CNN(四):ResNet与DenseNet结合--DPN
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊|接辅导、项目定制
前面实现了ResNet和DenseNet的算法,了解了它们有各自的特点:
- ResNet:通过建立前面层与后面层之间的“短路连接”(shortcu),其特征则直接进行sum操作,因此channel数不变;
- DenseNet:通过建立的是前面所有层与后面层的紧密连接(dense connection),其特征在channel维度上的直接concat来实现特征重用(feature reuse),因此channel数增加;
1 DPN设计理念
本课题是将ResNet与DenseNet相结合,而DPN则正是对它们俩进行了融合,所谓dual path,即一条path是ResNet,另外一条是DenseNet。在《Dual Path Networks》中,作者通过对ResNet和DenseNet的分解,证明了ResNet更侧重于特征的复用,而DenseNet则更侧重于特征的生成,通过分析两个模型的优劣,将两个模型有针对性的组合起来,提出了DPN。
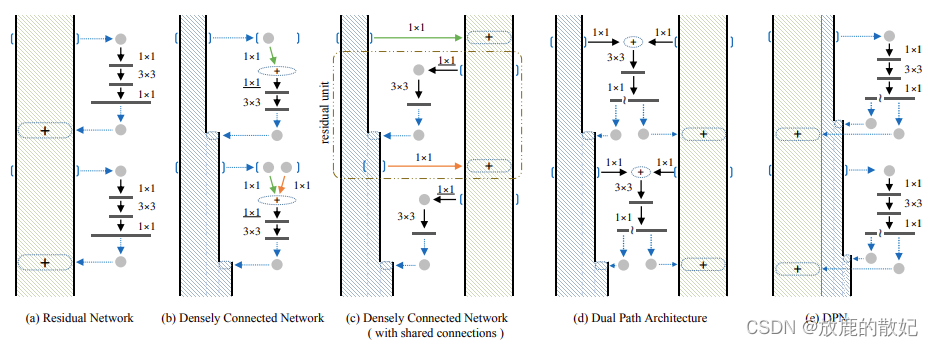
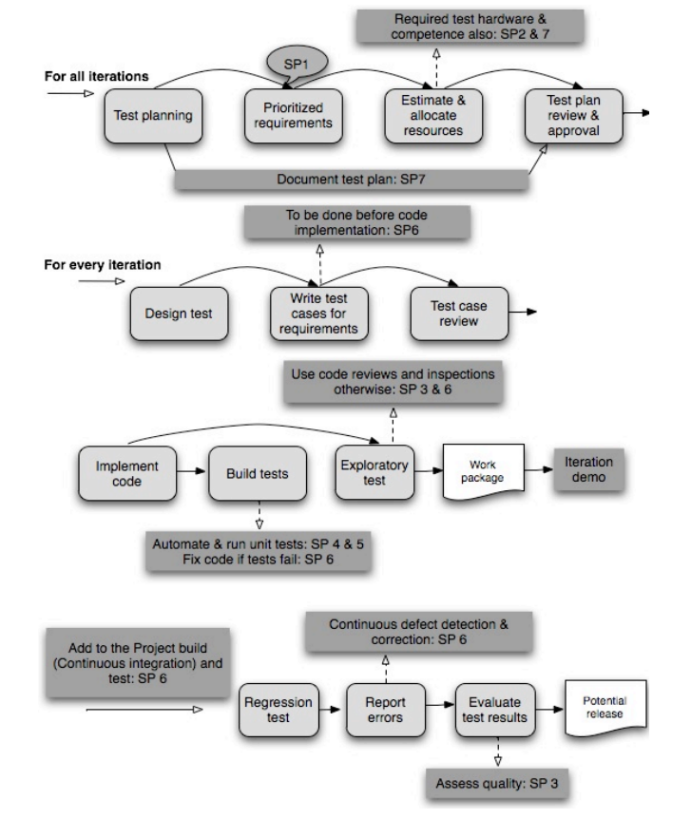
图中
- (a):为ResNet;
- (b):为Densely Connected Network,其中每一次都可以访问之前所有的micro-block的输出。为了与(a)中的micro-block设计保持一致,这里增加了一个1*1的卷积层(图中带下划线的部分);
- (c):通过在(b)中micro-block之间共享相同输出的第一个1*1连接,密集连接的网络退化为一个残差网络,即图中点线框中的部分;
- (d):Dual Path结构的DPN
- (e):与(d)等价,都表示DPN,这里为其实现形式,其中
表示分割操作,而+表示元素相加
由上图可知,ResNet复用了前面层的特征,而每一层的特征会原封不动的传到下一层,而在每一层通过卷积等操作后又会提取到不同的特征,因此特征的冗余度较低。但DenseNet的每个1*1卷积参数不同,前面提到的层不是被后面的层直接使用,而是被重新加工后生成了新的特征,因此这种结构很有可能会造成后面的层提取到的特征是前面的网络已经提取过的特征,故而DenseNet是一个冗余度较高的网络。DPN以ResNet为主要框架,保证特征的低冗余度,并添加了一个非常小的DenseNet分支,用于生成新的特征。
2 DPN代码实现
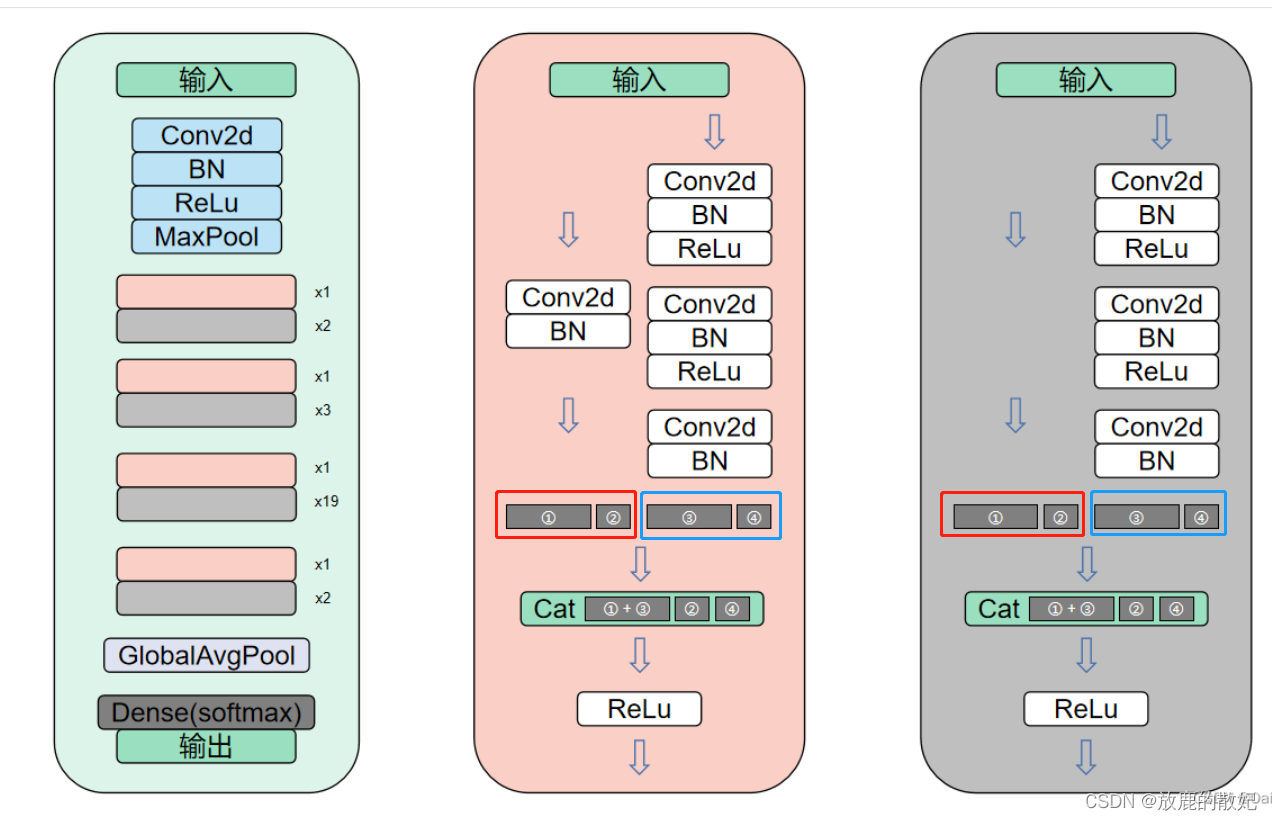
上图最左侧为DPN92的网络结构,对比下图的ResNet不难看出,DPN确是以ResNet为框架进行的改进。右侧是DPN主要模块的详细结构图,其中粉色模块对应ResNet中的ConvBlock模块,灰色模块对应ResNet中的IdentityBlock模块。但又由独特之处,就是在两个模块中,无论是直接shortcut还是经过一个Conc2d+BN,与ResNet的直接进行sum处理不同,这里将两条支路的特征分别进行截取,如图中红框和蓝框中所示,将其特征分别截取成①和②部分,以及③和④部分,其中①③的尺寸一致,②④的尺寸一致,然后将①和③进行sum操作后再与②④进行concat操作,这样便引入了DenseNet中的直接在channel维度上进行concat的思想。

2.1 前期工作
2.1.1 开发环境
-
电脑系统:ubuntu16.04
-
编译器:Jupter Lab
-
语言环境:Python 3.7
-
深度学习环境:pytorch
2.1.2 设置GPU
如果设备上支持GPU就使用GPU,否则注释掉这部分代码。
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warningswarnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(device)
2.1.3 导入数据
import os,PIL,random,pathlibdata_dir_str = '../data/bird_photos'
data_dir = pathlib.Path(data_dir_str)
print("data_dir:", data_dir, "\n")data_paths = list(data_dir.glob('*'))
classNames = [str(path).split('/')[-1] for path in data_paths]
print('classNames:', classNames , '\n')train_transforms = transforms.Compose([transforms.Resize([224, 224]), # resize输入图片transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换成tensortransforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 从数据集中随机抽样计算得到
])total_data = datasets.ImageFolder(data_dir_str, transform=train_transforms)
print(total_data)
print(total_data.class_to_idx)结果输出如图:

2.1.4 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset, test_dataset)batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size,shuffle=True,num_workers=1,pin_memory=False)
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size,shuffle=True,num_workers=1,pin_memory=False)for X, y in test_dl:print("Shape of X [N, C, H, W]:", X.shape)print("Shape of y:", y.shape, y.dtype)break结果输出如图:

2.2 搭建DPN
2.2.1 DPN模块搭建
import torch
import torch.nn as nnclass Block(nn.Module):"""param : in_channel--输入通道数mid_channel -- 中间经历的通道数out_channel -- ResNet部分使用的通道数(sum操作,这部分输出仍然是out_channel个通道)dense_channel -- DenseNet部分使用的通道数(concat操作,这部分输出是2*dense_channel个通道)groups -- conv2中的分组卷积参数is_shortcut -- ResNet前是否进行shortcut操作"""def __init__(self, in_channel, mid_channel, out_channel, dense_channel, stride, groups, is_shortcut=False):super(Block, self).__init__()self.is_shortcut = is_shortcutself.out_channel = out_channelself.conv1 = nn.Sequential(nn.Conv2d(in_channel, mid_channel, kernel_size=1, bias=False),nn.BatchNorm2d(mid_channel),nn.ReLU())self.conv2 = nn.Sequential(nn.Conv2d(mid_channel, mid_channel, kernel_size=3, stride=stride, padding=1, groups=groups, bias=False),nn.BatchNorm2d(mid_channel),nn.ReLU())self.conv3 = nn.Sequential(nn.Conv2d(mid_channel, out_channel+dense_channel, kernel_size=1, bias=False),nn.BatchNorm2d(out_channel+dense_channel))if self.is_shortcut:self.shortcut = nn.Sequential(nn.Conv2d(in_channel, out_channel+dense_channel, kernel_size=3, padding=1, stride=stride, bias=False),nn.BatchNorm2d(out_channel+dense_channel))self.relu = nn.ReLU(inplace=True)def forward(self, x):a = xx = self.conv1(x)x = self.conv2(x)x = self.conv3(x)if self.is_shortcut:a = self.shortcut(a)# a[:, :self.out_channel, :, :]+x[:, :self.out_channel, :, :]是使用ResNet的方法,即采用sum的方式将特征图进行求和,通道数不变,都是out_channel个通道# a[:, self.out_channel:, :, :], x[:, self.out_channel:, :, :]]是使用DenseNet的方法,即采用concat的方式将特征图在channel维度上直接进行叠加,通道数加倍,即2*dense_channel# 注意最终是将out_channel个通道的特征(ResNet方式)与2*dense_channel个通道特征(DenseNet方式)进行叠加,因此最终通道数为out_channel+2*dense_channelx = torch.cat([a[:, :self.out_channel, :, :]+x[:, :self.out_channel, :, :], a[:, self.out_channel:, :, :], x[:, self.out_channel:, :, :]], dim=1)x = self.relu(x)return xclass DPN(nn.Module):def __init__(self, cfg):super(DPN, self).__init__()self.group = cfg['group']self.in_channel = cfg['in_channel']mid_channels = cfg['mid_channels']out_channels = cfg['out_channels']dense_channels = cfg['dense_channels']num = cfg['num']self.conv1 = nn.Sequential(nn.Conv2d(3, self.in_channel, 7, stride=2, padding=3, bias=False, padding_mode='zeros'),nn.BatchNorm2d(self.in_channel),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=0))self.conv2 = self._make_layers(mid_channels[0], out_channels[0], dense_channels[0], num[0], stride=1)self.conv3 = self._make_layers(mid_channels[1], out_channels[1], dense_channels[1], num[1], stride=2)self.conv4 = self._make_layers(mid_channels[2], out_channels[2], dense_channels[2], num[2], stride=2)self.conv5 = self._make_layers(mid_channels[3], out_channels[3], dense_channels[3], num[3], stride=2)self.pool = nn.AdaptiveAvgPool2d((1,1))self.fc = nn.Linear(cfg['out_channels'][3] + (num[3] + 1) * cfg['dense_channels'][3], cfg['classes']) # fc层需要计算def _make_layers(self, mid_channel, out_channel, dense_channel, num, stride):layers = []# is_shortcut=True表示进行shortcut操作,则将浅层的特征进行一次卷积后与进行第三次卷积的特征图相加(ResNet方式)和concat(DeseNet方式)操作# 第一次使用Block可以满足浅层特征的利用,后续重复的Block则不需要线层特征,因此后续的Block的is_shortcut=False(默认值)layers.append(Block(self.in_channel, mid_channel, out_channel, dense_channel, stride=stride, groups=self.group, is_shortcut=True))self.in_channel = out_channel + dense_channel*2for i in range(1, num):layers.append(Block(self.in_channel, mid_channel, out_channel, dense_channel, stride=1, groups=self.group))# 由于Block包含DenseNet在叠加特征图,所以第一次是2倍dense_channel,后面每次都会多出1倍dense_channelself.in_channel += dense_channelreturn nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = self.conv4(x)x = self.conv5(x)x = self.pool(x)x = torch.flatten(x, start_dim=1)x = self.fc(x)return x2.2.2 DPN92和DPN98
def DPN92(n_class=4):cfg = {"group" : 32,"in_channel" : 64,"mid_channels" : (96, 192, 384, 768),"out_channels" : (256, 512, 1024, 2048),"dense_channels" : (16, 32, 24, 128),"num" : (3, 4, 20, 3),"classes" : (n_class)}return DPN(cfg)def DPN98(n_class=4):cfg = {"group" : 40,"in_channel" : 96,"mid_channels" : (160, 320, 640, 1280),"out_channels" : (256, 512, 1024, 2048),"dense_channels" : (16, 32, 32, 128),"num" : (3, 6, 20, 3),"classes" : (n_class)}return DPN(cfg)model = DPN92().to(device)
model这里使用模型DPN92,输出结果如下图所示(由于结果太大,只截取前后部分)

(中间部分省略)

2.2.3 查看模型详情
# 统计模型参数量以及其他指标
import torchsummary as summary
summary.summary(model, (3, 224, 224))结果输出如下(由于结果太长,只展示最前面和最后面):
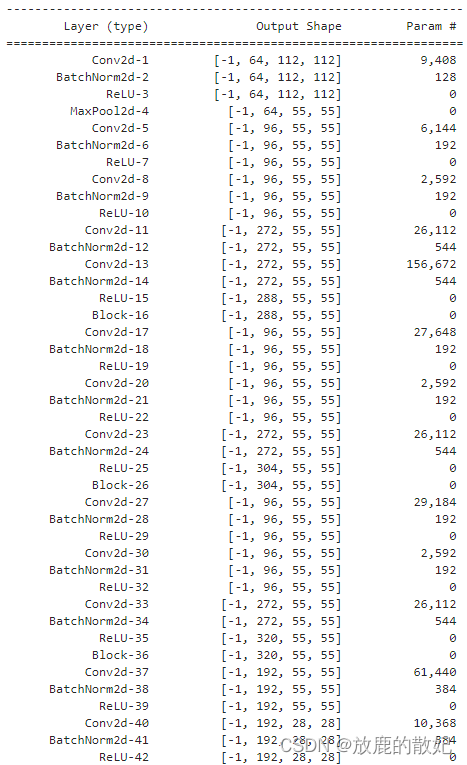
(中间部分省略)
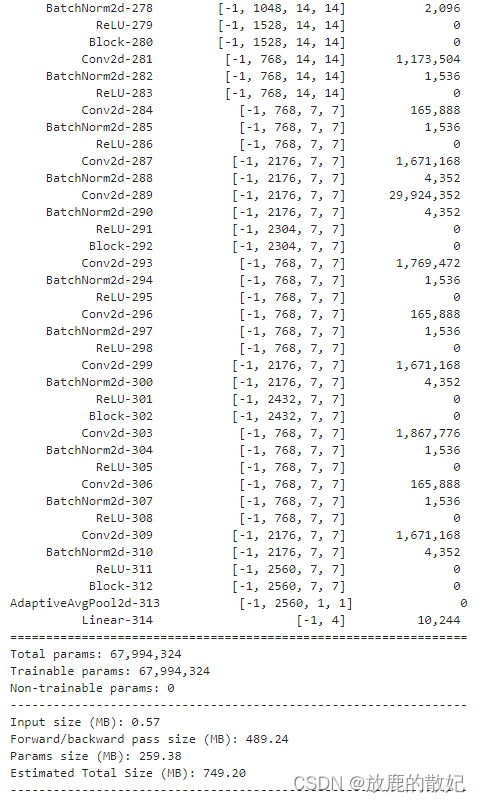
2.3 训练模型
2.3.1 编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出pred和真实值y之间的差距,y为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss2.3.2 编写测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)test_loss, test_acc = 0, 0 # 初始化测试损失和正确率# 当不进行训练时,停止梯度更新,节省计算内存消耗# with torch.no_grad():for imgs, target in dataloader: # 获取图片及其标签with torch.no_grad():imgs, target = imgs.to(device), target.to(device)# 计算误差tartget_pred = model(imgs) # 网络输出loss = loss_fn(tartget_pred, target) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 记录acc与losstest_loss += loss.item()test_acc += (tartget_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss2.3.3 正式训练
import copyoptimizer = torch.optim.Adam(model.parameters(), lr = 1e-4)
loss_fn = nn.CrossEntropyLoss() #创建损失函数epochs = 40train_loss = []
train_acc = []
test_loss = []
test_acc = []best_acc = 0 #设置一个最佳准确率,作为最佳模型的判别指标if hasattr(torch.cuda, 'empty_cache'):torch.cuda.empty_cache()for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)#scheduler.step() #更新学习率(调用官方动态学习率接口时使用)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)#保存最佳模型到best_modelif epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)#获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch: {:2d}. Train_acc: {:.1f}%, Train_loss: {:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr: {:.2E}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))PATH = './J3_best_model.pth'
torch.save(model.state_dict(), PATH)print('Done')结果输出如下:

2.4 结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()结果输出如下:
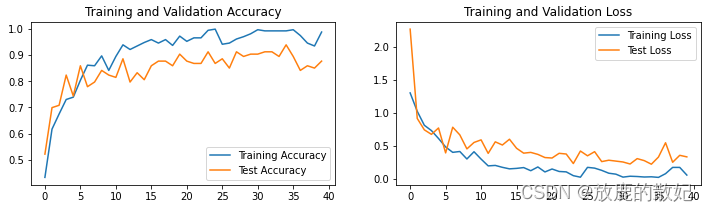
相关文章:
CNN(四):ResNet与DenseNet结合--DPN
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊|接辅导、项目定制 前面实现了ResNet和DenseNet的算法,了解了它们有各自的特点: ResNet:通过建立前面层与后面层之间的“短路…...
汽车EBSE测试流程分析(四):反思证据及当前问题解决
EBSE专题连载共分为“五个”篇章。此文为该连载系列的“第四”篇章,在之前的“篇章(三)”中已经结合具体研究实践阐述了“步骤二,通过系统调研确定改进方案”等内容。那么,在本篇章(四)中&#…...

如何在Spring MVC中使用@ControllerAdvice创建全局异常处理器
文章目录 前言一、认识注解:RestControllerAdvice和ExceptionHandler二、使用步骤1、封装统一返回结果类2、自定义异常类封装3、定义全局异常处理类4、测试 总结 前言 全局异常处理器是一种 🌟✨机制,用于处理应用程序中发生的异常ÿ…...

2023/08/05【网络课程总结】
1. 查看git拉取记录 git reflog --dateiso|grep pull2. TCP/IP和OSI七层参考模型 3. DNS域名解析 4. 预检请求OPTIONS 5. 渲染进程的回流(reflow)和重绘(repaint) 6. V8解析JavaScript 7. CDN负载均衡的简单理解 8. 重学Ajax 重学Ajax满神 9. 对于XML的理解 大白话叙述XML是…...

log_softmax比softmax更好?
多类别分类的一个trick 探讨一下在多类别分类场景,如翻译、生成、目标检测等场景下,使用log_softmax的效果优于softmax的原因。 假设词典大小为10,一个词的ID为9(即词典的最后一个词),使用交叉熵作为损失函…...
[LeetCode - Python]344.反转字符串(Easy);345. 反转字符串中的元音字母(Easy);977. 有序数组的平方(Easy)
1.题目 344.反转字符串(Easy) 1.代码 class Solution:def reverseString(self, s: List[str]) -> None:"""Do not return anything, modify s in-place instead."""# 双指针left,right 0, len(s)-1while left < right:temp s[left]s[…...
【SOP】最佳实践之 TiDB 业务写变慢分析
作者: 李文杰_Jellybean 原文来源: https://tidb.net/blog/d3d4465f 前言 在日常业务使用或运维管理 TiDB 的过程中,每个开发人员或数据库管理员都或多或少遇到过 SQL 变慢的问题。这类问题大部分情况下都具有一定的规律可循,…...

带有参数的 PL/SQL 过程/函数从选择查询返回表
技术标签: 【中文标题】带有参数的 PL/SQL 过程/函数从选择查询返回表【英文标题】:PL/SQL Procedure/function with params to return a table from(of) a select query【发布时间】:2020-12-01 11:17:49【问题描述】: 如何创建带参数的 (…...
文件的权限
1、修改文件的所属者和所属组 2、修改文件某一类人(所属者、所属组、其他人)的权限 一、用户对于普通文件的权限 二、用户对于目录文件的权限 三、访问控制列表ACL 四、特殊权限(了解) wuneng创建了几个文件,xiaoming对…...

vue3集成echarts最佳实践
安装 echarts npm install echarts --save 两种引用方式 非虚拟 dom import * as echarts from echarts;var chartDom document.getElementById(mychart); var myChart echarts.init(chartDom); var option;option {title: {text: Referer of a Website,subtext: Fake Da…...
一位年薪40W的测试被开除,回怼的一番话,令人沉思
一位年薪40W测试工程师被开除回怼道:“反正我有技术,在哪不一样” 一技傍身,万事不愁,当我们掌握了一技之长后,在职场上说话就硬气了许多,不用担心被炒,反过来还可以炒了老板,这一点…...
网络适配器和MAC地址
点对点信道:由于目的地只有一个选项,所以数据链路层不需要使用地址。 而在广播信道中: 各个主机如何判断信号是不是发给自己的? 当多个主机连接在同一个广播信道上,要想实现两个主机之间的通信,则每个主机都…...

react-player静音不能自动播放问题
现象 移动端不能自动播放 原因 取决于您使用的浏览器,但muted如果您不想与autoplay用户交互,则必须使用视频。 Chrome 的自动播放策略很简单: 始终允许静音自动播放。在以下情况下允许自动播放声音: 用户与域进行了交互&#x…...

培训Java技术要多久才能学会?答案都在这里啦
培训Java技术要多久才能学会?这是想学习Java开发的很多人都会问到的一个问题。而这个问题的答案其实并不是那么简单,因为学Java的时间长短受到众多因素的影响。本文将从个人基础、学习动力和学习效率三个方面来为您解答这个问题。 1. 个人基础 自己的基础对于学习…...

Java中使用HttpPost发送form格式的请求
在Java中使用HttpPost发送form格式的请求,可以使用Apache HttpClient库来实现。以下是一个示例代码: import org.apache.http.HttpEntity; import org.apache.http.HttpResponse; import org.apache.http.NameValuePair; import org.apache.http.client…...

C语言----字节对齐
一:字节对齐的概念 针对字节对齐,百度百科的解释如下: 字节对齐是字节按照一定规则在空间上排列,字节(Byte)是计算机信息技术用于计量存储容量和传输容量的一种计量单位,一个字节等于8位二进制数,在UTF-8编…...
)
Next.js入门介绍(服务端渲染)
Next.js 一 目录 不折腾的前端,和咸鱼有什么区别 目录一 目录二 前言三 设置四 多页面五 链接六 样式七 共享组件八 布局组件九 实战 9.1 目录结构 9.2 UI 组件 9.3 Markdown 内容 9.4 Pages 入口和 API 9.4.1 服务端渲染 9.5 Public 静态资源 9.6 resor…...

模板Plus
文章目录 1.非类型模板参数的引入2.标准库和普通数组3.模板的特化 1.非类型模板参数的引入 //非类型模板参数 -- 常量 template<class T, size_t N 10> class array { private:T _a[N]; };int main() {array<int> a1;array<int, 100> a2;array<double, …...

spring事务和数据库事务是怎么实现
Spring事务的原理 Spring事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,spring是无法提供事务功能的。对于纯JDBC操作数据库,想要用到事务,可以按照以下步骤进行: 获取连接 Connection con DriverManag…...

el-date-picker设置默认当前日期
HTMl部分: <el-form-item label"拍摄时间:"><el-date-pickerv-model"searchData.filmingTimeRange"type"daterange"align"right"unlink-panelsrange-separator"至"start-placeholder"…...
)
UE5实战:手把手教你用AIController和PathFollowingComponent实现NPC智能移动(含源码解析)
UE5智能寻路实战:从零构建NPC导航系统 在虚幻引擎5的游戏开发中,AI角色的自主移动能力直接影响着游戏体验的真实感。许多开发者初次接触UE5的AI系统时,往往会被NavigationSystem、AIController和PathFollowingComponent等模块的复杂关系所困扰…...

量子机器学习革新气象预测:高效台风轨迹建模
1. 量子机器学习在气象预测中的革新应用台风轨迹预测一直是气象学领域的重大挑战。传统数值天气预报(NWP)模型依赖于超级计算机集群,需要处理海量的大气动力学数据,计算成本高昂且能耗巨大。以台湾地区为例,每年平均遭受3.5次台风袭击&#x…...

别再乱接线了!用PulseView+逻辑分析仪抓STM32 SPI波形,保姆级避坑指南
逻辑分析仪实战:精准捕获STM32 SPI波形的五大黄金法则 当你在调试STM32的SPI外设时,是否遇到过这样的困境:代码配置完全按照手册操作,但逻辑分析仪显示的波形却充满毛刺、数据残缺不全?这往往不是代码逻辑的问题&#…...

如何用Python自动化脚本轻松抢到大麦网演唱会门票:终极指南
如何用Python自动化脚本轻松抢到大麦网演唱会门票:终极指南 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为抢不到心仪演唱会门票而烦恼吗?当周杰伦、五月天等热门演…...

歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程
歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 歌词滚动姬(LRC Maker)是…...

yolo26 pt转onnx
from ultralytics import YOLOdef main():# 加载你训练好的 YOLO26 模型model YOLO("D:\\ultralytics\\runs\\detect\\train-3\\weights\\best.pt") # 请将 best.pt 替换为你实际的文件路径# 导出为 ONNX 格式model.export(format"onnx",imgsz(640,384),…...

CircuitMind框架:突破LLM在数字电路设计中的布尔优化障碍
1. 项目概述:CircuitMind框架的创新价值在数字电路设计领域,布尔优化一直是硬件工程师面临的核心挑战。传统设计流程中,工程师需要手动应用卡诺图、奎因-麦克拉斯基算法等技巧来优化门级网表,这一过程既耗时又高度依赖专家经验。近…...

手机店还会存在吗
这两年买手机,有个很常见的小场景:人先进店,把样机拿起来拍几张照片,摸一下边框,试试重量,再问店员有没有现货。问完价格以后,很多人会低头打开电商平台。 门店最尴尬的地方就在这里。它承担了体…...

从LMS到BLMS:自适应滤波的‘批处理’思想如何解决工程中的收敛难题?
从LMS到BLMS:批处理思想如何重塑自适应滤波的工程实践 在实时信号处理领域,工程师们常常面临一个经典困境:算法响应速度与系统稳定性能之间的微妙平衡。想象一下,当你正在调试一套语音降噪系统时,每次麦克风接收到一个…...
)
树莓派I2C保姆级教程:从命令行工具到Python脚本,一次搞定多个传感器(附避坑指南)
树莓派I2C实战指南:从硬件调试到Python自动化控制 第一次接触树莓派的I2C接口时,我对着密密麻麻的引脚和传感器数据手册发呆了半小时。直到成功读取到第一个温湿度数据,才意识到I2C这种看似复杂的通信协议,其实就像一位耐心的翻译…...