【自然语言处理】大模型高效微调:PEFT 使用案例
文章目录
- 一、PEFT介绍
- 二、PEFT 使用
- 2.1 PeftConfig
- 2.2 PeftModel
- 2.3 保存和加载模型
- 三、PEFT支持任务
- 3.1 Models support matrix
- 3.1.1 Causal Language Modeling
- 3.1.2 Conditional Generation
- 3.1.3 Sequence Classification
- 3.1.4 Token Classification
- 3.1.5 Text-to-Image Generation
- 3.1.6 Image Classification
- 3.1.7 Image to text (Multi-modal models)
- 四、PEFT原理
- 4.1 LoRA
- 4.2 Prompt tuning
- 4.3 IA3
一、PEFT介绍
PEFT(Parameter-Efficient Fine-Tuning,参数高效微调),是一个用于在不微调所有模型参数的情况下,高效地将预训练语言模型(PLM)适应到各种下游应用的库。
PEFT方法仅微调少量(额外的)模型参数,显著降低了计算和存储成本,因为对大规模PLM进行完整微调的代价过高。最近的最先进的PEFT技术实现了与完整微调相当的性能。
代码:
https://github.com/huggingface/peft
文档:
https://huggingface.co/docs/peft/index
二、PEFT 使用
接下来将展示 PEFT 的主要特点,并帮助在消费设备上通常无法访问的情况下训练大型预训练模型。您将了解如何使用LoRA来训练1.2B参数的bigscience/mt0-large模型,以生成分类标签并进行推理。
2.1 PeftConfig
每个 PEFT 方法由一个PeftConfig类来定义,该类存储了用于构建PeftModel的所有重要参数。
由于您将使用LoRA,您需要加载并创建一个LoraConfig类。在LoraConfig中,指定以下参数:
- task_type,在本例中为序列到序列语言建模
- inference_mode,是否将模型用于推理
- r,低秩矩阵的维度
- lora_alpha,低秩矩阵的缩放因子
- lora_dropout,LoRA层的dropout概率
from peft import LoraConfig, TaskTypepeft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
有关您可以调整的其他参数的更多详细信息,请参阅LoraConfig参考。
2.2 PeftModel
使用 get_peft_model() 函数可以创建PeftModel。它需要一个基础模型 - 您可以从 Transformers 库加载 - 以及包含配置特定 PEFT 方法的PeftConfig。
首先加载您要微调的基础模型。
from transformers import AutoModelForSeq2SeqLMmodel_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
使用get_peft_model函数将基础模型和peft_config包装起来,以创建PeftModel。要了解您模型中可训练参数的数量,可以使用print_trainable_parameters方法。在这种情况下,您只训练了模型参数的0.19%!
from peft import get_peft_modelmodel = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# 输出示例: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
至此,我们已经完成了!现在您可以使用Transformers的Trainer、 Accelerate,或任何自定义的PyTorch训练循环来训练模型。
2.3 保存和加载模型
在模型训练完成后,您可以使用save_pretrained函数将模型保存到目录中。您还可以使用push_to_hub函数将模型保存到Hub(请确保首先登录您的Hugging Face帐户)。
model.save_pretrained("output_dir")# 如果要推送到Hub
from huggingface_hub import notebook_loginnotebook_login()
model.push_to_hub("my_awesome_peft_model")
这只保存了已经训练的增量PEFT权重,这意味着存储、传输和加载都非常高效。例如,这个在RAFT数据集的twitter_complaints子集上使用LoRA训练的bigscience/T0_3B模型只包含两个文件:adapter_config.json和adapter_model.bin,后者仅有19MB!
使用from_pretrained函数轻松加载模型进行推理:
from transformers import AutoModelForSeq2SeqLM
from peft import PeftModel, PeftConfigpeft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
三、PEFT支持任务
3.1 Models support matrix
3.1.1 Causal Language Modeling
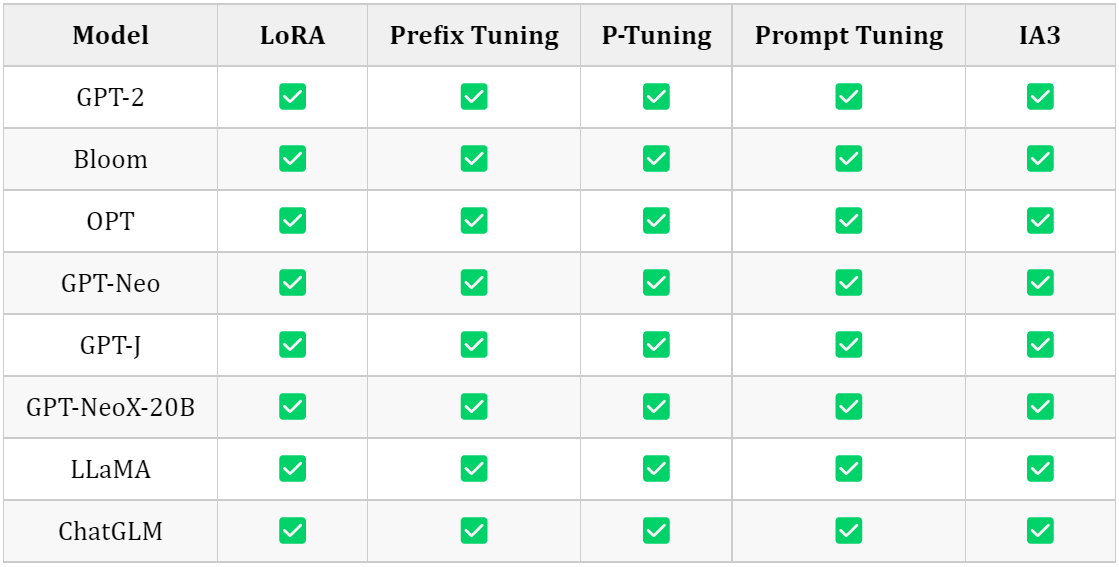
3.1.2 Conditional Generation

3.1.3 Sequence Classification
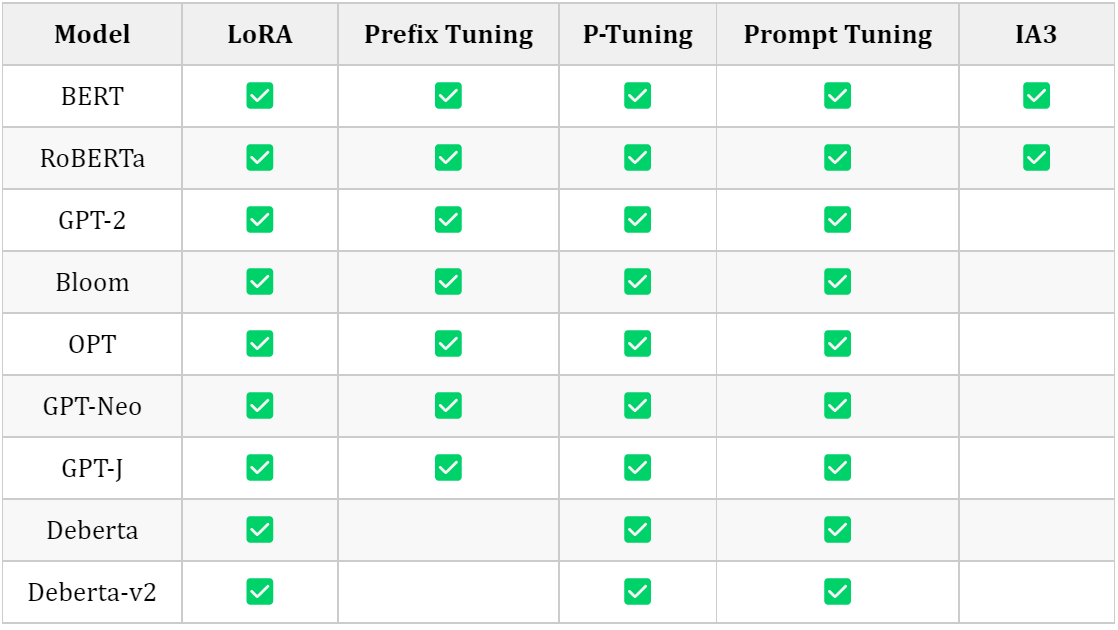
3.1.4 Token Classification
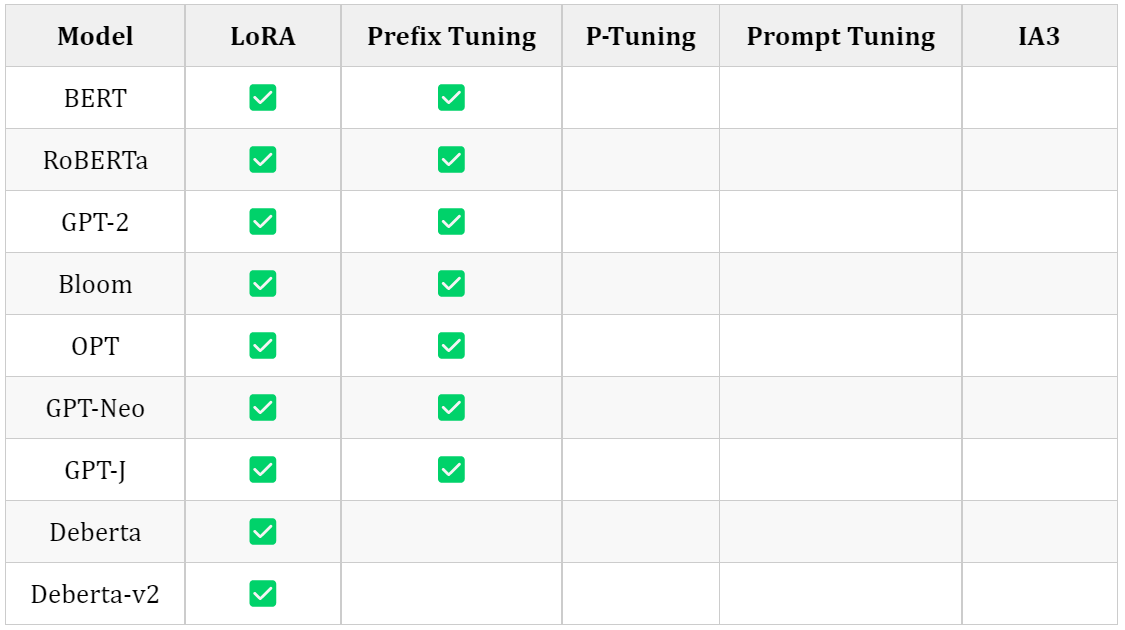
3.1.5 Text-to-Image Generation

3.1.6 Image Classification

3.1.7 Image to text (Multi-modal models)

四、PEFT原理
4.1 LoRA
LoRA(Low-Rank Adaptation)是一种技术,通过低秩分解将权重更新表示为两个较小的矩阵(称为更新矩阵),从而加速大型模型的微调,并减少内存消耗。
为了使微调更加高效,LoRA的方法是通过低秩分解,使用两个较小的矩阵(称为更新矩阵)来表示权重更新。这些新矩阵可以通过训练适应新数据,同时保持整体变化的数量较少。原始的权重矩阵保持冻结,不再接收任何进一步的调整。为了产生最终结果,同时使用原始和适应后的权重进行合并。
4.2 Prompt tuning
训练大型预训练语言模型是非常耗时且计算密集的。随着模型尺寸的增长,越来越多的人对更高效的训练方法产生了兴趣,例如提示(Prompting)。提示通过包括描述任务的文本提示或甚至演示任务示例的文本提示来为特定的下游任务准备一个冻结的预训练模型。通过使用提示,您可以避免为每个下游任务完全训练单独的模型,而是使用相同的冻结预训练模型。这更加方便,因为您可以将同一模型用于多个不同的任务,而训练和存储一小组提示参数要比训练所有模型参数要高效得多。
提示方法可以分为两类:
- 硬提示(Hard Prompts):手工制作的具有离散输入标记的文本提示;缺点是需要花费很多精力来创建一个好的提示。
- 软提示(Soft Prompts):可与输入嵌入连接并进行优化以适应数据集的可学习张量;缺点是它们不太易读,因为您不是将这些“虚拟标记”与实际单词的嵌入进行匹配。
4.3 IA3
为了使微调更加高效,IA3(通过抑制和放大内部激活来注入适配器)使用学习向量对内部激活进行重新缩放。这些学习向量被注入到典型的基于Transformer架构中的注意力和前馈模块中。这些学习向量是微调过程中唯一可训练的参数,因此原始权重保持冻结。处理学习向量(而不是像LoRA一样对权重矩阵进行学习的低秩更新)可以大大减少可训练参数的数量。
与LoRA类似,IA3具有许多相同的优点:
- IA3通过大大减少可训练参数的数量使微调更加高效(对于T0模型,IA3模型仅具有约0.01%的可训练参数,而即使是LoRA也有超过0.1%)。
- 原始的预训练权重保持冻结,这意味着您可以在其之上构建多个轻量级和便携的IA3模型,用于各种下游任务。
- 使用IA3进行微调的模型性能与完全微调的模型性能相当。
- IA3不会增加任何推理延迟,因为适配器权重可以与基础模型合并。
相关文章:
【自然语言处理】大模型高效微调:PEFT 使用案例
文章目录 一、PEFT介绍二、PEFT 使用2.1 PeftConfig2.2 PeftModel2.3 保存和加载模型 三、PEFT支持任务3.1 Models support matrix3.1.1 Causal Language Modeling3.1.2 Conditional Generation3.1.3 Sequence Classification3.1.4 Token Classification3.1.5 Text-to-Image Ge…...
FFmpeg将编码后数据保存成mp4
以下测试代码实现的功能是:持续从内存块中获取原始数据,然后依次进行解码、编码、最后保存成mp4视频文件。 可保存成单个视频文件,也可指定每个视频文件的总帧数,保存多个视频文件。 为了便于查看和修改,这里将可独立的…...

设置VsCode 将打开的多个文件分行(栏)排列,实现全部显示
目录 1. 前言 2. 设置VsCode 多文件分行(栏)排列显示 1. 前言 主流编程IDE几乎都有排列切换选择所要查看的文件功能,如下为Visual Studio 2022的该功能界面: 图 1 图 2 当在Visual Studio 2022打开很多文件时,可以按照图1、图2所示找到自…...

Vue.js2+Cesium1.103.0 六、标绘与测量
Vue.js2Cesium1.103.0 六、标绘与测量 点,线,面的绘制,可实时编辑图形,点击折线或多边形边的中心点,可进行添加线段移动顶点位置等操作,并同时计算出点的经纬度,折线的距离和多边形的面积。 De…...

【redis 延时队列】使用go-redis的list做异步,生产消费者模式
分享一个用到的,使用go-redis的list做异步,生产消费者模式,接着再用 go 协程去检测队列里是否有东西去消费 如果队列为空,就会一直pop,空轮询导致 cpu 资源浪费和redis qps无效升高,所以可以通过 time.Sec…...
激光焊接塑料多点测试全画面穿透率测试仪
工程塑料由于其具有高比强度、电绝缘性、耐磨性、耐腐蚀性等优点,已广泛应用于各个重要领域。另一方面,工程塑料还具有良好的焊接性,是制成复合材料的基体材料的优良选择,因此目前已成为国内外新型复合材料的研究热点。 工程塑料…...

用 Uno 当烧录器给 atmega328 烧录 bootloader
用 Uno 当烧录器给 atmega328 烧录 bootloader date: 2023-8-10 https://backmountaindevil.github.io/#/hackaday/arduino/isp 引脚接线 把两个板子的 11(MOSI)、12(MISO)、13(SCK)、5V、GND 两两相连,还要把 Uno(烧录器)的 10 接到atmeg…...
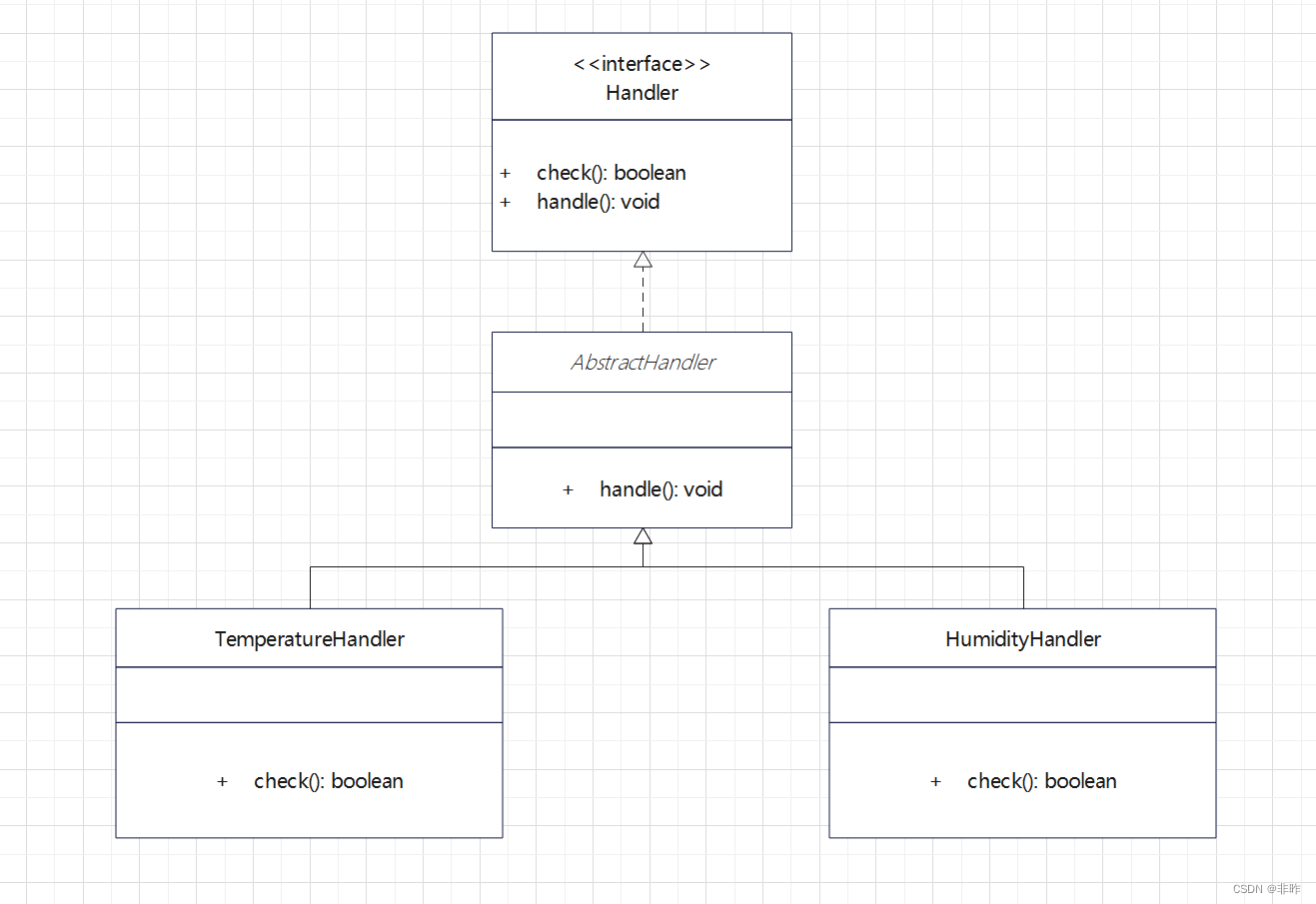
spring boot策略模式实用: 告警模块为例
spring boot策略模式实用: 告警模块 0 涉及知识点 策略模式, 模板方法, 代理, 多态, 反射 1 需求概括 场景: 每隔一段时间, 会获取设备运行数据, 如通过温湿度计获取到当前环境温湿度;需求: 对获取回来的进行分析, 超过配置的阈值需要产生对应的告警 2 方案设计 告警的类…...

Camunda 7.x 系列【10】使用 Rest API 运行流程实例
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 2.7.9 本系列Camunda 版本 7.19.0 源码地址:https://gitee.com/pearl-organization/camunda-study-demo 文章目录 1. 前言2. 官方接口文档3. 本地接口文档3.1 Postman3.2 Camunda Platform Run Swagger3.3 S…...

Python-OpenCV中的图像处理-边缘检测
Python-OpenCV中的图像处理-边缘检测 边缘检测Canny算子 边缘检测Canny算子 Canny 边缘检测是一种非常流行的边缘检测算法,是 John F.Canny 在 1986 年提出的。它是一个有很多步构成的算法:噪声去除、计算图像梯度、非极大值抑制、滞后阀值等。 Canny(i…...
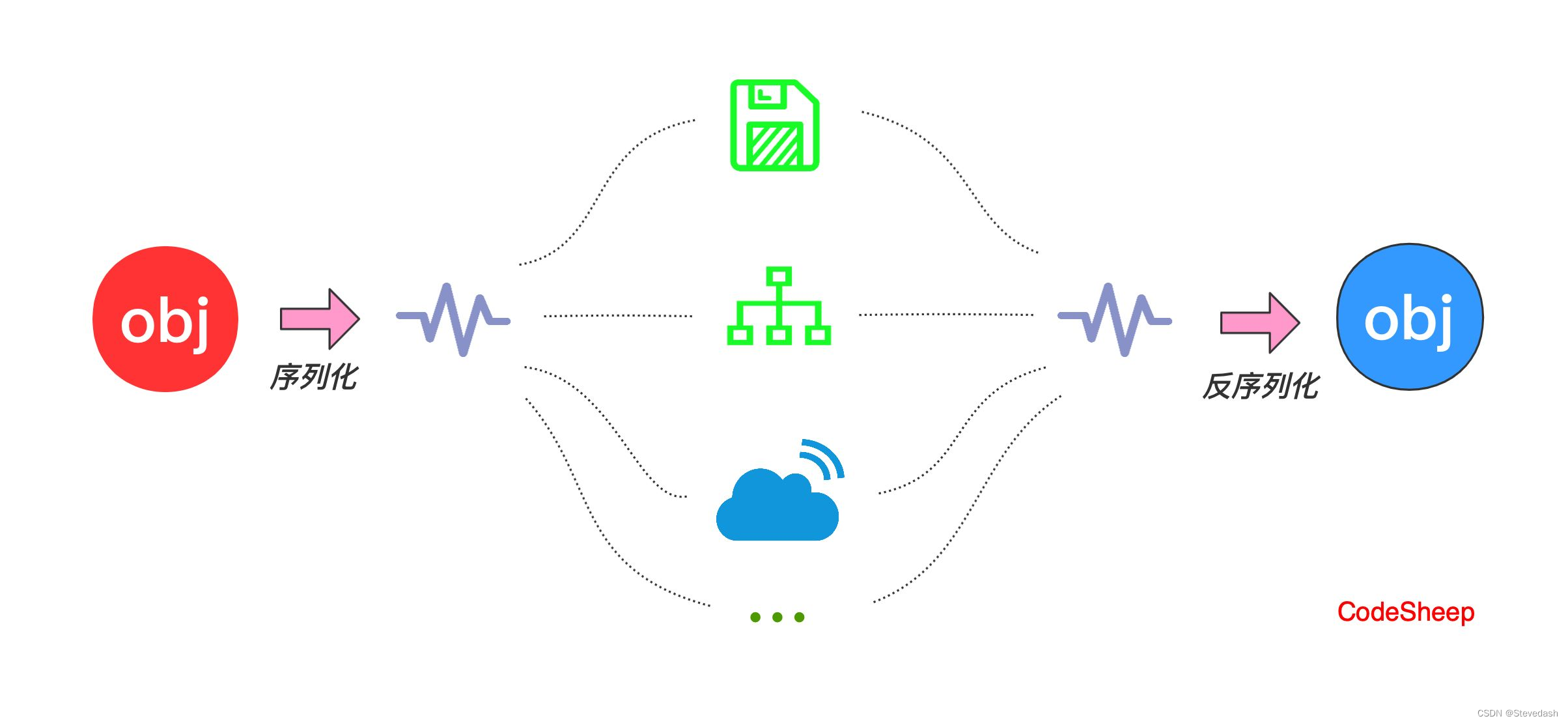
一文了解Java序列化和反序列化:对象的存储与传输
一文了解Java序列化和反序列化:对象的存储与传输 作者:Stevedash 发布时间:2023年8月9日 21点30分 前言 Java序列化是一项强大而重要的技术,它允许我们将对象转换为字节流,以便在存储、传输和重建时使用。在本文中&…...

react-codemirror2 编辑器需点击一下或者延时才显示数据的问题
现象: <Codemirror/>组件的数据已经赋上值的情况下,初始状态不渲染数据,需要点击编辑框获取焦点后才展示,或者延迟了几秒才显示出来。 原因: 指定了一些依赖的版本,可能不兼容了一些功能,…...
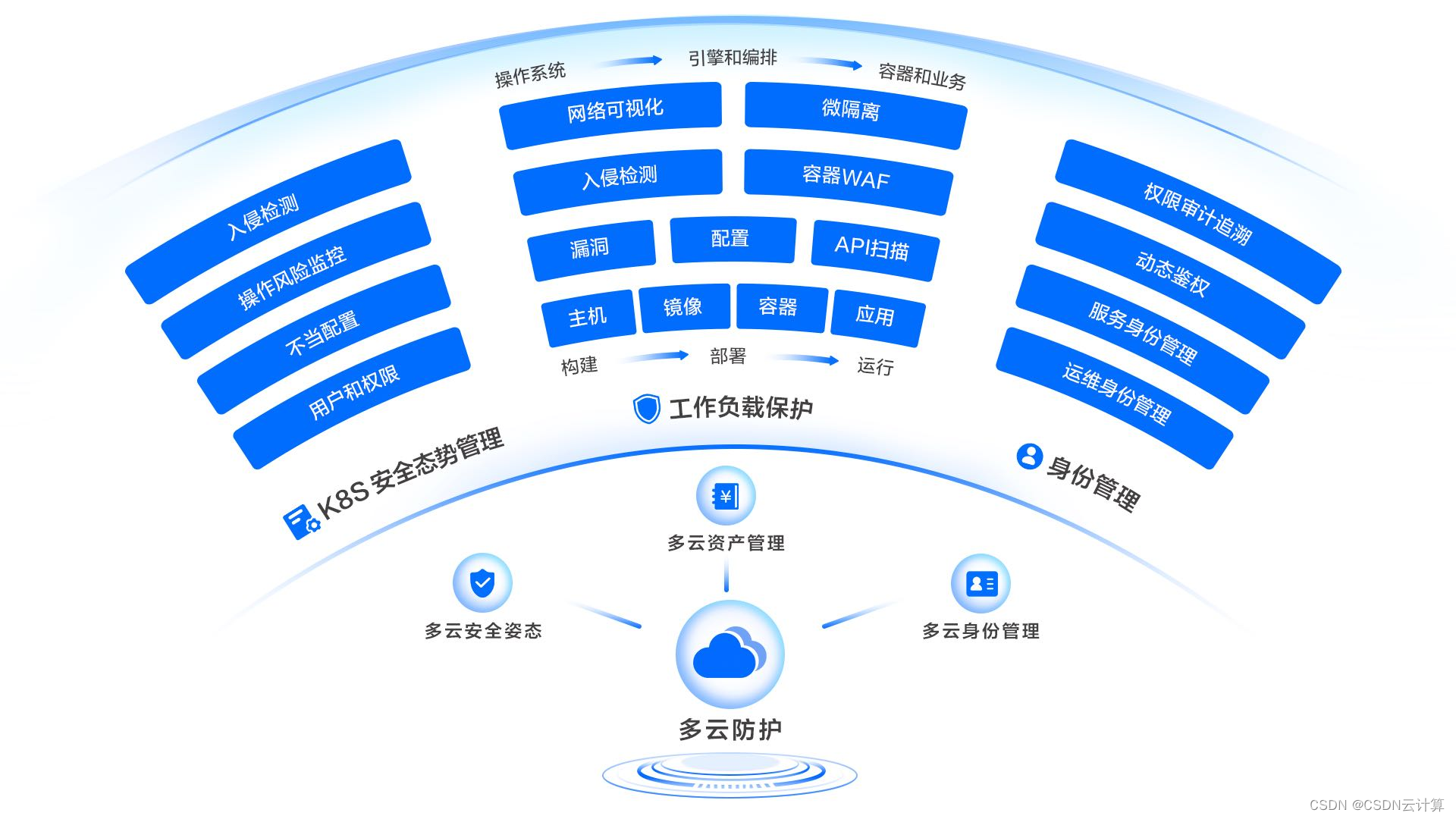
火山引擎联合Forrester发布《中国云原生安全市场现状及趋势白皮书》,赋能企业构建云原生安全体系
国际权威研究咨询公司Forrester 预测,2023年全球超过40%的企业将会采用云原生优先战略。然而,云原生在改变企业上云及构建新一代基础设施的同时,也带来了一系列的新问题,针对涵盖云原生应用、容器、镜像、编排系统平台以及基础设施…...

需要数电发票接口的,先熟悉下数电发票基本常识
最近有一些技术小伙伴来咨询数电发票接口的时候,对数电发票的一些常识不太了解, 导致沟通起来比较困难。比较典型的这三个问题: 一、开具数电票时,如何设置身份认证频次? 请公司的法定代表人或财务负责人登录江苏省电…...

node-sass是什么
一、Sass(Syntactically Awesome Style Sheets) 是一种CSS预处理器,它扩展了CSS的功能并提供了更强大的样式表语言。Sass允许开发人员使用变量、嵌套规则、混合(Mixins)、继承等高级功能来编写更简洁、可维护的样式代…...

C语言指针之 进阶
前言 今天来较为深入的介绍一下指针,希望大家能有所收获~ 那么,先进行一些简单的基础知识复习吧。 字符指针 格式:char * 补充: 表达式“abcdef”的值是首字符a的地址 所以当像下面这么使用时,它的含…...

C++单例模式
文章目录 1、什么是单例2、一个好的单例应该具备的条件3、懒汉模式与饿汉模式4、单例实现:线程安全、内存安全的懒汉式单例(基于C11的智能指针和互斥锁) 1、什么是单例 单例 Singleton 是设计模式的一种,其特点是只提供唯一一个类…...

C++ 析构函数
析构函数 析构函数于构造函数相对应,构造函数是对象创建的时候自动调用的,而析构函数就是对象在销毁的时候自动调用的 特点: 1)构造函数可以有多个来构成重载,但析构函数只能有一个,不能构成重载 2&…...

CSS——字体选择
在网页设计和开发中,字体选择是一个非常重要的因素。字体不仅仅是文字的表现形式,它们还能够传达出一种特定的情感和风格。在CSS中,我们可以通过使用字体代码来定义网页中使用的字体。 CSS提供了一种简单而灵活的方式来设置字体。通过使用fo…...
SpringBoot自动装配及run方法原理探究
自动装配 1、pom.xml spring-boot-dependencies:核心依赖在父工程中!我们在写或者引入一些SpringBoot依赖的时候,不需要指定版本,就因为有这些版本仓库 1.1 其中它主要是依赖一个父工程,作用是管理项目的资源过滤及…...

ArcGIS分区统计:从矢量边界到栅格数据的多维度指标提取
1. ArcGIS分区统计工具入门指南 第一次接触ArcGIS的分区统计功能时,我被它强大的数据处理能力惊艳到了。这个工具就像是一个智能的数据提取器,能够帮我们从复杂的空间数据中快速获取关键指标。想象一下,你手里有一张全国温度分布图࿰…...
)
Unity小白也能搞定的原神桌宠:从PMX模型到可拖拽交互的完整实现(附避坑点)
Unity小白也能搞定的原神桌宠:从PMX模型到可拖拽交互的完整实现(附避坑点) 1. 准备工作与环境搭建 作为一个Unity初学者,想要制作一个原神风格的桌宠,首先需要准备好必要的工具和环境。这个过程可能会让新手感到有些迷…...

知乎x-zse-96参数逆向实战:从断点调试到Python复现
1. 逆向分析前的准备工作 第一次接触知乎x-zse-96参数逆向时,我完全是个小白。记得当时为了抓取一些公开的问答数据,直接用requests发请求却总是返回403错误。后来才发现,知乎的接口有个关键的安全校验参数x-zse-96,这个参数的值是…...

避坑指南:uniapp中使用previewImage和downloadFile API的常见问题与解决方案
Uniapp图片预览与下载功能深度避坑指南 在移动应用开发中,图片预览和下载是最基础却又最容易出问题的功能之一。很多开发者第一次使用uniapp的previewImage和downloadFileAPI时,都会遇到各种"坑"——图片加载不出来、下载失败、权限问题、安卓…...

技术选型评估框架需求技术与团队匹配
技术选型评估框架:需求、技术与团队的精准匹配 在快速迭代的软件开发领域,技术选型直接决定项目的成败。如何从众多技术方案中选出最适合团队与业务需求的工具?关键在于构建一个科学的技术选型评估框架,确保需求、技术与团队能力…...

当AI学会编程,我们还能做什么邑
基础示例:单工作表 Excel 转 TXT 以下是将一个 Excel 文件中的第一个工作表转换为 TXT 的完整步骤: 1. 加载并读取Excel文件 from spire.xls import * from spire.xls.common import * workbook Workbook() workbook.LoadFromFile("示例.xlsx"…...

Inter字体深度解析:如何用现代字体系统提升数字产品的可读性与设计一致性
Inter字体深度解析:如何用现代字体系统提升数字产品的可读性与设计一致性 【免费下载链接】inter The Inter font family 项目地址: https://gitcode.com/gh_mirrors/in/inter Inter字体是一款专为屏幕显示设计的开源无衬线字体系统,通过精心优化…...
)
华为网络设备高效巡检命令全解析(运维必备)
1. 华为网络设备巡检命令的重要性 作为网络运维人员,每天最头疼的就是设备突然抽风,业务中断。记得去年双十一大促前夜,我们核心交换机突然丢包严重,要不是靠着几个关键巡检命令快速定位到是BGP邻居状态异常,估计第二天…...

OrCAD原理图打印终极指南:Instance和Occurrence模式选择对PDF标签的影响
OrCAD原理图打印终极指南:Instance和Occurrence模式选择对PDF标签的影响 在复杂电路设计中,原理图的清晰呈现与高效导航直接关系到团队协作效率与后期维护成本。作为Cadence OrCAD的核心功能之一,Instance与Occurrence模式的选择往往被工程师…...

Draw.io ECE插件:5分钟创建专业电路图的终极指南
Draw.io ECE插件:5分钟创建专业电路图的终极指南 【免费下载链接】Draw-io-ECE Custom-made draw.io-shapes - in the form of an importable library - for drawing circuits and conceptual drawings in draw.io. 项目地址: https://gitcode.com/gh_mirrors/dr/…...