因果推断(三)双重差分法(DID)
因果推断(三)双重差分法(DID)
双重差分法是很简单的群体效应估计方法,只需要将样本数据随机分成两组,对其中一组进行干预。在一定程度上减轻了选择偏差带来的影响。
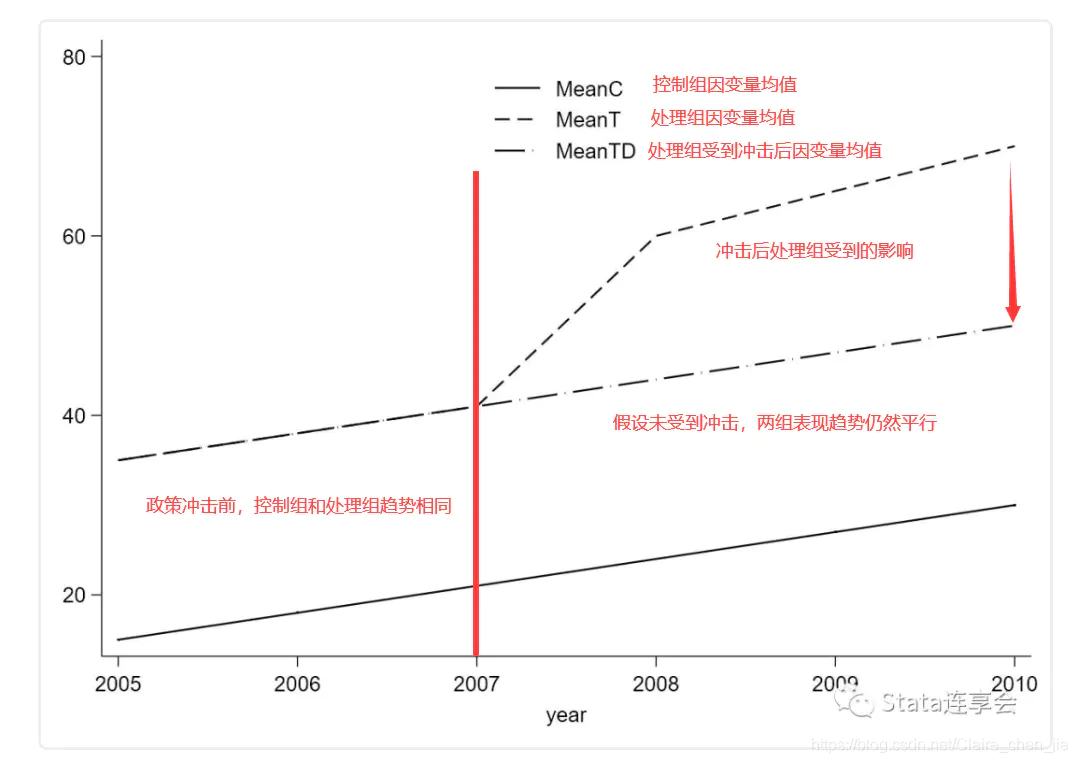
因果效应计算:对照组y在干预前后的均值差( A ˉ 2 − A ˉ 1 \bar A_2 - \bar A_1 Aˉ2−Aˉ1),实验组y在干预前后的均值差( B ˉ 2 − B ˉ 1 \bar B_2 - \bar B_1 Bˉ2−Bˉ1),则因果效应: ( B ˉ 2 − B ˉ 1 ) − ( A ˉ 2 − A ˉ 1 ) (\bar B_2 - \bar B_1)-(\bar A_2 - \bar A_1) (Bˉ2−Bˉ1)−(Aˉ2−Aˉ1)
假设前提:DID有一个很重要且很严格的平行趋势假设,即实验组和对照组在没有干预的情况下,结果的趋势是一样的。
准备数据
from faker import Faker
from faker.providers import BaseProvider, internet
from random import randint
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import math
import statsmodels.formula.api as smf
import warningswarnings.filterwarnings('ignore')# 绘图初始化
%matplotlib inline
sns.set(style="ticks")
# 自定义数据
fake = Faker('zh_CN')
class MyProvider(BaseProvider):def myCityLevel(self):cl = ["一线", "二线", "三线", "四线+"]return cl[randint(0, len(cl) - 1)]def myGender(self):g = ['F', 'M']return g[randint(0, len(g) - 1)]
fake.add_provider(MyProvider)# 构造假数据,模拟用户特征
uid=[]
cityLevel=[]
gender=[]
for i in range(10000):uid.append(i+1)cityLevel.append(fake.myCityLevel())gender.append(fake.myGender())raw_data= pd.DataFrame({'uid':uid,'cityLevel':cityLevel,'gender':gender,})raw_data['class'] = raw_data['uid'].map(lambda x: 'A' if x % 2 == 1 else 'B') # 按奇偶随机分组# 构造did数据
df = pd.DataFrame(columns=['uid','cityLevel','gender', 'class', 'sales', 'dt'])
for i,j in enumerate(range(2005,2011)):lift = 1+i*0.05df_temp = raw_data.copy()df_temp['sales'] = [int(x) for x in np.random.normal(300*lift, 60*lift, df_temp.shape[0])]df_temp['sales'] = df_temp.apply(lambda x: x.sales*0.88 if x['class']=='A' else x.sales, axis=1)if j>2007:df_temp['sales'] = df_temp.apply(lambda x: x.sales*(1+i*0.02) if x['class']=='B' else x.sales, axis=1)df_temp['dt'] = jdf=pd.concat([df,df_temp])df_did = df.groupby(['class', 'dt'])['sales'].sum().reset_index()
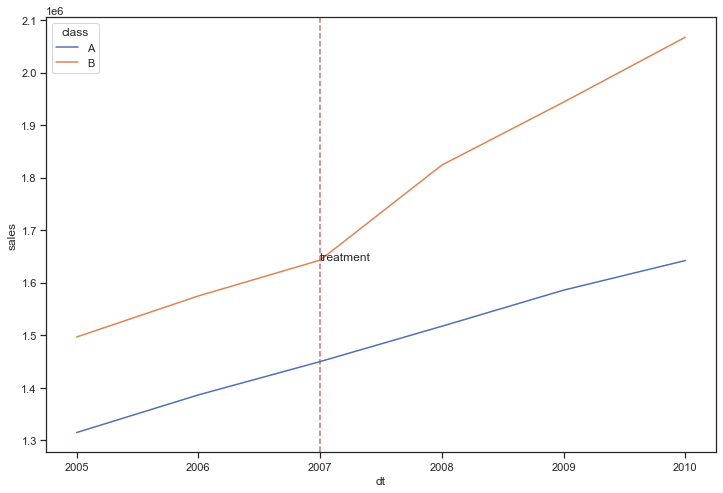
验证平行趋势假设
# 计算文字的y坐标
y_text = df_did.query('dt == 2007 and `class`=="B"')['sales'].values[0]
# 绘图查看干预前趋势
fig, ax = plt.subplots(figsize=(12,8))
sns.lineplot(x="dt", y="sales", hue="class", data=df_did)
ax.axvline(2007, color='r', linestyle="--", alpha=0.8)
plt.text(2007, y_text, 'treatment')
plt.show()
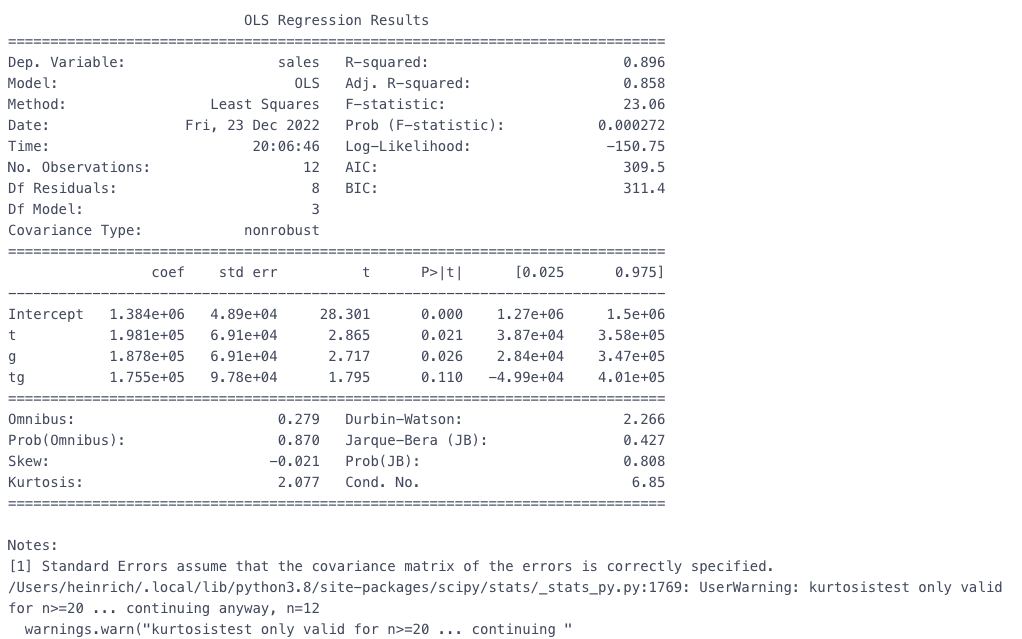
除了画图观察平行趋势,也可以通过回归拟合,参考自如何使用Python计算双重差分模型
# 方法2 回归计算 df_did['t'] = df_did['treatment'].map(lambda x: 1 if x=='干预后' else 0) # 是否干预后 df_did['g'] = df_did['class'].map(lambda x: 1 if x=='B' else 0) # 是否试验组 df_did['tg'] = df_did['t']*df_did['g'] # 交互项# 回归 est = smf.ols(formula='sales ~ t + g + tg', data=df_did).fit() print(est.summary())
可以看到交互项tg并不显著,因此可以认为具备平行趋势
计算因果效应
# 计算因果效应
df_did['treatment'] = df_did['dt'].map(lambda x: '干预后' if x>2007 else '干预前')
df_did_cal = df_did.groupby(['class', 'treatment'])['sales'].mean()
did = (df_did_cal.loc['B', '干预后'] - df_did_cal.loc['B', '干预前']) - \(df_did_cal.loc['A', '干预后'] - df_did_cal.loc['A', '干预前'])
print(did)
175541.82000000007
总结
在实际业务中,平行趋势假设是很难满足的,因此常常会先进性PSM构造相似的样本,这样两组群体基本上就会符合平行趋势假设了,所以常见以PSM+DID进行因果推断,有兴趣的同学可以结合这两期的内容自行尝试。
共勉~
相关文章:
因果推断(三)双重差分法(DID)
因果推断(三)双重差分法(DID) 双重差分法是很简单的群体效应估计方法,只需要将样本数据随机分成两组,对其中一组进行干预。在一定程度上减轻了选择偏差带来的影响。 因果效应计算:对照组y在干预…...
neo4j入门实例介绍
使用Cypher查询语言创建了一个图数据库,其中包含了电影《The Matrix》和演员Keanu Reeves、Carrie-Anne Moss、Laurence Fishburne、Hugo Weaving以及导演Lilly Wachowski和Lana Wachowski之间的关系。 CREATE (TheMatrix:Movie {title:The Matrix, released:1999,…...

CGAL-2D和3D线性几何内核-点和向量-内核扩展
文章目录 1.介绍1.1.鲁棒性 2.内核表示2.1.通过参数化实现泛型2.2.笛卡尔核2.3.同质核2.4.命名约定2.5.内核作为trait类2.6.选择内核和预定义内核 3.几何内核3.1.点与向量3.2.内核对象3.3.方位和相对位置 4.谓语和结构4.1.谓词4.2.结构4.3.交集和变量返回类型4.4.例子4.5.构造性…...

Ubuntu 22.04 安装docker
参考: https://docs.docker.com/engine/install/ubuntu/ 支持的Ubuntu版本: Ubuntu Lunar 23.04Ubuntu Kinetic 22.10Ubuntu Jammy 22.04 (LTS)Ubuntu Focal 20.04 (LTS) 1 卸载旧版本 非官方的安装包,需要先卸载: docker.io…...

电脑维护进阶:让你的“战友”更强大、更持久!
前言 无论是学习还是工作,电脑已经成为了IT人必不可少的得力助手。然而,电脑的性能和寿命需要经过细心的维护来保证。本文将详细探讨如何维护你的电脑,延长它的寿命,以及一些实用建议。 硬件保养篇 内部清洁 灰尘会导致电脑散热…...

【Leetcode】75.颜色分类
一、题目 1、题目描述 给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。 我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。 必须在不使用库内置的 sort 函数的情况下解决这个问…...

Pytesseract学习笔记
函数 pytesseract.image_to_string(image: Any, lang: Any None, …) 识别图像中的文本。 Parameters image(Any):输入图像,不接受bytes类型。...
cnvd通用型证书获取姿势
因为技术有限,只能挖挖不用脑子的漏洞,平时工作摸鱼的时候通过谷歌引擎引擎搜索找找有没有大点的公司有sql注入漏洞,找的方法就很简单,网站结尾加上’,有异常就测试看看,没有马上下一家,效率至上…...

elasticsearch的副本和分片的区别
es/elasticsearch的副本和分片的区别 一:概念 (1)集群(Cluster): ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互…...

Docker部署Gitlab
Docker部署Gitlab 文章目录 Docker部署Gitlab前置环境部署步骤初始化配置文件80端口部署方式(二选一)非80端口需要的部署方式(二选一)修改 gitlab.rb修改 gitlab.yml刷新配置 前置环境 docker 19.03.13 es 7.2.0 部署步骤 初始…...

ABeam News | ABeam大中华区新人入社式,开启崭新的职场探索之旅吧!
ABeam News | ABeam大中华区新人入社式,开启崭新的职场探索之旅吧! 隔空投送 很高兴认识你 7月3日,FY24 ABeam大中华区新人入社式在西安隆重举办,ABeam大中华区董事长兼总经理中野洋辅先生专程莅临入社式现场,与89名…...

【C++】开源:sqlite3数据库配置使用
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍sqlite3数据库配置使用。 无专精则不能成,无涉猎则不能通。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下,下…...
[Docker实现测试部署CI/CD----Jenkins集成相关服务器(3)]
目录 7、 Jenkins 集成 SonarQubeJenkins 中安装 SonarScanner下载移动修改配置文件 8、Jenkins配置SonarQube安装插件添加SonarQube添加 SonarScanner 9、Jenkins集成目标服务器 7、 Jenkins 集成 SonarQube Jenkins 中安装 SonarScanner SonarScanner 是一种代码扫描工具&am…...
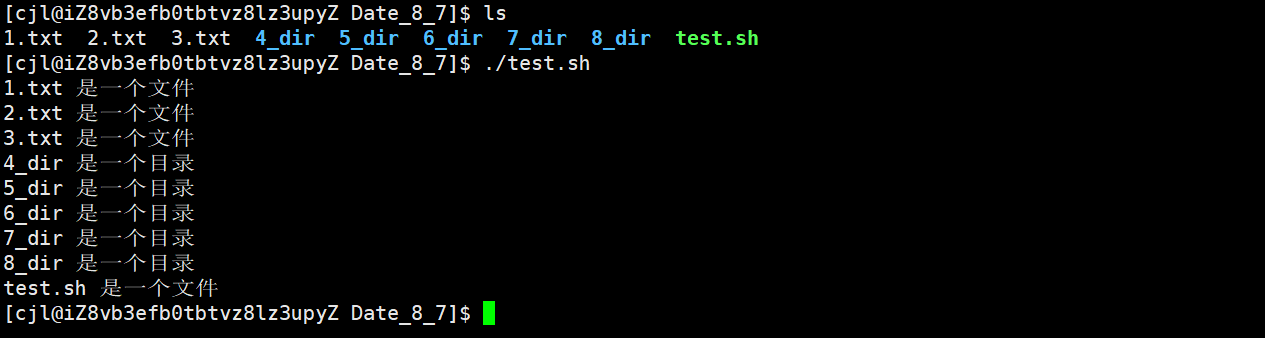
【Shell】基础语法(二)
文章目录 一、Shell基本语法文件名代换命令代换算术代换转义字符引号 二、Shell脚本语法条件测试分支结构循环 三、总结 一、Shell基本语法 文件名代换 用于匹配的字符称为通配符(Wildcard),如:* ? [ ] 具体如下: *…...
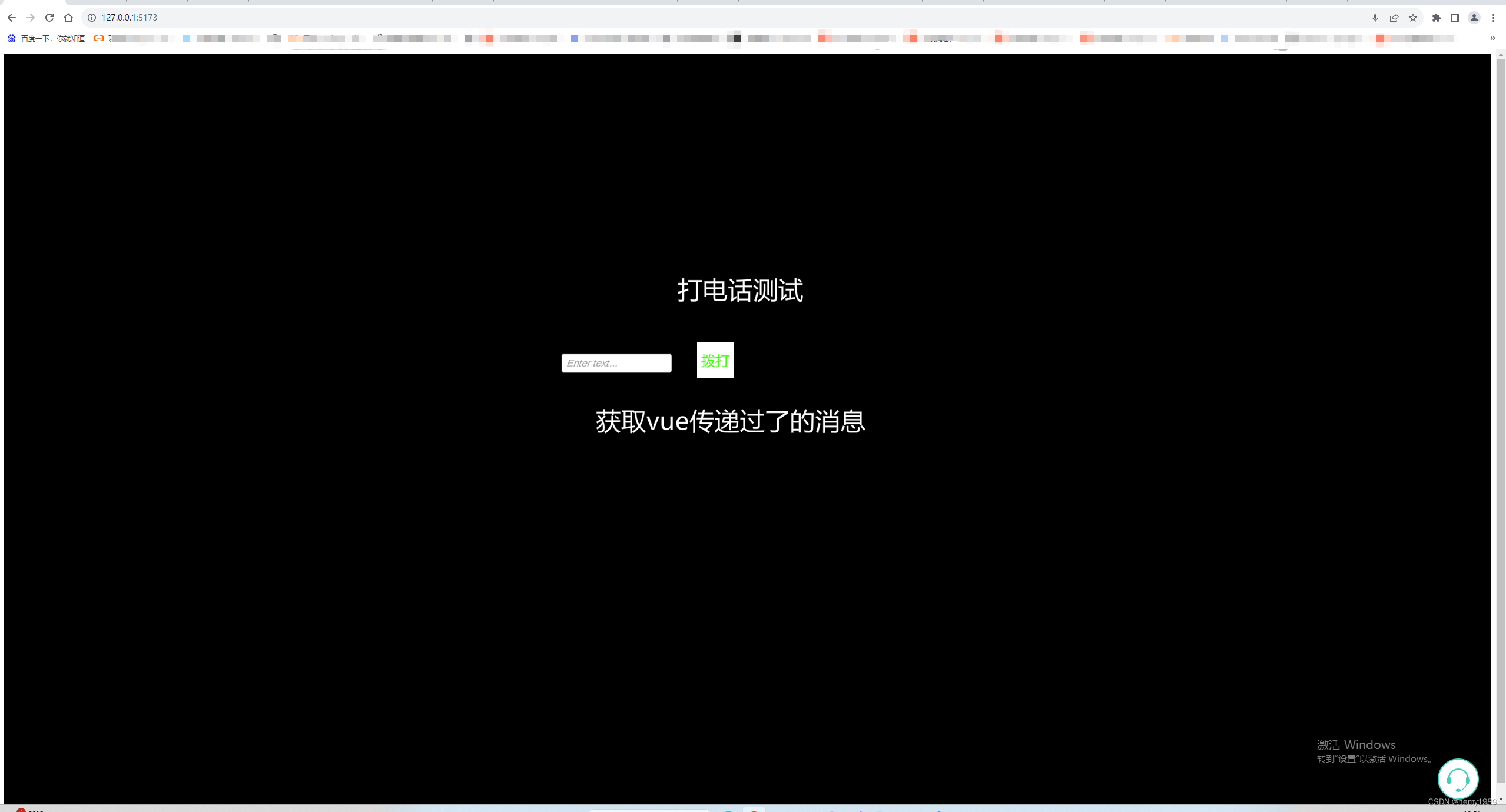
Unity之webgl端通过vue3接入腾讯云联络中心SDK
腾讯云联络中心SDK:云联络中心 Web-SDK 开发指南-文档中心-腾讯云 (tencent.com) 1 首先下载Demo 1.1 对其进行解压 1.2根据文档操作 查看README.md,根据说明设置server下的dev.js里的相关参数。 然后打开电脑终端,cd到项目的路径: 安装…...

《算法竞赛·快冲300题》每日一题:“连接草坪(II)”
《算法竞赛快冲300题》将于2024年出版,是《算法竞赛》的辅助练习册。 所有题目放在自建的OJ New Online Judge。 用C/C、Java、Python三种语言给出代码,以中低档题为主,适合入门、进阶。 文章目录 题目描述题解C代码Java代码Python代码 “ 连…...
LNMP及论坛搭建(第一个访问,单节点)
LNMP:目前成熟的一个企业网站的应用模式之一,指的是一套协同工作的系统和相关软件 能够提供静态页面服务,也可以提供动态web服务,LNMP是缩写 L:指的是Linux操作系统。 N:指的是nginx,nginx提…...
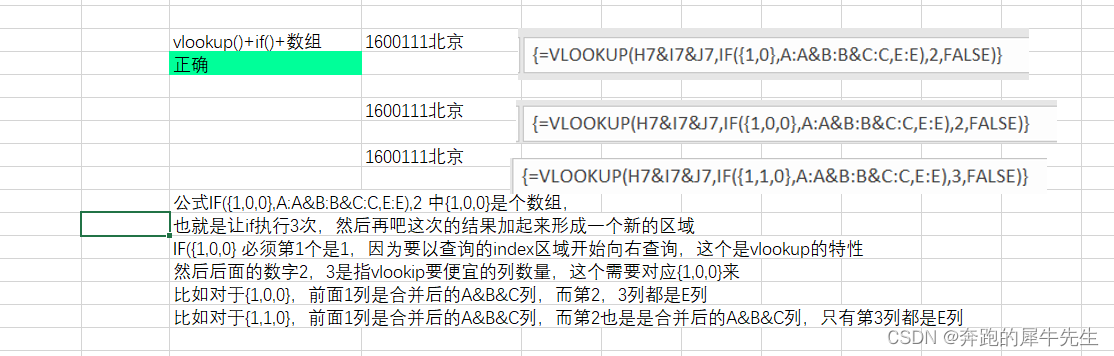
EXCEL,多条件查询数字/文本内容的4种方法
目录 1 问题:如何根据多条件查询到想要的内容 2 方法总结 2.1 方法1: sumif() 和sumifs() 适合查找符合条件的多个数值之和 2.2 方法2:使用lookup(1,0/((区域1条件1)*(区域2条件2)*....),结果查询区域) 2.3 方法3:使用 ind…...

全志D1-H (MQ-Pro)驱动 OV5640 摄像头
内核配置 运行 m kernel_menuconfig 勾选下列驱动 Device Drivers ---><*> Multimedia support --->[*] V4L platform devices ---><*> Video Multiplexer[*] SUNXI platform devices ---><*> sunxi video input (camera csi/mipi…...

2023下半年软考初级网络管理员报名入口-报名流程-备考方法
软考初级网络管理员2023下半年考试时间: 2023年下半年软考初级网络管理员的考试时间为11月4日、5日。考试时间在全国各地一致,建议考生提前备考。共分两科,第一科基础知识考试具体时间为9:00到11:30;第二科应用技术考试具体时间为…...
)
第二周(第12周)
1.单电源供电的二阶低通滤波器2.功率放大电路...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...
损坏诊断全解)
半导体元件(二极管/三极管/MOS管/IC)损坏诊断全解
半导体元件(二极管、三极管、MOS 管、集成电路)是 PCB 的核心功能单元,对过压、过流、ESD、高温极度敏感,损坏后直接导致电路功能失效、短路烧板。很多工程师维修时盲目更换芯片,不仅成本高,还易误判。一…...
)
CentOS服务器上VNC连接失败?手把手教你排查并修复个人端口问题(附重启命令)
CentOS服务器VNC连接故障深度排查指南:从原理到实战当你在深夜赶项目时,突然发现VNC连接不上服务器,那种焦虑感我深有体会。去年参与半导体器件仿真项目时,我也曾被这个问题困扰整整两天。本文将分享一套经过实战检验的排查方法论…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...