Hive常见面试题
Hive的基本概念
什么是Hive?它的主要作用是什么?
Hive是一个基于Hadoop生态系统的数据仓库和数据处理工具。
它提供了类似于SQL的查询语言(HiveQL),使用户能够使用SQL语句来查询和分析
大规模存储在Hadoop集群上的数据。Hive的主要作用是将大数据的处理变得更加易于理 解和使用,尤其适合那些熟悉SQL查询语言的非技术用户。
Hive允许用户定义表、执行查询、进行数据转换和加载,以及执行ETL(抽取、转换、加载)操作,从而使大数据分析更加简单。
Hive的数据存储是如何组织的?
Hive将数据存储在Hadoop分布式文件系统(HDFS)中。
数据以文件的形式存储在HDFS的分布式存储节点上。
在Hive中,数据存储以表的形式组织,表可以包含多个分区,每个分区都对应一个HDFS子目录,用于存储与分区相关的数据。每个表可以有多个列,每个列都有一个数据类型。
什么是Hive表的分区?如何创建和管理分区?
Hive表的分区是将表的数据根据特定的列值进行逻辑分隔的一种机制。通过将表数据按照分区键的值进行分组,可以提高查询性能、管理数据以及执行更有效的数据加载。分区键通常是表的一个或多个列。
创建和管理分区可以通过以下步骤完成:
创建分区表: 在创建表时,使用 PARTITIONED BY 子句指定分区列,例如:
sql
Copy code
CREATE TABLE sales (product STRING,amount DOUBLE
)
PARTITIONED BY (year INT, month INT);
加载数据: 将数据按照分区键的值分别加载到相应的子目录中。
添加分区: 可以使用 ALTER TABLE 语句添加分区,例如:
ALTER TABLE sales ADD PARTITION (year=2023, month=8);
查询分区数据: 在查询时,可以使用分区列的值来过滤数据,从而提高查询性能。
管理分区: 可以使用 SHOW PARTITIONS 命令查看表的所有分区,使用 DROP PARTITION 命令删除分区。
HiveQL语法:
HiveQL和传统SQL有什么相似之处和不同之处?
HiveQL(Hive Query Language)是Hive使用的查询语言,类似于传统的SQL(Structured Query Language)。虽然它们有一些相似之处,但也有一些不同之处,主要是因为Hive针对大数据处理的特点进行了一些扩展和适应。
相似之处:
-
语法相似: HiveQL的语法与传统的SQL非常相似,包括SELECT、FROM、WHERE、GROUP BY、JOIN等常见的SQL关键字和子句。
-
查询数据: HiveQL可以用于查询和分析数据,类似于传统SQL用于关系型数据库的查询操作。
-
数据定义: 类似于传统SQL,HiveQL也支持创建表、定义列、指定数据类型等数据定义操作。
-
数据操作: HiveQL支持数据插入、更新和删除等数据操作,类似于传统SQL的数据操作。
不同之处:
-
数据模型: Hive是基于Hadoop生态系统的大数据处理工具,因此它的数据模型更适合于分布式存储和处理。Hive中的表可以是非规范化的,并且支持类似于分区、桶、嵌套类型等特性。
-
执行引擎: Hive最初使用的是MapReduce作为执行引擎,后来引入了其他高性能的执行引擎,如Apache Tez和Apache Spark。这使得Hive能够更高效地处理大规模数据。
-
数据格式: Hive支持多种数据格式,包括文本、Parquet、ORC等,而传统SQL主要处理关系型数据库中的表。
-
数据类型: 由于Hive适用于非关系型数据存储,因此它引入了更多的数据类型,如数组、Map、Struct等,以支持更复杂的数据结构。
-
查询优化: Hive针对大规模数据的查询优化和执行方式可能与传统SQL有所不同,因为在分布式环境中的优化策略和技术有所不同。
总的来说,HiveQL在语法和操作上与传统SQL有很多相似之处,使得熟悉SQL的用户能够更容易地使用Hive进行大数据处理。然而,由于Hive的特点和应用场景,它在数据模型、执行引擎和数据处理方式等方面有一些与传统SQL不同的特点。
如何在Hive中创建表?可以使用哪些存储格式?
在Hive中创建表可以使用 CREATE TABLE 语句,同时可以指定表的结构、列、分区等信息。此外,你还可以选择不同的存储格式来存储表中的数据。以下是在Hive中创建表的基本步骤以及常见的存储格式示例:
创建表的基本语法:
CREATE TABLE table_name (column1 data_type,column2 data_type,...
)
[PARTITIONED BY (partition_column data_type, ...)]
[ROW FORMAT ...]
[STORED AS ...]
[TBLPROPERTIES (...)];
示例1:使用文本格式创建表
CREATE TABLE employee (emp_id INT,emp_name STRING,emp_salary DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
示例2:使用Parquet格式创建表
CREATE TABLE sales (product_id INT,sale_date STRING,amount DOUBLE
)
STORED AS PARQUET;
示例3:创建分区表
CREATE TABLE sales_partitioned (product_id INT,sale_date STRING,amount DOUBLE
)
PARTITIONED BY (year INT, month INT)
STORED AS PARQUET;
常见的存储格式有:
- TEXTFILE: 使用文本格式存储数据,每行一个记录,字段间使用分隔符分隔。
- SEQUENCEFILE: 使用二进制格式存储数据,适合大规模数据的存储和处理。
- RCFILE: 列式存储格式,提供更高的压缩率和查询性能。
- PARQUET: 列式存储格式,支持高效的压缩和快速的分析查询。
- ORC: 列式存储格式,优化了查询性能和压缩效率。
存储格式的选择会影响数据的存储和查询性能,不同格式适用于不同的场景。例如,Parquet和ORC通常用于数据仓库和分析查询,而TEXTFILE适用于简单的文本数据。选择存储格式时需要考虑数据的性质、查询需求和存储成本等因素。
数据导入和导出:
如何将数据从本地文件系统导入到Hive表中?
要将数据从本地文件系统导入到Hive表中,你可以使用Hive的 LOAD DATA 命令或 INSERT INTO 语句。以下是两种方法的详细说明:
方法一:使用 LOAD DATA 命令:
LOAD DATA 命令用于将数据从本地文件系统导入到Hive表中。它可以从本地文件或HDFS路径加载数据,并将数据加载到指定的Hive表中。以下是示例:
LOAD DATA LOCAL INPATH '/path/to/local/data/file' INTO TABLE target_table;
/path/to/local/data/file是本地文件系统中的数据文件路径。target_table是目标Hive表的名称。
方法二:使用 INSERT INTO 语句:
另一种方法是使用 INSERT INTO 语句来插入数据。在这种情况下,你需要先将数据加载到一个临时表中,然后再将数据插入到目标表中。以下是示例:
- 创建临时表并加载数据:
CREATE TABLE temp_table (column1 data_type,column2 data_type,...
);LOAD DATA LOCAL INPATH '/path/to/local/data/file' INTO TABLE temp_table;
- 将数据从临时表插入到目标表:
INSERT INTO target_table SELECT * FROM temp_table;
注意:
- 在使用
LOAD DATA命令时,如果数据文件在HDFS中而不是本地文件系统中,可以省略LOCAL关键字。 - 在使用
LOAD DATA命令时,确保Hive服务器和数据文件所在的机器之间有正确的权限和网络连接。 - 在使用
INSERT INTO语句时,确保目标表的列和临时表的列一致。 - 在生产环境中,通常会使用更复杂的数据导入方法,如使用分隔符、字段映射等。
除了使用 LOAD DATA 命令和 INSERT INTO 语句,还有其他一些方法可以将数据从本地文件系统导入到Hive表中,具体取决于你的需求和场景。以下是一些其他可能的方法:
-
外部表: 创建外部表并指定数据的位置,不会将数据移动到Hive仓库,而是在数据所在的位置进行查询。可以通过将数据文件拷贝到指定位置,或者直接在Hive表的外部位置加载数据。
-
Hive Streaming: 使用Hive Streaming API,你可以编写自定义应用程序将数据流式传输到Hive表中,这对于实时数据加载很有用。
-
HDFS命令: 使用HDFS命令,如
hdfs dfs -copyFromLocal或hdfs dfs -put,将本地文件复制到HDFS中,然后使用Hive表的LOAD DATA或INSERT INTO进行加载。 -
ETL工具: 使用ETL(抽取、转换、加载)工具,如Apache NiFi、Talend等,可以轻松地将数据从不同来源导入到Hive表中,进行数据清洗和转换。
-
Sqoop: Sqoop是一个用于在Hadoop和关系型数据库之间传输数据的工具,可以用来将关系型数据库中的数据导入到Hive表中。
-
自定义脚本: 你还可以编写自定义脚本来处理数据导入过程,使用编程语言(如Python、Java等)来读取本地文件,并将数据插入到Hive表中。
在选择数据导入方法时,考虑数据的大小、频率、数据转换需求和系统架构等因素。不同的方法适用于不同的情况,选择最适合你场景的方法可以提高数据导入的效率和质量。
如何将Hive查询的结果导出到本地文件系统?
性能调优:
什么是数据倾斜?如何处理数据倾斜问题?
数据倾斜是指在分布式计算环境中,数据在不同任务(如Map、Reduce等)之间分布不均匀,导致某些任务的执行速度远远慢于其他任务的现象。这可能会导致整个作业的执行时间增加,影响系统的性能和效率。
数据倾斜问题通常在以下情况下出现:
-
键分布不均匀: 数据按照某些键进行分组时,某些键的数据量远大于其他键,导致部分任务处理的数据远多于其他任务。
-
连接操作: 在连接操作中,如果某个键的数据在一个表中很多,而在另一个表中很少,可能会导致连接操作的数据分布不均匀。
-
聚合操作: 在聚合操作中,如果某个键的数据量远大于其他键,可能会导致聚合操作的负担不均匀。
处理数据倾斜问题是分布式计算环境中的一个重要挑战。以下是一些常见的处理数据倾斜问题的方法:
-
随机前缀: 对于键分布不均匀的情况,可以在键前面添加随机前缀,从而将数据均匀分布在不同的任务中。
-
增加分区: 对于分区表,可以增加分区的数量,从而将数据均匀分布在更多的分区中。
-
改变连接键: 在连接操作中,可以考虑更换连接键,选择在数据分布更均匀的键进行连接。
-
Combiner函数: 在MapReduce中,可以使用Combiner函数来在Map端进行部分聚合,从而减少Reduce阶段的数据量。
-
数据重分布: 可以通过数据重分布的方式,将数据重新分布到不同的任务中,从而平衡数据负载。
-
使用自定义Partitioner: 对于一些特殊情况,可以使用自定义的Partitioner来控制数据分布。
-
多阶段聚合: 对于聚合操作,可以采用多阶段的方式进行聚合,减少单个任务的负担。
-
动态调整任务数量: 在一些计算框架中,可以动态调整任务数量,从而更好地适应
如何优化Hive查询的性能?可以使用哪些技术和策略?
优化Hive查询的性能是一个重要的任务,特别是在大规模数据处理环境中。以下是一些优化Hive查询性能的常见技术和策略:
-
分区和桶: 使用分区和桶可以提高查询性能。分区可以减少查询的数据量,而桶可以提高数据的存储和访问效率。
-
合理设计表结构: 设计合适的表结构,选择合适的数据类型、列名和分区键,以适应查询需求和数据特点。
-
压缩数据: 使用合适的压缩格式(如Parquet、ORC)可以减少存储空间,提高查询性能。
-
使用分析函数: Hive支持分析函数(如窗口函数),它们可以在不引入额外的MapReduce任务的情况下执行一些复杂的数据分析操作。
-
避免笛卡尔积: 尽量避免多表之间的笛卡尔积操作,这会导致性能下降。
-
使用Map-Side Join: 如果一个表很小,可以将其加载到内存中,然后进行Map-Side Join,减少Shuffle操作。
-
分析执行计划: 使用
EXPLAIN命令来分析查询的执行计划,查看数据的流动和操作顺序,以找到性能瓶颈。 -
使用合适的执行引擎: 切换到合适的执行引擎,如Apache Tez或Apache Spark,可以提高查询性能。
-
数据倾斜处理: 处理数据倾斜问题,采用前缀随机化、数据重分布等方法来平衡数据负载。
-
优化连接操作: 使用SMB Join(Sort-Merge Join)或使用Map-Side Join,优化连接操作的性能。
-
缓存数据: 如果某些数据经常被查询,可以使用Hive的查询结果缓存机制,减少计算开销。
-
动态分区: 在某些情况下,使用动态分区来避免静态分区带来的开销。
-
适当调整并行度: 调整查询的并行度,根据集群资源和查询特点进行调整,以充分利用资源。
-
使用索引: 尽量避免使用Hive中的索引,因为Hive的索引性能不如传统数据库。
-
数据预聚合: 对于一些聚合查询,可以在ETL阶段进行预聚合,减少查询时的计算量。
优化Hive查询性能是一个综合性的任务,需要根据具体情况和查询特点进行适当的调整和优化。常常需要通过实验和性能测试来确定最佳的优化策略。
UDF和UDAF:
什么是Hive的用户定义函数(UDF)和用户定义聚合函数(UDAF)?如何创建和使用它们?
分区和桶:
什么是Hive表的分区和桶?有什么作用?
分区:
Hive表的分区是将表的数据按照某个或多个列的值进行逻辑上的分隔,将数据存储在不同的子目录中。每个分区对应一个子目录,其中存储了该分区的数据。分区能够有效地减少查询的数据量,提高查询性能,并且在某些情况下可以进行更细粒度的数据管理。
例如,如果有一个销售表,你可以根据年份和月份进行分区,将每个月的销售数据存储在不同的子目录中,这样在查询特定月份的销售数据时,只需要读取相应分区的数据,减少了不必要的数据扫描。
桶:
Hive表的桶是一种数据组织方式,它将表的数据按照某个列的哈希值分成固定数量的桶,并将每个桶存储在一个文件中。桶可以提高查询性能,特别是在连接操作和聚合操作中。
桶的主要优点在于:
- 相同桶号的数据在不同表之间可以更有效地进行连接操作,减少数据的移动。
- 桶的数量固定,因此Hive可以更准确地进行优化,如预估连接操作的数据大小。
分区和桶的作用:
-
查询性能优化: 分区和桶可以大幅度提高查询性能,减少不必要的数据扫描,使查询更加高效。
-
数据管理: 分区可以更方便地管理数据,例如对历史数据进行保留、归档等操作。
-
连接操作优化: 桶可以优化连接操作,减少数据移动,提高连接性能。
-
预估优化: Hive可以基于分区和桶的元数据信息更准确地预估查询执行计划。
需要注意的是,分区和桶的选择需要根据具体的数据特点、查询需求和系统资源进行权衡。正确使用分区和桶可以显著提高Hive表的查询性能和管理效率。
如何在创建表时定义分区和桶?
在创建表时,你可以使用 PARTITIONED BY 和 CLUSTERED BY 语句来定义分区和桶。以下是如何在创建表时定义分区和桶的示例:
定义分区:
使用 PARTITIONED BY 关键字来定义表的分区列。每个分区列将会创建一个子目录,数据会按照分区列的值存储在不同的子目录中。例如:
CREATE TABLE sales (product_id INT,sale_date STRING,amount DOUBLE
)
PARTITIONED BY (year INT, month INT);
在上述示例中,sales 表根据 year 和 month 列创建了分区。
定义桶:
使用 CLUSTERED BY 关键字来定义表的桶。你需要指定桶的列以及桶的数量。桶的数量固定,Hive会根据指定的列的哈希值将数据分散到不同的桶中。例如:
CREATE TABLE sales_bucketed (product_id INT,sale_date STRING,amount DOUBLE
)
CLUSTERED BY (product_id) INTO 10 BUCKETS;
在上述示例中,sales_bucketed 表根据 product_id 列创建了 10 个桶。
需要注意的是,分区和桶可以同时使用,也可以只使用其中一种。同时使用分区和桶可以进一步提高查询性能,但也会增加表的复杂度。在选择是否使用分区和桶时,需要根据数据的特点和查询需求进行权衡。
数据格式:
Hive支持哪些数据格式?请列举一些常见的数据格式。
Hive支持多种数据格式,不同的数据格式适用于不同的数据存储和查询需求。以下是一些常见的Hive支持的数据格式:
-
文本格式(TextFile): 文本格式是最简单的数据格式,每行都是文本数据。虽然不是最高效的格式,但它是通用的,易于查看和处理。
-
列式存储格式(Parquet、ORC): Parquet和ORC(Optimized Row Columnar)是列式存储格式,它们将数据按列存储,能够提高读取性能和压缩率,适合分析查询。它们支持谓词下推、列剪裁等优化。
-
Avro格式: Avro是一种自描述的二进制格式,支持复杂数据类型和架构演化。它适用于数据交换和通信。
-
SequenceFile格式: SequenceFile是Hadoop的二进制格式,支持快速顺序读写,适用于大规模数据的存储。
-
JSON格式: JSON格式用于存储半结构化数据,它的可读性和广泛支持使其适用于许多场景。
-
XML格式: XML格式适用于存储和交换具有层次结构的数据,但它相对于其他格式来说较冗长。
-
CSV格式: CSV(逗号分隔值)是一种常见的表格数据格式,适用于简单的表格数据。
-
其他定制格式: 你还可以使用自定义的分隔符或定界符来定义自己的数据格式,例如使用特定的分隔符或字符。
选择合适的数据格式取决于你的数据存储和查询需求。例如,如果你需要高性能的分析查询,可以考虑使用Parquet或ORC格式。如果你需要支持多种数据类型和架构的演化,可以选择Avro格式。每种格式都有其优势和局限性,应根据数据特点和查询需求进行选择。
不同的数据格式如何影响Hive查询的性能?
不同的数据格式可以显著影响Hive查询的性能,因为数据格式直接影响了数据的存储方式、压缩率、读取方式等。以下是不同数据格式对Hive查询性能的影响:
1. 列式存储格式(Parquet、ORC):
- 优势: 列式存储格式将数据按照列存储,而不是按行存储。这允许Hive仅读取查询需要的列,从而减少了I/O开销,提高了查询性能。另外,列式存储格式通常具有更好的压缩率,减少了存储空间的占用。
- 劣势: 在写入数据时,列式存储格式的性能可能稍低于行式存储格式,因为需要进行列的批量写入。
2. 行式存储格式(TextFile、SequenceFile):
- 优势: 行式存储格式对于一些插入操作和简单查询可能更快,因为每次读取的数据量更小。
- 劣势: 行式存储格式在扫描所有列时可能存在不必要的I/O开销,对于分析性查询可能性能较差。
3. Avro格式:
- 优势: Avro格式是一种自描述的二进制格式,它支持复杂数据类型和架构演化。它的自描述性使得在读取数据时不需要预先知道数据的结构,从而具有更好的灵活性。
- 劣势: 由于自描述性,Avro可能比其他格式稍慢,且在压缩方面可能不如Parquet或ORC。
4. 其他格式(JSON、XML、CSV等):
- 优势: 这些格式适用于不同的数据交换和通信需求,但在大规模数据分析场景中可能性能不如列式存储格式。
总体而言,列式存储格式(如Parquet和ORC)通常对Hive查询性能有积极的影响,特别是在分析性查询、复杂查询和大规模数据查询场景下。选择适当的数据格式可以根据查询需求来平衡性能、存储和写入效率。
Hive与其他工具的比较:
Hive与Spark SQL有什么区别?
Hive和Spark SQL都是用于在大数据环境中进行数据处理和查询的工具,但它们有一些区别,包括其架构、查询引擎、优势和用途等。以下是Hive和Spark SQL之间的一些主要区别:
1. 数据处理引擎:
- Hive:Hive使用类SQL的HiveQL语言,将查询翻译成MapReduce任务执行。它在Hadoop生态系统中已有很长时间,并且是基于批处理模型的。
- Spark SQL:Spark SQL是Apache Spark生态系统中的组件,它允许在Spark中执行SQL查询。Spark SQL支持交互式查询和流处理,能够处理批处理和实时数据。
2. 执行模型:
- Hive:Hive在底层使用MapReduce来执行查询,这意味着较大的查询可能需要多个MapReduce作业,导致延迟较高。
- Spark SQL:Spark SQL使用Spark的内存计算引擎,利用分布式内存进行数据处理,因此可以更快地执行查询,并支持迭代式处理和流式处理。
3. 性能:
- Hive:Hive在执行大型复杂查询时性能可能受到影响,因为它需要进行多个MapReduce任务的串行执行。
- Spark SQL:Spark SQL借助Spark的内存计算引擎,可以在内存中缓存数据,实现更快速的查询执行,尤其对于迭代式算法和迭代查询性能更佳。
4. 支持的数据源:
- Hive:主要用于处理Hadoop生态系统中的数据,如HDFS和HBase。
- Spark SQL:除了Hadoop生态系统中的数据,还可以处理其他数据源,如JSON、Parquet、Avro、ORC等。
5. 查询优化:
- Hive:Hive的查询优化在一定程度上受限,因为它主要通过转换成MapReduce任务来执行。
- Spark SQL:Spark SQL通过Catalyst查询优化器进行查询优化,能够更灵活地对查询进行优化和计划。
6. 用途:
- Hive:主要用于离线批处理分析,适用于处理大规模的历史数据分析任务。
- Spark SQL:适用于交互式查询、实时数据处理、流式处理等,更适合需要较低延迟和更灵活的查询场景。
总的来说,Hive和Spark SQL各有其优势,选择哪个取决于项目需求和场景。如果已有Hive基础或需要在Hadoop生态系统中进行大规模批处理分析,可以考虑使用Hive。如果需要更快速的交互式查询和支持实时处理,Spark SQL可能更适合。有时候,两者也可以结合使用,根据具体情况灵活选择。
相关文章:

Hive常见面试题
Hive的基本概念 什么是Hive?它的主要作用是什么? Hive是一个基于Hadoop生态系统的数据仓库和数据处理工具。 它提供了类似于SQL的查询语言(HiveQL),使用户能够使用SQL语句来查询和分析 大规模存储在Hadoop集群上的数…...

【单片机】晨启科技,酷黑版,密码锁
密码锁 任务要求: 当输入密码(至少6位密码)时,OLED显示屏显示输入的数字(或者字符),当密码位数输入完毕按下确认键时,对输入的密码与设定的密码进行比较(可使用外设键盘&…...
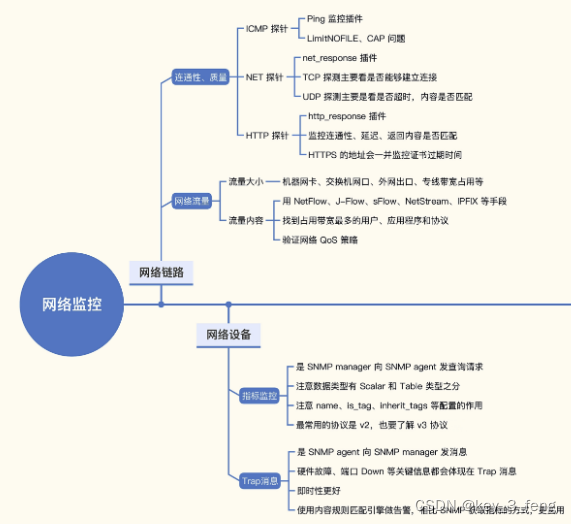
常见监控网络链路和网络设备的方法
网络监控主要包括网络链路监控和网络设备监控,通常系统运维人员会比较关注。 一、网络链路监控 网络链路监控主要包含三个部分,网络连通性、网络质量、网络流量。 连通性和质量的监控手段非常简单,就是在链路一侧部署探针,去探…...
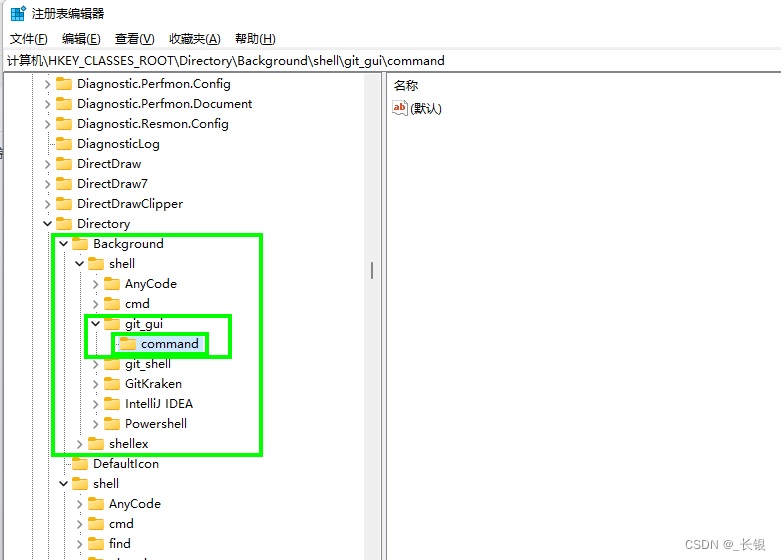
C#控制台程序+Window增加右键菜单
有时候我们可能会想定制一些自己的右键菜单功能,帮我们减少重复的操作。那么使用控制台程序加自定义右键菜单,就可以很好地满足我们的需求。 1 编写控制台程序 因为我只用到了在文件夹中空白处的右键菜单,所以这里提供了一个对应的模板&…...
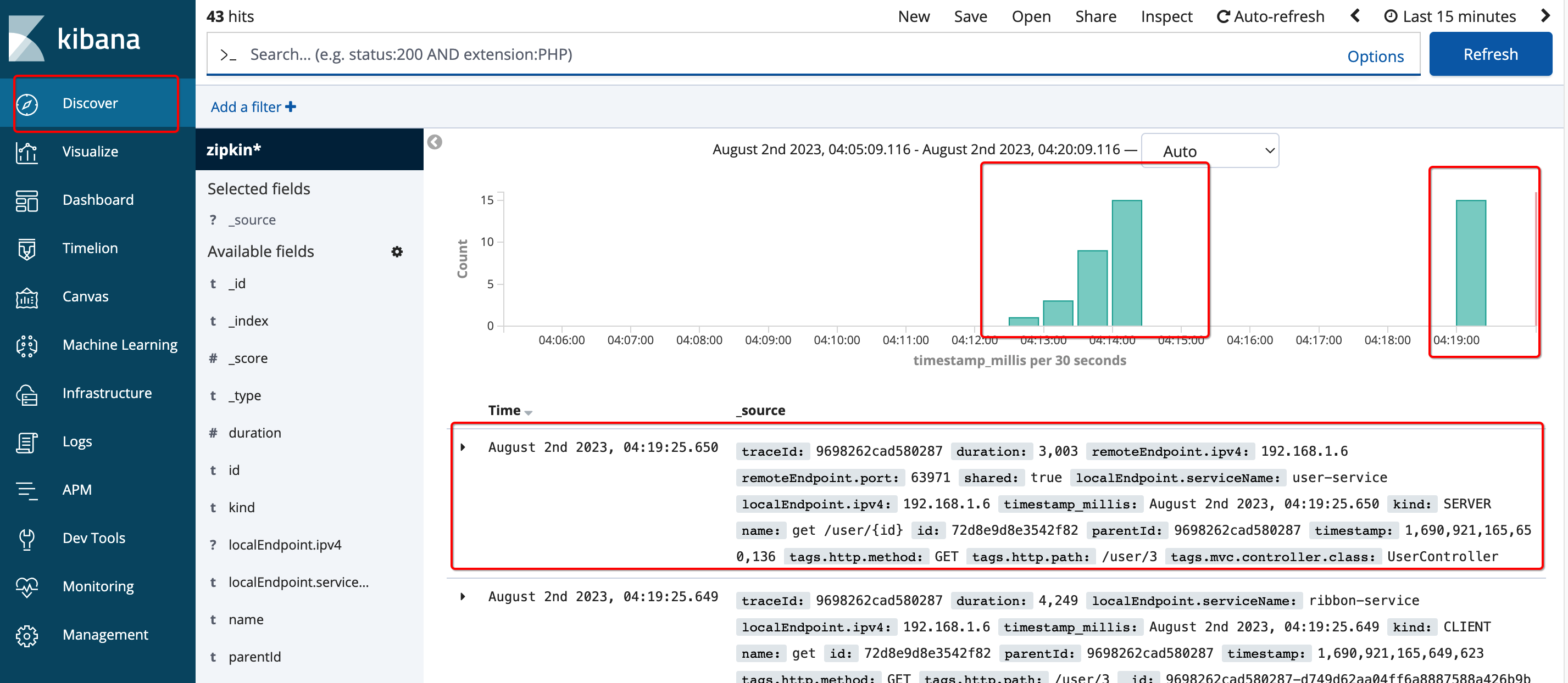
【Docker】Docker+Zipkin+Elasticsearch+Kibana部署分布式链路追踪
文章目录 1. 组件介绍2. 服务整合2.1. 前提:安装好Elaticsearch和Kibana2.2. 再整合Zipkin 点击跳转:Docker安装MySQL、Redis、RabbitMQ、Elasticsearch、Nacos等常见服务全套(质量有保证,内容详情) 本文主要讨论在Ela…...
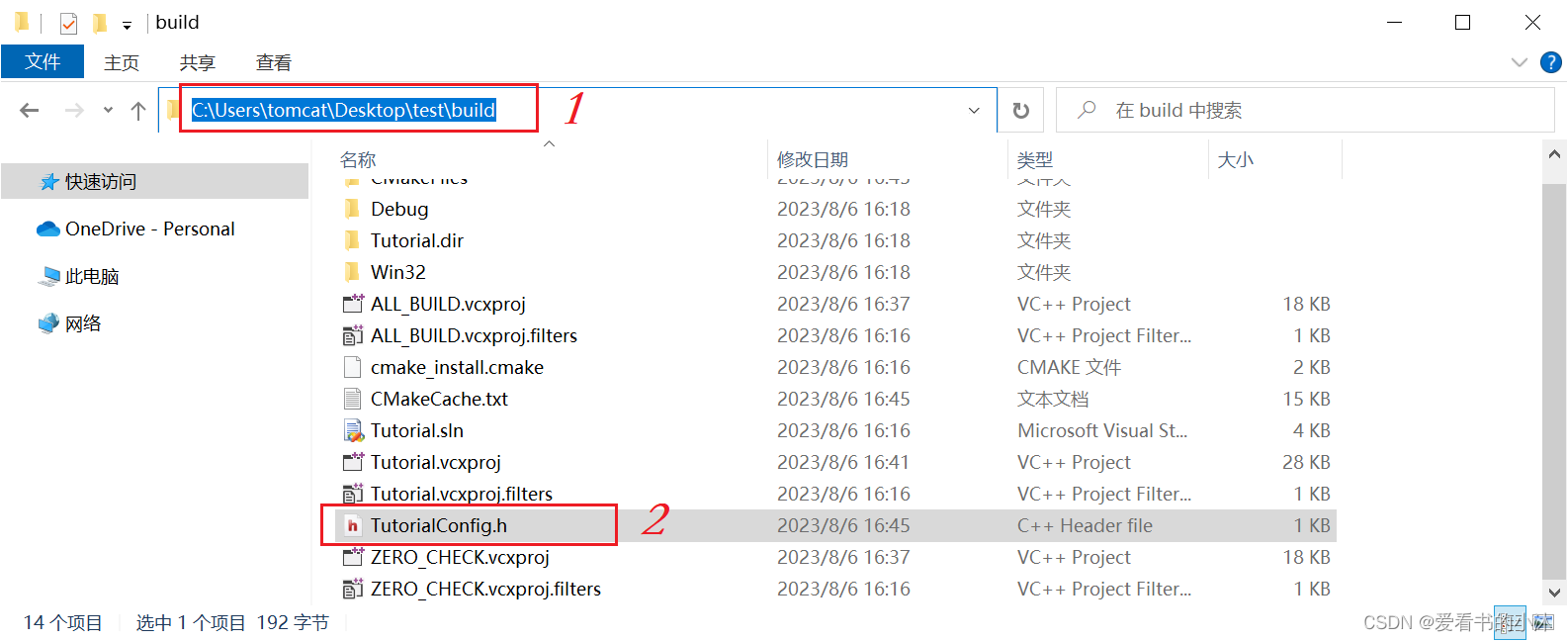
【小沐学C++】C++ 基于CMake构建工程项目(Windows、Linux)
文章目录 1、简介2、下载cmake3、安装cmake4、测试cmake4.1 单个源文件4.2 同一目录下多个源文件4.3 不同目录下多个源文件4.4 标准组织结构4.5 动态库和静态库的编译4.6 对库进行链接4.7 添加编译选项4.8 添加控制选项 5、构建最小项目5.1 新建代码文件5.2 新建CMakeLists.txt…...
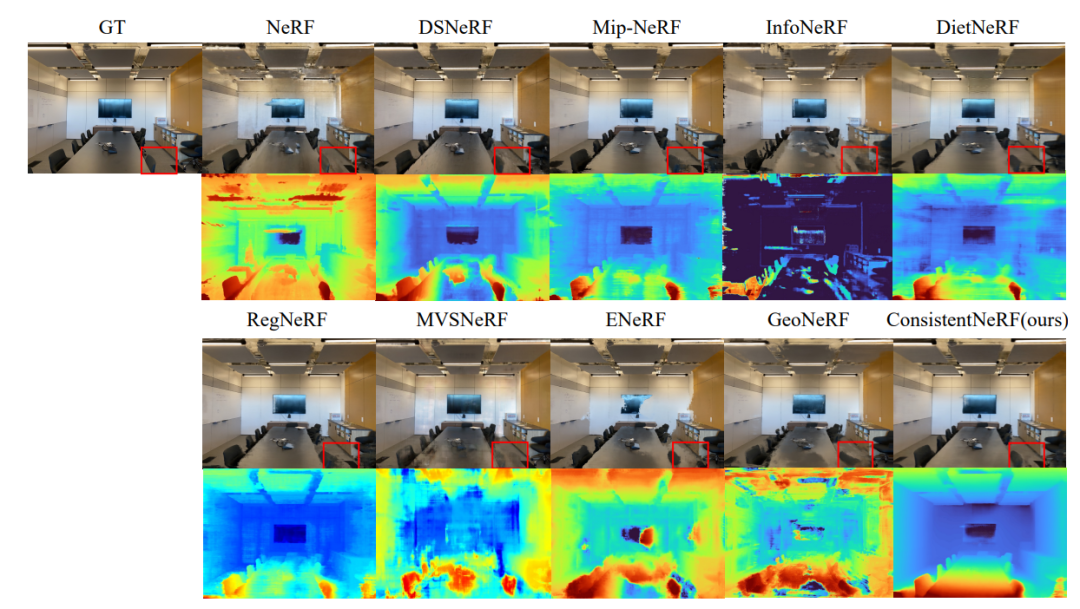
计算机视觉与图形学-神经渲染专题-ConsistentNeRF
摘要 Neural Radiance Fields (NeRF) 已通过密集视图图像展示了卓越的 3D 重建能力。然而,在稀疏视图设置下,其性能显着恶化。我们观察到,在这种情况下,学习不同视图之间像素的 3D 一致性对于提高重建质量至关重要。在本文中&…...

初级算法-其他
文章目录 位1的个数题意:解:代码: 汉明距离题意:解:代码: 颠倒二进制位题意:解:代码: 杨辉三角题意:解:代码: 有效的括号题意…...
Containerd的两种安装方式
1. 轻量级容器管理工具 Containerd 2. Containerd的两种安装方式 3. Containerd容器镜像管理 4. Containerd数据持久化和网络管理 操作系统环境为centos7u6 1. YUM方式安装 1.1 获取YUM源 获取阿里云YUM源 # wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun…...
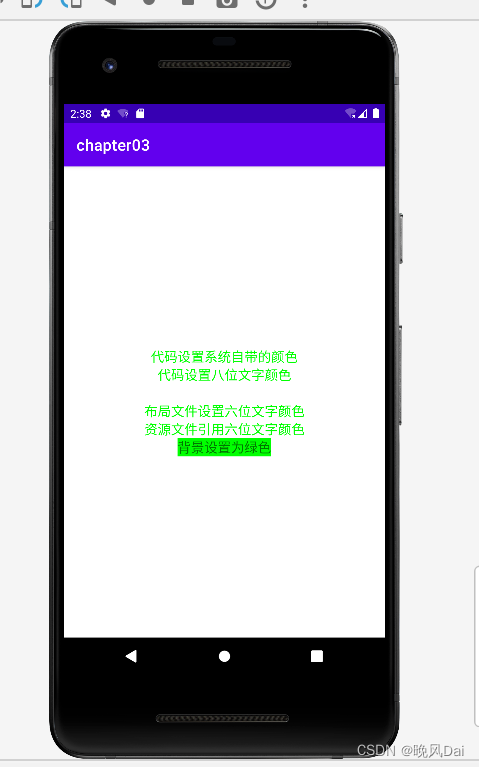
Android学习之路(1) 文本设置
Android学习之路(1) 文本 一、设置文本内容 设置文本内容的两种方式: 一种是在XML文件中通过属性android:text设置文本代码如下 <TextViewandroid:id"id/tv_hello"android:layout_width"wrap_content"android:layout_height"wrap_c…...
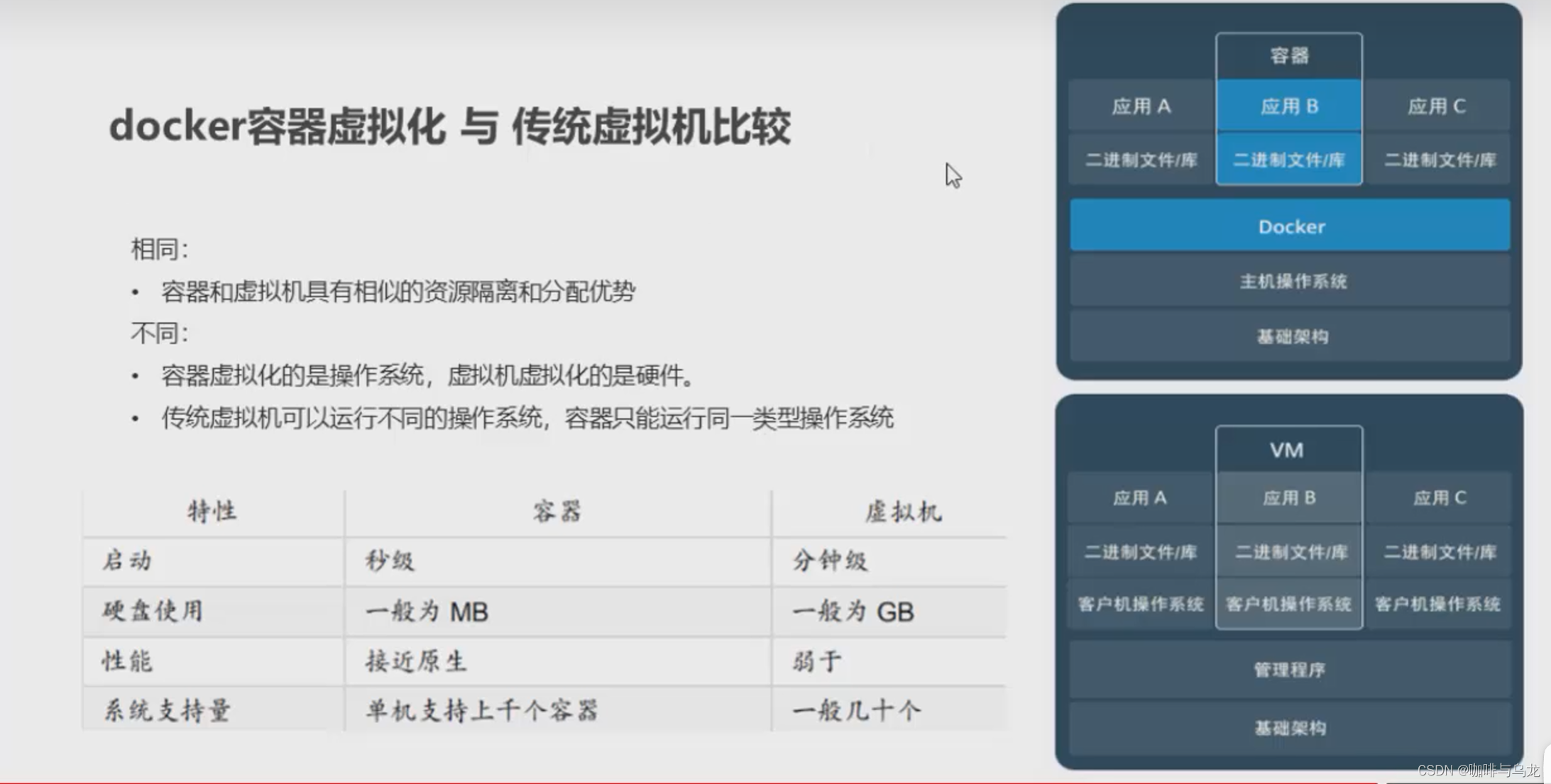
Docker相关命令与入门
1. Docker 命令 # centos 7 systemctl start docker # 启动服务 systemctl stop docker systemctl restart docker # 重启服务 systemctl status docker systemctl enable docker # 开机自启动1.1 镜像相关的命令 # 查看镜像 docker images docker images -q # 查看…...
如何配置一个永久固定的公网TCP地址来SSH远程树莓派?
文章目录 如何配置一个永久固定的公网TCP地址来SSH远程树莓派?前置条件命令行使用举例:修改cpolar配置文件 1. Linux(centos8)安装redis数据库2. 配置redis数据库3. 内网穿透3.1 安装cpolar内网穿透3.2 创建隧道映射本地端口 4. 配置固定TCP端口地址4.1 …...
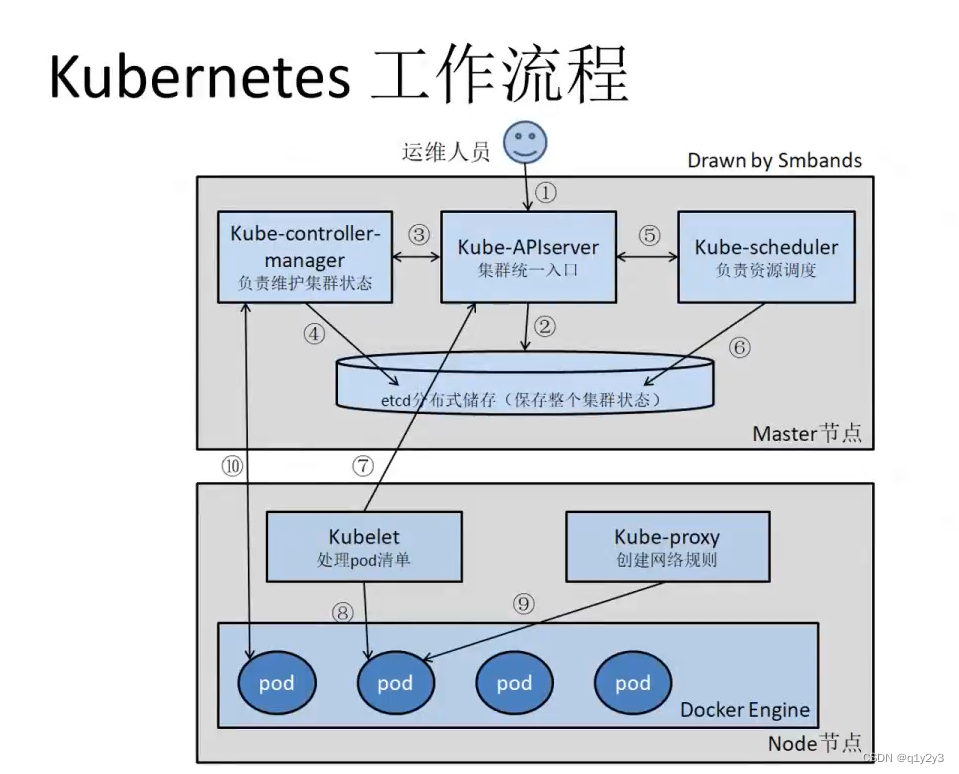
Kubernetes架构和工作流程
目录 一、kubernetes简介 1.k8s的由来 2.为什么用 k8s ? 3.k8s主要功能 二、k8s集群架构与组件 1.Master 组件 1.1Kube-apiserver 1.2Kube-controller-manager 1.3Kube-scheduler 2.Node组件 2.1Kubelet 2.2Kube-Proxy 2.3docker 或 rocket 3.配置存储中…...
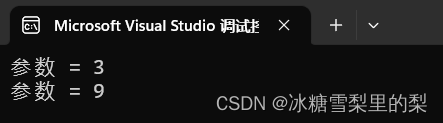
C语言赋值号的运算顺序
从右到左。 int & f(int & a) { printf("参数 %d\n", a); return a; } int main(void) {int a 9;int b 3;f(a) f(b);// 运行到此处,a 3,b 3return 0; } 输出...
fishing之第四篇使用案例一模拟登陆口
文章目录 一、访问钓鱼平台二、Sending Profiles(发件人邮箱配置)三、User&Groups(接收人邮件列表)四、Landing Pags(钓鱼页面配置)五、Email Templates(邮件内容配置)六、Campa…...
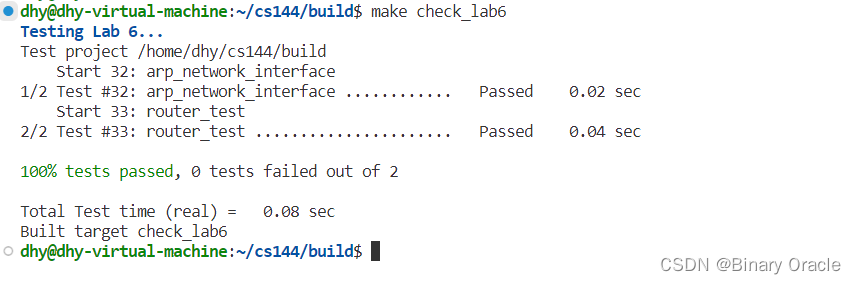
CS 144 Lab Six -- building an IP router
CS 144 Lab Six -- building an IP router 引言路由器的实现测试 对应课程视频: 【计算机网络】 斯坦福大学CS144课程 Lab Six 对应的PDF: Lab Checkpoint 5: building an IP router 引言 在本实验中,你将在现有的NetworkInterface基础上实现一个IP路由器…...
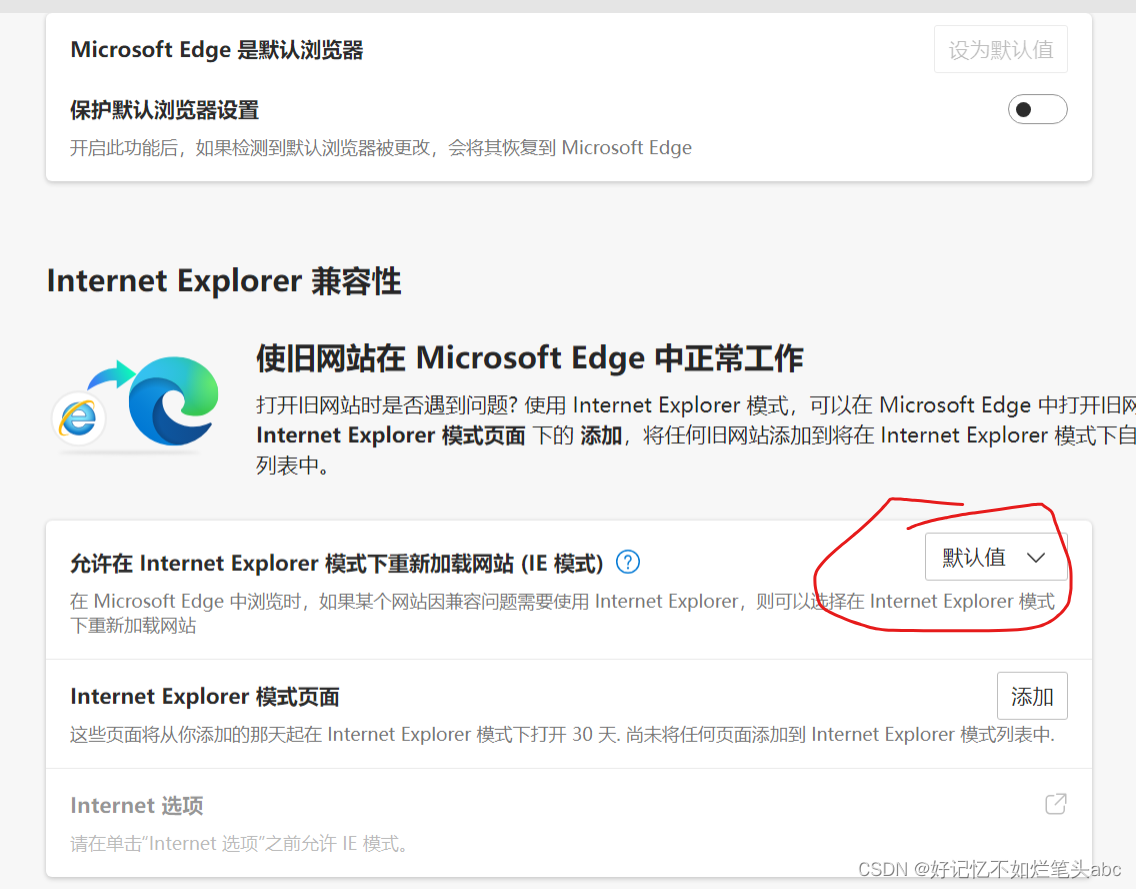
edge://settings/defaultbrowser default ie
Microsoft Edge 中的 Internet Explorer 模式 有些网站专为与 Internet Explorer 一起使用,它们具有 Microsoft Edge 等新式浏览器不支持的功能。 如果你需要查看其中的某个网站,可使用 Microsoft Edge 中的 Internet Explorer 模式。 大多数网站在新…...
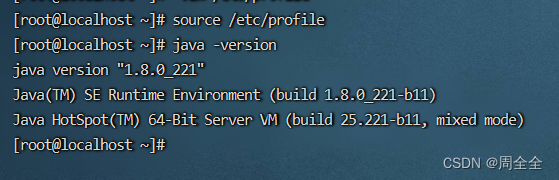
Centos7安装jdk8教程——rpm安装
1. rpm文件下载 下载链接 Java SE 8 Archive Downloads (JDK 8u211 and later) 2.上传到服务器指定路径下并安装 切换到上传目录,然后执行以下命令 rpm -ivh jdk-8u221-linux-x64.rpm3. 设置环境变量并重载配置 # 设置环境变量 vim /etc/profile# 文件末尾添加…...

Node.js-path模块操作路径的基本使用
path模块提供了操作路径的功能,以下为常用的API。 path.resolve():拼接规范的绝对路径 const path require("path"); // 目录的绝对路径 // __dirname: D:\node\path const pathStr path.resolve(__dirname, "index.html"); // 拼…...

油猴脚本:验证码识别辅助器
脚本信息 描述:当鼠标放在验证码图片上时,显示弹窗并提供识别选项 实现逻辑 定义了一个isRectangle函数,用于判断图片是否符合验证码的特征。判断条件是:图片的宽高比大于1.5,宽度大于等于80且高度大于等于30&#…...

面试题详解:Agent 记忆管理全解析——历史对话获取、摘要记忆、事实记忆、知识图谱记忆一次讲透
1. 什么是 Agent 记忆管理?为什么这件事越来越重要?1.1 如果没有记忆,Agent 就只能“活在当下”很多人第一次接触 Agent 时,会觉得记忆似乎就是保存聊天记录。可一旦系统要跨多轮、多天、甚至跨任务持续工作,就会发现单…...

Fansly下载器终极指南:3分钟学会离线保存你喜欢的创作者内容
Fansly下载器终极指南:3分钟学会离线保存你喜欢的创作者内容 【免费下载链接】fansly-downloader Easy to use fansly.com content downloading tool. Written in python, but ships as a standalone Executable App for Windows too. Enjoy your Fansly content of…...

ROS2 Galactic下源码编译TEB局部规划器:从依赖安装到成功运行Navigation2的保姆级避坑记录
ROS2 Galactic源码编译TEB局部规划器全流程实战指南 在机器人导航领域,TEB(Timed Elastic Band)局部规划器因其优秀的动态避障能力而备受青睐。然而当我们将目光转向ROS2 Galactic时,会发现官方仓库并未提供预编译的TEB功能包&…...

在Nodejs后端服务中集成多模型API实现智能客服
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成多模型API实现智能客服 构建一个智能客服系统时,开发者常常面临模型选择的两难:既要…...

基于I2C总线与ATtiny85的RGB LCD时钟:在5个GPIO上实现多设备驱动
1. 项目概述:当微型控制器遇上彩色显示屏几年前,我在为一个智能花盆项目寻找显示方案时遇到了一个经典难题:手头的Adafruit Trinket(基于ATtiny85)只有5个可用GPIO,而一个能显示温湿度、时间的16x2字符LCD屏…...

Vector CAN卡配置避坑指南:xlSetApplConfig函数详解与硬件通道分配实战
Vector CAN卡配置避坑指南:xlSetApplConfig函数详解与硬件通道分配实战 当你在深夜调试Vector CAN设备时,突然看到"Channel already assigned"的红色错误提示,是否感到一阵窒息?这种场景对于使用Vector硬件进行二次开发…...

Shermie-proxy:基于Node.js的脚本化HTTP/HTTPS代理调试工具实战指南
1. 项目概述与核心价值最近在折腾一些本地开发环境下的网络请求调试和抓包,发现一个挺有意思的开源项目kxg3030/shermie-proxy。这本质上是一个基于 Node.js 实现的 HTTP/HTTPS 代理服务器,但它的定位非常清晰:专为开发者本地调试和网络请求分…...

3分钟掌握DeepMosaics:AI智能马赛克处理与图像修复的终极指南
3分钟掌握DeepMosaics:AI智能马赛克处理与图像修复的终极指南 【免费下载链接】DeepMosaics Automatically remove the mosaics in images and videos, or add mosaics to them. 项目地址: https://gitcode.com/gh_mirrors/de/DeepMosaics 在数字时代&#x…...
)
保姆级避坑指南:在Ubuntu 18.04上从零搭建PX4仿真环境(ROS Melodic + Gazebo 9)
从零避坑:Ubuntu 18.04下PX4仿真环境全链路搭建实战 当无人机开发者第一次接触PX4生态时,往往会被复杂的工具链和隐蔽的环境依赖所困扰。本文将以"问题驱动"的方式,拆解ROS Melodic Gazebo 9 PX4组合环境搭建中的12个典型陷阱&am…...

阿里图像复原验证码识别
一、简介 这个就是阿里的图像还原验证码,他是从一个图片中任意抠出一个物品,可能是蜡烛、车轮、盘子、瓶子、盖子、扣子等等。然后让你通过鼠标拖动的方式,把物品拖到对应的位置上,完成图像复原验证。 这个验证码还有一个非常变态…...