分布式数据库视角下的存储过程
存储过程很好呀,那些用不好的人就是自己水平烂,不接受反驳!我就有过这样念头,但分布式数据库,更倾向少用或不用存储过程。
1 我从C/S时代走来
C/S架构时代的末期最流行开发套件是PowerBuilder和Sybase数据库:
- PowerBuilder可视化开发工具,像VB,开发好的程序运行在用户的PC终端上,通过驱动程序连接远端的数据库
- Sybase当时正与Oracle争夺数据库大头,和SQL Server有很深渊源,两者在架构和语言很像
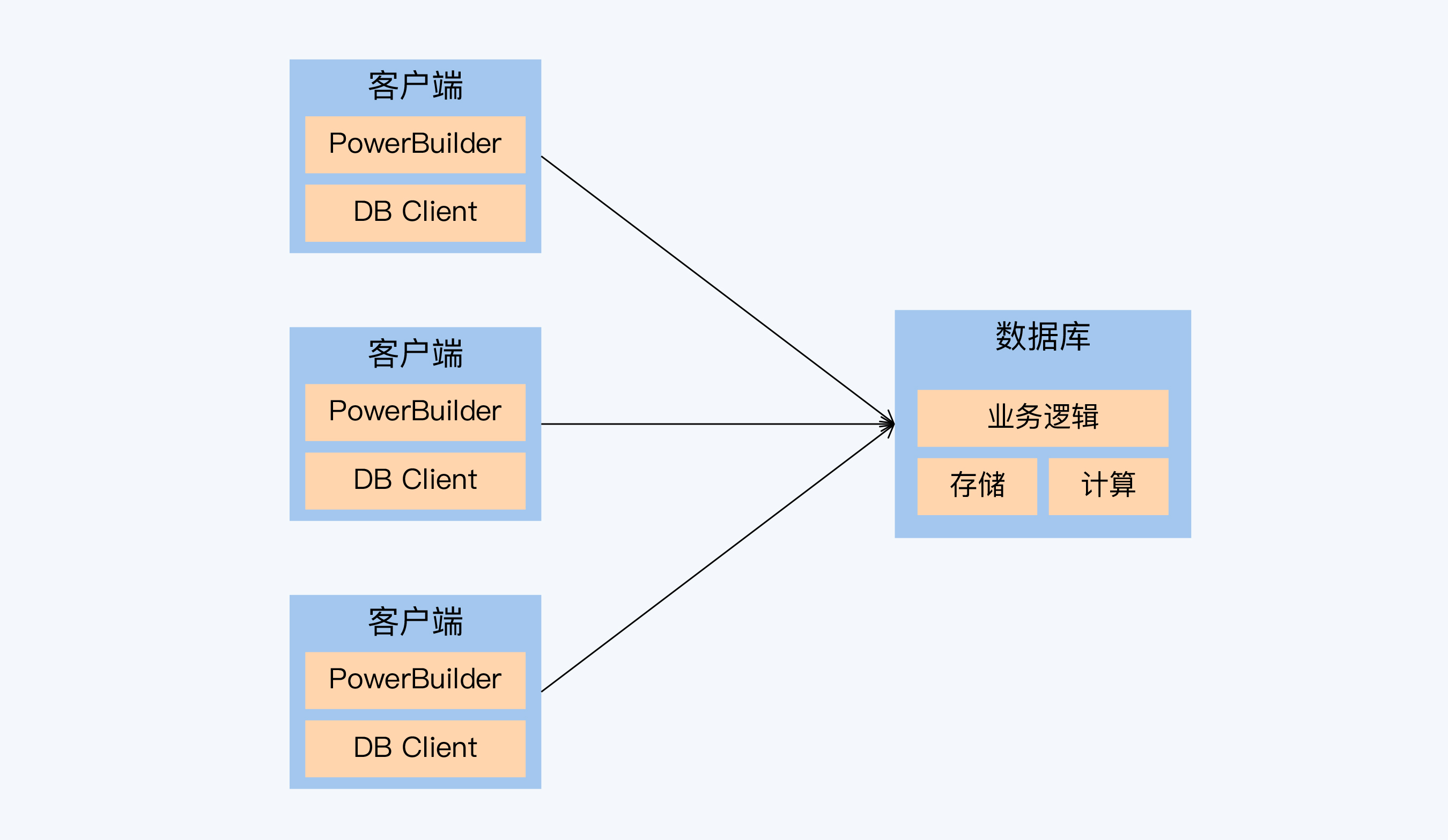
这C/S架构中,数据库不仅承担数据存储、计算功能,还要运行很重的业务逻辑,相当于数据库同时承担应用服务器(Application Server)的大多数功能。而这些业务逻辑的技术载体就是存储过程。所以,不管是Sybase还是Oracle,它们存储过程的功能都很强大。
2 触发器被抛弃
进入B/S,大家对数据库理解变化了,应用服务器承载服务器端主要业务逻辑,那还用存储过程吗?和今天问题一样。当时的主流观点认为存储过程还有存在价值,但它同胞兄弟触发器则被彻底抛弃。

触发器和存储过程一样也是自定义函数,但:
- 它不是显式调用,而是在操作数据表时被动触发,即执行insert、update和delete时
- 还可以选择触发时机是在操作前还是操作后,即before和after的语义
听上去功能强大,有点面向事件编程。但维护过触发器逻辑就发现这是大坑。随业务发展和变更,触发器逻辑越来越复杂,就有人会在触发器的逻辑里操纵另一张表,而那张表上又有其他触发器牵连到其他表,变成天网。踏错一小步,经过一串连锁反应就变成大灾难。所以,触发器退出历史舞台。(感觉还是没有过多限制,导致了滥用)
3 存储过程的优点
调用清晰,不存在触发器问题。优点明显,逻辑运行在数据库,没有网络传输数据的开销,所以在进行数据密集型操作时,性能优势突出。
当时要开发功能,追溯业务实体间的影响关系,如A影响B,B又影响到C。这个功能就是要以A为输入,把B和C都找出来,当然这个影响关系不只是三层了,一直要追溯到所有被影响实体。
典型的关联关系查询,适合用图数据库。但那时候还没可用图数据库,需在Oracle解决这问题。有一个比我更年轻的同事写了一段Java代码来实现这个功能,我猜他没有经历过C/S时代。程序运行起来,应用服务器不断地访问这张表,处理每一条记录的关联关系。性能可想而知,在一个数据量较少的测试环境上,程序足足跑了三十分钟。这大大超出了用户的容忍范围,必须要优化。
我换成存储过程来实现同样的逻辑,因为不需要网络传输,性能大幅度提升。最后,存储过程花了大概二十几秒就得到了同样的结果。干得漂亮!。
4 存储过程的问题
后来发现这方案移植性差。开发的产品要部署到客户环境,受相关基础软件制约。
有次,刚好碰到客户没使用Oracle,所以其他同事将我写的逻辑翻写到客户使用的数据库。可移植到TDB之后的存储过程没跑出结果,直接失败退出。跟踪了这段代码,最后发现问题不在逻辑本身,而在数据库。这段逻辑中我使用了递归算法,因为Oracle支持很深的递归层次,所以运行没问题;而TDB只支持有限的递归层次,而当时数据关联关系又比较多,所以程序没跑多久,就报错退出。
这段经历让我对存储过程的信心有一点动摇。存储过程对于环境有很重的依赖,而这个环境并不是操作系统和Java虚拟机这样遵循统一标准、有大量技术资料的开放环境,而是数据库这个不那么标准的黑盒子。
然而,存储过程的问题还不止于此。当我在C/S架构下开发时,就遇到了存储过程难以调试的问题,只不过当时大家都认为这是必须付出的代价。但是随着B/S架构的到来,Java代码的开发测试技术不断发展,相比之下存储过程难调试的问题就显得更突出了。而到了今天,敏捷开发日渐普及,DevOps工具链迅速发展,而存储过程呢,还是“遗世独立”的样子。
说了这么多,我希望你明白的是,今天的存储过程和当年的触发器,本质上面临的是同样的问题:一种技术必须要匹配同时代的工程化水平,与整个技术生态相融合,否则它就要退出绝大多数应用场景。
你看,《阿里巴巴Java开发手册》中也赫然写着“禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。”我想,他们大概是有和我类似的心路历程吧。
5 分布式数据库的支持情况
大多NewSQL分布式数据库仍不支持存储过程。OceanBase是例外,它在2.2版本增加对Oracle存储过程的支持。我认为这是它全面兼容Oracle策略的产物。但OceanBase官方说明很清楚,目前存储过程的功能还不满足生产要求。
对遗留系统的兼容可能就是今天存储过程最大意义。对那些从MySQL向分布式数据库迁移的系统,这诉求可能没那么强烈,因为这些系统没那么倚重存储过程。因为MySQL较晚版本才提供存储过程,而且功能也没Oracle强大,用户依赖小多了。存储过程没得到NewSQL广泛支持,还因架构难题。
看看业界尝试。
Google 2018年VLDB上发布F1新论文” F1 Query: Declarative Querying at Scale”。提出通过独立UDF Server支持自定义函数,即存储过程。这架构中,因为F1完全独立于数据存储,所以UDF Server自然也就被抽了出来。从论文提供的测试数据看,这个设计保持较高性能,但我觉得这和Google强大的网络设施有很大关系,在普通企业网络条件下能否适用,这还很难说。
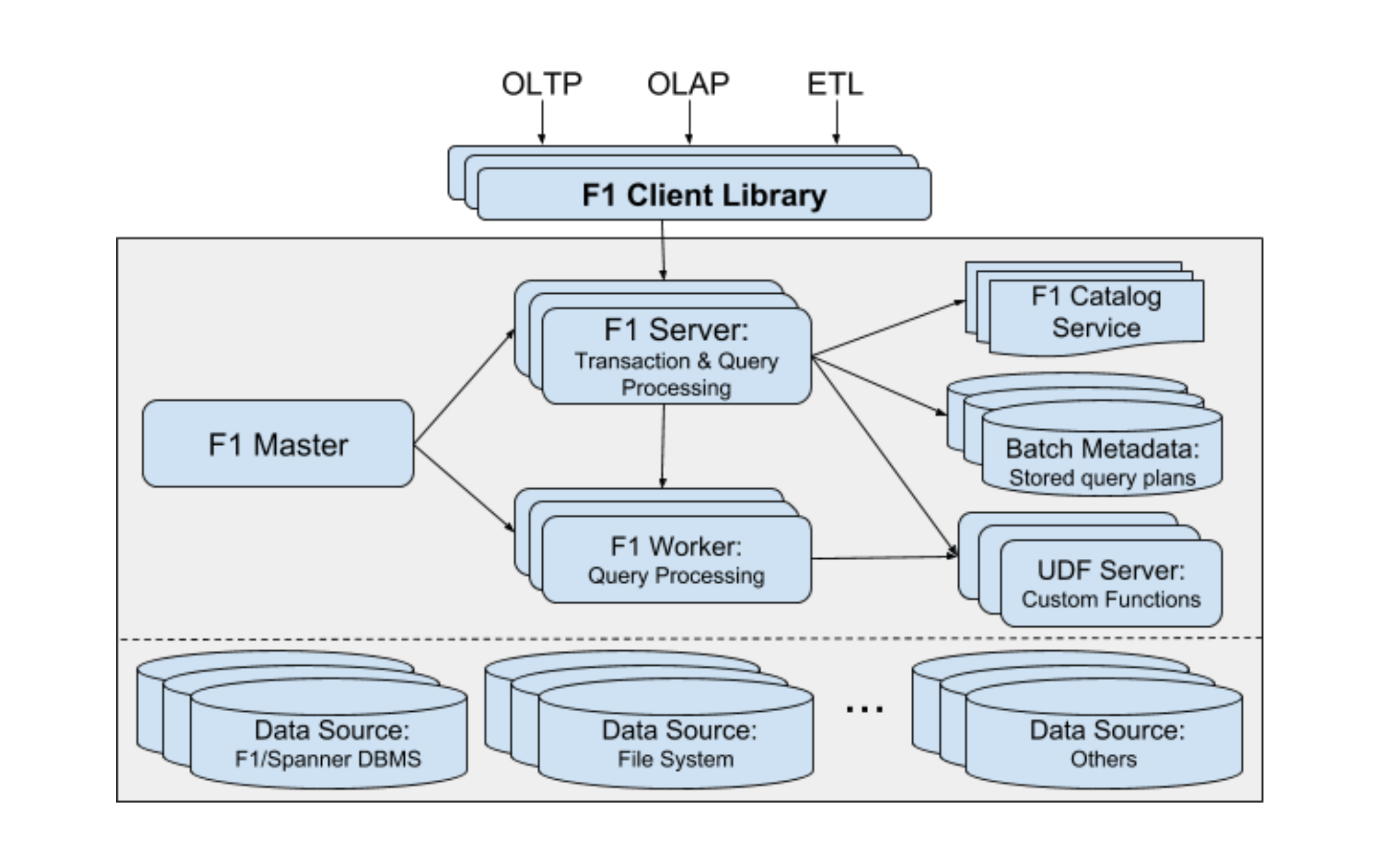
UDF Server的设计
- UDF实现了对通用语言的支持,除了SQL,还支持C++、Java、Go等多种语言实现方式。这样不依赖于数据库的SQL方言,逻辑表述的通用性更好。
- UDF并没有耦合在存储层。这意味着它的上下文环境可以更加开放。
这意味存储过程的调试问题可能得到明显改善,使其与DevOps体系对接成为可能。
更早的VoltDB也已对存储过程改革。VoltDB是基于内存的分布式数据库,由数据库领域传奇迈克尔 · 斯通布雷克(Micheal Stonebraker)主导开发。VoltDB将存储过程作为主要操作方式,并支持Java语言编写。开发者可继承系统提供的父类(VoltProcedure)开发自己的存储过程:
import org.voltdb.*;
public class LeastPopulated extends VoltProcedure {//待执行的SQL语句public final SQLStmt getLeast = new SQLStmt(" SELECT TOP 1 county, abbreviation, population "+ " FROM people, states WHERE people.state_num=?" + " AND people.state_num=states.state_num" + " ORDER BY population ASC;" );//执行入口public VoltTable[] run(int state_num) throws VoltAbortException {//赋输入参数voltQueueSQL( getLeast, state_num ); //SQL执行函数return voltExecuteSQL();}
}
先定义SQL,其中“state_num=?”是预留参数位置,而后在入口函数run()中赋参并执行。
VoltDB设计理念与众不同,很重视CPU使用效率。他们对传统数据库进行了分析,认为普通数据库只有12%的CPU时间在做真正有意义的数据操作,所以它的很多设计都是围绕着充分利用CPU资源。
存储过程实质上是预定义的事务,没有人工交互过程,也就避免CPU等待。同时,因存储过程的内容可预知,所以能尽早将数据加载到内存,进一步减少网络和磁盘I/O带来的CPU等待。
正是由于存储过程和内存的使用,VoltDB即使在单线程模型下也获得了很好的性能。反过来,单线程本身也让事务控制更加简单,避免了传统的锁管理的开销和CPU等待,提升了VoltDB的性能。
与其他数据库相比,存储过程对VoltDB意义已截然不同。
6 总结
- 存储过程移植差。高度依赖数据库环境,而数据库环境不像操作系统或虚拟机那样遵循统一的标准。因为同样的原因,存储过程调试也很复杂,也没有跟上敏捷开发的步伐,与今天工程化的要求不匹配。正是因为这两个工程化方面原因,不用或少用存储过程
- 分布式数据库角度,多数NewSQL还不支持存储过程,OceanBase作为唯一的例外,已经支持Oracle存储过程,但仍然没有达到生产级。
- F1的论文提出了独立UDF Server的思路,是分布式架构下存储过程的一种实现方案,但能不能适合普通的企业网络环境,尚待观察。但这个方案中,存储过程的实现语言不局限于SQL方言,而是放宽到多种主流语言,向标准兼容,具备更好的开放性。这提升了存储过程技术与DevOps融合的可能性。
- VoltDB作为一款内存型分布式数据库,以存储过程作为主要的操作定义方式,支持使用Java语言开发。甚至可以说,VoltDB的基础就是存储过程这种预定义事务方式。存储过程、内存存储、单线程三者互相影响,使得VoltDB具备出色的性能表现。
对于任何一个程序员来说,放弃一种已经熟练掌握而且执行高效的技术,必然是一个艰难的决定。但是今天,对于大型软件系统而言,工程化要求远比某项技术本身更加重要。不能与整个技术生态协作的技术,最终将无法避免被边缘化的命运。当你学习一门新技术前,无论是分布式数据库还是微服务,我都建议你要关注它与周边生态是否能够适配,因为符合潮流的技术有机会变得更好,而太过小众的技术则蕴藏了更大的不确定性。
参考
- Bart Samwel: F1 Query: Declarative Querying at Scale
7 FAQ
VoltDB的设计思路很特别,除了单线程、大量使用内存、存储过程支持Java语言外,它在数据的复制上的设计也是别出心裁,既不是NewSQL的Paxos协议也不是PGXC的主从复制,你能想到是如何设计的吗?复制机制和存储过程是有一定关系的。
1.业务代码跟技术代码应该要分离,我们需要保证业务逻辑到业务代码的翻译简单而纯粹。这既是在实现阶段,降低对具体技术的耦合,也是在保证业务代码的可测试性以及业务代码的简单和内聚。
2.具体技术的特性(比如存储过程)往往能起到杰出的性能。但这也增加了实现阶段的复杂性,而复杂意味着难维护,意味着成本和风险。虽然实现了软件行为价值,但架构质量上的健康却受到了伤害。所以在性能要求严格的场景,使用具体技术的一些特性无可厚非,但要保持警惕,认清这是把双刃剑。不可仗着自己"功力深厚"而肆意妄为。
3.没经历过c/s的时代。但从数据模型驱动设计的相关书籍中,可以看到存储过程在当初是如何的大行其道。可是放在现在,当存储过程等一系列手段成过去式后,数据模型驱动设计就开始变得很"贫血"。基本只剩实体关系模型和数据项这点单薄的信息承载能力,已经不适合再驱动复杂的业务软件的设计。
4.放上自己对数据模型驱动的实现,以做交流: https://github.com/Jxin-Cai/mdd/tree/master/data-model/mini-faas
VoltDB的这个分片复制和rocketMq的nameserver有异曲同工之妙。通过并行对所有副本执行操作,规避副本间达成共识的复杂性。
OceanBase支持Oracle的存储过程迫不得已,因为这决定着它是否能 “侵入” Oracle的传统客户阵营-大企业和金融领域,是纯商业行为。Oracle 的ERP产品大量采用存储过程来实现业务逻辑,最复杂的业务逻辑的源码打印出来几十页,这么复杂的存储过程,相信OceanBase的工具无法完美处理(移植到OB),但为竞标之类的商业行为,你如果不支持Oracle的很多特性,你就根本没有参与的机会。
VoltDB用K-safety机制解决数据复制的问题,其实就是N+1的副本机制,VoltDB在写数据操作的时候,会在每个副本中执行该语句,这样就可以保证数据被正确插入每个副本。这N+1的副本都可以同时提供访问,同时允许最多N个副本丢失(分区故障), 当N+1个副本都不可用的时候,VoltDB就会停止服务进行修复。
“《阿里巴巴 Java 开发手册》“禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。” 有误导嫌疑,这里存储过程针对MySQL,确实难以调试难以复制。在同等时代的产品产品中以oracle的PL/SQL,SQL server 的T-SQL编写的存储过程还是很有优势,DB2和Oracle都支持PL/SQL的,这里PL/SQL是具有移植性的,并且这个存储过程在SQL标准中叫做(SQL/PSM (SQL/Persistent Stored Modules) https://en.wikipedia.org/wiki/SQL/PSM)。
阿里开发手册的这条建议不是特指MySQL,放在MySQL这一章可能因为MySQL在阿里使用比较多,是有代表性的数据库。难道他们一边宣传禁用MySQL存储过程,一边暗地里快乐的用着Oracle的存储过程?似乎不大可能。
纵贯SQL标准的发展以及oracle的发展,存储过程的支持也是有发展历程的,存储过程在性能和开发效率上还是蛮高的。在大数据时代人们讲存储分离,存储归存储,计算归计算,在硬件和成本平衡的基础上,通过水平扩展来增加算力,把存储过程功能暂时不开发或者说难以开发,但是Apache hive是支持的存储过程的叫做hpsql。
另外,SQL标准对所有数据库都只是参照,不同的数据库,数据类型、全局变量、函数、甚至存储过程名的长度都有差异。没有完全相同的数据库,除非是专门适配。这也是为什说系统切换数据库是个大事。
在分布式数据库中的典型的代表 TiDB和CockroachDB 二者在语法兼容以及对存储过程的支持上有些不同,CockroachDB是支持pg语法的存储过程的(pg类似于PL/SQL)?
了解这些差异后,有的同学可能依然觉得这不是事,so easy。对个体来说,难还是易是个很主观的判断,关键在于你的团队是否能长期、低成本的使用这项技术,如果可以那也未尝不可。
既然存储过程都支持用JAVA了,那数据复制应该就可借鉴TCC,直接在代码层也就相当于是“服务层”实现,而且又基于内存,重试成本较低,直接用代码往节点里写得了?
都是基于内存,但与Redis不同,应该不会要求那么高的性能,直接用线程池同时往数据节点里写数据。
存储过程是单机数据库时代的不可替代的产物,当年我当程序员的时候,存储过程是最好的解决前后端代码分离的利器。一个10万条订单批量审核的操作,调用存储过程几分钟搞定,前端vb代码执行,一个小时都出不了结果?
是的,存储过程对于数据密集型计算,绝对是一大利器。
clickhouse的物化视图其实是个触发器,这种应该从什么角度分析?
ClickHouse 中的物化视图(MaterializedView)从机制上来看,确实可以看作是一种触发器。
- 功能角度
物化视图的作用是对某张基础表进行预计算,实时维护SELECT查询的结果,功能上相当于创建了一个实时更新的缓存视图。这与触发器在数据变更时自动执行预设操作的功能类似。
- 实现机制角度
ClickHouse通过引擎创建物化视图,当基础表有数据变更时,会自动触发物化视图的更新。这利用了引擎的触发器机制来实现物化视图的实时性。
- 使用场景角度
物化视图可用于数据分析、Dashboard等需要快速访问聚合结果的场景,取代重复查询,这与触发器的用途有相通之处。
- 性能角度
物化视图通过缓存提高读性能,但会增加写负载。需要权衡读写比例来决定是否使用。这也体现了触发器的性能权衡特点。
- 限制角度
物化视图对查询有各种限制条件,这些限制也是触发器通常需要考虑的因素。
综上,从多角度来看,ClickHouse的物化视图确实可看作一种特殊的触发器,对理解和使用物化视图都有帮助。这给了我一个新的角度来分析数据库中的各种自动化机制。
相关文章:
分布式数据库视角下的存储过程
存储过程很好呀,那些用不好的人就是自己水平烂,不接受反驳!我就有过这样念头,但分布式数据库,更倾向少用或不用存储过程。 1 我从C/S时代走来 C/S架构时代的末期最流行开发套件是PowerBuilder和Sybase数据库…...

深度学习常用的激活函数
深度学习的核心思想是通过多层次的神经网络结构,逐步抽取和表示数据中的高级特征,从而实现对复杂数据模式的学习和识别。 神经网络结构: 深度学习使用多层次的神经网络,包括输入层、隐藏层和输出层。这些网络结构允许模型自动学习…...
深度学习之用PyTorch实现逻辑回归
0.1 学习视频源于:b站:刘二大人《PyTorch深度学习实践》 0.2 本章内容为自主学习总结内容,若有错误欢迎指正! 代码(类比线性回归): # 调用库 import torch import torch.nn.functional as F#…...
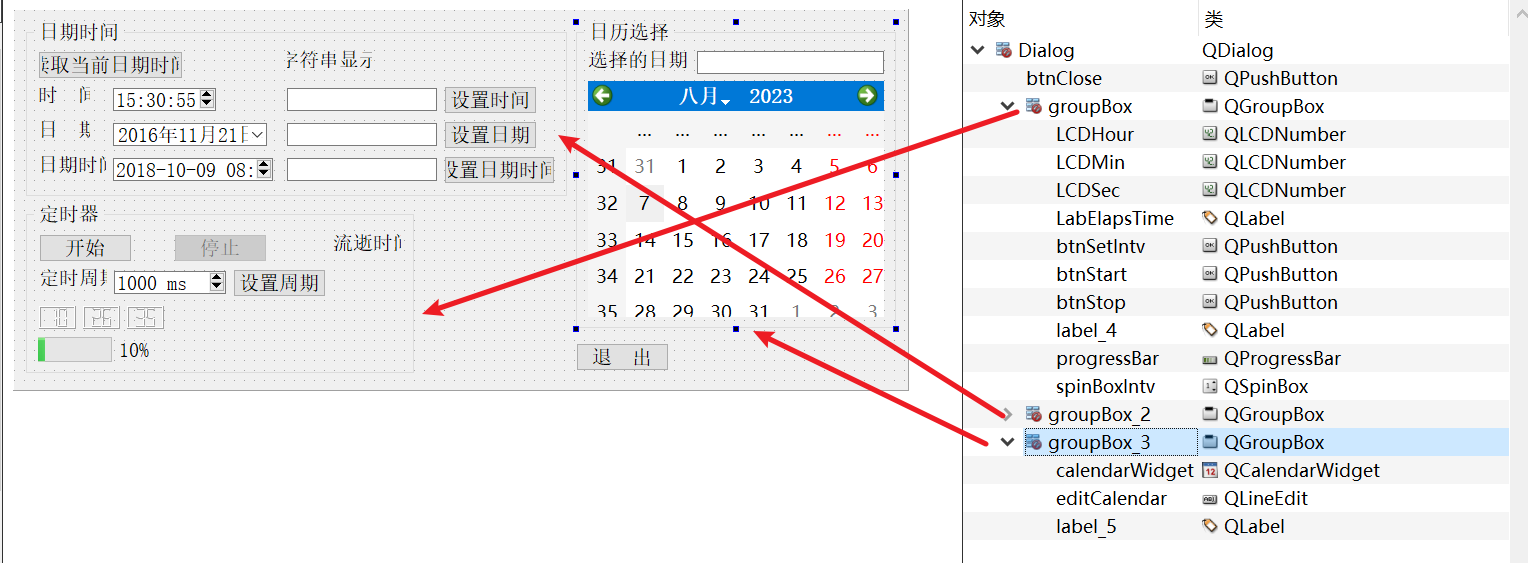
04-4_Qt 5.9 C++开发指南_时间日期与定时器
文章目录 1. 时间日期相关的类2. 源码2.1 可视化UI设计2.2 dialog.h2.3 dialog.cpp 1. 时间日期相关的类 时间日期是经常遇到的数据类型,Qt 中时间日期类型的类如下。 QTime:时间数据类型,仅表示时间,如 15:23:13。 QDate:日期数据类型&…...
7个顶级开源数据集来训练自然语言处理(NLP)和文本模型
推荐:使用 NSDT场景编辑器快速助你搭建可二次编辑的3D应用场景 NLP现在是一个令人兴奋的领域,特别是在像AutoNLP这样的用例中,但很难掌握。开始使用NLP的主要问题是缺乏适当的指导和该领域的过度广度。很容易迷失在各种论文和代码中ÿ…...

GitHub上受欢迎的Android UI Library
内容 抽屉菜单ListViewWebViewSwitchButton按钮点赞按钮进度条TabLayout图标下拉刷新ViewPager图表(Chart)菜单(Menu)浮动菜单对话框空白页滑动删除手势操作RecyclerViewCardColorDrawableSpinner布局模糊效果TabBarAppBar选择器(Picker)跑马灯日历时间主题样式ImageView通知聊…...

cpm log2((cpm/10) + 1) nmf 1e6 1e5
Gene expression units explained: RPM, RPKM, FPKM, TPM, DESeq, TMM, SCnorm, GeTMM, and ComBat-Seq Read count、CPM、 RPKM、FPKM和TPM的区别 - 简书 (jianshu.com) http://zyxue.github.io/2017/06/02/understanding-TCGA-mRNA-Level3-analysis-results-files-from-fir…...
竞赛项目 深度学习的视频多目标跟踪实现
文章目录 1 前言2 先上成果3 多目标跟踪的两种方法3.1 方法13.2 方法2 4 Tracking By Detecting的跟踪过程4.1 存在的问题4.2 基于轨迹预测的跟踪方式 5 训练代码6 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的视频多目标跟踪实现 …...

如何避免用waveformRecord复制数组
这里描述如何使用数组字段内存管理特定。这使得数组数据能够被移入和移出waveform,aai和aao类型的值字段(BPTR)。 使用这种特定包括用另一个(用户分配的)字段替代存储在BPTR字段的指针。基本规则是: 1、BPTR以及它当前指向的内存,只能在这个…...
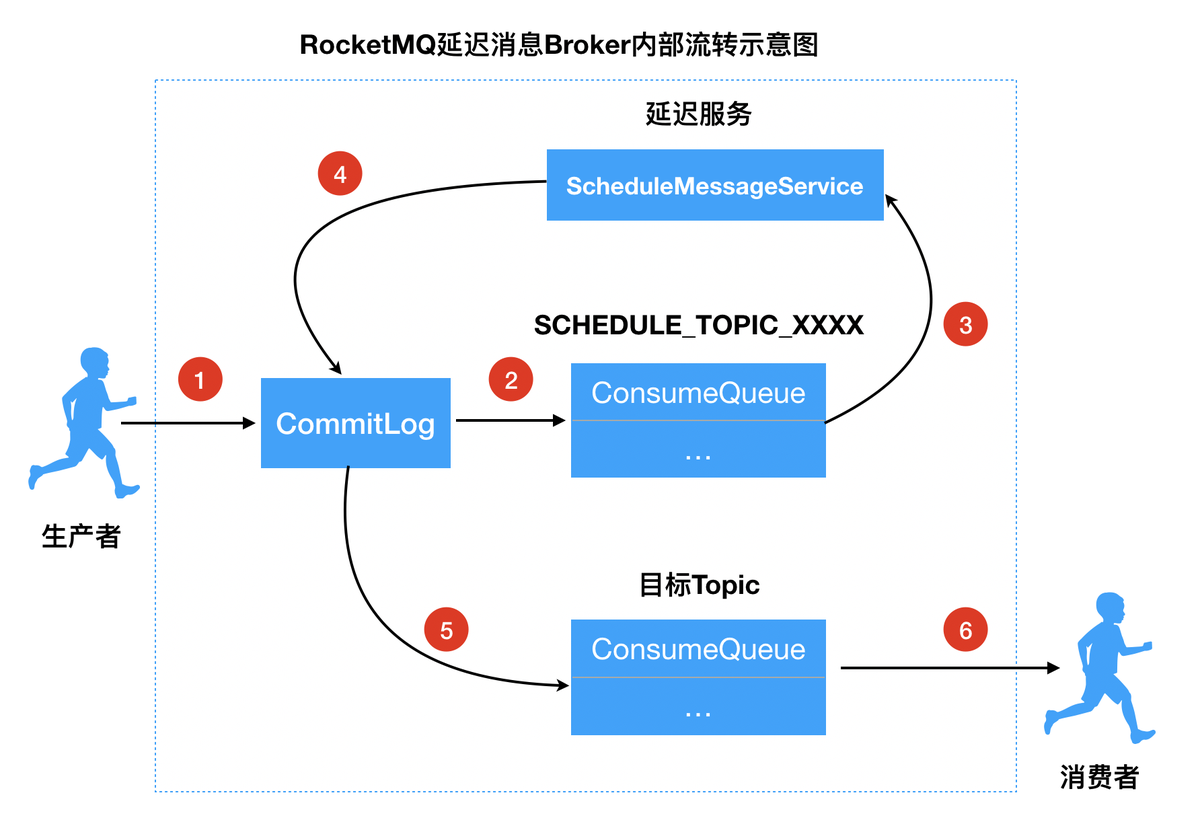
RocketMQ 延迟消息
RocketMQ 延迟消息 RocketMQ 消费者启动流程 什么是延迟消息 RocketMQ 延迟消息是指,生产者发送消息给消费者消息,消费者需要等待一段时间后才能消费到。 使用场景 用户下单之后,15分钟未支付,对支付账单进行提醒或者关单处理…...
Dex文件混淆(一):BlackObfuscator
Dex文件混淆(一):BlackObfuscator 首发地址:http://zhuoyue360.com/crack/105.html 文章目录 Dex文件混淆(一):BlackObfuscator1. 前言2.小试牛刀3. 参考学习1. dex2jar源码简析2. BlackObfuscator简析1. 控制流平坦化1. 控制流平坦化基本介绍 2. Dex解析…...
)
Linux下编译arm 32 出错(/bin/bash: arm-none-linux-gnueabi-gcc: command not found )
一、arm-none-linux-gnueabi-gcc不能再64位系统下下编译ARM的32位库的问题解决方法如下: sudo apt-get install lib32stdc6 sudo apt-get install lib32ncurses5 sudo apt-get install lib32z1 二、交叉编译工具没有写入环境变量或写错,重新写入环境变量…...

最近遇到的两个小问题总结:git问题和node问题
这两个问题都是我帮别人看问题的解决的,在windows系统上遇到的: 1、git没有配置全局变量 在使用git的时候,报’git‘不是内部或外部命令,也不是可运行的程序。然后再在其他文件下面试一下(git --version)…...
)
Java # Spring(1)
一、概念 1、核心技术:依赖注入(DI),AOP,事件(events),资源,i18n,验证,数据绑定,类型转换,SpEL。 2、测试:模…...

SCL更换阿里数据源
问题: zabbix安装前端环境报错 yum install zabbix-web-mysql-scl zabbix-apache-conf-scl -y 报错:Could not retrieve mirrorlist http://mirrorlist.centos.org/ 能上网 但是不能ping通http://mirrorlist.centos.org/ 解决: 修改repo数…...
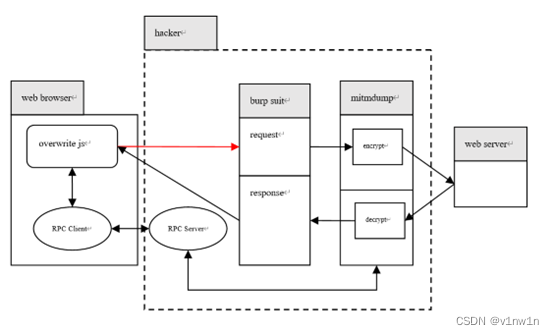
【web逆向】全报文加密流量的去加密测试方案
aHR0cHM6Ly90ZGx6LmNjYi5jb20vIy9sb2dpbg 国密混合 WEB JS逆向篇 先看报文:请求和响应都是全加密,这种情况就不像参数加密可以方便全文搜索定位加密代码,但因为前端必须解密响应的密文,因此万能的方法就是搜索拦截器,…...
Django实现音乐网站 ⑼
使用Python Django框架制作一个音乐网站, 本篇主要是后台对专辑、首页轮播图原有功能的基础上进行部分功能实现和显示优化。 目录 专辑功能优化 新增编辑 专辑语种改为下拉选项 添加单曲优化显示 新增单曲多选 更新歌手专辑数、专辑单曲数 获取歌手专辑数 保…...
【脚踢数据结构】
(꒪ꇴ꒪ ),Hello我是祐言QAQ我的博客主页:C/C语言,Linux基础,ARM开发板,软件配置等领域博主🌍快上🚘,一起学习,让我们成为一个强大的攻城狮!送给自己和读者的一句鸡汤🤔&…...

uni-app使用vue语法进行开发注意事项
目录 uni-app 项目目录结构 生命周期 路由 路由跳转 页面栈 条件编译 文本渲染 样式渲染 条件渲染 遍历渲染 事件处理 事件修饰符 uni-app 项目目录结构 组件/标签 使用(类似)小程序 语法/结构 使用vue 具体项目目录如下: 生命…...

iPhone USB网络共享驱动终极解决方案:快速解决Windows连接问题
iPhone USB网络共享驱动终极解决方案:快速解决Windows连接问题 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.co…...

别再到处找驱动了!STM32CubeMX安装后,CH340和ST-LINK驱动一键搞定指南
STM32开发板驱动安装全攻略:CH340与ST-LINK疑难解析 引言:为什么你的开发板无法识别? 当你兴冲冲地安装完STM32CubeMX,准备开始第一个嵌入式项目时,最令人沮丧的莫过于插上开发板后电脑毫无反应。这种"最后一公里…...
)
STM32智能光照监控DIY:当BH1750检测到光线过暗,蜂鸣器报警并OLED实时显示(源码开源)
STM32智能光照监控系统实战:从传感器到报警的完整实现 在智能家居和工业自动化领域,环境光照监控是一个基础但极其重要的功能。想象一下,当你需要确保实验室的精密仪器始终处于适宜光照环境中,或者希望为家中的植物提供恰到好处的…...

5分钟实现XGP存档完整提取:游戏进度无损迁移终极方案
5分钟实现XGP存档完整提取:游戏进度无损迁移终极方案 【免费下载链接】XGP-save-extractor Python script to extract savefiles out of Xbox Game Pass for PC games 项目地址: https://gitcode.com/gh_mirrors/xg/XGP-save-extractor XGP存档提取器是一个专…...
在YOLO、DeepLabV3+等模型中的实战调参心得)
从语义分割到目标检测:空洞卷积(Atrous Conv)在YOLO、DeepLabV3+等模型中的实战调参心得
空洞卷积在YOLO与DeepLabV3中的工程实践:从参数设计到性能调优 当我们在Cityscapes数据集上尝试将YOLOv5的SPPF模块替换为膨胀率为[1, 2, 5]的空洞卷积时,mAP指标意外下降了1.2%。这个现象引发了我对空洞卷积实际应用场景的深度思考——为什么理论上的感…...

OneMore:5个核心模块重塑你的OneNote生产力工作流
OneMore:5个核心模块重塑你的OneNote生产力工作流 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore 每天,全球数百万用户依赖OneNote进行知识管理…...

SAM数据引擎:AI与人类协同的实例分割标注革命
1. SAM数据引擎:AI与人类协同的标注革命在计算机视觉领域,实例分割一直被视为最具挑战性的任务之一。与简单的物体检测不同,实例分割需要精确到像素级别地识别和标注图像中的每一个对象。传统纯人工标注方式在面对数百万张图像时,…...

猫抓浏览器插件完整指南:5分钟掌握网页视频下载终极技巧
猫抓浏览器插件完整指南:5分钟掌握网页视频下载终极技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到这样的情况&…...

AI编程助手自动化脚本:解放双手,提升开发效率
1. 项目概述:解放双手的AI编程伴侣 如果你和我一样,每天都在使用Cursor或Windsurf这类AI驱动的IDE进行开发,那你一定对那个重复了无数次的流程感到熟悉:敲下指令,等待AI生成代码,眼睛在屏幕上扫描那个小小的…...

如何快速配置Unity游戏AI翻译插件:XUnity.AutoTranslator完全指南
如何快速配置Unity游戏AI翻译插件:XUnity.AutoTranslator完全指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语Unity游戏而烦恼吗?想轻松玩转全球游戏却受限于语言障…...