双向带头循环链表+OJ题讲解
💓博主个人主页:不是笨小孩👀
⏩专栏分类:数据结构与算法👀 刷题专栏👀 C语言👀
🚚代码仓库:笨小孩的代码库👀
⏩社区:不是笨小孩👀
🌹欢迎大家三连关注,一起学习,一起进步!!💓

复杂链表+OJ
- 链表的分类
- 带头双向循环链表的实现
- 结构
- 接口有哪些呢?
- 初始化
- 打印链表
- 尾插
- 头插
- 尾删
- 头删
- 查找
- 在pos前面插入
- 删除pos位置的数据
- 销毁链表
- 链表和顺序表的区别
- 用随机指针复制列表
链表的分类
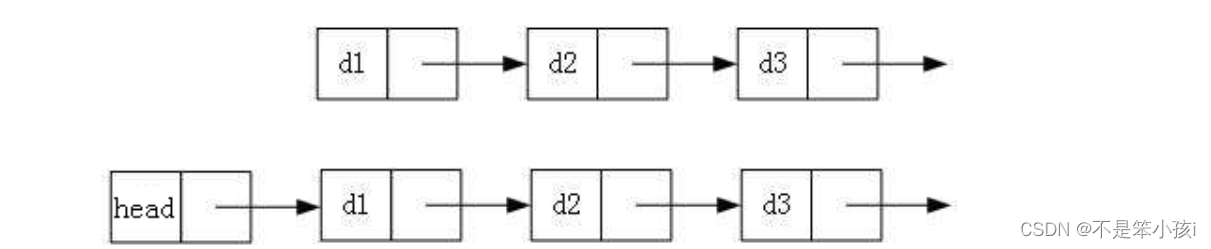
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1.单向or双向
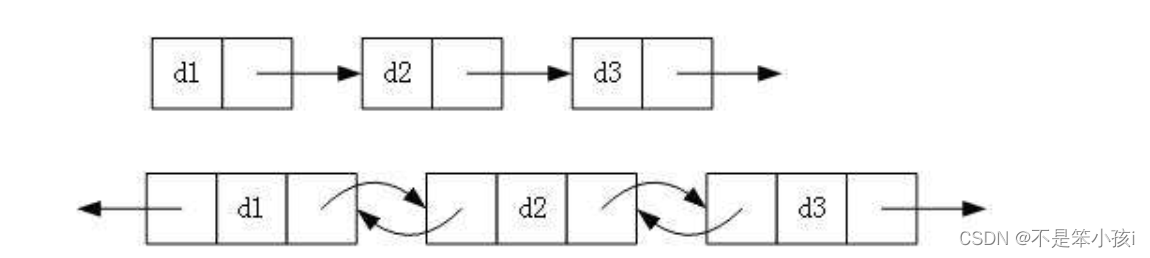
2.带头or不带头(哨兵位头结点)
3.循环or不循环
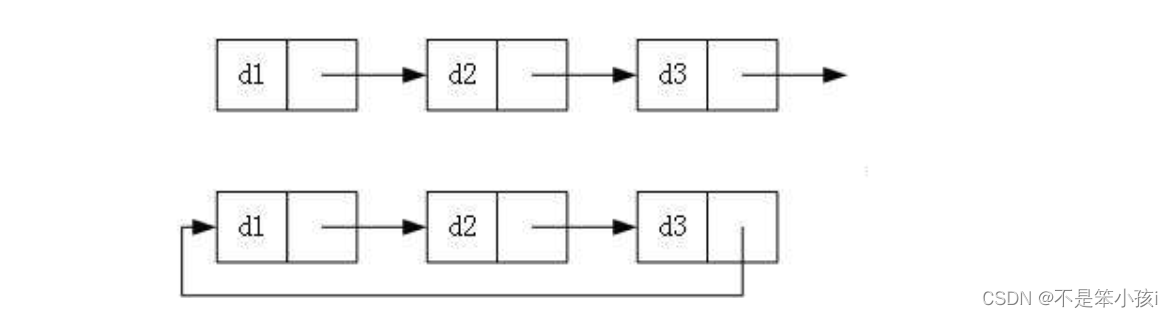
它们组合起来一共有8种结构,虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
1.无头单向非循环链表

这个链表我们前面已经讲过了,想详细了解的可以去看单链表详解。
2.带头双向循环链表

这个是我们本章节的重点,下面细讲。
总结:
1.无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结
构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2.带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都
是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带
来很多优势,实现反而简单了,后面我们代码实现了就知道了。
带头双向循环链表的实现
结构
既然是双向,那么这个结构体种就需要两个指针,一个用来存储下一个节点的指针,一个用来存储上一个节点的指针。
typedef int LTDateType;typedef struct ListNode
{//存储数据LTDateType date;//保存下一个节点的地址struct ListNode* next;//保存上一个节点的地址struct ListNode* prev;
}ListNode;接口有哪些呢?
// 创建返回链表的头结点.(初始化)
ListNode* ListCreate();// 双向链表销毁
void ListDestory(ListNode* pHead);// 双向链表打印
void ListPrint(ListNode* pHead);// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDateType x);// 双向链表尾删
void ListPopBack(ListNode* pHead);// 双向链表头插
void ListPushFront(ListNode* pHead, LTDateType x);// 双向链表头删
void ListPopFront(ListNode* pHead);// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDateType x);// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDateType x);// 双向链表删除pos位置的节点
void ListErase(ListNode* pos);
接下来我们来一一实现:
初始化
我们这里讲的是带头双向循环链表,所以我们在初始化的时候由于只有一个哨兵位头结点,所以我们直接让他的next和prev先指向自己,里面的数据可以是任何数。
// 创建返回链表的头结点.
ListNode* ListCreate()
{ListNode* node = (ListNode*)malloc(sizeof(ListNode));//判断是否开辟成功if (node == NULL){perror("malloc fail");exit(-1);}//初始化node->next = node;node->prev = node;node->date = 0;return node;
}
打印链表
打印链表很简单只需要遍历链表就可以了,但是这里的头结点是哨兵位不需要遍历,所以我们从phead的next开始,由于他是循环的,所以到phead结束。
// 双向链表打印
void ListPrint(ListNode* pHead)
{assert(pHead);ListNode* cur = pHead->next;while (cur != pHead){printf("%d->", cur->date);cur = cur->next;}printf("\n");
}
尾插
由于插入数据我们都需要开辟新的节点,所以我们下一个函数专门来创建节点:
ListNode* BuyListNode(int x)
{ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if (newnode == NULL){perror("malloc fail");exit(-1);}//节点里面的指针可以初始化为NULL,因为他们暂时无任何指向。newnode->date = x;newnode->next = NULL;newnode->prev = NULL;return newnode;
}
有了节点以后,我们可以利用pHead的prev找到尾,并保存在tail中,然后开始改变链接关系,让tail->next指向newnode,newnode->prev指向tail,然后将pHead->prev指向newnode,newnode->next指向pHead。在没有节点的情况下同样使用,这就体现了结构的优势。
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDateType x)
{assert(pHead);ListNode* newnode = BuyListNode(x);ListNode* tail = pHead->prev;tail->next = newnode;newnode->next = pHead;pHead->prev = newnode;newnode->prev = tail;
}
头插
头插同样需要新的节点,有了新的节点以后,我们保存pHead->next到first中去,然后改变链接关系,将first->prev指向newnode,将newnode->next指向first,将newnode的prev指向pHead,将pHead的next指向newnode。
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDateType x)
{assert(pHead);ListNode* newnode = BuyListNode(x);newnode->prev = pHead;newnode->next = pHead->next;pHead->next->prev = newnode;pHead->next = newnode;
}
尾删
尾删我们可以先保存一下尾节点,在保存尾节点的前一个节点,然后释放尾节点,在改变链接关系,将新的尾节点的next指向pHead,将pHead的prev指向新的尾。
// 双向链表尾删
void ListPopBack(ListNode* pHead)
{assert(pHead);//链表为空就别删了assert(pHead->next != pHead);//保存尾节点ListNode* tail = pHead->prev;//保存尾节点的前一个节点ListNode* tailPrev = tail->prev;//释放尾节点free(tail);//改变链接关系tailPrev->next = pHead;pHead->prev = tailPrev;
}
头删
我们保存第一个节点,也就是pHead->next到first中去,然后改变链接关系,将pHead->next改为first->next,然后将first后面的一个节点的prev,也就是first->next->prev改为pHead,然后释放first即可。
// 双向链表头删
void ListPopFront(ListNode* pHead)
{assert(pHead);assert(pHead->next != pHead);ListNode* first = pHead->next;pHead->next = first->next;first->next->prev = pHead;free(first);
}查找
查找和打印的方法一样遍历链表,找到就返回该节点,找不到返回NULL。
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDateType x)
{ListNode* cur = pHead->next;while (cur != pHead){if (cur->date == x){return cur;}cur = cur->next;}return NULL;
}
在pos前面插入
我们可以先保存pos前面的的节点到posPrev中去,在开辟一个新的节点,然后改变链接关系,将posPrev->next改为newnode,然后将newnode->prev指向posPrev,然后将newnode->next指向pos,最后将pos->prev指向newnode即可。
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDateType x)
{assert(pos);ListNode* posPrev = pos->prev;ListNode* newnode = BuyListNode(x);posPrev->next = newnode;newnode->prev = posPrev;newnode->next = pos;pos->prev = newnode;
}
删除pos位置的数据
删除就更简单了,只需要将pos前一个节点的next指向pos的next,将pos的下一个节点的prev指向pos的prev,然后释放pos即可。
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos)
{assert(pos);pos->prev->next = pos->next;pos->next->prev = pos->prev;free(pos);
}
销毁链表
遍历链表,依次销毁,最后销毁头即可。
// 双向链表销毁
void ListDestory(ListNode* pHead)
{ListNode* cur = pHead->next;while (cur != pHead){ListNode* del = cur;cur = cur->next;free(del);}free(pHead);
}双向带头循环链表到这里基本上就讲完了,它的结构复杂,但是代码写起来比起单链表还是非常简单的,接下来我们来比较一下链表和顺序表的区别。
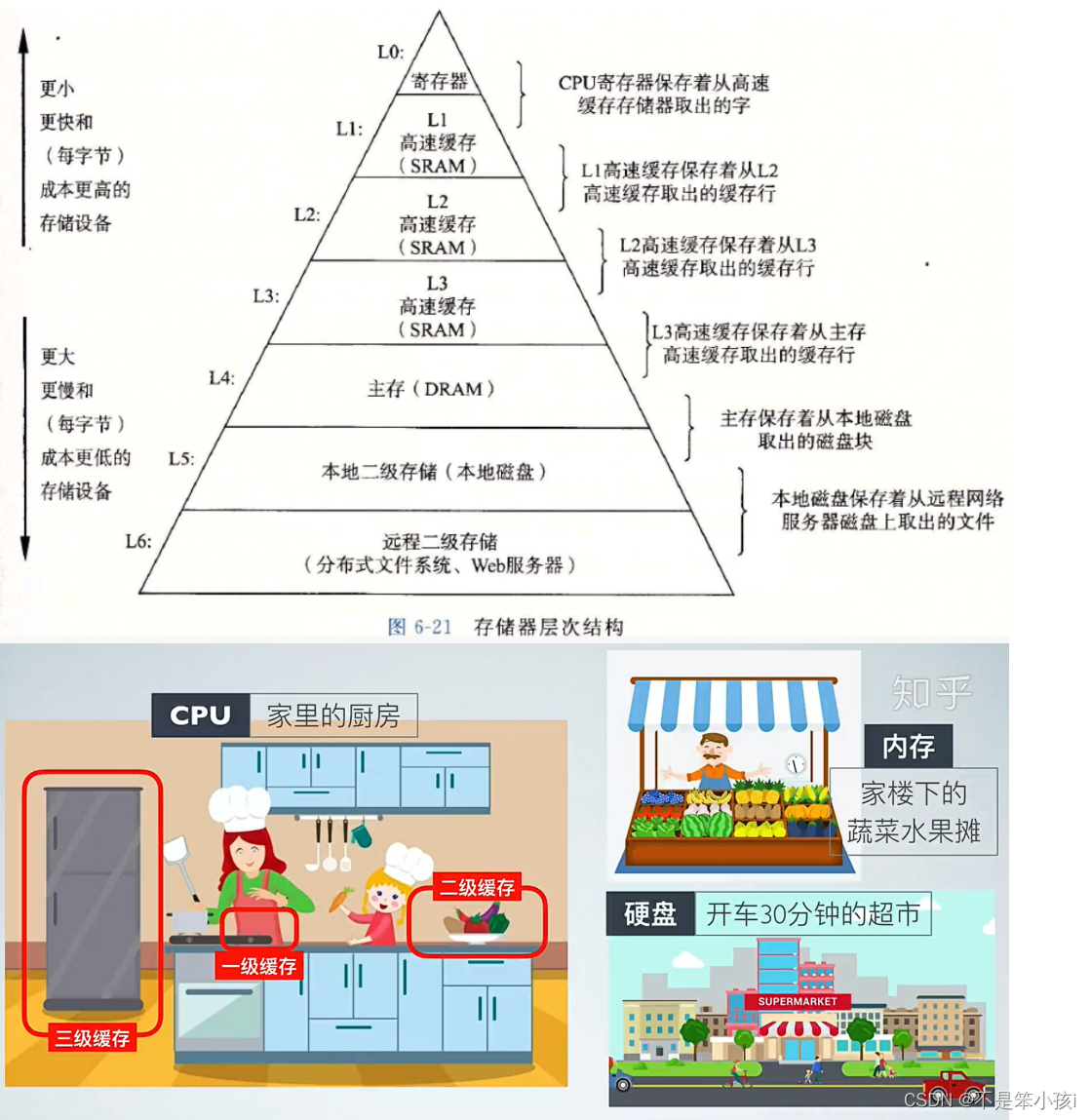
链表和顺序表的区别
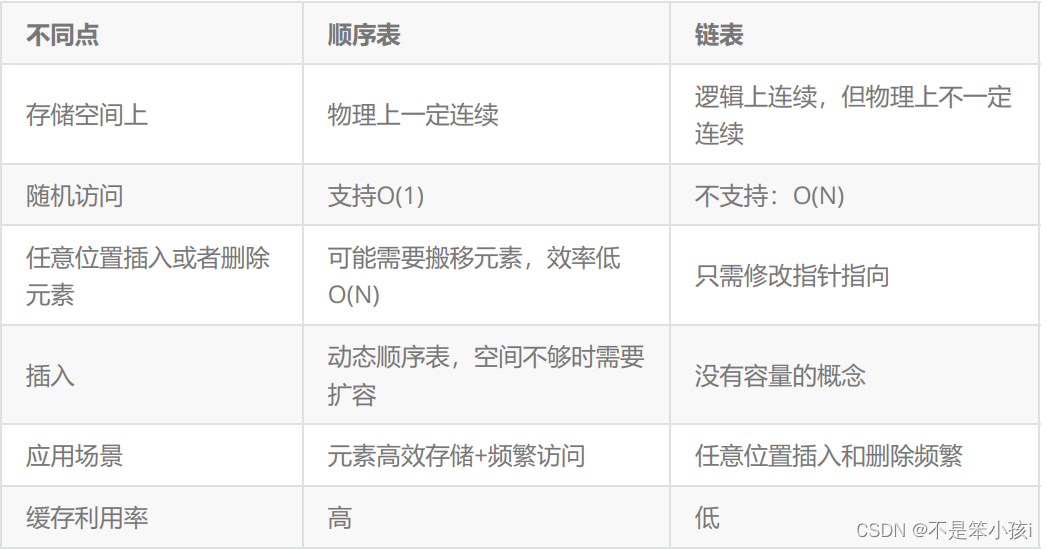
下图是缓存的一些知识:
用随机指针复制列表
如果我们单纯的拷贝一个链表,那非常简单,只需要遍历原链表,在遍历的同时开辟新的节点,存储原链表的值,然后将新的节点尾插起来就可以了。
但是这个题目出除了需要拷贝这个以外,每个结构中还有一个random指针,他们在原链表中指向原链表的任意节点或者空,我们还要拷贝这个,但是问题是我们在新的链表中无法找到原链表中random所对应的新的链表中的地址,所以我们原链表中找random的同时,还有在新的链表中找对应的random,这是比较麻烦的,而且时间复杂度是O(N^2),效率也低。
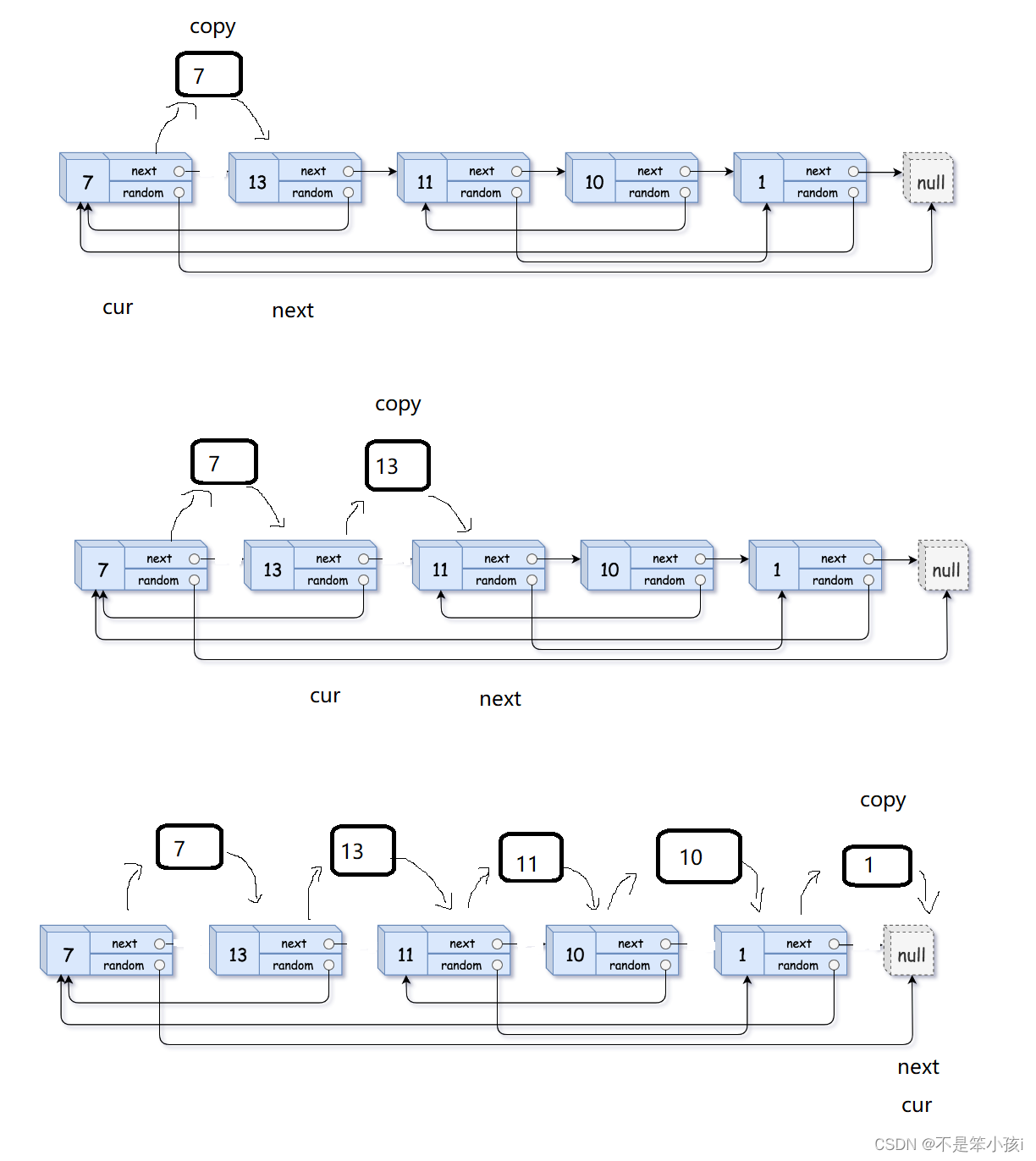
这里我们还有另外一个方法,就是我们先将每个节点都拷贝一份,放个拷贝的节点放在对应节点的后面,将他们重新链接起来,我们的问题就是找不到random对应的节点的地址,这样我们的节点的next即使random对应节点的地址,然后我们将拷贝的链表摘下来,尾插起来形成新的链表,同时恢复原链表,这样就可以了,这样做时间复杂度是O(N),而且没有额外的空间损耗,是个非常厉害的思路。
第一步:
第二步;
改变拷贝链表的random的值,他就是原链表的random的next。
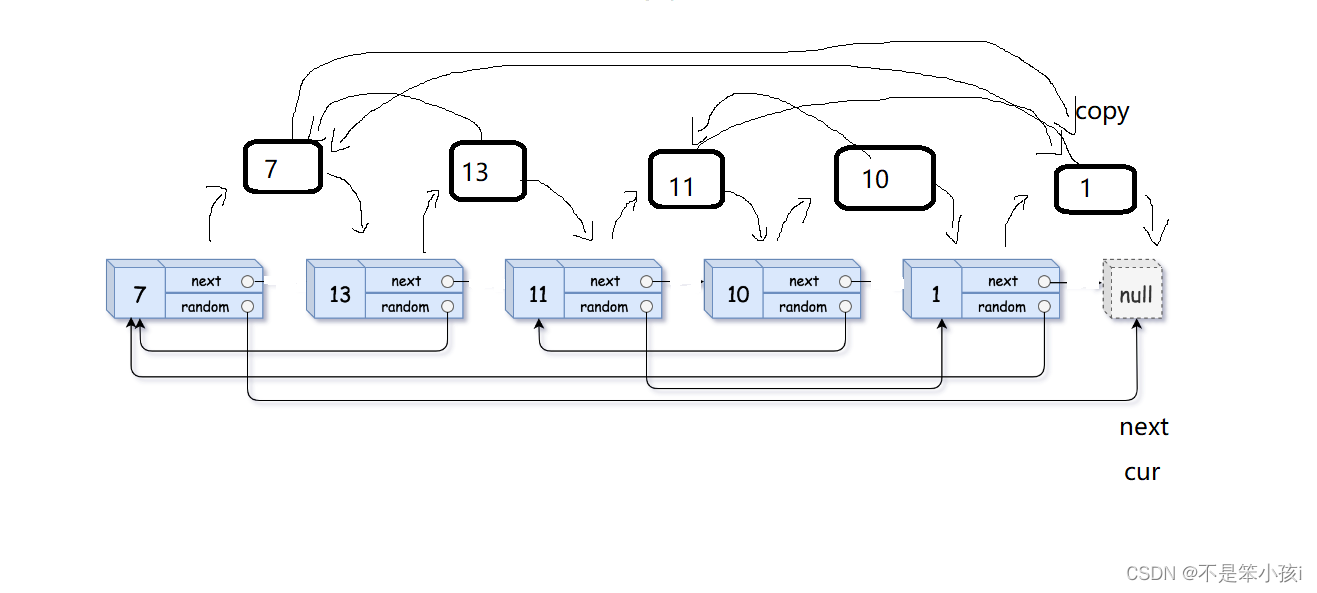
第三步
就是恢复链表,并且将拷贝的拿来尾插成新的链表。
代码如下:
struct Node* copyRandomList(struct Node* head)
{struct Node* cur = head;//第一步插入copywhile(cur){struct Node* next = cur->next;struct Node* copy = (struct Node*)malloc(sizeof(struct Node));//拷贝copy->val = cur->val;//改变链接关系cur->next = copy;copy->next = next;//cur迭代cur = copy->next;}cur = head;//第二步,改变copy的randomwhile(cur){struct Node* copy = cur->next;if(cur->random==NULL){copy->random=NULL;}else{copy->random = cur->random->next;}cur = copy->next;}//第三步 尾插并且恢复原链表cur = head;struct Node* copyhead = NULL,*copytail = NULL;while(cur){struct Node* copy = cur->next;struct Node* next = copy->next;//尾插copyif(copyhead==NULL){copyhead=copytail=copy;}else{copytail->next = copy;copytail = copytail->next;}//恢复原链表cur->next = next;cur = next; }return copyhead;
}
今天的分享就到这里,感谢大家的关注和支持。
相关文章:
双向带头循环链表+OJ题讲解
💓博主个人主页:不是笨小孩👀 ⏩专栏分类:数据结构与算法👀 刷题专栏👀 C语言👀 🚚代码仓库:笨小孩的代码库👀 ⏩社区:不是笨小孩👀 🌹欢迎大家三连关注&…...

电脑开不了机如何解锁BitLocker硬盘锁
事情从这里说起,不想看直接跳过 早上闲着无聊,闲着没事干,将win11的用户名称改成了含有中文字符的用户名,然后恐怖的事情发生了,蓝屏了… 然后就是蓝屏收集错误信息,重启,蓝屏收集错误信息&…...
Python Web开发 Jinja2模板引擎
在之前的文章中,简单介绍了Python Web开发框架Flask,知道了如何写个Hello World,但是距离用Flask开发真正的项目,还有段距离,现在我们目标更靠近一些 —— 学习下Jinja2模板。 模板的作用 模板是用来做什么的呢&…...
ubuntu上安装mosquitto服务
1、mosquitto是什么 Mosquitto 项目最初由 IBM 和 Eurotech 于 2013 年开发,后来于 2016 年捐赠给 Eclipse 基金会。Eclipse Mosquitto 基于 Eclipse 公共许可证(EPL/EDL license)发布,用户可以免费使用。作为全球使用最广的 MQTT 协议实现之一 &#x…...

嵌入式开发学习(STC51-9-led点阵)
内容 点亮一个点; 显示数字; 显示图像; LED点阵简介 LED 点阵是由发光二极管排列组成的显示器件 通常应用较多的是8 * 8点阵,然后使用多个8 * 8点阵可组成不同分辨率的LED点阵显示屏,比如16 * 16点阵可以使用4个8 *…...
用法简介并举例)
RedisTemplate.opsForZSet()用法简介并举例
RedisTemplate.opsForZSet()是RedisTemplate类提供的用于操作ZSet类型(有序集合)的方法。它可以用于对Redis中的ZSet数据结构进行各种操作,如添加成员、获取成员、删除成员等。 下面是一些常用的RedisTemplate.opsForZSet()方法及其用法示例…...

Java个人博客系统--基于Springboot的设计与实现
目录 一、项目概述 应用技术 接口实现: 数据库定义: 数据库建表: 博客表数据库相关操作: 添加项⽬公共模块 加密MD5 页面展示:http://121.41.168.121:8080/blog_login.html 项目源码:https://gitee…...
)
在jupyter中下载数据集失败及解决方法(以IMDB为例)
在IMDB数据集下载时,由于网络原因下载失败,报错如下: Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz ConnectionResetError Traceback (most recent call last) … Exception: URL fetch f…...

【设计模式】-工厂方法模式
工厂方法模式(Factory Method Pattern)是一种创建型设计模式,它通过定义一个用于创建对象的接口,但是将具体对象的创建推迟到子类中。这样,子类可以决定要实例化的对象类型。工厂方法模式提供了一种方式,通…...
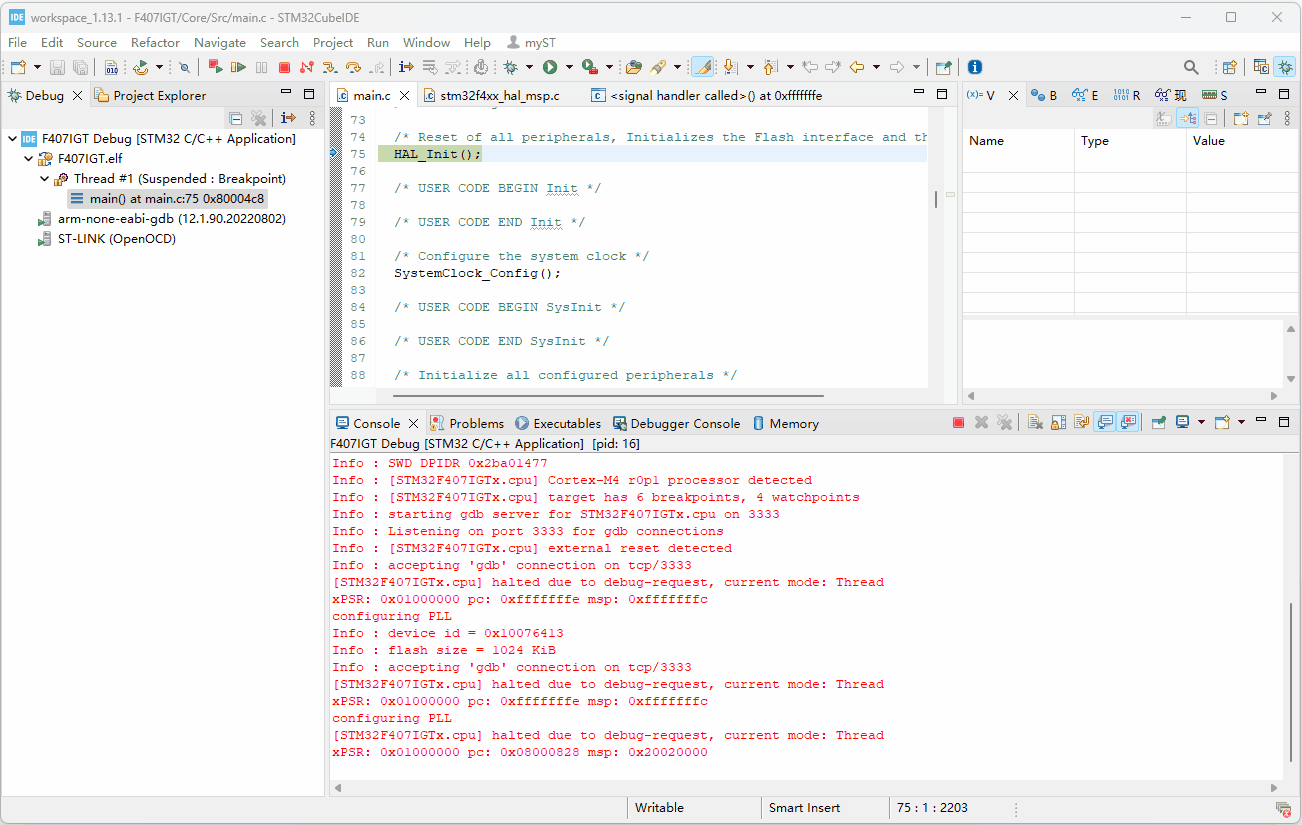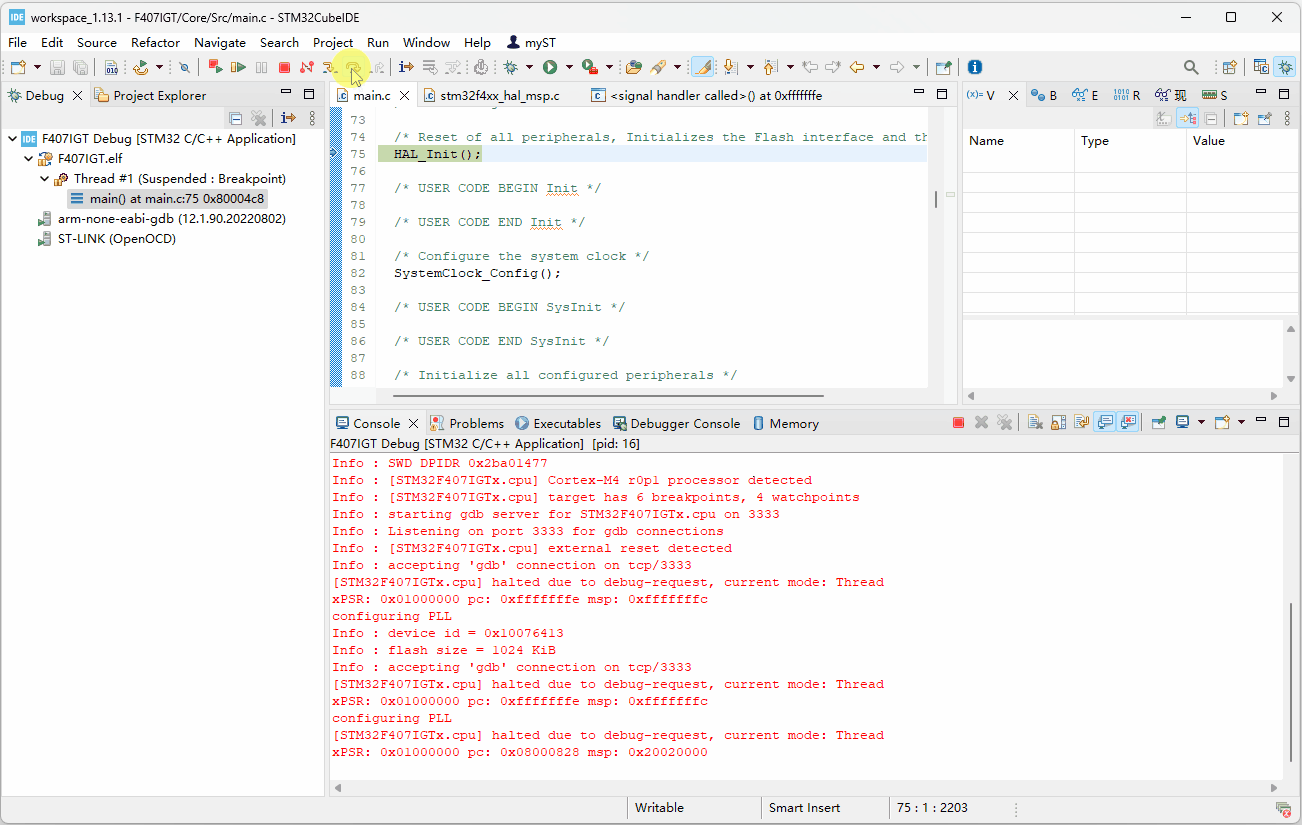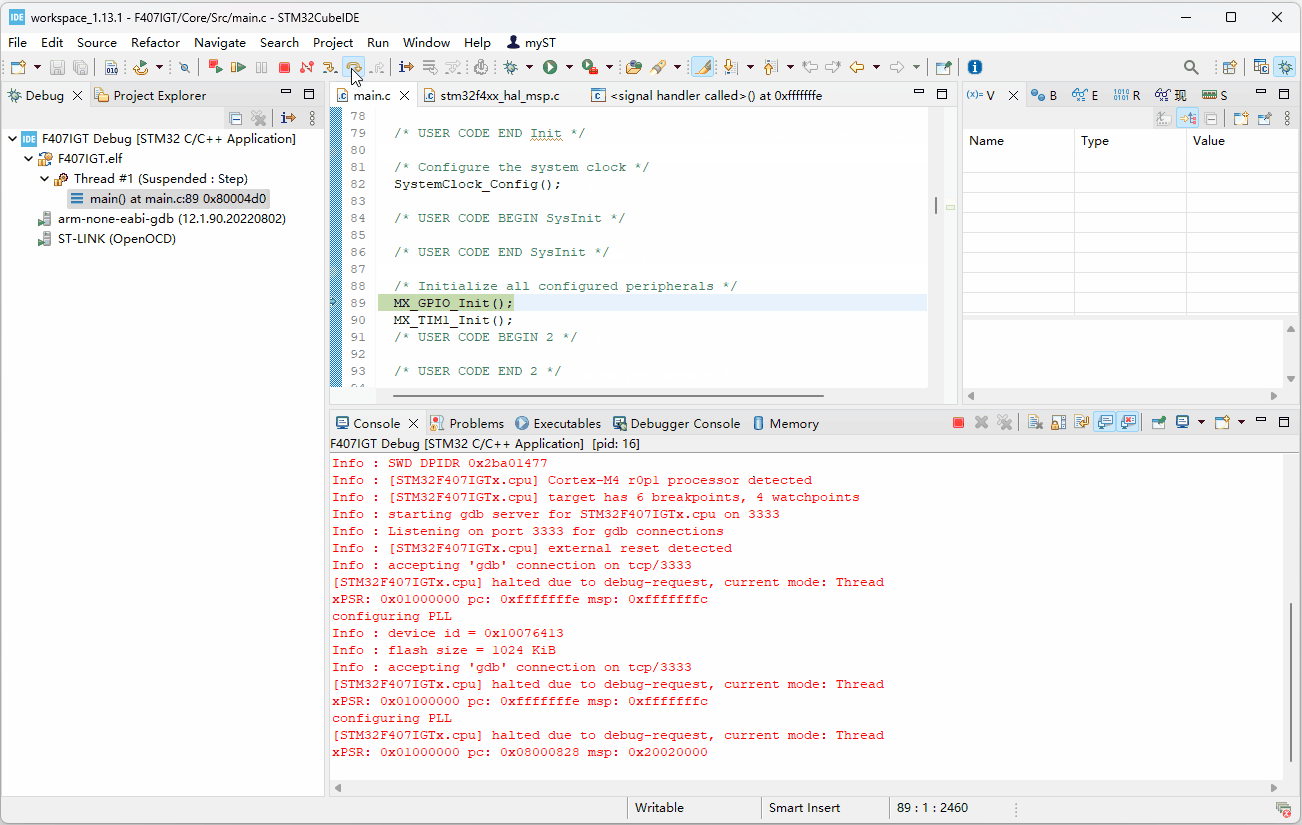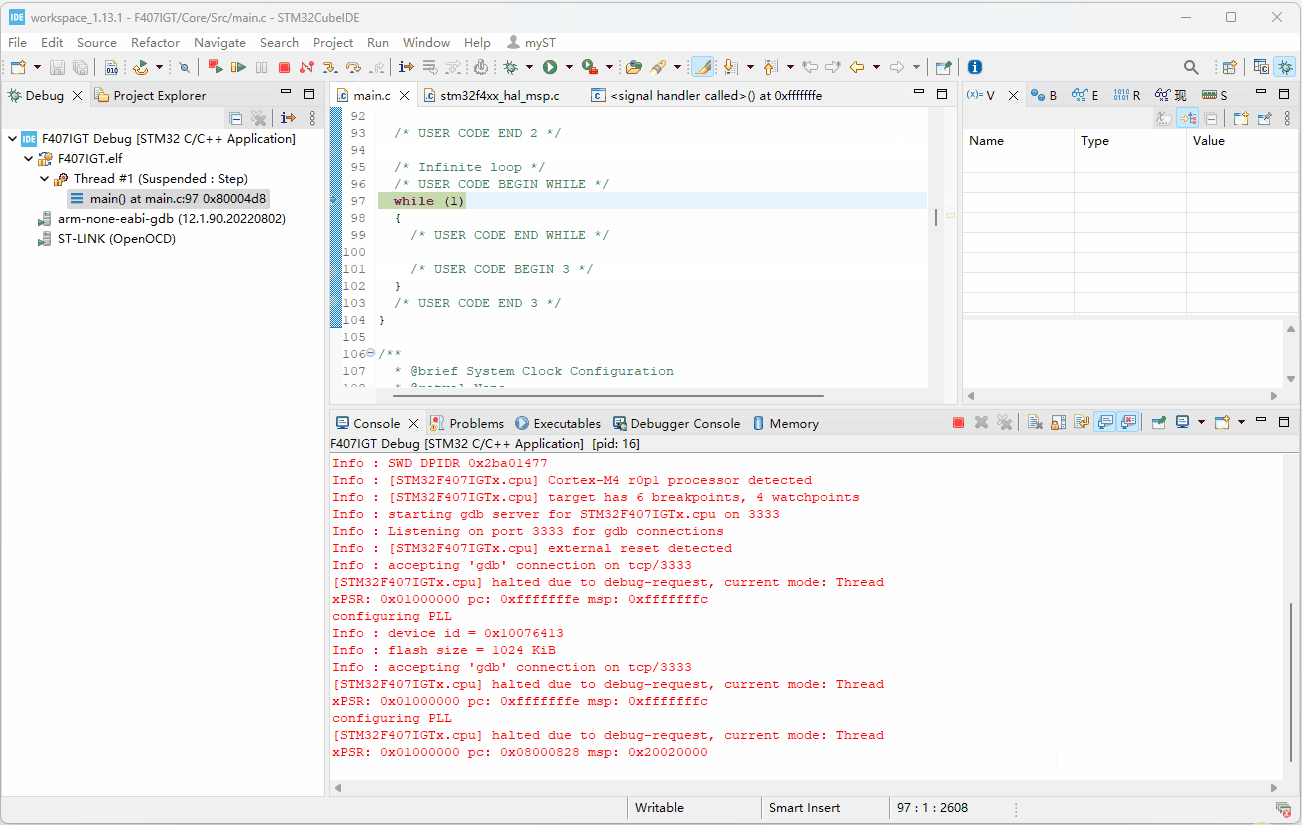
H7-TOOL的高速DAPLINK用于新版STM32CubeIDE V1.13及其以上版本的超简单实现方法(2023-08-08)
之前分享了一个方法,太繁琐了,H7-TOOL群的群友提供了一个方法,实现非常简单。1、使用STM32CubeMX或者自己创建一个STM32CubeIDE工程后,设置这两个地方即可: 配置调试器,设置完毕记得点击右下角的Apply 2、然…...
成功解决ubuntu-22.04的sudo apt-get update一直卡在【0% [Waiting for headers]】
成功解决ubuntu-22.04的sudo apt-get update一直卡在【0% [Waiting for headers]】 问题描述解决方案 问题描述 在下载安装包的时候一直卡在0% [Waiting for headers],报错信息如下: Get:1 file:/var/cudnn-local-repo-ubuntu1804-8.5.0.96 InRelease […...
:vue项目中的离线地图引入)
openLayers实战(一):vue项目中的离线地图引入
最近的项目涉及到离线地图的操作,查阅社区文章,决定使用openLayersvue离线地图的方式进行开发,前期基础引入操作完全参考掘金文章,非常优秀全面的文章。 openlayers 实战离线地图 - 掘金 此外,开发过程的地图操作可参考…...
如何构造一个安全的单例?
为什么要问这个问题? 我们知道,单例是一种很常用的设计模式,主要作用就是节省系统资源,让对象在服务器中只有一份。但是实际开发中可能有很多人压根没有写过单例这种模式,只是看过或者为了面试去写写demo熟悉一下。那…...

单片机开发 esp8266
一、固件界面 二、项目介绍 固件名称:esp8266-universalboard v1.0 提供商: 半条虫(466814195) 下载:esp8266-universalboard.bin 源码地址:Gitlab...

Linux 查看版本和用户权限提升实践心得
文章目录 linux (Ubuntu内核)查看版本版本信息解释内置yum工具?用户权限提升操作步骤 查看deepin系统的版本和其debian的版本遇到的问题:deepin-release文件不存在 linux (Ubuntu内核)查看版本 使用lsb_release命令: lsb_release -a该命令将…...
)
多线程编程5:线程同步和进程通信(C++11和linux)
常见的线程同步 linux: 互斥锁:实现共享资源的串行访问,有三个版本普通锁(默认属性),检错锁(可以防止相同线程重复加锁)和递归锁(相同线程可以重复加锁)条件变量:配合互斥锁使用,实现线程之间的通信&#…...

tensorrt官方int8量化方法汇总
原理及操作 量化的基本原理及流程可参看懂你的神经网络量化教程:第一讲、量化番外篇、TensorRT中的INT8、tensorRT int8量化示例代码 Tensorrt 方式1:trtexec(PTQ的一种) int8量化 trtexec --onnxXX.onnx --saveEnginemodel.…...
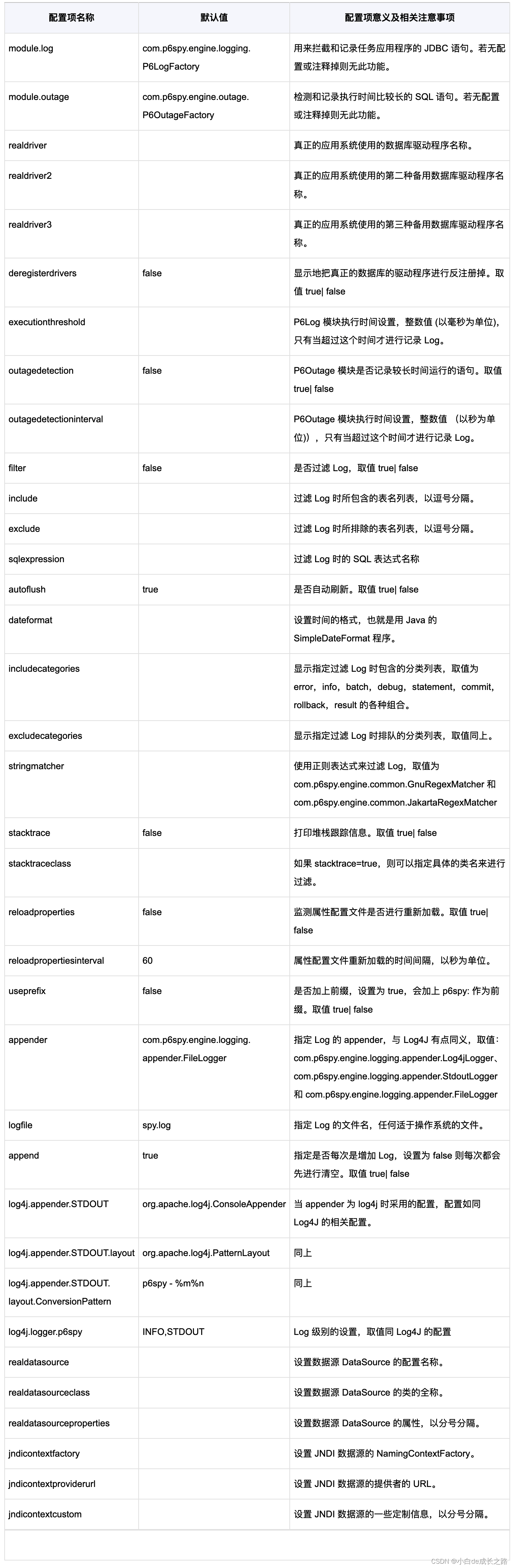
21、p6spy输出执行SQL日志
文章目录 1、背景2、简介3、接入3.1、 引入依赖3.2、修改database参数:3.3、 创建P6SpyLogger类,自定义日志格式3.4、添加spy.properties3.5、 输出样例 4、补充4.1、参数说明 1、背景 在开发的过程中,总希望方法执行完了可以看到完整是sql语…...
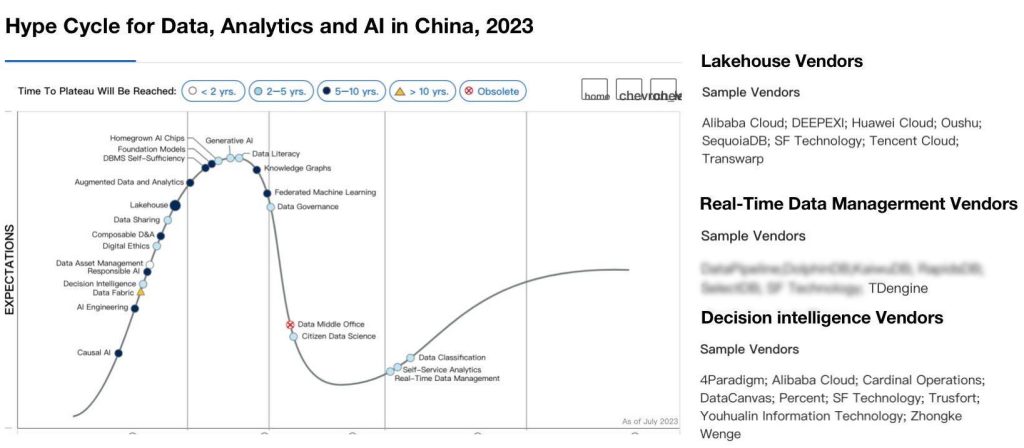
实力认证!TDengine 入选 Gartner 中国数据分析与人工智能技术成熟度曲线
近日,国际权威研究机构 Gartner 发布了《2023 年中国数据分析及人工智能技术成熟度曲线》(即《Hype Cycle for Data, Analytics and AI in China, 2023》)报告,TDengine 成功入选实时数据管理领域代表产品。 作为评估全球新技术成…...

如何将jar包部署到宝塔
尝试多种方式上传,但启动一直失败,这种方式亲测是好使的 项目内修改位置 在pom.xml文件中将mysql的scope改成provided,如果是固定的版本号会出现问题 之后就可以打包啦,直接点击maven中的package 找到打包文件的位置ÿ…...

杰理之主机插拔U盘,从机较高概率出现无声情况【篇】
switch节点初始丢数据时后续节点状态错误导致时间戳异常问题(对应rx无声)...

GPT5.5复杂任务拆解提示策略单次对话搞不定的活这样分
做多模型横向对比测试时常用的聚合平台推荐下:库拉KULAAI(c.877ai.cn),上面能直接调GPT-5.5和多个主流模型做复杂任务拆解能力对比。下面进入正题。复杂任务为什么让AI翻车用AI Agent干活一段时间后你一定遇到过这种情况。你让它一…...

零代码物联网实战:用WipperSnapper与Adafruit IO快速采集模拟与I2C传感器数据
1. 项目概述与核心价值在嵌入式开发和物联网项目的起步阶段,很多开发者,尤其是刚接触硬件的朋友,常常会卡在两个看似基础却至关重要的环节上:如何让微控制器“感知”到物理世界的连续变化,以及如何高效、可靠地读取那些…...

独立开发者如何利用Taotoken Token Plan套餐优化项目成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan套餐优化项目成本 对于独立开发者或小型项目团队而言,在拥抱大模型能力的同时&…...

Vue3企业级后台管理系统实战:如何用ant-design-vue3-admin高效构建现代化管理平台
Vue3企业级后台管理系统实战:如何用ant-design-vue3-admin高效构建现代化管理平台 【免费下载链接】ant-design-vue3-admin 一个基于 Vite2 Vue3 Typescript tsx Ant Design Vue 的后台管理系统模板,支持响应式布局,在 PC、平板和手机上均…...

科技与科学新闻摘要-2026年5月16日
科技与科学新闻摘要 日期: 2026年5月16日 科技领域重点新闻 1. 中国2025年度十大科学进展揭晓 核心要点: 中国科学技术部发布了2025年度十大科学进展,覆盖深空探测、人工智能、生命科学、能源技术等多个领域,集中展示了中国基础研究和应用研究的突破性…...

VScode界面突然变模糊?别急着换眼镜,先检查NVIDIA控制面板这个设置
VScode界面突然变模糊?三步精准定位显卡驱动的"视觉陷阱" 你是否曾在深夜赶代码时,突然发现VScode的界面变得像隔了层毛玻璃?文字边缘渗出光晕,图标轮廓开始"融化",仿佛显示器突然患上了散光。这种…...

SystemVerilog中logic数据类型:统一reg与wire的设计实践
1. 项目概述:从“reg”到“logic”的思维跃迁如果你写过Verilog,那么对reg和wire这两个数据类型一定再熟悉不过了。在RTL设计的世界里,我们习惯了用reg来描述寄存器,用wire来描述连线,这几乎成了一种肌肉记忆。但当你开…...
)
Midjourney碳素印相风格实战手册(胶片级颗粒+铁盐棕褐渐变+微裂纹纹理全还原)
更多请点击: https://intelliparadigm.com 第一章:碳素印相工艺的历史溯源与数字复刻价值 碳素印相(Carbon Printing)诞生于1864年,由英国科学家约瑟夫斯旺(Joseph Swan)发明,是摄影…...
)
告别密集计算:用SpConv稀疏卷积加速3D点云处理(附PyTorch代码示例)
告别密集计算:用SpConv稀疏卷积加速3D点云处理实战指南 在自动驾驶和机器人感知领域,LiDAR点云数据的处理一直是计算密集型任务的代表。传统3D卷积神经网络在处理这类数据时,往往需要消耗大量显存和计算资源,而实际上点云数据的有…...