Canal+Kafka实现Mysql数据同步
Canal介绍
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
canal可以用来监控数据库数据的变化,从而获得新增数据,或者修改的数据。
canal是应阿里巴巴存在杭州和美国的双机房部署,存在跨机房同步的业务需求而提出的。
阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
canal主要用途是基于 MySQL 数据库增量日志解析,并能提供增量数据订阅和消费,应用场景十分丰富。
目前canal主要支持mysql数据库。
github地址:https://github.com/alibaba/canal
版本下载地址:https://github.com/alibaba/canal/releases
文档地址:https://github.com/alibaba/canal/wiki/Docker-QuickStart
Canal应用场景
1)、电商场景下商品、用户实时更新同步到至Elasticsearch、solr等搜索引擎;
2)、价格、库存发生变更实时同步到redis;
3)、数据库异地备份、数据同步;
4)、代替使用轮询数据库方式来监控数据库变更,有效改善轮询耗费数据库资源。
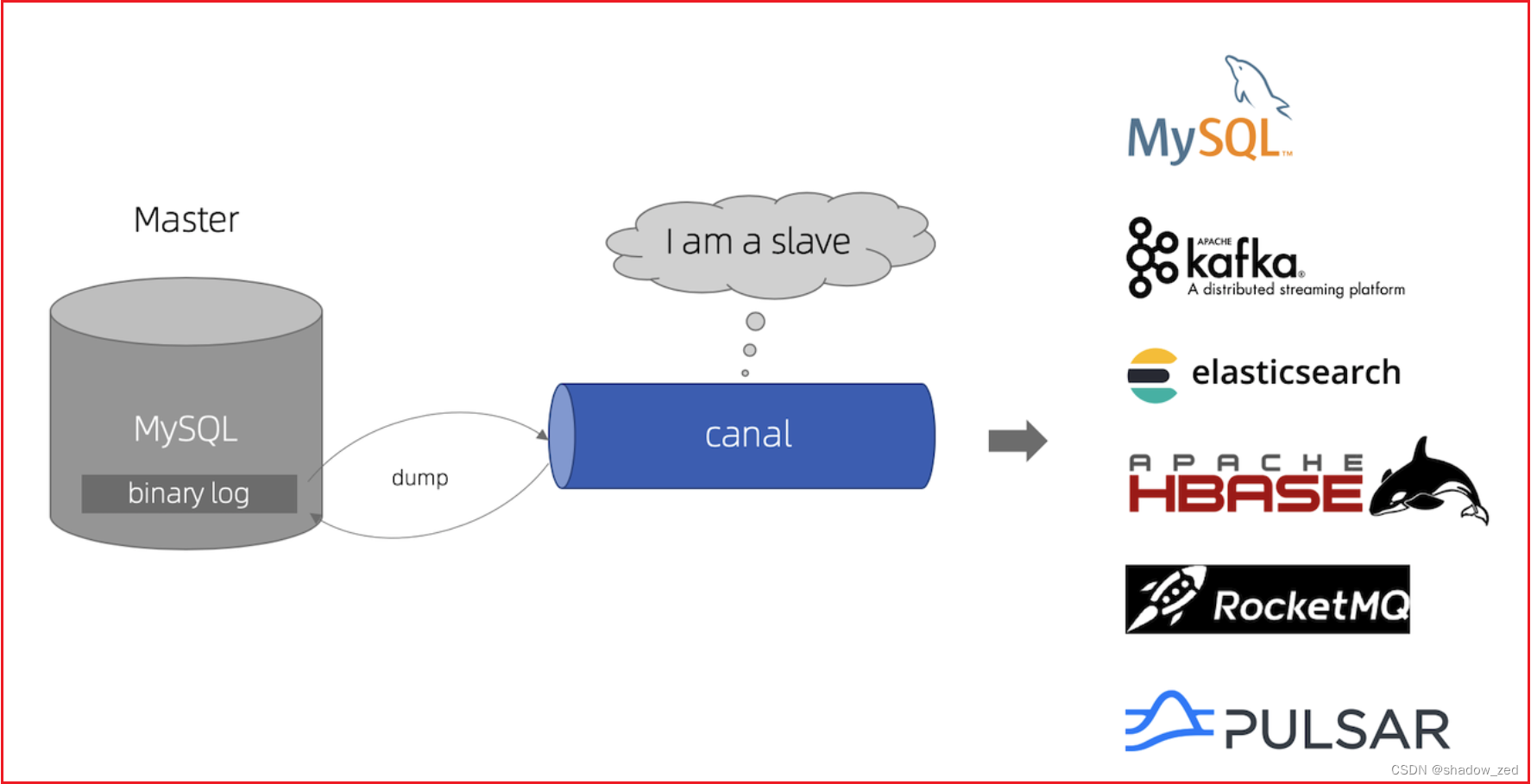

MySQL主从复制原理
1)、MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
2)、MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
3)、MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
Canal工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)

 Canal安装
Canal安装
参考文档:https://github.com/alibaba/canal/wiki/QuickStart
Canal配置
mq相关参数说明 (>=1.1.5版本)
在1.1.5版本开始,引入了MQ Connector设计,参数配置做了部分调整
| 参数名 | 参数说明 | 默认值 |
|---|---|---|
| canal.aliyun.accessKey | 阿里云ak | 无 |
| canal.aliyun.secretKey | 阿里云sk | 无 |
| canal.aliyun.uid | 阿里云uid | 无 |
| canal.mq.flatMessage | 是否为json格式 如果设置为false,对应MQ收到的消息为protobuf格式 需要通过CanalMessageDeserializer进行解码 | false |
| canal.mq.canalBatchSize | 获取canal数据的批次大小 | 50 |
| canal.mq.canalGetTimeout | 获取canal数据的超时时间 | 100 |
| canal.mq.accessChannel = local | 是否为阿里云模式,可选值local/cloud | local |
| canal.mq.database.hash | 是否开启database混淆hash,确保不同库的数据可以均匀分散,如果关闭可以确保只按照业务字段做MQ分区计算 | true |
| canal.mq.send.thread.size | MQ消息发送并行度 | 30 |
| canal.mq.build.thread.size | MQ消息构建并行度 | 8 |
|---|---|---|
| kafka.bootstrap.servers | kafka服务端地址 | 127.0.0.1:9092 |
| kafka.acks | kafka为 | all |
| kafka.compression.type | 压缩类型 | none |
| kafka.batch.size | kafka为 | 16384 |
| kafka.linger.ms | kafka为 | 1 |
| kafka.max.request.size | kafka为 | 1048576 |
| kafka.buffer.memory | kafka为 | 33554432 |
| kafka.max.in.flight.requests.per.connection | kafka为 | 1 |
| kafka.retries | 发送失败重试次数 | 0 |
| kafka.kerberos.enable | kerberos认证 | false |
| kafka.kerberos.krb5.file | kerberos认证 | ../conf/kerberos/krb5.conf |
| kafka.kerberos.jaas.file | kerberos认证 | ../conf/kerberos/jaas.conf |
|---|---|---|
| rocketmq.producer.group | rocketMQ为ProducerGroup名 | test |
| rocketmq.enable.message.trace | 是否开启message trace | false |
| rocketmq.customized.trace.topic | message trace的topic | 无 |
| rocketmq.namespace | rocketmq的namespace | 无 |
| rocketmq.namesrv.addr | rocketmq的namesrv地址 | 127.0.0.1:9876 |
| rocketmq.retry.times.when.send.failed | 重试次数 | 0 |
| rocketmq.vip.channel.enabled | rocketmq是否开启vip channel | false |
| rocketmq.tag | rocketmq的tag配置 | 空值 |
|---|---|---|
| rabbitmq.host | rabbitMQ配置 | 无 |
| rabbitmq.virtual.host | rabbitMQ配置 | 无 |
| rabbitmq.exchange | rabbitMQ配置 | 无 |
| rabbitmq.username | rabbitMQ配置 | 无 |
| rabbitmq.password | rabbitMQ配置 | 无 |
| rabbitmq.deliveryMode | rabbitMQ配置 | 无 |
|---|---|---|
| pulsarmq.serverUrl | pulsarmq配置 | 无 |
| pulsarmq.roleToken | pulsarmq配置 | 无 |
| pulsarmq.topicTenantPrefix | pulsarmq配置 | 无 |
|---|---|---|
| canal.mq.topic | mq里的topic名 | 无 |
| canal.mq.dynamicTopic | mq里的动态topic规则, 1.1.3版本支持 | 无 |
| canal.mq.partition | 单队列模式的分区下标, | 1 |
| canal.mq.enableDynamicQueuePartition | 动态获取MQ服务端的分区数,如果设置为true之后会自动根据topic获取分区数替换canal.mq.partitionsNum的定义,目前主要适用于RocketMQ | false |
| canal.mq.partitionsNum | 散列模式的分区数 | 无 |
| canal.mq.dynamicTopicPartitionNum | mq里的动态队列分区数,比如针对不同topic配置不同partitionsNum | 无 |
| canal.mq.partitionHash | 散列规则定义 库名.表名 : 唯一主键,比如mytest.person: id 1.1.3版本支持新语法,见下文 | 无 |
canal.mq.dynamicTopic 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema 或 schema.table,多个配置之间使用逗号或分号分隔
- 例子1:test\\.test 指定匹配的单表,发送到以test_test为名字的topic上
- 例子2:.*\\..* 匹配所有表,则每个表都会发送到各自表名的topic上
- 例子3:test 指定匹配对应的库,一个库的所有表都会发送到库名的topic上
- 例子4:test\\..* 指定匹配的表达式,针对匹配的表会发送到各自表名的topic上
- 例子5:test,test1\\.test1,指定多个表达式,会将test库的表都发送到test的topic上,test1\\.test1的表发送到对应的test1_test1 topic上,其余的表发送到默认的canal.mq.topic值
为满足更大的灵活性,允许对匹配条件的规则指定发送的topic名字,配置格式:topicName:schema 或 topicName:schema.table
- 例子1: test:test\\.test 指定匹配的单表,发送到以test为名字的topic上
- 例子2: test:.*\\..* 匹配所有表,因为有指定topic,则每个表都会发送到test的topic下
- 例子3: test:test 指定匹配对应的库,一个库的所有表都会发送到test的topic下
- 例子4:testA:test\\..* 指定匹配的表达式,针对匹配的表会发送到testA的topic下
- 例子5:test0:test,test1:test1\\.test1,指定多个表达式,会将test库的表都发送到test0的topic下,test1\\.test1的表发送到对应的test1的topic下,其余的表发送到默认的canal.mq.topic值
大家可以结合自己的业务需求,设置匹配规则,建议MQ开启自动创建topic的能力
canal.mq.partitionHash 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔
- 例子1:test\\.test:pk1^pk2 指定匹配的单表,对应的hash字段为pk1 + pk2
- 例子2:.*\\..*:id 正则匹配,指定所有正则匹配的表对应的hash字段为id
- 例子3:.*\\..*:$pk$ 正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找)
- 例子4: 匹配规则啥都不写,则默认发到0这个partition上
- 例子5:.*\\..* ,不指定pk信息的正则匹配,将所有正则匹配的表,对应的hash字段为表名
- •
按表hash: 一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题)
-
- 例子6: test\\.test:id,.\\..* , 针对test的表按照id散列,其余的表按照table散列
注意:大家可以结合自己的业务需求,设置匹配规则,多条匹配规则之间是按照顺序进行匹配(命中一条规则就返回)
其他详细参数可参考Canal AdminGuide
mq顺序性问题
binlog本身是有序的,写入到mq之后如何保障顺序是很多人会比较关注,在issue里也有非常多人咨询了类似的问题,这里做一个统一的解答
- 1.
canal目前选择支持的kafka/rocketmq,本质上都是基于本地文件的方式来支持了分区级的顺序消息的能力,也就是binlog写入mq是可以有一些顺序性保障,这个取决于用户的一些参数选择
- 2.
canal支持MQ数据的几种路由方式:单topic单分区,单topic多分区、多topic单分区、多topic多分区
- canal.mq.dynamicTopic,主要控制是否是单topic还是多topic,针对命中条件的表可以发到表名对应的topic、库名对应的topic、默认topic name
- canal.mq.partitionsNum、canal.mq.partitionHash,主要控制是否多分区以及分区的partition的路由计算,针对命中条件的可以做到按表级做分区、pk级做分区等
- 1.
canal的消费顺序性,主要取决于描述2中的路由选择,举例说明:
- 单topic单分区,可以严格保证和binlog一样的顺序性,缺点就是性能比较慢,单分区的性能写入大概在2~3k的TPS
- 多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题
- 单topic、多topic的多分区,如果用户选择的是指定table的方式,那和第二部分一样,保障的是表级别的顺序性(存在热点表写入分区的性能问题),如果用户选择的是指定pk hash的方式,那只能保障的是一个pk的多次binlog顺序性 ** pk hash的方式需要业务权衡,这里性能会最好,但如果业务上有pk变更或者对多pk数据有顺序性依赖,就会产生业务处理错乱的情况. 如果有pk变更,pk变更前和变更后的值会落在不同的分区里,业务消费就会有先后顺序的问题,需要注意
性能表现
Kafka + 混合DML场景测试
| 场景 | 1个topic + 单分区 | 1个topic+3分区 | 2个topic+1分区 | 2个topic+3分区 |
|---|---|---|---|---|
| 不开启flatMessage | 29.6k rps (9.71k tps) | 17.54k rps (6.53k tps) | 21.6k rps (7.9k tps) | 16.8k rps (5.71k tps) |
| 开启flatMessage | 11.79k rps (4.36k tps) | 15.97 rps (5.94k tps) | 11.91k rps (4.45k tps) | 16.96k rps (6.26k tps) |
Kafka + 单表的batch insert场景测试
| 场景 | 1个topic + 单分区 | 1个topic+3分区 |
|---|---|---|
| 不开启flatMessage | 59.6k rps | 45.1k rps |
| 开启flatMessage | 51.3k rps | 49.6k rps |
RocketMQ + 混合DML场景测试
| 场景 | 1个topic + 单分区 | 1个topic+3分区 | 2个topic+1分区 | 2个topic+3分区 |
|---|---|---|---|---|
| 不开启flatMessage | 29.6k rps (10.71k tps) | 23.3k rps (8.59k tps) | 26.7k rps (9.46k tps) | 21.7k rps (7.66k tps) |
| 开启flatMessage | 16.75k rps (6.17k tps) | 14.96k rps (5.55k tps) | 17.83k rps (6.63k tps) | 16.93k rps (6.26k tps) |
RocketMQ + 单表的batch insert场景测试
| 场景 | 1个topic + 单分区 | 1个topic+3分区 |
|---|---|---|
| 不开启flatMessage | 81.2k rps | 51.3k rps |
| 开启flatMessage | 62.6k rps | 57.9k rps |
附录:
canal官方文档:https://github.com/alibaba/canal/wiki/Canal-Kafka-RocketMQ-QuickStart
Canal+MQ性能表现:https://github.com/alibaba/canal/wiki/Canal-MQ-Performance
参考文档:https://www.cnblogs.com/zwh0910/p/17043265.html
相关文章:
Canal+Kafka实现Mysql数据同步
Canal介绍 canal [kənl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费 canal可以用来监控数据库数据的变化,从而获得新增数据,或者修改的数据。 canal是应阿里巴巴存在杭…...

K8s部署
K8s部署 一、实验架构 二进制搭建 Kubernetes v1.20 -单master节点部署k8s集群master01:192.168.111.10 kube-apiserver kube-controller-manager kube-scheduler etcd k8s集群master02:192.168.111.20k8s集群node01:192.168.111.20 kubele…...
MongoDB 分片集群
在了解分片集群之前,务必要先了解复制集技术! 1.1 MongoDB复制集简介 一组Mongodb复制集,就是一组mongod进程,这些进程维护同一个数据集合。复制集提供了数据冗余和高等级的可靠性,这是生产部署的基础。 1.1.1 复制集…...

CSDN 编程竞赛六十九期题解
竞赛总览 CSDN 编程竞赛六十九期:比赛详情 (csdn.net) 竞赛题解 题目1、S数 如果一个正整数自身是回文数,而且它也是一个回文数的平方,那么我们称这个数为S数。现在,给定两个正整数L、R,返回包含在范围 [L, R] 中S…...

vue3组合式api单文件组件写法
一,模板部分 <template><div class"device container"><breadcrumb :list"[首页, 应急处置]" /><div class"search_box"><div class"left"><span style"margin-right: 15px"…...
Unity游戏源码分享-多角色fps射击游戏
Unity游戏源码分享-多角色fps射击游戏 项目地址:https://download.csdn.net/download/Highning0007/88204023...

在Cesium中给管道添加水流效果
添加效果前后对比: 关键代码: /*** 水流粒子,目前支持向上或者向下的效果* param {Number} x* param {Number} y* param {Number} z* param {Number} options* example* options {* color: Cesium.Color.AZURE,* emissionRate: 5, …...

测试平台——项目模块模型类设计
这里写目录标题 一、项目应用1、项目包含接口:2、创建子应用3、项目模块设计a、模型类设计b、序列化器类设计c、视图类设计d、项目的增删改查操作4、接口模块设计a、模型类设计b、序列化器类设计c、视图类设计d、接口的增删改查查操作5、环境模块设计a、模型类设计b、序列化器…...
【Android】MVC,MVP,MVVM三种架构模式的区别
MVC 传统的代码架构模式,仅仅是对代码进行了分层,其中的C代表Controller,控制的意思 将代码划分为数据层,视图层,控制层,三层之间可以任意交互 MVP MVP是在MVC基础上改进而来的一种架构,其中的…...
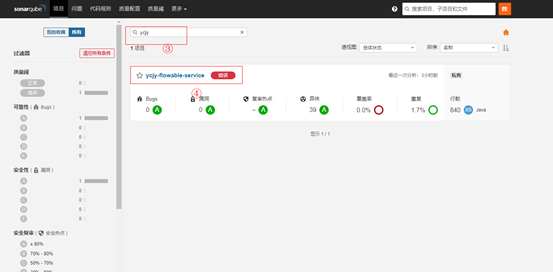
代码质量检查工具SonarQube
Devops流水线之SonarQube 文章目录 Devops流水线之SonarQube1. 软件功能介绍及用途2. 软件环境搭建与使用2.1 使用方法2.2 SonarQube相关属性说明2.3 Sonar配置文件内容说明 3. 使用环节4. 检查方法 1. 软件功能介绍及用途 SonarQube是一个用于代码质量管理的开源平台…...

开发命名规范
1项目命名规范 1、工程项目名,尽量想一些有意义、有传播价值的名称;比如星球、游戏、名人、名地名等;取名就跟给孩子取名一样,独特、有价值、有意义、好传播 2、所有的类都必须添加创建者和创建日期 3、所有代码:包括…...

12. Redis分布式高可用集群搭建
文章目录 Redis分布式高可用集群搭建一、redis集群有三种方式:1. 主从模式2. 哨兵3. 集群(master-cluster) 二、基于centos7操作系统操做1. 关闭防火墙,三台机器都执行2. hostname修改,三台机器都执行,这一步是为了在内…...

【微信小程序篇】-请求封装
最近自己在尝试使用AIGC写一个小程序,页面、样式、包括交互函数AIGC都能够帮我完成(不过这里有一点问题AIGC的上下文关联性还是有限制,会经常出现对于需求理解跑偏情况,需要不断的重复强调,并纠正错误,才能得到你想要的…...

区块链-Web3.0-什么是Web3.0?
一、什么是Web 3.0 Web 3.0,也被称为“去中心化Web”或“智能Web”,是互联网的下一代,它使用了分布式系统技术、区块链技术和智能合约等新型技术,旨在构建一个更加去中心化、安全、透明和智能的互联网。Web 3.0 可以带来更广泛的…...

动手学深度学习(三)线性神经网络—softmax回归
分类任务是对离散变量预测,通过比较分类的概率来判断预测的结果。 softmax回归和线性回归一样也是将输入特征与权重做线性叠加,但是softmax回归的输出值个数等于标签中的类别数,这样就可以用于预测分类问题。 分类问题和线性回归的区别&#…...
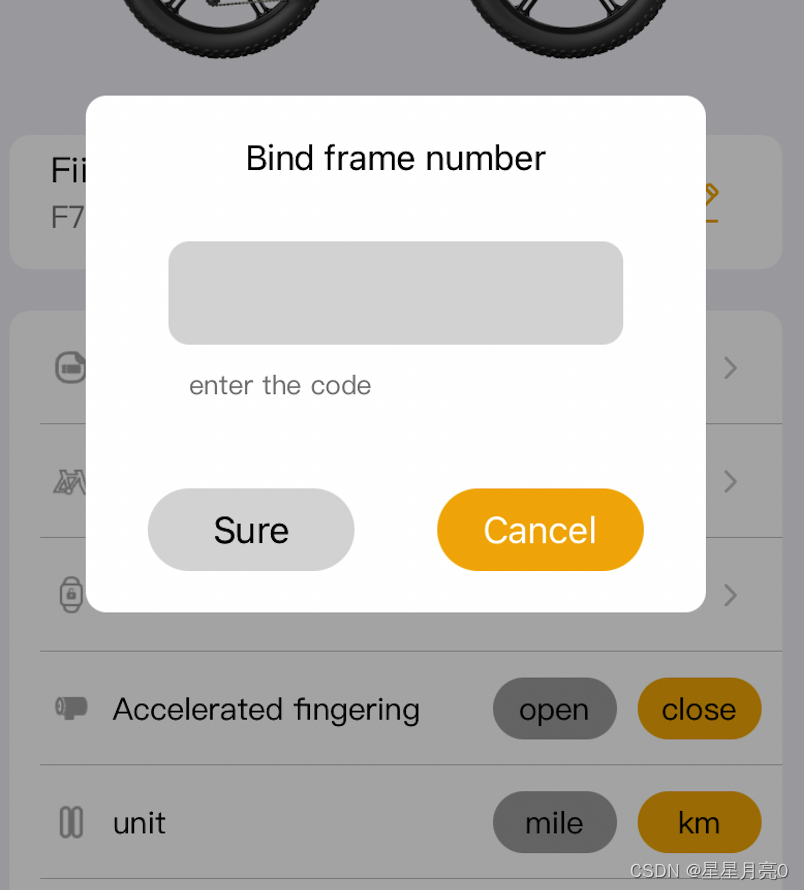
ios swift alert 自定义弹框 点击半透明部分弹框消失
文章目录 1.BaseAlertVC2.BindFrameNumAlertVC 1.BaseAlertVC import UIKitclass BaseAlertVC: GLBaseViewController {let centerView UIView()override func viewDidLoad() {super.viewDidLoad()view.backgroundColor UIColor(displayP3Red: 0, green: 0, blue: 0, alpha:…...
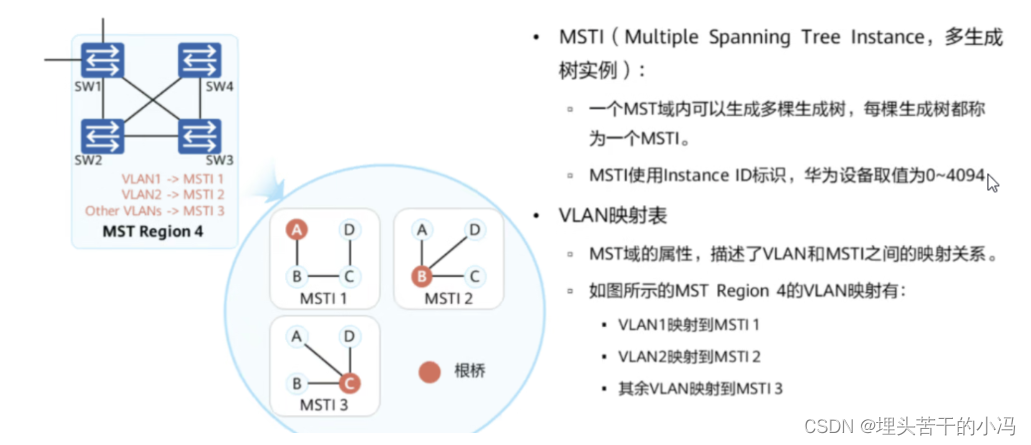
HCIP STP(生成树)
目录 一、STP概述 二、生成树协议原理 三、802.1D生成树 四、STP的配置BPDU 1、配置BPDU的报文格式 2、配置BPDU的工作过程 3、TCN BPDU 4、TCN BPDU的工作过程 五、STP角色选举 1、根网桥选举 2、根端口选举 3、指定端口选举 4、非指定端口选举 六、STP的接口状…...

【Unity开发必备】100多个 Unity 学习网址 资源 收藏整理大全【持续更新】
Unity 相关网站整理大全 众所周知,工欲善其事必先利其器,有一个好的工具可以让我们事半功倍,有一个好用的网站更是如此! 但是好用的网站真的太多了,收藏夹都满满的(但是几乎没打开用过😁)。 所以本文是对…...

Alpine Ridge控制器使其具备多种使用模式 - 英特尔发布雷电3接口:竟和USB Type-C统一了
同时又因为这建立在Type-C的基础上,雷电3也将利用现有的标准Type-C线缆引入有源支持。当使用Type-C的线缆时,雷电的速度就降到了20Gbps全双工——这与普通的Type-C的带宽相同——这是为了成本牺牲了一些带宽。可以比较一下,Type-C线的成本只有…...
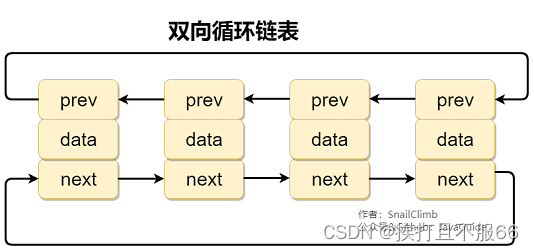
容器——2.Collection 子接口之 List
文章目录 2.1. Arraylist 和 Vector 的区别?2.2. Arraylist 与 LinkedList 区别?2.2.1. 补充内容:双向链表和双向循环链表2.2.2. 补充内容:RandomAccess 接口 2.3 ArrayList 的扩容机制 2.1. Arraylist 和 Vector 的区别? ArrayList 是 List 的主要实现类,底层使…...

Avian Physics与Bevy ECS的完美融合:架构设计与最佳实践
Avian Physics与Bevy ECS的完美融合:架构设计与最佳实践 【免费下载链接】avian ECS-driven 2D and 3D physics engine for the Bevy game engine. 项目地址: https://gitcode.com/gh_mirrors/be/avian Avian Physics是一款专为Bevy游戏引擎打造的ECS驱动型2…...

内容解锁工具:Bypass Paywalls Chrome Clean的全方位信息获取方案
内容解锁工具:Bypass Paywalls Chrome Clean的全方位信息获取方案 在信息爆炸的时代,获取优质内容往往需要付出高昂的订阅费用。Bypass Paywalls Chrome Clean作为一款免费开源的浏览器扩展,为用户提供了突破付费内容限制的解决方案ÿ…...

DHT温湿度传感器驱动库原理与工程实践
1. 项目概述servodht11是一个面向嵌入式 Arduino 生态的轻量级温湿度传感器驱动库,专为 DHT 系列数字传感器(DHT11、DHT22/AM2302、DHT21/AM2301、DHT33、DHT44)设计。尽管项目名称中包含servo字样,但根据其官方 README 文档及实际…...

2026届必备的降AI率平台推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当前,在学术研究这个范畴之内,借助人工智能技术来辅助论文撰写这种行…...

解放你的无人机!DankDroneDownloader:轻松掌控DJI固件的终极指南
解放你的无人机!DankDroneDownloader:轻松掌控DJI固件的终极指南 【免费下载链接】DankDroneDownloader A Custom Firmware Download Tool for DJI Drones Written in C# 项目地址: https://gitcode.com/gh_mirrors/da/DankDroneDownloader 你知道…...

高效掌握Ryujinx:从入门到精通的开源Switch模拟器实战指南
高效掌握Ryujinx:从入门到精通的开源Switch模拟器实战指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx作为一款用C#编写的开源Nintendo Switch模拟器࿰…...

国产化工控机浪潮下:C#上位机统信UOS+鲲鹏架构全栈适配零踩坑指南
去年给天津滨海新区某汽车零部件工厂做工控系统国产化改造,客户的硬指标没有任何商量余地:原有Windows平台的C#焊接上位机系统,必须无缝迁移到统信UOS 20专业版鲲鹏920工控机,724小时稳定运行,满足等保2.0三级要求&…...

终极指南:如何免费解锁Cursor Pro高级功能完整教程
终极指南:如何免费解锁Cursor Pro高级功能完整教程 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial …...

为什么92%的农业SaaS项目死在配置环节?PHP动态表单引擎+拖拽式规则编排实战揭秘
第一章:农业SaaS配置失效的底层归因分析农业SaaS系统中配置失效并非孤立现象,而是由基础设施层、中间件行为、应用逻辑与领域语义四重耦合引发的系统性退化。当作物生长模型参数在生产环境突然回滚至默认值,或灌溉策略调度器持续跳过边缘节点…...

Accio Work 全面解析:从免费白嫖到2000积分时代
Accio Work 全面解析:从免费白嫖到2000积分时代阿里国际推出的企业级 AI Agent 平台,能自主帮你做生意,但它真的免费吗?一、什么是 Accio Work?2026年3月24日,阿里国际在海外正式发布了一款名为 Accio Work…...