大数据课程F3——HIve的基本操作
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 掌握HIve的基本SQL语句和注意问题;
⚪ 掌握HIve的表结构;
⚪ 掌握HIve的数据类型;
⚪ 掌握HIve的基础函数和窗口函数;
一、基本SQL
1. SQL的执行方式
1. 通过hive -e的方式来执行指定的SQL,例如hive -e 'create database demo;'。
2. 通过hive -f的方式来执行指定的SQL脚本,例如hive -f test.sql。
3. 进入Hive的命令行里来执行指定的SQL。
2. 注意问题
1. 如果不指定,那么Hive默认将数据放在HDFS的/user/hive/warehouse目录下。
2. 在Hive中,每一个database都对应了一个单独的目录。
3. 在Hive启动的时候,自带一个default库。如果在建表的时候没有指定,那么默认也是将表放在default库下。
4. alter database可以修改指定库的属性,但是不能修改库的库名以及存储位置。
5. 在Hive中,没有主键的概念,不支持主键。
6. 在Hive中,每一个table也对应了一个单独的目录。
7. 在Hive中,需要在建表的时候指定字段之间的间隔符号。
8. insert into表示向表中追加数据;insert overwrite表示将表中的清空之后再添加当前的数据(覆盖)。
9. 需要注意的是,Hive中的数据会以文件的形式落地到HDFS上,在Hive的默认文件格式(textfile - 文本)下,不支持修改(update和delete)操作。如果需要Hive支持修改操作,那么需要在建表的时候指定文件格式为orc格式。但是在实际开发中,因为一般利用Hive存储历史数据,所以很少或者根本不对Hive中的数据进行修改,因此一般不适用orc格式。另外,orc格式虽然支持update和delete操作,但是效率非常低。
3. 基本SQL
| SQL | 解释 |
| create database demo; | 创建demo库 |
| create database if not exists demo4; | 如果demo4库不存在,则创建 |
| create database demo5 location '/demo5'; | 创建demo5库,同时指定存储位置 |
| show databases; | 查看所有的库 |
| show databases like 'demo*'; | 查看demo开头的库 |
| desc database demo; | 描述demo库 |
| desc database extended demo; | 描述demo库的详细信息 |
| use demo; | 使用demo库 |
| alter database demo set dbproperties ('date'='2020-12-25'); | 修改demo库的属性 |
| drop database demo5; | 删除demo5库 |
| drop database if exists demo4; | 如果demo4库存在,则删除 |
| drop database demo3 cascade; | 强制删除demo3库及其中的表 |
| create table person (id int, name string, age int); | 建立person表,包含id,name,age三个字段 |
| insert into table person values(1, 'colin', 19); | 插入数据 |
| select * from person; | 查询数据 |
| load data local inpath '/home/hivedemo/person.txt' into table person; | 从本地加载文件到Hive表中 |
| drop table person; | 删除表 |
| create table person (id int, name string, age int) row format delimited fields terminated by ' '; | 建表,指定字段之间的间隔符号为空格 |
| create table p2 like person; | 创建和person表结构一致的p2表 |
| describe p2; 或者 desc p2; | 描述p2 |
| show tables; | 查看所有的表 |
| insert into table p2 select * from person where age >= 18; | 从person中查询数据,将age>=18的数据放到p2表中 |
| create table if not exists p3 like person; | 如果p3表不存在,则创建和person结构一致的p3表 |
| from person insert overwrite table p2 select * where age >= 18 insert into table p3 select * where id < 5; | 从person表中查询数据,然后将查询出来的age>=18的数据覆盖到p2表中,同时将id<5的数据追加到p3表中 |
| create table if not exists p4 as select * from person where age < 18; | 创建p4表,同时在建表的时候,将person表中age<18的数据放进去 |
| insert overwrite local directory '/home/hivedata' row format delimited fields terminated by '\t' select * from person where age >= 18; | 将person表中age>=18的数据查询出来放到本地磁盘的/home/hivedata目录下 |
| insert overwrite directory '/person' row format delimited fields terminated by ',' select * from person where id >= 6; | 将person表中id>=6的数据查询出来放到HDFS的地址路径下 |
| alter table person rename to p1; | 重命名表 |
二、基本表结构
1. 内部表和外部表
1. 如果在Hive中手动建表手动添加数据(包括insert和load方式),那么这种表称之为内部表。
2. 如果在Hive中手动建表来管理HDFS上已经存在的数据,那么这种表称之为外部表。
3. 相对而言,在工程或者项目建立的初期,一般会建立外部表来管理HDFS上已经存在的数据;但是当外部表建立之后,不代表数据能够直接处理使用,还需要对数据进行抽取整理等清洗操作,来建立能够实际使用的内部表。
4. 建立外部表:
create external table orders(orderid int, orderdate string, productid int, num int) row format delimited fields terminated by ' ' location '/orders';
5. 查看表的详细信息:
desc extended orders;
#或者
desc formatted orders;
#在其中寻找Table Type:EXTERNAL_TABLE
6. 在Hive中,删除内部表的时候,这个表对应的目录也会从HDFS上删除;删除外部表的时候,只是删除了元数据,而这个表对应的目录没有从HDFS上移除。
2. 分区表
1. 分区表的作用通常是对数据来进行分类。
2. 建立分区表:
create table cities (id int, name string) partitioned by (province string) row format delimited fields terminated by ' ' ;
3. 加载数据:
load data local inpath '/home/hivedemo/hebei.txt' into table cities partition(province='hebei');
load data local inpath '/home/hivedemo/jiangsu.txt' into table cities partition(province='jiangsu');
4. 在Hive中,每一个分区对应一个单独的目录。
5. 如果在查询数据的时候,指定了分区字段,那么分区表的查询效率就会高于未分区的表;如果在查询数据的时候,进行了跨分区查询,那么此时未分区表的查询效率就要高于分区表。
6. 删除分区:
alter table cities drop partition(province = 'henan');
7. 手动添加分区:
alter table cities add partition (province='henan') location '/user/hive/warehouse/demo.db/cities/province=henan';
8. 修复表:
msck repair table cities;
9. 修改分区名:
alter table cities partition(province='__HIVE_DEFAULT_PARTITION__') rename to partition (province='sichuan');
10. 在Hive的分区表中,分区字段在原始数据中并不存在,而是在加载数据的时候来手动指定。如果分区字段在原始数据中存在,那么需要考虑动态分区。
相关文章:

大数据课程F3——HIve的基本操作
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握HIve的基本SQL语句和注意问题; ⚪ 掌握HIve的表结构; ⚪ 掌握HIve的数据类型; ⚪ 掌握HIve的基础函数和窗口函数; 一、基本SQL 1. SQL的执行方式 1. 通过hive -e的方式来执行指…...

top解析
top - 13:52:26 up 26 days, 20:56, 2 users, load average: 0.00, 0.01, 0.05 当前时间 系统运行时间,格式为时:分 当前登陆用户数2 系统负载,即任务队列的平均长度。三个数值分别为1分钟,5分钟,15分钟前到现在的平均…...

如何让子组件,router-view,呈现左右分布格局
1.用浮动进行浮动布局,定义一个大盒子,把浮动的样式写在公共样式里(这里在main.js里定义一下全局布局)。 2、能够在右边显示了...
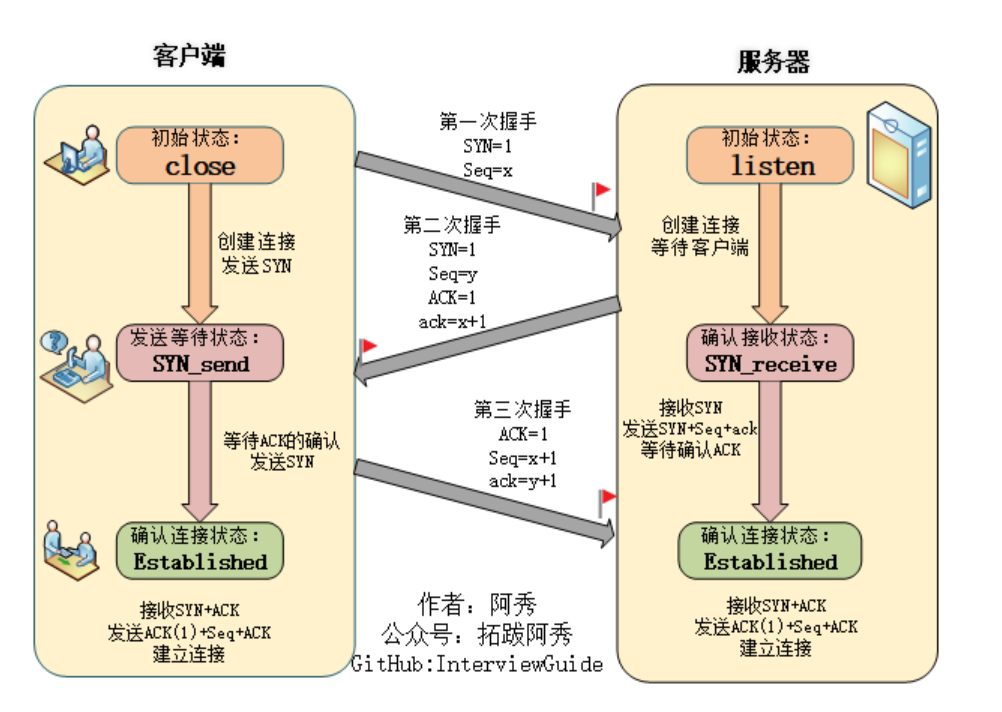
计算机网络—TCP和UDP、输入url之后显示主页过程、TCP三次握手和四次挥手
TCP基本认识 TCP是面向连接的、可靠的,基于字节流的传输层通信协议。 图片来源小林coding 序号:传输方向上字节流的字节编号。初始时序号会被设置一个随机的初始值(ISN),之后每次发送数据时,序号值 ISN…...
使用反汇编工具IDA查看发生异常的汇编代码的上下文去辅助分析C++软件异常
目录 1、概述 2、如何使用IDA打开并查看二进制文件的汇编代码 3、在IDA中找到发生崩溃的那条汇编指令的位置 3.1、如何在IDA中找到发生异常的那条汇编指令 3.2、示例 4、阅读汇编代码上下文需要掌握一定的基础汇编知识 5、最后 VC常用功能开发汇总(专栏文章列…...
怎么合并多个视频?简单视频合并方法分享
合并多个视频可以将它们组合成一个更长的视频,这对于需要播放多个短视频的情况非常有用。此外,合并视频还可以使视频编辑过程更加高效,因为不必将多个独立的视频文件分别处理。最后,合并视频可以减少文件数量,从而使整…...
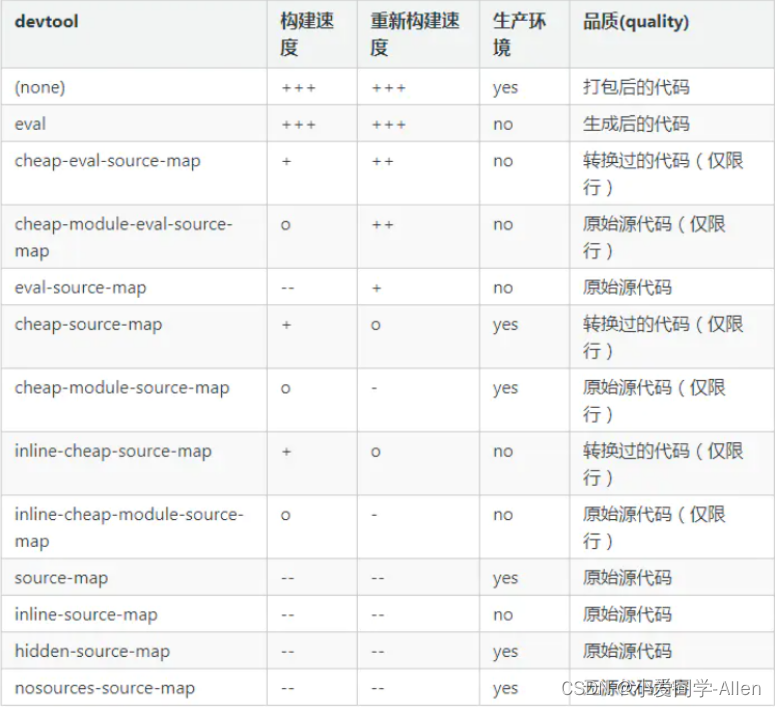
webpack基础知识九:如何提高webpack的构建速度?
一、背景 随着我们的项目涉及到页面越来越多,功能和业务代码也会随着越多,相应的 webpack 的构建时间也会越来越久 构建时间与我们日常开发效率密切相关,当我们本地开发启动 devServer 或者 build 的时候,如果时间过长ÿ…...

批量改名字序号和前缀
echo off setlocal enabledelayedexpansion set count10 for /f %%i in (dir /b *.jpg,*.png,*.bmp,*.jpeg,*.gif) do ( set /a count1 echo %%i 前缀_!count! rename %%i 前缀_!count!.png ) REM …...
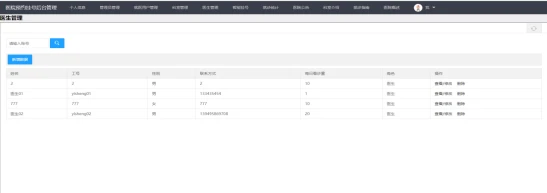
基于Spring Boot的医院预约挂号网站设计与实现(Java+spring boot+MySQL)
获取源码或者论文请私信博主 演示视频: 基于Spring Boot的医院预约挂号网站设计与实现(Javaspring bootMySQL) 使用技术: 前端:html css javascript jQuery ajax thymeleaf 微信小程序 后端:Java spring…...

Linux命令200例:join将两个文件按照指定的键连接起来分析
🏆作者简介,黑夜开发者,全栈领域新星创作者✌。CSDN专家博主,阿里云社区专家博主,2023年6月csdn上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责人。 &…...

谈谈网络安全
目录 1.概念 2.发展现状 3.主要问题 1.概念 网络安全是指保护计算机网络和其中的数据免受未经授权访问、损坏、窃取或破坏的过程和技术。网络安全涉及预防和检测潜在的威胁和漏洞,并采取措施保护网络的机密性、完整性和可用性。 网络安全的概念包括以下几个方面&am…...

机器学习深度学习——文本预处理
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——序列模型(NLP启动!) 📚订阅专栏:机器学习&am…...

Qt实现可伸缩的侧边工具栏(鼠标悬浮控制伸缩栏)
Qt实现可伸缩的侧边工具栏 一直在网上找,发现大多的实现方案都是用一个按钮,按下控制侧边栏的伸缩,但是我想要实现鼠标悬浮在侧边栏的时候就伸出,移开就收缩的功能,也没找到好的参考,所以决定自己实现一个…...

【Spring Boot】拦截器与统一功能处理
博主简介:想进大厂的打工人博主主页:xyk:所属专栏: JavaEE进阶 上一篇文章我们讲解了Spring AOP是一个基于面向切面编程的框架,用于将某方面具体问题集中处理,通过代理对象来进行传递,但使用原生Spring AOP实现统一的…...

RabbitMQ的6种工作模式
RabbitMQ的6种工作模式 官方文档: http://www.rabbitmq.com/ https://www.rabbitmq.com/getstarted.html RabbitMQ 常见的 6 种工作模式: 1、simple简单模式 1)、消息产生后将消息放入队列。 2)、消息的消费者监听消息队列,如果队列中…...

MFC第二十六天 CRgn类简介与开发、封装CMemoryDC类并应用开发
文章目录 CRgn类简介与开发CRgn类简介CRgn类区域管理开发CRgn类区域管理与不规则形状的选取 封装CMemoryDC类并应用开发CMemoryDC.h封装CMemoryDC开发游戏透明动画CFlashDlg.hCFlashDlg.cpp 封装CMemoryDC开发游戏动画 附录四大窗口CDC派生类 CRgn类简介与开发 CRgn类简介 CR…...
解决VScode远程服务器时opencv和matplotlib无法直接显示图像的问题
解决VScode远程服务器时opencv和matplotlib无法直接显示图像的问题 1、本方案默认本地已经安装了VScode与MobaXterm2、在服务器端3、在本地端安装MobaXterm4、测试5、opencv显示测试(测试过程中需保持MobaXterm开启的状态)6、 matplotlib显示测试&#x…...

支付模块功能实现(小兔鲜儿)【Vue3】
支付 渲染基础数据 支付页有俩个关键数据,一个是要支付的钱数,一个是倒计时数据(超时不支付商品释放) 准备接口 import request from /utils/httpexport const getOrderAPI (id) > {return request({url: /member/order/$…...

php meilisearch demo
# 创建一个meilisearch 使用完自动销毁 docker run -itd --rm -p 7700:7700 getmeili/meilisearch:v1.3docker-compose 参数 version: "3" networks:flyserver:driver: bridge services:search:image: getmeili/meilisearch:v1.3restart: alwaysenvironment:- MEILI…...

芒格之道——查理·芒格股东会讲话1987-2022
你越是认真生活,你的生活就会越美好! 这里将读书过程划线的内容摘抄在这里,方便自己回顾。 书分为两部分,我先读了后半部分,而且是从后往前读,到了前半部分,我是从前往后读。书还挺贵ÿ…...
)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码) 高速数据采集系统中,时序同步问题往往是工程师的噩梦。当AD7961工作在回声时钟模式时,数据信号与时钟信号的微妙相位关系可能导致采样结果出…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

5大优势解析:如何高效使用免费离线OCR工具
5大优势解析:如何高效使用免费离线OCR工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 项目…...

Arm Neoverse CMN-700互连架构与协议寄存器配置指南
1. Arm Neoverse CMN-700一致性互连架构解析在现代多核处理器设计中,一致性互连网络如同城市交通系统般重要。Arm Neoverse CMN-700作为第二代Coherent Mesh Network解决方案,其架构设计充分考虑了数据中心和边缘计算的严苛需求。与传统的总线或环形拓扑…...

Arm Cortex-X2/X3架构解析与性能优化实践
1. Arm Cortex-X2/X3集群架构概述在Armv9架构的高性能计算领域,Cortex-X2和X3代表了当前最先进的CPU设计理念。作为DynamIQ共享单元(DSU)的核心组件,它们通过可配置的缓存层次结构和智能一致性协议,为现代异构计算提供了灵活的解决方案。1.1 …...

芯片老化座的工作温度范围?
在芯片测试领域,老化座(Burn-in Socket)是保障半导体器件长期可靠性的关键设备。它不仅要在极端温度下稳定工作,还要确保测试数据的精准度。今天,我们以HMILU(深圳市鸿怡电子有限公司)为例&…...

WipperSnapper+Adafruit IO:无代码物联网开发实战,从传感器到云端自动化
1. 项目概述与核心价值如果你和我一样,在物联网(IoT)项目初期,常常被复杂的嵌入式编程、网络协议和云平台对接搞得焦头烂额,那么今天分享的这个实战项目,或许能让你眼前一亮。我们这次不谈复杂的代码&#…...

基于RP2040与I2C总线打造可编程合成器吉他:从硬件到固件的完整实践
1. 项目概述:打造你的第一把可编程合成器吉他 如果你对电子音乐制作和嵌入式硬件开发都感兴趣,那么将两者结合的DIY项目无疑是最迷人的领域。今天要分享的,就是基于Adafruit RP2040 PropMaker Feather微控制器,从零开始打造一把功…...

模拟WiFi反向散射技术:无电池物联网通信新突破
1. 项目概述:模拟WiFi反向散射技术的革新突破在物联网设备爆炸式增长的今天,电池续航已成为制约大规模部署的关键瓶颈。传统传感器节点即使采用低功耗设计,其电池寿命也鲜有超过3-5年。而Leggiero提出的模拟WiFi反向散射技术,则开…...
在Multi-Agent系统中的应用(图编排、动态DAG、Dynamic DAG)动态Agent Graph)
有向无环图(DAG)在Multi-Agent系统中的应用(图编排、动态DAG、Dynamic DAG)动态Agent Graph
文章目录有向无环图(DAG)在 Multi-Agent 系统中的应用一、什么是 DAG(有向无环图)二、为什么 Multi-Agent 需要 DAG三、Multi-Agent 的本质:任务图四、DAG 在 Multi-Agent 中的核心作用五、一个典型 Multi-Agent DAG六…...