【Pandas】学习笔记之groupby()、agg()、transform()
在数据分析过程中经常需要对数据集进行分组,并且统计均值,最大值等等。那么 groupby() 的学习就十分有必要了
groupby(): 分组
官方文档:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)
A groupby operation involves some combination of splitting the object, applying a function, and combining the results. This can be used to group large amounts of data and compute operations on these groups.
Parameters:
- by
- axis
- level
- as_index
- sort
- group_keys
- observed
- dropna
Returns:
DataFrameGroupBy , Returns a groupby object that contains information about the groups.
生成一个学生数据集,包含身高和成绩:
import pandas as pd
import numpy as npclasses = ["A", "B", "C"]student = pd.DataFrame({'class': [classes[x] for x in np.random.randint(0,len(classes),10)],'height': np.random.randint(150, 190, 10),'score': np.random.randint(50, 100, 10)})
按班级分组:
# 按班级分组
group = student.groupby('class')# pandas.core.groupby.generic.DataFrameGroupBy
type(group)
list(group) 的结果是:
Out[]:
[('A',class height score score_mean3 A 167 65 74.3333338 A 163 73 74.3333339 A 167 85 74.333333),('B',class height score score_mean1 B 175 76 59.6666676 B 151 53 59.6666677 B 185 50 59.666667),('C',class height score score_mean0 C 166 65 71.02 C 185 61 71.04 C 183 59 71.05 C 182 99 71.0)]
可以看到,groupby的过程将整个df按照指定的字段分为若干个子df
之后的agg、apply等操作都是对子df的操作
agg(): 聚合操作
常见的有:
- min最小值
- max最大值
- sum求和
- mean求均值
- count计数
- median中位数
- std标准差
- var方差
# 聚合操作之后的返回值类型为dataframe
a = student.groupby('class').agg('mean')
a = group.agg('mean')# 可以用字典来指定对不用的列求不同的值
b = student.groupby('class').agg({'score':'mean','height':'median'})
a:
Out[]: height score
class
A 165.666667 74.333333
B 170.333333 59.666667
C 179.000000 71.000000
b:
Out[26]: score height
class
A 74.333333 167.0
B 59.666667 175.0
C 71.000000 182.5
transform()
agg() 是返回统计的结果,返回值为df
transform() 对每一条数据进行处理, 相同组有相同的结果, 组内求完均值后会按照原索引的顺序返回结果
返回series
如果要在student上加一列学生所在班级的平均分
不使用transform需要两步:
# 1.先得到班级平均值的dict
avg_score_dict = student.groupby('class')['score'].mean().to_dict()
# 2.再对每个学生根据班级map一下
student['score_mean'] = student['class'].map(avg_score_dict)
使用transform只需要一步:
student['score_mean'] = student.groupby('class')['score'].transform('mean')
apply():
能够传入任意自定义的函数,实现复杂的数据操作
注意:
- groupby后的apply,以分组后的子DataFrame作为参数传入指定函数的,基本操作单位是DataFrame,而之前介绍的apply的基本操作单位是Series
- apply拥有更大的灵活性,但运行效率会比agg和transform更慢
假设我需要获取每个班分数最高的学生的数据:
# 获取分数最高的学生
def get_highest_student(x):df = x.sort_values(by='score', ascending=False)return df.iloc[0, :]highest_student = student.groupby('class', as_index=False).apply(get_highest_student)
相关文章:
【Pandas】学习笔记之groupby()、agg()、transform()
在数据分析过程中经常需要对数据集进行分组,并且统计均值,最大值等等。那么 groupby() 的学习就十分有必要了 groupby(): 分组 官方文档: DataFrame.groupby(byNone, axis0, levelNone, as_indexTrue, sortTrue, group_keysTrue, observedF…...

使用正则表达式 移除 HTML 标签后得到字符串
需求分析 后台返回的数据是 这样式的 需要讲html 标签替换 high_light_text: "<span stylecolor:red>OPPO</span> <span stylecolor:red>OPPO</span> 白色 01"使用正则表达式 function stripHTMLTags(htmlString) {return htmlString.rep…...
Java中String方法魔性学习
这里写目录标题 先进行专栏介绍String详解常用构造方法代码演示常用成员方法代码示例总结 先进行专栏介绍 本专栏是自己学Java的旅途,纯手敲的代码,自己跟着黑马课程学习的,并加入一些自己的理解,对代码和笔记 进行适当修改。希望…...
Smartbi 权限绕过漏洞复现(QVD-2023-17461)
0x01 产品简介 Smartbi大数据分析产品融合BI定义的所有阶段,对接各种业务数据库、数据仓库和大数据分析平台,进行加工处理、分析挖掘和可视化展现;满足所有用户的各种数据分析应用需求,如大数据分析、可视化分析、探索式分析、复杂…...

springboot自定义错误消息
为了提供自定义错误消息提示,springboot在resources目录下,有一个文件ValidationMessages.properties 用于存储 验证错误的消息提示: 比如: 这样一个ValidationMessage.properties username.notempty用户名不能为空 username.len…...
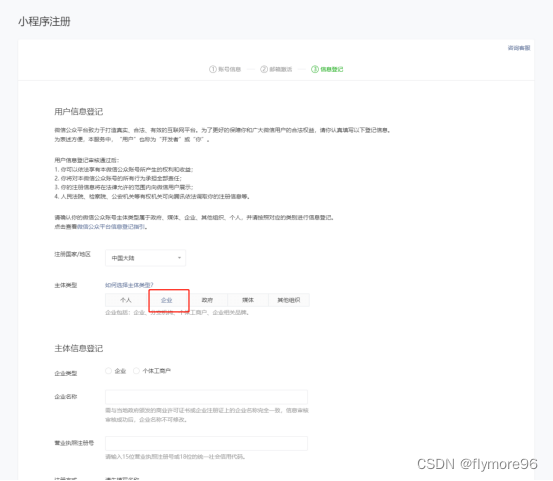
微信小程序申请步骤
微信公众平台链接:https://mp.weixin.qq.com/ 1、进到微信公众平台,点一下“点击注册”,挑选账号申请种类“小程序”,填好微信小程序用户信息,包含电子邮箱、登陆密码等。 2、微信公众平台会发送一封电子邮件…...

嘉楠勘智k230开发板上手记录(四)--HHB神经网络模型部署工具
按照K230_AI实战_HHB神经网络模型部署工具.md,HHB文档,RISC-V 编译器和模拟器安装来 一、环境 1. 拉取docker 镜像然后创建docker容器并进入容器 docker pull hhb4tools/hhb:2.4.5 docker run -itd --namehhb2_4 -p 22 "hhb4tools/hhb:2.4.5"…...
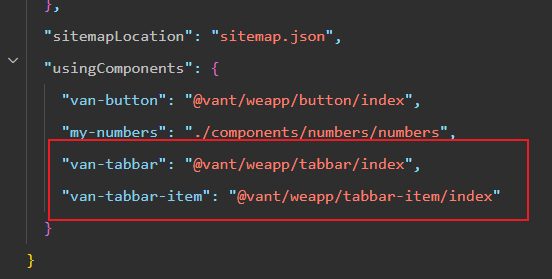
微信小程序的自定义TabBar及Vant的使用
一、安装Vant 1、在 资源管理器 空白位置,点右键打开 在外部终端窗口打开 2、初始化NPM npm init -y 3、安装命令 npm i vant/weapp1.3.3 -S --production 4、构建NPM包 在 工具 里选择构建NPM包 5、删除style:v2 在app.json里,删除"style"…...
canvas实现代码雨
学习抖音: 渡一前端必修课 效果图: 全部代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge">&…...
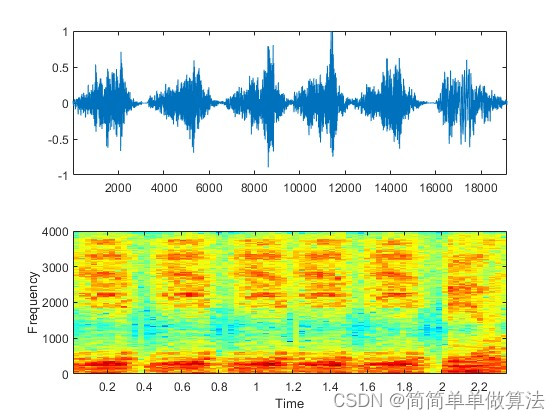
基于MFCC特征提取和HMM模型的语音合成算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022A 3.部分核心程序 ............................................................................ %hmm是已经…...

多重网格算法的cuda编程
这里写自定义目录标题 多重网格算法介绍问题描述——五点差分法求解二维泊松方程五点差分法Gauss迭代算法限制算子介绍提升算子二重网格算法多重网格算法多重网格cuda代码编写串行代码mg.c两重网格cuda并行代码jacobi迭代的cuda编程device_jacobiMakefilecuda_mg.cucuda_mg.hma…...
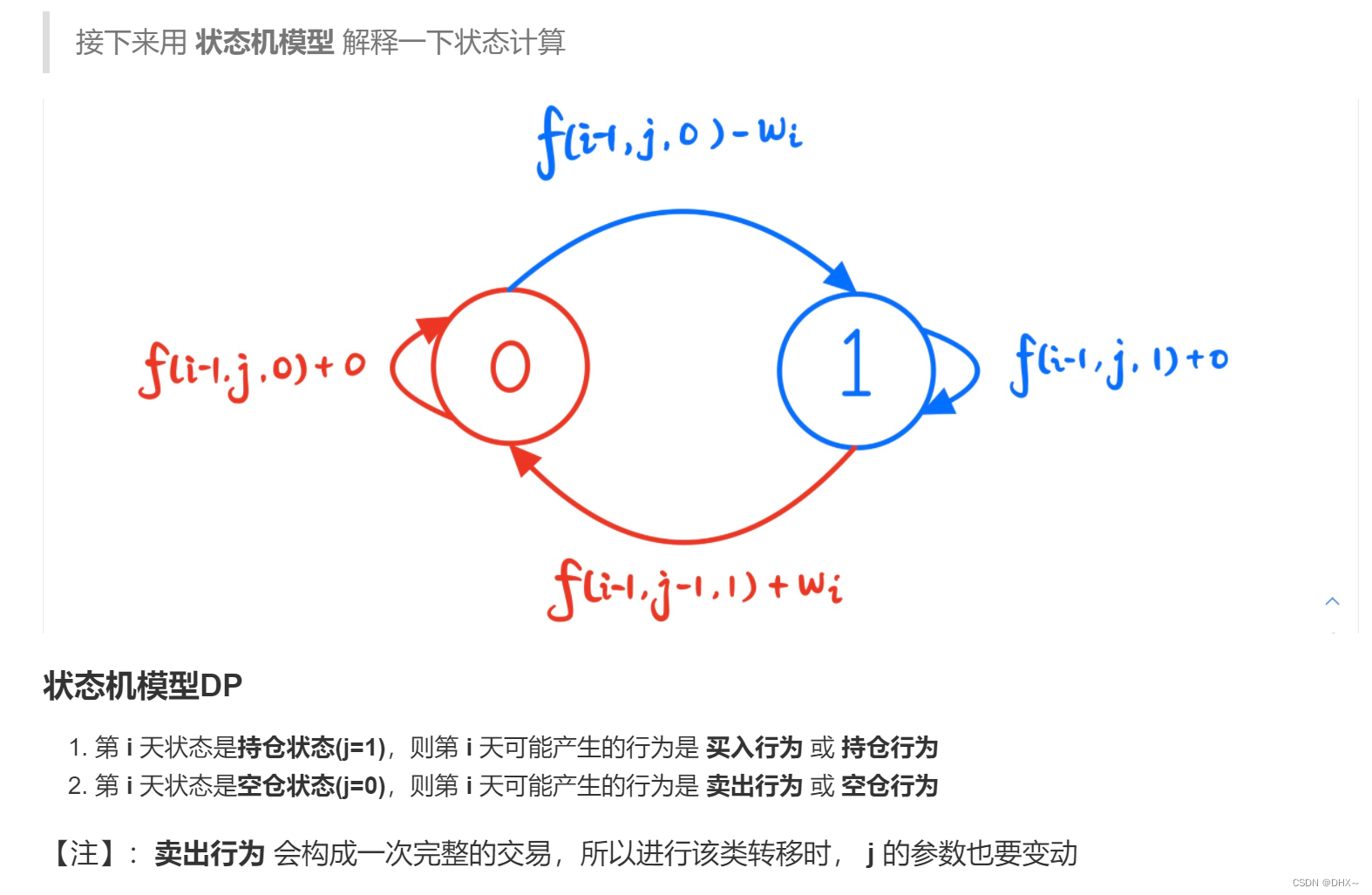
DP(状态机模型)
大盗阿福 阿福是一名经验丰富的大盗。趁着月黑风高,阿福打算今晚洗劫一条街上的店铺。 这条街上一共有 N 家店铺,每家店中都有一些现金。 阿福事先调查得知,只有当他同时洗劫了两家相邻的店铺时,街上的报警系统才会启动&#x…...

按照指定的文件顺序进行scp传输
前言 scp 默认传输顺序是按照文件名进行排序的, 但我当前工作中遇到要验证两台机器的神经网络层的精度,需要把网络层的输入输出(假设有100层, 一共64G) 从机器1传输到机器2 , 然后进行对比;这种情况下最好…...

小红书数据分析丨现实版模拟人生,这届网友热衷于“云开店”?
近期,小红书出现的一个神秘的热心群体,他们经常活跃在各种小店店主发布的求助帖评论区中,积极地帮助店主出谋划策,寻找小店经营的优化之道,成功帮助小店成功转亏为盈!江湖人称一一云股东。小红书话题#爱上帮…...

休闲卤味强势崛起:卤味零食成为新一代热门美食
随着人们生活水平的提高和消费观念的转变,休闲卤味逐渐成为了人们日常生活中的热门美食。据最新数据显示,2022年,我国卤味市场销售额达到了约2000亿元,预计到2025年将突破3000亿元大关。其中,休闲卤味以每年10%的速度持…...

自除数-C语言
描述 给定两个整数 left 和 right ,返回一个列表,列表的元素是范围 [left, right] 内所有的 自除数。 1 < left < right < 104 自除数 是指可以被它包含的每一位数整除的数,自除数 不允许包含 0 。例如,128 是一个 自除…...
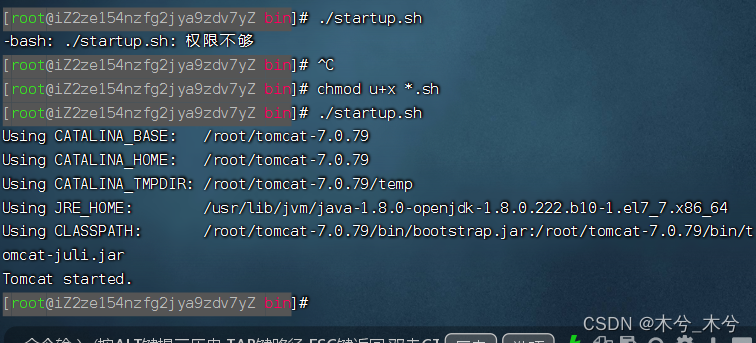
-bash: ./startup.sh: Permission denied解决
今天在Linux上启动Tomcat,结果弹出:-bash: ./startup.sh: Permission denied 的提示。 这是因为用户没有权限,而导致无法执行。用命令chmod 修改一下bin目录下的.sh权限就可以了。 在Tomcat的bin目录下 ,输入命令行 :c…...
Java课题笔记~ AOP 概述
AOP 简介 AOP(Aspect Orient Programming)面向切面编程。 面向切面编程是从动态角度考虑程序运行过程。 AOP的底层,就是采用动态代理的方式实现的。 采用了两种代理:JDK动态代理、CGLIB动态代理。 JDK动态代理:使…...
真我V3 5G(RMX2200 RMX2201)解锁刷机全过程
安卓系统新Rom包为GSI,更具有通用性,可以比较放心刷。 原厂系统垃圾多、广告多,甚至热点功能不支持ipv6,严重偏离热点机的定位。 主要参考 https://www.bilibili.com/read/cv20730877/https://www.bilibili.com/read/cv2073087…...

springCache-缓存
SpringCache 简介:是一个框架,实现了基于注解的缓存功能,底层可以切换不同的cache的实现,具体是通过CacheManager接口实现 使用springcache,根据实现的缓存技术,如使用的redis,需要导入redis的依赖包 基于map缓存 …...

设计型vs工程型 宁波景区标识服务商怎么选不踩坑
宁波某4A景区标识升级踩坑案例:3类适配性问题汇总前段时间宁波一家本土4A自然景区完成标识系统升级,不料上线3个月就收到近百条游客投诉,运营方不得不二次招标重做,前后浪费近百万预算。复盘整个项目,核心暴露了3类行业…...

嵌入式GUI性能优化实战:LVGL贝塞尔曲线绘制中的定点数与移位运算避坑指南
嵌入式GUI性能优化实战:LVGL贝塞尔曲线绘制中的定点数与移位运算避坑指南 在嵌入式系统开发中,流畅的图形用户界面(GUI)往往需要面对资源受限的硬件环境。当我们在STM32或ESP32这类微控制器上实现复杂的动画效果时,贝塞尔曲线因其平滑的过渡…...

别再手动转换时间了!用Jackson和Spring的这两个注解,搞定Java日期序列化所有坑
彻底告别Java日期转换噩梦:Jackson与Spring注解实战指南 如果你曾在Java项目中处理过日期时间转换,一定对以下场景不陌生:前端传过来的字符串日期需要手动解析成Date对象,返回给前端的日期格式乱七八糟,时区问题导致时…...

QiWe 免费开源微信机器人:从零到一的完整开发与部署指南
1. 为什么选择 QiWe 开源框架? 在私域流量运营和社群智能化的浪潮中,微信机器人早已成为降本增效的利器。然而,市面上许多闭源方案不仅收费高昂,还存在严重的数据泄露风险。QiWe 作为一款优秀的免费开源微信机器人框架,…...

LabVIEW虚拟仪表开发:从图形化编程到工业测控系统实战
1. 虚拟仪表:从概念到实践的革新 作为一名在工业自动化领域摸爬滚打了十多年的硬件工程师,我经历过从纯硬件调试到软硬件结合的漫长过程。早期,面对一个复杂的测试系统,我们往往需要堆满一桌子的真实仪器——示波器、信号发生器、…...
)
手把手教你用wget和迅雷搞定nuScenes数据集下载(附完整性校验命令)
高效获取nuScenes数据集的两种技术方案与完整性验证指南 在自动驾驶与计算机视觉研究领域,nuScenes数据集因其丰富的传感器数据和精细的标注体系已成为行业基准测试的重要资源。但对于大多数研究者而言,获取这个总容量超过550GB的数据集却面临着网络不稳…...

网络工程师避坑指南:eNSP中配置Eth-Trunk链路聚合的5个常见错误与排查方法
网络工程师避坑指南:eNSP中配置Eth-Trunk链路聚合的5个常见错误与排查方法 在华为eNSP模拟器中配置Eth-Trunk链路聚合时,许多网络工程师都会遇到各种"翻车"现场。明明按照教程一步步操作,却发现带宽没有叠加、端口状态异常…...

解密ASCII图表魔法:ditaa将文本艺术转化为专业图表的技术揭秘
解密ASCII图表魔法:ditaa将文本艺术转化为专业图表的技术揭秘 【免费下载链接】ditaa ditaa is a small command-line utility that can convert diagrams drawn using ascii art (drawings that contain characters that resemble lines like | / - ), into proper…...

Codex SQL迁移终极指南:数据库架构变更的自动化革命
Codex SQL迁移终极指南:数据库架构变更的自动化革命 在当今快速迭代的软件开发环境中,数据库架构变更是每个开发团队都必须面对的挑战。传统的手动SQL迁移过程不仅耗时耗力,还容易出错。Codex作为一款革命性的聊天驱动开发工具,通…...

30分钟搞定黑苹果:OpCore Simplify如何让Hackintosh配置从专业难题变成简单操作
30分钟搞定黑苹果:OpCore Simplify如何让Hackintosh配置从专业难题变成简单操作 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂…...