PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(10)——过拟合及其解决方法
- 0. 前言
- 1. 过拟合基本概念
- 2. 添加 Dropout 解决过拟合
- 3. 使用正则化解决过拟合
- 3.1 L1 正则化
- 3.2 L2 正则化
- 4. 学习率衰减
- 小结
- 系列链接
0. 前言
过拟合 (Overfitting) 是指在机器学习中,模型过于复杂而导致在训练数据上表现良好,但在新的未见过的数据上表现不佳的现象。直观的讲,可能会在训练过程中出现模型的训练准确率约为 100%,而测试准确率仅有 80% 左右的情况。在本文中,我们直观地介绍训练与测试准确率之间的差异的原因以及解决方法。
1. 过拟合基本概念
在《神经网络性能优化技术》中,我们经常看到这样的现象——训练数据集的准确率通常超过 95%,而验证数据集的准确率大约只为 89%。从本质上讲,这表明该模型在未见过的数据上的泛化程度不高,也表明模型正在学习训练数据集的异常数据,这些情况并不适用于验证数据集。
当模型过度关注于训练数据中的细节和噪音时,会导致过拟合。过拟合通常发生在模型复杂度过高、训练数据量较少或训练数据不平衡的情况下。当模型太过复杂时,它可能在训练数据中学习到了噪声和随机性,并将其视为普遍规律。当训练数据量较少时,模型可能没有足够的样本来全面学习数据的特征分布,从而容易出现过拟合。过拟合现象使得模型对训练数据中的个别特征过于敏感,而无法正确地推广到新的数据。可以使用以下策略降低模型过拟合的影响:
- 增加训练数据的数量,确保数据集更加全面和多样化
- 减少模型的复杂度,例如减少参数数量或使用正则化方法
- 使用交叉验证等技术来评估模型的性能,并进行模型选择
- 提前停止训练,即在模型开始过拟合之前停止迭代
- 进行特征选择,删除不相关或冗余的特征
- 数据预处理,例如归一化/标准化数据,处理异常值等
2. 添加 Dropout 解决过拟合
Dropout 是一种用于减少神经网络过拟合的正则化技术。在训练过程中,Dropout 会随机地将一部分神经元的输出置为 0 (即丢弃),从而降低神经网络对特定神经元的依赖性。具体来说,在每次训练迭代中,Dropout 会以一定的概率随机选择部分神经元,并将其输出置为 0,这意味着每个神经元都有一定的概率被“关闭”,从而迫使网络学习到更加鲁棒和独立的特征表示。

通过引入 Dropout,神经网络无法过度依赖某些特定神经元,因为它们的输出可能随时被丢弃。这样可以有效地减少神经网络的复杂性,降低模型对训练数据的噪音和过拟合的敏感性,提高模型的泛化能力。在训练完成后,通常不再应用 Dropout,而是使用所有的神经元进行推理和预测。这是因为在测试阶段,我们希望模型能够充分利用所有可用的神经元来最大限度地提取特征和进行预测。
正常模型训练时,每次计算 loss.backward() 时,都更新模型权重。通常,神经网络中包含数以百万计的参数,因此可能虽然大多数参数有助于训练模型,但某些参数可能会针对训练图像进行微调,从而导致它们的值仅由训练数据集中的少数图像决定,这会导致模型在训练数据上具有较高精度,但在验证数据集上的泛化能力较差。
由于 Dropout 在训练和验证过程中具有不同操作,因此必须预先指定模型的模式为 model.train() (处于训练阶段)或 model.eval() (处于验证阶段)。
定义架构时,在 get_model() 函数中指定 Dropout 如下:
from torch.optim import SGD, Adam
def get_model():model = nn.Sequential(nn.Dropout(0.5),nn.Linear(28 * 28, 1000),nn.ReLU(),nn.Dropout(0.5),nn.Linear(1000, 10)).to(device)loss_fn = nn.CrossEntropyLoss()optimizer = Adam(model.parameters(), lr=1e-3)return model, loss_fn, optimizer
在以上代码中,还在线性激活前添加了 Dropout,训练和验证数据集的损失和准确率变化如下所示:

使用相同的架构,未使用 Dropout 时训练和验证数据集的损失和准确率变化如下所示:

可以看出,训练数据集和验证数据集的准确率之间的差异没有之前模型差距那么大,有效的降低了模型的过拟合。
绘制两种情况下隐藏层的权重直方图,可以看到使用 Dropout 时训练和测试准确率之间的差距低于没有 Dropout 时模型训练和测试准确率的差距:


3. 使用正则化解决过拟合
除了训练准确率远高于验证准确率外,过拟合的另一个特征是网络中的某些权重值显著高于其他权重值,高权重值可能是模型为了拟合训练数据中异常值的表现。正则化是一种惩罚模型中具有较高值的权重的技术,因此,需要同时最小化训练数据的损失以及权重值。在本节中,我们将学习两类正则化:
- L1 正则化
- L2 正则化
3.1 L1 正则化
L1 正则化计算如下:
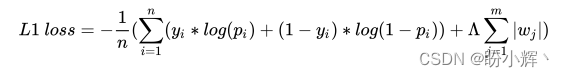
L 1 l o s s = − 1 n ( ∑ i = 1 n ( y i ∗ l o g ( p i ) + ( 1 − y i ) ) + Λ ∑ j = 1 m ∣ w j ∣ ) L1\ loss=-\frac 1n(\sum_{i=1}^n(y_i*log(p_i)+(1-y_i))+\Lambda \sum_{j=1}^m|w_j|) L1 loss=−n1(i=1∑n(yi∗log(pi)+(1−yi))+Λj=1∑m∣wj∣)
上述公式的第一部分是在以上模型中用于优化的分类交叉熵损失,而第二部分是指模型权重值的绝对值之和, Λ \Lambda Λ 是用于平衡交叉熵损失和权重绝对值的权重系数。L1 正则化通过将权重的绝对值合并到损失值的计算中来确保它惩罚具有较高绝对值的权重,L1 正则化在训练模型的同时进行:
def train_batch(x, y, model, opt, loss_fn):prediction = model(x)l1_regularization = 0for param in model.parameters():l1_regularization += torch.norm(param,1)batch_loss = loss_fn(prediction, y) + 0.0001*l1_regularizationbatch_loss.backward()optimizer.step()optimizer.zero_grad()return batch_loss.item()
在以上代码中,首先初始化 l1_regularization,并对所有层的权重和偏置进行了正则化。torch.norm(param,1) 提供了权重和偏置值的绝对值。此外,使用一个非常小的权重系数 (0.0001) 来平衡参数绝对值之和对损失函数的影响。
使用 L1 正则化后,训练和验证数据集上的损失和准确率的变化如下所示:

可以看到训练数据集和验证数据集的准确率差异相比没有 L1 正则化时更小。
3.2 L2 正则化
L2 正则化计算如下:
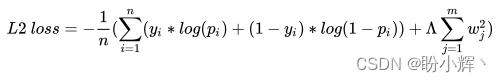
L 2 l o s s = − 1 n ( ∑ i = 1 n ( y i ∗ l o g ( p i ) + ( 1 − y i ) ∗ l o g ( 1 − p i ) ) + Λ ∑ j = 1 m w j 2 ) L2\ loss =-\frac 1n(\sum_{i=1}^n(y_i*log(p_i)+(1-y_i)*log(1-p_i))+\Lambda \sum_{j=1}^mw_j^2) L2 loss=−n1(i=1∑n(yi∗log(pi)+(1−yi)∗log(1−pi))+Λj=1∑mwj2)
其中,第一部分是指分类交叉熵损失,而第二部分是指模型权重值的平方和, Λ \Lambda Λ 是用于平衡交叉熵损失和权重平方和的权重系数。与 L1 正则化类似,通过将权重的平方和纳入损失计算来惩罚较高权重值。L2 正则化同样在训练模型的同时进行:
def train_batch(x, y, model, opt, loss_fn):prediction = model(x)l2_regularization = 0for param in model.parameters():l2_regularization += torch.norm(param,2)batch_loss = loss_fn(prediction, y) + 0.01*l2_regularizationbatch_loss.backward()optimizer.step()optimizer.zero_grad()return batch_loss.item()
在以上代码中,正则化的权重参数 (0.01) 略高于 L1 正则化,因为权重通常在 -1 到 1 之间,并且执行平方后会得到更小的结果值,如果权重参数较小,将导致在整体损失计算第二项的影响非常小。
使用 L2 正则化后,训练和验证数据集上的损失和准确率的变化情况如下所示:

可以看到 L2 正则化同样可以令验证和训练数据集的准确率和损失更接近。
最后,我们比较没有进行正则化和使用 L1/L2 正则化的权重,观察网络层的权重分布,如下图所示:

可以看到,与不执行正则化相比,执行 L1/L2 正则化时参数的分布范围非常小,这可能会减少为异常数据更新权重的机会。
我们已经知道了较高的学习率在缩放和未缩放的数据集上均难以得到最佳结果,在下一节中,我们将学习如何在模型开始过拟合时自动降低学习率.
4. 学习率衰减
在以上模型中,我们在模型训练过程中使用恒定的学习率,但是,通常可以将权重快速更新到接近最佳状态,在模型训练后期可以进行缓慢的更新,因为模型训练初期的损失较高,而在后期损失较低。这就需要模型训练初期具有较高学习率,然后随着模型接近最佳的准确率,学习率也需要逐渐降低,因此我们这需要了解在何时降低学习率。
一种常用的方法是持续监控验证损失,如果验证损失在一段 epoch 内没有减少,就降低学习率。PyTorch 提供了调度方法 lr_scheduler,当验证损失在之前的 “x” 个 epoch 内没有减少时,降低学习率:
from torch import optim
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,factor=0.5,patience=0,threshold = 0.001,verbose=True,min_lr = 1e-5,threshold_mode = 'abs')
在以上代码中,指定如果某个值在接下来的 n 个 epoch (使用 patience参数指定)没有提高指定阈值(使用 threshold 参数指定),则学习率衰减为原来的 0.5 倍(即变为原来的 1/2,使用 factor 参数指定),且使用参数 min_lr 指定学习率的最小值 (不低于 1e-5),并且使用参数 threshold_mode 指定阈值模式(此处使用 abs,以确保超过指定的最小阈值)。接下来,在训练模型时应用 lr_scheduler,并在模型训练时监测验证损失:
trn_dl, val_dl = get_data()
model, loss_fn, optimizer = get_model()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,factor=0.5,patience=0,threshold = 0.001,verbose=True,min_lr = 1e-5,threshold_mode = 'abs')train_losses, train_accuracies = [], []
val_losses, val_accuracies = [], []
for epoch in range(30):# print(epoch)train_epoch_losses, train_epoch_accuracies = [], []for ix, batch in enumerate(iter(trn_dl)):x, y = batchbatch_loss = train_batch(x, y, model, optimizer, loss_fn)train_epoch_losses.append(batch_loss) train_epoch_loss = np.array(train_epoch_losses).mean()for ix, batch in enumerate(iter(trn_dl)):x, y = batchis_correct = accuracy(x, y, model)train_epoch_accuracies.extend(is_correct)train_epoch_accuracy = np.mean(train_epoch_accuracies)for ix, batch in enumerate(iter(val_dl)):x, y = batchval_is_correct = accuracy(x, y, model)validation_loss = val_loss(x, y, model, loss_fn)scheduler.step(validation_loss)val_epoch_accuracy = np.mean(val_is_correct)train_losses.append(train_epoch_loss)train_accuracies.append(train_epoch_accuracy)val_losses.append(validation_loss)val_accuracies.append(val_epoch_accuracy)
在以上代码中,指定只要验证损失在连续的 epoch 内没有减少,就激活调度程序,学习率降低 0.5 倍,模型上执行调度程序输出如下:
Epoch 3: reducing learning rate of group 0 to 5.0000e-04.
Epoch 5: reducing learning rate of group 0 to 2.5000e-04.
Epoch 7: reducing learning rate of group 0 to 1.2500e-04.
Epoch 11: reducing learning rate of group 0 to 6.2500e-05.
Epoch 13: reducing learning rate of group 0 to 3.1250e-05.
Epoch 14: reducing learning rate of group 0 to 1.5625e-05.
Epoch 15: reducing learning rate of group 0 to 1.0000e-05.
训练和验证数据集的准确率和损失随时间变化如下:
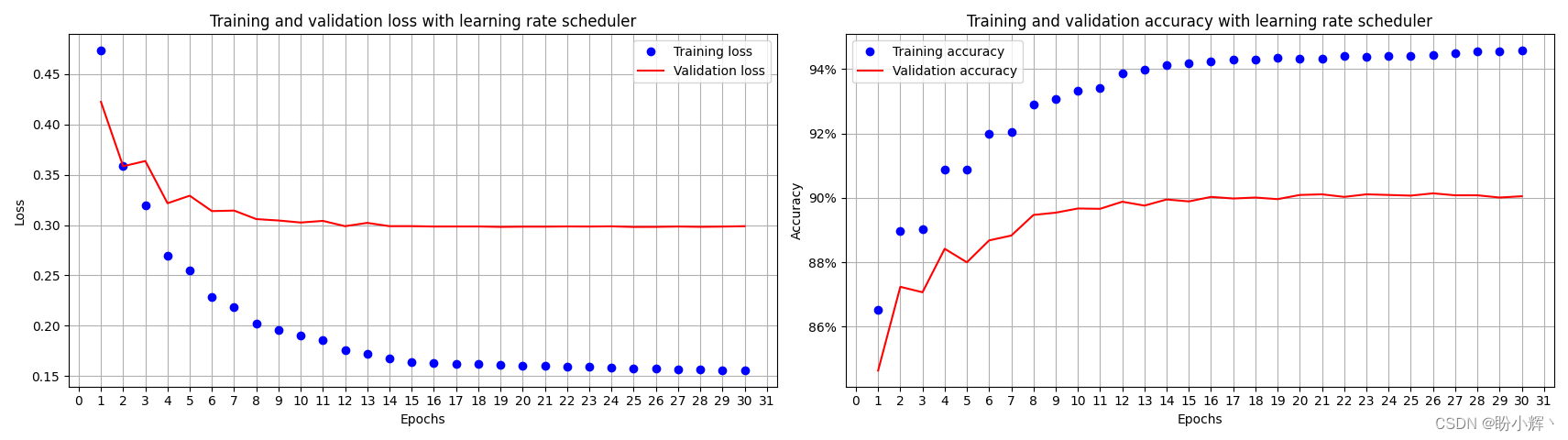
通过使用调度程序,即使对模型进行了 30 个(或更多) epoch 的训练,也没有严重的过拟合问题,这是因为当学习率衰减的极小时,权重的更新也变得非常小,因此训练和验证准确率之间的差距也非常小。
小结
过拟合是指机器学习模型在训练集上表现很好,但在测试集或未见过的数据上表现较差的现象。过拟合是由于模型在训练过程中过度拟合了训练数据的特点和噪声,导致了对训练样本的过度依赖和泛化能力不足。为了解决过拟合问题,选择适当的方法需要对具体问题和数据进行分析,并在模型构建和调优过程中进行实验和验证。在实践中,通常需要权衡模型的复杂度和泛化能力,以获得更好的结果。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
相关文章:
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(10)——过拟合及其解决方法 0. 前言1. 过拟合基本概念2. 添加 Dropout 解决过拟合3. 使用正则化解决过拟合3.1 L1 正则化3.2 L2 正则化 4. 学习率衰减小结系列链接 0. 前言 过拟合 (Overfitting) 是指在机器学习中,模型…...

【工作记录】week7
day3 1.本地切换分支 本地切换分支时,可以直接用 vscode 集成的工具 点击后直接选择即可: 其中红框中为本地分支,蓝框中则是远程分支! 当在本地切换到一个本地不存在的远程分支时,会在本地创建一个同名的分支&…...
安防监控视频融合EasyCVR平台接入RTSP流后设备显示离线是什么原因?
安防监控视频EasyCVR视频汇聚融合平台基于云边端智能协同架构,具有强大的数据接入、处理及分发能力,平台支持海量视频汇聚管理、全网分发、按需调阅、鉴权播放、智能分析等视频能力与服务。平台开放度高、兼容性强、可支持灵活拓展与第三方集成ÿ…...

MongoDB:Linux环境全套安装指南
😊 作者: 一恍过去 💖 主页: https://blog.csdn.net/zhuocailing3390 🎊 社区: Java技术栈交流 🎉 主题: MongoDB:Linux环境全套安装指南 ⏱️ 创作时间:…...

PostgreSql 启停
一、启动 直接运行 postgres 进程启动。使用 pg_ctl 命令启动。(pg_ctl 命令实际也是封装的 postgres 进程) 示例: pg_ctl -D /data/pg13/data start 或 postgres -D /data/pg13/data &二、停止 使用 pg_ctl 命令停止,优先…...
中介者模式(C++)
定义 用一个中介对象来封装(封装变化)一系列的对象交互。中介者使各对象不需要显式的相互引用(编译时依赖->运行时依赖),从而使其耦合松散(管理变化),而且可以独立地改变它们之间的交互。 应用场景 在软件构建过程中,经常会出现多个对象…...

LeetCode热题 100整理
53. 最大子数组和 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。子数组是数组中的一个连续部分。 示例 1: 输入:nums [-2,1,-3,4,-1,2,1,-5,4] 输…...

SDE与ODE
看这篇文章不错https://spaces.ac.cn/archives/9209 然后在结合https://www.bilibili.com/video/BV1814y1n7Eh/?spm_id_from333.788&vd_sourceeb433c8780bdd700f49c6fc8e3bd0911这个B站的视频...

AWK实战案例——筛选给定时间范围内的日志
时间戳与当地时间 概念: 1.时间戳: 时间戳是指格林威治时间自1970年1月1日(00:00:00 GMT)至当前时间的总秒数。它也被称为Unix时间戳(Unix Timestamp)。通俗的讲,时间戳是一份能够表示一份数据…...

摄影入门基础笔记
1.认识相机,传感器和镜头 微单相机和单反相机 运动相机、卡片机 微单和单反的区别? 微单的光学结构少了反光板的结构以及棱镜的结构 DSLR [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PCSYr2Ob-1691407493645)(https:/…...
如何在业务中体现TCC事务模型?
在分布式系统设计中,随着微服务的流行,通常一个业务操作被拆分为多个子任务,比如电商系统的下单和支付操作,就涉及到了创建和更新订单、扣减账户余额、扣减库存、发送物流消息等,那么在复杂业务开发中,如何…...

TouchGFX字库外置的另一种处理方式
最近有个带UI的项目,采用STM32F429做主控方案,对比touchgfx、lvgl和emwin,发现TouchGFX性能最好,并且界面设计工具也很好用,于是选择此图形引擎。 最开始是熟悉UI设计工具,需要一个表格控件,无…...

jvm的垃圾回收算法有哪些
jvm的垃圾回收算法有标记-清除、复制、标记-整理、分代回收算法,它们分别有不同的实现: 一、标记-清除算法 利用可达性分析算法分析之后,将未被标记的对象[即不可达对象]清除,以便回收它们所占用的内存。 缺点: 1、需…...
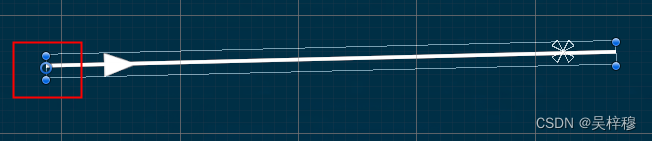
untiy 连接两个UI或一段固定一段跟随鼠标移动的线段
注意,仅适用于UI,且Canvas必须是Camera模式,不能用在3D物体上,3D物体请使用LineRenender 先创建一个图片,将锚点固定在左边 然后在脚本中添加如下内容 public RectTransform startObj;//起点物体public RectTransfor…...

如何成为顶级开源项目的贡献者
概述 对于程序员来讲,成为顶级开源项目的贡献者是一件有意义的事,当然,这也绝非易事。如果你正从事人工智能有关的工作,那么你一定了解诸如Google Tensorflow,Facebook Pytorch这样的开源项目。下面我们就说一说如何成…...

Threads and QObjects
QThread inherits QObject. It emits signals to indicate that the thread started or finished executing, and provides a few slots as well. QThread 派生于 QObject。QThread 会发射信号通知线程启动或终止执行任务,并且也会提供槽函数使用。 More interest…...

Tcp是怎样进行可靠准确的传输数据包的?
概述 很多时候,我们都在说Tcp协议,Tcp协议解决了什么问题,在实际工作中有什么具体的意义,想到了这些我想你的技术会更有所提升,Tcp协议是程序员编程中的最重要的一块基石,Tcp是怎样进行可靠准确的传输数据…...
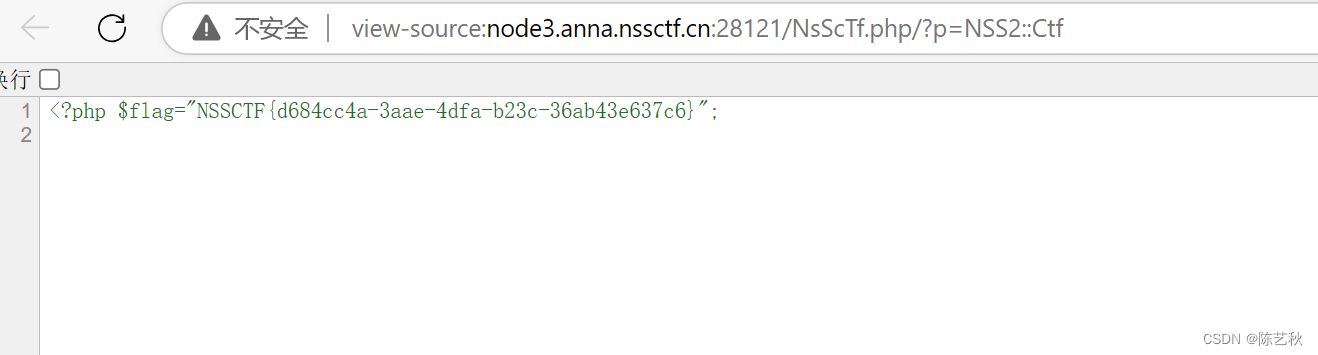
[SWPUCTF 2022 新生赛]numgame
这道题有点东西网页一段计算框,只有加和减数字,但是永远到大不了20,页面也没啥特别的,准备看源码,但是打不开,我以为是环境坏掉了,看wp别人也这样,只不过大佬的开发者工具可以打开&a…...

java异常机制分析
java异常机制分析 本文实例分析了java的异常机制,分享给大家供大家参考。相信有助于大家提高大家Java程序异常处理能力。具体分析如下: 众所周知,java中的异常(Exception)机制很重要,程序难免会出错,异常机制可以捕获…...

浅谈Python中的内存管理 程序的内存布局
Python中的内存管理 Python 的内存管理是通过私有堆空间来实现的。这个私有堆内存中存储了所有 Python 对象和数据结构。Python 的解释器自身则拥有对堆空间的访问权,程序员不能直接访问这个私有堆,但可以通过解释器的 API 来进行某些操作。 以下是 Py…...

抖音图片怎么去水印?2026年在线去水印工具+方法盘点,总有一款适合你
开篇:为什么要去水印? 保存抖音图片时,总会遇到水印的困扰。这些水印包含抖音logo、发布者名称,有时还会有账号信息。对于自媒体创作者、内容整理者或普通用户来说,去除水印往往是必需的。本文将介绍当下最实用的抖音图…...

通过taotoken审计日志追溯api调用详情与安全分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken审计日志追溯API调用详情与安全分析 对于将大模型API集成到业务流程中的团队而言,API调用的可见性与可控性…...

告别答辩PPT焦虑:百考通AI智能生成,高效搞定毕业答辩全流程
毕业季悄然来临,随着毕业论文定稿,答辩PPT成了不少同学面临的下一个挑战。不懂设计、不会梳理逻辑、找不到合适的学术模板……许多同学花费大量时间在排版调整、修改打磨上,不仅效率低下,还常常做出结构混乱、风格不统一的PPT&…...

为AI编程助手构建安全防线:Cursor自定义规则实战指南
1. 项目概述:为AI编程助手装上“安全护栏” 如果你和我一样,深度使用Cursor这类AI编程助手,那你一定体验过它带来的效率革命。它能帮你生成代码、重构函数、甚至解释复杂的逻辑,就像一个不知疲倦的编程伙伴。但硬币总有另一面——…...

Helm-Intellisense:VS Code智能补全插件,提升values.yaml编写效率
1. 项目概述:为什么我们需要一个Helm智能补全工具?如果你和我一样,日常工作中大量使用Helm来管理Kubernetes应用,那你一定对编写values.yaml文件时那种“盲人摸象”的感觉深有体会。面对一个动辄几十上百行配置的Helm Chart&#…...
TransPrompt:结构化提示词工程,提升LLM应用开发效率
1. 项目概述:当提示词工程遇上结构化工具最近在折腾大语言模型应用开发的朋友,估计都绕不开一个核心痛点:如何高效、稳定地管理那些越来越复杂、越来越长的提示词(Prompt)。直接写在代码里?改起来麻烦&…...

构建个人技能图谱:从结构化设计到自动化可视化的实践指南
1. 项目概述:一个技能图谱的诞生最近在GitHub上看到一个挺有意思的项目,叫dortort/skills。初看这个仓库名,你可能会有点懵,dortort是作者,那skills是什么?点进去一看,发现它不是一个具体的工具…...

工控一体机电脑核心性能特征解析:从选型到部署的实战指南
1. 项目概述:为什么我们需要重新审视工控一体机电脑?在工业自动化、智能制造、智慧零售乃至边缘计算这些听起来高大上的领域里,有一类设备常常是幕后的“无名英雄”,它不像机器人手臂那样引人注目,也不像云端服务器那样…...

AI代码管理器:统一多模型编程助手,提升开发效率与代码质量
1. 项目概述:一个面向开发者的多模型代码管理技能最近在折腾AI编程助手,发现一个挺有意思的现象:很多开发者手头可能同时用着Claude、CodeGemini这类工具,但每次切换都得重新配置环境、调整提示词,甚至要处理不同模型输…...

Minecraft物品堆叠架构深度解析:突破64限制的技术实现方案
Minecraft物品堆叠架构深度解析:突破64限制的技术实现方案 【免费下载链接】UltimateStack A Minecraft mod,can modify ur item MaxStackSize (more then 64) 项目地址: https://gitcode.com/gh_mirrors/ul/UltimateStack 在Minecraft模组开发领域…...