IDEA项目实践——创建Java项目以及创建Maven项目案例、使用数据库连接池创建项目简介
系列文章目录
IDEA上面书写wordcount的Scala文件具体操作
IDEA创建项目的操作步骤以及在虚拟机里面创建Scala的项目简单介绍
目录
系列文章目录
前言
一 准备工作
1.1 安装Maven
1.1.1 Maven安装配置步骤
1.1.2 解压相关的软件包
1.1.3 Maven 配置环境变量
1.1.4 配置Maven的私服
1.2 创建一个本地的MySQL数据库和数据表
二 创建Java项目
2.1 方式一 数据库连接池druid
2.1.1 MySQL-connector-java资源分享链接
2.1.2 druid资源链接
2.2 创建Java项目步骤如下
2.2.1 创建项目目录
2.2.2 创建一个新的Java类
2.2.3 导入jar包
2.2.4 将jar包加载到library
2.2.5 编写Java代码
版本一
版本二
2.3 方式二 配置文件的形式加载
2.3.1 在src目录之下创建配置文件
2.3.2 在配置文件当中添加如下的信息
2.3.3 创建一个demo2的Java文件
2.3.4 编辑Java代码
三 在IDEA上创建Maven项目来实现上述的功能
3.1 创建项目
3.2 创建一个Java类
3.3 编辑Java代码和配置文件
3.4 Java代码模块讲解
3.4.1 Java Scanner 类
3.4.2 系统添加数据模块方法
3.4.3 编辑MySQL与druid依赖
3.4.4 编辑插入数据方法
3.4.5 编辑查询代码
3.4.6 完整的优化后的代码
思考——如何优化上述的Java代码?
总结
前言
本文主要介绍IDEA项目实践,创建Java项目以及创建Maven项目案例、使用数据库连接池创建项目简介
一 准备工作
1.1 安装Maven
Maven资源分享包
链接:https://pan.baidu.com/s/1D3SHLKTMTTUDYLv45EXgeg?pwd=kmdf
提取码:kmdf
1.1.1 Maven安装配置步骤
1. 解压 apache-maven-3.6.1.rar 既安装完成2. 配置环境变量 MAVEN_HOME 为安装 路径,在 Path 添加 %MAVEN_HOME%/bin 目录3. 配置本地仓库:修改 conf /settings.xml 中的 < localRepository > 为一个指定目录4. 配置阿里云私服:修改 conf /settings.xml 中的 <mirrors> 标签,为其添加如下子标签
1.1.2 解压相关的软件包
解压你的Maven包,放在你的文件夹里面,配置相关的本地仓库文件
1.1.3 Maven 配置环境变量
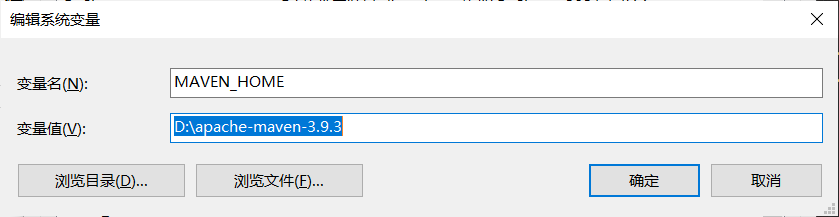
打开Windows1的高级设置,配置相关的环境变量
第一处
MAVEN_HOME
D:\apache-maven-3.9.3
第二处
Path
%MAVEN_HOME%/bin

1.1.4 配置Maven的私服
需要添加的内容如下:
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>先创建一个本地仓库文件夹【myRepository】你的仓库创建在你安装了Maven的地方。
在notepad++查找本地的【localRepository】
没有notepad++也可以使用记事本编辑,只要将内容修改完,并且保存完成即可。

在setting文件夹里面加入本地仓库位置
<localRepository>D:\apache-maven-3.9.3\myRepository</localRepository>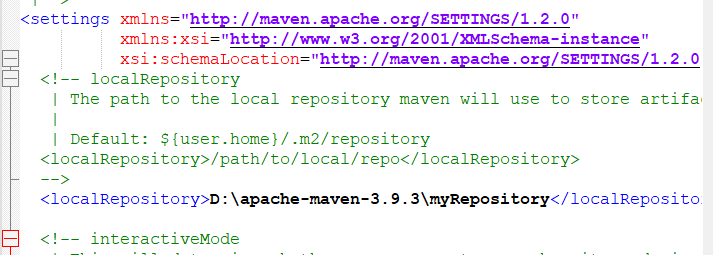
查找mirrors位置,修改为阿里的私服。
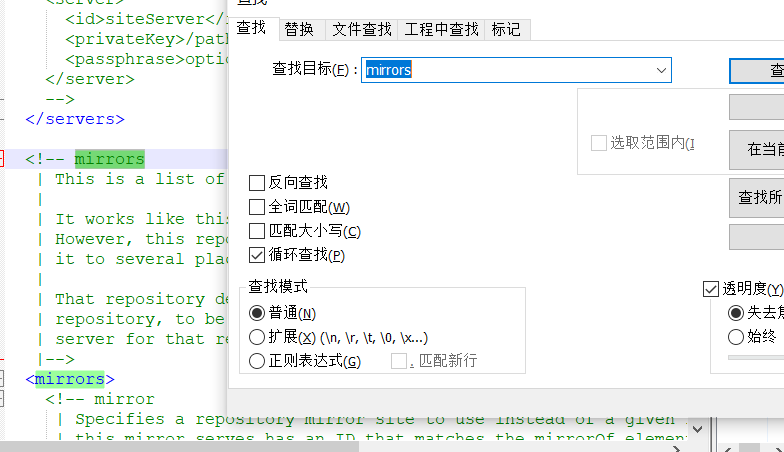
添加完成之后记得保存~

编辑完成之后退出。本地仓库就配置完成了。
1.2 创建一个本地的MySQL数据库和数据表
在此之前,需要配置本地MySQL服务的连接如下:
MySQL以及MySQL workbench的安装与配置【超详细安装教程】
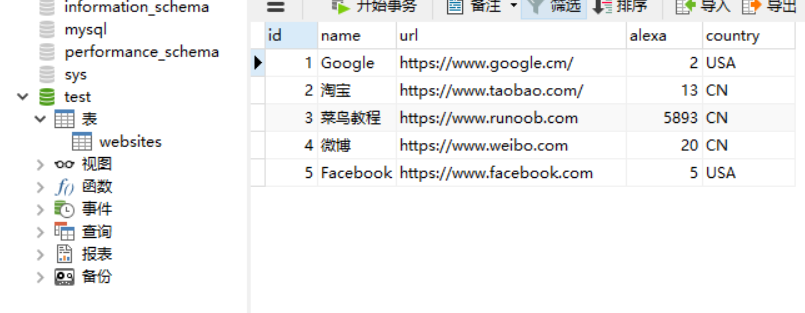
创建数据库和数据表的SQL语句
// 创建名为 test 的数据库
CREATE DATABASE test;
// 使用 test 数据库
USE test;
// 创建名为 websites 的表
CREATE TABLE `websites` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` char(20) NOT NULL DEFAULT '' COMMENT '站点名称',`url` varchar(255) NOT NULL DEFAULT '',`alexa` int(11) NOT NULL DEFAULT '0' COMMENT 'Alexa 排名',`country` char(10) NOT NULL DEFAULT '' COMMENT '国家',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
// 在 websites 中插入数据
INSERT INTO `websites` VALUES ('1', 'Google', 'https://www.google.cm/', '2', 'USA'),
('2', '淘宝', 'https://www.taobao.com/', '13', 'CN'),
('3', '菜鸟教程', 'http://www.runoob.com', '5892', 'CN'),
('4', '微博', 'http://weibo.com/', '20', 'CN'),
('5', 'Facebook', 'https://www.facebook.com/', '3', 'USA'),
('6', 'JueJin', 'https://www.juejin.cn/', '2213', 'CN');
创建之后的数据库如下图所示的界面:
二 创建Java项目
2.1 方式一 数据库连接池druid
创建步骤如下:
1. 导入jar包(mysql-connection-java.jar,druid.jar),同时加入到类加载路径中
2. 直接创建连接池对象:new对象 DruidDataSource
3. 然后设置属性。
1. setDriverClassName()
2. setUrl()
3. setUsername()
4. setPassword()
5. setInitialSize() //初始连接数
6. setMaxSize() //最大连接数
7. setMaxWait() //最大等待时间
4. 通过连接池对象,获取数据库连接
方式一的缺点:将MySQL的URL和用户以及密码是写死的,当你要修改的时候不好修改
2.1.1 MySQL-connector-java资源分享链接
MySQL-connector-java-8.0.31版本百度网盘连接
链接:https://pan.baidu.com/s/1A2NtVswiJjvxFB68GZ77Vw?pwd=wcmo
提取码:wcmo
MySQL-connector-java-5.1.49版本百度网盘连接
链接:https://pan.baidu.com/s/1FPL23h6Ca7_Y0N_HYZSm0Q?pwd=6kwi
提取码:6kwi
2.1.2 druid资源链接
druid-1.1.12版本
链接:https://pan.baidu.com/s/13Bwl-R3gN0fU5qHAGFHzwA?pwd=gu9g
提取码:gu9g
2.2 创建Java项目步骤如下
2.2.1 创建项目目录
选择创建Java文件
继续下一步
创建你的问价存储位置,此处建议专门写一个存放IDEA项目的文件夹。

2.2.2 创建一个新的Java类
在src文件里面创建一个新的Java类
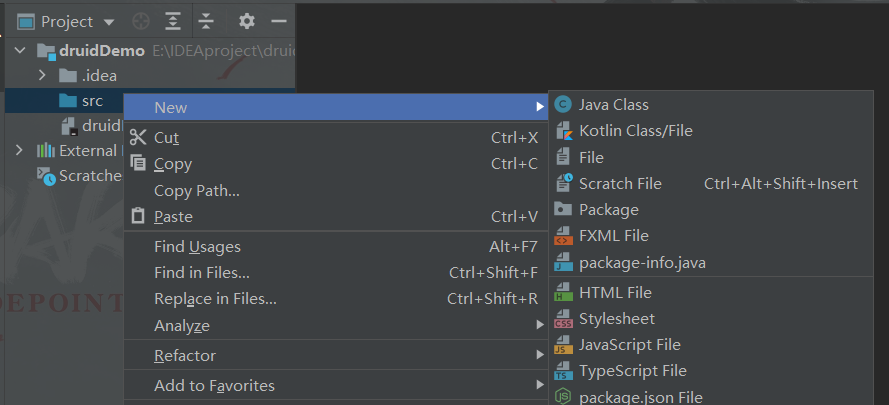
名字为: com.ambow.druid.DruidDemo
解释——前三个为包名称,后面为类名称。
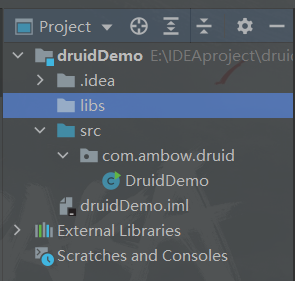
2.2.3 导入jar包
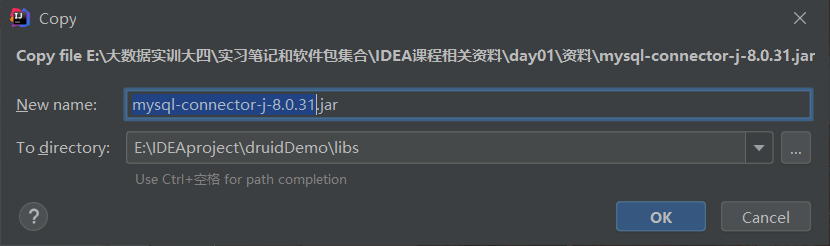
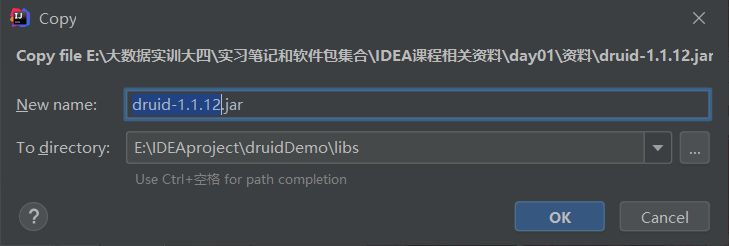
在项目里面新建一个文件夹导入前面的两个jar包【MySQL-connector-java-8.0.31和druid-1.1.12
】,需要自己创建一个libs文件夹存放这两个jar包。
此处记得选择自己的MySQL对应的Java包,下载之后,将两个jar包复制,将其粘贴在libs文件夹里面即可。
此处点击ok即可。
同上
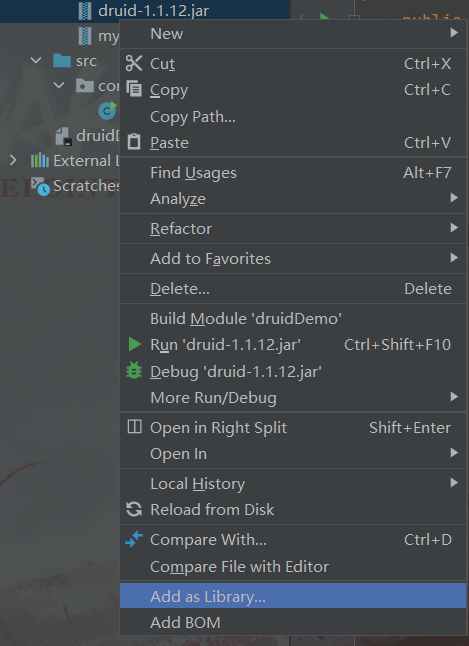
2.2.4 将jar包加载到library
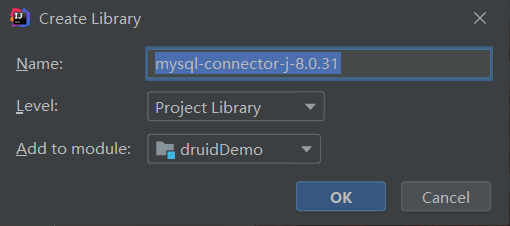
在两个jar包上面,鼠标右键,选择as a library加载
点击OK即可

2.2.5 编写Java代码
版本一
package com.ambow.druid;
import java.sql.*;
//方式一: druid的数据库连接池
public class DruidDemo {// MySQL 8.0 以下版本 - JDBC 驱动名及数据库 URL
// static final String JDBC_DRIVER = "com.mysql.jdbc.Driver";
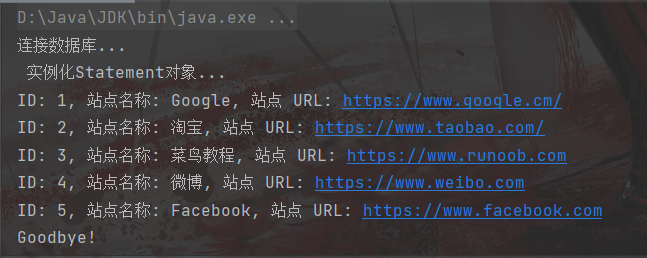
// static final String DB_URL = "jdbc:mysql://localhost:3306/test";// MySQL 8.0 以上版本 - JDBC 驱动名及数据库 URLstatic final String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver";static final String DB_URL = "jdbc:mysql://localhost:3306/test?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC";// 数据库的用户名与密码,需要根据自己的设置static final String USER = "root";static final String PASS = "root";public static void main(String[] args) {Connection conn = null;Statement stmt = null;try {// 注册 JDBC 驱动Class.forName(JDBC_DRIVER);// 打开链接System.out.println("连接数据库...");conn = DriverManager.getConnection(DB_URL, USER, PASS);// 执行查询System.out.println(" 实例化Statement对象...");stmt = conn.createStatement();String sql;sql = "SELECT id, name, url FROM websites";ResultSet rs = stmt.executeQuery(sql);// 展开结果集数据库while (rs.next()) {// 通过字段检索int id = rs.getInt("id");String name = rs.getString("name");String url = rs.getString("url");// 输出数据System.out.print("ID: " + id);System.out.print(", 站点名称: " + name);System.out.print(", 站点 URL: " + url);System.out.print("\n");}// 完成后关闭rs.close();stmt.close();conn.close();} catch (SQLException se) {// 处理 JDBC 错误se.printStackTrace();} catch (Exception e) {// 处理 Class.forName 错误e.printStackTrace();} finally {// 关闭资源try {if (stmt != null) stmt.close();} catch (SQLException se2) {}// 什么都不做try {if (conn != null) conn.close();} catch (SQLException se) {se.printStackTrace();}}System.out.println("Goodbye!");}
}运行结果如下:
版本二
代码演示
package com.ambow.druid;import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidPooledConnection;import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/*方式一: 直接创建DruidDataSource ,然后设置属性*/
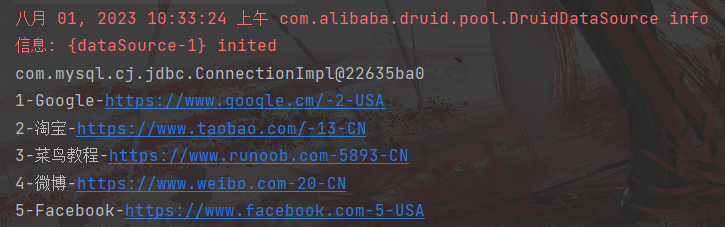
public class DruidDemo {public static void main(String[] args) throws SQLException {DruidDataSource dds = new DruidDataSource();dds.setDriverClassName("com.mysql.cj.jdbc.Driver");dds.setUrl("jdbc:mysql://localhost:3306/test?serverTimezone=UTC");dds.setUsername("root");dds.setPassword("root");dds.setInitialSize(5);//初识连接数dds.setMaxActive(10);//最大连接数dds.setMaxWait(3000);//最大等待时间//获取连接DruidPooledConnection connection = dds.getConnection();System.out.println(connection);//获取执行语句对象String sql = "select * from websites";PreparedStatement pstmt = connection.prepareStatement(sql);//获取结果集ResultSet rs = pstmt.executeQuery();while (rs.next()){System.out.println(rs.getInt(1) + "-" + rs.getString(2) + "-" + rs.getString(3) + "-" + rs.getInt(4) + "-" + rs.getString(5));}/*jdbc连接的四个参数:driverurlusernamepassword*/}
}运行结果:
2.3 方式二 配置文件的形式加载
- 导入jar包 mysql-connection-java.jar、druid-1.1.12.jar
- 定义配置文件
- 加载配置文件
- 获取数据库连接池对象
- 获取连接
此处的代码实现,首先也需要先将druid的jar包放到项目下的lib下并添加为库文件,与前面一样的形式创建。
2.3.1 在src目录之下创建配置文件

文件名称为: druid.properties
PS:Java里面的配置文件为properties类型

2.3.2 在配置文件当中添加如下的信息
将用户以及密码哪些信息写入配置文件
此处为8.0以上版本的书写方法
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql:///test?serverTimezone=UTC
username=root
password=root
# 初始化连接数量
initialSize=5
# 最大连接数
maxActive=10
# 最大等待时间
maxWait=3000以下为5.1 版本的写法【举例如下】
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://182.168.1.1/test
username=root
password=root
# ???????
initialSize=5
# ?????
maxActive=10
# ??????
maxWait=3000//前面的是IP地址以及数据库的名称2.3.3 创建一个demo2的Java文件
2.3.4 编辑Java代码
此处只是一个获取连接的代码
package com.ambow.druid;import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.util.Properties;/*方式二:提取配置文件(把连接数据库的参数,抽取出来)*/
public class DruidDemo2 {public static void main(String[] args) throws Exception {//获取当前项目的根目录System.out.println(System.getProperty("user.dir"));// 加载配置文件Properties prop = new Properties();//FileInputStream is = new FileInputStream("src/druid.properties");InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");prop.load(is);// 获取数据库连接池对象DataSource ds = DruidDataSourceFactory.createDataSource(prop);// 获取连接Connection connection = ds.getConnection();System.out.println(connection);}
}
运行结果:

注意:
System.getProperty("user.dir"),在web项目,返回值就不是项目的根目录了,而是tomcat的bin目录。
三 在IDEA上创建Maven项目来实现上述的功能
3.1 创建项目
在file里面选择创建新的项目,选择Maven项目

填写项目的名称,以及公司名称
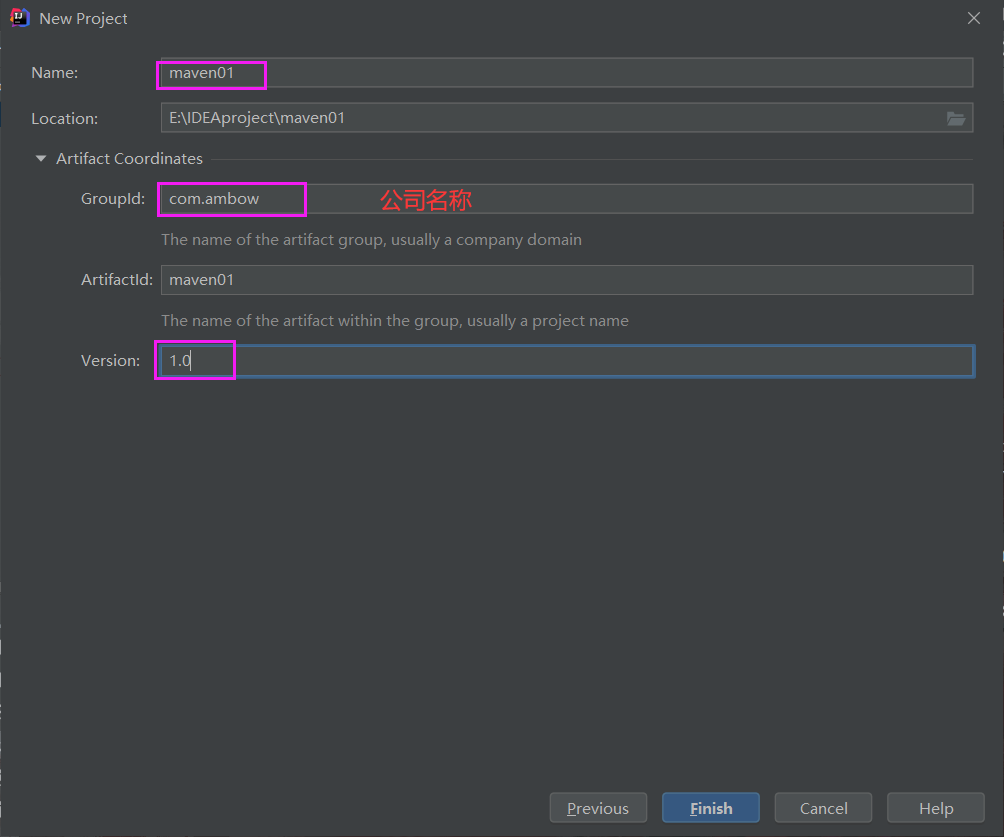
点击finsh即可。
此处补全一个资源文件夹

3.2 创建一个Java类
3.3 编辑Java代码和配置文件
编辑配置文件的方法与2.3.2 一样,此处不再赘述。
在刚才的类里面编辑Java代码
package com.ambow.druid;import java.sql.*;
import java.util.Scanner;public class App {static final String JDBC_DRIVER="com.mysql.cj.jdbc.Driver";static final String DB_URL="jdbc:mysql://localhost:3306/test";static final String USER = "root";static final String PASS ="root";static Scanner sc =new Scanner(System.in);//成为类成员前面加入static修饰public static void main(String[] args) throws SQLException {
// DruidDataSource dds = new DruidDataSource();
// dds.setDriverClassName("com.mysql.jdbc.Driver");
// dds.setUrl("jdbc:mysql://192.168.127.100:3306/db2");
// dds.setUsername("root");
// dds.setPassword("Admin2023!");
// dds.setInitialSize(5);
// dds.setMaxActive(10);
// dds.setMaxWait(3000);
// DruidPooledConnection connection = dds.getConnection();
// System.out.println(connection);//加入循环while (true) {System.out.println("***********************************");System.out.println("*********** 站点管理系统 ***********");System.out.println("*********** 1.新增站点 ***********");System.out.println("*********** 2.修改站点 ***********");System.out.println("*********** 3.删除站点 ***********");System.out.println("*********** 4.查询站点 ***********");System.out.println("*********** 0.退出系统 ***********");System.out.println("**********************************");System.out.println("请选择:");//静态方法只能访问静态变量int choose = sc.nextInt();switch (choose){case 1:addWebSite();break;case 2:modifyWebSite();break;case 3:dropWebSite();break;case 4:queryWebSite();break;case 0:System.out.println("退出系统");System.exit(0);break;default:System.out.println("对不起,您的选择有误!");break;}}}// String sql ="select * from websites";
// PreparedStatement pstmt =connection.prepareStatement(sql);
// ResultSet rs = pstmt.executeQuery();
// while (rs.next()){
// System.out.println(rs.getInt(1) +"-"+ rs.getString(2) +"-"+ rs.getString(3)
// +"-"+ rs.getInt(4) +"-"+ rs.getString(5));
// }
// rs.close();
// pstmt.close();
// connection.close();
// }private static void addWebSite() {System.out.println("请输入站点名称:");String name = sc.next();System.out.println("请输入站点URL:");String url = sc.next();System.out.println("请输入站点alexa:");int alexa = sc.nextInt();System.out.println("请输入站点所属国家:");String country = sc.next();Connection conn = null;PreparedStatement pstmt = null;try {Class.forName((JDBC_DRIVER));conn = DriverManager.getConnection(DB_URL, USER, PASS);String sql ="insert into websites values(null,?,?,?,?)";pstmt = conn.prepareStatement(sql);pstmt.setString(1,name);pstmt.setString(2,url);pstmt.setInt(3,alexa);pstmt.setString(4,country);pstmt.executeUpdate();System.out.println("添加站点成功!");}catch (SQLException se){se.printStackTrace();}catch (Exception e){e.printStackTrace();}finally {try{if(pstmt!=null) pstmt.close();}catch (SQLException se2){}try{if(conn!=null) conn.close();}catch (SQLException se){se.printStackTrace();}}}private static void modifyWebSite() {System.out.println("请输入要修改的站点名称:");String name = sc.next();System.out.println("请输入新站点URL:");String url = sc.next();System.out.println("请输入新站点alexa:");int alexa = sc.nextInt();System.out.println("请输入新站点所属国家:");String country = sc.next();Connection conn = null;PreparedStatement pstmt = null;try {Class.forName((JDBC_DRIVER));conn = DriverManager.getConnection(DB_URL, USER, PASS);String sql ="update websites set url=?,alexa= ?,country=? where name=?";pstmt = conn.prepareStatement(sql);pstmt.setString(1,name);pstmt.setString(2,url);pstmt.setInt(3,alexa);pstmt.setString(4,country);pstmt.executeUpdate();System.out.println("修改站点成功!");}catch (SQLException se){se.printStackTrace();}catch (Exception e){e.printStackTrace();}finally {try{if(pstmt!=null) pstmt.close();}catch (SQLException se2){}try{if(conn!=null) conn.close();}catch (SQLException se){se.printStackTrace();}}}private static void dropWebSite() {System.out.println("请输入要删除的站点名称:");String name = sc.next();
// System.out.println("请输入站点URL:");
// String url = sc.next();
// System.out.println("请输入站点alexa:");
// int alexa = sc.nextInt();
// System.out.println("请输入站点所属国家:");
// String country = sc.next();Connection conn = null;PreparedStatement pstmt = null;try {Class.forName((JDBC_DRIVER));conn = DriverManager.getConnection(DB_URL, USER, PASS);String sql ="delete from websites where name=?";pstmt = conn.prepareStatement(sql);pstmt.setString(1,name);
// pstmt.setString(2,url);
// pstmt.setInt(3,alexa);
// pstmt.setString(4,country);pstmt.executeUpdate();System.out.println("删除站点成功!");}catch (SQLException se){se.printStackTrace();}catch (Exception e){e.printStackTrace();}finally {try{if(pstmt!=null) pstmt.close();}catch (SQLException se2){}try{if(conn!=null) conn.close();}catch (SQLException se){se.printStackTrace();}}}private static void queryWebSite() {
// System.out.println("请输入要查询的站点名称:");
// String name = sc.next("name");
// System.out.println("请输入站点URL:");
// String url = sc.next("url");
// System.out.println("请输入站点alexa:");
// int alexa = sc.nextInt(Integer.parseInt("alexa"));
// System.out.println("请输入站点所属国家:");
// String country = sc.next("country");Connection conn = null;PreparedStatement pstmt = null;try {Class.forName((JDBC_DRIVER));conn = DriverManager.getConnection(DB_URL, USER, PASS);Statement stmt = conn.createStatement();String sql ="SELECT id,name,url FROM websites";ResultSet rs = stmt.executeQuery(sql);//pstmt = conn.prepareStatement(sql);
// pstmt.setString(name);
// pstmt.setString(2,url);
// pstmt.setInt(3,alexa);
// pstmt.setString(4,country);
// System.out.print("name");
// System.out.print("url");
// System.out.print("alexa");
// System.out.print("country");
// System.out.print("\n");//pstmt.executeQuery();// System.out.println("查询站点成功!");while (rs.next()){int id =rs.getInt("id");String name = rs.getString("name");String url = rs.getString("url");System.out.print("id"+":"+id+"-");System.out.print("name"+":"+name+"-");System.out.print("url"+":"+url);System.out.print("\n");System.out.println("查询站点成功!");}rs.close();stmt.close();conn.close();}catch (SQLException se){se.printStackTrace();}catch (Exception e){e.printStackTrace();}finally {try{if(pstmt!=null) pstmt.close();}catch (SQLException se2){}try{if(conn!=null) conn.close();}catch (SQLException se){se.printStackTrace();}}}
}
运行结果如下:

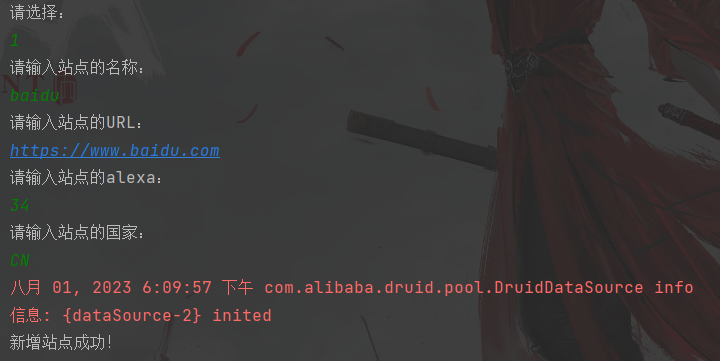
查看MySQL里面的表信息可以看到信息添加成功了。

修改站点信息
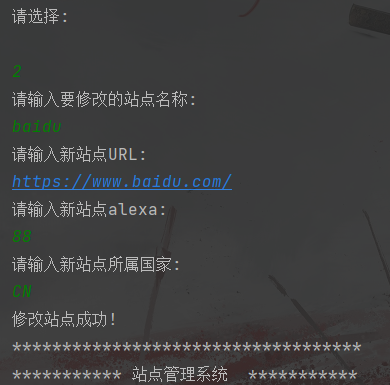
删除站点

删除之后的恢复为原来的情况
最后退出系统。

3.4 Java代码模块讲解
3.4.1 Java Scanner 类
java.util.Scanner 是 Java5 的新特征,我们可以通过 Scanner 类来获取用户的输入。
下面是创建 Scanner 对象的基本语法:
Scanner s = new Scanner(System.in);Scanner 类的 next() 与 nextLine() 方法获取输入的字符串,在读取数据前我们一般需要 使用 hasNext 与 hasNextLine 判断是否还有输入的数据。
next() 、nextInt() 、nextLine() 区别
next():
- 1、一定要读取到有效字符后才可以结束输入。
- 2、对输入有效字符之前遇到的空白,next() 方法会自动将其去掉。
- 3、只有输入有效字符后才将其后面输入的空白作为分隔符或者结束符。
- next() 不能得到带有空格的字符串。
nextLine():
- 1、以Enter为结束符,也就是说 nextLine()方法返回的是输入回车之前的所有字符。
- 2、可以获得空白。
如果要输入 int 或 float 类型的数据,在 Scanner 类中也有支持,但是在输入之前最好先使用 hasNextXxx() 方法进行验证,再使用 nextXxx() 来读取。
nextInt()、nextLine()区别:
- 1.nextInt()只会读取数值,剩下"\n"还没有读取,并将cursor放在本行中。
- 2.nextLine()会读取"\n",并结束(nextLine() reads till the end of line \n)。
- 3.如果想要在nextInt()后读取一行,就得在nextInt()之后额外加上cin.nextLine()
nextInt() 一定要读取到有效字符后才可以结束输入,对输入有效字符之前遇到的空格键、Tab键或Enter键等结束符,nextInt() 方法会自动将其去掉,只有在输入有效字符之后,nextInt()方法才将其后输入的空格键、Tab键或Enter键等视为分隔符或结束符。简单地说,nextInt()查找并返回来自此扫描器的下一个完整标记。完整标记的前后是与分隔模式匹配的输入信息,所以next方法不能得到带空格的字符串。
而nextLine() 方法的结束符只是Enter键,即nextLine() 方法返回的是Enter键之前的所有字符,它是可以得到带空格的字符串的。
可以看到,nextLine() 自动读取了被nextInt() 去掉的Enter作为他的结束符,所以没办法给s2从键盘输入值。经过验证,我发现其他的next的方法,如double nextDouble() , float nextFloat() , int nextInt() 等与nextLine() 连用时都存在这个问题,解决的办法是:在每一个 next() 、nextDouble() 、 nextFloat()、nextInt() 等语句之后加一个nextLine() 语句,将被next() 去掉的Enter结束符过滤掉。
此处使用的是scanner对象的nextInt()方法,使用switch-case分支进行判断需要执行的选项是那个。
Scanner sc =new Scanner(System.in);int choose = sc.nextInt();switch (choose){case 1:addWebSite();break;case 2:modifyWebSite();break;case 3:dropWebSite();break;case 4:queryWebSite();break;case 0:System.out.println("退出系统");System.exit(0);break;default:System.out.println("对不起,您的选择有误!");break;}在新定义的方法上面按住alt+回车既可以出现快捷方式,点击第一个创建一个方法。

创建完成之后新增while(true)让程序可以一直执行,程序的中断将会由输入的0来决定退出去。
完整的这一块代码
public static void main(String[] args) throws SQLException {while (true) {System.out.println("***********************************");System.out.println("*********** 站点管理系统 ***********");System.out.println("*********** 1.新增站点 ***********");System.out.println("*********** 2.修改站点 ***********");System.out.println("*********** 3.删除站点 ***********");System.out.println("*********** 4.查询站点 ***********");System.out.println("*********** 0.退出系统 ***********");System.out.println("**********************************");System.out.println("请选择:");Scanner sc =new Scanner(System.in);int choose = sc.nextInt();switch (choose){case 1:addWebSite();break;case 2:modifyWebSite();break;case 3:dropWebSite();break;case 4:queryWebSite();break;case 0:System.out.println("退出系统");System.exit(0);break;default:System.out.println("对不起,您的选择有误!");break;}}}3.4.2 系统添加数据模块方法
例如以下的方法
private static void dropWebSite() {System.out.println("请输入要删除的站点名称:");//sc.next方法将不会用到//前面设置的sc变量是只能在main方法里面使用,要想使用需要将sc变量放在外面使用
}解决方法:将sc变量放在main方法外面即可。变成整个类的作用方法
虽然提出来了,但是scanner的方法仍然不能使用,会出错,原因是sc为成员变量,main是静态的方法,静态的方法只能访问静态的方法,不能访问类里面的变量,需要将scanner变成一个静态的变量。
加入关键字static即可访问其方法

接下来继续编写方法原来实现相关功能
3.4.3 编辑MySQL与druid依赖
官方的网站链接如下:
Maven Repository: Search/Browse/Explore (mvnrepository.com)
在官方网站里面直接搜素需要的依赖即可
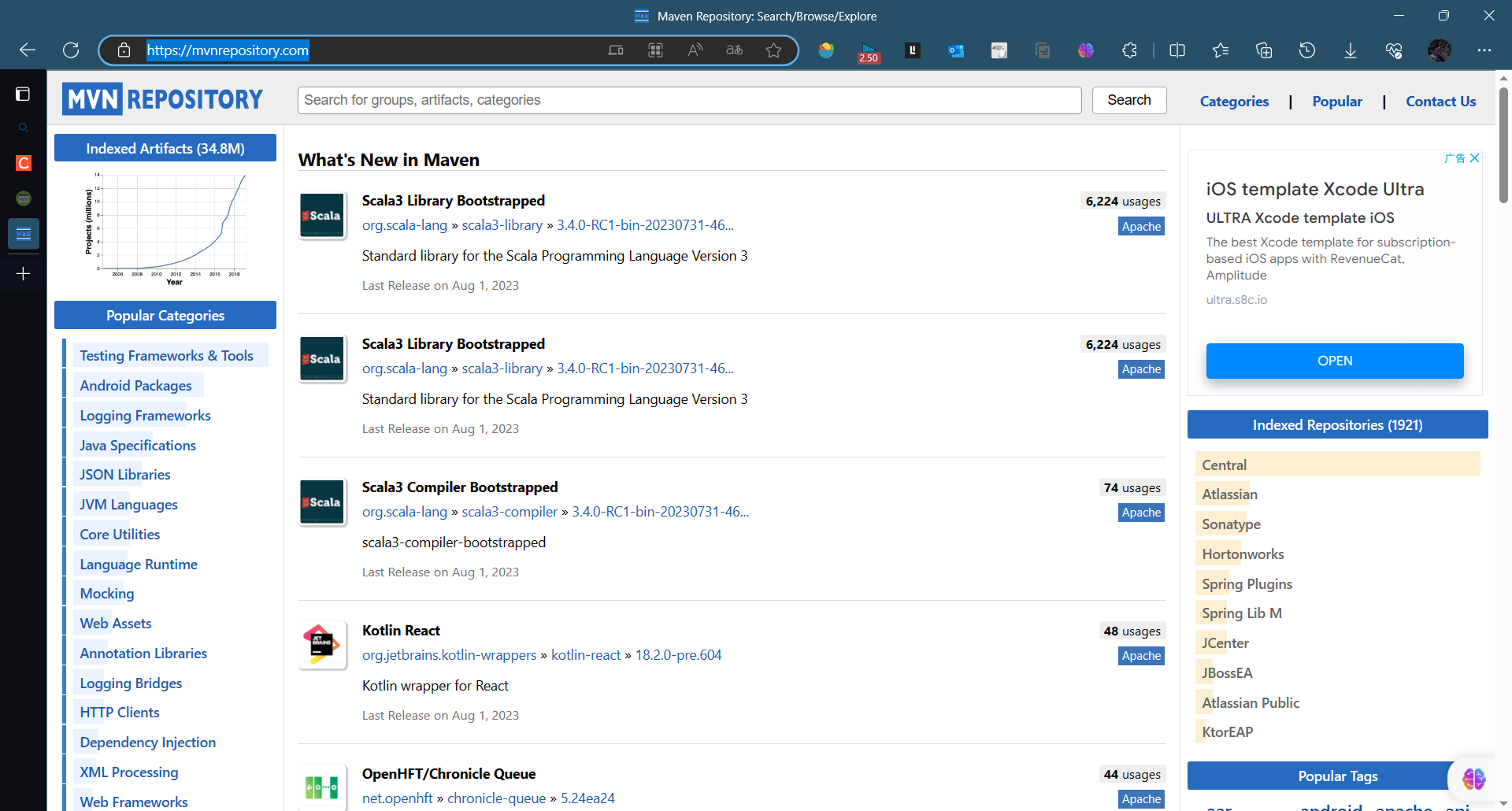
选择mysql搜素,选择访问比较多的即可

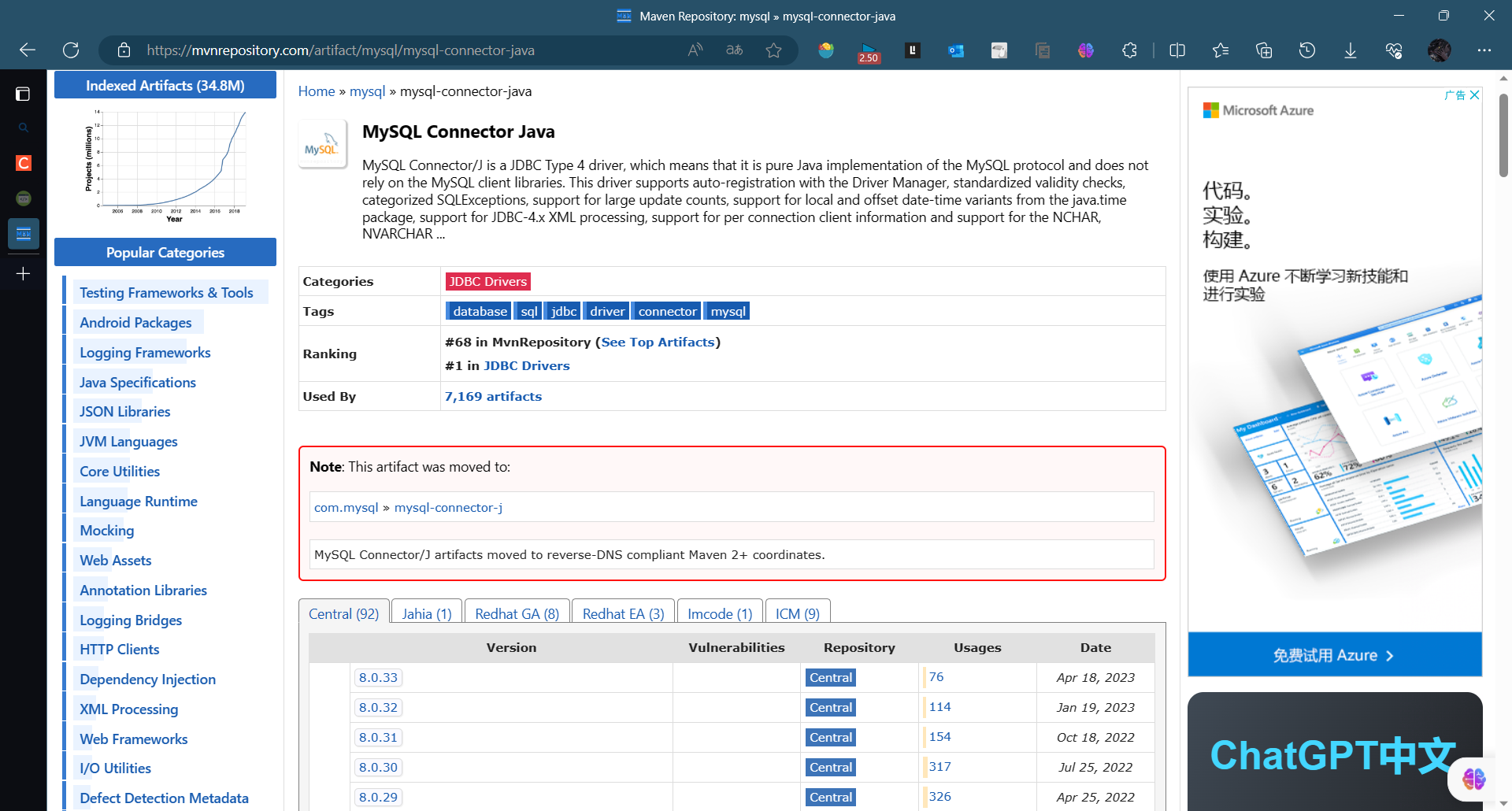 红色框住的是8.0版本以上的,选择自己的对应版本即可。此处小编的版本为8.0的版本,选择这个即可
红色框住的是8.0版本以上的,选择自己的对应版本即可。此处小编的版本为8.0的版本,选择这个即可


点击此处蓝色框住的部分即可复制,出现红色的提示即是复制成功
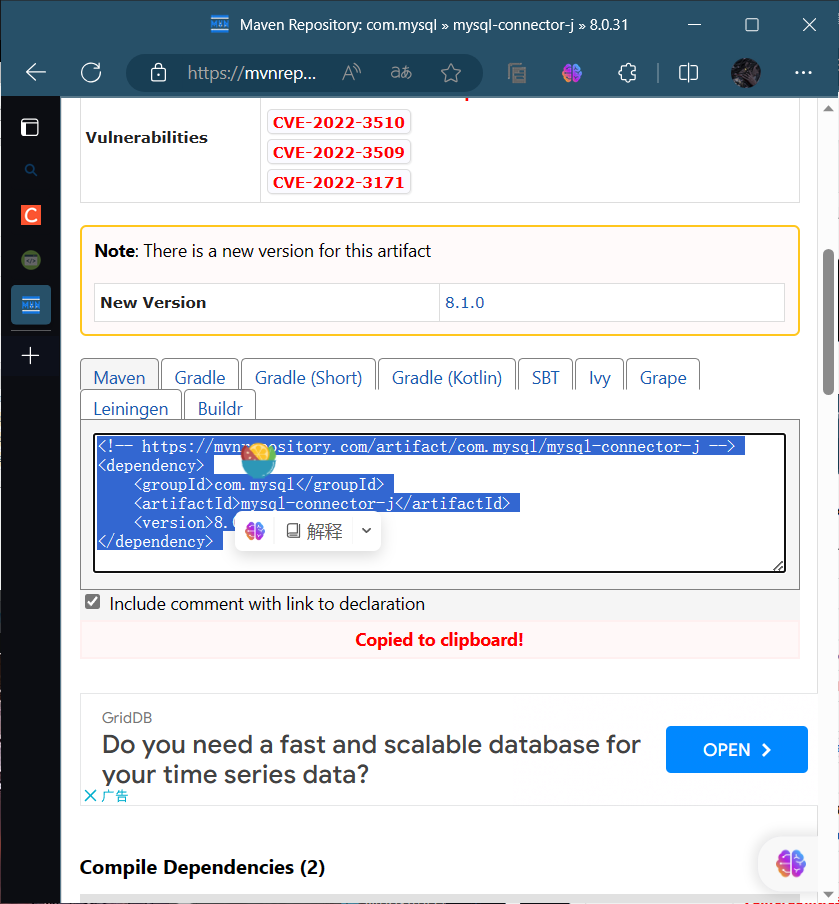
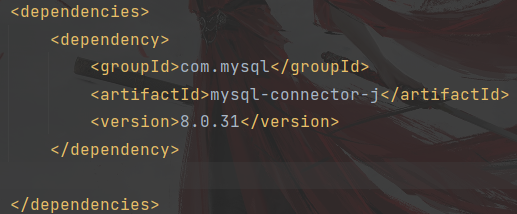
代码部分
<dependencies><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>8.0.31</version></dependency></dependencies>粘贴过来的显示为红色,如果之前未安装此组件的话,会有一个刷新的图标,点击一下,完成安装,安装完成之后红色部分会变成白色。
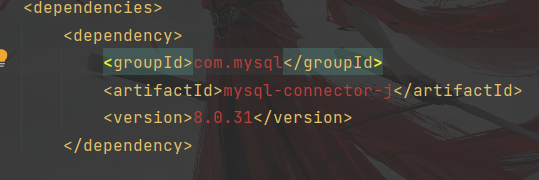
出现这种情况既是安装完成。
搜索druid依赖,点击第一个即可
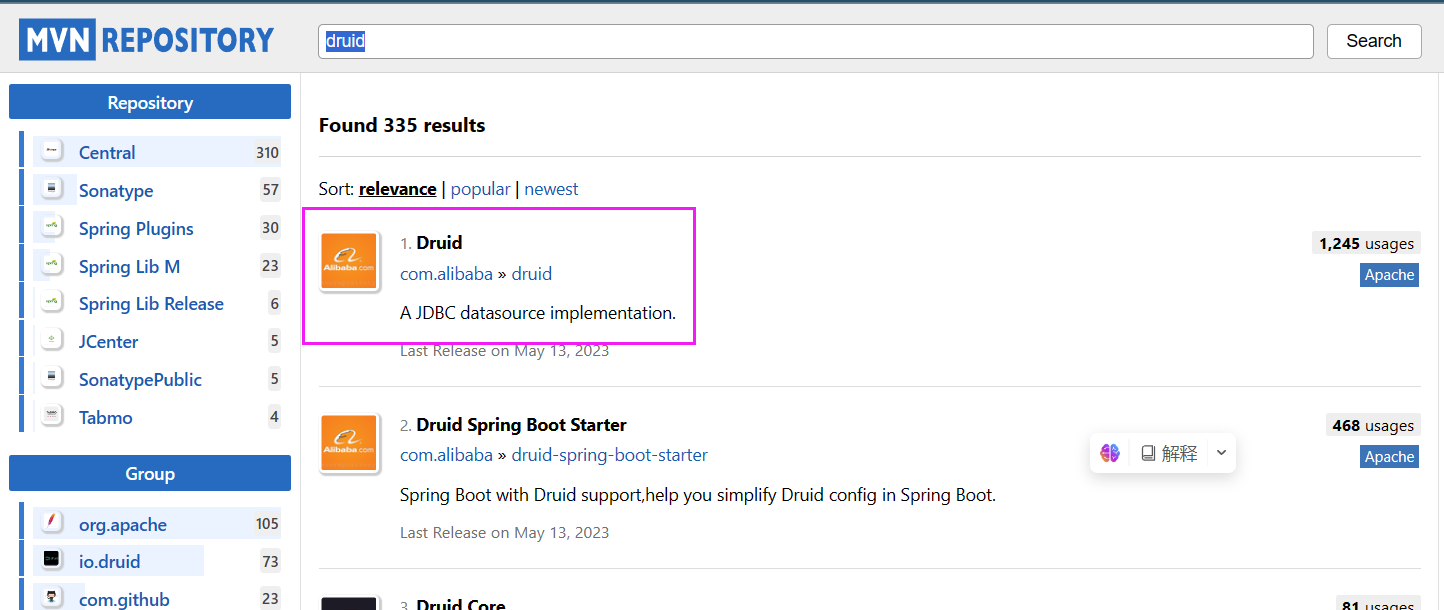
选择自己的对应版本
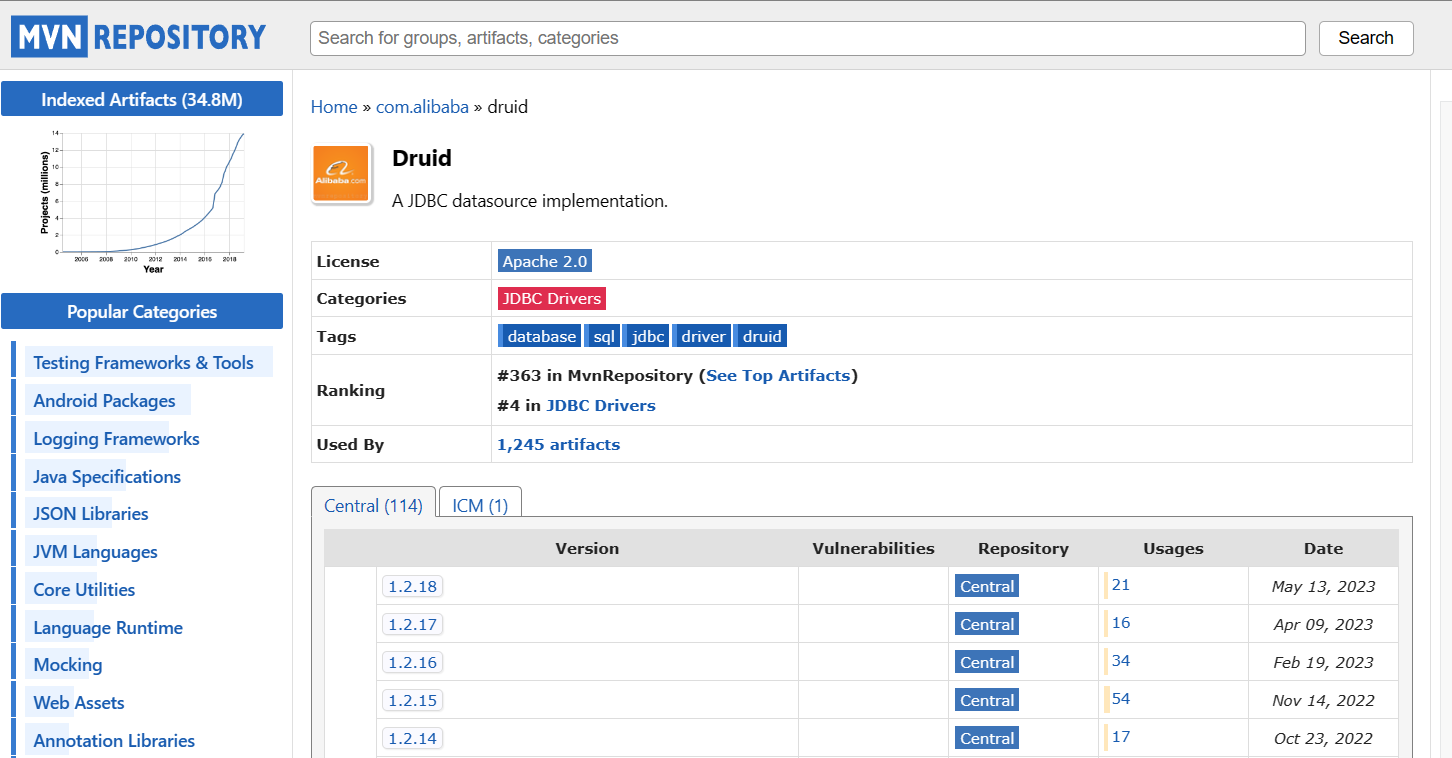

代码部分如下:
<!-- https://mvnrepository.com/artifact/com.alibaba/druid --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.8</version></dependency>粘贴上述代码即可。
3.4.4 编辑插入数据方法
前面先给用户一个输入区,并且将输入的内容编辑为相关的变量暂时存在内存区,此时的数据并没有保存到数据库里面。

下面加入配置文件原来访问数据库,设置与前面的2.3.2 编辑配置文件相同。
利用类加载器原来加载配置文件,让文件以流的形式读进来,
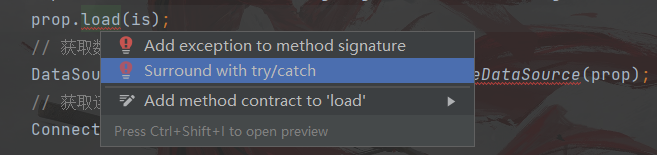
选择alt+enter,选择第二个,让异常抛出
此处还有异常,将异常的这段代码放在try-catch里面捕获一下抛出
这样捕获异常

捕获完成之后会自动放在catch语句里面
// 加载配置文件Properties prop = new Properties();InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");try {prop.load(is);// 获取数据库连接池对象DataSource ds = DruidDataSourceFactory.createDataSource(prop);// 获取连接Connection connection = ds.getConnection();} catch (IOException e) {e.printStackTrace();} catch (SQLException throwables) {throwables.printStackTrace();} catch (Exception e) {e.printStackTrace();}
此处创建一个预编译对象
完成之后使用其方法获取相关的数据,将其插入到数据库里面。
完整的插入代码
private static void addWebSite() {System.out.println("请输入站点名称:");String name = sc.next();System.out.println("请输入站点URL:");String url = sc.next();System.out.println("请输入站点alexa:");int alexa = sc.nextInt();System.out.println("请输入站点所属国家:");String country = sc.next();// 1 加载配置文件Properties prop = new Properties();InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");try {prop.load(is);// 2 获取数据库连接池对象DataSource ds = DruidDataSourceFactory.createDataSource(prop);// 3 获取连接Connection connection = ds.getConnection();// 4 执行SQL//插入SQL语句,?为占位符String sql ="insert into websites values(null,?,?,?,?)";//创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。PreparedStatement stmt = connection.prepareStatement(sql);//设置参数stmt.setString(1,name);stmt.setString(2,url);stmt.setInt(3,alexa);stmt.setString(4,country);stmt.executeUpdate();// 获取插入完成的值,一般插入完成之后会出现·插入影响的行数// 将返回变量的类型设置为int型int row = stmt.executeUpdate();//提示一下if (row != 0){System.out.println("添加站点成功!");}} catch (IOException e) {e.printStackTrace();} catch (SQLException throwables) {throwables.printStackTrace();} catch (Exception e) {e.printStackTrace();}
}3.4.5 编辑查询代码
PS:此处为未经优化的代码段 ,后续有优化之后的代码段。
在上述的插入代码的基础之上编辑查询代码即可。
private static void queryWebSite() {// 1 加载配置文件Properties prop = new Properties();InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");try {prop.load(is);// 2 获取数据库连接池对象DataSource ds = DruidDataSourceFactory.createDataSource(prop);// 3 获取连接Connection connection = ds.getConnection();// 4 执行SQL//插入SQL语句,?为占位符String sql ="select * from websites";//创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。PreparedStatement stmt = connection.prepareStatement(sql);//设置返回的参数,此处的返回值为结果集ResultSet rs = stmt.executeQuery();// 获取查询到的结果集while (rs.next()){// 将结果集拼接起来System.out.println(rs.getInt(1) + "-" + rs.getString(2) + "-" + rs.getString(3)+ "-" + rs.getInt(4) + "-" + rs.getString(5));}} catch (IOException e) {e.printStackTrace();} catch (SQLException throwables) {throwables.printStackTrace();} catch (Exception e) {e.printStackTrace();}}此处的获取数据库连接可以创建一个DruidUtil类来专门获取数据库连接
工具类的完整代码【此处就是将获取数据库连接的部分一一个类的形式创建,此时可以优化一下之前的代码】
优化之后的插入数据代码
private static void addWebSite() {System.out.println("请输入站点名称:");String name = sc.next();System.out.println("请输入站点URL:");String url = sc.next();System.out.println("请输入站点alexa:");int alexa = sc.nextInt();System.out.println("请输入站点所属国家:");String country = sc.next();try {// 3 获取连接,此处使用类方法进行调用。Connection connection = DruidUtil.getConn();// 4 执行SQL//插入SQL语句,?为占位符String sql ="insert into websites values(null,?,?,?,?)";//创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。PreparedStatement stmt = connection.prepareStatement(sql);//设置参数stmt.setString(1,name);stmt.setString(2,url);stmt.setInt(3,alexa);stmt.setString(4,country);stmt.executeUpdate();// 获取插入完成的值,一般插入完成之后会出现·插入影响的行数// 将返回变量的类型设置为int型int row = stmt.executeUpdate();//提示一下if (row != 0){System.out.println("添加站点成功!");}// 原先的异常处理也就不再需要,直接删除即可} catch (SQLException throwables) {throwables.printStackTrace();} catch (Exception e) {e.printStackTrace();}}优化之后的查询代码
private static void queryWebSite() {try {// 3 获取连接Connection connection = DruidUtil.getConn();// 4 执行SQL//插入SQL语句,?为占位符String sql ="select * from websites";//创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。PreparedStatement stmt = connection.prepareStatement(sql);//设置返回的参数,此处的返回值为结果集ResultSet rs = stmt.executeQuery();// 获取查询到的结果集while (rs.next()){// 将结果集拼接起来System.out.println(rs.getInt(1) + "-" + rs.getString(2) + "-" + rs.getString(3)+ "-" + rs.getInt(4) + "-" + rs.getString(5));}} catch (SQLException throwables) {throwables.printStackTrace();} catch (Exception e) {e.printStackTrace();}}3.4.6 完整的优化后的代码
package com.ambow.druid;import java.sql.*;
import java.util.Scanner;public class work01 {static Scanner sc =new Scanner(System.in);public static void main(String[] args){while(true) {System.out.println("***********************************");System.out.println("*********** 站点管理系统 ***********");System.out.println("*********** 1.新增站点 ***********");System.out.println("*********** 2.修改站点 ***********");System.out.println("*********** 3.删除站点 ***********");System.out.println("*********** 4.查询站点 ***********");System.out.println("*********** 0.退出系统 ***********");System.out.println("**********************************");System.out.println("请选择:");Scanner sc = new Scanner(System.in);int choose = sc.nextInt();switch (choose) {case 1:addWebSite();break;case 2:modifyWebSite();break;case 3:dropWebSite();break;case 4:queryWebSite();break;case 0:System.out.println("退出系统");System.exit(0);break;default:System.out.println("对不起,您的选择有误!");break;}}}private static void addWebSite() {System.out.println("请输入站点名称:");String name = sc.next();System.out.println("请输入站点URL:");String url = sc.next();System.out.println("请输入站点alexa:");int alexa = sc.nextInt();System.out.println("请输入站点所属国家:");String country = sc.next();try {// 3 获取连接,此处使用类方法进行调用。Connection connection = DruidUtil.getConn();// 4 执行SQL//插入SQL语句,?为占位符String sql ="insert into websites values(null,?,?,?,?)";//创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。PreparedStatement stmt = connection.prepareStatement(sql);//设置参数stmt.setString(1,name);stmt.setString(2,url);stmt.setInt(3,alexa);stmt.setString(4,country);stmt.executeUpdate();// 获取插入完成的值,一般插入完成之后会出现·插入影响的行数// 将返回变量的类型设置为int型int row = stmt.executeUpdate();//提示一下if (row != 0){System.out.println("添加站点成功!");}// 原先的异常处理也就不再需要,直接删除即可} catch (SQLException e) {e.printStackTrace();} catch (Exception e) {e.printStackTrace();}}private static void modifyWebSite() {System.out.println("请输入要修改的站点名称:");String name = sc.next();System.out.println("请输入新站点URL:");String url = sc.next();System.out.println("请输入新站点alexa:");int alexa = sc.nextInt();System.out.println("请输入新站点所属国家:");String country = sc.next();try {// 3 获取连接Connection connection = DruidUtil.getConn();// 4 执行SQL//插入SQL语句,?为占位符String sql ="update websites set url=?,alexa= ?,country=? where name=?";//创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。PreparedStatement stmt = connection.prepareStatement(sql);//设置参数stmt = connection.prepareStatement(sql);stmt.setString(1,name);stmt.setString(2,url);stmt.setInt(3,alexa);stmt.setString(4,country);stmt.executeUpdate();int row = stmt.executeUpdate();//提示一下if (row != 0){System.out.println("修改站点成功!");}} catch (SQLException e) {e.printStackTrace();} catch (Exception e) {e.printStackTrace();}}private static void dropWebSite() {System.out.println("请输入要删除的站点名称:");String name = sc.next();try {// 3 获取连接Connection connection = DruidUtil.getConn();// 4 执行SQL//插入SQL语句,?为占位符String sql ="delete from websites where name=?";//创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。PreparedStatement stmt = connection.prepareStatement(sql);//设置参数stmt.setString(1,name);stmt.executeUpdate();// 获取插入完成的值,一般插入完成之后会出现·插入影响的行数// 将返回变量的类型设置为int型int row = stmt.executeUpdate();//提示一下if (row != 0){System.out.println("删除站点成功!");}} catch (SQLException e) {e.printStackTrace();} catch (Exception e) {e.printStackTrace();}}private static void queryWebSite() {try {// 3 获取连接Connection connection = DruidUtil.getConn();// 4 执行SQL//插入SQL语句,?为占位符String sql ="select * from websites";//创建PreparedStatement预编译执行对象,将传入的SQL语句读出来。PreparedStatement stmt = connection.prepareStatement(sql);//设置返回的参数,此处的返回值为结果集ResultSet rs = stmt.executeQuery();// 获取查询到的结果集while (rs.next()){// 将结果集拼接起来System.out.println(rs.getInt(1) + "-" + rs.getString(2) + "-" + rs.getString(3)+ "-" + rs.getInt(4) + "-" + rs.getString(5));}} catch (SQLException e) {e.printStackTrace();} catch (Exception e) {e.printStackTrace();}}
}
思考——如何优化上述的Java代码?
优化方案——使用分层将代码分为几个模块
1、视图层
2、持久层 / 数据访问层 Dao -- Data Access Object 数据访问层
优化的方案将会在后续的文章当中给出具体的操作。
jdbc是硬编码的方式
SQL语句也是硬编码,缺点是不易维护

mybatis框架
总结
以上就是今天的内容~
欢迎大家点赞👍,收藏⭐,转发🚀,
如有问题、建议,请您在评论区留言💬哦。
最后:转载请注明出处!!!
相关文章:
IDEA项目实践——创建Java项目以及创建Maven项目案例、使用数据库连接池创建项目简介
系列文章目录 IDEA上面书写wordcount的Scala文件具体操作 IDEA创建项目的操作步骤以及在虚拟机里面创建Scala的项目简单介绍 目录 系列文章目录 前言 一 准备工作 1.1 安装Maven 1.1.1 Maven安装配置步骤 1.1.2 解压相关的软件包 1.1.3 Maven 配置环境变量 1.1.4 配…...
ArraySetter
简介 用来展示属性类型为数组的 setter 展示 配置示例 "setter": {"componentName": "ArraySetter","props": {"itemSetter": {"componentName": "ObjectSetter","props": {"c…...

Python如何解决Amazon亚马逊“图文验证码”识别(6)
前言 本文是该专栏的第55篇,后面会持续分享python爬虫干货知识,记得关注。 在本专栏前面,笔者有详细介绍多种登录验证码识别方法,感兴趣的同学可往前翻阅。而本文,笔者将单独详细介绍亚马逊Amazon的图文识别验证码的解决方法。 如上图所示,访问或请求频次达到一定程度之…...

plsql连接oracle出现TTC错误
这个错误莫名其妙,搜不到直接关联的解决方案。用了下面解决乱码的方式倒是解决了。 ORA-03137: TTC protocol internal error : [%s] [%s] [%s] [%s] [%s] [%s] [%s] [%s] 按照如下链接解决: PL/SQL Developer中文乱码解决方案_Bug君坤坤的博客-CSDN博…...

4-golang爬虫下载的代码
golang爬虫下载的代码: 下载程序的借鉴内容: 这个是关于gbk,utf8等相互转换的包 github.com/axgle/mahonia" 一、标准下载代码 package downloaderimport ("log""net/http""io""github.com/axgle/…...
Eureka增加账号密码认证登录
一、业务背景 注册中心Eureka在微服务开发中经常使用到,用来管理发布的微服务,供前端或者外部调用。但是如果放到生产环境,我们直接通过URL访问的话,这显然是不安全的。 所以需要给注册中心加上登录认证。 通过账号和密码认证进行…...

Practice5|58. 最后一个单词的长度、66. 加一
58. 最后一个单词的长度 1.题目: 给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。 单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。 示例 1: 输入:…...
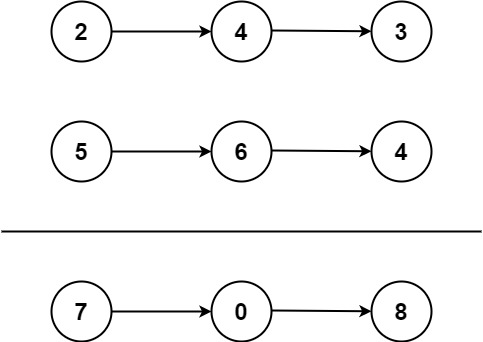
Practice4|14. 最长公共前缀、2. 两数相加
14. 最长公共前缀 1.题目: 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 ""。 示例 1: 输入:strs ["flower","flow","flight"] 输出…...
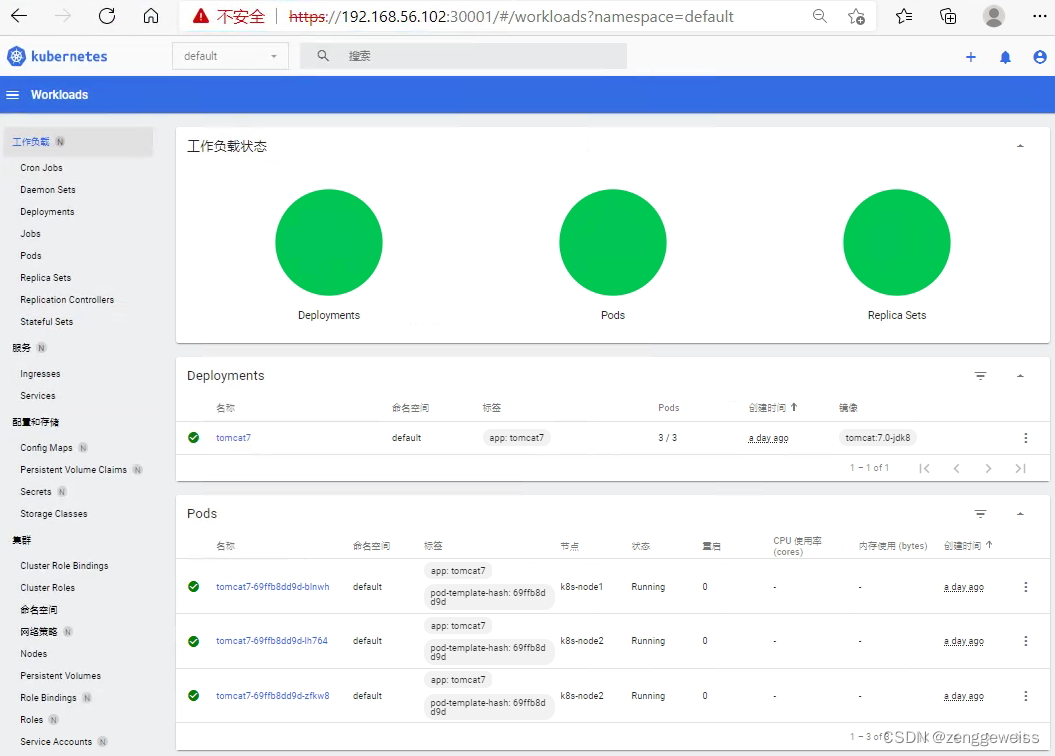
第28天-Kubernetes架构,集群部署,Ingress,项目部署,Dashboard
1.K8S集群部署 1.1.k8s快速入门 1.1.1.简介 Kubernetes简称k8s,是用于自动部署,扩展和管理容器化应用程序的开源系统。 中文官网:https://kubernetes.io/zh/中文社区:https://www.kubernetes.org.cn/官方文档:https…...
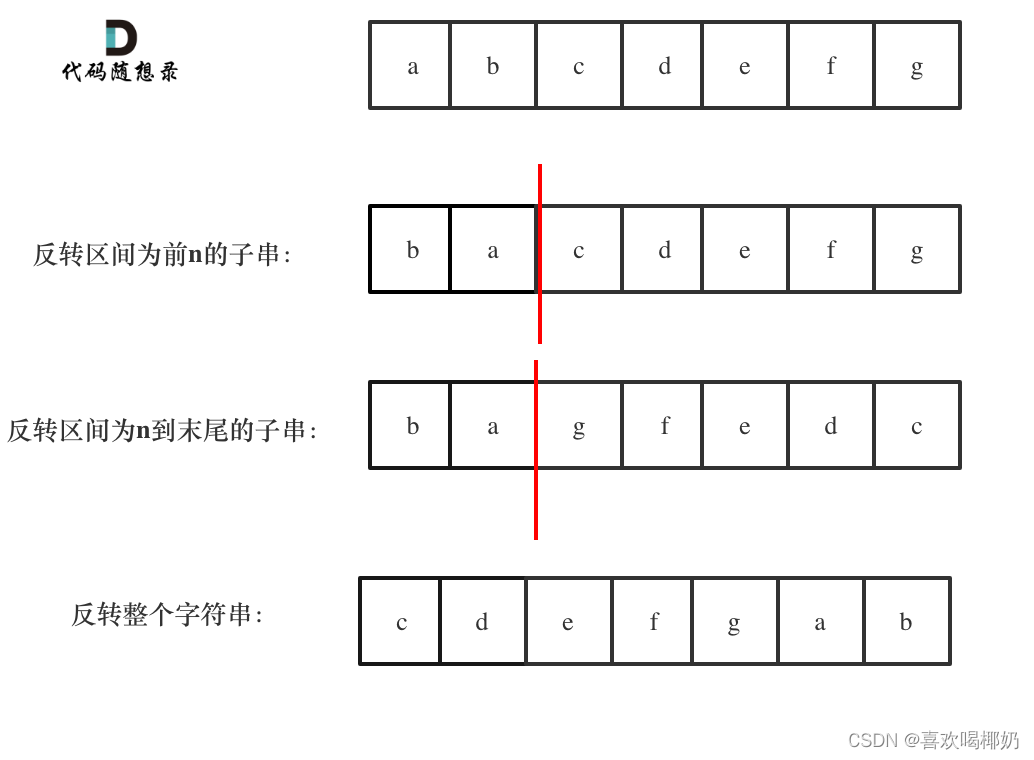
剑指OfferII-58.左旋转字符串
剑指OfferII-58.左旋转字符串 目录 剑指OfferII-58.左旋转字符串题目描述解法一:字符数组解法二:原地反转 题目描述 字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。 请定义一个函数实现字符串左旋转操作的功能。 比如,…...
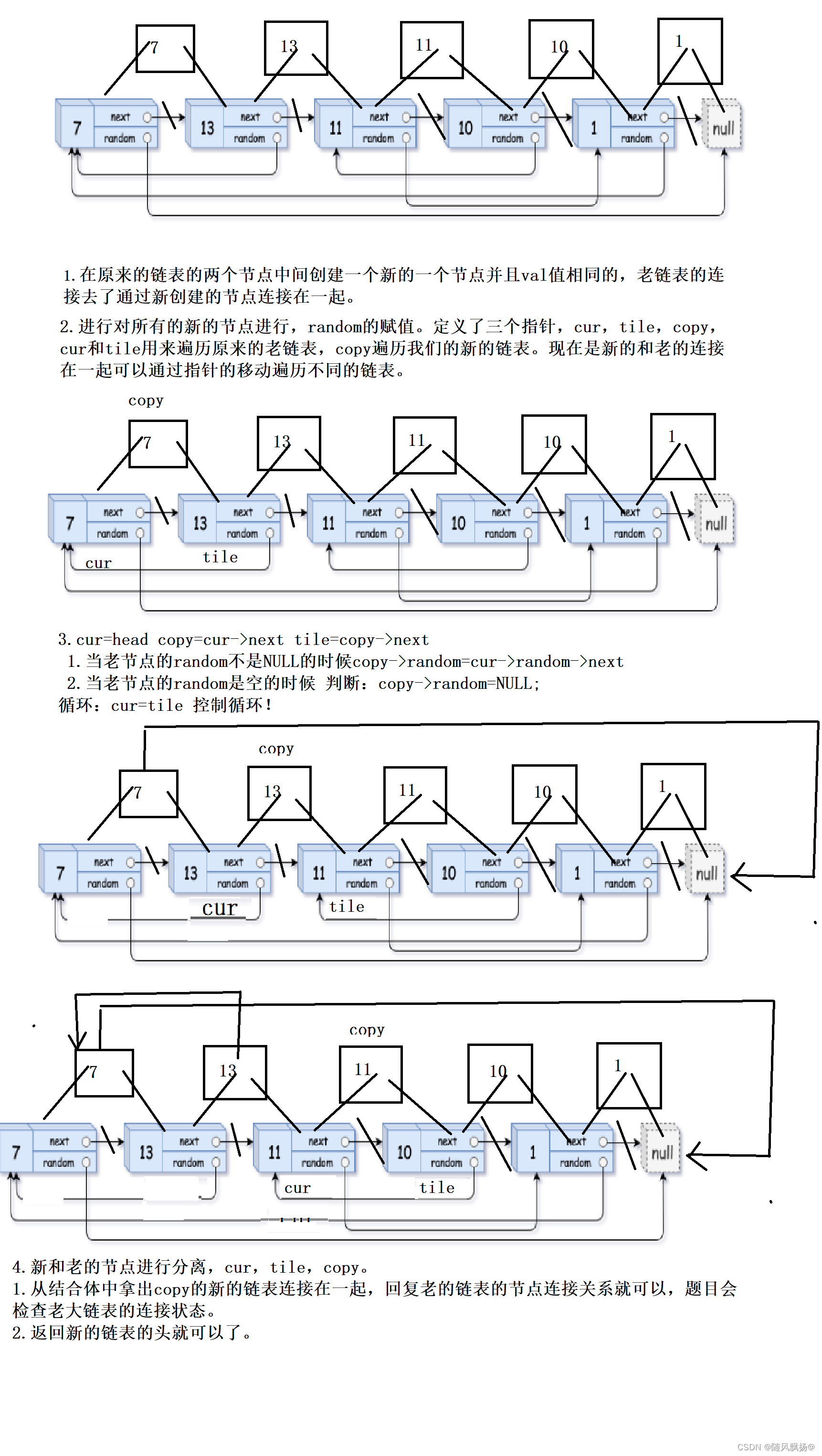
C语言每日一题:14《数据结构》复制带随机指针的链表
题目一: 题目链接: 思路一: 找相对位置暴力求解的方法: 1.复制一个新的链表出来遍历老的节点给新的节点赋值,random这个时候不去值。 2.两个链表同时遍历,遍历老链表的时候去寻找相对位置,在遍…...
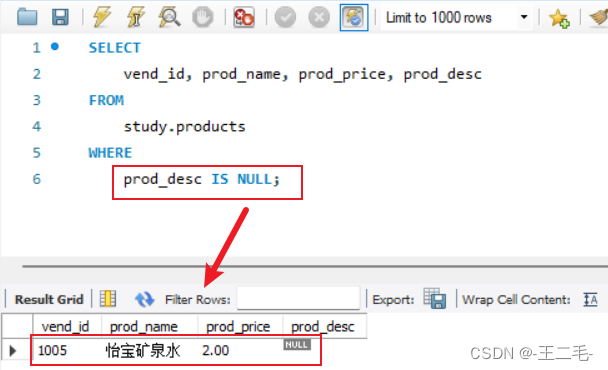
MySql008——检索数据:过滤数据(WHERE子句的使用)
前提:使用《MySql006——检索数据:基础select语句》中创建的products表 一、实际需求 数据库表一般包含大量的数据,但是很少需要检索表中所有行。通常只会根据特定条件提取表数据的子集。只检索所需数据需要指定搜索条件(search …...
vue2-v-show和v-if有什么区别,使用场景分别是什么?
1、v-show和v-if的共同点 在vue中,v-if和v-show的作用效果是相同的(不含v-else),都能控制元素在页面是否显示,在用法上也相同。 当表达式为true的时候,都会占据页面的位置 当表达式为false的时候ÿ…...

常用的排序算法简介:冒泡、选择、插入、归并、快速
常用的排序算法包括冒泡排序、选择排序、插入排序、归并排序和快速排序。以下是它们的简单介绍: 1. 冒泡排序(Bubble Sort): 冒泡排序是一种经典的基于交换的排序算法。它重复地比较相邻的元素,如果顺序错误&#…...

Golang之路---04 项目管理——编码规范
本文根据个人编码习惯以及网络上的一些文章,整理了一些大家能用上的编码规范,可能是一些主流方案,但不代表官方。 1. 文件命名 由于 Windows平台文件名不区分大小写,所以文件名应一律使用小写 不同单词之间用下划线分词…...
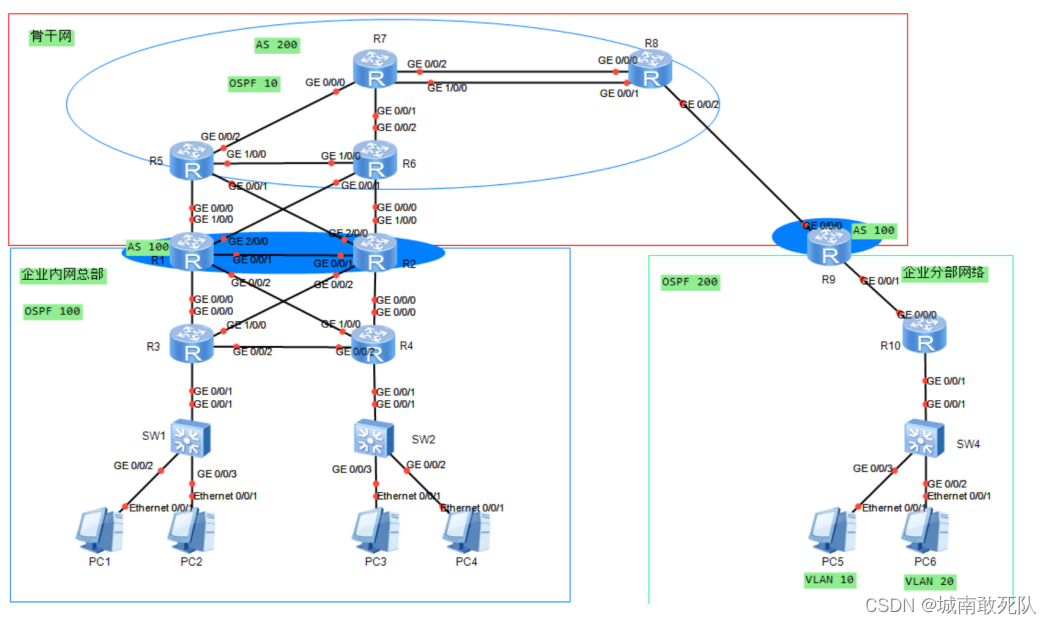
hcip——期中小试
要求: 1、该拓扑为公司网络,其中包括公司总部、公司分部以及公司骨干网,不包含运营商公网部分。 2 、设备名称均使用拓扑上名称改名,并且区分大小写。 3 、整张拓扑均使用私网地址进行配置。 4 、整张网络中,运行 O…...
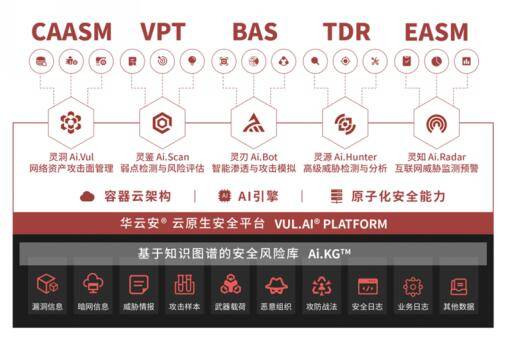
华云安参编的《云原生安全配置基线规范》正式发布
由中国信息通信研究院(以下简称“中国信通院”)、中国通信标准化协会主办的第十届可信云大会云原生安全分论坛于7月26日在北京国际会议中心成功召开。作为大会上展示的成果之一,由中国信通院联合行业领先企业共同编写的《云原生安全配置基线规…...
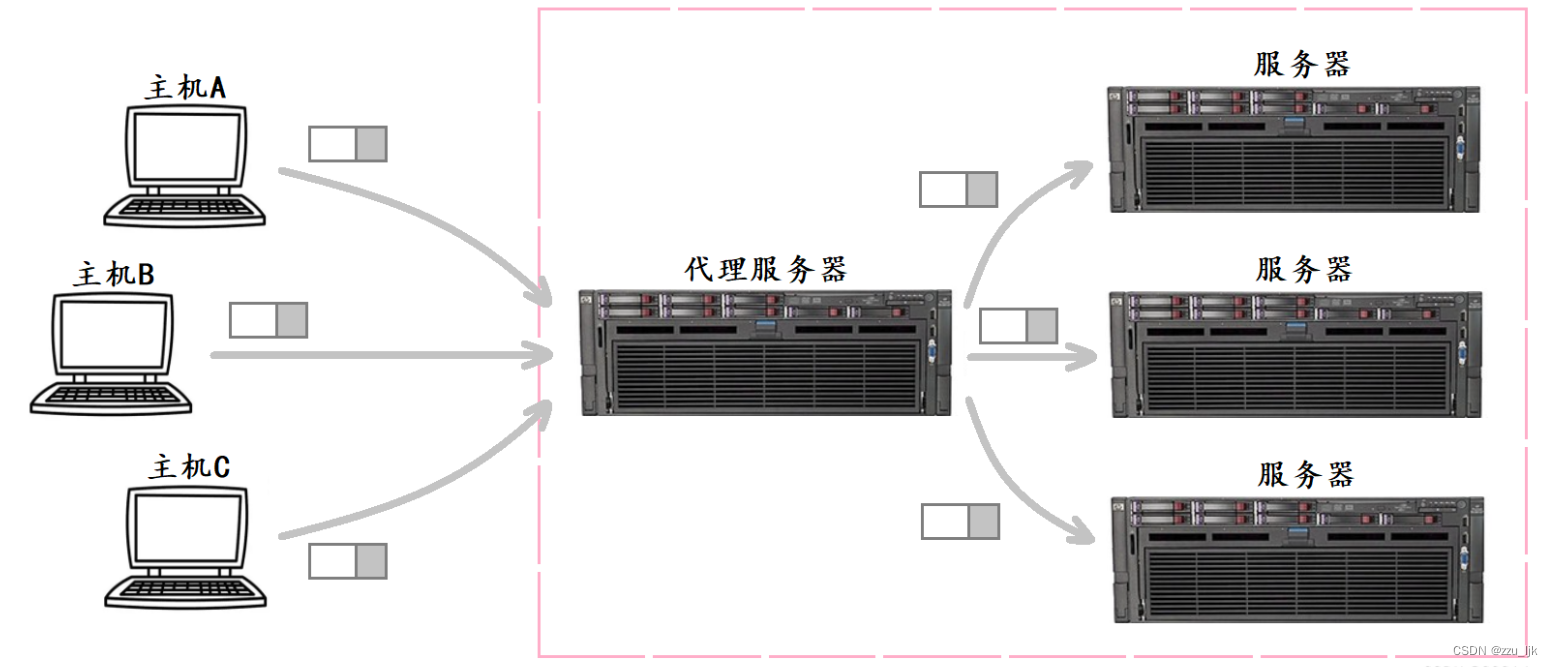
【计算机网络】NAT技术
文章目录 1. NAT技术简介2. 使用NAT技术转换IP的过程3. NAPT4. NAT技术的缺陷5. NAT和代理服务器 1. NAT技术简介 NAT(Network Address Translation,网络地址转换)技术,是解决IP地址不足的主要手段,并且能够有效避免外…...

Jenkins工具系列 —— 插件 实现用户权限分配与管理
文章目录 安装插件 Role-based Authorization Strategy添加用户注册配置权限查看当前使用者,获取user id配置管理员权限配置普通用户权限(非管理员权限) 小知识 安装插件 Role-based Authorization Strategy 点击 左侧的 Manage Jenkins —&…...
智能文件批量改名工具,自定义重命名,格式转换一步到位!
每当你需要将大量视频文件进行重命名,改变格式时,是不是总感觉手动操作费时费力,让你抓狂不已?别担心!我们的文件批量改名高手将会解决你的困扰 首先,我们要打开文件批量改名高手,在“文件批量重…...

单片机开发:C语言与汇编的实战选择指南
1. 单片机编程语言的选择困境作为一名在嵌入式领域摸爬滚打多年的工程师,我经常被新手问到一个经典问题:"单片机开发到底该用C语言还是汇编?"这个问题看似简单,实则牵涉到开发效率、执行性能、维护成本等多个维度的权衡…...

QML Material项目实战:从零构建一个完整的Material Design应用
QML Material项目实战:从零构建一个完整的Material Design应用 【免费下载链接】qml-material qml-material - 一个在 QtQuick 中实现 Google 材料设计(Material Design)的 QML 部件库,支持跨平台运行。 项目地址: https://gitc…...
)
新手避坑指南:用Pandas高效合并CIC-IDS-2018的10个CSV文件(附内存优化技巧)
新手避坑指南:用Pandas高效合并CIC-IDS-2018的10个CSV文件(附内存优化技巧) 网络安全数据分析的第一步往往是从处理原始数据集开始。CIC-IDS-2018作为业内广泛使用的基准数据集,其分散在10个CSV文件中的特征数据给初学者带来了不小…...

基于SpringBoot + Vue的人工智能时代个人计算机的安全防护科普系统
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...
)
HALCON开发避坑指南:解决SetWindowParam报错#5190的3种方法(附hcanvas.dll文件)
HALCON开发实战:彻底解决SetWindowParam报错#5190的深度解析 在工业视觉开发领域,HALCON作为行业标杆工具链,其窗口管理系统一直是实现高效图像处理的关键组件。但当你在Visual Studio中满怀信心地调用SetWindowParam进行窗口参数配置时&…...

2026最新大模型学习路线图!小白转行AI,这可能是你最好的起点!
大模型目前在可以说正处于一种“炙手可热”的状态,吸引了很多人的关注和兴趣,也有很多新人小白想要学习大模型技术,转战AI领域,以适应未来的大趋势,寻求更有前景的发展!2026最新大模型学习路线 一个明确的学…...

OpenClaw技能打包发布:将Qwen3.5-9B-AWQ-4bit图片工具上传ClawHub
OpenClaw技能打包发布:将Qwen3.5-9B-AWQ-4bit图片工具上传ClawHub 1. 为什么需要技能打包? 上周我在整理旅行照片时,突然意识到一个痛点:每次需要从几百张照片中筛选出包含特定元素的图片(比如"所有有狗的合照&…...

【行列式】
行列式,本质上是一个线性变换对“整体体积(长度/面积/体积的高维推广)”缩放了多少倍的量。它最核心的作用,就是判断这个线性变换有没有把空间“压瘪”,也就是用于恢复原向量的信息是否丢失。 所以它有三个最重要的用途…...

OpenClaw+千问3.5-9B会议纪要:语音转文字自动生成重点
OpenClaw千问3.5-9B会议纪要:语音转文字自动生成重点 1. 为什么需要自动化会议纪要 每次开完会最头疼的就是整理会议纪要。作为团队里经常负责记录的人,我经历过太多这样的场景:会议中疯狂打字记录,结果漏掉关键讨论点ÿ…...

Less 教程
Less 教程 引言 Less(Leaner Style Sheets)是一种由Sass作者开发的开源CSS预处理器。它增加了变量、混合(Mixins)、函数等特性,使CSS更加强大、灵活和易于维护。本教程将为您详细介绍Less的基本用法,帮助您快速上手。 Less 简介 什么是Less? Less 是一个 CSS 预处理…...