TextBrewer:融合并改进了NLP和CV中的多种知识蒸馏技术、提供便捷快速的知识蒸馏框架、提升模型的推理速度,减少内存占用
TextBrewer:融合并改进了NLP和CV中的多种知识蒸馏技术、提供便捷快速的知识蒸馏框架、提升模型的推理速度,减少内存占用
TextBrewer是一个基于PyTorch的、为实现NLP中的知识蒸馏任务而设计的工具包,
融合并改进了NLP和CV中的多种知识蒸馏技术,提供便捷快速的知识蒸馏框架,用于以较低的性能损失压缩神经网络模型的大小,提升模型的推理速度,减少内存占用。
1.简介
TextBrewer 为NLP中的知识蒸馏任务设计,融合了多种知识蒸馏技术,提供方便快捷的知识蒸馏框架。
主要特点:
- 模型无关:适用于多种模型结构(主要面向Transfomer结构)
- 方便灵活:可自由组合多种蒸馏方法;可方便增加自定义损失等模块
- 非侵入式:无需对教师与学生模型本身结构进行修改
- 支持典型的NLP任务:文本分类、阅读理解、序列标注等
TextBrewer目前支持的知识蒸馏技术有:
- 软标签与硬标签混合训练
- 动态损失权重调整与蒸馏温度调整
- 多种蒸馏损失函数: hidden states MSE, attention-based loss, neuron selectivity transfer, …
- 任意构建中间层特征匹配方案
- 多教师知识蒸馏
- …
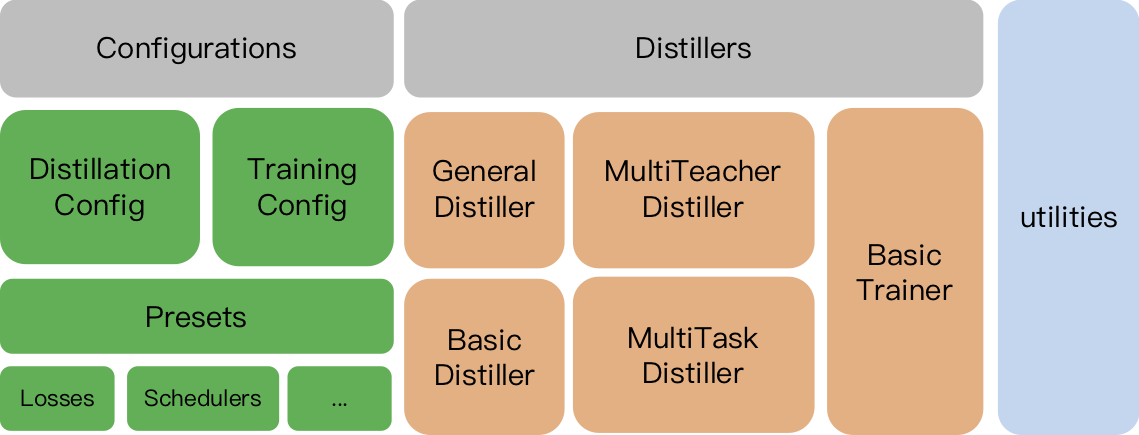
TextBrewer的主要功能与模块分为3块:
- Distillers:进行蒸馏的核心部件,不同的distiller提供不同的蒸馏模式。目前包含GeneralDistiller, MultiTeacherDistiller, MultiTaskDistiller等
- Configurations and Presets:训练与蒸馏方法的配置,并提供预定义的蒸馏策略以及多种知识蒸馏损失函数
- Utilities:模型参数分析显示等辅助工具
用户需要准备:
- 已训练好的教师模型, 待蒸馏的学生模型
- 训练数据与必要的实验配置, 即可开始蒸馏
在多个典型NLP任务上,TextBrewer都能取得较好的压缩效果。相关实验见蒸馏效果。
2.TextBrewer结构
2.1 安装要求
-
Python >= 3.6
-
PyTorch >= 1.1.0
-
TensorboardX or Tensorboard
-
NumPy
-
tqdm
-
Transformers >= 2.0 (可选, Transformer相关示例需要用到)
-
Apex == 0.1.0 (可选,用于混合精度训练)
-
从PyPI自动下载安装包安装:
pip install textbrewer
- 从源码文件夹安装:
git clone https://github.com/airaria/TextBrewer.git
pip install ./textbrewer
2.2工作流程
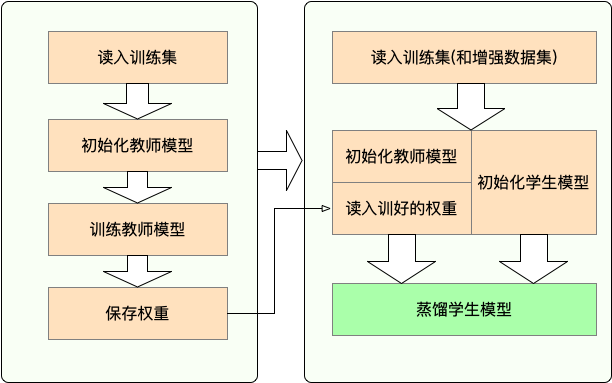
-
Stage 1 : 蒸馏之前的准备工作:
- 训练教师模型
- 定义与初始化学生模型(随机初始化,或载入预训练权重)
- 构造蒸馏用数据集的dataloader,训练学生模型用的optimizer和learning rate scheduler
-
Stage 2 : 使用TextBrewer蒸馏:
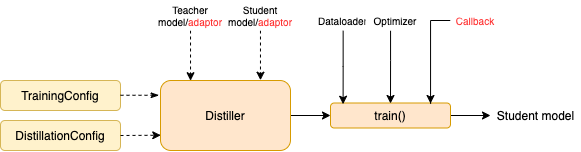
- 构造训练配置(
TrainingConfig)和蒸馏配置(DistillationConfig),初始化distiller - 定义adaptor 和 callback ,分别用于适配模型输入输出和训练过程中的回调
- 调用distiller的train方法开始蒸馏
- 构造训练配置(
2.3 以蒸馏BERT-base到3层BERT为例展示TextBrewer用法
在开始蒸馏之前准备:
- 训练好的教师模型
teacher_model(BERT-base),待训练学生模型student_model(3-layer BERT) - 数据集
dataloader,优化器optimizer,学习率调节器类或者构造函数scheduler_class和构造用的参数字典scheduler_args
使用TextBrewer蒸馏:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig, DistillationConfig#展示模型参数量的统计
print("\nteacher_model's parametrers:")
result, _ = textbrewer.utils.display_parameters(teacher_model,max_level=3)
print (result)print("student_model's parametrers:")
result, _ = textbrewer.utils.display_parameters(student_model,max_level=3)
print (result)#定义adaptor用于解释模型的输出
def simple_adaptor(batch, model_outputs):# model输出的第二、三个元素分别是logits和hidden statesreturn {'logits': model_outputs[1], 'hidden': model_outputs[2]}#蒸馏与训练配置
# 匹配教师和学生的embedding层;同时匹配教师的第8层和学生的第2层
distill_config = DistillationConfig(intermediate_matches=[ {'layer_T':0, 'layer_S':0, 'feature':'hidden', 'loss': 'hidden_mse','weight' : 1},{'layer_T':8, 'layer_S':2, 'feature':'hidden', 'loss': 'hidden_mse','weight' : 1}])
train_config = TrainingConfig()#初始化distiller
distiller = GeneralDistiller(train_config=train_config, distill_config = distill_config,model_T = teacher_model, model_S = student_model, adaptor_T = simple_adaptor, adaptor_S = simple_adaptor)#开始蒸馏
with distiller:distiller.train(optimizer, dataloader, num_epochs=1, scheduler_class=scheduler_class, scheduler_args = scheduler_args, callback=None)
2.4蒸馏任务示例
-
Transformers 4示例
- examples/notebook_examples/sst2.ipynb (英文): SST-2文本分类任务上的BERT模型训练与蒸馏。
- examples/notebook_examples/msra_ner.ipynb (中文): MSRA NER中文命名实体识别任务上的BERT模型训练与蒸馏。
- examples/notebook_examples/sqaudv1.1.ipynb (英文): SQuAD 1.1英文阅读理解任务上的BERT模型训练与蒸馏。
-
examples/random_token_example: 一个可运行的简单示例,在文本分类任务上以随机文本为输入,演示TextBrewer用法。
-
examples/cmrc2018_example (中文): CMRC 2018上的中文阅读理解任务蒸馏,并使用DRCD数据集做数据增强。
-
examples/mnli_example (英文): MNLI任务上的英文句对分类任务蒸馏,并展示如何使用多教师蒸馏。
-
examples/conll2003_example (英文): CoNLL-2003英文实体识别任务上的序列标注任务蒸馏。
-
examples/msra_ner_example (中文): MSRA NER(中文命名实体识别)任务上,使用分布式数据并行训练的Chinese-ELECTRA-base模型蒸馏。
2.4.1蒸馏效果
我们在多个中英文文本分类、阅读理解、序列标注数据集上进行了蒸馏实验。实验的配置和效果如下。
-
模型
-
对于英文任务,教师模型为BERT-base-cased
-
对于中文任务,教师模型为HFL发布的RoBERTa-wwm-ext 与 Electra-base
我们测试了不同的学生模型,为了与已有公开结果相比较,除了BiGRU都是和BERT一样的多层Transformer结构。模型的参数如下表所示。需要注意的是,参数量的统计包括了embedding层,但不包括最终适配各个任务的输出层。
- 英文模型
| Model | #Layers | Hidden size | Feed-forward size | #Params | Relative size |
|---|---|---|---|---|---|
| BERT-base-cased (教师) | 12 | 768 | 3072 | 108M | 100% |
| T6 (学生) | 6 | 768 | 3072 | 65M | 60% |
| T3 (学生) | 3 | 768 | 3072 | 44M | 41% |
| T3-small (学生) | 3 | 384 | 1536 | 17M | 16% |
| T4-Tiny (学生) | 4 | 312 | 1200 | 14M | 13% |
| T12-nano (学生) | 12 | 256 | 1024 | 17M | 16% |
| BiGRU (学生) | - | 768 | - | 31M | 29% |
- 中文模型
| Model | #Layers | Hidden size | Feed-forward size | #Params | Relative size |
|---|---|---|---|---|---|
| RoBERTa-wwm-ext (教师) | 12 | 768 | 3072 | 102M | 100% |
| Electra-base (教师) | 12 | 768 | 3072 | 102M | 100% |
| T3 (学生) | 3 | 768 | 3072 | 38M | 37% |
| T3-small (学生) | 3 | 384 | 1536 | 14M | 14% |
| T4-Tiny (学生) | 4 | 312 | 1200 | 11M | 11% |
| Electra-small (学生) | 12 | 256 | 1024 | 12M | 12% |
- T6的结构与DistilBERT[1], BERT6-PKD[2], BERT-of-Theseus[3] 相同。
- T4-tiny的结构与 TinyBERT[4] 相同。
- T3的结构与BERT3-PKD[2] 相同。
2.4.2 蒸馏配置
distill_config = DistillationConfig(temperature = 8, intermediate_matches = matches)
#其他参数为默认值
不同的模型用的matches我们采用了以下配置:
| Model | matches |
|---|---|
| BiGRU | None |
| T6 | L6_hidden_mse + L6_hidden_smmd |
| T3 | L3_hidden_mse + L3_hidden_smmd |
| T3-small | L3n_hidden_mse + L3_hidden_smmd |
| T4-Tiny | L4t_hidden_mse + L4_hidden_smmd |
| T12-nano | small_hidden_mse + small_hidden_smmd |
| Electra-small | small_hidden_mse + small_hidden_smmd |
各种matches的定义在examples/matches/matches.py中。均使用GeneralDistiller进行蒸馏。
2.4.3训练配置
蒸馏用的学习率 lr=1e-4(除非特殊说明)。训练30~60轮。
2.4.4英文实验结果
在英文实验中,我们使用了如下三个典型数据集。
| Dataset | Task type | Metrics | #Train | #Dev | Note |
|---|---|---|---|---|---|
| MNLI | 文本分类 | m/mm Acc | 393K | 20K | 句对三分类任务 |
| SQuAD 1.1 | 阅读理解 | EM/F1 | 88K | 11K | 篇章片段抽取型阅读理解 |
| CoNLL-2003 | 序列标注 | F1 | 23K | 6K | 命名实体识别任务 |
我们在下面两表中列出了DistilBERT, BERT-PKD, BERT-of-Theseus, TinyBERT 等公开的蒸馏结果,并与我们的结果做对比。
Public results:
| Model (public) | MNLI | SQuAD | CoNLL-2003 |
|---|---|---|---|
| DistilBERT (T6) | 81.6 / 81.1 | 78.1 / 86.2 | - |
| BERT6-PKD (T6) | 81.5 / 81.0 | 77.1 / 85.3 | - |
| BERT-of-Theseus (T6) | 82.4/ 82.1 | - | - |
| BERT3-PKD (T3) | 76.7 / 76.3 | - | - |
| TinyBERT (T4-tiny) | 82.8 / 82.9 | 72.7 / 82.1 | - |
Our results:
| Model (ours) | MNLI | SQuAD | CoNLL-2003 |
|---|---|---|---|
| BERT-base-cased (教师) | 83.7 / 84.0 | 81.5 / 88.6 | 91.1 |
| BiGRU | - | - | 85.3 |
| T6 | 83.5 / 84.0 | 80.8 / 88.1 | 90.7 |
| T3 | 81.8 / 82.7 | 76.4 / 84.9 | 87.5 |
| T3-small | 81.3 / 81.7 | 72.3 / 81.4 | 78.6 |
| T4-tiny | 82.0 / 82.6 | 75.2 / 84.0 | 89.1 |
| T12-nano | 83.2 / 83.9 | 79.0 / 86.6 | 89.6 |
说明:
- 公开模型的名称后括号内是其等价的模型结构
- 蒸馏到T4-tiny的实验中,SQuAD任务上使用了NewsQA作为增强数据;CoNLL-2003上使用了HotpotQA的篇章作为增强数据
- 蒸馏到T12-nano的实验中,CoNLL-2003上使用了HotpotQA的篇章作为增强数据
2.4.5中文实验结果
在中文实验中,我们使用了如下典型数据集。
| Dataset | Task type | Metrics | #Train | #Dev | Note |
|---|---|---|---|---|---|
| XNLI | 文本分类 | Acc | 393K | 2.5K | MNLI的中文翻译版本,3分类任务 |
| LCQMC | 文本分类 | Acc | 239K | 8.8K | 句对二分类任务,判断两个句子的语义是否相同 |
| CMRC 2018 | 阅读理解 | EM/F1 | 10K | 3.4K | 篇章片段抽取型阅读理解 |
| DRCD | 阅读理解 | EM/F1 | 27K | 3.5K | 繁体中文篇章片段抽取型阅读理解 |
| MSRA NER | 序列标注 | F1 | 45K | 3.4K (测试集) | 中文命名实体识别 |
实验结果如下表所示。
| Model | XNLI | LCQMC | CMRC 2018 | DRCD |
|---|---|---|---|---|
| RoBERTa-wwm-ext (教师) | 79.9 | 89.4 | 68.8 / 86.4 | 86.5 / 92.5 |
| T3 | 78.4 | 89.0 | 66.4 / 84.2 | 78.2 / 86.4 |
| T3-small | 76.0 | 88.1 | 58.0 / 79.3 | 75.8 / 84.8 |
| T4-tiny | 76.2 | 88.4 | 61.8 / 81.8 | 77.3 / 86.1 |
| Model | XNLI | LCQMC | CMRC 2018 | DRCD | MSRA NER |
|---|---|---|---|---|---|
| Electra-base (教师) | 77.8 | 89.8 | 65.6 / 84.7 | 86.9 / 92.3 | 95.14 |
| Electra-small | 77.7 | 89.3 | 66.5 / 84.9 | 85.5 / 91.3 | 93.48 |
说明:
- 以RoBERTa-wwm-ext为教师模型蒸馏CMRC 2018和DRCD时,不采用学习率衰减
- CMRC 2018和DRCD两个任务上蒸馏时他们互作为增强数据
- Electra-base的教师模型训练设置参考自Chinese-ELECTRA
- Electra-small学生模型采用预训练权重初始化
3.核心概念
3.1Configurations
TrainingConfig和DistillationConfig:训练和蒸馏相关的配置。
3.2Distillers
Distiller负责执行实际的蒸馏过程。目前实现了以下的distillers:
BasicDistiller: 提供单模型单任务蒸馏方式。可用作测试或简单实验。GeneralDistiller(常用): 提供单模型单任务蒸馏方式,并且支持中间层特征匹配,一般情况下推荐使用。MultiTeacherDistiller: 多教师蒸馏。将多个(同任务)教师模型蒸馏到一个学生模型上。暂不支持中间层特征匹配。MultiTaskDistiller:多任务蒸馏。将多个(不同任务)单任务教师模型蒸馏到一个多任务学生模型。BasicTrainer:用于单个模型的有监督训练,而非蒸馏。可用于训练教师模型。
3.3用户定义函数
蒸馏实验中,有两个组件需要由用户提供,分别是callback 和 adaptor :
3.3.1Callback
回调函数。在每个checkpoint,保存模型后会被distiller调用,并传入当前模型。可以借由回调函数在每个checkpoint评测模型效果。
3.3.2Adaptor
将模型的输入和输出转换为指定的格式,向distiller解释模型的输入和输出,以便distiller根据不同的策略进行不同的计算。在每个训练步,batch和模型的输出model_outputs会作为参数传递给adaptor,adaptor负责重新组织这些数据,返回一个字典。
更多细节可参见完整文档中的说明。
4.FAQ
Q: 学生模型该如何初始化?
A: 知识蒸馏本质上是“老师教学生”的过程。在初始化学生模型时,可以采用随机初始化的形式(即完全不包含任何先验知识),也可以载入已训练好的模型权重。例如,从BERT-base模型蒸馏到3层BERT时,可以预先载入RBT3模型权重(中文任务)或BERT的前三层权重(英文任务),然后进一步进行蒸馏,避免了蒸馏过程的“冷启动”问题。我们建议用户在使用时尽量采用已预训练过的学生模型,以充分利用大规模数据预训练所带来的优势。
Q: 如何设置蒸馏的训练参数以达到一个较好的效果?
A: 知识蒸馏的比有标签数据上的训练需要更多的训练轮数与更大的学习率。比如,BERT-base上训练SQuAD一般以lr=3e-5训练3轮左右即可达到较好的效果;而蒸馏时需要以lr=1e-4训练30~50轮。当然具体到各个任务上肯定还有区别,我们的建议仅是基于我们的经验得出的,仅供参考。
Q: 我的教师模型和学生模型的输入不同(比如词表不同导致input_ids不兼容),该如何进行蒸馏?
A: 需要分别为教师模型和学生模型提供不同的batch,参见完整文档中的 Feed Different batches to Student and Teacher, Feed Cached Values 章节。
Q: 我缓存了教师模型的输出,它们可以用于加速蒸馏吗?
A: 可以, 参见完整文档中的 Feed Different batches to Student and Teacher, Feed Cached Values 章节。
相关文章:
TextBrewer:融合并改进了NLP和CV中的多种知识蒸馏技术、提供便捷快速的知识蒸馏框架、提升模型的推理速度,减少内存占用
TextBrewer:融合并改进了NLP和CV中的多种知识蒸馏技术、提供便捷快速的知识蒸馏框架、提升模型的推理速度,减少内存占用 TextBrewer是一个基于PyTorch的、为实现NLP中的知识蒸馏任务而设计的工具包, 融合并改进了NLP和CV中的多种知识蒸馏技术࿰…...
乍得ECTN(BESC)申请流程
根据TCHAD/CHAD乍得法令,自2013年4月1日起,所有运至乍得的货物都必须申请ECTN(BESC)电子货物跟踪单。如果没有申请,将被视为触犯乍得的条例,并在目的地受到严厉惩罚。ECTN是英语ELECTRONIC CARGO TRACKING NOTE的简称;…...

【100天精通python】Day28:文件与IO操作_JSON文件处理
目录 专栏导读 1. JSON数据格式简介 1.1 示例JSON数据 1.2 JSON文件的特点 2 json模块的常用操作 2.1 读写JSON文件的示例 2.2 解析JSON字符串 2.3 修改JSON数据 2.4 查询和操作嵌套数据 2.5 处理包含特殊字符的JSON文件 2.6 处理日期和时间 2.7 处理大型JSON文…...
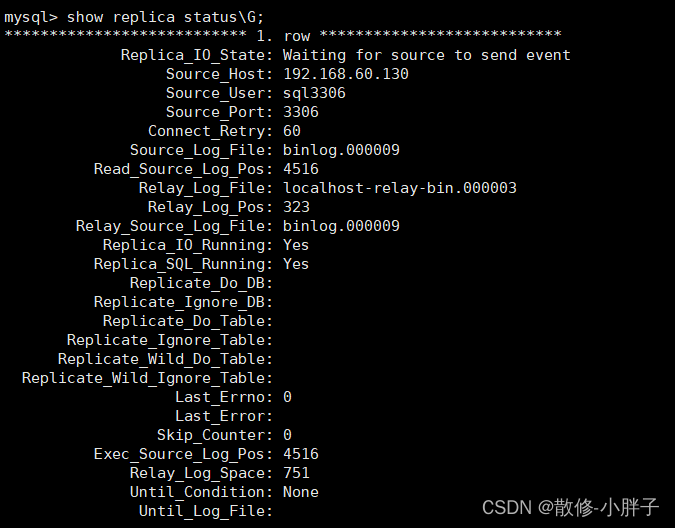
配置两台数据库为主从数据库模式
一、主库配置 1、修改配置文件 /etc/my3306.cnf #mysql服务ID,保证整个集群环境中唯一,默认为1server-id1#是否只读,1代表只读,0代表读写read-only0#忽略的数据,指不需要同步的数据库#binlog-ignore-dbmysql#指定同步…...

linux允许root远程ssh登录
修改文件/etc/ssh/sshd_config # cat /etc/ssh/sshd_config ... #LoginGraceTime 2m #PermitRootLogin prohibit-password #StrictModes yes #MaxAuthTries 6 #MaxSessions 10 ...将 #PermitRootLogin prohibit-password标注为: PermitRootLogin yes样例…...
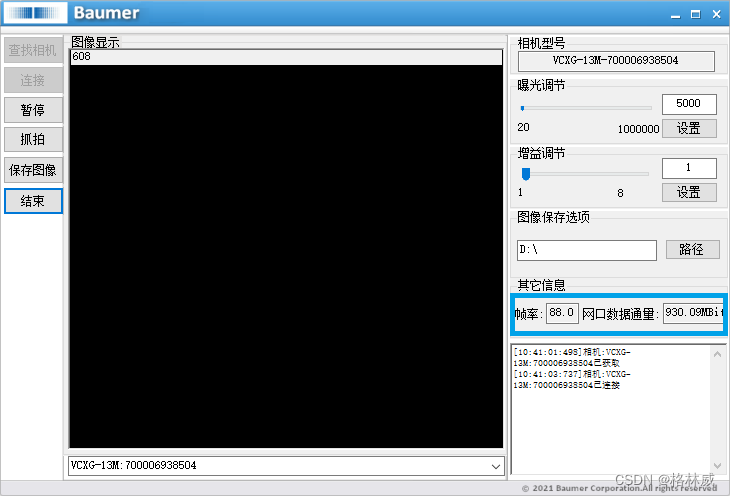
Baumer工业相机堡盟工业相机如何通过BGAPISDK获取相机接口数据吞吐量(C++)
Baumer工业相机堡盟工业相机如何通过BGAPISDK里函数来获取相机当前数据吞吐量(C) Baumer工业相机Baumer工业相机的数据吞吐量的技术背景CameraExplorer如何查看相机吞吐量信息在BGAPI SDK里通过函数获取相机接口吞吐量 Baumer工业相机通过BGAPI SDK获取数…...
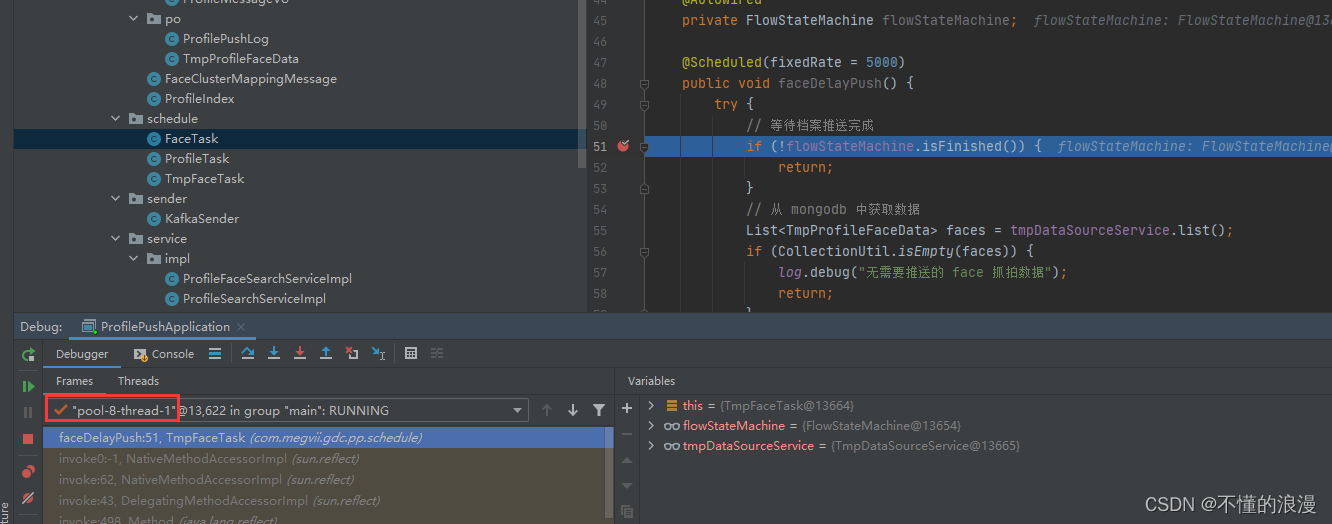
Spring @Scheduled单线程单实例的坑
文章目录 前言背景验证解决方案 前言 在 Java Spring 项目中经常会用 Scheduled 来实现一些定时任务的场景,有必要了解一些它使用时的问题和内部实现机制。本文是偶然间发现的一个问题,刷新了我的认知,分享给大家。 其他相关文章࿱…...
单链表的增删改查)
7-数据结构-(带头节点)单链表的增删改查
问题: 单链表带头结点的创建以及输出,以及带与不带头节点的区别 思路: 单链表,逻辑上是线性结构,由许多单链表结点,串成一串。其单链表结构体中,数据项由data数据域和结点指针域。带头节点是为…...
每天一道leetcode:剑指 Offer 53 - II. 0~n-1中缺失的数字(适合初学者二分查找)
今日份题目: 一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0~n-1之内。在范围0~n-1内的n个数字中有且只有一个数字不在该数组中,请找出这个数字。 示例1 输入: [0,1,3] 输出: 2 示例2 …...

玩机搞机---安卓新机型payload.bin刷写救砖 无需专用线刷包
目前的新机型官方卡刷包解包后都是payload.bin分区格式的卡刷固件。而有个别一些机型没有线刷包,当这些机型出现系统问题的时候有以下几种方法参考救砖。遇到类似故障的朋友可以借鉴参考下. 其中的不足和相关的资源可以参考这两个博文。任何教程的目的只是拓展你的…...
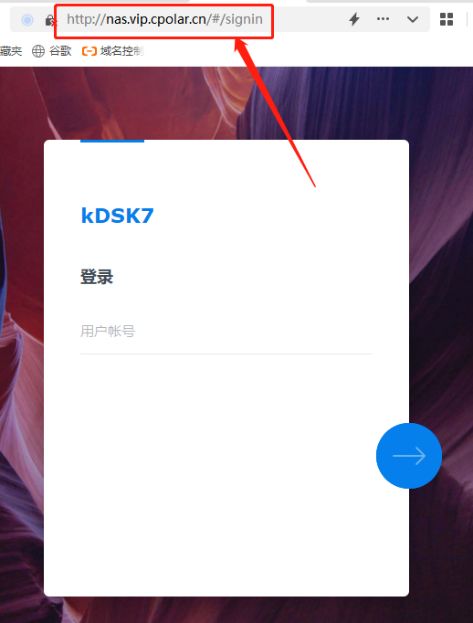
配置固定二级子域名远程访问内网群晖NAS 7.X版 【内网穿透】——“cpolar内网穿透”
配置固定二级子域名远程访问内网群晖NAS 7.X版 【内网穿透】 文章目录 配置固定二级子域名远程访问内网群晖NAS 7.X版 【内网穿透】前言1. 创建一条固定数据隧道2. 找到“保留二级子域名”栏位3. 重新编辑之前建立的临时数据隧道4. 进入“在线隧道列表”页面5. 在其他浏览器访问…...

【枚举】CF1706 C
有人一道1400写了一个小时 Problem - C - Codeforces 题意: 思路: 首先先去观察样例: 很显然,对于n是奇数的情况,只有一种情况,直接操作偶数位就好了 主要是没搞清楚n是偶数的情况 其实有个小技巧&…...
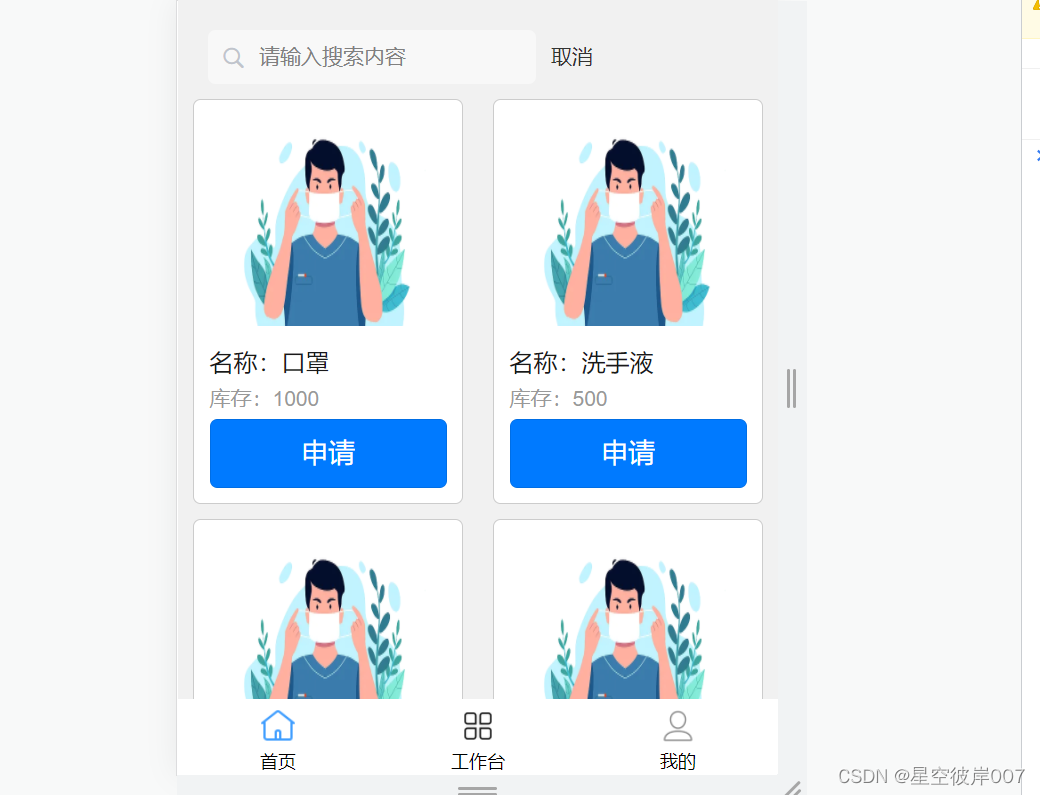
uniapp-疫情应急管理系统学生端
1 疫情资讯展示 <template><view class"container"><uni-section title"自定义卡片内容" type"line"><uni-card title"基础卡片" class"card-box" v-for"(item,index) in epidemicNewsList"…...
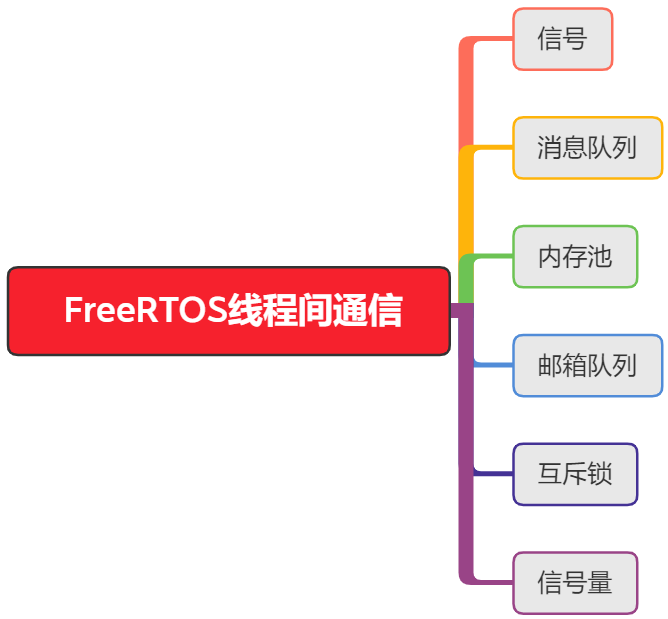
FreeRTOS的线程间通信
一、分类 FreeRTOS的线程间通信分为这几大类 由于我还在学习中,目前显从信号开始记录学习 二、逐块讲解 1、信号(osSignalWait osSignalSet) FreeRTOS从V8.2.0版本开始提供任务通知这个功能,每个任务多有一个32位的通知值&am…...
Linux内存管理工作原理:
Linux使用虚拟内存和内存映射来管理内存。每个进程都有独立的虚拟地址空间,通过将虚拟地址映射到物理内存,实现对内存的管理和访问。 虚拟地址空间划分:32位系统中,内核空间占1GB,用户空间占3GB;64位系统中…...

【并发编程】ShenyuAdmin里面数据同步用到的无锁环形队列LMAX Disruptor并发框架
并发,数据同步往往是业务开发中比较重要的部分。 shenyu网关数据同步设计方案图 shenyu官网给出的同步设计方案图如下: 基于事件异步并发框架com.lmax.disruptor 下载下示例代码,跑起来发现,在shenyuAdmin模块里面用到了com.lma…...
Nginx(2)
目录 1.安装Nginx1.yum安装2.编译安装3.Nginx命令 2.配置文件详解 1.安装Nginx 1.yum安装 [rootdocker ~]# yum -y install nginx通过 rpm -ql nginx 查看安装信息 2.编译安装 2.1安装所需要的依赖 yum install -y gcc gcc-c make libtool wget pcre pcre-devel zlib zlib-…...

二维数组的鞍点
描述 给定一个二维数组,找出其中的鞍点。若存在鞍点,则输出其位置;否则输出“NO”。 鞍点的定义:在一个矩阵的行和列中,某个元素是所在行的最大值,而同列中又是最小值。 输入 输入包含多行,…...
)
go 内置函数copy()
go内置函数copy go 内置函数copy()函数说明:代码例子1:代码例子2:代码例子3: go 内置函数copy() 函数说明: 当我们在Go语言中需要将一个切片的内容复制到另一个切片时,可以使用内置的copy()函数。copy()函…...

Spring简述
Sping是什么Spring主要模块IOCDI依赖注入的三种方式 AOP术语 Sping是什么 Spring是一个轻量级的开源框架,主要作用是为了简化开发,它以IOC(控制反转)和AOP(面向切面编程)为内核 Spring主要模块 我们一般…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

如何在macOS上免费解锁QQ音乐加密文件:完整指南
如何在macOS上免费解锁QQ音乐加密文件:完整指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结果…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参
Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参 【免费下载链接】gz-sim Open source robotics simulator. The latest version of Gazebo. 项目地址: https://gitcode.com/gh_mirrors/gz/gz-sim Gazebo Sim是一款功能强大的开源机器人模拟器ÿ…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

HoRain云--CLAUDE.md 使用指南
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...