MySQL—索引
这里写目录标题
- 索引是什么? 索引优缺点?
- MySQL索引类型
- 索引底层实现? 为什么使用B+树, 而不是B树, BST, AVL, 红黑树等等?
- 什么是聚簇索引和非聚簇索引?
- 非聚簇索引一定会回表吗?
- 什么是联合索引?为什么需要注意联合索引中的字段顺序?
- 什么是最左前缀原则?
- 什么是前缀索引?
- 什么是索引下推?
- 如何查看MySQL语句是否使用到索引?
- 为什么建议使用自增主键作为索引?
- 建立索引的原则
- MySQL 索引优化方式
- 什么情况下索引失效?
- MySQL单表不要超过2000W行,靠谱吗?
- MySQL 使用 like “%x“,索引一定会失效吗?
索引是什么? 索引优缺点?
索引是一种数据结构,用于快速查找和检索数据。它们在很多场景中都非常有用,比如数据库查询、文本搜索引擎和文件系统。当我们谈论索引时,通常是指数据库索引,它们作用于数据库表,通过对表中的一列或多列进行排序和组织,从而提高查询速度。
优点:
-
提高查询速度:索引的主要优点是能显著提高数据查找速度。通过使用索引,数据库可以避免全表扫描,从而更快地定位到所需的数据行。
-
加速表连接:在多表连接查询中,使用索引可以显著提高连接速度。数据库可以利用索引在两个表之间更快地找到匹配的行。
-
提高排序和分组速度:索引可以帮助数据库在排序和分组数据时更高效地工作。如果已经存在一个排序索引,那么数据库在进行排序操作时可以直接使用索引,而不需要额外的排序步骤。
缺点:
-
占用存储空间:索引需要占用额外的存储空间,因为它们本身也是数据结构。对于大型数据库,索引可能占用相当大的空间。
-
插入、更新和删除操作变慢:当对表中的数据进行插入、更新或删除操作时,数据库需要同时更新相关索引。这会导致这些操作的速度变慢,因为每次执行这些操作时,都需要维护索引结构。
-
索引管理和维护开销:创建和维护索引需要额外的计算资源和时间。在数据库中添加或修改索引时,需要进行索引重建,这会消耗大量的计算资源。此外,索引的选择和调优需要专业知识,以确保数据库性能得到优化。
总之,索引是一种在查询速度和数据修改速度之间进行权衡的技术。在选择是否使用索引时,需要根据具体应用场景和需求进行评估。在查询密集型应用中,索引往往非常有益;而在数据更新频繁的场景中,索引可能导致性能下降。因此,在创建和使用索引时,需要充分考虑它们的优缺点。
MySQL索引类型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n8ixZan9-1691570962605)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\image-20230730204209557.png)]](https://img-blog.csdnimg.cn/882e33dc6b75497db897d692d3421d3c.png)
索引底层实现? 为什么使用B+树, 而不是B树, BST, AVL, 红黑树等等?
索引的底层实现通常使用树型数据结构。这是因为树型数据结构在搜索、插入、删除等操作中具有较高的效率。主流的数据库系统(如 MySQL、Oracle、SQL Server 等)主要使用 B-Tree(B 树)或其变种 B+树,作为索引的底层数据结构。下面我们来探讨为什么使用 B+树,而不是其他树型数据结构(如 B 树、BST、AVL、红黑树等)。
B+树相较于B树的优点:
-
B+树的所有叶子节点都存储了索引信息,并且通过指针相互连接,便于进行范围查找。而 B 树只有部分节点存储索引信息,范围查找效率较低。
-
B+树的内部节点只存储键值,不存储实际数据,这使得每个内部节点可以存储更多的键值,从而降低了树的高度。相比之下,B 树的每个节点都存储了实际数据,占用更多空间,树的高度可能更高。
-
B+树的查询性能更稳定,因为所有查询都需要遍历到叶子节点。而在 B 树中,查询性能取决于数据所在的节点层级,可能导致性能波动。
-
叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引;
-
所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表;
-
非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小)。
-
非叶子节点中有多少个子节点,就有多少个索引;
B+树相较于BST、AVL、红黑树等平衡二叉查找树的优点:
-
B+树是多路平衡查找树,每个节点可以有多个孩子,而平衡二叉查找树每个节点只有两个孩子。多路查找树可以减少树的高度,从而降低磁盘 I/O 操作次数,提高查询速度。
-
B+树具有更好的磁盘空间利用率。在数据库系统中,读取磁盘数据的最小单位是页(Page),B+树的节点大小通常设定为页的大小。这样,每次磁盘 I/O 操作可以将一个完整的 B+树节点加载到内存中。而 BST、AVL、红黑树等平衡二叉查找树的节点大小通常远小于页的大小,导致每次磁盘 I/O 操作无法充分利用磁盘空间,降低了空间利用率。
-
平衡二叉查找树在插入和删除操作时,需要进行旋转操作来维护平衡。在数据库系统中,旋转操作可能导致大量的磁盘 I/O 操作,降低性能。而 B+树在插入和删除操作时,只需要分裂和合并节点,不需要进行旋转操作,性能更高。
综上所述,B+树作为数据库索引的底层实现,相较于其他树型数据结构具有较高的查询效率、更好的磁盘空间利用率和更稳定的性能。这些优点使得 B+树成为数据库领域中主流的索引数据结构。
什么是聚簇索引和非聚簇索引?
聚簇索引(Clustered Index)和非聚簇索引(Non-Clustered Index)是两种不同类型的数据库索引,它们在数据存储和查询性能方面有一些区别。以下是关于聚簇索引和非聚簇索引的详细解释:
聚簇索引(Clustered Index):
-
聚簇索引并不是一种独立的索引类型,而是指数据行与索引行在存储上的排列方式。在聚簇索引中,表中的数据行按照索引键的顺序存储在磁盘上。换句话说,聚簇索引定义了表中数据的物理存储顺序。
-
由于聚簇索引决定了数据的物理顺序,因此每个表只能有一个聚簇索引。在具有聚簇索引的表中,数据行的查找非常快,因为索引键值可以直接指向数据行的存储位置。
-
一些数据库管理系统(如 SQL Server 和 MySQL 的 InnoDB 存储引擎)会自动创建聚簇索引。通常情况下,聚簇索引是基于表的主键创建的。
非聚簇索引(Non-Clustered Index):
-
非聚簇索引是一种独立于表数据的索引结构。非聚簇索引存储了索引键值和指向数据行的指针(或数据行的聚簇索引键值)。非聚簇索引与表数据的存储顺序无关,因此可以为表创建多个非聚簇索引。
-
在非聚簇索引中,索引键和数据行分开存储,这意味着查询时需要额外的 I/O 操作来获取数据行。首先,数据库系统需要查找非聚簇索引以找到数据行的指针(或聚簇索引键值),然后再根据指针(或聚簇索引键值)查找数据行。这个过程被称为“回表”(Key Lookup 或 Bookmark Lookup)。
-
非聚簇索引适用于过滤、排序和聚合等操作,特别是当查询只涉及索引键值时(即覆盖索引查询),非聚簇索引的性能非常高。
总之,聚簇索引和非聚簇索引在数据存储和查询性能方面有一些区别。聚簇索引决定了表中数据的物理存储顺序,查询速度快,但每个表只能有一个。非聚簇索引独立于表数据,可以为表创建多个,适用于过滤、排序和聚合等操作。在实际应用中,根据查询需求和性能要求选择合适的索引类型,以优化数据库的整体性能。
区别
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
非聚簇索引一定会回表吗?
非聚簇索引不一定会回表。在某些情况下,非聚簇索引可以避免回表操作,从而提高查询性能。这种情况通常发生在覆盖索引(Covering Index)查询中。覆盖索引是指查询所需的所有列都包含在非聚簇索引中的情况。也就是说,非聚簇索引包含了查询所需的全部数据,因此无需回表到数据行以获取额外的信息。在这种情况下,数据库系统可以直接从非聚簇索引中获取查询结果,从而避免了回表操作。
非聚簇索引不一定会回表。当查询只涉及覆盖索引中的列时,可以避免回表操作,从而提高查询性能。为了充分利用覆盖索引优势,可以根据查询需求设计合适的非聚簇索引,使其包含查询所需的所有列。
什么是联合索引?为什么需要注意联合索引中的字段顺序?
联合索引(Compound Index,也称为复合索引或多列索引)是一种数据库索引,它包含两个或多个列的值。使用联合索引可以根据多个列的值快速定位到数据行。联合索引的主要目的是优化多列过滤条件的查询性能。
在联合索引中,字段顺序非常重要,原因如下:
-
查询性能: 联合索引的查询性能取决于查询条件中涉及的列以及它们在索引中的顺序。当查询条件完全匹配索引的前导列(最左边的列)时,查询性能最佳。如果查询条件仅涉及索引的非前导列,则联合索引可能无法发挥其性能优势。因此,在创建联合索引时,应该将查询条件中最常用的列放在前面,以提高查询性能。
-
索引选择性: 索引选择性(Index Selectivity)是指索引中不重复值的比例。具有较高选择性的索引通常具有更好的查询性能,因为它们可以更快地过滤出不符合条件的行。在创建联合索引时,应将具有较高选择性的列放在前面,以提高索引的选择性。
-
排序和分组操作: 联合索引可以提高排序和分组操作的性能,但这取决于排序或分组列的顺序与索引中的字段顺序相匹配。在创建联合索引时,应考虑将通常用于排序或分组的列放在索引中的适当位置。
-
覆盖索引: 如前所述,覆盖索引(Covering Index)是指查询所需的所有列都包含在索引中,从而避免回表操作。在联合索引中,字段顺序也会影响覆盖索引的性能。因此,在设计联合索引时,应确保查询所需的所有列都包含在索引中,并注意列的顺序。
总之,联合索引中的字段顺序对查询性能、索引选择性、排序和分组操作以及覆盖索引等方面具有重要意义。在创建联合索引时,应根据查询需求和性能要求合理安排字段顺序,以充分发挥联合索引的优势。
什么是最左前缀原则?
最左前缀原则(Leftmost Prefix Principle)是指在使用联合索引(Compound Index)时,查询条件必须使用索引的最左边的一列或连续多列,以便数据库引擎能够充分利用索引来优化查询性能。最左前缀原则是数据库查询优化的一个重要原则,它涉及到联合索引的列顺序和查询条件的匹配。
什么是前缀索引?
前缀索引(Prefix Index)是一种对数据库表中字符串类型列的部分内容进行索引的方法。在某些情况下,为了节省存储空间并提高查询性能,我们可能不需要对整个字符串进行索引,而只需要对字符串的前缀部分进行索引。前缀索引可以减少索引的大小,从而提高查询速度和降低维护成本。
需要注意的是,前缀索引也有一些限制和缺点:
- 兼容性问题: 并非所有数据库系统都支持前缀索引。例如,MySQL 支持前缀索引,而 PostgreSQL 和 SQL Server 则不支持。
- 查询限制: 使用前缀索引时,查询条件中的 LIKE 运算符可能无法充分利用索引。例如,当查询条件中使用了后缀通配符(如
url LIKE 'http://example.com/%')时,前缀索引可以发挥作用;但如果查询条件中使用了前缀通配符(如url LIKE '%/example.html'),前缀索引将无法提高查询性能。 - 准确性问题: 前缀索引可能导致查询结果不准确,因为只有部分字符串内容被索引。因此,在创建前缀索引时,需要确保所选的前缀长度足够区分不同的字符串值。
总之,前缀索引是一种针对字符串类型列的部分内容进行索引的方法,可以节省存储空间并提高查询性能。但在使用前缀索引时,需要注意兼容性问题、查询限制以及准确性问题。
什么是索引下推?
- 索引下推(Index Condition Pushdown,简称 ICP)是一种数据库查询优化技术,它允许数据库管理系统在索引扫描过程中对查询条件进行过滤。通过将过滤操作提前到索引扫描阶段,可以减少从磁盘读取数据的次数,从而提高查询性能。
- 在没有应用索引下推优化的情况下,数据库系统通常会先执行索引扫描,然后将符合索引条件的记录从磁盘加载到内存中,最后再过滤掉不符合其他查询条件的记录。这样做的缺点是,如果有很多记录符合索引条件,但不符合其他查询条件,那么将会产生大量无效的磁盘 I/O。
- 索引下推的优势在于,它将过滤操作提前到索引扫描阶段,这样只有符合所有查询条件的记录才会被加载到内存中。这有助于减少无效的磁盘 I/O,提高查询效率。
- 需要注意的是,索引下推优化并非适用于所有情况,它取决于数据库管理系统的具体实现以及查询条件的复杂程度。在实际应用中,数据库查询优化器通常会自动决定是否启用索引下推优化。
如何查看MySQL语句是否使用到索引?
在MySQL中,你可以使用EXPLAIN命令来查看查询语句的执行计划,从而判断是否使用了索引。EXPLAIN命令会返回关于查询语句如何使用索引、表连接顺序等详细信息。要查看一个查询语句是否使用了索引,你可以在查询语句前加上EXPLAIN关键字,然后执行该语句。
为什么建议使用自增主键作为索引?
使用自增主键作为索引有以下几个原因:
-
唯一性:自增主键保证了每个记录的主键ID是唯一的。这对于数据库系统来说很重要,因为唯一性有助于确保数据的完整性,避免因重复数据导致的问题。唯一的主键也意味着更高效的索引,因为数据库可以直接通过主键查找到唯一的记录,而无需检查其他列。
-
插入性能:自增主键在插入新记录时,会为每个新记录分配一个比前一个记录更大的ID。由于自增主键是递增的,这意味着新插入的数据会被添加到索引的末尾。这对于插入性能有很大的优势,因为数据库不需要在中间位置插入记录并重新调整索引结构。相比之下,如果使用非自增主键作为索引,插入新记录可能会导致索引结构频繁调整,从而降低插入性能。
-
避免热点问题:自增主键在插入新数据时,由于数据是逐步增长的,因此可以避免热点问题。热点问题是指在某个特定区域集中访问数据的情况,这可能导致数据库性能下降。使用自增主键作为索引,可以将数据分散在整个索引结构中,从而避免热点问题。
-
简化查询:使用自增主键作为索引,可以简化查询语句。因为主键ID是唯一的,所以你可以直接根据主键ID查询记录,而无需在查询条件中包含其他列。这有助于提高查询性能,因为数据库只需要检查一个索引列。
需要注意的是,虽然使用自增主键作为索引有很多优势,但这并不意味着它适用于所有情况。在某些特定场景下,使用其他类型的主键或复合索引可能更合适。因此,在设计数据库结构时,需要根据实际需求和性能考虑选择合适的索引策略。
建立索引的原则
建立索引时,需要遵循一定的原则,以确保索引能够提高查询性能并在维护和存储方面保持高效。以下是建立索引的一些建议原则:
-
选择性高的列:索引具有较高选择性的列,即具有大量不同值的列。高选择性的列可以更有效地过滤记录,从而提高查询性能。相反,具有较低选择性的列(如性别、布尔值等)可能不适合建立索引,因为它们不能有效地过滤记录。
-
频繁用于查询条件的列:为经常用于查询条件(如WHERE子句、JOIN操作等)的列创建索引。这可以提高这些查询的性能。同时,也可以考虑创建复合索引,将多个频繁用于查询条件的列组合在一起。
-
用于排序和分组的列:为经常用于排序(ORDER BY子句)和分组(GROUP BY子句)的列创建索引。这可以加速排序和分组操作。
-
避免过多的索引:每个索引都需要额外的存储空间和维护成本。过多的索引会增加数据库的存储需求,并可能降低写操作(如插入、更新和删除)的性能。因此,在创建索引时要权衡利弊,避免为不常用的查询创建不必要的索引。
-
谨慎使用全文索引:全文索引(Full-Text Index)适用于针对大量文本数据的搜索场景。虽然全文索引可以提高文本搜索性能,但它们需要额外的存储空间和维护成本。因此,在创建全文索引时要谨慎评估实际需求。
-
使用合适的索引类型:根据数据类型和查询需求选择合适的索引类型。例如,对于字符串类型的列,可以使用前缀索引(Prefix Index)来减少索引占用的空间。对于地理空间数据,可以使用空间索引(Spatial Index)来提高查询性能。
-
考虑使用覆盖索引:覆盖索引(Covering Index)是包含查询中所有需要的列的索引。当查询只需要访问覆盖索引中的列时,数据库可以避免访问实际的数据表,从而提高查询性能。
-
定期评估和优化索引:数据库的使用模式和数据分布可能会随着时间的推移而发生变化。因此,建议定期评估和优化索引,以确保它们能够适应当前的查询需求。可以使用数据库提供的工具和命令(如MySQL的
EXPLAIN命令)来分析查询性能,并根据需要添加、删除或修改索引。
总之,建立索引的原则是在提高查询性能的同时,尽量减少索引对存储和维护的影响。在设计索引策略时,需要根据实际需求和性能考虑进行权衡。
MySQL 索引优化方式
在 MySQL 中,优化索引是提高查询性能的关键方法之一。以下是一些常见的 MySQL 索引优化方式:
-
选择合适的列进行索引:为查询频繁的列创建索引,这样可以加快查询速度。但不要对过多的列创建索引,因为索引会占用额外的存储空间,并且在插入、更新和删除操作时会增加开销。
-
使用复合索引:复合索引(也称为多列索引)是基于多个列的值创建的索引。复合索引可以在多列条件查询时提高性能。在创建复合索引时,考虑列在查询中的使用顺序并将最常用的列放在索引的前面。
-
使用覆盖索引:覆盖索引是包含查询所需全部列的索引。当查询仅涉及覆盖索引中的列时,MySQL 可以直接从索引中获取数据,而无需访问表本身,从而提高查询性能。考虑在经常一起查询的列上创建覆盖索引。
-
使用前缀索引:前缀索引是基于列值的前缀(而非整个列值)创建的索引。前缀索引可以减少索引的大小,并提高查询速度。在创建前缀索引时,选择合适的前缀长度以平衡索引大小和查询性能。
-
**避免使用 SELECT ***:避免在查询中使用 SELECT * 以减少传输和处理的数据量。相反,仅选择需要的列,这样可以更好地利用覆盖索引。
-
优化 LIKE 查询:避免在 LIKE 查询中使用以百分号(%)开头的模式,因为这会导致索引失效。如果可能,将百分号(%)放在模式的末尾,以便 MySQL 可以利用索引。
-
使用 EXPLAIN 分析查询:使用 EXPLAIN 命令分析查询的执行计划,以了解 MySQL 如何使用索引。根据 EXPLAIN 输出的信息,可以判断是否需要对索引进行优化。
-
定期维护索引:定期使用 OPTIMIZE TABLE 命令对表进行优化,以整理索引并释放未使用的空间。此外,可以使用 ANALYZE TABLE 命令更新表的统计信息,以帮助 MySQL 优化器更好地选择索引。
-
考虑使用索引提示:在某些情况下,MySQL 优化器可能无法选择最佳的索引。可以使用索引提示(例如 USE INDEX、FORCE INDEX 等)来告诉 MySQL 使用特定的索引。
-
了解存储引擎的索引特性:不同的存储引擎(例如 InnoDB、MyISAM 等)具有不同的索引实现和特性。了解所使用的存储引擎的索引特性,并根据这些特性进行优化。
通过上述方法对 MySQL 索引进行优化,可以有效地提高查询性能并减少资源消耗。在实际应用中,需要根据表的结构和查询模式来选择合适的优化策略。
什么情况下索引失效?
-
- 使用 != 或 <>
- 类型不一致导致索引失效
- 函数导致的索引失效, 函数用在索引列时, 不走索引
如 SELECT * FROM t WHERE DATE(create_time) = ‘yyyy-MM-dd’- 运算符导致的索引失效
如 SELECT * FROM t WHERE K-1=2,若有INDEX(K),则不走索引 - OR引起的索引失效
如 SELECT * FROM t WHERE k=1 OR j=2, 若有INDEX(k), 则不走索引, 如果OR连接的时同一个字段, 则不会失效 - 模糊查询导致的索引失效
如 SELECT * FROM t WHRER name = ‘%三’, %放字符串字段前匹配不走索引 - NOT IN, NOT EXISTS导致索引失效
在某些情况下,数据库可能无法使用索引来优化查询,导致索引失效。以下是一些可能导致索引失效的情况:
-
使用函数或表达式:在查询条件中对索引列使用函数或表达式可能导致索引失效。这是因为数据库无法直接比较函数或表达式的结果与索引值。例如,
SELECT * FROM users WHERE LOWER(username) = 'john_doe'。 -
隐式类型转换:如果查询条件中的数据类型与索引列的数据类型不匹配,可能导致隐式类型转换,从而使索引失效。为避免这种情况,确保查询条件中的数据类型与索引列的数据类型一致。
-
使用OR条件:在查询条件中使用OR条件连接多个列可能导致索引失效。这是因为数据库在处理OR条件时可能无法同时使用多个索引。例如,
SELECT * FROM users WHERE username = 'john_doe' OR email = 'john@example.com'。为解决这个问题,可以考虑使用UNION查询代替OR条件。 -
使用%前导通配符:在使用LIKE操作符进行模糊搜索时,如果使用%作为前导通配符,可能导致索引失效。这是因为数据库无法确定搜索字符串的起始位置,从而无法使用索引进行优化。例如,
SELECT * FROM users WHERE username LIKE '%doe'。 -
不等式操作符:在某些情况下,使用不等于(<>)操作符可能导致索引失效。这是因为数据库可能无法有效地使用索引来过滤不等于给定值的记录。
-
复合索引列顺序:在使用复合索引时,查询条件中的列顺序与复合索引中的列顺序不一致可能导致索引失效。为避免这种情况,确保查询条件中的列顺序与复合索引中的列顺序一致。
-
索引选择性较低:如果索引的选择性较低(即索引列的唯一值占总记录数的比例较低),数据库可能会选择全表扫描而不是使用索引来执行查询。这是因为全表扫描在这种情况下可能比使用低选择性的索引更有效。
-
查询优化器的决策:查询优化器可能会基于统计信息、表大小和其他因素来决定是否使用索引。在某些情况下,查询优化器可能认为全表扫描或其他方法比使用索引更有效。这种情况下,索引可能被认为是失效的。
要解决索引失效的问题,可以根据具体情况调整查询语句,确保数据库能够有效地使用索引来优化查询。同时,定期更新数据库统计信息,以帮助查询优化器做出更准确的决策。
MySQL单表不要超过2000W行,靠谱吗?
- MySQL 的表数据是以页的形式存放的,页在磁盘中不一定是连续的。
- 页的空间是 16K, 并不是所有的空间都是用来存放数据的,会有一些固定的信息,如,页头,页尾,页码,校验码等等。
- 在 B+ 树中,叶子节点和非叶子节点的数据结构是一样的,区别在于,叶子节点存放的是实际的行数据,而非叶子节点存放的是主键和页号。
- 索引结构不会影响单表最大行数,2000W 也只是推荐值,超过了这个值可能会导致 B + 树层级更高,影响查询性能。
MySQL 单表行数的上限取决于多个因素,如硬件资源、存储引擎、表结构和查询性能等。因此,是否靠谱要根据具体情况来判断。
在实际生产环境中,有许多 MySQL 单表存储了超过 2000W(即 2000 万)行的记录。然而,在大量数据的情况下,查询和维护性能可能会受到影响。为了避免性能瓶颈,通常采用如下策略:
-
优化索引:为表中的查询频繁的列创建合适的索引,以提高查询性能。合理使用覆盖索引(Covering Index)和前缀索引(Prefix Index)可以帮助减少磁盘 I/O 和内存使用。
-
分区表:MySQL 支持表分区,将一个大表划分为多个独立的子表。这样,查询时只需要扫描相关的子表,而不是整个大表。分区表可以根据不同的分区方法(例如按照范围、列表、哈希等)进行划分。
-
垂直拆分:将一个大表按照列进行拆分,将不常用的列或者较大的列单独存储在一个或多个新表中。这样,查询时只需要访问所需列的数据,减少 I/O 和内存使用。
-
水平拆分:将一个大表按照行进行拆分,将记录分布到多个子表中。这可以通过分布式数据库或者应用层的数据分片(Sharding)实现。通过水平拆分,能够更好地利用硬件资源,提高查询性能。
-
硬件升级:提升服务器的硬件配置,如内存、磁盘和 CPU 等,可以缓解由于大量数据导致的性能问题。
综上所述,MySQL 单表存储 2000W 行记录是可以实现的,但在实际应用中需要根据系统的需求和性能要求进行权衡。如果可能,采用上述策略进行优化,以保持良好的查询和维护性能。
MySQL 使用 like “%x“,索引一定会失效吗?
是的,当你在 MySQL 中使用 LIKE 语句并且模式以百分号(%)开头时,索引通常会失效。这是因为以百分号开头的模式表示任意长度和任意字符的前缀,MySQL 无法在索引中找到特定的起始位置来进行搜索。
相关文章:
MySQL—索引
这里写目录标题 索引是什么? 索引优缺点?MySQL索引类型索引底层实现? 为什么使用B树, 而不是B树, BST, AVL, 红黑树等等?什么是聚簇索引和非聚簇索引?非聚簇索引一定会回表吗?什么是联合索引?为什么需要注意联合索引中的字段顺序?什么是最左前缀原则?什么是前缀索引?…...

Android图形-合成与显示-概论
目录 引言 概念与理解 SurfaceFlinger Surface HWC Fence: Gralloc: DisplayDevice 引言 Activity是Android的主要UI相关组件。通过View的相关类和接口实现,在WMS的管理下,进行窗口和控件的测量,布局和绘制&am…...

Swift 5 数组如何获取集合的索引和对应的元素值
Swift 5 数组如何获取集合的索引和对应的元素值 在Swift 5中,你可以使用enumerated()方法来获取集合的索引和对应的元素值。这个方法会返回一个包含索引和元素的元组数组。以下是使用enumerated()方法来获取一个数组的索引和元素的示例: let array [1…...

计算 Nginx 日志的PV和UV
计算 Nginx 日志的 PV(页面浏览量)和 UV(独立访客数),你需要使用一些工具和技术。 PV(页面浏览量)是指网站的所有页面被访问的总次数,而 UV(独立访客数)则是指…...

Spring中常用的注解
1.声明Bean的注解(标注在类上) Component:表示普通的组件,也可泛指下面三种组件。Controller:控制层。Service:业务逻辑层。Repository:数据访问层。 2.Bean的生命周期的注解 Scope表示设置Spring是如何创建Bean的…...

Plugin 插件
Plugin 插件 插件是 webpack 的支柱功能。插件目的在于解决 loader 无法实现的其他事。Webpack 提供很多开箱即用的插件。 常用插件 clean-webpack-plugin 自动清理输出目录 html-webpack-plugin 自动生成使用 bundle.js 的 HTML copy-webpack-plugin 拷贝文件到输出目…...

Structure needs cleaning fsimage文件系统损坏修复
最近清除数据的时候发现有些文件无法rm [rootnode101 application_1691504014432_0002]# rm -rf ls:* [rootnode101 application_1691504014432_0002]# ls ls: 无法访问flink-dist-cache-8f72398e-9254-42d4-a14d-a0def99b493d: Structure needs cleaning以下操作可能会删除文件…...
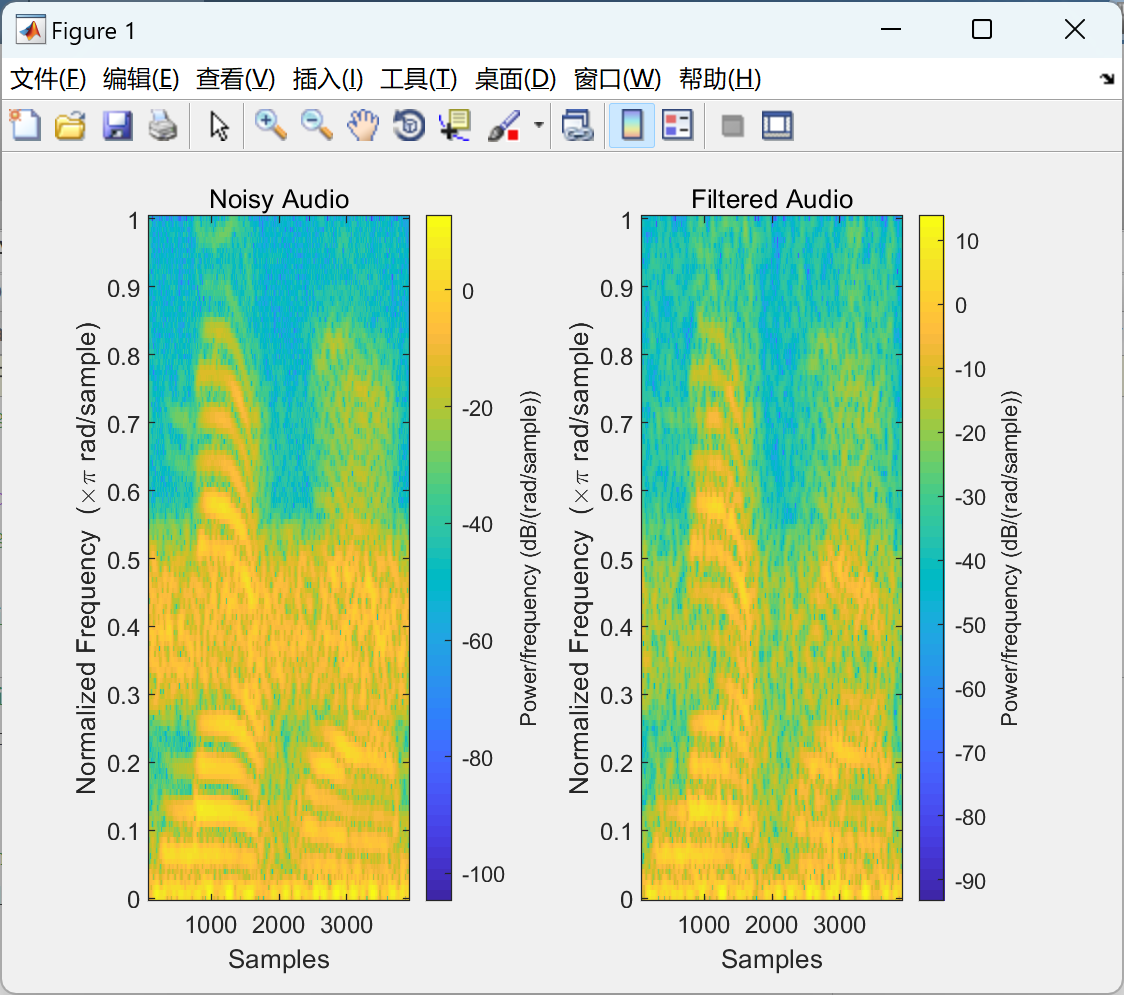
MATLAB|信号处理的Simulink搭建与研究
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
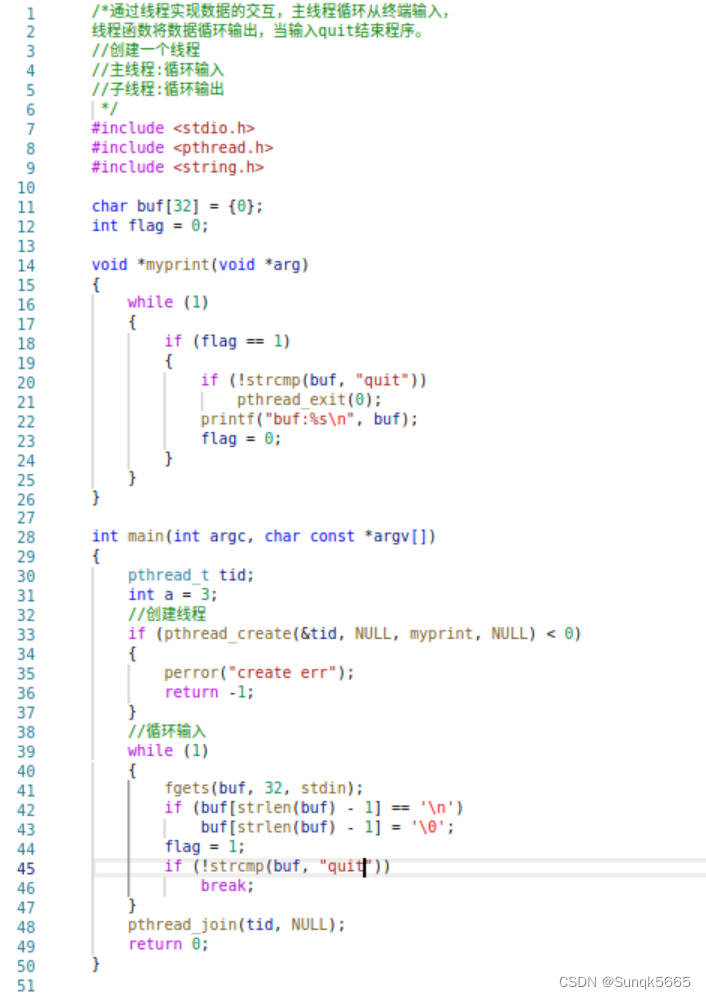
LinuxC编程——线程
目录 一、概念二、进程与线程的区别⭐⭐⭐三、线程资源四、函数接口4.1 线程创建4.2 线程退出4.3 线程回收4.3.1 阻塞回收4.3.2 非阻塞回收 4.4 pthread_create之传参4.5 练习 一、概念 是一个轻量级的进程,为了提高系统的性能引入线程。 进程与线程都参与cpu的统一…...
的实例)
使用fetch调用fastapi接口(post)的实例
前端代码 //定义函数 async function sendRequest(data) {let myurl"http://127.0.0.1:8848/get_student_info"const response await fetch(myurl, {method: POST,mode: cors, // 执行跨域请求headers: {Content-Type: application/json, },body: JSON.st…...
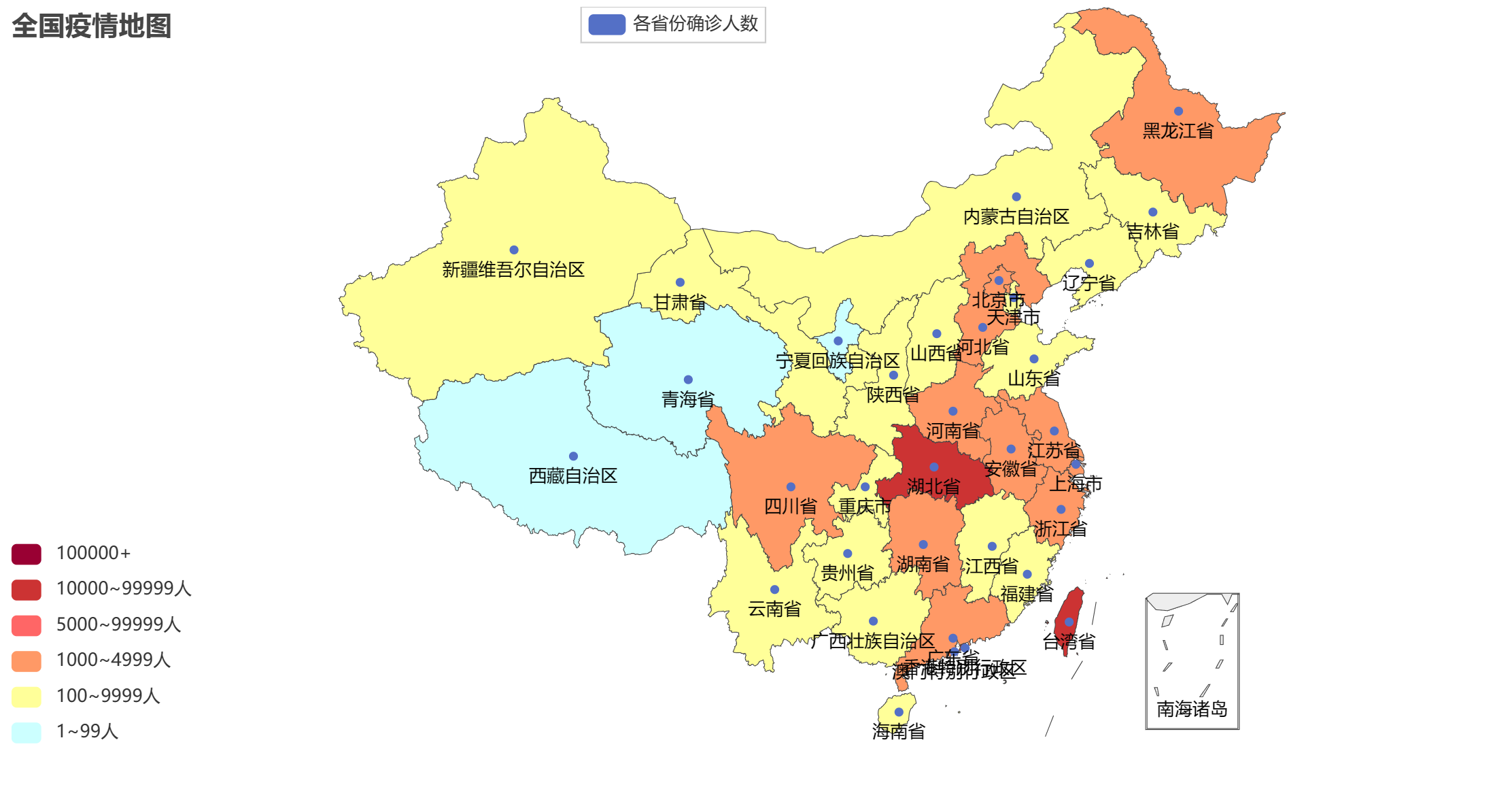
探索规律:Python地图数据可视化艺术
文章目录 一 基础地图使用二 国内疫情可视化图表2.1 实现步骤2.2 完整代码2.3 运行结果 一 基础地图使用 使用 Pyecharts 构建地图可视化也是很简单的。Pyecharts 支持多种地图类型,包括普通地图、热力图、散点地图等。以下是一个构建简单地图的示例,以…...

Django-------自定义命令
每次在启动Django服务之前,我们都会在终端运行python manage.py xxx的管理命令。其实我们还可以自定义管理命令,这对于执行独立的脚本或任务非常有用,比如清除缓存、导出用户邮件清单或发送邮件等等。 自定义的管理命令不仅可以通过manage.p…...

【Linux】在浏览器输入网址后发生了什么事情?
在浏览器输入网址后发生了什么事情? 1.域名解析2.建立TCP连接3.发出HTTP请求4.响应请求5.TCP断开连接6.解析资源和布局渲染 其实我们在浏览器输入网址后,发生了如下的事情 1.域名解析 由于计算机是无法识别我们输入的地址的,那么就需要将当前…...
推荐两本书《JavaRoadmap》、《JustCC》
《JavaRoadmap》 前言 本书的受众 如果你是一名有开发经验的程序员,对 Java 语言语法也有所了解,但是却一直觉得自己没有入门,那么希望这本书能帮你打通 Java 语言的任督二脉。 本书的定位 它不是一本大而全的书,而是一本打通、…...

使用基于jvm-sandbox的对三层嵌套类型的改造
使用基于jvm-sandbox的对三层嵌套类型的改造 问题背景 先简单介绍下基于jvm-sandbox的imock工具,是Java方法级别的mock,操作就是监听指定方法,返回指定的mock内容。 jvm-sandbox 利用字节码操作和自定义类加载器的技术,将原始方法…...

[HDLBits] Mt2015 q4b
Circuit B can be described by the following simulation waveform: Implement this circuit. module top_module ( input x, input y, output z );//001 100 010 111assign z(xy); endmodule...

C++:堆排序
堆排序 输入一个长度为n的整数数列,从小到大输出前m小的数 输入格式 第一行包含整数n和m 第二行包含n个整数,表示整数数列 输出格式 共一行,包含m个整数,表示整数数列中前m小的数 数据范围 1 ≤ m ≤ n ≤ 1 0 5 1\le m\le …...
Grafana Prometheus 通过JMX监控kafka
第三方kafka exporter方案 目前网上关于使用Prometheus 监控kafka的大部分资料都是使用一个第三方的 kafka exporter,他的原理大概就是启动一个kafka客户端,获取kafka服务器的信息,然后提供一些metric接口供Prometheus使用,随意它…...

vue项目切换页面白屏不显示解决方案
问题描述 1、页面切换后白屏,同时切换回上一个页面同样白屏 2、刷新后正常显示 3、有警告:Component inside <Transition> renders non-element root node that cannot be animated 解决方法 <Transition>中的组件呈现不能动画化的非元素…...
Goland报错 : Try to open it externally to fix format problem
这句报错的意思也就是 : 尝试在外部打开以解决格式问题 解决方案 : 将图片格式该为.png格式,再粘贴进去就可以了! 改变之后的效果 : 那么,这样就ok了...

算法工程师的随身匕首:PyTorch 极简入门与实战
PyTorch 快速入门指南 一、PyTorch 是什么? PyTorch 是一个基于 Python 的深度学习框架,由 Facebook AI Research 开发。它以动态计算图和直观的接口著称,是研究和生产中最受欢迎的框架之一。 二、环境安装 # 基础安装(CPU版本&am…...

保姆级教程:在YOLOv8.yaml里手动添加P2层,让你的模型看清8x8像素的小目标
在YOLOv8中集成P2层的实战指南:从配置文件修改到性能优化 当面对监控摄像头中快速移动的蚂蚁群或是卫星图像里的小型车辆时,传统目标检测模型往往会力不从心。这些8x8像素级别的微小目标,恰恰是许多实际应用场景中的关键检测对象。本文将彻底…...

DoL-Lyra整合包:三步打造你的专属Degrees of Lewdity游戏体验
DoL-Lyra整合包:三步打造你的专属Degrees of Lewdity游戏体验 【免费下载链接】DOL-CHS-MODS Degrees of Lewdity 整合 项目地址: https://gitcode.com/gh_mirrors/do/DOL-CHS-MODS 你是否厌倦了在Degrees of Lewdity英文原版游戏中费力查找词典?…...

赋能每一份热爱,你的专属AI创作伙伴「小加同学」来了!
这个时代,「把热爱做成事业」很难吗?有深耕内容的自媒体人,熬到深夜写文调图,却总难抓住流量密码;有奔走忙碌的OPC创业者,对需求、理素材、出方案,被琐事消磨;有坚守初心的中小商家&…...

毕业设计新方式:8款AI工具让论文与代码不再困难
文章总结表格(工具排名对比) 工具名称 核心优势 aibiye 精准降AIGC率检测,适配知网/维普等平台 aicheck 专注文本AI痕迹识别,优化人类表达风格 askpaper 快速降AI痕迹,保留学术规范 秒篇 高效处理混AIGC内容&…...
)
Shell脚本自动化监控:用curl的-w参数批量检查网站健康状态(附完整脚本)
Shell脚本自动化监控:用curl的-w参数批量检查网站健康状态 最近在维护公司十几个微服务时,我发现手动检查每个接口状态简直是一场噩梦。直到重新审视了curl的-w参数,才意识到这个被低估的功能能带来怎样的效率革命。本文将分享如何用Shell脚本…...

MicroBlaze 大程序 Flash 固化与自启
MicroBlaze 大程序 Flash 固化与自启1. 核心原因分析:为什么大程序不能直接固化?在带 ARM 核的 FPGA(如 Zynq 系列)中,硬件内置了 BootROM 和 FSBL 机制,可以自动处理镜像打包和 DDR 初始化。但在 纯 FPGA&…...

【网络层-ICMP互联网控制报文协议】
网络层-ICMP互联网控制报文协议一、概念二、应用三、报文类型一、概念 1.专门用来传递网络状态、报错、探测连通性的 “网络信使 / 反馈员”。 2.IP协议只管发包,不管包有没有送到、有没有丢包,ICMP就是给IP做辅助、报错、探测的。 3.ICMP告诉发送方&am…...

、SEATA分布式事务——XA模式奖
MySQL 中的 count 三兄弟:效率大比拼! 一、快速结论(先看结论再看分析) 方式 作用 效率 一句话总结 count(*) 统计所有行数 最高 我是专业的!我为统计而生 count(1) 统计所有行数 同样高效 我是 count(*) 的马甲兄弟…...
)
AI:词向量模型详解(Word Embedding)
词向量模型详解(Word Embedding) 词向量(Word Embedding)是自然语言处理(NLP)中最基础且影响深远的表示学习方法之一。它将离散的词汇映射为低维、稠密的实数向量,使计算机能够“理解”词语之间…...