C语言标准定义的32个关键字

欢迎关注博主 Mindtechnist 或加入【智能科技社区】一起学习和分享Linux、C、C++、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和技术。
C语言标准定义的32个关键字
- 1. 数据类型关键字(12个)
- (1) 声明和定义的区别
- (2) 数据类型关键字
- 2. 控制语句关键字(12个)
- 3. 存储类关键字(5个)
- 4. 其他关键字(3个)
专栏:《精通C语言》
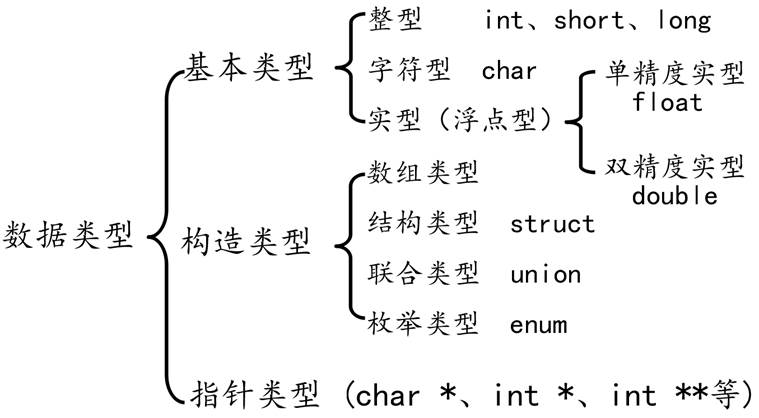
1. 数据类型关键字(12个)
C语言中的数据类型主要有下面几种。实际上,数据类型可以理解为固定大小内存块的别名,给变量指定类型就是告诉编译器给该变量分配多大的内存空间,而变量相当于是内存块的门牌号。
(1) 声明和定义的区别
定义可以看作是声明的一个特例,并非所有的声明都是定义。可以通过是否分配内存来区分定义和声明,定义会建立存储空间,而声名不会建立存储空间。
int function()
{//定义int val; //定义一个变量val,此时会给val分配内存,由数据类型int决定分配多大内存,int为4字节。val = 10; //可以为val赋值。//声明extern int val_2; //声明变量val_2,不会建立内存。//val_2 = 10; //error: 声明不会建立内存,没有内存空间所以无法赋值。return 0;
}
- 定义:定义是指创建一个对象并为这个对象分配一块内存,同时将变量名和这个内存块进行绑定。但是,同一个变量在同一作用域只能定义一次,如果多次定义的话,编译器会提示重定义错误。
- 声明:
- 告诉编译器,某个名称已经被预定了,其他对象/内存块不能再使用这个名称。
- 告诉编译器,某个名称已经绑定好内存块了,该对象是在其他位置定义的,这里用到本名称时不要报错。
(2) 数据类型关键字
char:声明字符型变量。
char类型用于存储一个单一字符,即1字节存储单元。在给char类型变量赋值时需要把值用英文半角单引号’'引起来,存储时并非真正把该字符放到存储空间,而是把该字符对应的ASCII码存放到存储单元中。(也可以把char类型看作是1字节整形)。
ASCII对照表如下
| ASCII值 | 控制字符 | ASCII值 | 字符 | ASCII值 | 字符 | ASCII值 | 字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | " | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | / | 124 | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ` |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
在上面的ASCII码表中,ASCII值0-31表示非打印控制字符,用于控制打印机等外围设备;32-126为打印字符,这些字符在键盘上都可以找到;127表示del命令。
转义字符
| 转义字符 | 含义 | ASCII码值(十进制) |
|---|---|---|
| \a | 警报 | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) (跳到下一个TAB位置) | 009 |
| \v | 垂直制表(VT) | 011 |
| \ | 代表一个反斜线字符"" | 092 |
| ’ | 代表一个单引号(撇号)字符 | 039 |
| " | 代表一个双引号字符 | 034 |
| ? | 代表一个问号 | 063 |
| \0 | 数字0 | 000 |
| \ddd | 8进制转义字符,d范围0~7 | 3位8进制 |
| \xhh | 16进制转义字符,h范围09,af,A~F | 3位16进制 |
int:声明整型变量。
在C语言标准中并没有明确规定整型数据的长度,整型数据在内存中所占的字节数与操作系统有关系。(一般为4字节)
| 打印格式 | 含义 |
|---|---|
| %d | 输出一个有符号的10进制int类型 |
| %o | 输出8进制的int类型 |
| %x | 输出16进制的int类型,字母以小写输出 |
| %X | 输出16进制的int类型,字母以大写写输出 |
| %u | 输出一个10进制的无符号数 |
short:声明短整型变量。
长度一般不长于int型数据。(一般为2字节)
long:声明长整型变量。
长度一般不短于int型数据。(Windows为4字节;Linux为4字节(32位),8字节(64位)。)
| 打印格式 | 含义 |
|---|---|
| %hd | 输出short类型 |
| %d | 输出int类型 |
| %l | 输出long类型 |
| %ll | 输出long long类型 |
| %hu | 输出unsigned short类型 |
| %u | 输出unsigned int类型 |
| %lu | 输出unsigned long类型 |
| %llu | 输出unsigned long long类型 |
float:声明单精度浮点型变量。
浮点型变量也叫做实型变量,用于存储小数数值。float单精度浮点型一般占用4字节存储空间,7位有效数字。
double:声明双精度浮点型变量。
double双精度浮点型精度高于float单精度浮点型,占用8字节存储空间,15-16位有效数字。
浮点型变量存储的是小数,并且浮点型变量的存储单元是有限的,这就导致一个小数有效位以外的数字将被舍去,这样便会出现一些误差。尤其是float单精度浮点型,有时候将一个小数赋值给一个float型变量,然后打印该浮点型变量都会出现和原小数不一致这样的情况。一般使用double双精度可以提升精度,并且在C语言中,一个小数后面不加f则被认为是双精度double类型,只有小数后面加f才表示float类型,比如3.14f。
signed:声明有符号类型变量。
缺省时,编译器默认为signed有符号类型。在计算机中,所有的数据都是以01的二进制形式来存储的,对于有符号数来说如何表示一个数值的正负是一个问题,因此便有了原码、反码和补码。
- 原码:二进制数据的最高位用来作为符号位,1表示负数,0表示正数,剩余位来表示这个数据的数值大小(绝对值),也就是说,负数的原码是在其绝对值原码的基础上将最高位变成0。原码的表示简单易懂,正负数区分方便且易于转换,但是在实际用于计算时却不太方便,当两个正数做减法运算,或者两个异号的数相加时,必须先比较两个数的绝对值大小才能进行减法运算,以便于决定最终结果是正号还是负号。所以,原码表示数据时不便于做加减运算。
- 反码:正数的反码与原码相同;负数的反码是在负数的原码基础上,符号位不变,其它位全部取反。反码的存在一般是为了方便计算补码。
- 补码:对正数来说,原码、反码、补码是完全一致的;对负数来说,补码是在其反码的基础上将整个数加1。在计算机系统中,所有的数值一律用补码的形式来存储。补码的存在主要有这几种意义:
- 统一0的编码。不管是用原码还是反码来表示0,都会有两种表示方式,即正0和负0,但是我们知道,0不区分正负。这就导致同一个数值0出现两种表示方式,而使用补码表示时,对于正0,原码为00000000,反码为00000000,补码为00000000;对于负0,原码为10000000,反码为11111111,补码为11111111+1=00000000,其中最高位(第九位)数字1被舍弃。这样,正0和负0的补码就一样了。
- 便于运算。使用补码进行运算时可以将减法转化为加法,对于任何数的加减运算,都直接使用补码进行加法运算即可,并且可以将符号位和其他位统一处理,当两个用补码表示的数相加时,如果最高位(符号位)有进位,则进位直接舍弃。
unsigned:声明无符号类型变量。
| 数据类型 | 占用空间 | 取值范围 |
|---|---|---|
| short | 2字节 | -32768 到 32767 (-2^15 ~ 2^15-1) |
| int | 4字节 | -2147483648 到 2147483647 (-2^31 ~ 2^31-1) |
| long | 4字节 | -2147483648 到 2147483647 (-2^31 ~ 2^31-1) |
| unsigned short | 2字节 | 0 到 65535 (0 ~ 2^16-1) |
| unsigned int | 4字节 | 0 到 4294967295 (0 ~ 2^32-1) |
| unsigned long | 4字节 | 0 到 4294967295 (0 ~ 2^32-1) |
struct:声明结构体变量。
数组是相同类型数据的集合,而结构体可以把不同的数据组合成一个整体。通过结构体,我们可以把大量的不同类型数据,甚至是函数和其他复合类型数据打包为一个整体。在使用struct关键字时,应区分开结构体类型和结构体变量的区别,声明结构体类型并不会分配内存,只有在定义结构体类型的时候才会分配内存。通常struct关键字会和typedef关键字一块使用,通过别名的方式可以在定义结构体变量时不需要再写struct关键字。
struct st
{int a;char b;
}; //声明结构体类型
struct st s_val = {1, 'a'}; //定义结构体变量,分配内存//定义结构体变量时不能省略struct关键字typedef struct st
{int a;char b;
}_st; //给结构体类型取别名为_st
_st val = {1, 'a'}; //可以不写struct
结构体变量所占的存储空间大小是所有结构体成员所占存储空间大小的总和,并且需要考虑内存对齐方式。而且,空结构体(没有任何成员)也是占存储空间的,空结构体占1字节存储空间。
在结构体中可以包含一种称为柔性数组的成员,柔性数组是一个未知大小的数组,它必须是结构体的最后一个成员,并且柔性数组成员的前面必须有一个其他成员。
struct st
{int val;int arr[0]; //int arr[];
};
这个0长度的数组成员arr是不占存储空间的,这个结构体的大小为4字节。有了这个0长度数组我们便可以方便的扩展这个结构体的大小了
struct st *p_st = (struct st *)malloc(sizeof(struct st) + 10 * sizeof(int));
如上,我们使用包含0长度数组的结构体类型定义一个结构体指针,并通过malloc在堆上为其分配一块内存,这块内存的大小为44字节,而结构体类型大小只有4字节,但是我们却可以像访问普通数组一样通过p_st[i]来访问这块内存。也就是说,柔性数组并不是结构体类型的成员,但是通过结构体成员却可以访问我们自定义的柔性数组存储空间。
最后,在C++中,struct结构体和class类的区别,struct成员默认是public属性,而class的成员默认是private属性。
同样,在C语言中也可以实现C++面向对象的效果,使用struct结构可以实现封装,而结构体做结构体成员又可以实现C++中的继承,并且,函数指针做结构体成员可是模仿C++类中的方法。
union:声明联合数据类型。
联合union是一个能在同一个存储空间存储不同类型数据的类型,也就是说,union的所有成员共享同一块存储空间,同一存储空间段可以用来存放几种不同类型的成员,但每一时刻只有一种起作用。联合体所占的存储空间长度为占用存储空间最大的成员的长度,所以也叫做共用体。共用体变量中起作用的成员是最后一次存放的成员,在存入一个新的成员后原有的成员的值会被覆盖。并且,共用体变量的地址和它的各成员的地址都是同一地址。
一个union变量只分配一个足够大的存储空间能够存储最大长度的成员,而不会给每一个成员都分配内存,这是union与struct最大的区别。union主要用来达到节省空间的目的,和struct一样,在C++中,union的成员默认属性为public。
看下面的例子
typedef union
{int data;char buf[2];
}u_t;int main()
{u_t* p, u;memset(&u, 0, sizeof(u));p = &u;p->buf[0] = 0x12;p->buf[1] = 0x34;printf("%x\n", p->data);return 0;
}
对union成员的访问也需要考虑大端存储模式和小端存储模式。
enum:声明枚举类型。
通过enum枚举类型可以定义枚举变量,该枚举变量的值只能是枚举类型中列举出来的那些值。
enum 枚举名
{枚举值表
};
枚举值表中的所有可用值是枚举变量可以使用的值,也成为枚举元素。枚举值是常量,在程序中枚举值不能作为左值(不能给枚举值使用赋值语句赋值)。另外,枚举元素本身由系统定义了一个表示序号的数值从0开始顺序定义为0,1,2 …依次递增,我们也可以显示的给枚举元素赋值。
enum day
{mom = 1,tue, //2wed, //3fri = 5,sat, //6sun //7
};
我们知道使用宏定义#define也可以定义常量,但是宏定义常量和枚举常量是有区别的,#define 宏常量是在预编译阶段进行简单替换,而枚举常量则是在编译的时候确定其值。
void:声明空类型指针(void类型指针可以接受任何类型指针的赋值,无需类型转换),声明函数无返回值或无参数等。
void主要的用途是限制函数的返回值或者函数参数。在C语言中,如果一个函数不加返回值类型限定,那么编译器会默认该函数返回整型值,所以,当一个函数没有返回值的时候,一定要声明为void类型。当函数没有参数时,也应该声明为void。实际上,在C++中函数参数为void表示该函数不接受任何参数,如果调用该函数时添加了参数那么会报错;而C语言中,参数为void的函数可以接受任何类型的参数。为了统一,无论C还是C++,只要函数没有参数,都要显式指明参数为void。
void类型指针可以指向任何类型的内存块,但是使用void类型指针的时候要格外注意。在ANSI标准中,不允许对void类型指针进行加减操作,这是因为指针的步长是由指针的类型决定的。比如
int *p = 0xaa;
p++; //指针类型为int,每次加一移动4字节
这里int类型的指针每次自加一会移动4字节,因为int类型的对象占据的存储空间就是4字节。而void类型的指针在移动时你并不知道它指向的存储空间的大小。但是在GNU标准中是允许对void类型指针进行加减操作的。为了统一,我们可以在对void类型指针进行加减操作时强制类型转换,以此来说明指针移动步长。
void *p;
(int *)p++;
对于函数来说,如果函数的参数可以是任意类型指针,那么可以将函数参数声明为void*类型,比如典型的C语言内存操作函数memset和memcpy函数,内存操作函数所操作的对象是一块内存本身,本就不应该关心这块内存是什么类型,只要我们通过函数参数告诉编译器我们要操作的这块内存的大小就行了,这也是C语言内存操作函数的精髓所在,并且也体现了作为一个内存操作API的统一性。比如
int buf[20];
memset(&buf, 0, 20 * (sizeof(int)));
这句代码的意思是把buf这个数组清0,我们只要把buf这块内存的首地址传给memset函数,并将要清0的这块内存的大小通过参数传入就可以了。
最后,void是一种抽象,可以参考C++中的抽象类来理解。抽象类不能实例化,同样我们也不能去定义一个void类型的变量,因为在定义变量时,编译器要为变量分配内存,而void类型本身就是一种抽象,编译器不知道分配多大内存给这个变量。通常,void类型用于定义一个可以指向任何类型内存块的指针。
2. 控制语句关键字(12个)
if:条件语句。
else:条件语句中的否定分支,在if后使用或作为else if分支。
switch:开关语句。
case:开关语句分支。
case后面的值只能是整型或字符型的常量或者常量表达式。当有较多的case选项时,应该尽量把出现概率更大的case选项放在前面,以提升程序的执行效率。
default:开关语句中的其他分支。
for:循环语句。
do:循环语句中的循环体。
while:循环语句中的条件。
break:跳出循环。
continue:跳出本次循环,进入下一次循环。
goto:无条件跳转。
return:返回语句,可带参数。
return用来终止一个函数,并将return后面的值返回给函数的返回值。在函数内部,当执行到return语句的时候就会终止这个函数,并返回值,return语句后面的程序将不会再被执行。
return返回的值不能是存储在栈上的值(局部变量),因为局部变量在这个函数结束的时候被自动销毁,它的生命周期仅限于这个函数内部,所以不能作为return语句的返回值。
3. 存储类关键字(5个)
auto:声明自动变量,缺省时编译器默认为auto。
默认情况下,缺省时所有变量都是auto的。
extern:声明外部变量。
extern表示外部的,通过extern声明的变量或函数表示该变量或者函数是在外部文件定义的,告诉编译器在本文件中遇到该变量或者函数时,去其他文件中寻找变量或函数的定义。
register:声明寄存器变量。
定义寄存器变量,提高效率。register是建议型的指令,而不是命令型的指令,如果CPU有空闲寄存器,那么register就生效,如果没有空闲寄存器,那么register无效。该关键字请求编译器尽量的将变量存放在CPU内部寄存器中,这样在访问变量时不需要再通过内存寻址的方式访问,而是直接在寄存器中访问,大大提升了访问速度。但是CPU内部寄存器是有限的,所以register关键字只能是尽可能的请求编译器把变量存放在寄存器,而不是一定存放在寄存器。因为register关键字用于请求将数据存放在寄存器,所以使用register修饰符来修饰的变量必须是能被CPU寄存器所接受的类型,即register修饰的变量必须是长度小于或等于整形长度的值。同时,因为register修饰的变量可能会存放在寄存器中(也可能存放在内存中),所以不能对register修饰的变量进行取址操作,即不能通过取址操作符&来获取register修饰变量的地址。
static:声明静态变量。
-
修饰变量
static关键字可以修饰全局变量和局部变量,并且他们都会被存放在内存的静态区。
- 静态全局变量:限定变量的作用域为当前文件,即从变量定义之处开始一直到当前文件末尾,当前文件中该变量定义之前也无法使用(除非加extern声明),其他文件中即便是使用extern声明也无法使用。
- 静态局部变量:定义在函数体内部,并且作用域仅限于当前函数,当前文件该函数体外部无法使用。因为static修饰的静态变量存放在内存的静态区,所以函数运行结束这个静态变量也不会被销毁,函数下次被调用时这个变量的值依然存在,也就是我们说的静态局部变量只能被初始化一次,并且有记忆功能,下次调用函数时可以使用上次函数调用结束时静态局部变量的值。需要注意的是,普通的局部变量存放在栈区,函数调用结束变量就会被析构,也就是说普通局部变量的声明周期为定义该变量的函数体内。而静态局部变量存放在静态区,它的生命周期是整个程序执行期间,也就是说定义该静态局部变量的函数执行完毕,并不会析构静态局部变量,而是在当前程序执行完毕才会析构。
-
修饰函数
使用static关键字修饰函数可以将函数变为静态函数,也成为内部函数,静态函数的作用域为当前文件,在该文件之外无法访问。使用静态函数的好处是可以避免不同文件中函数同名引起的错误,但是会导致该文件之外无法调用的问题。
const:声明只读变量(C和C++区别)。
在C语言中,const定义的并不是真正的常量,而是具有只读属性的变量,其本质还是变量,只不过不可修改(实际上在C语言中是可以通过指针等其他方式间接修改的);而在C++中,const定义的是真正的常量,C++中是通过符号表一一对应的方式实现的。通过下面的例子也可以证明
const int NUM = 10;
char buf[NUM];
上面代码在C语言中编译不通过,但是在C++中编译通过。我们知道,定义数组时要指定数组大小,以便于编译器分配内存。在C语言中编译不通过也就证明了const定义的依然是变量,而不是常量。
编译器通常不会为const只读变量分配存储空间,而是将它们保存在符号表中,这使得它们成为一个编译期间的值,没有读写内存的操作,大大提高了效率。另外需要注意const与宏#define的区别
#define NUM 1 //宏定义一个常量
const int VAL = 2; //还没有将VAL放入内存中
int a = VAL; //此时为VAL分配内存,后面不再分配内存
int b = NUM; //预编译期间进行宏替换,分配内存
int c = VAL; //不会分配内存
int d = NUM; //宏替换,还会分配内存
从汇编的角度来看,const定义的只读变量只是给出了内存地址,而#define给出的是立即数。所以,在程序运行过程中,const定义的只读变量只有一份拷贝(全局只读变量存放在静态区,而不是堆栈),而#define定义的常量在内存中有多份拷贝。#define在预编译的时候进行宏替换,而const只读变量是在编译时确定它的值。另外,#define定义的常量没有类型,而const修饰的只读变量是有类型的。const 修饰的只读变量不能用来作为定义数组的维数,
也不能放在case 关键字后面。
最后,当const修饰指针时,放在不同位置所代表的含义也不同。
const int *p; //const修饰指针指向的内存,//指针本身可变,指针指向的内存不可修改
int const *p; //const修饰指针指向的内存,//指针本身可变,指针指向的内存不可修改int * const p; //const修饰指针本身,//指针指向不可修改,指针指向的内存可以修改const int const *p; //指针本身和指针指向的内存都不可修改
4. 其他关键字(3个)
sizeof:计算一个对象所占的字节数。
sizeof在使用时虽然会加括号,但是他并不是函数,而是一个关键字。实际上,通过sizeof计算一个变量所占的内存大小时可以省略括号,sizeof(val)和sizeof val都可以,但是在计算数据类型的大小时必须加括号sizeof(int),否则的话会和类型扩展混淆,比如unsigned int就是扩展为无符号整型变量。因为sizeof不是函数,所以在使用时不需要包含任何头文件,但是sizeof是有返回值的,范围值类型为size_t,在32位操作系统下是unsigned int类型。
在计算一个字符串变量的大小时要区分sizeof与strlen的区别,strlen是一个函数,用于计算字符串的长度,所以不包含字符串最后的’\n’,而sizeof是计算变量所占内存大小,包括字符串结束符’\n’。
typedef:取别名。
typedef可以为一个数据类型定义一个新的名字,但是不能创建一个新的类型。与#define不同,typedef仅限于为数据类型取别名,而不能为表达式或具体的值取别名。#define发生在预处理阶段,typedef发生在编译阶段。
volatile:防止编译器优化,说明变量在程序执行中可被隐含地改变。
volatile是易变的意思,它修饰的变量表示该变量的值可能被某些因素所修改,比如操作系统、硬件外设或其他线程等等。volatile关键字修饰的变量,编译器不会对改变量进行优化访问。
当我们读取一个普通变量的值时,编译器为了加快访问速度,一般会在缓存中读取该变量的值,而不是直接去寄存器取值。但是,有时候寄存器的值并不是通过程序去修改的,比如嵌入式开发中常用开发板进行开发,很多时候寄存器的值会被芯片的外设所修改。这时候,虽然我们程序中并没有去修改寄存器的值,但是寄存器值却因为外界因素而发生了改变。当我们去访问这种变量的时候,如果不加volatile关键字,编译器默认会在缓存中取值,而此时缓存中的值是一个旧值,变量的真实值已经发生了改变。所以,加volatile关键字就是为了告诉编译器,不要对访问进行优化,每次都应该去变量的地址处去访问变量值,以此来确保每次取到的都是变量的最新值。
下面通过例子说明
int val = 1;
int a = val;
int b = val;
在上面的代码中,变量val没有被用作左值(也就是说在程序中变量val的值没有被显式改变),这时候编译器就会认为变量val的值没有发生过改变,并会对val的访问做优化处理。当给变量a赋值时,编译器取到val的值之后赋给a,并且这个值会被放到缓存中。当给b赋值时,因为编译器认为val的值没有发生改变,所以会直接在缓存中取val的值,而不会去val变量的地址处取值,这样大大提高了访问速度。这么做的前提是,两次访问val的语句之间没有将val当左值的语句(即修改val值的语句)。
如果说将val变量修饰为volatile变量,那就不同了。
volatile int val = 1;
int a = val;
int b = val;
此时,编译器认为val的值是随时可能发生改变的,不管程序中有没有将val当作左值的语句,每次访问val变量都会区val变量的地址处去访问。也就是说,在给a赋值时,编译器将会在val地址处取值,当给b赋值时,编译器依然会去val变量的地址处取值。
一般来说,对寄存器变量、端口数据变量、多线程共享数据变量使用volatile修饰可以保证对变量真实值的稳定访问。


相关文章:
C语言标准定义的32个关键字
欢迎关注博主 Mindtechnist 或加入【智能科技社区】一起学习和分享Linux、C、C、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和技术。 …...

PE半透明屏是怎么制造的?工艺、材料、应用
PE半透明屏是一种新型的屏幕材料,具有半透明的特点。 它由聚乙烯(PE)材料制成,具有良好的透明度和柔韧性。PE半透明屏广泛应用于建筑、广告、展览等领域,具有很高的市场潜力。 PE半透明屏的特点之一是其半透明性。 它…...

linux文本三剑客---grep,sed,awk
目录 grep 什么是grep? grep实例演示 命令参数: 案例演示: sed 概念: 常用选项: 案例演示: awk 概念: awk常用命令选项: awk变量: 内置变量 自定义变量 a…...
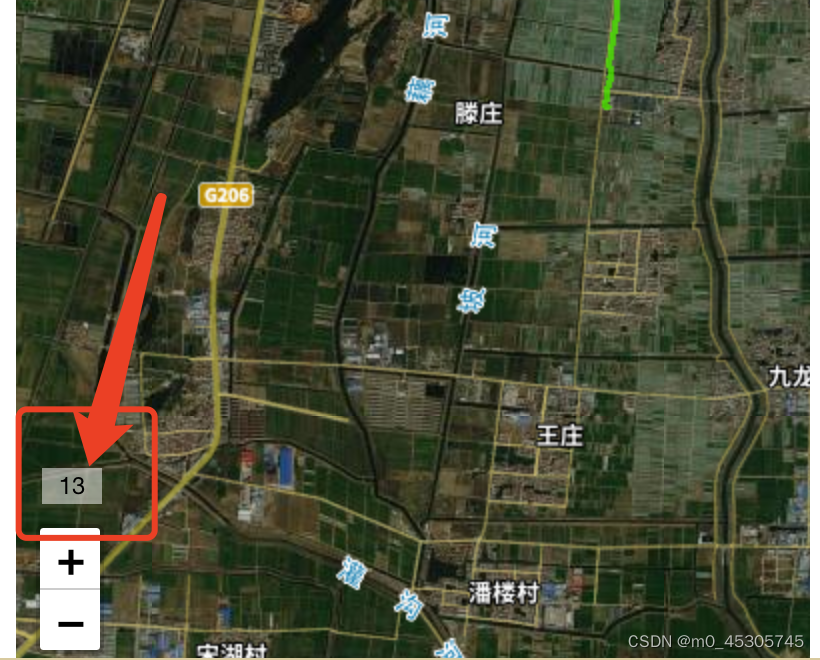
leaflet-uniapp 缩放地图的同时 显示当前缩放层级
记录实现过程: 需求为移动端用户在使用地图时,缩放地图的同时,可以获知地图此时缩放的级别。 效果图如下:此时缩放地图级别为13 map.on() 有对应的诸多行为 查看官网即可,这里根据需要为--zoomstart zoom zoomend 代…...
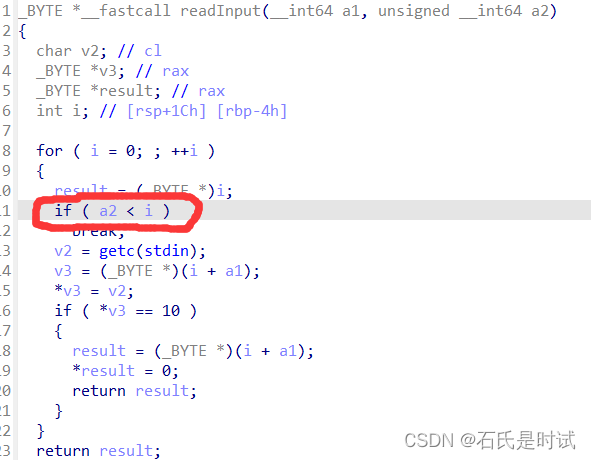
[Securinets CTF Quals 2023] Admin Service,ret2libc,One is enough
只作了3个pwn,第4个附件没下下来,第5个不会 Admin Service 这是个最简单的题,最后来弄出来。原来只是看过关于maps文件的,一直没什么印象。 题目一开始设置seccomp禁用execv等,看来是用ORW,然后建了个mm…...
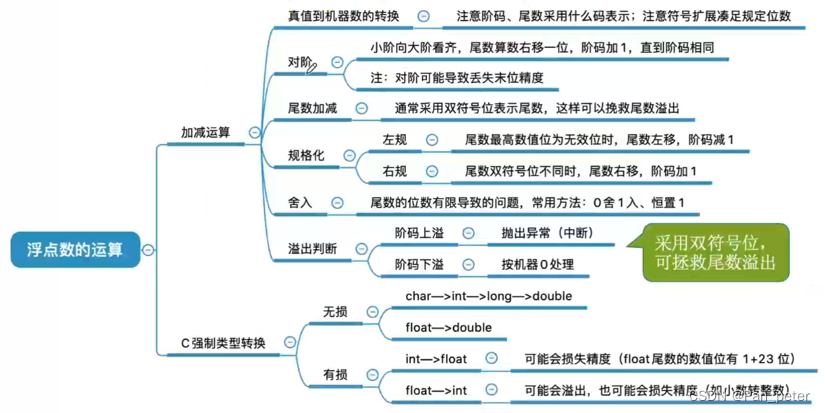
计算机组成原理-笔记-第二章
二、第二章——数据的表示和运算 1、进位制度(二进制、十进制) 2、BCD码(余三码、2421码) 编码方式 功能 好处 弊处 BCD码 将每个十进制数码转换为4位二进制码 精度高,适合直接用于数码管或LED等显示设备 编码…...

mysql大量数据导入记要
需求描述 在工作中经历过两个项目要对数据库中的数据做大量数据的导出,转换和导入的工作。对于不涉及数据格式转换的导出导入工作,一般都是数据的备份。这个工作一般都由DBA搞定。对于要进行格式转换的工作,一般还是要由程序员参与。除非DBA…...
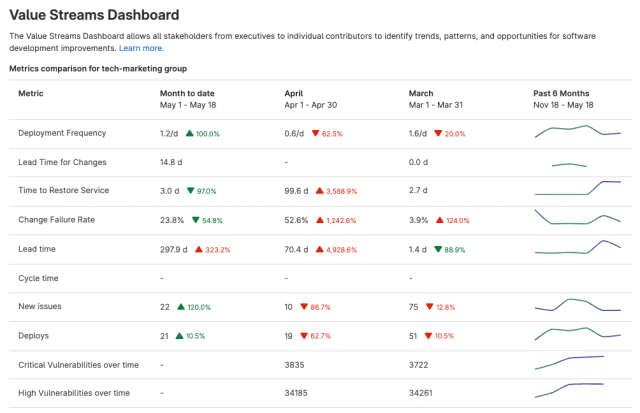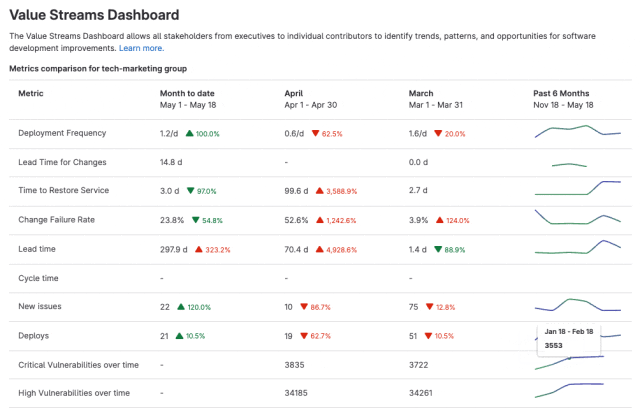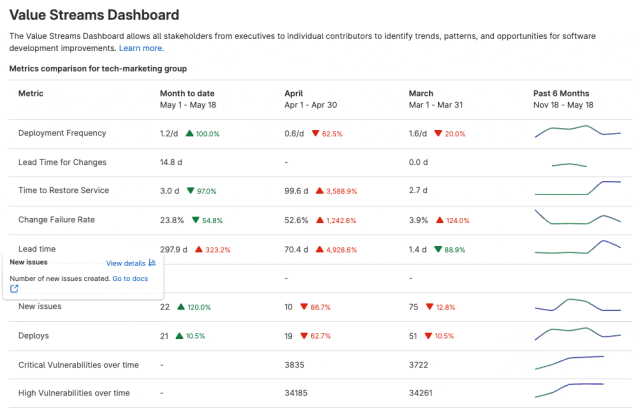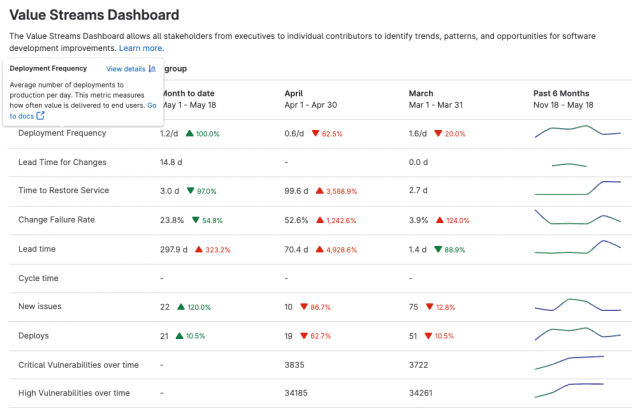
极狐GitLab 全新「价值流仪表盘」使用指南
本文来源:about.gitlab.com 作者:Haim Snir 译者:极狐(GitLab) 市场部内容团队 GitLab / 极狐GitLab 价值流仪表盘的使用相对简单,这种可以定制化的仪表盘能够让决策者识别数字化转型进程中的趋势及机遇。 如果你已经在用 GitLab…...

通过logrotate实现nginx容器内日志按天存储
场景 最近底层api需要上集群,于是用nginx做了转发,但是随着时间的增长,nginx的日志越来越大,磁盘空间也顶不住了,于是需要对日志进行分割,由于nginx原生是不支持日志按天存储和分割的,网上也介…...

广东珠海电子行业导入MES系统需要注意什么
一、电子行业工厂的生产特征 1.高度自动化: 电子行业的生产车间大多采用高度自动化的生产设备制造工艺。自动化流水线能够实现高效、精准和连续的生产过程,提升产品完整性和生产率。 2.多样化和个性化定制需求: 电子产品市场的需求多样化&…...

小红书2023/08/06Java后端笔试 AK
T1(模拟、哈希表) #include <bits/stdc.h>using namespace std;typedef long long LL; typedef pair<string, int> PSI;const int N 1e5 10;void solve() {string line, t;getline(cin, line);line ;vector<PSI> ans;unordered_m…...

3、有序数组的平方
有一个有序数组从大到小排列:-10 -5 1 2 3 4,将他们的每一项平方,然后再形成新的有序数组。 解法:双指针 因为前面是负数,后面是正数,平方和的最大值一定是从两端取得,所以可以定义一个头指针和…...
 的 MLOps)
用于自然语言处理 (NLP) 的 MLOps
介绍 自然语言处理( NLP )的人工智能关注的是计算机和人们如何用日常语言进行交流。鉴于 NLP 模型在生产系统中的部署,我们需要简化 NLP 应用程序的不断使用,从而使 MLOps(机器学习操作)对 NLP 有所帮助。在生产系统中自动创建、训练、测试和部署 NLP 模型是 MLOps for …...

C#抽象静态方法
抽象静态方法 在C# 11中,引入了对抽象静态接口成员的支持。这个特性可以让你在接口中定义静态抽象方法、属性、或事件。具体来说,一个接口可以定义一个或多个抽象静态成员,这些成员没有具体的实现。任何实现该接口的类或结构必须提供这些成员…...
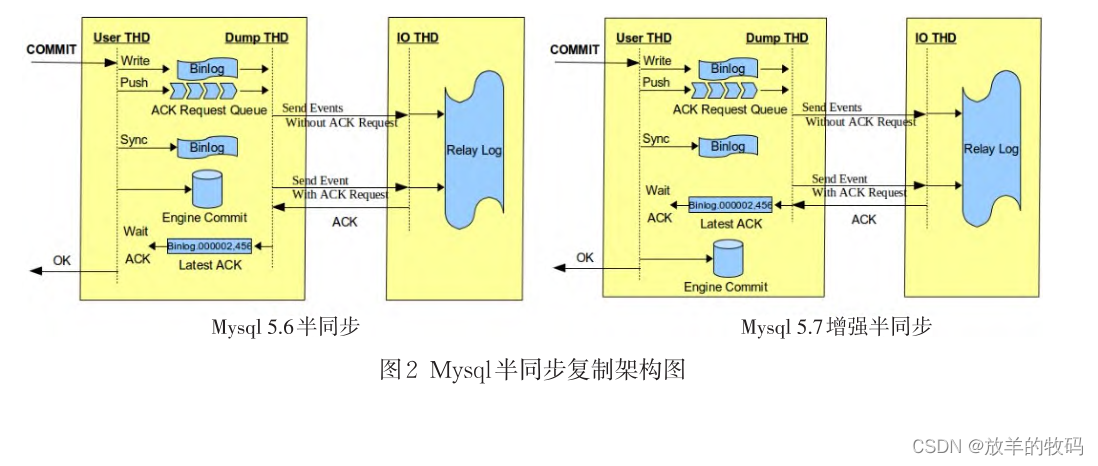
小研究 - Mysql快速全同步复制技术的设计和应用(一)
Mysql半同步复制技术在高性能的数据管理中被广泛采用,但它在可靠性方面却存在不足.本文对半同步复制技术进行优化,提出了一种快速全同步复制技术,通过对半同步数据复制过程中的事务流程设置、线程资源合理应用、批量日志应用等技术手段&#…...

HTML <samp> 标签
定义和用法 以下元素都是短语元素。虽然这些标签定义的文本大多会呈现出特殊的样式,但实际上,这些标签都拥有确切的语义。 我们并不反对使用它们,但是如果您只是为了达到某种视觉效果而使用这些标签的话,我们建议您使用样式表&a…...
linux动态库编译框架)
C之(8)linux动态库编译框架
C之(8)Linux动态库编译基础框架 Author: Once Day Date:2023年8月5日 漫漫长路,有人对你微笑过嘛… 参考引用文档: VERSION (LD) (sourceware.org)Warning Options (Using the GNU Compiler Collection (GCC))All about symbo…...
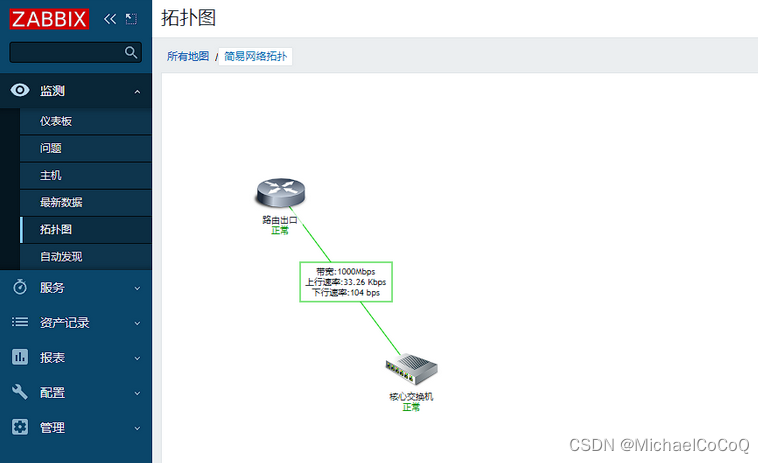
Zabbix网络拓扑配置
一、简介 网络拓扑功能是一项非常重要的功能,它可以直观展示网络设备主机状态及端口传输速率等指标信息,帮助运维人员快速发现和定位故障问题;Zabbix同样配备了强大的网络拓扑功能,如何使用Zabbix拓扑图功能创建一个公司网络拓扑…...
2.4G芯片XL2408开发板,SOP16封装,芯片集成1T 8051内核单片机
XL2408开发板可用于2.4G芯片XL2408开发板的开发调试。XL2408烧录仿真需要使用WS_LINK。XL2408开发板烧录仿真需要接4根线:PA13:DIO,PA14:CLK,VCC,GND。 XL2408芯片集成射频收发机、频率收生器、晶体振荡器、调制解调器等功能模块,…...
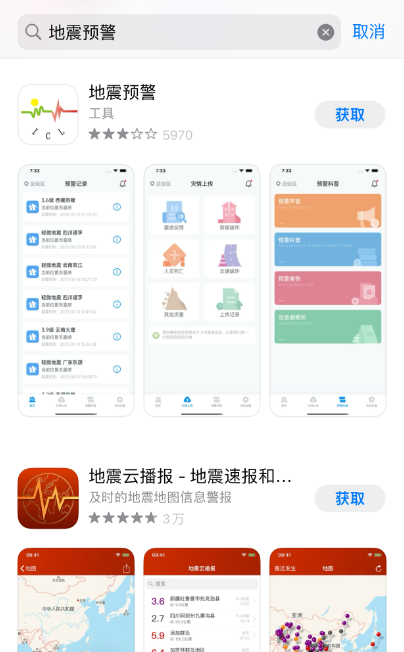
iPhone苹果手机地震预警功能怎么开启?
iPhone苹果手机地震预警功能怎么开启? 1、打开iPhone苹果手机设置; 2、在iPhone苹果手机设置内找到辅助功能; 3、在辅助功能内找到触控; 4、在iPhone苹果手机辅助功能触控内找到振动,如果是关闭状态请启; …...

Qwen3-ASR-1.7B车载场景应用:驾驶语音助手开发
Qwen3-ASR-1.7B车载场景应用:驾驶语音助手开发 1. 引言 开车时操作导航、切歌、调音量,这些看似简单的操作却暗藏风险。低头一秒,车辆就能开出几十米,事故往往就发生在这瞬间。传统的触屏操作不仅分心,还让驾驶变得不…...
到镜像运行全链路)
Wan2.2-I2V-A14B保姆级教程:从云服务器选购(CPU/内存/磁盘)到镜像运行全链路
Wan2.2-I2V-A14B保姆级教程:从云服务器选购到镜像运行全链路 1. 前言:为什么选择私有部署 在当今视频内容需求爆炸式增长的时代,能够快速生成高质量视频内容的能力变得尤为重要。Wan2.2-I2V-A14B作为一款先进的文生视频模型,可以…...

RefluxJS入门指南:构建React应用的终极单向数据流解决方案
RefluxJS入门指南:构建React应用的终极单向数据流解决方案 【免费下载链接】refluxjs A simple library for uni-directional dataflow application architecture with React extensions inspired by Flux 项目地址: https://gitcode.com/gh_mirrors/re/refluxjs …...

openclaw v2026.4.1 发布!16 大核心功能升级 + 28 项关键修复,AI 智能体网关全面进化,稳定性与安全性再攀高峰
一、前言:开源AI智能体标杆再升级,v2026.4.1引领本地自动化新潮流 2026年4月2日,开源AI智能体执行网关领域的标杆项目OpenClaw正式推出v2026.4.1最新版本。作为一款主打本地优先、自托管、全开源的AI智能体框架,OpenClaw自诞生以来…...

千问3.5-9B Visio图表智能生成:从文本描述到专业架构图
千问3.5-9B Visio图表智能生成:从文本描述到专业架构图 1. 效果惊艳的智能图表生成 想象一下,你只需要用简单的文字描述系统架构,就能在几分钟内获得专业的Visio图表。千问3.5-9B让这个场景成为现实。这个模型不仅能理解复杂的系统架构描述…...

成本优化实战:gemma-3-12b-it本地部署为OpenClaw节省40%Token
成本优化实战:gemma-3-12b-it本地部署为OpenClaw节省40%Token 1. 为什么我要做这次优化 上个月我统计OpenClaw的账单时,发现一个惊人的现象:我的自动化助手每天要消耗近3万Token。最夸张的是,其中70%的Token都花在了"鼠标移…...

FireRedASR Pro优化指南:如何提升长音频识别效率
FireRedASR Pro优化指南:如何提升长音频识别效率 1. 长音频识别的核心挑战 语音识别系统在处理长音频时面临几个关键瓶颈问题: 内存压力:随着音频时长增加,需要缓存的中间状态呈指数级增长计算复杂度:注意力机制的时…...

PyTorch 2.8开源大模型镜像实操:HuggingFace模型本地化API服务封装
PyTorch 2.8开源大模型镜像实操:HuggingFace模型本地化API服务封装 1. 镜像环境概览 1.1 硬件与软件配置 这个基于PyTorch 2.8的深度学习镜像经过RTX 4090D显卡和CUDA 12.4的深度优化,为大型模型推理和训练提供了开箱即用的环境。主要配置包括&#x…...

魔兽争霸3现代化修复指南:三步让经典游戏在Windows 10/11完美运行
魔兽争霸3现代化修复指南:三步让经典游戏在Windows 10/11完美运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代电…...

Phi-3-mini-4k-instruct-gguf惊艳效果:中文长难句拆解+逻辑关系标注+通俗转述三重能力展示
Phi-3-mini-4k-instruct-gguf惊艳效果:中文长难句拆解逻辑关系标注通俗转述三重能力展示 1. 模型能力概览 Phi-3-mini-4k-instruct-gguf作为微软Phi-3系列的轻量级文本生成模型,在中文处理方面展现出令人惊喜的能力。这个开箱即用的模型特别擅长处理三…...