neo4j查询语言Cypher详解(一)--语法和子句
前言
neo4j的图查询语言叫Cypher。Cypher的独特之处在于它提供了一种匹配模式和关系的可视化方式。 (nodes)-[:ARE_CONNECTED_TO]->(otherNodes)使用圆角括号表示节点(nodes), -[:ARROWS]->表示关系。
语法
解析
Cypher解析器接受任意输入字符串。
unicode通常可以使用转义 \uxxx。
支持的空白符
| 描述 | Unicode 字符列表 |
|---|---|
| Unicode General Category Zp | \u2029 |
| Unicode General Category Zs | \u0020 (space), \u1680, \u2000-200A, \u202F, \u205F, \u3000 |
| Unicode General Category class Zl | \u2028 |
| Horizontal Tabulation | \t, \u0009 |
| Line Feed | \n, \u000A |
| Vertical Tabulation | \u000B |
| Form Feed | \f, \u000C |
| Carriage Return | \r, \u000D |
| File Separator | \u001C |
| Group Separator | \u001D |
| Record Separator | \u001E |
| Unit Separator | \u001F |
表达式
字面量
- 数值:
13,-40000,3.14,6.022E23,Inf,Infinity,NaN - 十六进制:
0x13af,0xFC3A9,-0x66eff。 以0x开头 - 八进制:
0o1372,-0o5671。以0o开头。 - 字符串:
'Hello',"World"。单引号或者双引号 - boolean:
true,false
通用表达式
- 变量:
n,x,rel,myFancyVariable - 属性:
n.prop,x.prop,rel.thisProperty,myFancyVariable. - 动态属性:
n["prop"],rel[n.city + n.zip],map[coll[0]]. - 参数:
$param,$0 - List:
['a', 'b'],[1, 2, 3],['a', 2, n.property, $param],[] - 函数调用:
length(p),nodes(p) - 聚合函数:
avg(x.prop),count(*) - path-pattern:
(a)-[r]->(b),(a)-[r]-(b),(a)--(b),(a)-->()<--(b) - 操作符:
1 + 2,3 < 4 - 断言表达式:
a.prop = 'Hello',length(p) > 10,a.name IS NOT NULL - 标签和关系类型表达式:
(n:A|B),()-[r:R1|R2]→(). - 子查询:
EXISTS { MATCH (n)-[r]→(p) WHERE p.name = 'Sven' } - 正则表达式:
a.name =~ 'Tim.*' - 字符串匹配:
a.surname STARTS WITH 'Sven',a.surname ENDS WITH 'son'ora.surname CONTAINS 'son' - CASE:
CASE
通用条件表达式可以使用CASE结构表示。Cypher中存在CASE的两种变体:
- 简单形式(允许将一个表达式与多个值进行比较)
- 通用形式(允许表示多个条件语句)。
如果您想在后续子句或语句中使用CASE表达式的结果,CASE只能作为
RETURN或WITH的一部分使用。
简单形式
CASE testWHEN value THEN result[WHEN ...][ELSE default]
ENDMATCH (n)
RETURN
CASE n.eyesWHEN 'blue' THEN 1WHEN 'brown' THEN 2ELSE 3
END AS result
通用形式
谓词将按顺序求值,直到找到一个真值,并使用结果值。如果没有找到匹配项,则返回ELSE子句中的表达式。但是,如果没有ELSE情况并且没有找到匹配,则返回null。
MATCH (n)
RETURN
CASEWHEN n.eyes = 'blue' THEN 1WHEN n.age < 40 THEN 2ELSE 3
END AS result
后续语句使用CASE表达式结果
您可以使用CASE的结果来设置节点或关系的属性。例如,你可以为表达式选择的节点设置属性,而不是直接指定节点:
MATCH (n)
WITH n, // 使用WITH 来处理结果
CASE n.eyesWHEN 'blue' THEN 1WHEN 'brown' THEN 2ELSE 3
END AS colourCode
SET n.colourCode = colourCode
处理null
MATCH (n)
RETURN n.name,
CASE n.ageWHEN null THEN -1ELSE n.age - 10
END AS age_10_years_ago
子查询
子查询表达式可以出现在表达式有效的任何地方。子查询有一个范围,由开始和结束大括号{和}表示。在外部作用域中定义的任何变量都可以在子查询自己的作用域中引用。在子查询内部引入的变量不是外部作用域的一部分,因此不能在外部访问。
EXISTS子查询
EXISTS子查询可用于查明指定模式在数据中是否至少存在一次。它的用途与路径模式相同,但功能更强大,因为它允许在内部使用MATCH和WHERE子句。此外,与路径模式不同,它可以出现在任何表达式位置。如果子查询的求值至少为一行,则整个表达式将变为真。这也意味着系统只需要评估是否至少有一行,并且可以跳过其余的工作。
任何非写查询都是允许的。EXISTS子查询与常规查询的不同之处在于,最终的RETURN子句可以省略,因为在子查询中定义的任何变量在表达式之外都不可用,即使使用了最终的RETURN子句。
值得注意的是,如果EXISTS只包含一个模式和一个可选的where子句,则可以在子查询中省略MATCH关键字。
简单形式:
MATCH (person:Person)
WHERE EXISTS { //对Person进行关系判断(person)-[:HAS_DOG]->(:Dog)
}
RETURN person.name AS name
Where子查询:
MATCH (person:Person)
WHERE EXISTS {MATCH (person)-[:HAS_DOG]->(dog:Dog) //有match,where ,更细的判断WHERE person.name = dog.name
}
RETURN person.name AS name
嵌套Exists:
MATCH (person:Person)
WHERE EXISTS {MATCH (person)-[:HAS_DOG]->(dog:Dog)WHERE EXISTS {MATCH (dog)-[:HAS_TOY]->(toy:Toy)WHERE toy.name = 'Banana'}
}
RETURN person.name AS name
作为结果:
MATCH (person:Person)
RETURN person.name AS name, EXISTS {MATCH (person)-[:HAS_DOG]->(:Dog)
} AS hasDog //作为一个boolean值结果
UNION 结合
Exists可以与UNION子句一起使用,而RETURN子句不是必需的。值得注意的是,如果一个分支有RETURN子句,那么所有分支都需要RETURN子句。下面的示例演示了如果UNION分支中的一个至少返回一行,那么整个EXISTS表达式将求值为true。
MATCH (person:Person)
RETURNperson.name AS name,EXISTS { //至少有1个 Pet。MATCH (person)-[:HAS_DOG]->(:Dog)UNION //UNION ,表示多个联合作为一个结果集,MATCH (person)-[:HAS_CAT]->(:Cat)} AS hasPet
WITH 结合
外部范围的变量对整个子查询都是可见的,即使使用WITH子句也是如此。为了避免混淆,不允许隐藏这些变量。当内部作用域内新引入的变量用相同的变量定义时,外部作用域变量将被遮蔽。在下面的示例中,外部变量名被遮蔽,因此会抛出错误。
WITH 'Peter' as name
MATCH (person:Person {name: name})
WHERE EXISTS {WITH "Ozzy" AS nameMATCH (person)-[:HAS_DOG]->(d:Dog)WHERE d.name = name
}
RETURN person.name AS name
// The variable `name` is shadowing a variable with the same name from the outer scope and needs to be renamed (line 4, column 20 (offset: 90))
RETURN 结合
EXISTS子查询不需要在子查询的末尾使用RETURN子句。如果存在,则不需要使用别名,这与CALL子查询不同。EXISTS子查询返回的任何变量在该子查询之后都不可用。
MATCH (person:Person)
WHERE EXISTS {MATCH (person)-[:HAS_DOG]->(:Dog)RETURN person.name
}
RETURN person.name AS name
COUNT 子查询
可以使用COUNT子查询表达式对子查询返回的行数进行计数。
任何非写查询都是允许的。COUNT子查询与常规查询的不同之处在于,最终的RETURN子句可以省略,因为在子查询中定义的任何变量在表达式之外都不可用,即使使用了最终的RETURN子句。一个例外是,对于DISTINCT UNION子句,RETURN子句仍然是强制性的。
值得注意的是,如果COUNT仅由一个模式和一个可选的where子句组成,则可以在子查询中省略MATCH关键字。
简单 Count 子查询
MATCH (person:Person)
WHERE COUNT { (person)-[:HAS_DOG]->(:Dog) } > 1 // count 关系
RETURN person.name AS name
Count中Where语句
MATCH (person:Person)
WHERE COUNT {(person)-[:HAS_DOG]->(dog:Dog)WHERE person.name = dog.name //限定了 dog的name。
} = 1
RETURN person.name AS name
Count中Union
MATCH (person:Person)
RETURNperson.name AS name,COUNT {MATCH (person)-[:HAS_DOG]->(dog:Dog)RETURN dog.name AS petName // dogUNIONMATCH (person)-[:HAS_CAT]->(cat:Cat)RETURN cat.name AS petName // cat} AS numPets // count (union结果集)
Count 中 With
WITH 'Peter' as name
MATCH (person:Person {name: name})
WHERE COUNT {WITH "Ozzy" AS name //变量名冲突MATCH (person)-[:HAS_DOG]->(d:Dog)WHERE d.name = name
} = 1
RETURN person.name AS nameMATCH (person:Person)
WHERE COUNT {WITH "Ozzy" AS dogName //新的变量MATCH (person)-[:HAS_DOG]->(d:Dog)WHERE d.name = dogName
} = 1
RETURN person.name AS name
Count在其他语句
MATCH (person:Person)
RETURN person.name, COUNT { (person)-[:HAS_DOG]->(:Dog) } as howManyDogs //统计dogMATCH (person:Person) WHERE person.name ="Andy"
SET person.howManyDogs = COUNT { (person)-[:HAS_DOG]->(:Dog) } //设置dog 数量
RETURN person.howManyDogs as howManyDogsMATCH (person:Person)
RETURNCASEWHEN COUNT { (person)-[:HAS_DOG]->(:Dog) } > 1 THEN "Doglover " + person.nameELSE person.nameEND AS resultMATCH (person:Person)
RETURN COUNT { (person)-[:HAS_DOG]->(:Dog) } AS numDogs, //作为 Group key。avg(person.age) AS averageAgeORDER BY numDogs
COLLECT 子查询
可以使用COLLECT子查询表达式创建一个包含给定子查询返回的行的列表。返回的数据类型是个List。
简单Collect子查询
MATCH (person:Person)
WHERE 'Ozzy' IN COLLECT { MATCH (person)-[:HAS_DOG]->(dog:Dog) RETURN dog.name } //类似 SQL 中的 in。
RETURN person.name AS name
Collect结合Where
MATCH (person:Person)
RETURN person.name as name, COLLECT {MATCH (person)-[r:HAS_DOG]->(dog:Dog)WHERE r.since > 2017RETURN dog.name
} as youngDogs //返回的是个List,[]。
Collect结合Union
MATCH (person:Person)
RETURNperson.name AS name,COLLECT {MATCH (person)-[:HAS_DOG]->(dog:Dog)RETURN dog.name AS petNameUNION // 类似 SQL union,结果集MATCH (person)-[:HAS_CAT]->(cat:Cat)RETURN cat.name AS petName} AS petNames //返回的是个List,[]。
Collect 结合 WITH
MATCH (person:Person)
RETURN person.name AS name, COLLECT {WITH 2018 AS yearOfTheDog //定义 变量MATCH (person)-[r:HAS_DOG]->(d:Dog)WHERE r.since = yearOfTheDogRETURN d.name
} as dogsOfTheYear //返回的是个List,[]。
Collect在其他语句
MATCH (person:Person) WHERE person.name = "Peter"
SET person.dogNames = COLLECT { MATCH (person)-[:HAS_DOG]->(d:Dog) RETURN d.name }
RETURN person.dogNames as dogNamesMATCH (person:Person)
RETURNCASEWHEN COLLECT { MATCH (person)-[:HAS_DOG]->(d:Dog) RETURN d.name } = [] THEN "No Dogs " + person.nameELSE person.nameEND AS resultMATCH (person:Person)
RETURN COLLECT { MATCH (person)-[:HAS_DOG]->(d:Dog) RETURN d.name } AS dogNames, //作为 group keyavg(person.age) AS averageAgeORDER BY dogNames
COLLECT vs collect()
Collect() 会移除 null。collect{}不移除null,如果需要移除,要加过滤条件。
MATCH (p:Person)
RETURN collect(p.nickname) AS names
// ["Pete", "Tim"]
RETURN COLLECT {MATCH (p:Person)RETURN p.nickname ORDER BY p.nickname} AS names
//["Pete", "Tim", null]RETURN COLLECT {MATCH (p:Person)WHERE p.nickname IS NOT NULL // 过滤条件。RETURN p.nickname ORDER BY p.nickname} AS names
// ["Pete", "Tim"]
type断言表达式
<expr> IS :: <TYPE>
UNWIND [42, true, 'abc'] AS val
RETURN val, val IS :: INTEGER AS isInteger//从变量里每个元素都进行判断。
val isInteger
42 true
true false
'abc' false
// NOT
UNWIND [42, true, 'abc'] AS val
RETURN val, val IS NOT :: STRING AS notString
// IS :: returns true for all expressions evaluating to null
toFloat(null) IS :: BOOLEAN // true。
// IS NOT :: returns false for all expressions evaluating to null
(null + 1) IS NOT :: DATE // false//属性断言
MATCH (n:Person)
WHERE n.age IS :: INTEGER AND n.age > 18
RETURN n.name AS name, n.age AS age
Cypher将把任何精确的数值参数视为INTEGER,而不管其声明的大小。
同义词
<expr> IS TYPED <TYPE>
<expr> :: <TYPE>
<expr> IS NOT TYPED <TYPE>
ANY 、NOTHING
ANY是一个超类型,它匹配所有类型的值。NOTHING是包含一组空值的类型。这意味着它对所有值返回false。
RETURN 42 IS :: ANY AS isOfTypeAny, 42 IS :: NOTHING AS isOfTypeNothing
//true false
LIST类型
UNWIND [[42], [42, null], [42, 42.0]] as val
RETURN val, val IS :: LIST<INTEGER> AS isIntList //注意LIST 的 内部类型,类似JAVA 泛型
//
[42] true
[42, null] true
[42, 42.0] false //42.0不是INTEGER
空列表匹配任何内部类型,包括
NOTHING。
RETURN[] IS :: LIST<NOTHING> AS isNothingList, //TRUE[] IS :: LIST<INTEGER> AS isIntList, // true[] IS :: LIST<FLOAT NOT NULL> AS isFloatNotNullList //true
标签表达式
在早期版本的Neo4j中,节点的标签表达式只有一个冒号操作符,表示AND操作符。随着版本5的发布,除了单个冒号操作符之外,还引入了一个带有扩展逻辑操作符集的新标签表达式。重要的是要注意,不能混合使用这些不同类型的标签表达式语法。
当应用于节点的标签集时,标签表达式的计算结果为true或false。假设没有应用其他筛选器,那么求值为true的标签表达式表示匹配该节点。
| Node | ||||||||
|---|---|---|---|---|---|---|---|---|
| Label expression | () | (:A) | (:B) | (:C) | (:A:B) | (:A:C) | (:B:C) | (:A:B:C) |
| () | √ | √ | √ | √ | √ | √ | √ | √ |
| (:A) | √ | √ | √ | √ | ||||
| (:A&B) | √ | √ | ||||||
| (:A|B) | √ | √ | √ | √ | √ | √ | ||
| (:!A) | √ | √ | √ | √ | ||||
| (:!!A) | √ | √ | √ | √ | ||||
| (:A&!A) | ||||||||
| (:A|!A) | √ | √ | √ | √ | √ | √ | √ | √ |
| (:%) | √ | √ | √ | √ | √ | √ | √ | |
| (:!%) | √ | |||||||
| (:%|!%) | √ | √ | √ | √ | √ | √ | √ | √ |
| (:%&!%) | ||||||||
| (:A&%) | √ | √ | √ | √ | ||||
| (:A|%) | √ | √ | √ | √ | √ | √ | √ | |
| (:(A&B)&!(B&C)) | √ | |||||||
| (:!(A&%)&%) | √ | √ | √ |
语法
- 没有标签:
MATCH (n) - 单个标签:
MATCH (n:A) - AND:
MATCH (n:A&B) - OR:
MATCH (n:A|B) - NOT:
MATCH (n:!A) - 通配符:
MATCH (n:%), 至少一个标签 - 嵌套Lable:
MATCH (n:(!A&!B)|C) - WHERE:
MATCH (n) WHERE n:A|B - WITH,RETURN:
MATCH (n) RETURN n:A&B
关系类型表达式
关系必须有准确的一种类型。例如,模式(a)-[r:R&Q]-(b)或(a)-[r:!%]-(b)永远不会返回任何结果。
变长关系只能有由|组成的关系类型表达式。这意味着()-[r:!R*]-()是不允许的,而 ()-[r:Q|R*]-()是允许的。
| 关系 | |||
|---|---|---|---|
| 关系类型表达式 | [:A] | [:B] | [:C] |
| [] | √ | √ | √ |
| [:A] | √ | ||
| [:A&B] | |||
| [:A|B] | √ | √ | |
| [:!A] | √ | √ | |
| [:!!A] | √ | ||
| [:A&!A] | |||
| [:A|!A] | √ | √ | √ |
| [:%] | √ | √ | √ |
| [:!%] | |||
| [:%|!%] | √ | √ | √ |
| [:%&!%] | |||
| [:A&%] | √ | ||
| [:A|%] | √ | √ | √ |
标签表达式不能与标签语法结合使用。例如:A:B&C将抛出错误。相反,使用:A&B&C或:A:B:C。
语法
-
没有标签:
MATCH ()-[r]->() -
单个标签:
MATCH ()-[r:R1]->() -
OR:
MATCH ()-[r:R1|R2]->() -
NOT:
MATCH ()-[r:!R1]->() -
嵌套Lable:
MATCH ()-[r:(!R1&!R2)|R3]->() -
WHERE:
MATCH (n)-[r]->(m) WHERE r:R1|R2 -
WITH,RETURN:
MATCH (n)-[r]->(m) RETURN r:R1|R2 AS result -
CASE
MATCH (n)-[r]->(m) RETURN CASEWHEN n:A&B THEN 1WHEN r:!R1&!R2 THEN 2ELSE -1 END AS result
没有AND,因为AND不返回任何结果
参数
Cypher支持带参数查询。参数化查询是一种查询,其中占位符用于参数,并在执行时提供参数值。这意味着开发人员不必借助字符串构建来创建查询。此外,参数使Cypher更容易缓存执行计划,从而加快查询执行时间。
参数可用于:
-
字面量和表达式
-
节点和关系id
参数不能用于以下结构,因为它们构成了编译成查询计划的查询结构的一部分:
- 属性key:
MATCH (n) WHERE n.$param = 'something' - 关系类型:
MATCH (n)-[:$param]→(m) - 标签:
(n:$param)
参数可以由字母和数字组成,也可以由字母和数字的任意组合组成,但不能以数字或货币符号开头。
在运行查询时设置参数取决于客户端环境。例如:
-
Shell环境:
:param name => 'Joe' -
Neo4j Browser:
:param name => 'Joe' -
驱动:根据语言
-
Neo4j HTTP API:
参数以JSON格式给出,提交它们的确切方式取决于所使用的驱动程序。
Auto-parameterization
从版本5开始,即使查询是部分参数化的,Cypher也会尝试推断参数。查询中的每个文字都被一个参数替换。这增加了计算计划的可重用性,这些查询除了字面量之外都是相同的。不建议依赖这种行为——用户应该在他们认为合适的地方使用参数。
字符串字面量
// 参数
{"name": "Johan"
}
//用法1:
MATCH (n:Person)
WHERE n.name = $name
RETURN n
//用法2:
MATCH (n:Person {name: $name})
RETURN n
正则表达式
//输入参数
{"regex": ".*h.*"
}
//用法:
MATCH (n:Person)
WHERE n.name =~ $regex
RETURN n.name
字符串
MATCH (n:Person)
WHERE n.name STARTS WITH $name
RETURN n.name使用属性创建节点
{"props": {"name": "Andy","position": "Developer"}
}
CREATE ($props)
创建多个节点
{"props": [ {"awesome": true,"name": "Andy","position": "Developer"}, {"children": 3,"name": "Michael","position": "Developer"} ]
}
UNWIND $props AS properties //把属性展开
CREATE (n:Person)
SET n = properties //赋值所有属性
RETURN n
set属性
{"props": {"name": "Andy","position": "Developer"}
}
MATCH (n:Person)
WHERE n.name = 'Michaela'
SET n = $props
SKIP LIMIT
{"s": 1,"l": 1
}
//
MATCH (n:Person)
RETURN n.name
SKIP $s //
LIMIT $l //
node id
//单id
{ "id" : "4:1fd57deb-355d-47bb-a80a-d39ac2d2bcdb:0"}
MATCH (n)
WHERE elementId(n) = $id
RETURN n.name
//多id
{"ids" : [ "4:1fd57deb-355d-47bb-a80a-d39ac2d2bcdb:0", "4:1fd57deb-355d-47bb-a80a-d39ac2d2bcdb:1" ]
}
MATCH (n)
WHERE elementId(n) IN $ids
RETURN n.name
方法调用
{"indexname" : "My_index"
}
CALL db.resampleIndex($indexname)
操作符
Operators at a glance
| 操作符类型 | |
|---|---|
| 聚合操作符 | DISTINCT |
| 属性操作符 | . 静态属性访问 [] 动态属性访问= 替换节点或属性的全部属性+= 修改已存在属性,新增不存在属性 |
| 数学操作符 | +, -, *, /, %, ^ |
| 比较操作符 | =, <>, <, >, <=, >=, IS NULL, IS NOT NULL |
| 字符串特定操作符 | STARTS WITH, ENDS WITH, CONTAINS, =~ (正则匹配) |
| 逻辑操作符 | AND, OR, XOR, NOT |
| 字符串操作符 | + (字符串连接) |
| 时间操作符 | + and - for operations between durations and temporal instants/durations, * and / for operations between durations and numbers |
| map操作符 | . 静态key访问, []动态key访问 |
| List操作符 | +连接List,所有元素放一个ListIN List是否存在元素[]动态访问元素 |
注释
Cypher使用 // 来记性注释。
MATCH (n) RETURN n //This is an end of line comment
子句
Match
MATCH (n) //匹配所有节点
MATCH (movie:Movie) //匹配指定节点
// 关联节点
MATCH (director {name: 'Oliver Stone'})--(movie) //关联的任意节点
RETURN movie.title MATCH (:Person {name: 'Oliver Stone'})--(movie:Movie) //关联到movie
RETURN movie.title关系
//出关系:-->
MATCH (:Person {name: 'Oliver Stone'})-->(movie)
RETURN movie.title
//无方向关系
MATCH (a)-[:ACTED_IN {role: 'Bud Fox'}]-(b)
RETURN a, b
//多关系
MATCH (wallstreet {title: 'Wall Street'})<-[:ACTED_IN|DIRECTED]-(person)
RETURN person.name
关系深度
在单个模式中,关系只匹配一次。在关系独特性一节中了解更多。
关系类型一般用字母数字混合命名,如果有特殊字符,需用反引号( `)括起来。eg:(rob)-[:`OLD FRIENDS`]->(martin)。
// 2层关系
MATCH (charlie {name: 'Charlie Sheen'})-[:ACTED_IN]->(movie)<-[:DIRECTED]-(director)
RETURN movie.title, director.name
OPTIONAL MATCH
OPTIONAL MATCH 与Match模式基本类似,唯一差别是,如果没有匹配上,则用null 表示,类似于SQL中的Outer Join。
Cypher中的查询是作为管道运行的。如果一个子句没有返回结果,它将有效地结束查询,因为后续子句将没有数据可执行。
//不会返回结果。
MATCH (a:Person {name: 'Martin Sheen'})
MATCH (a)-[r:DIRECTED]->() //没有匹配,则不会执行下一步。
RETURN a.name, r
//会返回结果。
MATCH (p:Person {name: 'Martin Sheen'})
OPTIONAL MATCH (p)-[r:DIRECTED]->() //没有匹配,则返回null。
RETURN p.name, r //OUTER JOIN,p 是有值的,空Node用null表示。
Optional 关系
MATCH (a:Person {name: 'Charlie Sheen'})
OPTIONAL MATCH (a)-->(x)
RETURN x //返回 null
Optional元素的属性
如果元素返回null,则元素的属性也返回null。不会抛出空指针。
MATCH (a:Movie {title: 'Wall Street'})
OPTIONAL MATCH (a)-->(x)
RETURN x, x.name //返回:null null
Optional 命名关系
MATCH (a:Movie {title: 'Wall Street'})
OPTIONAL MATCH (a)-[r:ACTED_IN]->()
RETURN a.title, r // 关系返回 null。MATCH (a:Movie {title: 'Wall Street'})
OPTIONAL MATCH (x)-[r:ACTED_IN]->(a)
RETURN a.title, x.name, type(r) // 返回的是ACTED_IN,不是null。
注意:虽然关系r 返回null,但是type® 返回的是ACTED_IN。
RETURN
MATCH p = (keanu:Person {name: 'Keanu Reeves'})-[r]->(m)
RETURN * //返回所有元素。即所有匹配的变量:p,keanu,r,m
含有特殊字符的变量名,使用反引号( ` )括起来。
列别名使用 AS ,eg:RETURN p.nationality AS citizenship
Optional 属性
如果一个元素没有指定的属性,则返回null。
其他表达式
RETURN m.released < 2012, "I'm a literal",[p=(m)--() | p] AS `(m)--()`
结果去重
MATCH (p:Person {name: 'Keanu Reeves'})-->(m)
RETURN DISTINCT m
WITH
WITH子句允许将查询部分链接在一起,将一个查询部分的结果作为下一个查询部分的起点或标准。
重要的是要注意WITH影响作用域中的变量。没有包含在WITH子句中的任何变量都不会转移到查询的其余部分。通配符*可用于包含当前范围内的所有变量。
使用WITH,您可以在将输出传递给后续查询部分之前对其进行操作。可以对结果集中的项的Shape和(或)数量进行操作。
WITH的一种常见用法是限制传递给其他MATCH子句的条目数量。通过组合ORDER By和LIMIT,可以根据某些条件获得前X个条目,然后从图中引入额外的数据。
WITH还可以用于引入包含表达式结果的新变量,以供后续查询部分使用。为方便起见,通配符*扩展为当前范围内的所有变量,并将它们携带到下一个查询部分。
另一个用途是对聚合值进行过滤。WITH用于引入聚合,然后在WHERE中的谓词中使用聚合。这些聚合表达式在结果中创建新的绑定。
WITH还用于分离图的读取和更新。查询的每个部分必须是只读的或只写的。当从写部分切换到读部分时,必须使用with子句进行切换。
引入变量
MATCH (george {name: 'George'})<--(otherPerson)
WITH otherPerson, toUpper(otherPerson.name) AS upperCaseName //upperCaseName 新变量
WHERE upperCaseName STARTS WITH 'C'
RETURN otherPerson.name
通配符扩展
MATCH (person)-[r]->(otherPerson)
WITH *, type(r) AS connectionType //把几个变量携带下去。person,r,otherPerson
RETURN person.name, otherPerson.name, connectionType
过滤聚合结果
MATCH (david {name: 'David'})--(otherPerson)-->()
WITH otherPerson, count(*) AS foaf //聚合 COUNT
WHERE foaf > 1 //过滤,类似SQL HAVING
RETURN otherPerson.name
结果排序
MATCH (n)
WITH n
ORDER BY n.name DESC
LIMIT 3
RETURN collect(n.name)
分支限制
可以匹配路径,限制到一定数量,然后使用这些路径作为基础再次匹配,以及任意数量的类似有限搜索。
MATCH (n {name: 'Anders'})--(m)
WITH m //从这个地方开始,对m进行限制
ORDER BY m.name DESC
LIMIT 1 //返回第一个记录
MATCH (m)--(o) //基于返回的记录,再进行匹配。
RETURN o.name
限制后过滤
UNWIND [1, 2, 3, 4, 5, 6] AS x
WITH x
LIMIT 5 //先限制
WHERE x > 2 //再过滤
RETURN x
UNWIND
展开List的元素。
UNWIND [1, 2, 3, null] AS x //结果为4行记录:1,2,3,null
UNWIND [] AS empty //返回0行记录。
UNWIND null AS x //展开一个非List元素,返回0行记录
UNWIND $events AS event //可以对参数进行展开
WHERE
WHERE子句本身并不是一个子句— —相反,它是MATCH、OPTIONAL MATCH和WITH子句的一部分。
当与MATCH和OPTIONAL MATCH一起使用时,WHERE会向所描述的模式添加约束。在匹配完成后,它不应该被视为一个过滤器。然而,在WITH的情况下,WHERE只是过滤结果。
在有多个MATCH / OPTIONAL MATCH子句的情况下,WHERE中的谓词总是最为最接近的前面的MATCH / OPTIONAL MATCH中的模式的一部分。如果将WHERE放在错误的MATCH子句中,结果和性能都可能受到影响。
//节点模式断言
WITH 30 AS minAge
MATCH (a:Person WHERE a.name = 'Andy')-[:KNOWS]->(b:Person WHERE b.age > minAge)
RETURN b.name
///约束Label 1
MATCH (a:Person {name: 'Andy'})
RETURN [(a)-->(b WHERE b:Person) | b.name] AS friends //约束b。
//boolean操作
MATCH (n:Person)
WHERE n.name = 'Peter' XOR (n.age < 30 AND n.name = 'Timothy') OR NOT (n.name = 'Timothy' OR n.name = 'Peter')
RETURNn.name AS name,n.age AS age
ORDER BY name
//约束Label 2
MATCH (n)
WHERE n:Swedish
RETURN n.name, n.age
//约束节点属性
MATCH (n:Person)
WHERE n.age < 30
RETURN n.name, n.age
//约束关系属性
MATCH (n:Person)-[k:KNOWS]->(f)
WHERE k.since < 2000
RETURN f.name, f.age, f.email
//约束动态节点属性
WITH 'AGE' AS propname
MATCH (n:Person)
WHERE n[toLower(propname)] < 30
RETURN n.name, n.age
//约束关系
WITH 2000 AS minYear
MATCH (a:Person)-[r:KNOWS WHERE r.since < minYear]->(b:Person)
RETURN r.since
与With一起使用
MATCH (n:Person)
WITH n.name as name
WHERE n.age = 25
RETURN name
字符串匹配
MATCH (n:Person)
WHERE n.name STARTS WITH 'Pet'WHERE n.name ENDS WITH 'ter'WHERE n.name CONTAINS 'ete'WHERE NOT n.name ENDS WITH 'y'WHERE n.name =~ 'Tim.*'WHERE n.email =~ '.*\\.com'WHERE n.name =~ '(?i)AND.*' //大小写不敏感
路径模式约束
模式是Cypher中的表达式,它返回一个路径列表。列表表达式也是谓词;空列表表示false,非空列表表示true。
模式不仅是表达式,也是谓词。模式的唯一限制是它必须能够在单一路径中表达它。与MATCH不同,不能在多个路径之间使用逗号。要使用WHERE组合多个模式,请使用AND。注意,不能引入新的变量。尽管它可能看起来与MATCH模式非常相似,但WHERE子句用于消除匹配的路径。MATCH (a)-[]→(b)与WHERE (a)-[]→(b)非常不同。前者将为它能找到的a和b之间的每一条路径生成一条路径,而后者将消除a和b之间没有直接关系链的任何匹配路径。
MATCH(timothy:Person {name: 'Timothy'}),(other:Person)
WHERE other.name IN ['Andy', 'Peter'] AND (other)-->(timothy) //约束关系。
RETURN other.name, other.age
ORDER BY
ORDER BY是RETURN或WITH后续的子句,它指定输出应该排序以及如何排序。
MATCH (n)
WITH n ORDER BY n.age
RETURN collect(n.name) AS names
ORDER BY 可以基于表达式结果排序。
MATCH (n)
RETURN n.name, n.age, n.length
ORDER BY keys(n) //keys
SKIP,LIMIT
MATCH (n)
RETURN n.name
ORDER BY n.name
SKIP 1
LIMIT 2
可以基于表达式结果
MATCH (n)
RETURN n.name
ORDER BY n.name
SKIP 1 + toInteger(3*rand())
CREATE
创建Node
CREATE (n) //创建单个节点
CREATE (n), (m) //创建多个节点
CREATE (n:Person)
CREATE (n:Person:Swedish)
CREATE (n:Person {name: 'Andy', title: 'Developer'})// 创建的节点,定义个变量,后续引用
CREATE (a {name: 'Andy'})
RETURN a.name
创建关系
MATCH(a:Person),(b:Person)
WHERE a.name = 'A' AND b.name = 'B'
CREATE (a)-[r:RELTYPE {name: a.name + '<->' + b.name}]->(b) //创建关系,并设置属性。
RETURN type(r), r.name
//一个路径
CREATE p = (:Person {name:'Andy'})-[:WORKS_AT]->(:Company {name: 'Neo4j'})<-[:WORKS_AT]-(:Person {name: 'Michael'})
RETURN p
DELETE
MATCH (n:Person {name: 'Laurence Fishburne'})-[r:ACTED_IN]->()
DELETE r
//删除节点,并删除它的关系
MATCH (n:Person {name: 'Carrie-Anne Moss'})
DETACH DELETE n //关系一起删除
SET
MATCH (n {name: 'Andy'})
SET n.surname = 'Taylor' //设置属性
RETURN n.name, n.surnameMATCH (n {name: 'Andy'})
SET n.surname = 'Taylor' //设置属性
RETURN n.name, n.surname
//移除属性
MATCH (n {name: 'Andy'})
SET n.name = null //null
RETURN n.name, n.age
//替换所有属性
MATCH (p {name: 'Peter'})
SET p = {name: 'Peter Smith', position: 'Entrepreneur'}
RETURN p.name, p.age, p.position
//移除所有属性
MATCH (p {name: 'Peter'})
SET p = {}
RETURN p.name, p.age
操作属性
使用map和+=改变特定属性:
-
map中不在节点或关系上的任何属性都将被添加。
-
map中不在节点或关系上的任何属性将保持原样。
-
map和节点或关系中的任何属性都将在节点或关系中被替换。但是,如果映射中的任何属性为
null,则将从节点或关系中删除该属性。
MATCH (p {name: 'Peter'})
SET p += {age: 38, hungry: true, position: 'Entrepreneur'}
RETURN p.name, p.age, p.hungry, p.position
REMOVE
//移除属性
MATCH (a {name: 'Andy'})
REMOVE a.age
RETURN a.name, a.age
//移除 Label
MATCH (n {name: 'Peter'})
REMOVE n:German
RETURN n.name, labels(n)
FOREACH
FOREACH子句用于更新集合中的数据,无论是路径的组件还是聚合的结果。
FOREACH括号内的变量上下文与其外部的变量上下文是分开的。这意味着,如果在FOREACH语句中创建节点变量,则不能在FOREACH语句之外使用它,除非进行匹配才能找到它。
在FOREACH括号内,您可以执行任何更新命令:SET、REMOVE、CREATE、MERGE、DELETE和FOREACH。
MATCH p=(start)-[*]->(finish)
WHERE start.name = 'A' AND finish.name = 'D'
FOREACH (n IN nodes(p) | SET n.marked = true)
MERGE
MERGE子句要么匹配图中的现有节点模式并绑定它们,要么(如果不存在)创建新数据并绑定它。通过这种方式,它充当MATCH和CREATE的组合,允许根据是否匹配或创建指定数据执行特定操作。
出于性能原因,强烈建议在使用MERGE时在标签或属性上创建模式索引。
当对完整模式使用MERGE时,行为是要么匹配整个模式,要么创建整个模式。MERGE不会部分地使用现有模式。如果需要部分匹配,可以通过将模式拆分为多个MERGE子句来实现。
在并发更新下,MERGE只保证MERGE模式的存在,而不保证唯一性。为了保证具有某些属性的节点的唯一性,应该使用属性唯一性约束。
与MATCH类似,MERGE可以匹配模式的多次出现。如果有多个匹配项,它们都将被传递到查询的后面阶段。
MERGE子句的最后一部分是ON CREATE和(或)ON MATCH操作符。这允许查询表达对节点或关系属性的附加更改,具体取决于元素是在数据库中匹配(MATCH)还是创建(CREATE)。
MERGE (robert:Critic)
RETURN robert, labels(robert)MERGE (charlie {name: 'Charlie Sheen', age: 10})
RETURN charlieMERGE (michael:Person {name: 'Michael Douglas'})
RETURN michael.name, michael.bornInMATCH (person:Person)
MERGE (location:Location {name: person.bornIn}) // 引用person的属性
RETURN person.name, person.bornIn, location
ON CREATE 和ON MATCH
Merge事件触发器
MERGE (keanu:Person {name: 'Keanu Reeves', bornIn: 'Beirut', chauffeurName: 'Eric Brown'})
ON CREATESET keanu.created = timestamp() //创建时,set 创建时间
RETURN keanu.name, keanu.createdMERGE (person:Person)
ON MATCHSET person.found = true //可以设置多个属性的。
RETURN person.name, person.foundMERGE (keanu:Person {name: 'Keanu Reeves'})
ON CREATESET keanu.created = timestamp()
ON MATCHSET keanu.lastSeen = timestamp()
RETURN keanu.name, keanu.created, keanu.lastSeen
//直接关系
MATCH(charlie:Person {name: 'Charlie Sheen'}),(wallStreet:Movie {title: 'Wall Street'})
MERGE (charlie)-[r:ACTED_IN]->(wallStreet)
RETURN charlie.name, type(r), wallStreet.title
//非直接关系
MATCH(charlie:Person {name: 'Charlie Sheen'}),(oliver:Person {name: 'Oliver Stone'})
MERGE (charlie)-[r:KNOWS]-(oliver)
RETURN r
MATCH (person:Person)
MERGE (person)-[r:HAS_CHAUFFEUR]->(chauffeur:Chauffeur {name: person.chauffeurName})//引用变量
RETURN person.name, person.chauffeurName, chauffeur
CALL
CALL { }
以RETURN语句结束的子查询称为返回子查询,而没有RETURN语句的子查询称为单元子查询。
对每个输入行求值一个子查询。返回子查询的每个输出行都与输入行组合以构建子查询的结果。这意味着返回的子查询将影响行数。如果子查询不返回任何行,则子查询之后将没有行可用。
另一方面,调用单元子查询是因为它们的副作用(即只用于修改,而不用于返回),而不是因为它们的结果,因此不会影响封闭查询的结果。
子查询({}中的子句)如何与封闭查询(外面的子句)交互是有限制的:
-
子查询只能引用封闭查询中的变量,如果它们是显式导入的。
-
子查询不能返回与封闭查询中的变量名称相同的变量。
-
从子查询返回的所有变量随后都可以在封闭查询中使用。
UNWIND [0, 1, 2] AS x
CALL { //子查询MATCH (n:Counter)SET n.count = n.count + 1RETURN n.count AS innerCount //返回的变量
}
WITH innerCount
MATCH (n:Counter)
RETURNinnerCount,n.count AS totalCount
Post-union
CALL {MATCH (p:Person)RETURN pORDER BY p.age ASCLIMIT 1
UNION //返回结果集MATCH (p:Person)RETURN pORDER BY p.age DESCLIMIT 1
}
RETURN p.name, p.age
ORDER BY p.name
事务
LOAD CSV FROM 'file:///friends.csv' AS line
CALL {WITH lineCREATE (:Person {name: line[1], age: toInteger(line[2])})
} IN TRANSACTIONSMATCH (n)
CALL {WITH nDETACH DELETE n
} IN TRANSACTIONS
事务批次处理
可以根据提交当前事务和开始新事务之前要处理的输入行数来指定每个单独事务中要完成的工作量。输入行数是用of n rows(或of n ROW)修饰符设置的。如果省略,默认批处理大小为1000行。行数可以使用计算结果为正整数且不引用节点或关系的任何表达式来表示。
LOAD CSV FROM 'file:///friends.csv' AS line
CALL {WITH lineCREATE (:Person {name: line[1], age: toInteger(line[2])})
} IN TRANSACTIONS OF 2 ROWS //2行一个事务
异常处理
用户可以从三个不同的选项标志中选择一个来控制在CALL{…}中的事务:
ON ERROR CONTINUE:忽略可恢复的错误并继续执行后续的内部事务。外部事务成功。它将导致来自失败的内部查询的预期变量被绑定为该特定事务的空值。
ON ERROR BREAK:忽略可恢复的错误并停止后续内部事务的执行。外部事务成功。它将导致来自失败内部查询的预期变量被绑定为空,用于所有后续事务(包括失败的事务)。
ON ERROR FAIL不能确认可恢复的错误并停止后续内部事务的执行。外部事务失败。如果没有显式指定标志,这是默认行为。
UNWIND [1, 0, 2, 4] AS i
CALL {WITH iCREATE (n:Person {num: 100/i}) // Note, fails when i = 0RETURN n
} IN TRANSACTIONSOF 1 ROWON ERROR CONTINUE
RETURN n.num;
状态报告
可以使用report status作为变量来报告内部事务的执行状态,这个标志在ON ERROR FAIL时是不允许的。每次内部查询执行完成后(无论成功与否),都会创建一个状态值,记录有关执行和执行它的事务的信息:
如果内部执行产生一行或多行作为输出,则在所选变量名称下向每一行添加到此状态值的绑定。
如果内部执行失败,则生成单行,其中包含到所选变量下的此状态值的绑定,以及内部查询(如果有的话)应该返回的所有变量的空绑定。
状态值是一个Map值,包含以下字段:
Started:内部事务启动时为true,否则为false。Committed,当内部事务更改成功提交时为true,否则为false。transactionId:内部事务id,如果事务没有启动,则为空。errorMessage,内部事务错误消息,如果没有错误则为null。
UNWIND [1, 0, 2, 4] AS i
CALL {WITH iCREATE (n:Person {num: 100/i}) // Note, fails when i = 0RETURN n
} IN TRANSACTIONSOF 1 ROWON ERROR CONTINUEREPORT STATUS AS s
RETURN n.num, s;
限制
-
嵌套的
CALL{…}子句不受支持。 -
不支持
UNION中的IN TRANSACTIONS。 -
不支持在写子句之后的
IN TRANSACTIONS,除非该写子句是在CALL{…}中。
另外,当在CALL子查询中使用 WITH子句时,有一些限制:
-
只有通过
with子句导入的变量才能被使用。 -
在导入的
WITH子句中不允许使用表达式或别名。 -
不可能在导入
WITH子句之后加上以下任何子句:DISTINCT、ORDER BY、WHERE、SKIP和LIMIT。
CALL 方法
UNION
USE
Load CSV
-
CSV文件的URL是通过使用
FROM指定的,后面跟着一个URL的任意表达式。 -
需要使用
AS为CSV数据指定一个变量。 -
CSV文件可以存储在数据库服务器上,然后使用
file:/// URL访问。另外,LOAD CSV还支持通过HTTPS、HTTP和FTP访问CSV文件。 -
LOAD CSV支持使用
gzip和Deflate压缩的资源。此外,LOAD CSV支持本地存储的CSV文件压缩与ZIP。 -
LOAD CSV将遵循
HTTP重定向,但出于安全原因,它不会遵循更改协议的重定向,例如,如果重定向从HTTPS转到HTTP。 -
LOAD CSV通常与查询子句
CALL{…}in TRANSACTIONS一起使用。
文件URLs配置
dbms.security.allow_csv_import_from_file_urls:是否支持 file:/// 协议。默认true。
server.directories.import:file:/// 文件的根目录,仅对本地文件有效。
CSV文件格式
-
字符编码为UTF-8
-
结束行终止取决于系统,例如,在Unix上是\n,在windows上是\r\n;
-
默认的字段结束符是
, -
字段结束符可以通过使用
LOAD CSV命令中的FIELDTERMINATOR选项来更改; -
CSV文件中允许使用带引号的字符串,并且在读取数据时删除引号;
-
字符串引号的字符是双引号
" -
如果
dbms.import.csv.legacy_quote_escaping设置为默认值true,\用作转义字符; -
双引号必须位于带引号的字符串中,并使用转义字符或第二个双引号进行转义。
导入
LOAD CSV FROM 'file:///artists.csv' AS line //给每行命名一个变量
CREATE (:Artist {name: line[1], year: toInteger(line[2])}) //变量通过[]引用属性LOAD CSV FROM 'https://data.neo4j.com/bands/artists.csv' AS line
CREATE (:Artist {name: line[1], year: toInteger(line[2])})
//第一行为列头: WITH HEADERS
LOAD CSV WITH HEADERS FROM 'file:///artists-with-headers.csv' AS line
CREATE (:Artist {name: line.Name, year: toInteger(line.Year)})
//自定义 字段分隔符
LOAD CSV FROM 'file:///artists-fieldterminator.csv' AS line FIELDTERMINATOR ';'
CREATE (:Artist {name: line[1], year: toInteger(line[2])})//事务支持
LOAD CSV FROM 'file:///artists.csv' AS line
CALL {WITH lineCREATE (:Artist {name: line[1], year: toInteger(line[2])})
} IN TRANSACTIONS
//linenumber() 返回行记录
LOAD CSV FROM 'file:///artists.csv' AS line
RETURN linenumber() AS number, line
// file() 获取文件path
LOAD CSV FROM 'file:///artists.csv' AS line
RETURN DISTINCT file() AS path
SHOW
SHOW [ALL|BUILT IN|USER DEFINED] FUNCTION[S]
[YIELD { * | field[, ...] } [ORDER BY field[, ...]] [SKIP n] [LIMIT n]]
[WHERE expression]
[RETURN field[, ...] [ORDER BY field[, ...]] [SKIP n] [LIMIT n]]SHOW PROCEDURE[S]
[YIELD { * | field[, ...] } [ORDER BY field[, ...]] [SKIP n] [LIMIT n]]
[WHERE expression]
[RETURN field[, ...] [ORDER BY field[, ...]] [SKIP n] [LIMIT n]]SHOW SETTING[S] [setting-name[,...]]
[YIELD { * | field[, ...] } [ORDER BY field[, ...]] [SKIP n] [LIMIT n]]
[WHERE expression]
[RETURN field[, ...] [ORDER BY field[, ...]] [SKIP n] [LIMIT n]]SHOW TRANSACTION[S] [transaction-id[,...]]
[YIELD { * | field[, ...] } [ORDER BY field[, ...]] [SKIP n] [LIMIT n]]
[WHERE expression]
[RETURN field[, ...] [ORDER BY field[, ...]] [SKIP n] [LIMIT n]]TERMINATE TRANSACTION[S] transaction_id[, ...]
[YIELD { * \| field[, ...] }[ORDER BY field[, ...]][SKIP n][LIMIT n][WHERE expression][RETURN field[, ...] [ORDER BY field[, ...]] [SKIP n] [LIMIT n]]
]
节点变量 (Node variables)
如果我们以后想要引用某个节点,我们可以给它一个变量,比如§代表person或者(t)代表thing。
如果节点与返回的结果不相关,可以使用空括号()指定一个匿名节点。这意味着您不能在稍后的查询中返回此节点。
节点标签 (Node labels)
如果您还记得属性图数据模型,还可以通过分配节点标签将相似的节点分组在一起。标签允许你指定要查找或创建的特定类型的实体。在我们的示例中,Person、Technology和Company是标签。
你可以把这想象成告诉SQL在哪个表中查找特定的行。就像告诉SQL从person或Employee或Customer表中查询一个人的信息一样,您也可以告诉Cypher只检查这些信息的标签。这有助于Cypher区分实体并优化查询的执行。在可能的情况下,在查询中使用节点标签总是更好。
不指定标签,则会查询所有节点,性能会严重下降。
() //匿名节点(no label or variable) ,后面不能引用
(p:Person) //using variable p and label Person
(:Technology) //no variable, label Technology
(work:Company) //using variable work and label Company
关系类型 (Relationship types)
关系类型对关系进行分类并添加意义,类似于标签对节点进行分组的方式。在我们的属性图数据模型中,关系表示节点如何相互连接和关联。通常可以通过查找动作或动词来识别数据模型中的关系。
[:LIKES] - makes sense when we put nodes on either side of the relationship (Sally LIKES Graphs)
[:IS_FRIENDS_WITH] - makes sense when we put nodes with it (Sally IS_FRIENDS_WITH John)
[:WORKS_FOR] - makes sense with nodes (Sally WORKS_FOR Neo4j)
关系变量 (Relationship variables)
想在查询的后面引用一个关系,我们可以给它一个变量,比如[r]或[rel]。如果以后不需要引用该关系,则可以使用两个破折号--, -->, <--指定匿名关系。
例如,您可以使用-[rel]->或-[rel:LIKES]->并在稍后的查询中调用rel变量来引用关系及其详细信息。
如果您忘记了关系类型前面的冒号(
:),例如-[LIKES]->,它表示一个变量(而不是关系类型)。由于没有声明关系类型,Cypher搜索所有类型的关系。
节点或关系属性 (Node or relationship properties)
属性是名称-值对,它为节点和关系提供了额外的细节。在Cypher中,我们可以在节点的括号内或关系的括号内使用花括号。然后将属性的名称和值放入花括号内。我们的示例图有一个节点属性(name)和一个关系属性(since)。
Node property: (p:Person {name: 'Sally'})
Relationship property: -[rel:IS_FRIENDS_WITH {since: 2018}]->
属性可以具有各种数据类型的值。
Cypher模式
节点和关系构成了图形模式的构建块。这些构建块可以组合在一起来表达简单或复杂的模式。模式是图最强大的功能。在Cypher中,它们可以写成连续的路径,也可以分成更小的模式,并用逗号连接在一起。
要在Cypher中显示模式,需要将目前所学的节点和关系语法结合起来。
在Cypher中,该模式类似于下面的代码。
(p:Person {name: "Sally"})-[rel:LIKES]->(g:Technology {type: "Graphs"})
普通
:guide cypher #附录
参考
导入数据:https://neo4j.com/docs/getting-started/data-import/
Cypher :https://neo4j.com/docs/cypher-manual/current/introduction/
相关文章:
--语法和子句)
neo4j查询语言Cypher详解(一)--语法和子句
前言 neo4j的图查询语言叫Cypher。Cypher的独特之处在于它提供了一种匹配模式和关系的可视化方式。 (nodes)-[:ARE_CONNECTED_TO]->(otherNodes)使用圆角括号表示节点(nodes), -[:ARROWS]->表示关系。 语法 解析 Cypher解析器接受任意输入字符串。 unico…...

PCIe总线详解
一、PCIe简介 PCI Express (peripheral component interconnect express) 简称PCIe,是一种高速、串行、全双工、计算机扩展总线标准,采用高速差分总线,并采用端到端的连接方式,因此在每一条PCIe链路中两端只能各连接一个设备。相对…...
【vim 学习系列文章 4 - vim与系统剪切板之间的交互】
文章目录 背景1.1.1 vim支持clipboard 检查1.1.2 vim的寄存器 上篇文章:【vim 学习系列文章 3 - vim 选中、删除、复制、修改引号或括号内的内容】 背景 从vim中拷贝些文字去其它地方粘贴,都需要用鼠标选中vim的文字后,Ctrlc、Ctrlv&#x…...

代码随想录算法训练营第五十六天| 583. 两个字符串的删除操作 72. 编辑距离
代码随想录算法训练营第五十六天| 583. 两个字符串的删除操作 72. 编辑距离 一、力扣583. 两个字符串的删除操作 题目链接 思路:相等时不删除,不相等时,两个字符串各删除一个,比大小,删除用步骤少的。 class Soluti…...
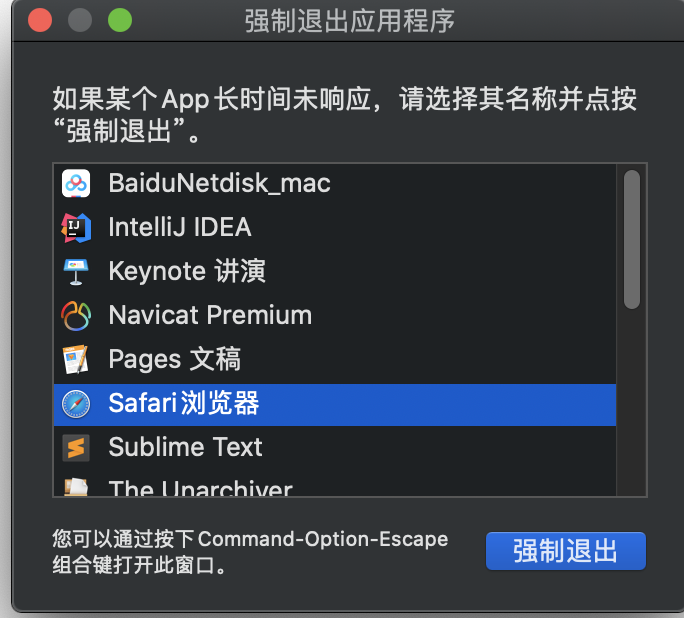
Mac强制停止应用
有时候使用Mac的时候,某个应用卡住了,但是肯定不能因为一个应用卡住了, 就将电脑重启吧,所以只需要单独停止该应用即可,使用快捷键optioncommandesc就会出现强制停止的界面,选择所要停止的应用,…...

Linux系统Redis的哨兵架构配置
Linux系统Redis的哨兵架构配置 此处基于 Linux系统Redis的主从架构配置 进行哨兵高可用架构的搭建 此案例在一台虚拟机上启动6379和6380和6381三个reids主从实例(6379为主节点,6380和6381为从节点),以及26379、26380、26381的sent…...

HarmonyOS/OpenHarmony-ArkTS基于API9元服务开发快速入门
一、创建项目 二、创建卡片 三、添加资源 四、具体代码 Entry Component struct WidgetNewCard {/** The title.*/readonly TITLE: string harmonyOs;readonly CONTEXT: string 技术构建万物智联;/** The action type.*/readonly ACTION_TYPE: string router;/** The…...
macbook怎么卸载软件?2023年最新全新解析macbook电脑怎样删除软件
macbook怎么卸载软件?2023年最新全新解析macbook电脑怎样删除软件。关于Mac笔记本如何卸载软件_Mac笔记本卸载软件的四种方法的知识大家了解吗?以下就是小编整理的关于Mac笔记本如何卸载软件_Mac笔记本卸载软件的四种方法的介绍,希望可以给到…...
c51单片机16个按键密码锁源代码(富proteus电路图)
注意了:这个代码你是没法直接运行的,但是如果你看得懂,随便改一改不超过1分钟就可以用 #include "reg51.h" #include "myheader.h" void displayNumber(unsigned char num) {if(num1){P10XFF;P10P11P14P15P160;}else if…...

GraalVM
一、GraalVM GraalVM 是由 Oracle 开发的一个高性能、高效的通用虚拟机。它是一个全球性的项目,涵盖了多种编程语言和平台,并为开发者提供了一种统一的虚拟机环境。GraalVM 的核心特性是支持多语言混合执行,即在同一个运行时环境中同时执行多…...

File 类和 InputStream, OutputStream 的用法总结
目录 一、File 类 1.File类属性 2.构造方法 3.普通方法 二、InputStream 1.方法 2.FileInputStream 三、OutputStream 1.方法 2.FileOutputStream 四、针对字符流对象进行读写操作 一、File 类 1.File类属性 修饰符及类型属性说明static StringpathSeparator依赖于系统的路…...

开源进展 | WeBASE v3.1.0发布,新增多个实用特性
WeBASE是一个友好、功能丰富的区块链中间件平台,通过一系列通用功能组件和实用工具,助力社区开发者更快捷地与区块链进行交互。 目前WeBASE已更新迭代至v3.1.0版本,本次更新中,WeBASE带来了最新的合约Java脚手架导出功能ÿ…...

C++动态加载 插件
动态加载(Dynamic Loading)是指在程序运行时,根据需要动态地加载和链接代码或资源。 动态加载的主要目的是实现程序的灵活性和可扩展性,以及减少内存消耗和启动时间。通过动态加载,程序可以根据运行时的需求加载特定的…...

redis的缓存更新策略
目录 三种缓存更新策略 业务场景: 主动更新的三种实现 操作缓存和数据库时有三个问题 1.删除缓存还是更新缓存? 2.如何保证缓存与数据库的操作的同时成功或失败? 3.先操作缓存还是先操作数据库? 缓存更新策略的最佳实践方案&am…...
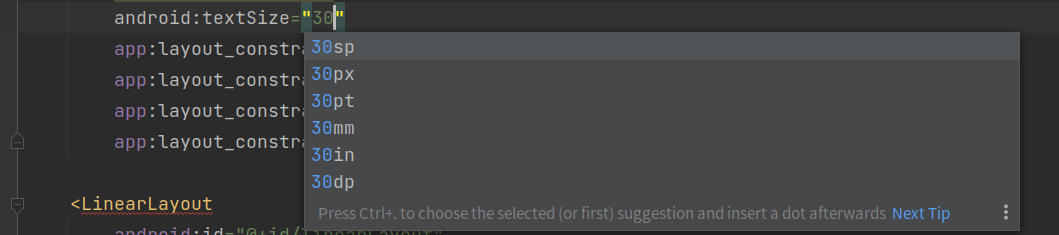
Android应用开发(6)TextView进阶用法
Android应用开发学习笔记——目录索引 本章介绍文本视图(TextView)的显示,包括:设置文本内容、设置文本大小、设置文本显示颜色。 一、设置TextView显示内容 Layout XML文件中设置 如:res/layout/activity_main.xm…...
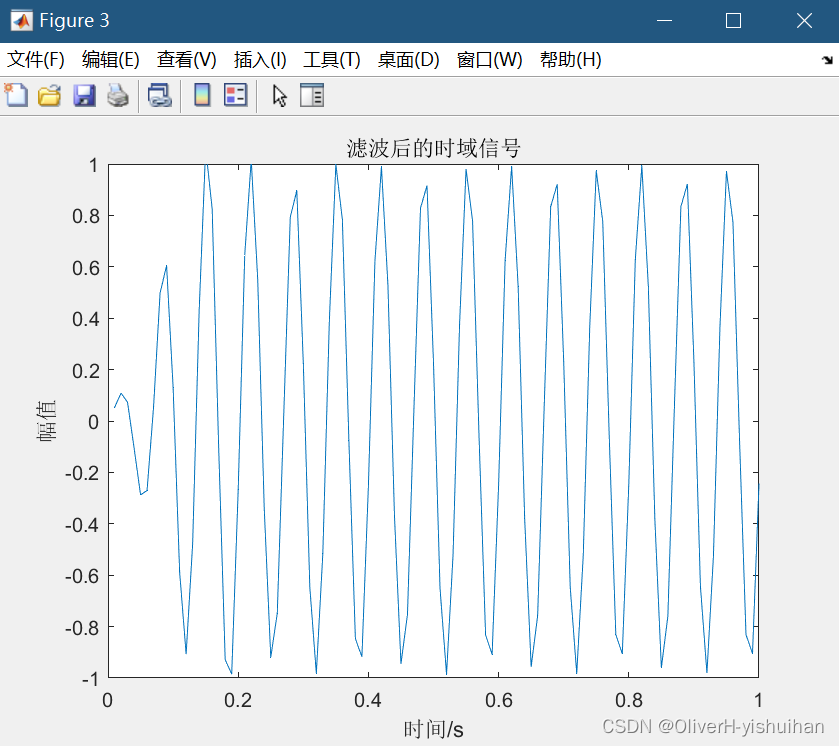
Matlab滤波、频谱分析
Matlab滤波、频谱分析 滤波: 某目标信号是由5、15、30Hz正弦波混合而成的混合信号,现需要设计一个滤波器滤掉5、30Hz两种频率。 分析:显然我们应该设计一个带通滤波器,通带频率落在15Hz附近。 % 滤波 % 某目标信号是由5、15、3…...

车载软件架构 —— 车载软件入侵检测系统
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 没有人关注你。也无需有人关注你。你必须承认自己的价值,你不能站在他人的角度来反对自己。人…...

“深入解析JVM内部机制:理解Java虚拟机的工作原理“
标题:深入解析JVM内部机制:理解Java虚拟机的工作原理 摘要:本文将深入探讨Java虚拟机(JVM)的内部机制,解释其工作原理。我们将讨论JVM的组成部分、类加载过程、运行时数据区域以及垃圾回收机制。此外&…...
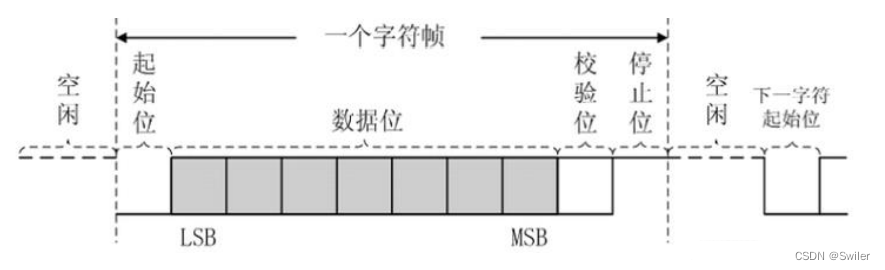
FPGA初步学习之串口发送模块【单字节和字符串的发送】
串口相关简介 UART 在发送或接收过程中的一帧数据由4部分组成,起始位、数据位、奇偶校验位和停止位,如图所示。其中,起始位标志着一帧数据的开始,停止位标志着一帧数据的结束,数据位是一帧数据中的有效数据。 通常用…...

Kotlin重点理解安全性
目录 一 Kotlin安全性1.1 可空类型1.2 安全调用运算符1.3 Elvis 运算符1.4 非空断言运算符1.5 安全类型转换1.6 延迟初始化 一 Kotlin安全性 Kotlin 在设计时采用了一系列策略,旨在尽可能地减少空指针异常(NullPointerException)的出现。空指…...

Python 使用 `raise` 报错抛出异常显示 Unicode 码如何解决
在 Python 开发中,我们经常使用 raise 抛出异常来处理错误情况。但有时候,异常信息中的中文或其他非 ASCII 字符会被显示为 Unicode 转义序列(如 \u6b63\u6587),而不是直接显示中文(如“正文”)…...
)
Fedora 40 虚拟机避坑指南:VMware 17.5 安装与内核降级实战(解决卡顿与兼容性问题)
Fedora 40 虚拟机性能优化全攻略:从内核调优到图形加速的深度实践 当你在VMware Workstation 17.5上运行Fedora 40时,是否遇到过系统卡顿、响应迟缓的问题?这并非个例——最新Linux发行版与虚拟化平台间的兼容性挑战,往往让开发者…...

Godot资源解压器godotdec:从游戏资源保护到开发分析的技术实践
Godot资源解压器godotdec:从游戏资源保护到开发分析的技术实践 【免费下载链接】godotdec An unpacker for Godot Engine package files (.pck) 项目地址: https://gitcode.com/gh_mirrors/go/godotdec 在游戏开发与资源管理领域,Godot引擎的.pck…...

KeymouseGo:让重复操作自动化的效率工具指南
KeymouseGo:让重复操作自动化的效率工具指南 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo 在数字化工作环境中…...

解决Swagger2集成中v2/api-docs接口404问题的关键:正确配置Docket分组
1. 为什么访问v2/api-docs会返回404? 这个问题困扰过不少开发者。当你兴冲冲地集成完Swagger2,打开swagger-ui.html页面,却发现页面一片空白,控制台报错显示v2/api-docs接口返回404。更让人抓狂的是,单独访问这个接口时…...

如何一次删除iPad上的多个应用程序? - 5 种有效方法
随着时间的推移,您的 iPad 可能会积累许多不必要的应用程序,导致存储空间不足并影响设备性能。因此,最好的方法是删除这些应用程序。然而,逐个删除它们可能很耗时;一次性删除多个应用程序可以更有效地释放空间并提高设…...

基于三菱PLC的自动配料控制系统的设计
基于PLC的自动配料控制系统设计【配套10000字设计lumwen,三菱PLC组态王组态等】 基于三菱PLC的自动配料控制系统的设计 混凝土搅拌站分为:砂石给料、水和一些特殊的加剂给料、传输搅拌与存储 搅拌机控制系统上电后,进入人机对话的操作界面&am…...
轻量化CLIP推理部署)
万象视界灵坛部署案例:边缘设备(Jetson Orin)轻量化CLIP推理部署
万象视界灵坛部署案例:边缘设备(Jetson Orin)轻量化CLIP推理部署 1. 项目概述 万象视界灵坛(Omni-Vision Sanctuary)是一款基于OpenAI CLIP模型的高级多模态智能感知平台。该平台通过创新的像素风格界面设计…...

从数据孤岛到智能决策中枢:一体化系统如何重构 HR 数据流
去年某制造企业 HR 总监跟我抱怨:员工入职要在招聘系统录一遍信息,转正时人事系统再录一遍,发工资时薪酬系统又要重新核对。三个系统互不相通,一个员工的完整档案要从三个地方拼凑。这不是个例,而是很多企业正在经历的…...

前端框架选择指南:别再盲目跟风了!
前端框架选择指南:别再盲目跟风了! 毒舌时刻 前端框架?听起来就像是前端工程师为了显得自己很专业而特意搞的一套复杂流程。你以为随便选个框架就能解决所有问题?别做梦了!到时候你会发现,框架的坑比你想象…...