领域,内存子系统的性能调优往往是工程师们最关注的焦点之一。随着DDR5内存的普及,其更高的带宽和更低的功耗为系统性能带来了显著提升&…...
驱动应用程序设计)
基于STM32LXXX的数字电位器(TPL0401A-10QDCKRQ1)驱动应用程序设计
一、简介: TPL0401A-10QDCKRQ1 是德州仪器(TI)推出的一款车规级单通道数字电位器,主要面向STM32LXXX等低功耗平台。 二、主要技术特性: 核心规格:128抽头(7位分辨率)、10kΩ端到端电阻、IC接口、SC-70-6小型封装、车规级(AEC-Q100)[-40℃至+125℃]。 电气特性:工…...