Spark(38):Streaming DataFrame 和 Streaming DataSet 转换
目录
0. 相关文章链接
1. 基本操作
1.1. 弱类型 api
1.2. 强类型
1.3. 直接执行 sql
2. 基于 event-time 的窗口操作
2.1. event-time 窗口理解
2.2. event-time 窗口生成规则
3. 基于 Watermark 处理延迟数据
3.1. 什么是 Watermark 机制
3.2. update 模式下使用 watermark
3.3. append 模式下使用 wartermark
3.4. watermark 机制总结
4. 流数据去重
5. join操作
5.1. Stream-static Joins
5.1.1. 内连接
5.1.2. 外连接
5.2. Stream-stream Joins
5.2.1. inner join
4.2.2. outer join
6. Streaming DF/DS 不支持的操作
0. 相关文章链接
Spark文章汇总
1. 基本操作
在 DF/DS 上大多数通用操作都支持作用在 Streaming DataFrame/Streaming DataSet 上。
准备处理数据: people.json
{"name": "Michael","age": 29,"sex": "female"}
{"name": "Andy","age": 30,"sex": "male"}
{"name": "Justin","age": 19,"sex": "male"}
{"name": "Lisi","age": 18,"sex": "male"}
{"name": "zs","age": 10,"sex": "female"}
{"name": "zhiling","age": 40,"sex": "female"}1.1. 弱类型 api
代码示例:
import org.apache.spark.sql.types.{LongType, StringType, StructType}
import org.apache.spark.sql.{DataFrame, SparkSession}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 创建格式,并读取数据val peopleSchema: StructType = new StructType().add("name", StringType).add("age", LongType).add("sex", StringType)val peopleDF: DataFrame = spark.readStream.schema(peopleSchema).json("/Project/Data/json")// 弱类型 apival df: DataFrame = peopleDF.select("name", "age", "sex").where("age > 20")df.writeStream.outputMode("append").format("console").start.awaitTermination()// 关闭执行环境spark.stop()}
}结果输出:
-------------------------------------------
Batch: 0
-------------------------------------------
+-------+---+------+
| name|age| sex|
+-------+---+------+
|Michael| 29|female|
| Andy| 30| male|
|zhiling| 40|female|
+-------+---+------+1.2. 强类型
代码示例:
import org.apache.spark.sql.types.{LongType, StringType, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 创建格式,并读取数据val peopleSchema: StructType = new StructType().add("name", StringType).add("age", LongType).add("sex", StringType)val peopleDF: DataFrame = spark.readStream.schema(peopleSchema).json("/Project/Data/json")// 强类型,转成 dsval peopleDS: Dataset[People] = peopleDF.as[People]val df: Dataset[String] = peopleDS.filter((_: People).age > 20).map((_: People).name)df.writeStream.outputMode("append").format("console").start.awaitTermination()// 关闭执行环境spark.stop()}
}case class People(name: String, age: Long, sex: String)结果输出:
-------------------------------------------
Batch: 0
-------------------------------------------
+-------+
| value|
+-------+
|Michael|
| Andy|
|zhiling|
+-------+1.3. 直接执行 sql
代码示例:
import org.apache.spark.sql.types.{LongType, StringType, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 创建格式,并读取数据val peopleSchema: StructType = new StructType().add("name", StringType).add("age", LongType).add("sex", StringType)val peopleDF: DataFrame = spark.readStream.schema(peopleSchema).json("/Project/Data/json")// 直接执行SQL,创建临时表peopleDF.createOrReplaceTempView("people")val df: DataFrame = spark.sql("select * from people where age > 20")df.writeStream.outputMode("append").format("console").start.awaitTermination()// 关闭执行环境spark.stop()}
}结果输出:
-------------------------------------------
Batch: 0
-------------------------------------------
+-------+---+------+
| name|age| sex|
+-------+---+------+
|Michael| 29|female|
| Andy| 30| male|
|zhiling| 40|female|
+-------+---+------+2. 基于 event-time 的窗口操作
2.1. event-time 窗口理解
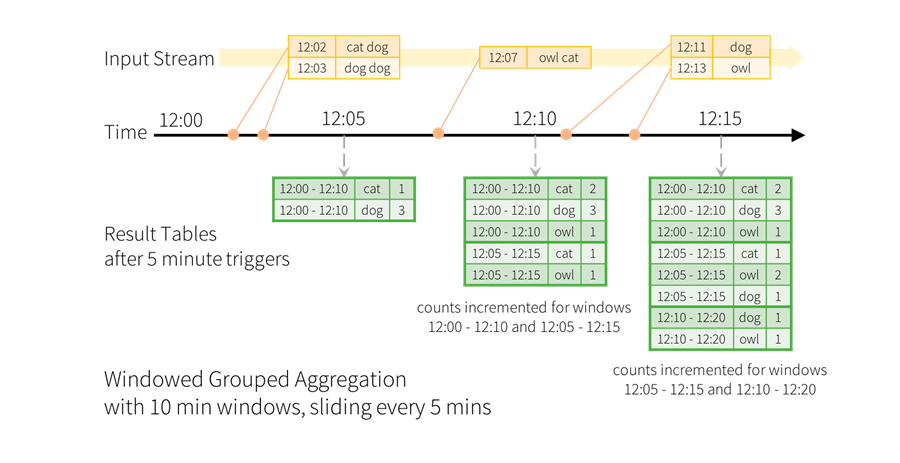
在 Structured Streaming 中, 可以按照事件发生时的时间对数据进行聚合操作, 即基于 event-time 进行操作。在这种机制下, 即不必考虑 Spark 陆续接收事件的顺序是否与事件发生的顺序一致, 也不必考虑事件到达 Spark 的时间与事件发生时间的关系。因此, 它在提高数据处理精度的同时, 大大减少了开发者的工作量。我们现在想计算 10 分钟内的单词, 每 5 分钟更新一次, 也就是说在 10 分钟窗口 12:00 - 12:10, 12:05 - 12:15, 12:10 - 12:20等之间收到的单词量。 注意, 12:00 - 12:10 表示数据在 12:00 之后 12:10 之前到达。现在,考虑一下在 12:07 收到的单词。单词应该增加对应于两个窗口12:00 - 12:10和12:05 - 12:15的计数。因此,计数将由分组键(即单词)和窗口(可以从事件时间计算)索引。
统计后的结果应该是这样的:
代码示例:
import org.apache.spark.sql.functions.window
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import java.sql.Timestampobject StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 使用socket数据源val lines: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).option("includeTimestamp", value = true) // 给产生的数据自动添加时间戳.load// 把行切割成单词, 保留时间戳val words: DataFrame = lines.as[(String, Timestamp)].flatMap((line: (String, Timestamp)) => {line._1.split(" ").map(((_: String), line._2))}).toDF("word", "timestamp")// 按照窗口和单词分组, 并且计算每组的单词的个数,最后按照窗口排序val wordCounts: Dataset[Row] = words.groupBy(// 调用 window 函数, 返回的是一个 Column 类型// 参数 1: df 中表示时间戳的列// 参数 2: 窗口长度// 参数 3: 滑动步长window($"timestamp", "60 seconds", "10 seconds"),$"word").count().orderBy($"window")wordCounts.writeStream.outputMode("complete").format("console").option("truncate", "false") // 不截断.为了在控制台能看到完整信息, 最好设置为 false.start.awaitTermination()// 关闭执行环境spark.stop()}
}结果输出:
-------------------------------------------
Batch: 0
-------------------------------------------
+------+----+-----+
|window|word|count|
+------+----+-----+
+------+----+-----+-------------------------------------------
Batch: 1
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2023-08-02 21:18:00, 2023-08-02 21:19:00]|abc |3 |
|[2023-08-02 21:18:10, 2023-08-02 21:19:10]|a |3 |
|[2023-08-02 21:18:10, 2023-08-02 21:19:10]|abc |5 |
|[2023-08-02 21:18:20, 2023-08-02 21:19:20]|abc |5 |
|[2023-08-02 21:18:20, 2023-08-02 21:19:20]|a |3 |
|[2023-08-02 21:18:30, 2023-08-02 21:19:30]|a |3 |
|[2023-08-02 21:18:30, 2023-08-02 21:19:30]|abc |5 |
|[2023-08-02 21:18:40, 2023-08-02 21:19:40]|abc |5 |
|[2023-08-02 21:18:40, 2023-08-02 21:19:40]|a |3 |
|[2023-08-02 21:18:50, 2023-08-02 21:19:50]|a |3 |
|[2023-08-02 21:18:50, 2023-08-02 21:19:50]|abc |5 |
|[2023-08-02 21:19:00, 2023-08-02 21:20:00]|a |3 |
|[2023-08-02 21:19:00, 2023-08-02 21:20:00]|abc |2 |
+------------------------------------------+----+-----+-------------------------------------------
Batch: 2
-------------------------------------------
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2023-08-02 21:18:00, 2023-08-02 21:19:00]|abc |3 |
|[2023-08-02 21:18:10, 2023-08-02 21:19:10]|a |3 |
|[2023-08-02 21:18:10, 2023-08-02 21:19:10]|abc |5 |
|[2023-08-02 21:18:20, 2023-08-02 21:19:20]|abc |5 |
|[2023-08-02 21:18:20, 2023-08-02 21:19:20]|a |3 |
|[2023-08-02 21:18:30, 2023-08-02 21:19:30]|a |3 |
|[2023-08-02 21:18:30, 2023-08-02 21:19:30]|abc |5 |
|[2023-08-02 21:18:40, 2023-08-02 21:19:40]|abc |5 |
|[2023-08-02 21:18:40, 2023-08-02 21:19:40]|a |3 |
|[2023-08-02 21:18:50, 2023-08-02 21:19:50]|a |3 |
|[2023-08-02 21:18:50, 2023-08-02 21:19:50]|abc |5 |
|[2023-08-02 21:19:00, 2023-08-02 21:20:00]|a |3 |
|[2023-08-02 21:19:00, 2023-08-02 21:20:00]|abc |2 |
|[2023-08-02 21:19:10, 2023-08-02 21:20:10]|a |2 |
|[2023-08-02 21:19:10, 2023-08-02 21:20:10]|abc |1 |
|[2023-08-02 21:19:20, 2023-08-02 21:20:20]|a |2 |
|[2023-08-02 21:19:20, 2023-08-02 21:20:20]|abc |1 |
|[2023-08-02 21:19:30, 2023-08-02 21:20:30]|a |2 |
|[2023-08-02 21:19:30, 2023-08-02 21:20:30]|abc |1 |
|[2023-08-02 21:19:40, 2023-08-02 21:20:40]|a |2 |
+------------------------------------------+----+-----+
only showing top 20 rows由此可以看出, 在这种窗口机制下, 无论事件何时到达, 以怎样的顺序到达, Structured Streaming 总会根据事件时间生成对应的若干个时间窗口, 然后按照指定的规则聚合。
2.2. event-time 窗口生成规则
可以查看 org.apache.spark.sql.catalyst.analysis.TimeWindowing 类下的如下代码:
The windows are calculated as below:
maxNumOverlapping <- ceil(windowDuration / slideDuration)
for (i <- 0 until maxNumOverlapping)windowId <- ceil((timestamp - startTime) / slideDuration)windowStart <- windowId * slideDuration + (i - maxNumOverlapping) * slideDuration + startTimewindowEnd <- windowStart + windowDurationreturn windowStart, windowEnd将event-time 作为“初始窗口”的结束时间, 然后按照窗口滑动宽度逐渐向时间轴前方推进, 直到某个窗口不再包含该 event-time 为止。 最终以“初始窗口”与“结束窗口”之间的若干个窗口作为最终生成的 event-time 的时间窗口。
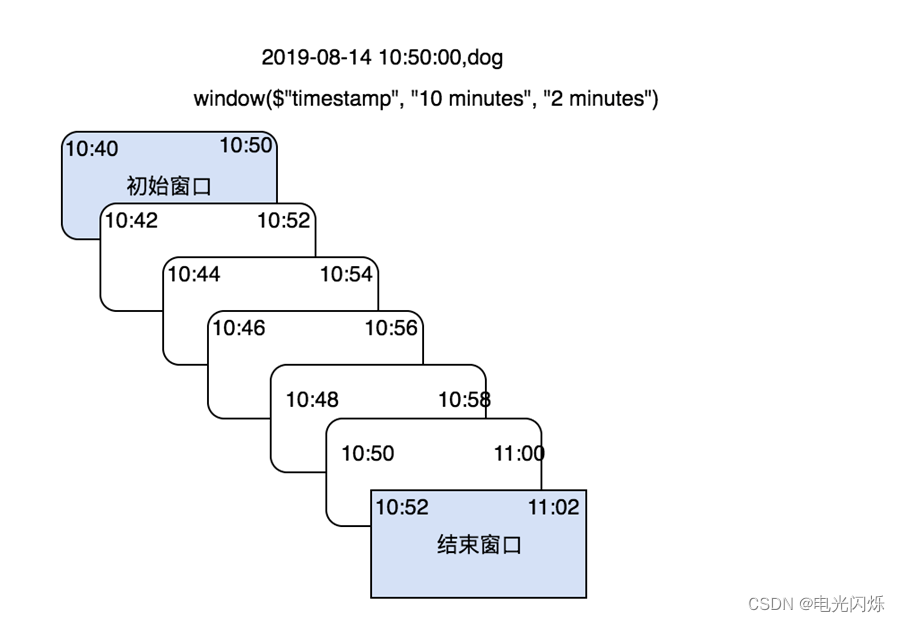
每个窗口的起始时间与结束时间都是前必后开的区间, 因此初始窗口和结束窗口都不会包含 event-time, 最终不会被使用。
得到窗口如下:

3. 基于 Watermark 处理延迟数据
3.1. 什么是 Watermark 机制
在数据分析系统中, Structured Streaming 可以持续的按照 event-time 聚合数据, 然而在此过程中并不能保证数据按照时间的先后依次到达。 例如: 当前接收的某一条数据的 event-time 可能远远早于之前已经处理过的 event-time。 在发生这种情况时, 往往需要结合业务需求对延迟数据进行过滤。现在考虑如果事件延迟到达会有哪些影响。 假如, 一个单词在 12:04(event-time) 产生, 在 12:11 到达应用。 应用应该使用 12:04 来在窗口(12:00 - 12:10)中更新计数, 而不是使用 12:11。 这些情况在我们基于窗口的聚合中是自然发生的, 因为结构化流可以长时间维持部分聚合的中间状态。
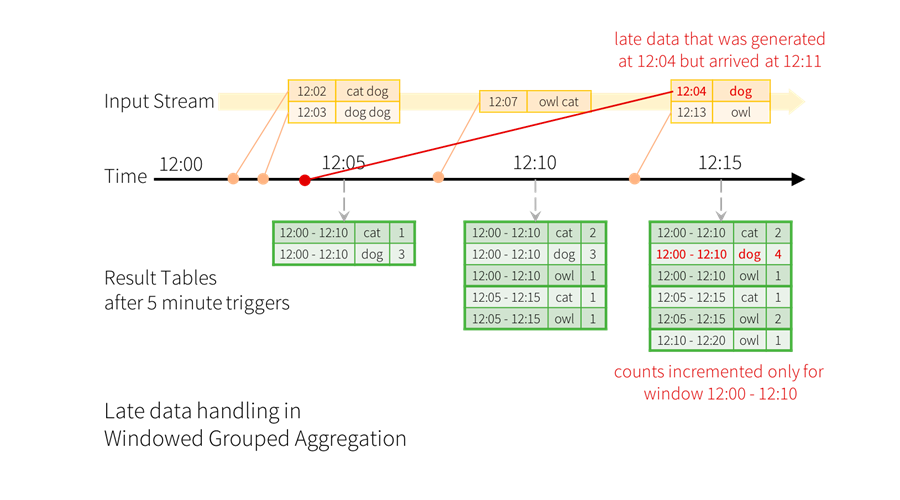
但是, 如果这个查询运行数天, 系统很有必要限制内存中累积的中间状态的数量。 这意味着系统需要知道何时从内存状态中删除旧聚合, 因为应用不再接受该聚合的后期数据。为了实现这个需求, 从 spark2.1, 引入了 watermark(水印), 使用引擎可以自动的跟踪当前的事件时间, 并据此尝试删除旧状态。通过指定 event-time 列和预估事件的延迟时间上限来定义一个查询的 watermark。 针对一个以时间 T 结束的窗口, 引擎会保留状态和允许延迟时间直到(max event time seen by the engine - late threshold > T)。 换句话说, 延迟时间在上限内的被聚合, 延迟时间超出上限的开始被丢弃。
可以通过withWatermark() 来定义watermark,watermark 计算方式:watermark = MaxEventTime - Threshhod;而且, watermark只能逐渐增加, 不能减少。
Structured Streaming 引入 Watermark 机制, 主要是为了解决以下两个问题:
- 处理聚合中的延迟数据
- 减少内存中维护的聚合状态.
注意:在不同输出模式(complete, append, update)中, Watermark 会产生不同的影响。
3.2. update 模式下使用 watermark
在 update 模式下, 仅输出与之前批次的结果相比, 涉及更新或新增的数据。
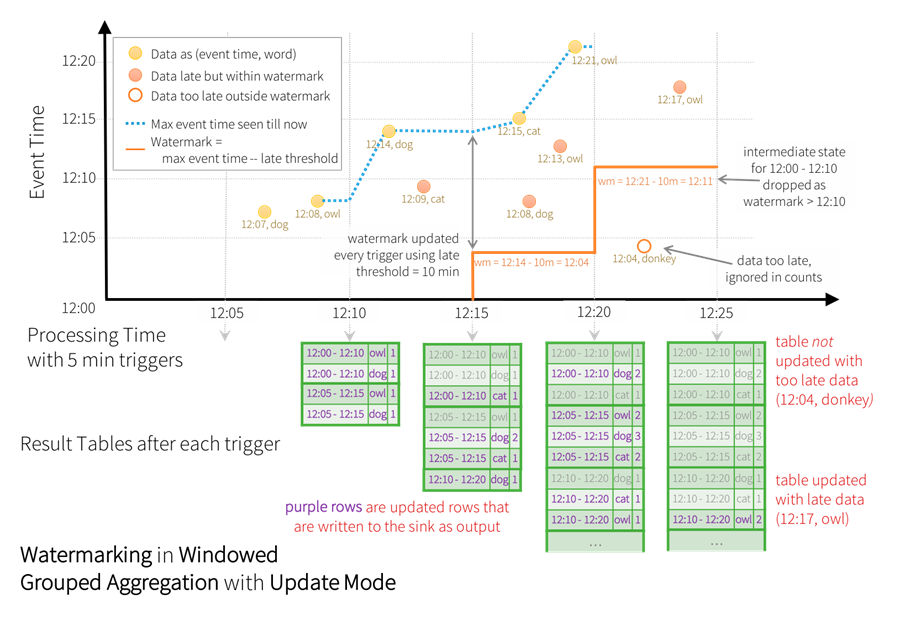
代码示例如下:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import java.sql.Timestampobject StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 使用socket数据源val lines: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load// 输入的数据中包含时间戳, 而不是自动添加的时间戳val words: DataFrame = lines.as[String].flatMap((line: String) => {val split: Array[String] = line.split(",")split(1).split(" ").map(((_: String), Timestamp.valueOf(split(0))))}).toDF("word", "timestamp")// 使用 withWatermark 方法,添加watermark, 参数 1: event-time 所在列的列名 参数 2: 延迟时间的上限.val wordCounts: Dataset[Row] = words.withWatermark("timestamp", "2 minutes").groupBy(window($"timestamp", "10 minutes", "2 minutes"), $"word").count()// 数据输出val query: StreamingQuery = wordCounts.writeStream.outputMode("update").trigger(Trigger.ProcessingTime(1000)).format("console").option("truncate", "false").startquery.awaitTermination()// 关闭执行环境spark.stop()}
}初始化的wartmark是 0,通过如下输入的几条数据,可以看到水位线的变化。
第一次输入数据: 2023-08-07 10:55:00,dog 。这个条数据作为第一批数据。 按照window($"timestamp", "10 minutes", "2 minutes")得到 5 个窗口。 由于是第一批, 所有的窗口的结束时间都大于 wartermark(0), 所以 5 个窗口都显示,如下所示:
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2023-08-07 10:50:00, 2023-08-07 11:00:00]|dog |1 |
|[2023-08-07 10:54:00, 2023-08-07 11:04:00]|dog |1 |
|[2023-08-07 10:48:00, 2023-08-07 10:58:00]|dog |1 |
|[2023-08-07 10:52:00, 2023-08-07 11:02:00]|dog |1 |
|[2023-08-07 10:46:00, 2023-08-07 10:56:00]|dog |1 |
+------------------------------------------+----+-----+然后根据当前批次中最大的 event-time, 计算出来下次使用的 watermark. 本批次只有一个数据(10:55), 所有: watermark = 10:55 - 2min = 10:53 。
第二次输入数据: 2023-08-07 11:00:00,dog 。 这条数据作为第二批数据, 计算得到 5 个窗口。 此时的watermark=10:53, 所有的窗口的结束时间均大于 watermark。 在 update 模式下, 只输出结果表中涉及更新或新增的数据。
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2023-08-07 10:58:00, 2023-08-07 11:08:00]|dog |1 |
|[2023-08-07 10:54:00, 2023-08-07 11:04:00]|dog |2 |
|[2023-08-07 10:56:00, 2023-08-07 11:06:00]|dog |1 |
|[2023-08-07 10:52:00, 2023-08-07 11:02:00]|dog |2 |
|[2023-08-07 11:00:00, 2023-08-07 11:10:00]|dog |1 |
+------------------------------------------+----+-----+其中: count 是 2 的表示更新, count 是 1 的表示新增。 没有变化的就没有显示(但是内存中仍然保存着)。此时的的 watermark = 11:00 - 2min = 10:58 。如下数据为在内存中保存着,但是没有打印出来的数据:
|[2023-08-07 10:46:00, 2023-08-07 10:56:00]|dog |1 |
|[2023-08-07 10:48:00, 2023-08-07 10:58:00]|dog |1 |
|[2023-08-07 10:50:00, 2023-08-07 11:00:00]|dog |1 |第三次输入数据: 2023-08-07 10:55:00,dog 。 这条数据作为第 3 批次,相当于一条延迟数据,计算得到 5 个窗口。此时的 watermark = 10:58 当前内存中有两个窗口的结束时间已经低于 10: 58。
|[2023-08-07 10:46:00, 2023-08-07 10:56:00]|dog |1 |
|[2023-08-07 10:48:00, 2023-08-07 10:58:00]|dog |1 |则立即删除这两个窗口在内存中的维护状态。 同时, 当前批次中新加入的数据所划分出来的窗口, 如果窗口结束时间低于 11:58, 则窗口会被过滤掉。
所以这次输出结果:
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2023-08-07 10:50:00, 2023-08-07 11:00:00]|dog |2 |
|[2023-08-07 10:54:00, 2023-08-07 11:04:00]|dog |3 |
|[2023-08-07 10:52:00, 2023-08-07 11:02:00]|dog |3 |
+------------------------------------------+----+-----+第三个批次的数据处理完成后, 立即计算: watermark= 10:55 - 2min = 10:53, 这个值小于当前的 watermask(10:58), 所以保持不变(因为 watermask 只能增加不能减少)。
3.3. append 模式下使用 wartermark
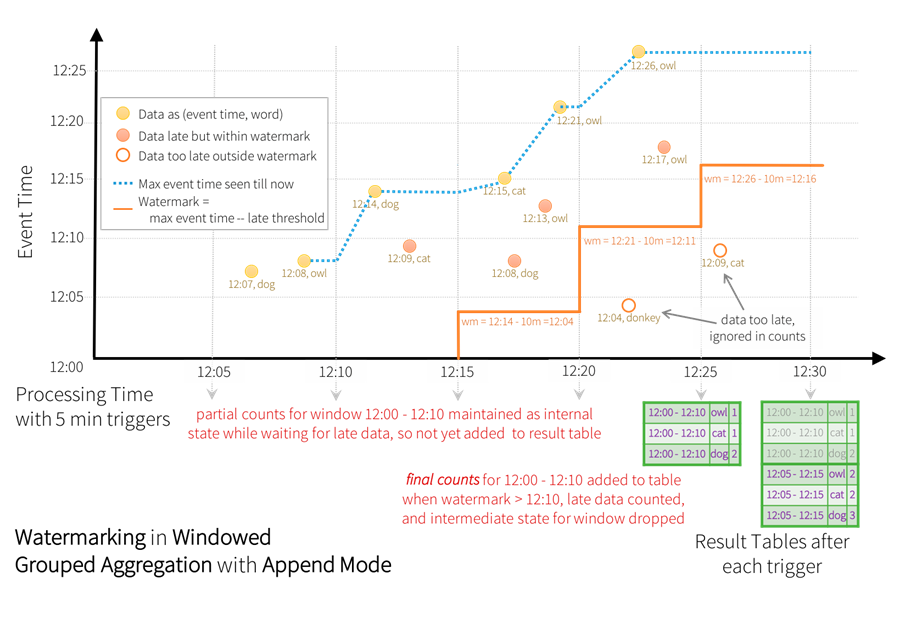
代码示例如下:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import java.sql.Timestampobject StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 使用socket数据源val lines: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load// 输入的数据中包含时间戳, 而不是自动添加的时间戳val words: DataFrame = lines.as[String].flatMap((line: String) => {val split: Array[String] = line.split(",")split(1).split(" ").map(((_: String), Timestamp.valueOf(split(0))))}).toDF("word", "timestamp")// 使用 withWatermark 方法,添加watermark, 参数 1: event-time 所在列的列名 参数 2: 延迟时间的上限.val wordCounts: Dataset[Row] = words.withWatermark("timestamp", "2 minutes").groupBy(window($"timestamp", "10 minutes", "2 minutes"), $"word").count()// 数据输出val query: StreamingQuery = wordCounts.writeStream.outputMode("append").trigger(Trigger.ProcessingTime(0)).format("console").option("truncate", "false").startquery.awaitTermination()// 关闭执行环境spark.stop()}
}
在 append 模式中, 仅输出新增的数据, 且输出后的数据无法变更。
第一次输入数据: 2023-08-07 10:55:00,dog 。 这个条数据作为第一批数据。 按照window($"timestamp", "10 minutes", "2 minutes")得到 5 个窗口。 由于此时初始 watermask=0, 当前批次中所有窗口的结束时间均大于 watermask。但是 Structured Streaming 无法确定后续批次的数据中是否会更新当前批次的内容。 因此, 基于 Append 模式的特点, 这时并不会输出任何数据(因为输出后数据就无法更改了), 直到某个窗口的结束时间小于 watermask, 即可以确定后续数据不会再变更该窗口的聚合结果时才会将其输出, 并移除内存中对应窗口的聚合状态。
+------+----+-----+
|window|word|count|
+------+----+-----+
+------+----+-----+然后根据当前批次中最大的 event-time, 计算出来下次使用的 watermark。 本批次只有一个数据(10:55), 所有: watermark = 10:55 - 2min = 10:53
第二次输入数据: 2023-08-07 11:00:00,dog 。这条数据作为第二批数据, 计算得到 5 个窗口。 此时的watermark=10:53, 所有的窗口的结束时间均大于 watermark, 仍然不会输出。
+------+----+-----+
|window|word|count|
+------+----+-----+
+------+----+-----+然后计算 watermark = 11:00 - 2min = 10:58
第三次输入数据: 2023-08-07 10:55:00,dog 。相当于一条延迟数据,这条数据作为第 3 批次, 计算得到 5 个窗口。 此时的 watermark = 10:58 当前内存中有两个窗口的结束时间已经低于 10: 58。
|[2023-08-07 10:48:00, 2023-08-07 10:58:00]|dog |1 |
|[2023-08-07 10:46:00, 2023-08-07 10:56:00]|dog |1 |则意味着这两个窗口的数据不会再发生变化, 此时输出这个两个窗口的聚合结果, 并在内存中清除这两个窗口的状态。所以这次输出结果:
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2023-08-07 10:48:00, 2023-08-07 10:58:00]|dog |1 |
|[2023-08-07 10:46:00, 2023-08-07 10:56:00]|dog |1 |
+------------------------------------------+----+-----+第三个批次的数据处理完成后, 立即计算: watermark= 10:55 - 2min = 10:53, 这个值小于当前的 watermask(10:58), 所以保持不变。(因为 watermask 只能增加不能减少)
3.4. watermark 机制总结
- watermark 在用于基于时间的状态聚合操作时, 该时间可以基于窗口, 也可以基于 event-timeb本身。
- 输出模式必须是append或update。 在输出模式是complete的时候(必须有聚合), 要求每次输出所有的聚合结果。 我们使用 watermark 的目的是丢弃一些过时聚合数据, 所以complete模式使用wartermark无效也无意义。
- 在输出模式是append时, 必须设置 watermask 才能使用聚合操作。 其实, watermask 定义了 append 模式中何时输出聚合聚合结果(状态), 并清理过期状态。
- 在输出模式是update时, watermask 主要用于过滤过期数据并及时清理过期状态。
- watermask 会在处理当前批次数据时更新, 并且会在处理下一个批次数据时生效使用。 但如果节点发送故障, 则可能延迟若干批次生效。
- withWatermark 必须使用与聚合操作中的时间戳列是同一列。df.withWatermark("time", "1 min").groupBy("time2").count() 无效。
- withWatermark 必须在聚合之前调用。 f.groupBy("time").count().withWatermark("time", "1 min") 无效。
4. 流数据去重
需求内容:根据唯一的 id 实现数据去重
代码示例:
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import java.sql.Timestampobject StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 使用socket数据源val lines: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load// 数据预处理val words: DataFrame = lines.as[String].map((line: String) => {val arr: Array[String] = line.split(",")(arr(0), Timestamp.valueOf(arr(1)), arr(2))}).toDF("uid", "ts", "word")// 去重重复数据 uid 相同就是重复. 可以传递多个列val wordCounts: Dataset[Row] = words.withWatermark("ts", "2 minutes").dropDuplicates("uid")// 输出数据wordCounts.writeStream.outputMode("append").format("console").start.awaitTermination()// 关闭执行环境spark.stop()}
}数据输入(按顺序从上到下):
1,2023-08-09 11:50:00,dog
2,2023-08-09 11:51:00,dog
1,2023-08-09 11:50:00,dog
3,2023-08-09 11:53:00,dog
1,2023-08-09 11:50:00,dog
4,2023-08-09 11:45:00,dog注意点:
- dropDuplicates 不可用在聚合之后, 即通过聚合得到的 df/ds 不能调用dropDuplicates
- 使用watermask - 如果重复记录的到达时间有上限,则可以在事件时间列上定义水印,并使用guid和事件时间列进行重复数据删除。该查询将使用水印从过去的记录中删除旧的状态数据,这些记录不会再被重复。这限制了查询必须维护的状态量。
- 没有watermask - 由于重复记录可能到达时没有界限,查询将来自所有过去记录的数据存储为状态。
测试:
- 第一次输入数据:1,2023-08-09 11:50:00,dog
+---+-------------------+----+
|uid| ts|word|
+---+-------------------+----+
| 1|2023-08-09 11:50:00| dog|
+---+-------------------+----+- 第二次输入数据:2,2023-08-09 11:51:00,dog
+---+-------------------+----+
|uid| ts|word|
+---+-------------------+----+
| 2|2023-08-09 11:51:00| dog|
+---+-------------------+----+- 第三次输入数据:1,2023-08-09 11:50:00,dog (id 重复无输出)
- 第四次输入数据:3,2023-08-09 11:53:00,dog (此时 watermask=11:51)
+---+-------------------+----+
|uid| ts|word|
+---+-------------------+----+
| 3|2023-08-09 11:53:00| dog|
+---+-------------------+----+- 第五次输入数据:1,2023-08-09 11:50:00,dog (数据重复, 并且数据过期, 所以无输出)
- 第六次输入数据:4,2023-08-09 11:45:00,dog (数据过时, 所以无输出)
5. join操作
Structured Streaming 支持 streaming DataSet/DataFrame 与静态的DataSet/DataFrame 进行 join, 也支持 streaming DataSet/DataFrame与另外一个streaming DataSet/DataFrame 进行 join。join 的结果也是持续不断的生成, 类似于前面的 streaming 的聚合结果。
5.1. Stream-static Joins
静态数据:
lisi,male
zhiling,female
zs,male流式数据:
lisi,20
zhiling,40
ww,305.1.1. 内连接
代码示例:
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 1. 静态 dfval arr: Array[(String, String)] = Array(("lisi", "male"), ("zhiling", "female"), ("zs", "male"));val staticDF: DataFrame = spark.sparkContext.parallelize(arr).toDF("name", "sex")// 2. 流式 dfval lines: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()val streamDF: DataFrame = lines.as[String].map((line: String) => {val arr: Array[String] = line.split(",")(arr(0), arr(1).toInt)}).toDF("name", "age")// 3. join 等值内连接 a.name=b.nameval joinResult: DataFrame = streamDF.join(staticDF, "name")// 4. 输出joinResult.writeStream.outputMode("append").format("console").start.awaitTermination()// 关闭执行环境spark.stop()}
}数据输出:
+-------+---+------+
| name|age| sex|
+-------+---+------+
|zhiling| 40|female|
| lisi| 20| male|
+-------+---+------+5.1.2. 外连接
代码示例:
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 1. 静态 dfval arr: Array[(String, String)] = Array(("lisi", "male"), ("zhiling", "female"), ("zs", "male"));val staticDF: DataFrame = spark.sparkContext.parallelize(arr).toDF("name", "sex")// 2. 流式 dfval lines: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()val streamDF: DataFrame = lines.as[String].map((line: String) => {val arr: Array[String] = line.split(",")(arr(0), arr(1).toInt)}).toDF("name", "age")// 3. joinval joinResult: DataFrame = streamDF.join(staticDF, Seq("name"), "left")// 4. 输出joinResult.writeStream.outputMode("append").format("console").start.awaitTermination()// 关闭执行环境spark.stop()}
}数据输出:
+-------+---+------+
| name|age| sex|
+-------+---+------+
|zhiling| 40|female|
| ww| 30| null|
| lisi| 20| male|
+-------+---+------+5.2. Stream-stream Joins
在 Spark2.3, 开始支持 stream-stream join。Spark 会自动维护两个流的状态, 以保障后续流入的数据能够和之前流入的数据发生 join 操作, 但这会导致状态无限增长。 因此, 在对两个流进行 join 操作时, 依然可以用 watermark 机制来消除过期的状态, 避免状态无限增长。
第 1 个数据格式:姓名,年龄,事件时间
lisi,female,2023-08-09 11:50:00
zs,male,2023-08-09 11:51:00
ww,female,2023-08-09 11:52:00
zhiling,female,2023-08-09 11:53:00
fengjie,female,2023-08-09 11:54:00
yifei,female,2023-08-09 11:55:00第 2 个数据格式:姓名,年龄,事件时间
lisi,18,2023-08-09 11:50:00
zs,19,2023-08-09 11:51:00
ww,20,2023-08-09 11:52:00
zhiling,22,2023-08-09 11:53:00
yifei,30,2023-08-09 11:54:00
fengjie,98,2023-08-09 11:55:005.2.1. inner join
对 2 个流式数据进行 join 操作,输出模式仅支持append模式。
不带 watermast 的 inner join(join 的速度很慢):
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import java.sql.Timestampobject StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 第 1 个 streamval nameSexStream: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load.as[String].map((line: String) => {val arr: Array[String] = line.split(",")(arr(0), arr(1), Timestamp.valueOf(arr(2)))}).toDF("name", "sex", "ts1")// 第 2 个 streamval nameAgeStream: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 8888).load.as[String].map((line: String) => {val arr: Array[String] = line.split(",")(arr(0), arr(1).toInt, Timestamp.valueOf(arr(2)))}).toDF("name", "age", "ts2")// join 操作val joinResult: DataFrame = nameSexStream.join(nameAgeStream, "name")// 数据输出joinResult.writeStream.outputMode("append").format("console").trigger(Trigger.ProcessingTime(0)).start().awaitTermination()// 关闭执行环境spark.stop()}
}// 数据输出:
// +-------+------+-------------------+---+-------------------+
// | name| sex| ts1|age| ts2|
// +-------+------+-------------------+---+-------------------+
// |zhiling|female|2023-08-09 11:53:00| 22|2023-08-09 11:53:00|
// | ww|female|2023-08-09 11:52:00| 20|2023-08-09 11:52:00|
// | yifei|female|2023-08-09 11:55:00| 30|2023-08-09 11:54:00|
// | zs| male|2023-08-09 11:51:00| 19|2023-08-09 11:51:00|
// |fengjie|female|2023-08-09 11:54:00| 98|2023-08-09 11:55:00|
// | lisi|female|2023-08-09 11:50:00| 18|2023-08-09 11:50:00|
// +-------+------+-------------------+---+-------------------+
带 watermast 的 inner join(join 的速度很慢):
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import java.sql.Timestampobject StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 第 1 个 streamval nameSexStream: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load.as[String].map((line: String) => {val arr: Array[String] = line.split(",")(arr(0), arr(1), Timestamp.valueOf(arr(2)))}).toDF("name1", "sex", "ts1")// 第 2 个 streamval nameAgeStream: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 8888).load.as[String].map((line: String) => {val arr: Array[String] = line.split(",")(arr(0), arr(1).toInt, Timestamp.valueOf(arr(2)))}).toDF("name2", "age", "ts2").withWatermark("ts2", "1 minutes")// join 操作val joinResult: DataFrame = nameSexStream.join(nameAgeStream,expr("""|name1=name2 and|ts2 >= ts1 and|ts2 <= ts1 + interval 1 minutes""".stripMargin))// 数据输出joinResult.writeStream.outputMode("append").format("console").trigger(Trigger.ProcessingTime(0)).start().awaitTermination()// 关闭执行环境spark.stop()}
}// 数据输出:
// +-------+------+-------------------+-------+---+-------------------+
// | name1| sex| ts1| name2|age| ts2|
// +-------+------+-------------------+-------+---+-------------------+
// |zhiling|female|2023-08-09 11:53:00|zhiling| 22|2023-08-09 11:53:00|
// | ww|female|2023-08-09 11:52:00| ww| 20|2023-08-09 11:52:00|
// | zs| male|2023-08-09 11:51:00| zs| 19|2023-08-09 11:51:00|
// |fengjie|female|2023-08-09 11:54:00|fengjie| 98|2023-08-09 11:55:00|
// | lisi|female|2023-08-09 11:50:00| lisi| 18|2023-08-09 11:50:00|
// +-------+------+-------------------+-------+---+-------------------+4.2.2. outer join
外连接必须使用 watermast,和内连接相比, 代码几乎一致, 只需要在连接的时候指定下连接类型即可:joinType = "left"。
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import java.sql.Timestampobject StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 第 1 个 streamval nameSexStream: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load.as[String].map((line: String) => {val arr: Array[String] = line.split(",")(arr(0), arr(1), Timestamp.valueOf(arr(2)))}).toDF("name1", "sex", "ts1")// 第 2 个 streamval nameAgeStream: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", 8888).load.as[String].map((line: String) => {val arr: Array[String] = line.split(",")(arr(0), arr(1).toInt, Timestamp.valueOf(arr(2)))}).toDF("name2", "age", "ts2").withWatermark("ts2", "1 minutes")// join 操作val joinResult: DataFrame = nameSexStream.join(nameAgeStream,expr("""|name1=name2 and|ts2 >= ts1 and|ts2 <= ts1 + interval 1 minutes""".stripMargin),joinType = "left")// 数据输出joinResult.writeStream.outputMode("append").format("console").trigger(Trigger.ProcessingTime(0)).start().awaitTermination()// 关闭执行环境spark.stop()}
}// 数据输出:
// +-------+------+-------------------+-------+---+-------------------+
// | name1| sex| ts1| name2|age| ts2|
// +-------+------+-------------------+-------+---+-------------------+
// |zhiling|female|2023-08-09 11:53:00|zhiling| 22|2023-08-09 11:53:00|
// | ww|female|2023-08-09 11:52:00| ww| 20|2023-08-09 11:52:00|
// | zs| male|2023-08-09 11:51:00| zs| 19|2023-08-09 11:51:00|
// |fengjie|female|2023-08-09 11:54:00|fengjie| 98|2023-08-09 11:55:00|
// | lisi|female|2023-08-09 11:50:00| lisi| 18|2023-08-09 11:50:00|
// +-------+------+-------------------+-------+---+-------------------+
6. Streaming DF/DS 不支持的操作
到目前, DF/DS 的有些操作 Streaming DF/DS 还不支持:
- 多个Streaming 聚合(例如在 DF 上的聚合链)目前还不支持
- limit 和取前 N 行还不支持
- distinct 也不支持
- 仅仅支持对 complete 模式下的聚合操作进行排序操作
- 仅支持有限的外连接
- 有些方法不能直接用于查询和返回结果, 因为他们用在流式数据上没有意义
- count() 不能返回单行数据, 必须是s.groupBy().count()
- foreach() 不能直接使用, 而是使用: ds.writeStream.foreach(...)
- show() 不能直接使用, 而是使用 console sink
如果执行上面操作会看到这样的异常: operation XYZ is not supported with streaming DataFrames/Datasets。
注:其他Spark相关系列文章链接由此进 -> Spark文章汇总
相关文章:
Spark(38):Streaming DataFrame 和 Streaming DataSet 转换
目录 0. 相关文章链接 1. 基本操作 1.1. 弱类型 api 1.2. 强类型 1.3. 直接执行 sql 2. 基于 event-time 的窗口操作 2.1. event-time 窗口理解 2.2. event-time 窗口生成规则 3. 基于 Watermark 处理延迟数据 3.1. 什么是 Watermark 机制 3.2. update 模式下使用 w…...
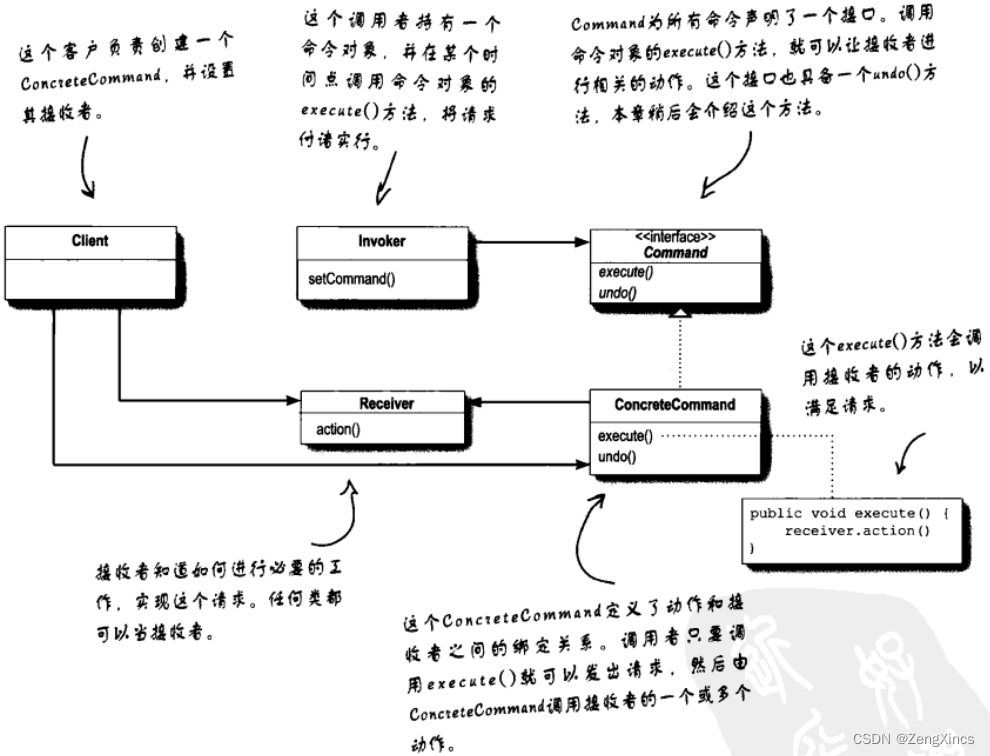
设计模式之六:命令模式(封装调用)
命令模式可以将请求的对象和执行请求的对象解耦(实际上是通过命令对象进行沟通,即解耦)。(个人感觉,这章讲的很一般) 按个人理解来讲: 假如需要一个遥控器,遥控器有一个插口可以插上…...

git删除历史提交中的某些文件
要从所有提交中删除PDF文件并保留本地文件,你需要使用git filter-repo命令或git filter-branch命令来重写历史。请注意,这将修改提交历史,因此需要小心操作,确保在执行之前备份数据。 以下是使用git filter-repo命令的示例&#…...
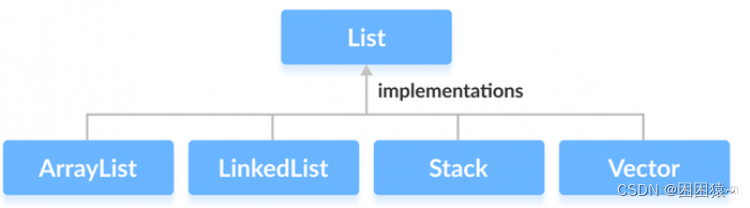
Java List(列表)
List 是一个有序、可重复的集合,集合中每个元素都有其对应的顺序索引。List 集合允许使用重复元素,可以通过索引来访问指定位置的集合元素。List 集合默认按元素的添加顺序设置元素的索引,第一个添加到 List 集合中的元素的索引为 0ÿ…...
虚拟机的创建与使用
一、虚拟机的下载 链接:百度网盘下载链接 提取码:a9p4 二、新建虚拟机系统 需要有版本序列号 注意: 选择 第一个是纯dos 的窗口指令 桌面没有任何东西 选择第二个就是正常的操作系统.有文件夹 我的电脑之类的 三、从主机中复制文件到虚拟机中需要安装 …...

springboot传给前端日期少了八小时
在Spring Boot中,如果从MySQL数据库中获取日期,并在前端显示时少了8小时,这通常是由于时区的问题导致的。MySQL默认使用系统的时区,而Spring Boot默认使用UTC时区。 spring-boot默认使用Jackson对返回到前端的值进行序列化。Jack…...
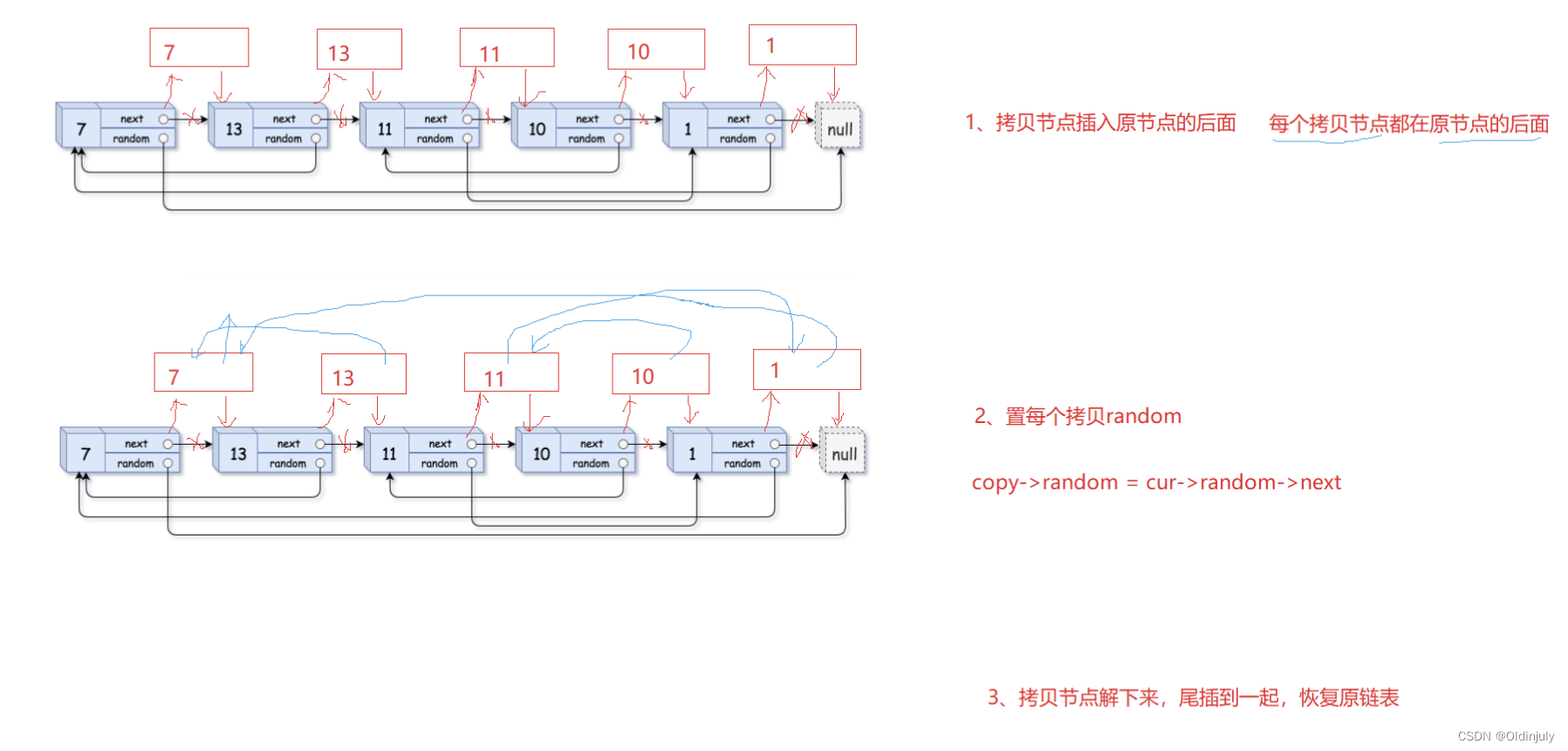
链表数组OJ题汇总
前言: 在计算机科学中,数组和链表是两种常见的数据结构,用于存储和组织数据。它们分别具有不同的特点和适用场景。 本博客将深入讨论数组和链表在OJ题目中的应用。我们将从基本概念开始,介绍数组和链表的定义和特点,并…...

中间人攻击与 RADIUS 身份验证
在数字时代,中间人(MitM)攻击已成为一种日益严重的威胁。根据网络安全风险投资公司的网络安全统计数据,预计到2025年,网络犯罪每年将给世界造成10.5万亿美元的损失,比2015年的3万亿美元大幅增加。这种令人震…...
虚拟机安装国产操作系统的方法
1.这里以银河麒麟为例,其他以liunx为基础的国产操作系统都是一样的方法。 2.下载操作系统如下(选第一个就行): 任选其一下载: 3.安装虚拟机软件(这里以virtualbox为例,vmare也是一样都可以) 4.打开虚拟机…...
【Linux】云服务器自动化部署VuePress博客(Jenkins)
前言 博主此前是将博客部署在 Github Pages(基于 Github Action)和 Vercel 上的,但是这两种部署方式对于国内用户很不友好,访问速度堪忧。因此将博客迁移到自己的云服务器上,并且基于 Jenkins(一款开源持续…...

Golang字符串处理深入解析:探索 strings 标准库的全部方法
Golang 的 strings 标准库提供了许多用于处理字符串的函数。以下是一些主要的方法: Contains(s, substr string) bool: 检查字符串是否包含子串。ContainsAny(s, chars string) bool: 检查字符串是否包含字符集中的任何字符。ContainsRune(s string, r rune) bool:…...
如何在群辉NAS系统下安装cpolar套件,并使用cpolar内网穿透?
如何在群辉NAS系统下安装cpolar套件,并使用cpolar内网穿透? 文章目录 如何在群辉NAS系统下安装cpolar套件,并使用cpolar内网穿透?前言1. 在群辉NAS系统下安装cpolar套件2. 管理隧道列表3. 创建固定数据隧道 前言 群晖作为大容量存储系统,既可…...
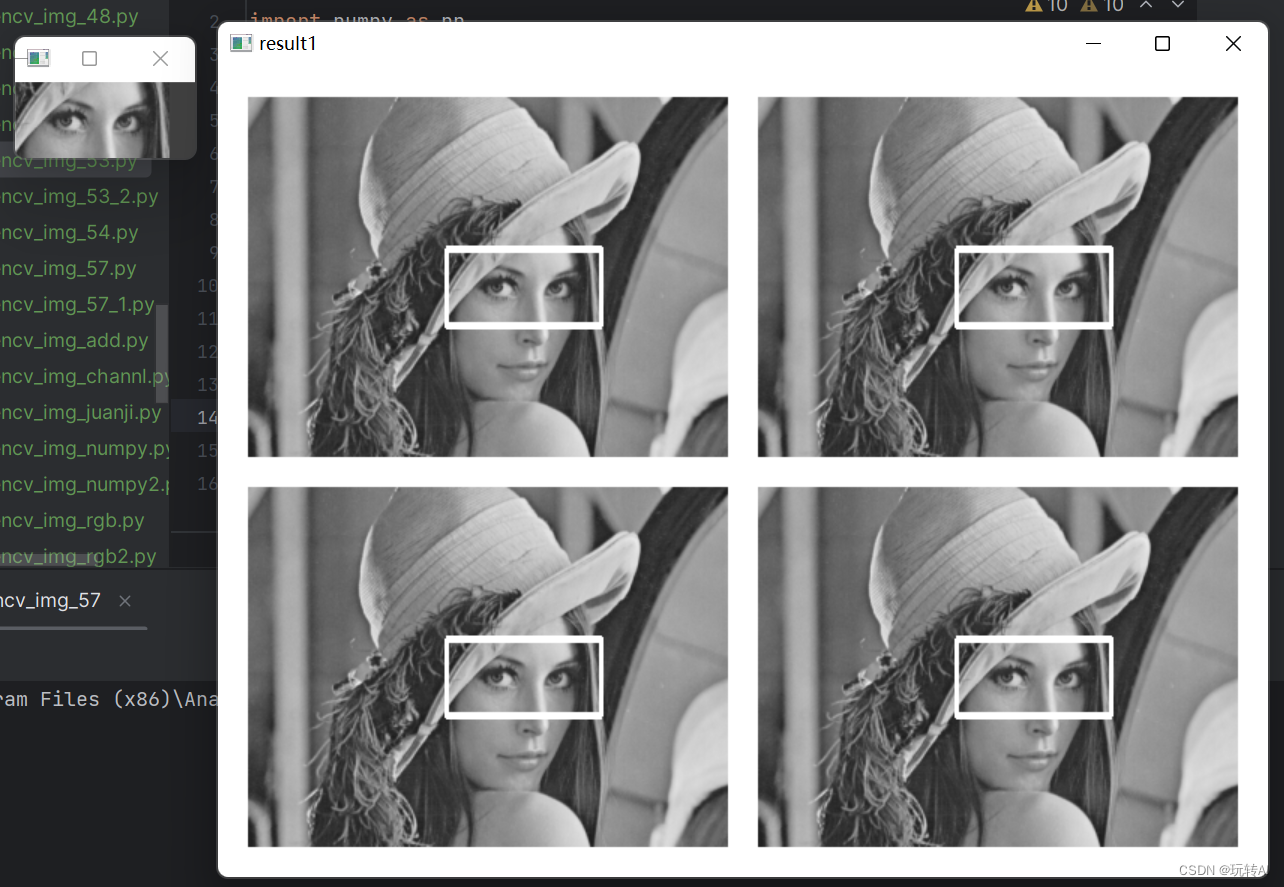
opencv基础57-模板匹配cv2.matchTemplate()->(目标检测、图像识别、特征提取)
OpenCV 提供了模板匹配(Template Matching)的功能,它允许你在图像中寻找特定模板(小图像)在目标图像中的匹配位置。模板匹配在计算机视觉中用于目标检测、图像识别、特征提取等领域。 以下是 OpenCV 中使用模板匹配的基…...

搜索插入位置
题目描述: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 示例 1: 输入: nums [1,3,5,6], target …...
)
Centos Linux快速复制文件并查看进度的方法(保留文件原始时间戳等属性)
用cp命令保证快速复制,screen保证不丢失你对cp命令执行情况的掌控。 需要用到screen软件包,防止复制过程中终端被关闭。 centos linux直到7默认都没有screen,需要安装一下 普通账户: sudo yum -y install screen root账户&am…...

牛奶产业链的工业“链主品牌”利乐是如何诞生的?
瑞典的利乐公司,一个在乳品产业链中占据重要地位的“链主品牌”,通过提供创新的包装材料和解决方案,在全球范围内占据了显著的市场份额。利乐从不生产一滴奶,却赚取了中国乳业 75%的利润,一年创收超过 800 亿人民币。在…...

【历史上的今天】8 月 11 日:苹果电脑之父诞生;阿里巴巴收购雅虎中国;OpenAI 击败电竞世界冠军
整理 | 王启隆 透过「历史上的今天」,从过去看未来,从现在亦可以改变未来。 今天是 2023 年 8 月 11 日,在 1999 年的今天,欧亚一些地区观赏到了一次壮丽的日全食景象。这次日全食是本世纪最后一次日全食,将持续两分钟…...

Flutter 报错 Could not create task ‘xxx‘.this and base files have different roots
遇到此问题也是先去百度了,有的说改了Gradle版本、gradle-wrapper.properties版本和ext.kotlin_version版本之后解决的,我没尝试,我用蹩脚的英语大致读了一下就不是这样说的,况且我用有道翻译了也不是这个意思啊,我不知…...
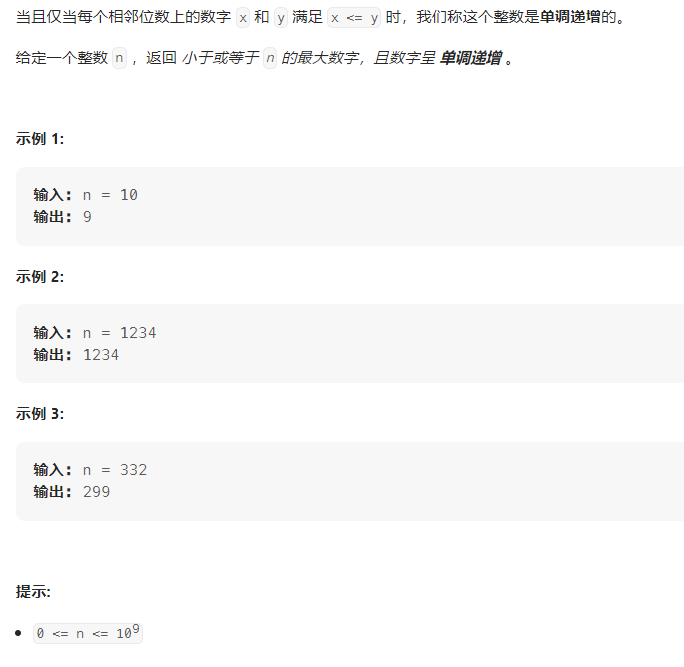
单调递增的数字——力扣738
文章目录 题目描述解法题目描述 解法 #include<iostream> #include<string>using namespace std;int monotoneIncreasingDigits...

STL文件格式详解【3D】
STL(StereoLithography:立体光刻)文件是 3 维表面几何形状的三角形表示。 表面被逻辑地细分或分解为一系列小三角形(面)。 每个面由垂直方向和代表三角形顶点(角)的三个点来描述。 切片算法使用…...

10个rom-rb最佳实践技巧:从入门到专家级
10个rom-rb最佳实践技巧:从入门到专家级 【免费下载链接】rom Data mapping and persistence toolkit for Ruby 项目地址: https://gitcode.com/gh_mirrors/ro/rom rom-rb是Ruby的强大数据映射和持久化工具包,它提供了灵活的方式来处理数据访问层…...

第四章:TTM分析: 4.5.1 ttm_device对三大设计目标的实现
2. 统一管理异构内存域 这是 ttm_device 最基础的职责:将 VRAM、GTT、SYSTEM 等物理上完全不同的内存,纳入统一的管理框架。 2.1 资源管理器数组 man_drv[] struct ttm_resource_manager *man_drv[TTM_NUM_MEM_TYPES];这是一个按内存域类型索引的指针…...

PyWxDump技术剖析:数据解密工具的合规边界与安全启示
PyWxDump技术剖析:数据解密工具的合规边界与安全启示 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 技术挑战与应对策略的双重博弈 在数字隐私与数据安全日益重要的今天,微信数据解密工具PyWxDump…...

视觉语言模型几何对偶框架解决幻觉问题
1. 项目背景与核心挑战视觉语言模型(VLM)在跨模态理解任务中展现出强大能力的同时,也面临着"幻觉"问题——模型生成的描述与图像实际内容存在偏差。这种现象在医疗诊断、自动驾驶等关键领域可能造成严重后果。传统解决方法多从数据…...

STM32F103驱动WS2812B全彩灯带:手把手教你用PWM+DMA实现呼吸灯和彩虹跑马灯
STM32F103驱动WS2812B全彩灯带:从基础驱动到高级特效实战 在嵌入式开发领域,控制WS2812B全彩LED灯带一直是电子爱好者和创客们热衷的项目。这种集成了控制电路和RGB芯片的智能外设,仅需单线通信就能实现复杂的灯光效果,为各种创意…...

5分钟掌握哔哩下载姬:B站视频下载的完整免费方案
5分钟掌握哔哩下载姬:B站视频下载的完整免费方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)…...

一分钟了解UART协议
UART(Universal Asynchronous Receiver/Transmitter,通用异步收发器)是一种双向、串行、异步的通信总线,仅用一根数据接收线和一根数据发送线就能实现全双工通信。 典型的串口通信使用3根线完成,分别是:发送线(TX)、接收线(RX)和地线(GND),通信时必须将双方的TX和…...

OpenClaw科研全场景用法:从文献到实验室的完整自动化方案
OpenClaw与科研的结合,本质上是将研究者从“动手执行”中解放出来,把精力集中到“动脑思考”上。以下是覆盖科研全流程的场景化用法指南。 一、全场景能力图谱 OpenClaw的153个科研Skill覆盖了从文献调研到论文发表、从数据分析到实验操作的完整链条&…...

Unity游戏视觉去马赛克技术解析:6款BepInEx插件实现原理与实战指南
Unity游戏视觉去马赛克技术解析:6款BepInEx插件实现原理与实战指南 【免费下载链接】UniversalUnityDemosaics A collection of universal demosaic BepInEx plugins for games made in Unity3D engine 项目地址: https://gitcode.com/gh_mirrors/un/UniversalUni…...

图像生成提示词工程
这个系列将集合各种优秀图像或视频生成的提示词:1. 毕业照生成效果:提示词:根据我的人物肖像自动生成一张收藏版史诗叙事海报(毕业照:巨大的我的侧脸剪影作为外轮廓,剪影内部自动生长出最契合该主题的完整世…...